根据spim的cache实验
cache硬件设计实验总结

cache硬件设计实验总结
一、实验内容
本次实验主要是简单熟悉cache硬件设计的基础,以及学习cache在系统中的应用。
学习的主要内容有:
1、cache硬件结构,包括cache的分类、cache的结构及工作原理;
2、cache替换算法的概述;
3、cache的动态优化。
二、实验目的
通过本次实验,学生可以掌握cache的硬件结构,理解cache 的替换算法,以及cache的动态优化,为以后学习更深入的cache 知识打下扎实的基础。
三、实验过程
1、首先,学生阅读有关cache硬件结构的相关资料,理解cache的分类、结构及工作原理;
2、然后,学生学习cache的替换算法,如最近最久未使用(LRU)、先进先出(FIFO)、最佳置换(OPT)等;
3、接着,学生了解cache的动态优化,学习cache置换算法的变种,以及新型cache技术,如组织优化(Organize)、负载均衡(Load Balance)等;
4、最后,学生自己动手实现cache的编程,并用调试工具检测cache的程序是否正确。
四、实验总结
经过本次实验,我们对cache的硬件结构、替换算法、动态优化有了更加全面的认识,并且深入理解了cache在系统中的应用,锻炼了我们的编程能力。
同时,我们在实验中,也提升了自己的专业技能,为以后学习打下扎实的基础。
体系结构试验报告(cache存储过程)
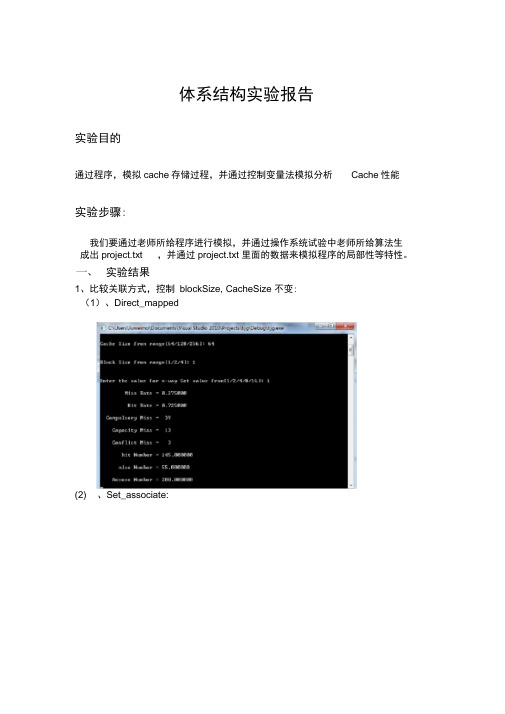
体系结构实验报告实验目的通过程序,模拟cache存储过程,并通过控制变量法模拟分析Cache性能实验步骤:我们要通过老师所给程序进行模拟,并通过操作系统试验中老师所给算法生成出project.txt ,并通过project.txt 里面的数据来模拟程序的局部性等特性。
实验结果1、比较关联方式,控制blockSize, CacheSize 不变:(1)、Direct_mapped(2) 、Set_associate:(3) 、Fully_associate通过上述三个比较可以看出,各种映射有自己的优点。
但是不难看出,增大关联度会减小miss rate,但是增加到一定程度又会有抑制作用。
2.比较Cache大小对于性能的影响。
(1)、Direct_mapped,Cache容量为64 时:(2rDirecflmapped〉Cache朿*R128 手(3r Direcflmapped〉Cache助*R256口F一pwsef 峑s 2O J I 0\^J.e e K ^g 63-L w g <J g -f aJnnnrEd理"巧 nmrMecIrlxMLH肆一事呼LJw匸-dJ-LUfJF U »»a iB cinIJr ltRn x li 黑鱼*=£1K s 1!蚯c a p w p llrt t M:C4mw JLl n rll n i H HHi L n h != l£lx-瞌忻恥f*<41.匸«F 23L L/2\.*X «礼 j !H F i <n对比实验结果,不难发现,随着Cache容量的增加,Cache的命中率一直在提升。
分析原因发现,虽然Cache容量大了,但并不等于其预存的内容增多,所以命中率会上升。
3、比较Cache大小对于性能的影响。
(1)、Direct_mapped,关联度为 1 时:(2)、Direct_mapped,关联度为2 时:(3)、Direct_mapped,关联度为4 时:(4) 、Direct mapped ,关联度为 8 时:I ■ C -\LI wrs 1.11uwei mo\Dw_-m e ts'_Vi EUUI I ^tud o l£f Pre e-crE\tt. q\Dfft!uq\ti'g.-i-j rIE Is-* -IrMHiF OP n tiny Ret U <A lun f 1± flhissH41# a 聊C4pnic4tv Conflictnx5S(5) 、Direct map ped ,关联度为 16 时:可以看出,随着关联度的提高,命中率也有所增加Canipuilsnry 1XSE-hH MuflfafiP = I44.MIUUM1Ace R -S3 NumWr ■寸-F口寸 灭 」eqlunu>loo-q〈 p ①ddelu —10①」一q <(L)S33I・鹫詡M us y u s L l's童wr#*■L 書-E .f n -sr e U F K e$us.H92m £百1-■阿*E戏*%贰%严一&丫A*u-uk s ?£Lc 』 C3"f l a毒* 1和4£sE E *B J W11v m 「>!5q言石-d ^l L l e l迟E n p xll -,.I 曰右号v d d -o'w -o M n 「口釜l Y ci-te L ^R 」eqlunu>loo-q 〈 p ①ddelu —10①」Q <通过以上三组数据不难看出,当block number增加时,命中率明显增高了。
计算机组成原理实验报告-Cache模拟器的实现

计算机组成原理实验报告-Cache模拟器的实现实验内容:1、启动CacheSim。
2、根据课本上的相关知识,进一步熟悉Cache的概念和工作机制。
3、依次输入以下参数:Cache容量、块容量、映射方式、替换策略和写策略。
Cache容量块容量映射方式替换策略写策略256KB 8 Byte 直接映射------ -------64KB 32 Byte 4路组相联 LRU -------64KB 32 Byte 4路组相联随机--------8KB 64 Byte 全相联 LRU ---------4、读取cache-traces.zip中的trace文件。
5、运行程序,观察cache的访问次数、读/写次数、平均命中率、读/写命中率。
思考:1、Cache的命中率与其容量大小有何关系?2、Cache块大小对不命中率有何影响?3、替换算法和相联度大小对不命中率有何影响?实验步骤与预习:实验步骤:1、启动CacheSim。
2、根据课本上的相关知识,进一步熟悉Cache的概念和工作机制。
3、依次输入以下参数:Cache容量、块容量、映射方式、替换策略和写策略。
4、读取cache-traces.zip中的trace文件。
5、运行程序,观察cache的访问次数、读/写次数、平均命中率、读/写命中率。
预习:Cache:高速缓冲存储器高速缓冲器是存在于主存与CPU之间的一级存储器,由静态存储芯片(SRAM)组成,容量比较小但速度比主存高得多,接近于CPU的速度。
Cache的功能是用来存放那些近期需要运行的指令与数据。
目的是提高CPU对存储器的访问速度。
工作机制:主要由三大部分组成:Cache存储器:存放由主存调入的指令与数据块。
地址转换部件:建立目录表以实现主存地址到缓存地址的转换。
替换部件:在缓存已满时按照一定的策略进行数据块替换,并修改地址转换部件。
实验结果:一般而言,cache用量越大,其cpu命中率越高,当然容量也没必要太大,当cache 容量达到一定的值时,命中率不因容量的增大而有明显的提高。
实验3 Cache性能分析

实验3 Cache 性能分析3.1 实验目的1. 加深对Cache 的基本概念、基本组织结构以及基本工作原理的理解;2. 掌握Cache 的容量、相联度、块大小对Cache 性能的影响;3. 掌握降低Cache 不命中率的各种方法,以及这些方法对Cache 性能提高的好处;4. 理解LRU 与随机法的基本思想以及它们对Cache 性能的影响;3.2 实验平台实验平台采用Cache 模拟器My Cache 。
3.3 实验内容及步骤首先要掌握My Cache 模拟器的使用方法。
3.3.1 Cache 的容量对不命中率的影响 1. 启动MyCache 模拟器。
2. 用鼠标单击“复位”按钮,把各参数设置为默认值。
3. 选择一个地址流文件。
方法:选择“访问地址”→“地址流文件”选项,然后单击“浏览”按钮,从本模拟器所在的文件夹下的“地址流”文件夹中选取。
4. 选择不同的Cache 容量,包括2KB 、4KB 、8KB 、16KB 、32KB 、64KB 、128KB 和256KB 。
分别执行模拟器(单击“执行到底”按钮即可执行),然后在表5.1中记录各种情况下的不命中率。
地址流文件名: E:\cjh\系统结构模拟器\MyCache 模拟器\地址流\all.din 5. 以容量为横坐标,画出不命中率随Cache 容量变化而变化的曲线,并指明地址流文件名。
不命中率随Cache容量变化图0.00%2.00%4.00%6.00%8.00%10.00%12.00%248163264128Cache容量(KB)不命中率6据结果,你能得出什么结论?3.3.2 相联度对不命中率的影响1. 用鼠标单击“复位”按钮,把各参数设置为默认值。
此时的Cache 的容量为64KB 。
2. 选择一个地址流文件。
方法:选择“访问地址”→“地址流文件”选项,然后单击“浏览”按钮,从本模拟器所在的文件夹下的“地址流”文件夹中选取。
3. 选择不同的Cache 相联度,包括直接映像、2路、4路、8路、16路和32路。
计组实验报告

计组实验报告【实验名称】:基于MIPS的Cache设计与实现【实验目的】:通过设计、模拟和测试基于MIPS的Cache,理解和掌握Cache的基本原理和实现方法,加深对计算机组成原理的理解和应用。
【实验设备】:Xilinx ISE Design Suite 14.7、Verilog HDL仿真工具、Mars模拟器。
【实验原理】Cache是计算机系统中重要的存储器层次结构,它可以提高访问速度,降低访问延迟。
Cache是一种由高速存储器和控制电路组成的存储器,它的作用是缓存主存中最近使用过的指令和数据,当下一次需要使用这些指令和数据时,可以直接从Cache中获取,而不需要访问主存,从而提高访问速度。
计算机系统中的Cache存储器既可以用硬件实现,也可以用软件实现。
MIPS Cache包括指令Cache和数据Cache两个部分。
指令Cache用于存储CPU需要的指令,而数据Cache用于存储CPU需要的数据。
Cache中的每一个存储块叫做一个Cache 行,每一个Cache行包括若干字块,每一个字块包括若干字节。
Cache行的大小一般是2^n 个字节。
Cache使用一种叫做Cache命中的技术,通过判断当前CPU需要的数据是否在Cache中来确定是否需要访问主存。
如果当前CPU需要的数据在Cache中,则称为Cache命中,可以直接从Cache中获取数据;如果当前CPU需要的数据不在Cache中,则称为Cache未命中,需要从主存中获取数据。
Cache有三种常见的替换算法:随机替换算法、先进先出(FIFO)替换算法和最近最少使用(LRU)替换算法。
随机替换算法是最简单的方法,它实现起来比较简单,但是效率不高。
FIFO替换算法是一种比较简单的替换算法,它在实现的时候需要维护一个队列来保证替换最早进入Cache的数据,但是这种算法无法适应程序的访存局部性。
LRU替换算法是一种比较复杂的替换算法,它需要维护一个使用时间序列来记录各数据块被使用的时间,当需要替换时,选择使用时间最旧的数据块替换掉。
体系结构试验报告(cache存储过程)
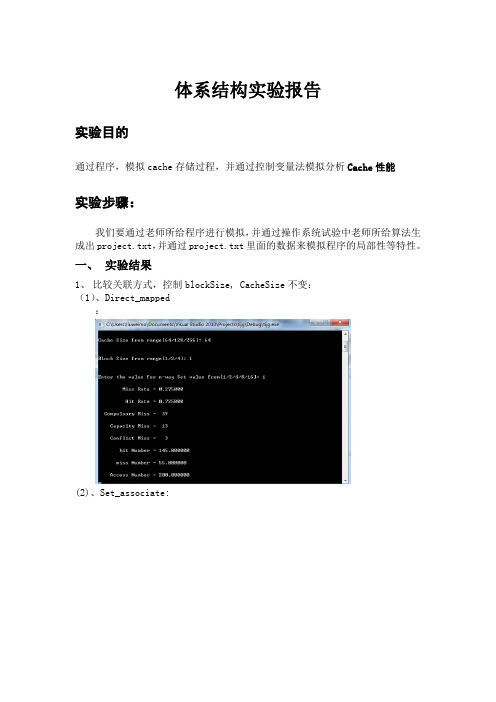
体系结构实验报告实验目的通过程序,模拟cache存储过程,并通过控制变量法模拟分析Cache性能实验步骤:我们要通过老师所给程序进行模拟,并通过操作系统试验中老师所给算法生成出project.txt,并通过project.txt里面的数据来模拟程序的局部性等特性。
一、实验结果1、比较关联方式,控制blockSize, CacheSize不变:(1)、Direct_mapped:(2)、Set_associate:(3) 、Fully_associate通过上述三个比较可以看出,各种映射有自己的优点。
但是不难看出,增大关联度会减小miss rate,但是增加到一定程度又会有抑制作用。
2.比较Cache大小对于性能的影响。
(1)、Direct_mapped,Cache容量为64时:(2)、Direct_mapped,Cache容量为128时:(3)、Direct_mapped,Cache容量为256时:对比实验结果,不难发现,随着Cache容量的增加,Cache的命中率一直在提升。
分析原因发现,虽然Cache容量大了,但并不等于其预存的内容增多,所以命中率会上升。
3、比较Cache大小对于性能的影响。
(1)、Direct_mapped,关联度为1时:(2)、Direct_mapped,关联度为2时:(3)、Direct_mapped,关联度为4时:(4)、Direct_mapped,关联度为8时:(5)、Direct_mapped,关联度为16时:可以看出,随着关联度的提高,命中率也有所增加。
—4、比较block Number对于Cache性能影响。
(1)、Direct_mapped, block number为1时:(2)、Direct_mapped, block number为2时:(1)、Direct_mapped, block number为4时:通过以上三组数据不难看出,当block number增加时,命中率明显增高了。
可溶解热塑性聚酰亚胺薄膜的制备和性能研究
可溶解热塑性聚酰亚胺薄膜的制备和性能研究目录一、内容概括 (2)1. 研究背景 (2)2. 研究意义 (3)3. 研究目的和内容 (4)二、实验材料与方法 (5)1. 实验原料 (6)2. 制备方法 (7)溶液制备 (8)薄膜浇筑与干燥 (9)固化处理 (10)3. 性能测试方法 (12)原位红外光谱分析 (13)X射线衍射分析 (14)热稳定性测试 (15)机械性能测试 (16)三、结果与讨论 (17)1. 形貌结构分析 (18)2. 热性能分析 (19)3. 机械性能分析 (19)4. 溶解性研究 (20)四、结论与展望 (22)一、内容概括本论文主要研究了可溶解热塑性聚酰亚胺薄膜的制备及其性能。
通过一系列实验,探讨了不同条件对聚酰亚胺薄膜溶解性和性能的影响,并对其结构与性能进行了表征。
本文介绍了热塑性聚酰亚胺的发展背景和重要性,以及可溶解热塑性聚酰亚胺薄膜在电子器件、柔性电路板等领域的应用潜力。
论文详细描述了实验部分,包括材料选择、制备方法、性能测试等。
在结果与讨论部分,论文展示了所制备的可溶解热塑性聚酰亚胺薄膜在不同溶剂中的溶解性,以及薄膜的力学性能、热稳定性和光学性能。
实验结果表明,通过优化制备条件,可以获得具有良好溶解性和优异性能的热塑性聚酰亚胺薄膜。
本文总结了研究成果,并展望了可溶解热塑性聚酰亚胺薄膜在未来的应用前景。
通过本论文的研究,为可溶解热塑性聚酰亚胺薄膜的进一步开发和应用提供了重要的理论依据和实践参考。
1. 研究背景随着科学技术的不断发展,可溶解热塑性聚酰亚胺(SPIM)薄膜在电子、光电、生物医药等领域具有广泛的应用前景。
目前市场上的SPIM薄膜主要依赖于传统的溶液浇铸法制备,存在工艺复杂、成本高昂、环境污染严重等问题。
研究一种新型、高效、环保的SPIM薄膜制备方法具有重要的理论和实际意义。
溶胶凝胶法作为一种新兴的聚合物制备技术,已经在聚合物材料领域取得了显著的成果。
该方法通过将聚合物溶液与溶剂混合,再通过加热或冷却等条件使溶胶中的高分子链发生交联反应,最终形成凝胶状物质。
cache硬件设计实验报告
cache硬件设计实验报告摘要:本文介绍了 cache 硬件设计的基本原理和实现方法,并通过一个具体的实验案例,展示了如何通过 cache 硬件设计来提高计算机系统的性能。
实验过程中使用了 NVIDIA CUDA 平台,实现了一个基于 cache 硬件设计的并行计算框架,用于处理大规模图像数据。
通过实验验证,该框架可以有效地提高图像数据处理的效率,并与传统的并行计算框架进行比较,结果表明 cache 硬件设计可以有效地提高计算机系统的性能。
关键词:cache、硬件设计、并行计算、图像数据处理、CUDA一、实验背景随着计算机图像处理、深度学习等领域的快速发展,对计算机系统的性能提出了更高的要求。
为了提高计算机系统的性能,越来越多的研究人员开始研究基于 cache 硬件设计的并行计算框架。
cache 硬件设计可以通过优化数据访问顺序,提高计算机系统的数据预取能力,从而提高计算机系统的性能。
在图像处理、深度学习等领域中,大量的数据需要进行并行处理,因此 cache 硬件设计成为了一种非常重要的并行计算框架。
二、实验目的本文旨在通过 cache 硬件设计实验,验证 cache 硬件设计对于计算机系统性能的提升作用。
具体实验目的是:1. 验证 cache 硬件设计是否能够提高计算机系统的数据预取能力;2. 验证 cache 硬件设计是否能够提高计算机系统的效率;3. 比较 cache 硬件设计和传统的并行计算框架在图像处理领域的性能差异。
三、实验方案1. 实验环境本文的实验环境采用 NVIDIA CUDA 平台,操作系统为 Linux。
实验中使用的 GPU 为 GeForce GTX 1080,内存为 8GB。
2. 实验框架本文的实验框架采用基于 cache 硬件设计的并行计算框架,具体包括以下三个模块:模块一:cache 硬件设计模块。
该模块实现一个基于 CUDA 点多线程并行计算框架,用于处理大规模图像数据。
cache实验报告
cache实验报告Cache实验报告一、引言计算机系统中的缓存(Cache)是一种用于提高数据访问速度的技术。
通过在CPU与主存之间插入一个高速缓存存储器,可以减少CPU等待主存数据的时间,从而提高系统的整体性能。
本实验旨在通过实际操作,深入了解并掌握Cache的工作原理。
二、实验目的1. 了解Cache的基本概念和工作原理;2. 学习Cache的组织结构和映射方式;3. 掌握Cache的读写操作流程;4. 分析Cache的命中率和访问延迟。
三、实验环境本实验使用Intel Core i7处理器和8GB内存的计算机。
四、实验步骤1. 确定实验所需的Cache参数,包括Cache大小、Cache块大小和关联度等;2. 设计并编写测试程序,用于模拟不同的内存访问模式;3. 运行测试程序,并记录Cache的读写命中次数和访问延迟;4. 分析实验结果,计算Cache的命中率和平均访问延迟。
五、实验结果与分析1. Cache命中率根据实验数据统计,我们可以计算出Cache的命中率。
命中率是指在所有内存访问中,Cache能够直接从Cache中读取数据的比例。
通过调整Cache的大小和关联度等参数,可以观察到命中率的变化。
实验结果表明,增加Cache的大小和提高关联度可以显著提高命中率。
2. 访问延迟访问延迟是指从CPU发出内存读写请求到实际完成读写操作所需的时间。
通过实验测量,我们可以得到不同访问模式下的平均访问延迟。
实验结果显示,随着Cache大小的增加,访问延迟逐渐减少。
这是因为Cache能够更快地响应CPU的读写请求,减少了CPU等待主存数据的时间。
3. 性能优化通过实验结果的分析,我们可以发现一些性能优化的方法。
首先,合理设置Cache的大小和关联度,可以提高命中率和降低访问延迟。
其次,采用合适的替换算法(如LRU)可以减少缓存失效的次数,提高Cache的效率。
此外,程序的空间局部性和时间局部性对Cache的性能也有重要影响,优化算法和数据结构可以提高程序的局部性,从而提高Cache的命中率。
Cache模拟实验
Cache 模拟实验1、原理在计算机系统中,缓存技术无处不在。
在整个存储系统中,寄存器是高速缓存的缓存,高速缓存是内存的缓存,内存又是硬盘的缓存,而硬盘又是网络设备的缓存。
在空间上,靠近CPU 的存储器是远离CPU 的缓存,而且越靠近CPU 存储器的速度越快,容量越小,单位存储的价格越高,这些存储器构成的计算机存储系统更像一座山——存储器山,图中仅展示了3级存储,如下图:靠近CPU 方向速度高容量小单位存储价格高速度低容量大单位存储价格低远离CPU 方向当CPU 访问存储器时,是从最靠近它的存储器来查找,如果要存储的内容不在靠近它的存储器中,再从下一级存储器中读取一块,如果下一级存储器中也没有找到要存储的内容,就再在下下一级存储器中读取一块,这个过程将一直延续到最底层存储器。
当要存储的内容调入到靠近它的存储器中之后,CPU再从其中存取所需的内容。
这个过程就叫Cache。
Cache是以块为单位进行的,块的大小有上层存储的大小来决定,一般Cache用一个4元组来描述——(S,E,B,m),S是上层存储器的分组数,用s来表示S占用的位数,E是每个组中包含的行数,B是一行中真正存储数据的字节数,用b来表示B占用的位置,m是存储系统的地址线的宽度。
为了便于Cache的管理还要有一个标志位,用来标识本行数据是否有效,这个有效标志不会出现在内存地址中;除此之外,还有标志位,这个标志位是出现在内存地址中的,我们用t 来表示。
内存地址,包含t,s和b。
如下图:t bits 标志s bits 组索引上图就是Cache的一行的单独内容,整个Cache就是这样的数据结构的集合,现在举个例子来综合进行说明,假如m=8,b=2,E=1,s=2,那么t就等于m-b-s,也就是t=4。
此外E=1,也就是每一个组中包含一行。
CPU假如读取0x00地址的内容,从Cache中读取要分3步进行,首先,确定组,地址0x00的二进制表示 0000 0000B,bit2和bit3,就是组的索引,可以确定是第0组。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
汕头大学实验报告
学院: 工学院系: 计算机系专业: 计算机科学与技术年级: 13实验时间: 2015.6.16 姓名: 林子伦学号: 2013101030实验名称:基于SPIM-CACHE的Cache实验
一.实验目的:
(1)熟悉SPIM-CACHE模拟器环境
(2)深入认识CACHE的工作原理及其作用。
二.实验内容:
(1)阅读实验指导书资料(虚拟教室提供了英文论文的电子版本);
(2)下载SPIM-CACHE软件,理解英文论文的基本内容之后,给出几种典型的cache配置,运行英文论文提供的代码,记录运行时CACHE命中率等重要数据;(3)运行Fig.4代码,了解mapping functions 即映射规则
(4)运行Fig.7代码,了解temporal and spatial locality 即时空局部性,进一步理解cache的工作原理;
(5)运行Fig.8代码,运行学习replacement algorithms 即替代算法,理解其工作原理。
三.实验地点,环境
实验地点:软件工程实验室
实验环境:
操作系统:Microsoft Windows 8 中文版
处理器:Intel(R) Core(TM) i3-3120M CPU @ 2.50GHz 2.50GHz
内存: 4.00GB(3.82GB 可用)
四.实验记录及实验分析(80%):
4.1实验前配置:
1) 按下图配置好Spim设置
2)关于实验中cache设置如下(具体配置根据下面实验要求)
——》
——》
Cache size ——cache大小
Block size ——块大小
Mapping ——组相连
4.2实验一:fig4.s
实验目的:Algorithm and corresponding code to study mapping functions Cache配置:256-B size, 16-B line size, four-way set associative
实验操作:
1) Ctrl+O 打开运行代码fig4.s
代码如下:
.data 0x10000480
Array_A: .word 1,1,1,1,2,2,2,2
.data 0x10000CC0
Array_B: .word 3,3,3,3,4,4,4,4
.text
.globl _start
_start: la $2,Array_A
li $6,0
li $4,8
loop: lw $5,0($2)
add $6,$6,$5
addi $2,$2,4
addi $4,$4,-1
bgt $4,$0,loop
2) 按F5运行程序,得到结果如下图
Instruction cache’s hit rate : 0.792453
Data cache’s hit rate : 0.750000
4.3实验二:fig7.s
实验目的:Algorithm and corresponding code to study temporal and spatial locality
4.3.1 spatial locality
Cache配置:256-B size, four-way set associative, 分别定义block size
为16,8,4B
实验操作:
1) Ctrl+O 打开运行代码fig7.s
代码如下:
.data 0x10000480
Array_A: .word 1,1,1,1,2,2,2,2
.data 0x10000CC0
Array_B: .word 3,3,3,3,4,4,4,4
.text
.globl __start
__start: li $8,1
#这里要得到教程里的0.75,0.5,0 这里的$8里一定要为1
ext_loop: la $2,Array_A
la $3,Array_B
li $6,0 #sum=0
li $4,8 #number of elements
loop: lw $5,0($2)
lw $7,0($3)
add $6,$6,$5 #sum=sum+arrayA[i]
add $6,$6,$7 #sum=sum+arrayB[i]
addi $2,$2,4
addi $3,$3,4
addi $4,$4,-1
addi $8,$8,-1
bgt $8,$0,ext_loop
.end
2)按F5运行程序
Block size:16B
命中率为0.75
Block size:8B
命中率为0.5
Block size:4B
命中率为0
4.3.2 temporal locality
Cache配置:256-B size, 16-B line size, four-way set associative
实验操作:
1) Ctrl+O 打开运行代码fig7.s
代码如下:(代码中N每次改写为1或5或10或100)
.data 0x10000480
Array_A: .word 1,1,1,1,2,2,2,2
.data 0x10000CC0
Array_B: .word 3,3,3,3,4,4,4,4
.text
.globl __start
__start: li $8,N #N=1,5,10,100
ext_loop: la $2,Array_A
la $3,Array_B
li $6,0 #sum=0
li $4,8 #number of elements
loop: lw $5,0($2)
lw $7,0($3)
add $6,$6,$5 #sum=sum+arrayA[i]
add $6,$6,$7 #sum=sum+arrayB[i]
addi $2,$2,4
addi $4,$4,-1
bgt $4,$0,loop
addi $8,$8,-1
bgt $8,$0,ext_loop
.end
2) 按F5运行程序
N=1
命中率为0.759036。
N=5
命中率为0.950860。
N=10
命中率为0.975369。
N=100
命中率为0.997531。
4.4实验三:fig8.s
实验目的:Algorithm and corresponding code provided to work on replacement algorithms and strides.
Cache配置:256-B size, 16-B line, and direct mapped.
实验操作:
1) Ctrl+O 打开运行代码fig8.s
代码如下:
.data 0x10000000
Array_A: .word 0,1,2,3,4,5,6,7,8,9,10,11,...,125,126,127
.text
.globl __start
__start: li $8,100 #external loop
li $3,4 #stride value
li $6,0
sll $9,$3,2
ext_loop: li $5,128
li $4,0
int_loop: lw $7,Array_A($4)
add $6,$6,$7
add $4,$4,$9
sub $5,$5,$3
bgt $5,$0,int_loop
addi $8,$8,-1
bgt $8,$0,ext_loop
.end
五.实验体会(20%)
1. 本次试验对照着英语的教程,尝试的了解并发现了试验教程有些许错误:错误说明
1.1 从右边我们可以看到数组AB都只有8个元素
1.2 所以左边的循环应该一个为循环次数一个为数组个数
1.3 从右边我们可以看到内层循环次数固定为8 外层循环个数不定为N(根据实验要
求为1,5,10,100)
1.4 所以左边的c语言代码应该是
Sum=0;
For(j=0;j<N;j++) //N=1,5,10,100
For(i=0; i<8;i++)
Sum=sum+A[i]+B[i];
2. 本次实验过程中还经常遇到一个问题
无论是哪个程序,都提示在语句__start: 这条语句出现错误,这个问题的解决办法是打开菜单栏Simulator->Settings 红色框内的选项不能打钩
3. 本次实验很好地体会了cache的各种工作,对cache有了更深入的了解,对课程的学习有很大的帮助。