Cache模拟器实验报告
体系结构试验报告(cache存储过程)
体系结构实验报告实验目的通过程序,模拟cache存储过程,并通过控制变量法模拟分析Cache性能实验步骤:我们要通过老师所给程序进行模拟,并通过操作系统试验中老师所给算法生成出project.txt ,并通过project.txt 里面的数据来模拟程序的局部性等特性。
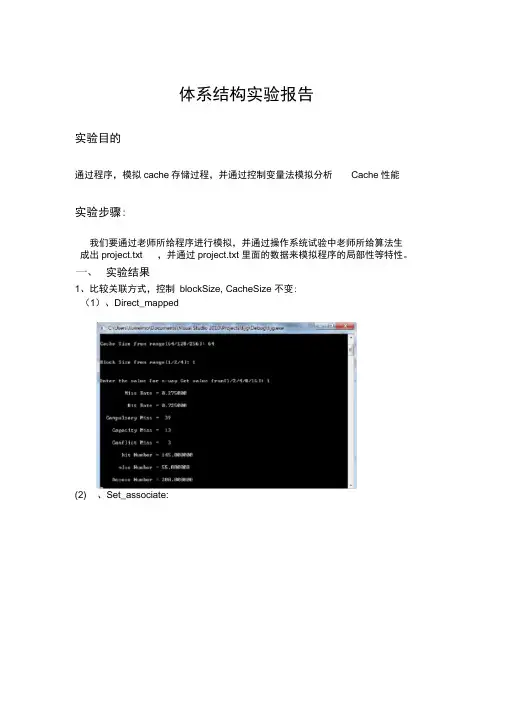
实验结果1、比较关联方式,控制blockSize, CacheSize 不变:(1)、Direct_mapped(2) 、Set_associate:(3) 、Fully_associate通过上述三个比较可以看出,各种映射有自己的优点。
但是不难看出,增大关联度会减小miss rate,但是增加到一定程度又会有抑制作用。
2.比较Cache大小对于性能的影响。
(1)、Direct_mapped,Cache容量为64 时:(2rDirecflmapped〉Cache朿*R128 手(3r Direcflmapped〉Cache助*R256口F一pwsef 峑s 2O J I 0\^J.e e K ^g 63-L w g <J g -f aJnnnrEd理"巧 nmrMecIrlxMLH肆一事呼LJw匸-dJ-LUfJF U »»a iB cinIJr ltRn x li 黑鱼*=£1K s 1!蚯c a p w p llrt t M:C4mw JLl n rll n i H HHi L n h != l£lx-瞌忻恥f*<41.匸«F 23L L/2\.*X «礼 j !H F i <n对比实验结果,不难发现,随着Cache容量的增加,Cache的命中率一直在提升。
分析原因发现,虽然Cache容量大了,但并不等于其预存的内容增多,所以命中率会上升。
3、比较Cache大小对于性能的影响。
(1)、Direct_mapped,关联度为 1 时:(2)、Direct_mapped,关联度为2 时:(3)、Direct_mapped,关联度为4 时:(4) 、Direct mapped ,关联度为 8 时:I ■ C -\LI wrs 1.11uwei mo\Dw_-m e ts'_Vi EUUI I ^tud o l£f Pre e-crE\tt. q\Dfft!uq\ti'g.-i-j rIE Is-* -IrMHiF OP n tiny Ret U <A lun f 1± flhissH41# a 聊C4pnic4tv Conflictnx5S(5) 、Direct map ped ,关联度为 16 时:可以看出,随着关联度的提高,命中率也有所增加Canipuilsnry 1XSE-hH MuflfafiP = I44.MIUUM1Ace R -S3 NumWr ■寸-F口寸 灭 」eqlunu>loo-q〈 p ①ddelu —10①」一q <(L)S33I・鹫詡M us y u s L l's童wr#*■L 書-E .f n -sr e U F K e$us.H92m £百1-■阿*E戏*%贰%严一&丫A*u-uk s ?£Lc 』 C3"f l a毒* 1和4£sE E *B J W11v m 「>!5q言石-d ^l L l e l迟E n p xll -,.I 曰右号v d d -o'w -o M n 「口釜l Y ci-te L ^R 」eqlunu>loo-q 〈 p ①ddelu —10①」Q <通过以上三组数据不难看出,当block number增加时,命中率明显增高了。
Cache模拟器实验报告

Cache模拟器一、实验目标:程序运行时,都会对内存进行相关操作,所访问的内存地址可以被记录下来,形成memory trace文件。
在本实验中,你将使用benchmark 程序产生的memory trace文件来测试Cache命中率,文件可以在/classes/fa07/cse240a/proj1-traces.tar.gz上获得。
每次存储器访问都包含了三个信息:1.访问类型,’l’表示Load操作,’s’表示Store操作;2.地址。
采用32位无符号的十六进制表示;3.存储器访问指令之间的间隔指令数。
例如第5条指令和第10条指令为存储器访问指令,且中间没有其他存储器访问指令,则间隔指令数为4。
通过写一段程序,模拟Cache模拟器的执行过程。
二、实验要求:写一段程序模拟Cache模拟器的执行过程,并对5个trace文件进行测试,完成以下目标:1.请统计Load类型指令和Store类型指令在这5个trace文件中的指令比例。
2.设Cache总容量为32KB,对以下所有参数进行组合(共有72种组合),测量相应5个文件的Cache命中率。
通过对命中率的分析,可以发现什么规律。
行大小:32字节、64字节、128字节相连度:8路相联、4路相联、2路相联、1路相联替换策略:FIFO,随机替换,LRU写策略:写直达、写回3. 给出5个文件的最佳Cache命中率的参数组合。
针对不同的trace 文件,最佳配置是否相同。
4. 测量各种组合下Cache和主存之间的数据传输量。
5. 给出5个文件的最小数据传输量的参数组合。
这个组合和第3问中得到的组合是否一致。
针对不同的trace文件,最佳配置是否相同。
6. Cache缺失有三种原因:1)强制缺失;2)容量缺失;3)冲突缺失。
分析这三种缺失并说明你的分析方法。
7. 请给出5个trace文件在最优Cache命中率的情况下,这三种缺失所占的比例,并和教材图C.8给出的比例进行比较。
Cache实验
Caches实验杨祯 15281139实验目的1.阅读分析附件模拟器代码2.通过读懂代码加深了解cache的实现技术3.结合书后习题1进行测试4.通过实验设计了解参数(cache和block size等)和算法(LRU,FIFO 等)选择的优化配置与组合,需要定性和定量分析,可以用数字或图表等多种描述手段配合说明。
阅读分析模拟器代码课后习题stride=132下直接相连映射1)实验分析由题意得:cachesize=256B blockinbyte=4*4BNoofblock=256B/16B=16个组数位16array[0]的块地址为0/4=0 映射到cache的块号为0%16=0 array[132]的块地址为132/4=33 映射到cache的块号为33%16=1第一次访问cache中的0号块与1号块时,会发生强制性失效,之后因为调入了cache中,不会发生失效,所以misscount=2 missrate=2/(2*10000)=1/10000hitcount=19998 hitrate=9999/10000 实验验证stride=131下直接相连映射实验分析由题意得:cachesize=256B blockinbyte=4*4BNoofblock=256B/16B=16个组数位16array[0]的块地址为0/4=0 映射到cache的块号为0%16=0array[131]的块地址为131/4=32 映射到cache的块号为32%16=0 第一次访问cache中的0号时,一定会发生强制性失效,次数为1;之后因为cache中块号为0的块不断地被替换写入,此时发生的是冲突失效,冲突失效次数为19999,则发生的失效次数为19999+1=20000 所以misscount=20000 missrate=20000/(2*10000)=1实验验证stride=132下2路组相连映射实验分析由题意得:cachesize=256B blockinbyte=4*4BNoofblock=256B/16B=16个Noofset=16/2=8组array[0]的块地址为0/4=0 映射到cache的组号为0%8=0array[132]的块地址为132/4=33 映射到cache的组号为33%8=1第一次访问cache中的0号块与1号块时,一定会发生强制性失效,之后因为调入了cache中,不会发生失效,所以misscount=2 missrate=2/(2*10000)=1/10000hitcount=19998 hitrate=9999/10000 实验验证stride=131下2路组相连映射实验分析由题意得:cachesize=256B blockinbyte=4*4BNoofblock=256B/16B=16个Noofset=16/2=8组array[0]的块地址为0/4=0 映射到cache的组号为0%8=0array[131]的块地址为131/4=32 映射到cache的组号为32%8=0 第一次访问cache中的0组时,一定会发生强制性失效,因为1组中有2个块,不妨假设array[0]对应0组中的第0块,array[131]对应0组中的第1块,则强制失效次数为1;之后因为 array[0]与array[131]都在0组,不会发生失效则发生的失效次数为2次,命中次数为19998,所以misscount=2 missrate=2/(2*10000)=1/10000hitcount=19998 hitrate=9999/10000实验验证实验分析(1)block块大小与Cache容量对Cache效率的影响实验以Hitrate作为衡量指标,在直接相连映射,组相连度为1,project.txt 为500个1---100的随机数。
根据spim的cache实验
汕头大学实验报告学院: 工学院系: 计算机系专业: 计算机科学与技术年级: 13实验时间: 2015.6.16 姓名: 林子伦学号: 2013101030实验名称:基于SPIM-CACHE的Cache实验一.实验目的:(1)熟悉SPIM-CACHE模拟器环境(2)深入认识CACHE的工作原理及其作用。
二.实验内容:(1)阅读实验指导书资料(虚拟教室提供了英文论文的电子版本);(2)下载SPIM-CACHE软件,理解英文论文的基本内容之后,给出几种典型的cache配置,运行英文论文提供的代码,记录运行时CACHE命中率等重要数据;(3)运行Fig.4代码,了解mapping functions 即映射规则(4)运行Fig.7代码,了解temporal and spatial locality 即时空局部性,进一步理解cache的工作原理;(5)运行Fig.8代码,运行学习replacement algorithms 即替代算法,理解其工作原理。
三.实验地点,环境实验地点:软件工程实验室实验环境:操作系统:Microsoft Windows 8 中文版处理器:Intel(R) Core(TM) i3-3120M CPU @ 2.50GHz 2.50GHz内存: 4.00GB(3.82GB 可用)四.实验记录及实验分析(80%):4.1实验前配置:1) 按下图配置好Spim设置2)关于实验中cache设置如下(具体配置根据下面实验要求)——》——》Cache size ——cache大小Block size ——块大小Mapping ——组相连4.2实验一:fig4.s实验目的:Algorithm and corresponding code to study mapping functions Cache配置:256-B size, 16-B line size, four-way set associative实验操作:1) Ctrl+O 打开运行代码fig4.s代码如下:.data 0x10000480Array_A: .word 1,1,1,1,2,2,2,2.data 0x10000CC0Array_B: .word 3,3,3,3,4,4,4,4.text.globl _start_start: la $2,Array_Ali $6,0li $4,8loop: lw $5,0($2)add $6,$6,$5addi $2,$2,4addi $4,$4,-1bgt $4,$0,loop2) 按F5运行程序,得到结果如下图Instruction cache’s hit rate : 0.792453Data cache’s hit rate : 0.7500004.3实验二:fig7.s实验目的:Algorithm and corresponding code to study temporal and spatial locality4.3.1 spatial localityCache配置:256-B size, four-way set associative, 分别定义block size为16,8,4B实验操作:1) Ctrl+O 打开运行代码fig7.s代码如下:.data 0x10000480Array_A: .word 1,1,1,1,2,2,2,2.data 0x10000CC0Array_B: .word 3,3,3,3,4,4,4,4.text.globl __start__start: li $8,1#这里要得到教程里的0.75,0.5,0 这里的$8里一定要为1ext_loop: la $2,Array_Ala $3,Array_Bli $6,0 #sum=0li $4,8 #number of elementsloop: lw $5,0($2)lw $7,0($3)add $6,$6,$5 #sum=sum+arrayA[i]add $6,$6,$7 #sum=sum+arrayB[i]addi $2,$2,4addi $3,$3,4addi $4,$4,-1addi $8,$8,-1bgt $8,$0,ext_loop.end2)按F5运行程序Block size:16B命中率为0.75Block size:8B命中率为0.5Block size:4B命中率为04.3.2 temporal localityCache配置:256-B size, 16-B line size, four-way set associative实验操作:1) Ctrl+O 打开运行代码fig7.s代码如下:(代码中N每次改写为1或5或10或100).data 0x10000480Array_A: .word 1,1,1,1,2,2,2,2.data 0x10000CC0Array_B: .word 3,3,3,3,4,4,4,4.text.globl __start__start: li $8,N #N=1,5,10,100ext_loop: la $2,Array_Ala $3,Array_Bli $6,0 #sum=0li $4,8 #number of elementsloop: lw $5,0($2)lw $7,0($3)add $6,$6,$5 #sum=sum+arrayA[i]add $6,$6,$7 #sum=sum+arrayB[i]addi $2,$2,4addi $4,$4,-1bgt $4,$0,loopaddi $8,$8,-1bgt $8,$0,ext_loop.end2) 按F5运行程序N=1命中率为0.759036。
计算机组成原理之Cache模拟器的实现上课讲义

计算机组成原理之C a c h e模拟器的实现实验一 Cache模拟器的实现一.实验目的(1)加深对Cache的基本概念、基本组织结构以及基本工作原理的理解。
(2)掌握Cache容量、相联度、块大小对Cache性能的影响。
(3)掌握降低Cache不命中率的各种方法以及这些方法对提高Cache性能的好处。
(4)理解LRU与随机法的基本思想以及它们对Cache性能的影响。
二、实验内容和步骤1、启动Cachesim2.根据课本上的相关知识,进一步熟悉Cache的概念和工作机制。
Cache概念:高速缓冲存Cache工作机制:大容量主存一般采用DRAM,相对SRAM速度慢,而SRAM速度快,但价格高。
程序和数据具有局限性,即在一个较短的时间内,程序或数据往往集中在很小的存储器地址范围内。
因此,在主存和CPU之间可设置一个速度很快而容量相对较小的存储器,在其中存放CPU当前正在使用以及一个较短的时间内将要使用的程序和数据,这样,可大大加快CPU访问存储器的速度,提高机器的运行效率3、依次输入以下参数:Cache容量、块容量、映射方式、替换策略和写策略。
(1)Cache容量:启动CacheSim,提示请输入Cache容量,例如1、2、4、8......。
此处选择输入4。
(2)块容量:如下图所示,提示输入块容量,例如1、2、4、8......。
此处选择输入16。
(3)映射方式:如下图所示,提示输入主存储器和高速缓存之间的assoiativity方法(主存地址到Cache地址之间的映射方式),1代表直接映射(固定的映射关系)、2代表组相联映射(直接映射与全相联映射的折中)、3代表全相联映射(灵活性大的映射关系)。
此处选择全相联映射。
(4)替换策略:如下图所示,提示输入替换策略,1代表先进先出(First-In-First-Out,FIFO)算法、2代表近期最少使用(Least Recently Used,LRU)算法、3代表最不经常使用(Least Frequently Used,LFU)、4代表随机法(Random)。
计算机体系结构cache模拟器实验报告

计算机体系结构——Cache模拟器实验实验报告姓名崔雪莹学号12281166班级计科1202班老师董岚2015年06月07日一、阅读分析附件模拟器代码 (4)1、关键参数 (4)2、关键算法 (5)二、课后习题 (8)1、习题内容 (8)2、题目分析 (8)3、计算及结果 (9)4、模拟器上实验结果检验 (11)三、整体分析 (15)1、三种映射方式对Cache效率的的影响 (15)2、block块大小与Cache容量对Cache效率的影响 (16)3、Cache容量与相连度对Cache效率的影响 (17)4、三种失效类型影响因素 (18)四、实验思考和感受 (21)1、关于模拟器的思考 (21)2、关于整个实验的思考 (22)一、阅读分析附件模拟器代码1、关键参数(1)用户可见参数:(用户通过命令行输入参数)(2)程序内部主要参数:(代码内部重要参数)2、关键算法注:这里不粘贴代码,只是进行简单的代码算法说明(1)块地址表示:注:图是我按照自己的想法自己画的,可能有些地方并不准确,望老师指正。
图中以一个例子来解释cache模拟器中block和数据地址的关系,以及和组地址和标志位的关系。
(2)Index与tag:由上面计算:index = blockaddress % NOofset index = 16 % 8 = 2tag = blockaddress / Noofset tag = 16/8 = 2以上例,字地址16为例,写成二进制为0001 0010 B,其中组数为8,又因为2^3=8,所以字地址取后3位为:index = 010 B = 2 ,取前29位为:tag = 0…0010 B = 2 。
所以,算法与理论是一致的。
(3)Valid:有效位。
当通过上述方式寻址找到了数据存放的数据块,接下来判断有效位:有效位为1,说明数据是有效的,可以从block提取数据;有效位为0,说明块里的数据是无效的,所以不能从block提取数据,出现miss,此时判断miss类型,同时需要访问内存或下一级存储,将数据放到cache里。
计组实验报告
计组实验报告【实验名称】:基于MIPS的Cache设计与实现【实验目的】:通过设计、模拟和测试基于MIPS的Cache,理解和掌握Cache的基本原理和实现方法,加深对计算机组成原理的理解和应用。
【实验设备】:Xilinx ISE Design Suite 14.7、Verilog HDL仿真工具、Mars模拟器。
【实验原理】Cache是计算机系统中重要的存储器层次结构,它可以提高访问速度,降低访问延迟。
Cache是一种由高速存储器和控制电路组成的存储器,它的作用是缓存主存中最近使用过的指令和数据,当下一次需要使用这些指令和数据时,可以直接从Cache中获取,而不需要访问主存,从而提高访问速度。
计算机系统中的Cache存储器既可以用硬件实现,也可以用软件实现。
MIPS Cache包括指令Cache和数据Cache两个部分。
指令Cache用于存储CPU需要的指令,而数据Cache用于存储CPU需要的数据。
Cache中的每一个存储块叫做一个Cache 行,每一个Cache行包括若干字块,每一个字块包括若干字节。
Cache行的大小一般是2^n 个字节。
Cache使用一种叫做Cache命中的技术,通过判断当前CPU需要的数据是否在Cache中来确定是否需要访问主存。
如果当前CPU需要的数据在Cache中,则称为Cache命中,可以直接从Cache中获取数据;如果当前CPU需要的数据不在Cache中,则称为Cache未命中,需要从主存中获取数据。
Cache有三种常见的替换算法:随机替换算法、先进先出(FIFO)替换算法和最近最少使用(LRU)替换算法。
随机替换算法是最简单的方法,它实现起来比较简单,但是效率不高。
FIFO替换算法是一种比较简单的替换算法,它在实现的时候需要维护一个队列来保证替换最早进入Cache的数据,但是这种算法无法适应程序的访存局部性。
LRU替换算法是一种比较复杂的替换算法,它需要维护一个使用时间序列来记录各数据块被使用的时间,当需要替换时,选择使用时间最旧的数据块替换掉。
cache硬件设计实验报告
cache硬件设计实验报告摘要:本文介绍了 cache 硬件设计的基本原理和实现方法,并通过一个具体的实验案例,展示了如何通过 cache 硬件设计来提高计算机系统的性能。
实验过程中使用了 NVIDIA CUDA 平台,实现了一个基于 cache 硬件设计的并行计算框架,用于处理大规模图像数据。
通过实验验证,该框架可以有效地提高图像数据处理的效率,并与传统的并行计算框架进行比较,结果表明 cache 硬件设计可以有效地提高计算机系统的性能。
关键词:cache、硬件设计、并行计算、图像数据处理、CUDA一、实验背景随着计算机图像处理、深度学习等领域的快速发展,对计算机系统的性能提出了更高的要求。
为了提高计算机系统的性能,越来越多的研究人员开始研究基于 cache 硬件设计的并行计算框架。
cache 硬件设计可以通过优化数据访问顺序,提高计算机系统的数据预取能力,从而提高计算机系统的性能。
在图像处理、深度学习等领域中,大量的数据需要进行并行处理,因此 cache 硬件设计成为了一种非常重要的并行计算框架。
二、实验目的本文旨在通过 cache 硬件设计实验,验证 cache 硬件设计对于计算机系统性能的提升作用。
具体实验目的是:1. 验证 cache 硬件设计是否能够提高计算机系统的数据预取能力;2. 验证 cache 硬件设计是否能够提高计算机系统的效率;3. 比较 cache 硬件设计和传统的并行计算框架在图像处理领域的性能差异。
三、实验方案1. 实验环境本文的实验环境采用 NVIDIA CUDA 平台,操作系统为 Linux。
实验中使用的 GPU 为 GeForce GTX 1080,内存为 8GB。
2. 实验框架本文的实验框架采用基于 cache 硬件设计的并行计算框架,具体包括以下三个模块:模块一:cache 硬件设计模块。
该模块实现一个基于 CUDA 点多线程并行计算框架,用于处理大规模图像数据。
实验1-Cache性能分析
西安邮电大学(计算机学院)课内实验报告实验名称:Cache性能分析专业名称:计算机科学与技术班级:学生姓名:学号(8位):指导教师:实验日期:实验1 Cache性能分析1 实验目的(1)加深对Cache的基本概念、基本组织结构以及基本工作原理的理解。
(2)掌握Cache容量、相联度、块大小对Cache性能的影响。
(3)掌握降低Cache不命中率的各种方法.2 实验平台采用MyCache模拟器.MyCache模拟器的使用方法:(1) 双击MyCache。
exe,启动模拟器。
(2)系统打开操作界面,如下图所示:(3)略、写不命中时的调块策略。
可以直接从列表中选择.(4) 访问地址可以选择来自地址流文件,也可以选择手动输入.如果是前者,则可以通过单击“浏览"按钮,从模拟器所在文件夹下的“地址流”文件夹中选取地址流文件(.din)文件,然后执行。
执行得方式可以是单步,也可以选择一次执行结束。
如果选择手动输入,就可以在“执行控制”区域中输入块地址,然后单击“访问”按钮.系统会在界面的右边显示访问类型、地址、块号以及块内地址.(5) 模拟结果包括:●访问总次数,总的不命中次数,总的不命中率。
●读指令操作的次数,其不命中次数及其不命中率.●读数据操作的次数,其不命中次数及其不命中率。
●写数据操作的次数,其不命中次数及其不命中率。
●手动输入单次访问的相关信息。
3 实验内容和步骤3。
1 Cache容量对不命中率的影响(1) 启动MyCache.(2)单击“复位”按钮,将各参数设置为默认值。
(3)选择一个地址流文件。
具体方法:选择“访问地址”→“地址流文件"选项,然后单击“浏览”按钮,从本模拟器所在的文件夹下的“地址流”文件夹中选取。
(4) 选择不同的Cache容量,包括2KB,4 KB,8 KB,16 KB,32 KB,64 KB,128 KB和256 KB,分别执行模拟器(单击“执行到底”按钮就可执行),然后在表1.1中记录各种情况下的不命中率。
实验5 Cache实验
深圳大学实验报告课程名称:计算机系统(2)实验项目名称:Cache实验学院:计算机与软件学院专业:计算机与软件学院所有专业指导教师:罗秋明报告人:学号:班级:实验时间:2017年6月6日实验报告提交时间:2017年6月9日教务处制一、实验目标:了解Cache对系统性能的影响二、实验环境:1、个人电脑(Intel CPU)2、Fedora 13 Linux 操作系统三、实验内容与步骤1、编译并运行程序A,记录相关数据。
2、不改变矩阵大小时,编译并运行程序B,记录相关数据。
3、改变矩阵大小,重复1和2两步。
4、通过以上的实验现象,分析出现这种现象的原因。
程序A:#include <sys/time.h>#include <unistd.h>#include <stdio.h>main(int argc,char *argv[]){float *a,*b,*c, temp;long int i,j,k,size, m;struct timeval time1,time2;if(argc<2) {printf("\n\tUsage:%s <Row of square matrix>\n",argv[0]);exit(-1);} //ifsize=atoi(argv[1]);m =size*size;a=(float*)malloc(sizeof(float)*m);b=(float*)malloc(sizeof(float)*m);c=(float*)malloc(sizeof(float)*m);for(i=0;i<size;i++) {for(j=0;j<size;j++) {a[i*size+j]=(float)(rand()%1000/100.0);b[i*size+j]=(float)(rand()%1000/100.0);}gettimeofday(&time1,NULL);for(i=0;i<size;i++){for(j=0;j<size;j++){c[i*size+j]=0;for(k=0;k<size;k++)c[i*size+j]+=a[i*size+k]*b[k*size+j];}gettimeofday(&time2,NULL);_sec-=_sec;_usec-=_usec;if(_usec<0L) {_usec+=1000000L;_sec-=1;}printf("Executiontime=%ld.%6ld seconds\n",_sec,_usec);} //forreturn(0);}//main程序B:#include <sys/time.h>#include <unistd.h>#include <stdio.h>main(int argc,char *argv[]){float *a,*b,*c,temp;long int i,j,k,size,m;struct timeval time1,time2;if(argc<2){printf("\n\tUsage:%s <Row of square matrix>\n",argv[0]);exit(-1);}size=atoi(argv[1]);m=size*size;a=(float*)malloc(sizeof(float)*m);b=(float*)malloc(sizeof(float)*m);c=(float*)malloc(sizeof(float)*m);for(i=0;i<size;i++)for(j=0;j<size;j++){a[i*size+j]=(float)(rand()%1000/100.0);c[i*size+j]=(float)(rand()%1000/100.0);}gettimeofday(&time1,NULL);for(i=0;i<size;i++)for (j=0;j<size;j++){b[i*size+j]= c[j*size+i];for (i=0;i<size;i++)for(j=0;j<size;j++){c[i*size+j]= 0;for (k=0;k<size;k++)c[i*size+j]+=a[i*size+k]*b[j*size+k];} //forgettimeofday(&time2,NULL);_sec-=_sec;_usec-=_usec;if(_usec<0L){_usec+=1000000L;_sec-=1;}printf("Executiontime=%ld.%6ld seconds\n",_sec,_usec);}//forreturn(0);}四、实验结果及分析1、用C语言实现矩阵(方阵)乘积一般算法(程序A),填写下表:分析:由下图1,可得到上表的结果,程序主要代码如下所示,对二维数组b是跳跃的,类似下表1的访问顺序,这样导致了程序的空间局部性很差:for(j=0;j<size;j++){c[i*size+j] = 0;for (k=0;k<size;k++)c[i*size+j] += a[i*size+k]*b[k*size+j];}表1图22、程序B是基于Cache的矩阵(方阵)乘积优化算法,填写下表:分析:由下图4可以得到上表的数据,由下面主要代码可知,优化后的代码访问数组b的顺序类似下图3,这样相对程序A对cache的命中率大大得到了提高:for(j=0;j<size;j++){c[i*size+j] = 0;for (k=0;k<size;k++)c[i*size+j] += a[i*size+k] *b[j*size+k];} //for表2以下图说明为什么程序B的空间局部性好:图43、优化后的加速比(speedup)加速比定义:加速比=优化前系统耗时/优化后系统耗时;所谓加速比,就是优化前的耗时与优化后耗时的比值。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Cache模拟器一、实验目标:程序运行时,都会对内存进行相关操作,所访问的内存地址可以被记录下来,形成memory trace文件。
在本实验中,你将使用benchmark 程序产生的memory trace文件来测试Cache命中率,文件可以在/classes/fa07/cse240a/proj1-traces.tar.gz上获得。
每次存储器访问都包含了三个信息:1.访问类型,’l’表示Load操作,’s’表示Store操作;2.地址。
采用32位无符号的十六进制表示;3.存储器访问指令之间的间隔指令数。
例如第5条指令和第10条指令为存储器访问指令,且中间没有其他存储器访问指令,则间隔指令数为4。
通过写一段程序,模拟Cache模拟器的执行过程。
二、实验要求:写一段程序模拟Cache模拟器的执行过程,并对5个trace文件进行测试,完成以下目标:1.请统计Load类型指令和Store类型指令在这5个trace文件中的指令比例。
2.设Cache总容量为32KB,对以下所有参数进行组合(共有72种组合),测量相应5个文件的Cache命中率。
通过对命中率的分析,可以发现什么规律。
行大小:32字节、64字节、128字节相连度:8路相联、4路相联、2路相联、1路相联替换策略:FIFO,随机替换,LRU写策略:写直达、写回3. 给出5个文件的最佳Cache命中率的参数组合。
针对不同的trace 文件,最佳配置是否相同。
4. 测量各种组合下Cache和主存之间的数据传输量。
5. 给出5个文件的最小数据传输量的参数组合。
这个组合和第3问中得到的组合是否一致。
针对不同的trace文件,最佳配置是否相同。
6. Cache缺失有三种原因:1)强制缺失;2)容量缺失;3)冲突缺失。
分析这三种缺失并说明你的分析方法。
7. 请给出5个trace文件在最优Cache命中率的情况下,这三种缺失所占的比例,并和教材图C.8给出的比例进行比较。
三、程序设计与实现:本程序我打算采用java进行编写,因为java能够很好地体现面向对象编程的优点。
首先需要定义相关的数据类型。
将指令定义为一个单独的指令类,好方便操作和记录统计,其中属性包括该指令的类型,比如是Load指令还是Store指令,还包括指令的地址。
class Instruction {String type;String addrs;}将Cache定义为一个类,Cache中的字段包括Tag标识字段,用于查找到相应组后进行比较看是否命中。
Dirty字段用于写回策略中判断是否数据已经被修改了,如果修改了则在置换的时候需要写回,在统计Cache与主存的数据传输量时需要用到。
最后一个字段是count,该字段用于记录该Cache块最近被访问的频度,用于组相连时LRU替换策略时判断哪个块最长时间没被访问到。
class Cache {int tag;int dirty;int count;}最后定义一个Cache模拟器类。
用一个二维数组来模拟Cache,因为二维数组可以很好地表示组相连Cache,而直接相连和全相联Cache都是组相连的特殊情况,当第一维为1时,表示全相连Cache,当第二维为1时,表示直接相连Cache。
public class CacheSimulator {public long size;// Cache大小public int line_size;// 块大小public int set_associativity;// 相联度public static long set_count;// 组数public int[] set_indexs;// 用于FIFO中记录需替换的块号public Cache[][] caches;public static ArrayList<Instruction> instrs= new ArrayList<Instruction>();public static HashSet<String> compulsory= new HashSet<String>();// 记录强制缺失public static long conflict;// 记录冲突缺失public boolean write_method = false;//false表示写回,true表示写直达public int replace_method = 0;// 0为Random,1为FIFO,2为LRUpublic static HitRationType[] hitRations= new HitRationType[72];public static int communication_times;Random rand = new Random(set_associativity);// 用于随机替换策略static int offset = 0;static int read_misses = 0, read_hits = 0;static int reads = 0;static int write_misses = 0, write_hits = 0;static int writes = 0;static int others = 0;static int totals = 0;接下来需要定义几个辅助方法,首先第一个是readFile()方法,通过读入trace文件来将数据提取出来,保存到指令list中,同时统计读操作和写操作的指令数目,以及总的指令数目。
具体如下所示:static void readFile(String path) throws IOException { File file = new File(path);BufferedReader br = new BufferedReader(new InputStreamReader( new FileInputStream(file)));String s;String sts[];while ((s = br.readLine()) != null) {sts = s.split(" ");Instruction inst = new Instruction();//将数据保存到指令类中if (sts[0].endsWith("l")) {//统计指令类型数目reads++;inst.type = "l";} else {writes++;inst.type = "s";}inst.addrs = sts[1];others += Integer.parseInt(sts[2]);instrs.add(inst);String tmp = "" + getIndex(inst.addrs);compulsory.add(tmp);}totals = reads + writes + others;br.close();}定义一个函数getIndex()和getTag(),输入一个十六进制的指令,然后分别返回其对应的索引字段和Tag字段。
要求索引字段和Tag 字段,首先得分别算出地址中tag字段、索引字段和块内偏移字段的位数,而这与Cache的映射策略、Cache的大小以及块大小有关。
static int getIndex(String addr) {String to = toBinaryString(addr);String index_add = to.substring((int) (to.length() - offset- (int) log(set_count, 2)), to.length()- offset);int index = Integer.parseInt(index_add, 2);return index;}static int getTag(String addr) {String to = toBinaryString(addr);String tag_add = to.substring(0, to.length() - offset- (int) (to.length() - offset - (int) log(set_count, 2)));int tag = Integer.parseInt(tag_add, 2);return tag;}在getIndex()函数中用到了一个自定义的log函数,该函数能够通过将一个数据返回其以2为基值的对数值,比如Cache块大小为32,则log(32,2)返回5。
public static double log(double value, double base) {return Math.log(value) / Math.log(base);}由于java中所实现的将十六进制数转换为2进制数的函数并不完善,比如当十六进制数字最高几位为0时,java API中的函数默认不将其进行转换,而是直接忽略。
因此,在程序中需要自定义一个函数来实现将十六进制的指令转换为2进制表示。
static String toBinaryString(String addr) {String sub = addr.substring(2);StringBuffer sb = new StringBuffer();for (int i = 0; i < sub.length(); i++) {switch (sub.charAt(i)) {case'0':sb.append("0000");break;case'1':sb.append("0001");break;。
//太长而且重复,此处就省略了default:System.out.println("数据有误!");break;}}return sb.toString();}程序主体执行过程很简单,对每一条保存在指令list中的指令进行如下操作。
首先通过getIndex()和getTag()函数获取指令的Index 字段和Tag字段,然后通过该index字段作为第一维的索引去查找Cache二维数组,然后进行tag字段的比较,如果改组中有匹配的Tag,则说明该指令在Cache中,命中了。
否则说明不命中,此时判断该Cache 行是否已经满了,如果没满,则将该指令所在的那一块加载到Cache 中,如果满了,则根据设定好的替换策略,调用相应的替换策略进行替换。