判别分析作业3
多元统计分析课件第六章-判别分析例题与操作过程可修改文字

.
(一) 操作步骤 1. 在SPSS窗口中选择Analyze→Classify→Discriminate,调 出判别分析主界面,将左边的变量列表中的“group”变量选 入分组变量中,将—变量选入自变量中,并选择Enter independents together单选按钮,即使用所有自变量进行判 别分析。
1
5
50.06 23.03 2.83 23.74 112.52 63.3
1
6
33.24 6.24 1.18 22.9 160.01 65.4
2
7
32.22 4.22 1.06 20.7 124.7 68.7
2
8
41.15 10.08 2.32 32.84 172.06 65.85
2
9
53.04 25.74 4.06 34.87 152.03 63.5
由此表可知,两个Fisher判别函数分别为:
y1 74.99 1.861X1 1.656X 2 0.877 X3 0.798X 4 0.098X 5 1.579X 6 y2 29.482 0.867X1 1.155X 2 0.356X 3 0.089X 4 0.054X 5 0.69 X 6
判别分析例题
例1:设有两个正态总体 G1 和 G2 ,已知:
(1)
ห้องสมุดไป่ตู้
10 15
(2)
20 25
18 12 1=12 32
20 7
2
=
7
5
试用距离判别法判断:样品:
X
20 20
,应归属于哪一类
判别分析例题 解:比较X到两个总体的马氏距离的大小
所以X属于正态总体 G1
例2:
第4章判别分析习题

D 2 ( X , G1 ) ( X 1 )' 1 ( X 1 ) 5. 8 ((6,0) (5,1)) 2.1 5.8 (1,1) 2.1 2.1 7.6
1
2. 1 7. 6
1ห้องสมุดไป่ตู้
(6,0) (5,1)
1 1 0.4436602
D2 ( X , G2 ) ( X 2 )'1 ( X 2 ) 1.673809
由于 D(X,G2)>D(X,G1),所以X属于G1。
本章结束
4.6 试析距离判别法、贝叶斯判别法和费希尔判别法的异同 答:相同点:它们全是用来判别 p 维空间中的某个点到 底是来自哪个总体的一种算法。 区别是算法的不同,贝叶斯判别法是在距离判别法的基 础上,又考虑的判错问题。而费希尔判别法是以一种线 性组合的形式出现。 4.7 设有两个二元总体 G1 和 G2,从中分别抽取样本计算得到
5 X 1 ,
(1)
X
( 2)
3 2 ,
5.8 2.1 ˆ p 2.1 7.6
假设 1 2 ,试用距离判别法建立判别函数和规则。 样品 X (6,0)' 应属于哪个总体。
解:由式4.3及4.4式有
第四章 判别分析习题
思考与习题
4.1 简述欧氏距离与马氏距离的区别与联系 答:欧氏距离是马氏距离的特例。
2 1 D ( X , Y ) ( X Y )' (X Y ) , 在马氏距离的测定中,
当其中的协差阵等于单位距阵
I 时,马氏距离
就是欧氏距离。 4.2 试叙述判别分析的实质 答:判别分析就是希望利用已测得的变量数据,找出一 种判别函数,使得这一函数具有某种最优性质,能 把属于不同类别的样本点尽可能的区别开来。
判别分析作业
判别分析与聚类分析不同。
判别分析是在已知研究对象分成若干类型(或组别)并已取得各种类型的一批已知样品的观测数据,在此基础上根据某些准则建立判别式,然后对未知类型的样品进行判别分类。
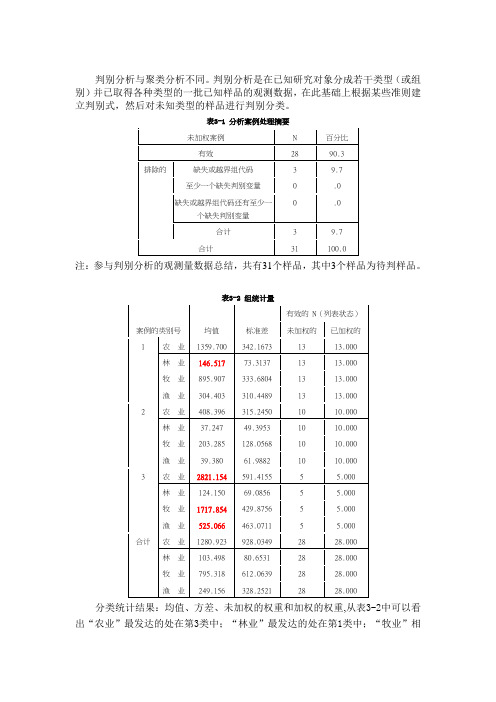
表3-1 分析案例处理摘要未加权案例N 百分比有效28 90.3排除的缺失或越界组代码 3 9.7至少一个缺失判别变量0 .0缺失或越界组代码还有至少一个缺失判别变量0 .0合计 3 9.7合计31 100.0注:参与判别分析的观测量数据总结,共有31个样品,其中3个样品为待判样品。
表3-2 组统计量案例的类别号均值标准差有效的 N(列表状态)未加权的已加权的1 农业1359.700 342.1673 13 13.000林业146.517 73.3137 13 13.000牧业895.907 333.6804 13 13.000渔业304.403 310.4489 13 13.0002 农业408.396 315.2450 10 10.000林业37.247 49.3953 10 10.000牧业203.285 128.0568 10 10.000渔业39.380 61.9882 10 10.0003 农业2821.154 591.4155 5 5.000林业124.150 69.0856 5 5.000牧业1717.854 429.8756 5 5.000渔业525.066 463.0711 5 5.000合计农业1280.923 928.0349 28 28.000林业103.498 80.6531 28 28.000牧业795.318 612.0639 28 28.000渔业249.156 328.2521 28 28.000 分类统计结果:均值、方差、未加权的权重和加权的权重,从表3-2中可以看出“农业”最发达的处在第3类中;“林业”最发达的处在第1类中;“牧业”相对比较发达的处在第3类中;“渔业”比较发达的处在第3类中.表3-3 汇聚的组内矩阵a农业林业牧业渔业协方差农业147937.808 32.329 53946.036 38237.523林业32.329 4221.968 763.564 5011.382牧业53946.036 763.564 88914.814 -1202.757渔业38237.523 5011.382 -1202.757 81954.578相关性农业 1.000 .001 .470 .347林业.001 1.000 .039 .269牧业.470 .039 1.000 -.014渔业.347 .269 -.014 1.000a. 协方差矩阵的自由度为 25。
判别分析练习题
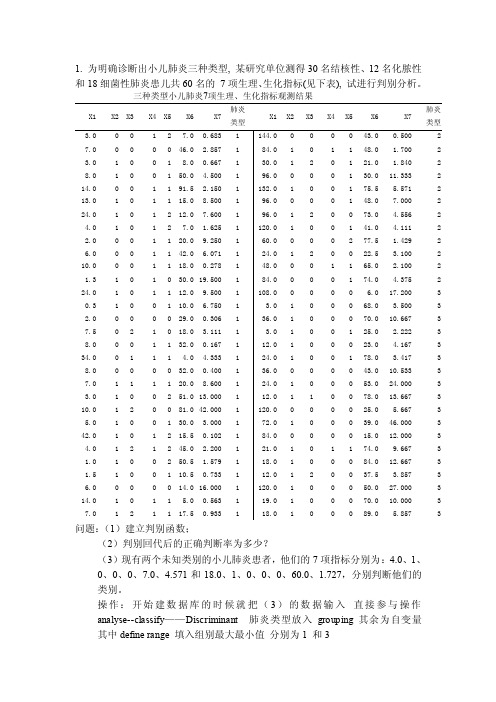
1. 为明确诊断出小儿肺炎三种类型, 某研究单位测得30名结核性、12名化脓性和18细菌性肺炎患儿共60名的7项生理、生化指标(见下表), 试进行判别分析。
三种类型小儿肺炎7项生理、生化指标观测结果X1 X2 X3 X4 X5 X6 X7 肺炎类型X1 X2 X3 X4 X5 X6 X7肺炎类型问题:(1)建立判别函数;(2)判别回代后的正确判断率为多少?(3)现有两个未知类别的小儿肺炎患者,他们的7项指标分别为:4.0、1、0、0、0、7.0、4.571和18.0、1、0、0、0、60.0、1.727,分别判断他们的类别。
操作:开始建数据库的时候就把(3)的数据输入直接参与操作analyse--classify——Discriminant 肺炎类型放入grouping 其余为自变量其中define range 填入组别最大最小值分别为1 和3Statistics 里面,fisher’s为bayes判别选择fisher’s Classify——display——summary table显示结果Save —(全选)—predicted group membership新数据的预测分类Probabilities of group membership 回代正确率Discriminant scores 判别得分结果中:classification function coefficients下标为fisher’s linear分为几类就有几个判别函数:y=0.033x1+1.617x2+…..Classification rescult’s 下标的88.3%为正确率2. 下表是10名健康人(group=1)和6名心肌梗塞患者(group=2)的三个心电图指标(X1,X2,X3)。
试进行判别分析。
group X1 X2 X31 436.70 49.59 2.321 290.67 30.02 2.461 352.53 36.23 2.361 340.91 38.28 2.441 332.83 41.92 2.281 319.97 31.42 2.491 361.31 37.99 2.021 366.5 39.87 2.421 292.56 26.07 2.161 276.84 16.60 2.912 510.47 67.64 1.732 510.41 62.71 1.582 470.30 54.40 1.682 364.12 46.26 2.092 416.07 45.37 1.902 515.70 84.59 1.75问题:(1)建立判别函数;(2)判别回代后的正确判断率为多少?(3)现有一人,他的3项指标为:420.50、32.42、1.98,判断他是健康人还是心肌梗塞患者?操作与上相同,要注意的是:F判别对数据分布无要求,适用于两组判别分析;B要求数据为多元正态分布,适用于多组判别分析。
判别分析练习题

判别分析练习题判别分析练习题在统计学中,判别分析是一种用于分类和预测的方法。
它通过对不同类别的样本进行分析,构建一个分类模型,以便将未知样本分配到正确的类别中。
判别分析在各个领域都有广泛的应用,如医学诊断、金融风险评估等。
下面我将给大家提供一些判别分析的练习题,希望能够帮助大家更好地理解和应用这一方法。
1. 假设有两个类别的样本,每个样本都有两个变量。
已知两个类别的样本均值和协方差矩阵如下:类别1:均值为(1, 2),协方差矩阵为[[2, 1], [1, 2]]类别2:均值为(3, 4),协方差矩阵为[[3, 1], [1, 3]]现有一个未知样本(2, 3),请利用判别分析方法判断该样本属于哪个类别。
解答:首先,我们需要计算两个类别的判别函数值。
对于类别1,判别函数为:g1(x) = -0.5 * (x - μ1) * Σ1^-1 * (x - μ1)T - 0.5 * ln(|Σ1|) + ln(P1)其中,x为未知样本,μ1为类别1的均值,Σ1为类别1的协方差矩阵,P1为类别1的先验概率。
类似地,对于类别2,判别函数为:g2(x) = -0.5 * (x - μ2) * Σ2^-1 * (x - μ2)T - 0.5 * ln(|Σ2|) + ln(P2)其中,μ2为类别2的均值,Σ2为类别2的协方差矩阵,P2为类别2的先验概率。
根据给定的均值和协方差矩阵,我们可以计算出:μ1 = (1, 2), Σ1 = [[2, 1], [1, 2]]μ2 = (3, 4), Σ2 = [[3, 1], [1, 3]]假设两个类别的先验概率相等,即P1 = P2 = 0.5。
将未知样本(2, 3)代入判别函数中,可以计算出:g1(2, 3) = -4.5g2(2, 3) = -5.5由于g2(2, 3)的值较小,所以未知样本更有可能属于类别2。
2. 现有一个三类别的样本,每个样本有三个变量。
已知三个类别的样本均值和协方差矩阵如下:类别1:均值为(1, 2, 3),协方差矩阵为[[2, 1, 1], [1, 2, 1], [1, 1, 2]]类别2:均值为(4, 5, 6),协方差矩阵为[[3, 1, 2], [1, 3, 2], [2, 2, 3]]类别3:均值为(7, 8, 9),协方差矩阵为[[4, 1, 2], [1, 4, 2], [2, 2, 4]]现有一个未知样本(3, 4, 5),请利用判别分析方法判断该样本属于哪个类别。
SPSS操作方法:判别分析例题

SPSS操作方法:判别分析例题为研究1991年中国城镇居民月平均收入状况,按标准化欧氏平方距离、离差平方和聚类方法将30个省、市、自治区.分为三种类型。
试建立判别函数,判定广东、西藏分别属于哪个收入类型。
判别指标及原始数据见表9-4。
1991年30个省、市、自治区城镇居民月平均收人数据表单位:元/人 x1:人均生活费收入 x6:人均各种奖金、超额工资(国有+集体) x2:人均国有经济单位职工工资 x7:人均各种津贴(国有+集体)x3:人均来源于国有经济单位标准工资x8:人均从工作单位得到的其他收入x4:人均集体所有制工资收入 x9:个体劳动者收入5贝叶斯判别的SPSS操作方法:1. 建立数据文件2.单击Analyze→ Classify→ Discriminant,打开Discriminant Analysis 判别分析对话框如图1所示:图1 Discriminant Analysis判别分析对话框3.从对话框左侧的变量列表中选中进行判别分析的有关变量x1~x9进入Independents 框,作为判别分析的基础数据变量。
从对话框左侧的变量列表中选分组变量Group进入Grouping Variable 框,并点击Define Range...钮,在打开的Discriminant Analysis: Define Range对话框中,定义判别原始数据的类别数,由于原始数据分为3类,则在Minimum(最小值)处输入1,在Maximum(最大值)处输入3(见图2)。
选择后点击Continue按钮返回Discriminant Analysis主对话框。
图2 Define Range对话框4、选择分析方法Enter independent together 所有变量全部参与判别分析(系统默认)。
本例选择此项。
Use stepwise method 采用逐步判别法自动筛选变量。
单击该项时Method 按钮激活,打开Stepwise Method对话框如图3所示,从中可进一步选择判别分析方法。
判别分析法(数学建模相关习题)

1 1 2 , a 1 1 2 2
W x a ' x
举例
2、μ1 ≠ μ2,∑1 ≠ ∑2
d 2 x,1 x 1 1 x 1
'
d 2 x, 2 x 2 1 x 2
化简
d 2 x, 1 d 2 x, 2 2 x
x 1 , 若d 2 x, 1 d 2 x, 2 x 2 , 若d 2 x, 1 d 2 x, 2
1 2
2
1 ' 1 2 2x a 2a x '
0.0784 0.0647 0.0197 0.0217 总体样本离差矩阵 s1 0.0647 0.1350 s2 0.0217 0.0389
平均协方差阵的估计ˆ V
0.0075 0.0066 1 s1 s2 0.0066 0.0134 n1 n2 2
1
2
例题:对28名一级和25名健将级标枪运动员测试了6个 影响标枪成绩的训练指标; 30米跑(x1)、 投小铅球( x2 )、 挺举重量( x3 )、
抛实心球( x4 )、前抛铅球( x5 )、 五级跳( x6 )。
编号 组别 x1
Hale Waihona Puke x24.30 4.10 : 4.20 4.00
4.30
x3
82.3 87.48 : 89.20 103.00
平均 y=0.9625x+0.6065 用它来判定发现不好 2、心型平分线 取Af和Apf的中心(1.41,1.80), (1.22,1.93),垂直平分线方程是 y=1.52576x-0.1485
多元统计作业-判别分析
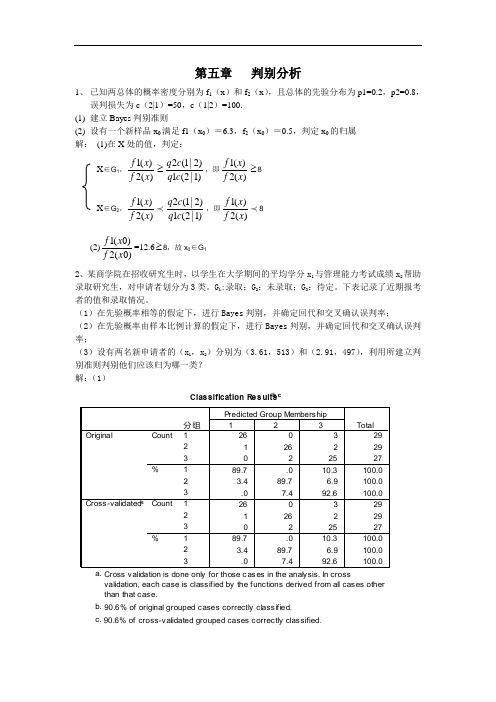
第五章 判别分析1、 已知两总体的概率密度分别为f 1(x )和f 2(x ),且总体的先验分布为p1=0.2,p2=0.8,误判损失为c (2|1)=50,c (1|2)=100. (1) 建立Bayes 判别准则(2) 设有一个新样品x 0满足f1(x 0)=6.3,f 2(x 0)=0.5,判定x 0的归属 解: (1)在X 处的值,判定:X ∈G 1,1()2()f x f x ≥2(1|2)1(2|1)q c q c ,即1()2()f x f x ≥8X ∈G 2,1()2()f x f x 2(1|2)1(2|1)q c q c ,即1()2()f x f x 8(2)1(0)2(0)f x f x =12.6≥8,故x 0∈G 12、某商学院在招收研究生时,以学生在大学期间的平均学分x 1与管理能力考试成绩x 2帮助录取研究生,对申请者划分为3类。
G 1:录取;G 2:未录取;G 3:待定。
下表记录了近期报考者的值和录取情况。
(1)在先验概率相等的假定下,进行Bayes 判别,并确定回代和交叉确认误判率;(2)在先验概率由样本比例计算的假定下,进行Bayes 判别,并确定回代和交叉确认误判率;(3)设有两名新申请者的(x 1,x 2)分别为(3.61,513)和(2.91,497),利用所建立判别准则判别他们应该归为哪一类? 解:(1)回代误判率:8/85=0.0941,交叉确认误判率同样为8/85=0.0941,第2号、3号、24号、30号、31号、58号、74号、75号被误判。
(2)号、30号、31号、58号、74号、75号被误判。
(3)建立Fisher线性判别准则W1=-151.902+60.431X1+0.172X2W2=-89.815+45.255X1+0.138X2W3=-110.818+53.024X1+0.137X2把(3.61,513)代入以上三式,W1=154.48991,W2=144.34955,W3=150.87964把(2.91,497)代入以上三式,W1=109.43621,W2=110.46305,W3=111.57084故第一个申请者判为W1(W1最大),第二个申请者判为W3(W3最大)。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
判别分析法
一、筛选变量
1、通过单因素方差分析剔除不显著变量:在SPSS软件中建立变量和已知数据表,通过Analyze-Classify-Discriminant进入判别分析对话框,由题意知分组变量group即为因变量,其范围定义为:最小值1,最大值2。
自变量为X1、X
2、X
3、X4,通过勾选Statistics选项中的单因素方差分析得到表3-1如下
3-1
由表中可看出收益性指标(X2)和生产效率指标(X4)的显著性水平均大于0.05,接受原假设,即这两个判别变量在各组间差异不显著,所以剔除X2、X4。
2、对判别变量选择逐步进入,得到表3-2至3-4
(3-2)
(3-3)
(3-4)
表3-2至3-3表示逐步判别法中每一步进入的变量;表3-4表示最终删除的变量,通过上表可以明显地看出最终删除的变量是收益性指标(X2)和生产效率指标(X4)。
二、判别分析
1.Box’s 检验:通过第一步将不显著变量剔除后,在SPSS软件中勾选Box’s M判断协方差阵是否相等,得到表3-5和3-6
(3-5)
(3-6)
表3-5反映的是协方差矩阵的秩和行列式的对数值,由行列式的值可以看出,协方差阵不是病态矩阵。
由表3-6可以看出总体协方差矩阵检验的P值0.01<0.05,拒绝原假设,即总体协方差阵不相等。
所以将Winthin-groups换为Separate-groups看两种协方差阵是否存在显著差异,结果表明两种方法没有差异,因此任选一种继续进行判别。
2、Fisher判别
通过在软件中选择非标准化判别得到表3-7至3-12
(3-7)
(3-8)
(3-9)
(3-10)
(3-11)
(3-12)
表3-11是非标准化的判别函数,由此可以写出判别函数的表达式:
y=-1.823+2.321*X1+0.777*X3
表3-7和3-8分析的是典型判别函数,其中表3-7反映了判别函数的特征值、解释方差的比例和典型相关系数,从表中可清楚的看出只有一个判别函数,而且它解释了100%的方差。
表3-8是对判别函数的显著性检验,由表中的P值可以看出显著的小于0.05,即该判别函数的检验是显著的。
表3-9是标准化的判别函数,标准化变量的系数是判别权重,表3-10是结构矩阵,即判别载荷。
从这两个表中可以看出判别变量对判别函数的影响大小,绝对值越大的影响越大,因此从表中系数可以看出短期支付能力(X3)对判别函数的影响要大于总负债率(X1)对判别函数的影响。
(3-13)
表3-13是分类矩阵表,这里交叉验证是“留一个在外”的。
即,每个观测都是通过除了这个观测以外的其他观测所推导出的判别函数来分类的。
由该表交错验证法得到的数据可以看出,在17个破产企业中有14个被判对,判对率为
82.4%;21个正常运行企业中有17个被判对,判对率为81%。
所以在38个企业中,共有31个企业的分类是正确的,故原始数据的判对率为31/38=94.7%。
由表3-13中的原始数据(original)中还可以看出8个待判企业中有4个第1类的,4个第2类的。
将待判的八个企业的X1和X3的值分别带入判别方程
计算得到y1、y2、 y3…… y8然后分别计算与表3-12的两种类型的重心的距
离,哪个距离小就判给哪一类,通过对save中的选项的勾选可以在SPSS数据表中输出待判企业的分类结果为前4个待判企业被判为第1类,后4个待判企业被判为第2类。