计量经济学第四章习题详解
【VIP专享】计量经济学第四章练习题及参考解答

(2) 3.060 1.657ln() 1.057ln()
(0.337) (0.092) (0.215)0.992 0.991 F 1275.093
GDP CPI R =-+-===进口居民消费价格指数的回归系数的符号不能进行合理的经济意义解释可能数据中有多重共线性。
计算相关系数:
22ln Y 4.09071.2186ln () t= (-10.6458) (34.6222)
0.9828 0.9820 1198.698
GDP R R F =-+===ln Y 5.4424 2.6637ln (PI)C =-+
从修正的可决系数和F统计量可以看出,全部变量对数线性多元回归整体对样本拟合很好,著。
可是其中的lnX3、lnX4、lnX6对lnY影响不显著,而且lnX2、lnX5
可以看出lnx1与lnx2、lnx3、lnx4、lnx5、lnx6之间高度相关,许多相关系数高于作为解释变量,很可能会出现严重多重共线性问题。
在本章开始的“引子”提出的“农业的发展反而会减少财政收入吗?
表4.13 1978-2007
财政收入(亿元)CS农业增加值(亿元)NZ工业增加值(亿元)GZ建筑业增加值
1132.31027.51607
1146.41270.21769.7
1159.91371.61996.5
1175.81559.52048.4
(1)根据样本数据得到各解释变量的样本相关系数矩阵如下:样本相关系数矩阵
解释变量之间相关系数较高,特别是农业增加值、工业增加值、建筑业增加值、最终消费之间,相关系数都在这显然与第三章对模型的无多重共线性假定不符合。
《计量经济学》习题(第四章)

《计量经济学》习题(第四章)第四章习题⼀、单选题1、如果回归模型违背了同⽅差假定,最⼩⼆乘估计量____A .⽆偏的,⾮有效的 B.有偏的,⾮有效的C .⽆偏的,有效的 D.有偏的,有效的2、Goldfeld-Quandt ⽅法⽤于检验____A .异⽅差性 B.⾃相关性C .随机解释变量 D.多重共线性3、DW 检验⽅法⽤于检验____A .异⽅差性 B.⾃相关性C .随机解释变量 D.多重共线性4、在异⽅差性情况下,常⽤的估计⽅法是____A .⼀阶差分法 B.⼴义差分法C .⼯具变量法 D.加权最⼩⼆乘法5、在以下选项中,正确表达了序列⾃相关的是____j i u x Cov D j i x x Cov C ji u u Cov B ji u u Cov A j i j i j i j i ≠≠≠≠≠=≠≠,0),(.,0),(.,0),(.,0),(.6、如果回归模型违背了⽆⾃相关假定,最⼩⼆乘估计量____A .⽆偏的,⾮有效的 B.有偏的,⾮有效的C .⽆偏的,有效的 D.有偏的,有效的7、在⾃相关情况下,常⽤的估计⽅法____A .普通最⼩⼆乘法 B.⼴义差分法C .⼯具变量法 D.加权最⼩⼆乘法8、White 检验⽅法主要⽤于检验____A .异⽅差性 B.⾃相关性C .随机解释变量 D.多重共线性9、Glejser 检验⽅法主要⽤于检验____A .异⽅差性 B.⾃相关性C .随机解释变量 D.多重共线性10、简单相关系数矩阵⽅法主要⽤于检验____A .异⽅差性 B.⾃相关性C .随机解释变量 D.多重共线性2222)(.)(.)(.)(.σσσσ==≠≠i i i i x Var D u Var C x Var B u Var A12、所谓不完全多重共线性是指存在不全为零的数k λλλ,,,21 ,有____1112211221221122.0.0..k k k k k x x x k k k k A x x x v B x x x C x x x v e D x x x v e v λλλλλλλλλλλλ++++=+++=∑?++++=++++=式中是随机误差项13、设21,x x 为解释变量,则完全多重共线性是____0.(021.0.021.22121121=+=++==+x x e x D v v x x C e x B x x A 为随机误差项)14、⼴义差分法是对____⽤最⼩⼆乘法估计其参数 11211211121121)()1(....-------+-+-=-++=++=++=t t t t t t t t t t t t t t t u u x x y y D u x y C u x y B u x y A ρρβρβρρρβρβρββββ15、在DW 检验中要求有假定条件,在下列条件中不正确的是____A .解释变量为⾮随机的 B.随机误差项为⼀阶⾃回归形式C .线性回归模型中不应含有滞后内⽣变量为解释变量D.线性回归模型为⼀元回归形式16、在下例引起序列⾃相关的原因中,不正确的是____A.经济变量具有惯性作⽤B.经济⾏为的滞后性C.设定偏误D.解释变量之间的共线性17、在DW 检验中,当d 统计量为2时,表明____A.存在完全的正⾃相关B.存在完全的负⾃相关C.不存在⾃相关D.不能判定18、在DW 检验中,当d 统计量为4时,表明____A.存在完全的正⾃相关B.存在完全的负⾃相关C.不存在⾃相关D.不能判定19、在DW 检验中,当d 统计量为0时,表明____A.存在完全的正⾃相关C.不存在⾃相关D.不能判定20、在DW 检验中,存在不能判定的区域是____A. 0﹤d ﹤l d ,4-l d ﹤d ﹤4B. u d ﹤d ﹤4-u dC. l d ﹤d ﹤u d ,4-u d ﹤d ﹤4-l dD. 上述都不对21、在修正序列⾃相关的⽅法中,能修正⾼阶⾃相关的⽅法是____A. 利⽤DW 统计量值求出ρB. Cochrane-Orcutt 法C. Durbin 两步法D. 移动平均法22、在下列多重共线性产⽣的原因中,不正确的是____A.经济本变量⼤多存在共同变化趋势B.模型中⼤量采⽤滞后变量C.由于认识上的局限使得选择变量不当D.解释变量与随机误差项相关23、在DW 检验中,存在正⾃相关的区域是____A. 4-l d ﹤d ﹤4B. 0﹤d ﹤l dC. u d ﹤d ﹤4-u dD. l d ﹤d ﹤u d ,4-u d ﹤d ﹤4-l d24、逐步回归法既检验⼜修正了____A .异⽅差性 B.⾃相关性 C .随机解释变量 D.多重共线性25、设)()(,2221i i i i i ix f u Var u x y σσββ==++=,则对原模型变换的正确形式为____ )()()()(.)()()()(.)()()()(..212222122121i i i i i i i i i i i i i i i i i i i i i i i i x f u x f x x f x f y D x f u x f x x f x f y C x f u x f x x f x f y B u x y A ++=++=++=++=ββββββββ 26、在修正序列⾃相关的⽅法中,不正确的是____A.⼴义差分法B.普通最⼩⼆乘法C.⼀阶差分法D. Durbin 两步法27、在检验异⽅差的⽅法中,不正确的是____A. Goldfeld-Quandt ⽅法B. spearman 检验法C. White 检验法28、在DW 检验中,存在零⾃相关的区域是____A. 4-l d ﹤d ﹤4B. 0﹤d ﹤l dC. u d ﹤d ﹤4-u dD. l d ﹤d ﹤u d ,4-u d ﹤d ﹤4-l d29.如果模型中的解释变量存在完全的多重共线性,参数的最⼩⼆乘估计量是()A .⽆偏的 B. 有偏的 C. 不确定 D. 确定的30. 已知模型的形式为u x y 21+β+β=,在⽤实际数据对模型的参数进⾏估计的时候,测得DW 统计量为0.6453,则⼴义差分变量是( )A. 1t t ,1t t x 6453.0x y 6453.0y ----B. 1t t 1t t x 6774.0x ,y 6774.0y ----C. 1t t 1t t x x ,y y ----D. 1t t 1t t x 05.0x ,y 05.0y ----31. 在具体运⽤加权最⼩⼆乘法时,如果变换的结果是x u x x x 1xy 21+β+β=,则Var(u)是下列形式中的哪⼀种?( )A. 2σxB. 2σ2x B. 2σx D. 2σLog(x)32. 在线性回归模型中,若解释变量1x 和2x 的观测值成⽐例,即有i 2i 1kx x =,其中k 为⾮零常数,则表明模型中存在( )A. 异⽅差B. 多重共线性C. 序列⾃相关D. 设定误差33. 已知DW 统计量的值接近于2,则样本回归模型残差的⼀阶⾃相关系数ρ近似等于( ) A. 0 B. –1 C. 1 D. 4⼆、多项选择1、能够检验多重共线性的⽅法有____A.简单相关系数法B. DW检验法C. 判定系数检验法D. ⽅差膨胀因⼦检验E.逐步回归法2、能够修正多重共线性的⽅法有____A.增加样本容量B.岭回归法C.剔除多余变量E.差分模型3、如果模型中存在异⽅差现象,则会引起如下后果____A. 参数估计值有偏B. 参数估计值的⽅差不能正确确定C. 变量的显著性检验失效D. 预测精度降低E. 参数估计值仍是⽆偏的4、能够检验异⽅差的⽅法是____A. gleiser检验法B. White检验法C. 图形法D. spearman检验法E. DW检验法F. Goldfeld-Quandt检验法5、如果模型中存在序列⾃相关现象,则会引起如下后果____A. 参数估计值有偏B. 参数估计值的⽅差不能正确确定C. 变量的显著性检验失效D. 预测精度降低E. 参数估计值仍是⽆偏的6、检验序列⾃相关的⽅法是____A. gleiser检验法B. White检验法C. 图形法D. DW检验法E. Goldfeld-Quandt检验法7、能够修正序列⾃相关的⽅法有____A. 加权最⼩⼆乘法B. Durbin两步法C. ⼴义最⼩⼆乘法D. ⼀阶差分法E. ⼴义差分法8、Goldfeld-Quandt检验法的应⽤条件是____A. 将观测值按解释变量的⼤⼩顺序排列B. 样本容量尽可能⼤C. 随机误差项服从正态分布D. 将排列在中间的约1/4的观测值删除掉9、在DW检验中,存在不能判定的区域是____A. 0﹤d﹤l dB. u d﹤d﹤4-u dC. l d﹤d﹤u dD. 4-u d﹤d﹤4-l dE. 4-l d﹤d﹤4。
计量经济学第四章习题详解word精品

第四章习题4.1没有进行t 检验,并且调整的可决系数也没有写出来,也就是没有考虑自由度的影响,会使结果存在一研究的目的和要求我们知道,商品进口额与很多因素有关,了解其变化对进出口产品有很大帮助。
为了探究和预测商品 进口额的变化,需要定量地分析影响商品进口额变化的主要因素。
二、模型的设定及其估计经分析,商品进口额可能与国内生产总值、居民消费价格指数有关。
为此,考虑国内生产总值 居民消费价格指数 CPI 为主要因素。
各影响变量与商品进口额呈正相关。
为此,设定如下形式的计量经济 模型:4.3199511048.160793.7302.8+ In+ InCP1996 11557.4 71176.6 327.9 1997 11806.5 78973.0 337.1 1998 11626.1 84402.3 334.4 1999 13736.4 89677.1 329.7 2000 18638.8 99214.6 331.0 2001 20159.2 109655.2 333.3 2002 24430.3 120332.7 330.6 2003 34195.6 135822.8 334.6 2004 46435.8 159878.3 I 347.7 2005 54273.7 183084.8 353.9 2006 63376.9 211923.5 359.2 2007 73284.6 249529.9 376.5 2008 79526.5 314045.4 398.7 2009 68618.4 340902.8 395.9 201094699.3 401512.8 408.9 2011113161.4472881.6431.0GDP 、式中, 为第 年中国商品进口额(亿元);In GDP 为第 年国内生产总值(亿元);In CPI 为居民消费价格 指数(以1985年为100)。
各解释变量前的回归系数预期都大于零。
(完整word版)计量经济学第四章习题详解

第四章习题4.1 没有进行t检验,并且调整的可决系数也没有写出来,也就是没有考虑自由度的影响,会使结果存在误差.4.3200224430.3120332。
7 330.6200334195。
6135822.8 334。
6200446435.8159878.3 l347.7200554273.7183084.8 353.9200663376.9211923。
5 359。
2200773284。
6249529。
9 376.5200879526.5314045.4 398.7200968618。
4340902。
8 395。
9201094699.3401512.8 408。
92011113161.4472881.6 431.0一研究的目的和要求我们知道,商品进口额与很多因素有关,了解其变化对进出口产品有很大帮助。
为了探究和预测商品进口额的变化,需要定量地分析影响商品进口额变化的主要因素。
二、模型的设定及其估计经分析,商品进口额可能与国内生产总值、居民消费价格指数有关。
为此,考虑国内生产总值GDP、居民消费价格指数CPI为主要因素。
各影响变量与商品进口额呈正相关。
为此,设定如下形式的计量经济模型:=+ln+lnCP式中,亿元);lnGDP为国内生产总值(亿元);lnCPI为居民消费价格指数(以1985年为100)。
各解释变量前的回归系数预期都大于零。
为估计模型,根据上表的数据,利用EViews软件,生成Y、lnGDP、lnCPI等数据,采用OLS方法估计模型参数,得到的回归结果如下图所示:模型方程为:lnY=-3。
111486+1。
338533lnGDP-0.421791lnCPI(0。
463010)(0。
088610)(0。
233295)t= (—6。
720126) (15。
10582)(—1。
807975)=0.988051 =0.987055 F=992。
2582该模型=0.988051,=0。
987055,可决系数很高,F检验值为992.2582,明显显著。
计量经济学第四章练习题及参考解答

第四章练习题及参考解答4.1 假设在模型i i i iu X X Y +++=33221βββ中,32X X 与之间的相关系数为零,于是有人建议你进行如下回归:ii i i i i u X Y u X Y 23311221++=++=γγαα(1)是否存在3322ˆˆˆˆβγβα==且?为什么? (2)111ˆˆˆβαγ会等于或或两者的某个线性组合吗? (3)是否有()()()()3322ˆvar ˆvar ˆvar ˆvarγβαβ==且? 练习题4.1参考解答:(1) 存在3322ˆˆˆˆβγβα==且。
因为()()()()()()()23223223232322ˆ∑∑∑∑∑∑∑--=iiiii iii iii x x x x x xx y x x y β当32X X 与之间的相关系数为零时,离差形式的032=∑i i x x有()()()()222223222322ˆˆαβ===∑∑∑∑∑∑iiiiiiii xx y x x x x y 同理有:33ˆˆβγ= (2) 111ˆˆˆβαγ会等于或的某个线性组合 因为12233ˆˆˆY X X βββ=--,且122ˆˆY X αα=-,133ˆˆY X γγ=- 由于3322ˆˆˆˆβγβα==且,则 11222222ˆˆˆˆˆY Y X Y X X αααββ-=-=-=11333333ˆˆˆˆˆY Y X Y X X γγγββ-=-=-=则 1112233231123ˆˆˆˆˆˆˆY Y Y X X Y X X Y X X αγβββαγ--=--=--=+- (3) 存在()()()()3322ˆvar ˆvar ˆvar ˆvarγβαβ==且。
因为()()∑-=22322221ˆvarr x iσβ当023=r 时,()()()22222232222ˆvar 1ˆvar ασσβ==-=∑∑iixr x 同理,有()()33ˆvar ˆvar γβ=4.2在决定一个回归模型的“最优”解释变量集时人们常用逐步回归的方法。
计量经济学课后答案第四、五章(内容参考)

计量经济学课后答案第四、五章(内容参考)第四章随机解释变量问题1. 随机解释变量的来源有哪些?答:随机解释变量的来源有:经济变量的不可控,使得解释变量观测值具有随机性;由于随机干扰项中包括了模型略去的解释变量,而略去的解释变量与模型中的解释变量往往是相关的;模型中含有被解释变量的滞后项,而被解释变量本身就是随机的。
2.随机解释变量有几种情形? 分情形说明随机解释变量对最小二乘估计的影响与后果?答:随机解释变量有三种情形,不同情形下最小二乘估计的影响和后果也不同。
(1)解释变量是随机的,但与随机干扰项不相关;这时采用OLS估计得到的参数估计量仍为无偏估计量;(2)解释变量与随机干扰项同期无关、不同期相关;这时OLS估计得到的参数估计量是有偏但一致的估计量;(3)解释变量与随机干扰项同期相关;这时OLS估计得到的参数估计量是有偏且非一致的估计量。
3. 选择作为工具变量的变量必须满足那些条件?答:选择作为工具变量的变量需满足以下三个条件:(1)与所替代的随机解释变量高度相关;(2)与随机干扰项不相关;(3)与模型中其他解释变量不相关,以避免出现多重共线性。
4.对模型Y t =β+β1X1t+β2X2t+β3Yt-1+μt假设Yt-1与μt相关。
为了消除该相关性,采用工具变量法:先求Y t关于X1t与 X2t回归,得到Yt,再做如下回归:Y t =β+β1X1t+β2X2t+β3Y t?1-+μt试问:这一方法能否消除原模型中Yt的相关性? 为什么?解答:能消除。
在基本假设下,X1t,X2t与μt应是不相关的,由此知,由X1t 与X2t估计出的Yt应与μt不相关。
5.对于一元回归模型Y t =β+β1Xt*+μt假设解释变量Xt *的实测值Xt与之有偏误:Xt= Xt*+et,其中et是具有零均值、无序列相关,且与Xt不相关的随机变量。
试问:(1) 能否将X t= X t*+e t代入原模型,使之变换成Y t=β0+β1X t+νt后进行估计? 其中,νt为变换后模型的随机干扰项。
斯托克,沃森计量经济学第四章实证练习stata操作及答案

斯托克,沃森计量经济学第四章实证练习stata操作及答案E4.1E4.2E4.3E4.4VARIABLES aheage 0.605(0.0245)Constant 1.082(0.688)Observations 7,711R-squared 0.029Robust standard errors in parentheses*** p<0.01, ** p<0.05, * p<0.11.①截距估计值estimated intercept:1.082②斜率估计值estimated slope:0.605回归方程:ahe= 1.082+0.605*age③当工人年长1岁,平均每小时工资增加0.605美元。
2.Bob: 0.605*26+1.082=16.812(美元)Alexis: 0.605*30+1.082=19.232(美元)答:预测Bob的收入为每小时16.812美元,Alexis为19.232美元。
3.年龄不能解释不同个体收入变化的大部分。
因为R-squared反映了因变量的全部变化能通过回归关系被自变量充分解释的比例,而分析得R-squared的值为0.029,解释度低,说明年龄不能解释不同个体收入变化的大部分。
1.答:两者看上去有微弱的正相关关系2.VARIABLES course_evalbeauty 0.133(0.0550)Constant 3.998(0.0449)Observations 463R-squared 0.036Robust standard errors in parentheses*** p<0.01, ** p<0.05, * p<0.1①截距估计值:3.998斜率估计值:0.133回归方程:Course_Eval=3.998+0.133*beauty//mean beautyMean estimation Number of obs = 463Mean Std.Err. 95% Conf. Interval beauty 4.75e-08 0.0367 -0.0720 0.0720②截距的估计值=Course_Eval的样本均值-斜率估计值*Beauty 的样本均值计算得Beauty的样本均值趋近于零,所以截距的估计值等于Course_Eval的样本均值。
伍德里奇---计量经济学第4章部分计算机习题详解(MATLAB)
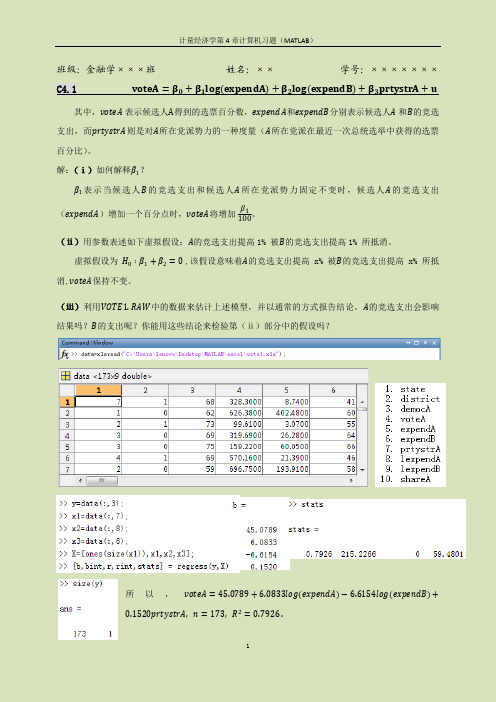
班级:金融学×××班姓名:××学号:×××××××C4.1 voteA=β0+β1log expendA+β2log expendB+β3prtystrA+u 其中,voteA表示候选人A得到的选票百分数,expendA和expendB分别表示候选人A和B的竞选支出,而prtystrA则是对A所在党派势力的一种度量(A所在党派在最近一次总统选举中获得的选票百分比)。
解:(ⅰ)如何解释β1?β1表示当候选人B的竞选支出和候选人A所在党派势力固定不变时,候选人A的竞选支出(expendA)增加一个百分点时,voteA将增加β1 100。
(ⅱ)用参数表述如下虚拟假设:A的竞选支出提高1% 被B的竞选支出提高1% 所抵消。
虚拟假设为H0∶β1+β2=0 ,该假设意味着A的竞选支出提高x% 被B的竞选支出提高x% 所抵消,voteA保持不变。
(ⅲ)利用VOTE1.RAW中的数据来估计上述模型,并以通常的方式报告结论。
A的竞选支出会影响结果吗?B的支出呢?你能用这些结论来检验第(ⅱ)部分中的假设吗?所以,voteA=45.0789+6.0833log expendA−6.6154log expendB+0.1520prtystrA, n=173, R2=0.7926 .由截图可得:expendA 系数β1的 t 统计量为15.9187,在很小的显著水平上都是显著的,意味着当其他条件不变时,A 的竞选支出增加1%,voteA 将增加0.0608。
同理可得,expendB 系数β2的 t 统计量为-17.4632,在很小的显著水平上都是显著的,意味着当其他条件不变时,B 的竞选支出增加1%,voteA 将增加0.066。
由于A 的竞选支出的系数β1和B 的竞选支出的系数β2符号相反,绝对值差不多,所以近似有虚拟假设“ H 0∶β1+β2=0 ”成立,即第(ⅱ)部分中的假设成立。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第四章习题
4.1 没有进行t检验,并且调整的可决系数也没有写出来,也就是没有考虑自由度的影响,会使结果存在误差。
一研究的目的和要求
我们知道,商品进口额与很多因素有关,了解其变化对进出口产品有很大帮助。
为了探究和预测商品进口额的变化,需要定量地分析影响商品进口额变化的主要因素。
二、模型的设定及其估计
经分析,商品进口额可能与国内生产总值、居民消费价格指数有关。
为此,考虑国内生产总值GDP、居民消费价格指数CPI为主要因素。
各影响变量与商品进口额呈正相关。
为此,设定如下形式的计量经济模型:
lnY t=β1+β2ln GDP t+β3lnCP I t
式中,Y t为第t年中国商品进口额(亿元);lnGDP为第t年国内生产总值(亿元);lnCPI为居民消费价格指数(以1985年为100)。
各解释变量前的回归系数预期都大于零。
为估计模型,根据上表的数据,利用EViews软件,生成Y、lnGDP、lnCPI等数据,采用OLS方法估计模型参数,得到的回归结果如下图所示:
模型方程为:
lnY=-3.111486+1.338533lnGDP-0.421791lnCPI
(0.463010) (0.088610) (0.233295)
t= (-6.720126) (15.10582) (-1.807975)
R2=0.988051 R̅2=0.987055 F=992.2582
该模型R2=0.988051,R̅2=0.987055,可决系数很高,F检验值为992.2582,明显显著。
但是当α=0.05 (n-k)=t0.025(27-3)=2.064,不仅lnCPI的系数不显著,而且,lnCPI的符号与预期相反,这表明可能存在时,tα
2
严重的多重共线性。
计算各解释变量的相关系数,选择lnGDP,lnCPI数据,“view/correlation”得相关系数矩阵。
1
由相关系数矩阵可以看出,各解释变量相互之间的相关系数较高,证实确实存在一定的多重共线性。
为了进一步了解多重共线性的性质,我们做辅助回归,即每个解释变量分别作为被解释变量都对剩余的解释变量进行回归。
lnGDP与lnCPI的相关系数很高,证明存在多重共线性。
三、其他分析
1.进行下面的回归
①ln Y t=A1+A2lnGD P t+v1i
模型的估计结果为:
ln Y t̂=−3.750670+1.185739lnGD P t
(0.312255)(0.027822)
t = (-12.01156)(42.61933)
R2=0.986423 R̅2=0.985880 F=1816.407
②ln Y t=B1+B2lnCP I t+v2i
模型的估计结果为:
ln Y t̂=−6.854535+2.939295lnCP I t
(1.242243)(0.222756)
t = (-5.517871)(13.19511)
R2=0.874442 R̅2=0.869419 F=174.1108
③lnGD P t=C1+C2lnCP I t+v3i
模型的估计结果为:
[1]lnGD P t=−2.796381+2.511022lnCP I t
(0.882798)(0.158302)
t = (-3.167634)(15.86227)
R2=0.909621 R̅2=0.906005 F=251.6117
由此对多重共线性的认识:
由上面的几组拟合效果可知,单方程拟合效果都很好,可决系数分别为:0.986423和0.874442,可决系数较高,说明GDP和CPI单个对商品进口额有显著的影响。
但是,当这两个变量同时引进模型时,影响方向发生了改变,这只有通过相关系数的检验才能发现,第三个回归结果也说明了,它们间有很强的线性相关关系。
建议:如果仅仅是做预测,可以不用在意这些多重共线性,如果是进行结构分析,就需要注意了
一、研究的目的和要求
国家财政收入的高低是政府有效实施其各项职能的重要保障。
国家财政收入主要来源于各项税收收入,只有经济持续而健康地增长,才能提供持续的税收来源,因而经济增长是其重要的影响因素;另外,财政收入需要满足日益增长的财政支出的需要。
为此,需要定量地分析影响国家财政收入的主要因素。
二、模型设定及其估计
为了分析各主要因素对国家财政收入的影响,建立财政收入(亿元)(CZSR)为被解释变量,财政支出(亿元)(CZZC)、国内生产总值(亿元)(GDP)、税收总额(亿元)(SSZE)等为解释变量的计量模型。
为此,设定如下形式的计量经济模型:
CZS R i=β0+β1CZZ C i+β2GD P i+β3SSZ E i+μi
式中,CZS R i为第i年财政收入(亿元);CZZ C i为第i年财政支出(亿元);GD P i为第i年国内生产总值GDP (现价)(亿元);SSZ E i为第i年税收总额(亿元)。
各解释变量的系数预期都大于零。
利用EViews软件,生成CZSR、CZZC、GDP、SSZE等数据,采用OLS方法估计模型参数,得到回归结果如下图所示:
回归方程可写为:
̂=-221.8540+0.090114CZZC-0.025334GDP+1.176894SSZE
CZSR i
(130.6532 ) (0.044367) (0.005069) (0.062162)
t= (-1.698038) (2.031129) (-4.998036) (18.93271)
R2=0.999857 R̅2=0.999838 F=53493.93
该模型R2=0.999857,R̅2=0.999838,可决系数很高,F检验值为53493.93,明显显著。
但是当α=0.05 (n-k)=t0.025(27-4)=2.069,不仅CZZC的系数不显著,并且,GDP的系数与预期相反,这表明可能存在严时,t∂
2
重的多重共线性。
计算各解释变量的相关系数,选择CZZC、GDP、SSZE数据,点“view/correlation”得相关系数矩阵,如下图所示:
由各相关系数矩阵可知,各解释变量之间的相关系数较高,证实确实存在一定的多重共线性。
为了进一步了解多重共线性的性质,我们做辅助回归,即将每个解释变量分别作为被解释变量都对其余的解释变量进行回归。
下表是所得到的可决系数和方差扩大因子的数值,如下表所示:
j
余解释变量之间有严重的多重共线性。
三、对多重共线性的处理
运用逐步回归法,逐步选择和剔除引起多重共线性的变量,具体步骤如下:1.先用被解释变量对每一个所考虑的解释变量作简单回归,结果如下所示:aCZSR与CZZC的一元回归结果
R2=0.997459 R̅2=0.997357 F=9813.609
bCZSR与GDP的一元回归的结果
R2=0.985727 R̅2=0.985156 F=1726.571
c.CZSR与SSZE的一元回归结果
R2=0.999665 R̅2=0.999652 F=74596.56
2.对以被解释变量贡献最大的解释变量所对应的回归方程为基础,518D逐个引入其余的解释变量。
由上面的回归结果可知,SSZE对CZSR的回归结果可决系数最大,再此基础上,逐个引入剩下的解释变量CZZC和GDP
在c的基础上引入解释变量CZZC,得到如下的回归结果:
R2=0.999701 R̅2=0.999676 F=40130.62
对比c结果可知,新的回归结果对R̅2有改进,但是F检验不通过,并且,CZZC的t值为1.702195,未通过t检验,所以CZZC是多余的。
在c的基础上引入解释变量GDP,得到下面的回归结果:
R2=0.999831 R̅2=0.999817 F=70993.46
对比c结果可知,新的回归结果对R̅2有改进,F检验也通过了,并且不影响t检验,所以,该解释变量可以保留。
综上所述,可知,回归方程为:
̂=-247.5609-0.026094GDP+1.290500SSZE
CZSR i
(138.2470) (0.005374) (0.028836)
t= (-1.790714) (-4.855620) (44.75386)
R2=0.999831 R̅2=0.999817 F=70993.46。