Cache命中率分析工具的使用(附源代码)
Cache安装使用

5TERMINAL使用(3)
常用操作
4运行Routine: 不传参数:d Tag^Routine,或d ^Routine 假如:文件名为Test.mac 的Routine内容为:
GetTime w $ZD($p($h,",",1),3)_" "_$ZT($p($h,",",2)) 在Terminal中运行结果为:
课后练习(2)
7创建命名空间和远程数据库 8建立定时任务,查看任务的运行情况 9创建csp Application 10新建一个Routine,打印出输入整数的3次方 11新建一个类方法,交换两个整数a和b的值,并进行调 试 12导入导出Global 13导入导出Routine 14导入导出类定义、工程
1CACHÉ介绍(4)
Caché SQL存取
SQL 网关(SQL Gateway)功能使得 Caché应用程序能从关系型数据 库中 存取数据;关系型数据库转移到 Caché上 Caché可以兼容所有这些使用 SQL 的应用程序 DDL 文件中的关系型表格定义来创建数据结构
1CACHÉ介绍(5)
1CACHÉ介绍(7)
Caché 完整的开发环境 提供开发、调试、部署的环境, 提供插件工具对外部接口的引用。 提供导入导出代码工具
2CACHÉ安装(1)
安装准备 1安装文件 2License:cache.key 安装要求
注意:安装文件路径不能包含中文
2CACHÉ安装(2)
可采用多种方式数据建模:对象、表格、或者多维数组 Studio、DDL、 Rational Rose 多种技术编写数据库和业务逻辑 Cache ObjectScript 、CachéBasic、JAVA、.Net
Cache实验

Caches实验杨祯 15281139实验目的1.阅读分析附件模拟器代码2.通过读懂代码加深了解cache的实现技术3.结合书后习题1进行测试4.通过实验设计了解参数(cache和block size等)和算法(LRU,FIFO 等)选择的优化配置与组合,需要定性和定量分析,可以用数字或图表等多种描述手段配合说明。
阅读分析模拟器代码课后习题stride=132下直接相连映射1)实验分析由题意得:cachesize=256B blockinbyte=4*4BNoofblock=256B/16B=16个组数位16array[0]的块地址为0/4=0 映射到cache的块号为0%16=0 array[132]的块地址为132/4=33 映射到cache的块号为33%16=1第一次访问cache中的0号块与1号块时,会发生强制性失效,之后因为调入了cache中,不会发生失效,所以misscount=2 missrate=2/(2*10000)=1/10000hitcount=19998 hitrate=9999/10000 实验验证stride=131下直接相连映射实验分析由题意得:cachesize=256B blockinbyte=4*4BNoofblock=256B/16B=16个组数位16array[0]的块地址为0/4=0 映射到cache的块号为0%16=0array[131]的块地址为131/4=32 映射到cache的块号为32%16=0 第一次访问cache中的0号时,一定会发生强制性失效,次数为1;之后因为cache中块号为0的块不断地被替换写入,此时发生的是冲突失效,冲突失效次数为19999,则发生的失效次数为19999+1=20000 所以misscount=20000 missrate=20000/(2*10000)=1实验验证stride=132下2路组相连映射实验分析由题意得:cachesize=256B blockinbyte=4*4BNoofblock=256B/16B=16个Noofset=16/2=8组array[0]的块地址为0/4=0 映射到cache的组号为0%8=0array[132]的块地址为132/4=33 映射到cache的组号为33%8=1第一次访问cache中的0号块与1号块时,一定会发生强制性失效,之后因为调入了cache中,不会发生失效,所以misscount=2 missrate=2/(2*10000)=1/10000hitcount=19998 hitrate=9999/10000 实验验证stride=131下2路组相连映射实验分析由题意得:cachesize=256B blockinbyte=4*4BNoofblock=256B/16B=16个Noofset=16/2=8组array[0]的块地址为0/4=0 映射到cache的组号为0%8=0array[131]的块地址为131/4=32 映射到cache的组号为32%8=0 第一次访问cache中的0组时,一定会发生强制性失效,因为1组中有2个块,不妨假设array[0]对应0组中的第0块,array[131]对应0组中的第1块,则强制失效次数为1;之后因为 array[0]与array[131]都在0组,不会发生失效则发生的失效次数为2次,命中次数为19998,所以misscount=2 missrate=2/(2*10000)=1/10000hitcount=19998 hitrate=9999/10000实验验证实验分析(1)block块大小与Cache容量对Cache效率的影响实验以Hitrate作为衡量指标,在直接相连映射,组相连度为1,project.txt 为500个1---100的随机数。
Cache性能分析
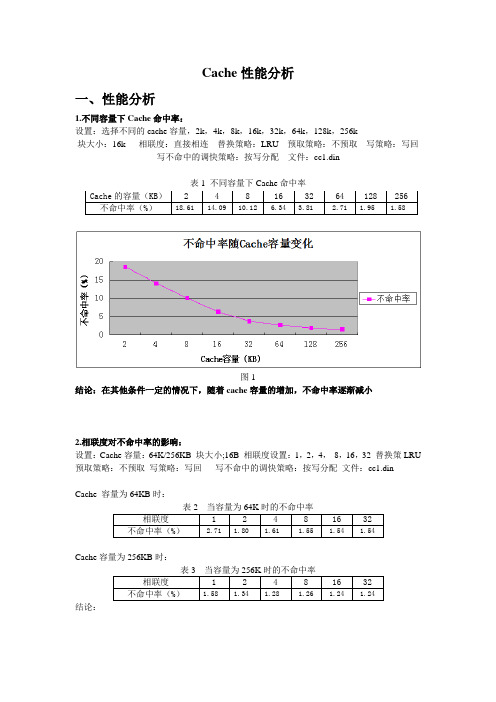
Cache 性能分析一、性能分析1.不同容量下Cache 命中率:设置:选择不同的cache 容量,2k ,4k ,8k ,16k ,32k ,64k ,128k ,256k块大小:16k 相联度:直接相连 替换策略:LRU 预取策略:不预取 写策略:写回写不命中的调快策略:按写分配 文件:cc1.din表1 不同容量下Cache 命中率图1结论:在其他条件一定的情况下,随着cache 容量的增加,不命中率逐渐减小2.相联度对不命中率的影响:设置:Cache 容量:64K/256KB 块大小;16B 相联度设置:1,2,4, 8,16,32 替换策LRU 预取策略:不预取 写策略:写回 写不命中的调快策略:按写分配 文件:cc1.dinCache 容量为64KB 时:表2 当容量为64K 时的不命中率相联度 1 2 4 8 16 32不命中率(%)2.71 1.80 1.61 1.55 1.54 1.54Cache 容量为256KB 时:表3 当容量为256K 时的不命中率相联度 1 2 4 8 16 32不命中率(%)1.58 1.34 1.28 1.26 1.24 1.24 结论:Cache 的容量(KB ) 2 4 8 16 32 64 128 256不命中率(%)18.61 14.09 10.12 6.34 3.81 2.71 1.95 1.58图2结论:(1)当Cache容量一定时,随着相联度的不断增加,不命中率逐渐减小,但是当相联度增加到一定程度时,不命中率保持不变。
(2)当关联度相同时,Cache容量越大,不命中率越小,当关联度增加到一定程度时,不命中率和Cache容量大小无关。
3.Cache块大小对命中率的影响:设置:Cahce块大小(B):16,32,64,128,256 Cache容量设置(KB):2,8,32,128,512相联度:直接相联预取策略:不预取写策略:写回写不命中的调快策略:按写分配文件:eg.din表4 不同Cache行大小情况下Cache的不命中率块大小(B)Cache的容量(KB)2 8 32 128 51216 7.80% 7.40% 7.20% 7.20% 7.20%32 5.40% 5.00% 4.70% 4.70% 4.70%64 4.00% 3.40% 3.10% 3.10% 3.10%128 4.40% 3.30% 2.40% 2.40% 2.40%256 6.50% 5.10% 2.30% 1.90% 1.90%图3结论:(1)在Cache容量一定时,Cache 不命中率随着Cache行的增加先减小后增加。
java cache的hitcount函数

java cache的hitcount函数以下是一篇关于Java缓存的hitcount函数的文章:Java Cache的hitcount函数:将缓存性能提升到一个新的水平引言:在当今的软件开发中,性能是一个至关重要的因素。
为了提高性能,开发人员通常会使用各种优化技术。
其中之一就是缓存。
缓存是一种存储在内存中的临时数据存储器,用于存储频繁访问的数据,以提高数据访问速度。
在Java编程语言中,我们经常使用缓存来加快代码的执行速度。
在本文中,我们将重点讨论一个名为hitcount的函数,以及如何使用它来改进缓存性能。
1. 什么是缓存?在计算机科学中,缓存是一种高速数据存储器,用于存储经常被访问的数据,以便在将来的访问中提供更快的访问速度。
缓存可以存储各种类型的数据,例如数据库查询结果、网络请求结果或计算结果。
当代码需要访问这些数据时,它首先检查缓存,如果数据已经存储在缓存中,则直接从缓存中获取数据,从而避免了耗时的访问原始数据源的过程。
2. 缓存的好处使用缓存可以带来许多好处。
首先,它显着提高了代码的执行速度。
由于缓存数据存储在内存中,而内存的访问速度通常比磁盘或网络访问速度快得多,因此缓存能够提供更快的数据访问速度。
其次,使用缓存可以减轻数据源的负载。
当代码频繁访问数据源时,缓存可以减少与数据源的交互次数,从而减少了对数据源的压力。
最后,缓存还可以降低网络延迟。
如果数据源位于远程服务器上,通过缓存将数据存储在本地内存中,可以避免网络传输延迟,并且可以更快地访问数据。
3. hitcount函数的作用hitcount函数是一个用于统计缓存命中次数的函数。
当代码从缓存中获取数据时,它会调用hitcount函数,该函数会记录缓存命中的次数。
通过统计缓存命中次数,开发人员可以评估缓存的性能。
如果缓存命中次数较高,说明缓存效果良好,数据几乎都从缓存中获取。
相反,如果缓存命中次数较低,可能意味着缓存策略需要进行优化或者数据不适合缓存。
实验4 Cache性能分析

实验4 Cache性能分析4.1 实验目的1.加深对Cache的基本概念、基本组织结构以及基本工作原理的理解;2.掌握Cache的容量、相联度、块大小对Cache性能的影响;3.掌握降低Cache不命中率的各种方法,以及这些方法对Cache性能提高的好处;4.理解LRU与随机法的基本思想以及它们对Cache性能的影响;4.2 实验平台实验平台采用Cache模拟器My Cache。
4.3 实验内容及步骤首先要掌握My Cache模拟器的使用方法。
4.3.1 Cache的容量对不命中率的影响1.启动MyCache模拟器。
2.用鼠标单击“复位”按钮,把各参数设置为默认值。
3.选择一个地址流文件。
方法:选择“访问地址”→“地址流文件”选项,然后单击“浏览”按钮,从本模拟器所在的文件夹下的“地址流”文件夹中选取。
4.选择不同的Cache容量,包括2KB、4KB、8KB、16KB、32KB、64KB、128KB和256KB。
分别执行模拟器(单击“执行到底”按钮即可执行),然后在表5.1中记录各种情况下的不命中率。
地址流文件名:5.以容量为横坐标,画出不命中率随Cache容量变化而变化的曲线,并指明地址流文件名。
6.根据该模拟结果,你能得出什么结论?4.3.2 相联度对不命中率的影响1.用鼠标单击“复位”按钮,把各参数设置为默认值。
此时的Cache的容量为64KB。
2.选择一个地址流文件。
方法:选择“访问地址”→“地址流文件”选项,然后单击“浏览”按钮,从本模拟器所在的文件夹下的“地址流”文件夹中选取。
3.选择不同的Cache相联度,包括直接映像、2路、4路、8路、16路和32路。
分别执行模拟器(单击“执行到底”按钮即可执行),然后在表5.2中记录各种情况下的不命中率。
地址流文件名:4.把Cache的容量设置为256KB,重复3的工作,并填写表5.3。
5.以相联度为横坐标,画出在64KB和256KB的情况下不命中率随Cache相联度变化而变化的曲线,并指明地址流文件名。
run-clang-tidy用法

run-clang-tidy用法run-clang-tidy是一个用于运行Clang-Tidy静态分析工具的实用程序。
它提供了一种便捷的方法来检查和改进C++代码的质量和可读性。
本文将详细介绍run-clang-tidy的用法,以便读者了解如何在其项目中使用此工具进行代码检查和改进。
1. 什么是Clang-Tidy?Clang-Tidy是一个基于Clang的静态分析工具,用于检查C++代码中的潜在问题和一般性错误。
它使用编译器内部的静态分析框架,并提供了大量的检查规则,以帮助开发人员识别常见的编码错误和潜在问题。
2. 为什么使用run-clang-tidy?使用Clang-Tidy可以帮助开发人员在编译时检测可能导致运行时错误、内存泄漏、未定义行为和性能问题的代码。
它能够捕获一些编译器可能会忽略的问题,并提供相应的建议和修复建议,帮助开发人员改进代码质量。
run-clang-tidy是一个方便的工具,它简化了使用Clang-Tidy的过程。
3. 安装run-clang-tidy要使用run-clang-tidy,您需要安装LLVM和Clang。
您可以从官方网站(4. 配置run-clang-tidy在您的C++项目中,您需要创建一个名为`.clang-tidy`的文件来配置run-clang-tidy。
这个文件描述了您希望运行的Clang-Tidy检查和选项。
您可以根据您的项目需求自定义配置。
以下是一个示例`.clang-tidy`文件的内容:Checks: 'modernize-*'CheckOptions:- { key: modernize-use-auto, value: false }- { key: modernize-loop-convert, value: false }上述示例配置了一些在现代化转换方面的检查,如`modernize-use-auto`和`modernize-loop-convert`。
cachefs使用方法

cachefs使用方法Cachefs是一个用于Linux系统的内核文件系统,它允许用户将磁盘上的文件缓存到内存中,以提高文件读取的速度。
Cachefs 的使用方法涉及几个步骤:1. 安装Cachefs,首先,您需要确保您的Linux内核支持Cachefs,并且已经安装了Cachefs的用户空间工具。
您可以通过包管理器来安装Cachefs,或者从源代码进行编译安装。
2. 配置Cachefs,一旦Cachefs安装完成,您需要进行一些配置。
您可以编辑Cachefs的配置文件,通常是在/etc/cachefilesd.conf中。
您可以指定要缓存的目录、缓存的大小、缓存的策略等。
3. 启动Cachefs,在配置完成后,您需要启动Cachefs服务。
您可以使用systemctl或service命令来启动Cachefs服务。
一旦Cachefs服务启动,它将开始监视您指定的目录,并将文件缓存到内存中。
4. 监控Cachefs,一旦Cachefs开始运行,您可以使用cachefilesdctl工具来监视Cachefs的运行情况。
您可以查看缓存命中率、缓存大小等信息。
5. 测试Cachefs,最后,您可以测试Cachefs的性能。
您可以通过读取经常访问的文件来测试Cachefs是否能够加速文件读取。
您还可以通过监视系统资源使用情况来评估Cachefs对内存和CPU 的影响。
需要注意的是,Cachefs的使用方法可能会因Linux发行版和Cachefs版本而有所不同,因此在使用Cachefs之前,请务必查阅相应的文档和指南以获取准确的使用方法。
希望这些信息能够帮助您更好地理解Cachefs的使用方法。
缓存命中率测试标准

缓存命中率测试标准一、引言缓存命中率是衡量缓存系统性能的重要指标之一。
高缓存命中率表示缓存系统能够高效地提供数据,减轻后端数据库的负载,从而提升系统的响应速度和并发能力。
本文将从缓存命中率的定义和计算方法、测试环境搭建、测试数据准备和测试指标分析等方面,对缓存命中率的测试标准进行探讨。
二、缓存命中率的定义和计算方法2.1 定义缓存命中率是指在一定时间内,缓存系统中所命中的缓存请求数占总请求数的比例。
通常用百分比表示,高命中率表示大部分数据都能从缓存中获取,反之表示缓存系统效果较差。
2.2 计算方法缓存命中率的计算方法有多种,以下是常用的两种方法:2.2.1 单位时间内的命中率单位时间内的命中率计算非常简单,直接将命中的请求数除以总请求数即可,如下所示:命中率 = (命中的请求数 / 总请求数) × 100%2.2.2 滑动窗口平均命中率滑动窗口平均命中率是计算一定时间范围内的命中率的方法。
它利用滑动窗口记录最近一段时间的缓存命中情况,并根据窗口的长度计算平均命中率。
计算公式如下:平均命中率 = (滑动窗口内的命中请求数 / 滑动窗口内的总请求数) × 100%三、测试环境搭建为了进行缓存命中率的测试,我们需要搭建一个合适的测试环境。
下面是测试环境的搭建步骤:1.准备一台运行缓存系统的服务器,可以使用开源的缓存软件,比如Redis、Memcached等。
2.准备一台运行数据库的服务器,用于模拟后端数据库。
3.在测试客户端上安装相应的测试工具,比如Apache JMeter、Redis-benchmark等。
四、测试数据准备进行缓存命中率测试需要准备一定量的测试数据,以模拟实际的应用场景。
以下是测试数据准备的步骤:1.创建一个包含大量数据的数据库表,可以使用工具生成测试数据,确保数据具有一定的规模和分布。
2.将部分数据加载到缓存系统中,以模拟实际应用中缓存系统的初始化。
3.编写测试脚本或使用测试工具,模拟用户对数据的读取和更新操作。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
题目:安装一种Cache命中率分析工具,并现场安装、演示。
一、什么是CPU-Cache
CPU缓存(Cache Memory)是位于CPU与内存之间的临时存储器,它的容
量比内存小的多但是交换速度却比内存要快得多。
高速缓存的出现主要是为了解
决CPU运算速度与内存读写速度不匹配的矛盾,因为CPU运算速度要比内存读
写速度快很多,这样会使CPU花费很长时间等待数据到来或把数据写入内存。
在缓存中的数据是内存中的一小部分,但这一小部分是短时间内CPU即将访问的,当CPU调用大量数据时,就可先缓存中调用,从而加快读取速度。
CPU包
含多个核心,每个核心又有独自的一级缓存(细分成代码缓存和数据缓存)和二
级缓存,各个核心之间共享三级缓存,并统一通过总线与内存进行交互。
二、关于Cache Line
整个Cache被分成多个Line,每个Line通常是32byte或64byte,Cache Line
是Cache和内存交换数据的最小单位,每个Cache Line包含三个部分
Valid:当前缓存是否有效
Tag:对应的内存地址
Block:缓存数据
三、Cache命中率分析工具选择
1、Linux平台:Valgrind分析工具;
2、Windows平台如下:
java的Jprofiler;
C++的VisualStudio2010及以后的版本中自带profile工具;
Application Verifier;
intel vtune等。
四、选用Valgrind分析工具在Linux-Ubuntu14.04环境下实验
1.Valgrind分析工具的常用命令功能:
memcheck:检查程序中的内存问题,如泄漏、越界、非法指针等。
callgrind:检测程序代码的运行时间和调用过程,以及分析程序性能。
cachegrind:分析CPU的cache命中率、丢失率,用于进行代码优化。
helgrind:用于检查多线程程序的竞态条件。
massif:堆栈分析器,指示程序中使用了多少堆内存等信息。
2.Valgrind分析工具的安装:
使用Ubuntu统一安装命令:sudo apt-get install valgrind
之后等待安装完成即可。
安装界面如图(由于我已经安装了此工具,而且没有更新的版本,图上结果为无可用升级)。
五、使用Valgrind分析工具测试程序的Cache命中率
1.首先,编写两个C语言程序,主要使用对数组数据两种读写方式来测试Cache命中率的不同,同时根据程序做同一件事的运行时间来判断程序质量的好坏。
代码如下:
cache1.c :
#include <stdio.h>
#include <time.h>
#include<sys/time.h>
#define MAXROW 8000
#define MAXCOL 8000
int main () {
struct timeval startTime,endTime;
float Timeuse;
int i,j;
static int x[MAXROW][MAXCOL];
printf ("Running!\n");
gettimeofday(&startTime,NULL);
for (i=0;i<MAXROW;i++)
for (j=0;j<MAXCOL;j++)
x[i][j] = i*j;
printf("Completed!\n");
gettimeofday(&endTime,NULL);
Timeuse = 1000000*(_sec - _sec) + (_usec - _usec);
Timeuse /= 1000000;
printf("Timeuse = %f\n",Timeuse);
return 0;
}
cache2.c :
#include <stdio.h>
#include <time.h>
#include<sys/time.h>
#define MAXROW 8000
#define MAXCOL 8000
int main () {
struct timeval startTime,endTime;
float Timeuse;
int i,j;
static int x[MAXROW][MAXCOL];
printf ("Running!\n");
gettimeofday(&startTime,NULL);
for (j=0;j<MAXCOL;j++)
for (i=0;i<MAXROW;i++)
x[i][j] = i*j;
printf("Completed!\n");
gettimeofday(&endTime,NULL);
Timeuse = 1000000*(_sec - _sec) + (_usec - _usec);
Timeuse /= 1000000;
printf("Timeuse = %f\n",Timeuse);
return 0;
}
2.对以上两个程序进行Cache命中率测试:
①编译两程序:
gcc -o cache1 cache1.c
gcc -o cache2 cache2.c
②使用命令valgrind --tool=cachegrind ./cache1
测试cache1程序的Cache命中率:
③使用命令valgrind --tool=cachegrind ./cache2
测试cache2程序的Cache命中率:
3.对测试结果进行分析:
·由cache1测试结果可以看出程序cache1的D1 miss rate: 0.8%可知1级Cache的数据未命中率为0.8%,即命中率为99.2%;
·由Timeuse = 9.733398可以cache1中数组循环完成的时间是9.733398s
由cache2测试结果可以看出程序cache2的D1 miss rate: 14.2%可知1级Cache的数据未命中率为14.2%,即命中率为85.8%;
·由Timeuse = 15.708803可以cache1中数组循环完成的时间是15.708803s
综上可知cache1程序的cache命中率大于cache2,cache1循环所用时间少于cache2,即cache1程序质量比cache2好。
六、感想
这次研讨主要对Cache及Cache命中率测试工具进行了讨论,准备这次研讨时,我先查找了有关CPU Cache的资料并进行学习,加深了我对CPU Cache的理解,之后,查找了各种有关Cache命中率分析工具的资料,并选择Linux环境下的Valgrind作为此次研讨使用的工具。
在对程序进行Cache命中率的测试过程中,我对程序代码进行了设计编写,尽可能的使得程序Cache命中率变化明显,进而容易对比,容易理解。
这也让我对Valgrind工具的使用更加熟悉,也对造成Cache命中率高低的因素有了更明确的理解,深感收获很多!。