编译原理陈火旺版7章7
编译原理 第7章习题解答

第七章习题解答7.1 给定文法:S→(A)A→ABBA→BB→bB→c①构造它的基本LR(0)项目集;②构造它的LR(0)项目集规范族;③构造识别该文法活前缀的DFA;④该文法是SLR文法吗?若是,构造它的SLR分析表。
7.2 给定文法:E→EE+E→EE*E→a①构造它的LR(0)项目集规范族;②它是SLR(1)文法吗?若是,构造它的SLR(1)分析表;③它是LR(1)文法吗?若是,构造它的LR(1)分析表;④它是LALR(1)文法吗?若是,构造它的LALR分析表。
7.3 给出一个非LR(0)文法。
7.4 给出一个SLR(1)文法,但它不是LR(0)文法,构造它的SLR分析表。
7.5 给出一个LR(1)文法,但它不是LALR(1)文法,构造它的规范LR(1)分析表。
7.6 给定二义性文法:① E→E+E② E→E*E③ E→(E)④ E→id用所述的无二义性规则和(或)另加一些无二义性规则,例如,给算符*、+施加某种结合规则。
①构造它的LR(0)项目集规范族及识别活前缀的DFA;②构造它的LR分析表。
习题参考答案7.1 解:文法的基本LR(0)项目集为S→.(A) S→(.A) S→(A.) S→(A).A→.ABB A→A.BB A→AB.B A→ABB.A→.B A→B. B→.b B→b.B→.c B→c.构造该文法的识别活前缀的DFSA如下图所示:I文法的识别活前缀的DFSA该文法的LR(0)项目集规范族={I0,I1,I2,I3,I4,I5,I6,I7,I8}因为在构造出来的识别活前缀的DFA中,每一个状态对应的项目集都不含有移进-归约、归约-归约冲突,所以该文法是LR(0)文法,当然也是SLR文法。
因为 FOLLOW(S)={#}FOLLOW(A)=FIRST{)}∪FIRST(BB)={),b,c}FOLLOW(B)=FIRST(B)∪FOLLOW(A)={b,c,)}其对应的SLR(1)分析表如下表所示。
编译原理第七章 习题参考答案
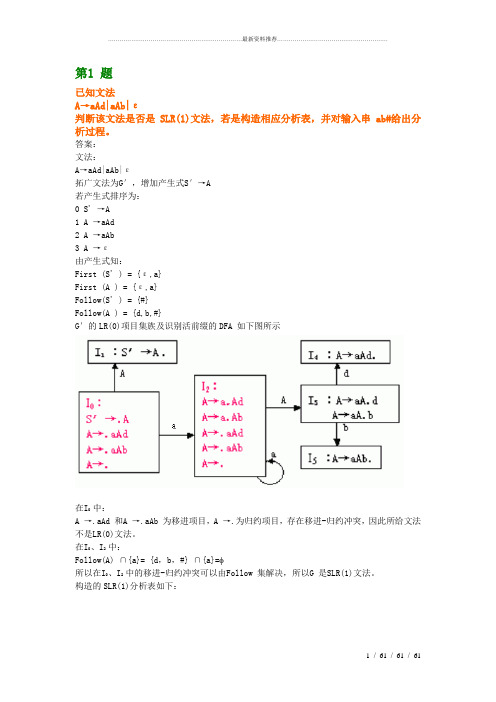
第1 题已知文法A→aAd|aAb|ε判断该文法是否是SLR(1)文法,若是构造相应分析表,并对输入串ab#给出分析过程。
答案:文法:A→aAd|aAb|ε拓广文法为G′,增加产生式S′→A若产生式排序为:0 S' →A1 A →aAd2 A →aAb3 A →ε由产生式知:First (S' ) = {ε,a}First (A ) = {ε,a}Follow(S' ) = {#}Follow(A ) = {d,b,#}G′的LR(0)项目集族及识别活前缀的DFA 如下图所示在I0 中:A →.aAd 和A →.aAb 为移进项目,A →.为归约项目,存在移进-归约冲突,因此所给文法不是LR(0)文法。
在I0、I2 中:Follow(A) ∩{a}= {d,b,#} ∩{a}=所以在I0、I2 中的移进-归约冲突可以由Follow 集解决,所以G 是SLR(1)文法。
构造的SLR(1)分析表如下:对输入串ab#的分析过程:第2 题若有定义二进制数的文法如下:S→L·L|LL→LB|BB→0|1(1) 试为该文法构造LR 分析表,并说明属哪类LR 分析表。
(2) 给出输入串101.110 的分析过程。
答案:文法:S→L.L|LL→LB|BB→0|1拓广文法为G′,增加产生式S′→S若产生式排序为:0 S' →S1 S →L.L2 S →L3 L →LB4 L →B5 B →06 B →1由产生式知:First (S' ) = {0,1}First (S ) = {0,1}First (L ) = {0,1}First (B ) = {0,1}Follow(S' ) = {#}Follow(S ) = {#}Follow(L ) = {.,0,1,#}Follow(B ) = {.,0,1,#}G′的LR(0)项目集族及识别活前缀的DFA 如下图所示:在I2 中:B →.0 和 B →.1 为移进项目,S →L.为归约项目,存在移进-归约冲突,因此所给文法不是LR(0)文法。
编译原理 - 陈火旺版 - 第七章

3
后缀式
后缀式(逆波兰式)
表达式E的后缀形式E’的写法:
• 若E是变量或常量,则E’ = E • 若E=E1 op E2,则E’ =E1’ E2’ op • 若E=(E1),则E’ = E1 表达式变为后缀形式的语义规则
E→E1 op E2 E→(E1) E→i {E.CODE := E1.CODE||E2.CODE||op } {E.CODE := E1.CODE} {E.CODE := i}
推广到表达式外的范围
• 例如 a:=b*c+b*d 后缀形式:abc*bd*+:=
5
图
抽象语法树
内部结点表示运算符,后代表示运算对象
无循环有向图(DAG)
与抽象语法树
• 相同之处:内部结点表示运算符,后代表示运算对象 • 不同之处:考虑到公共子表达式(不只一个父结点),更加紧 凑高效
四元组表示 (1) (-,C, D , T1) (2) (*, B, T1, T2) (3) (+, A, T2 , T3) (4) (↑, F, G , T4) (5) ( /, E, T4, T5) (6) (-, T3, T5 , T6)
13
说明语句的翻译
说明语句
定义局部于该过程的数据对象(以标识符标识) 为数据对象分配空间,在符号表中登记数据对象的名 字,类型,分配的存储地址 有过程嵌套的,表示出嵌套关系
编译方法
中国人民大学信息学院 陈文萍
1
第7章 语义分析和中间代码生成
中间语言 一些语法成分的翻译
说明语句 赋值语句 布尔表达式 控制语句 过程调用
类型检查
2
语义分析概述
《编译基本知识》(陈火旺版)课后作业任务参备考资料答案解析

第6章属性文法和语法制导翻译7. 下列文法由开始符号S产生一个二进制数,令综合属性val给出该数的值:试设计求S.val的属性文法,其中,已知B的综合属性c, 给出由B产生的二进位的结果值。
例如,输入101.101时,S.val=5.625,其中第一个二进位的值是4,最后一个二进位的值是0.125。
【答案】11. 设下列文法生成变量的类型说明:(1)构造一下翻译模式,把每个标识符的类型存入符号表;参考例6.2。
【答案】第7章语义分析和中间代码产生1. 给出下面表达式的逆波兰表示(后缀式):【答案】3. 请将表达式-(a+b)*(c+d)-(a+b+c)分别表示成三元式、间接三元式和四元式序列。
【答案】间接码表:(1)→(2)→(3)→(4)→(1)→(5)→(6)4. 按7.3节所说的办法,写出下面赋值句A:=B*(-C+D) 的自下而上语法制导翻译过程。
给出所产生的三地址代码。
5. 按照7.3.2节所给的翻译模式,把下列赋值句翻译为三地址代码:A[i, j]:=B [i, j] + C[A [k, l]] + d [ i+j]【答案】6. 按7.4.1和7.4.2节的翻译办法,分别写出布尔式A or ( B and not (C or D) )的四元式序列。
【答案】用作数值计算时产生的四元式: 用作条件控制时产生的四元式:其中:右图中(1)和(8)为真出口,(4)(5)(7)为假出口。
7. 用7.5.1节的办法,把下面的语句翻译成四元式序列:While A<C and B<D do if A=1 then C:=C+1 else while A ≦D do A:=A+2; 【答案】第9章 运行时存储空间组织4. 下面是一个Pascal 程序:当第二次( 递归地) 进入F 后,DISPLAY 的内容是什么?当时整个运行栈的内容是什么? 【答案】第1次进入F 后,运行栈的内容: 第2次进入F 后,运行栈的内容: 109 8 7 6 5 4 3 2 1第2次进入F 后,Display 内容为:5. 对如下的Pascal 程序,画出程序执行到(1)和(2)点时的运行栈。
《编译原理》教学课件-第7章 中间代码生成 7-2说明语句

D→id:T {enter(top(tblptr),,T.type,top(offset));
top(offset):=top(offset)+T.width }
N → { t:=mktable(top(tblptr));
push(t,tblptr);push(0,offset) }
图7.6 处理嵌套过程中的说明语句
3
每一个过程都建立一张独立的符号表 在符号表中有一个指针指向其外围过程的符号
表 在一个过程中,对于它内部定义的过程,都有
一个指针指向其内部过程的符号表
4
主程序:sort
readarray exchange quicksort
partition
5
sort
nil
header
a
x
readarray
offset:=offset+T.width }
Tinteger
{T.type:=interger; T.width=4;}
Treal
{T.type:=real; T.width=8;}
Tarray [num] of T1 { T.type:=array(num.val, T1.type);
T.width:=num.val*T1.width }
enterproc(table,name,newtable)在指针table指示的符 号表中为名字为name的过程建立一个新项
8
7.2.3 记录中的域名
Trecord LD end { T.type:=record(top(tblptr));
T.width:=top(offset);
pop(tblptr); pop(offset); }
编译原理 语义分析和中间代码产生 陈火旺

VARPART计算方法 VARPART:= i1; k:=1; While k<n do Begin VARPART:= VARPART*dk+1+ik+1; k:=k+1 end 其中CONSPART只依赖于数组各维的界限d和数组的首地址a, 它和数组元素各维下标i1, i2, ……, in无关
2.赋值句中数组元素的翻译 . (1)文法 S→L:=E L→id[Elist]∣id Elist→Elist, E∣E E E E→E+E∣(E)∣L (2)语义 赋值句中引用数组元素 (3)目标结构 [X:=]=A[E1, E2, ….., En] 说明 ①变址取数 X:=T1[T] (=[ ],T1[ T], _ , X) ②变址存数 T1[T]= X ([ ]=,X, _, T1[ T])
3.三地址语句表示法 . (1)四元式 四元式 带有四个域的记录结构 (op,arg1,arg2,result) 如:a:=b*-c+b*-c的四元式 <0>uminus c _ T1 <1> * b T1 T2 <2>uminus c T3 <3> * b T3 T4 <4> + T2 T4 T5 <5> := T5 _ a
第七章 语义分析和中间代码产生 7.1 中间语言 7.2 说明语句 7.3 赋值语句的翻译 7.4 布尔表达式的翻译 7.5 控制流语句的翻译 复习题
7.1 中间语言(Intermediate Language) 中间语言( )
一、中间代码(Intermediate Code, Intermediate 中间代码( representation) ) 1.中间代码 中间代码 源程序的一种内部表达,不依赖目标机的结构,易于机械 生成目标代码的中间表示,称为中间代码。 2.为什么要此阶段? 为什么要此阶段? 为什么要此阶段 使逻辑结构清楚 有利于不同目标机上实现同一种语言 有利于进行与机器无关的优化 这些内部形式也能用于解释
编译原理第7章答案
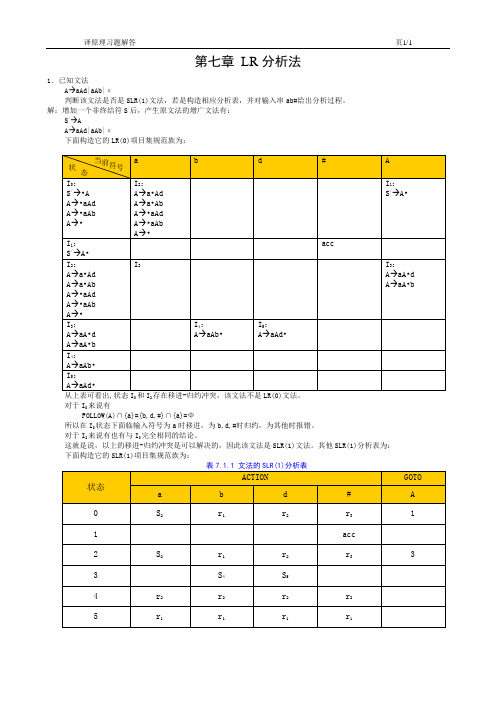
第七章LR分析法1.已知文法A→aAd|aAb|ε判断该文法是否是SLR(1)文法,若是构造相应分析表,并对输入串ab#给出分析过程。
解:增加一个非终结符S/后,产生原文法的增广文法有:S/→AA→aAd|aAb|ε下面构造它的LR(0)项目集规范族为:02对于I0来说有FOLLOW(A)∩{a}={b,d,#}∩{a}=Φ所以在I0状态下面临输入符号为a时移进,为b,d,#时归约,为其他时报错。
对于I2来说有也有与I0完全相同的结论。
这就是说,以上的移进-归约冲突是可以解决的,因此该文法是SLR(1)文法。
其他SLR(1)分析表为:下面构造它的SLR(1)项目集规范族为:15S→a|^|(T)T→T,S|S(1)构造它的LR(0),LALR(1),LR(1)分析表。
(2)给出对输入符号串(a#和(a,a#的分析过程。
(3)说明(1)中三种分析表发现错误的时刻和输入串的出错位置有何区别。
解:(1)加入非终结符S/,方法的增广文法为:S/→SS→aS→^S→(T)T→T,ST→S下面构造它的LR(0)项目集规范族为:表7.15.1 文法的LR(0)分析表17.若包含条件语句的语句文法可缩写为:S→iSeS|iS|S;S|a其中:i代表if,e代表else,a代表某一语句。
若规定:(1)else与其左边最近的if结合(2);服从左结合试给出文法中i,e,; 的优先关系,然后构造出无二义性的LR分析表,并对输入串iiaea#给出分析过程。
解:加入S/→S产生式构造出增广文法如下:[0] S/→S[1] S→iSeS[2] S→iS[3] S→S;S[4] S→a由习惯可知,定义文法中i,e,;,a4个算符的优先关系为:a>e>i>;。
并且i与;的结合方向均为自左至右。
由上述状态项目集可见:a.状态I1存在移进-归约冲突,由于FOLLOW(S/)∩{;}={#}∩{;}=Φ,所以面临#号时应acc,面临;号时应移进。
《编译原理》(陈火旺版)课后作业参考答案ch6-10

第6章 属性文法和语法制导翻译7. 下列文法由开始符号S 产生一个二进制数,令综合属性v al 给出该数的值:试设计求S.val 的属性文法,其中,已知B 的综合属性c, 给出由B 产生的二进位的结果值。
例如,输入101.101时,S.val=5.625,其中第一个二进位的值是4,最后一个二进位的值是0.125。
【答案】11. 设下列文法生成变量的类型说明:(1)构造一下翻译模式,把每个标识符的类型存入符号表;参考例6.2。
【答案】第7章 语义分析和中间代码产生1. 给出下面表达式的逆波兰表示(后缀式):3. 请将表达式-(a+b)*(c+d)-(a+b+c)分别表示成三元式、间接三元式和四元式序列。
【答案】间接码表:(1)→(2)→(3)→(4)→(1)→(5)→(6)4. 按7.3节所说的办法,写出下面赋值句A:=B*(-C+D ) 的自下而上语法制导翻译过程。
给出所产生的三地址代码。
【答案】5. 按照7.3.2节所给的翻译模式,把下列赋值句翻译为三地址代码: A[i, j]:=B [i, j] + C[A [k, l]] + d [ i+j] 【答案】6. 按7.4.1和7.4.2节的翻译办法,分别写出布尔式A or ( B and not (C or D) )的四元式序列。
【答案】用作数值计算时产生的四元式: 用作条件控制时产生的四元式:其中:右图中(1)和(8)为真出口,(4)(5)(7)为假出口。
7. 用7.5.1节的办法,把下面的语句翻译成四元式序列: While A<C and B<D do if A=1 then C:=C+1else while A ≦D do A:=A+2; 【答案】第9章 运行时存储空间组织4. 下面是一个Pascal 程序:当第二次( 递归地) 进入F 后,DISPLAY 的内容是什么?当时整个运行栈的内容是什么? 【答案】第1次进入F 后,运行栈的内容: 第2次进入F 后,运行栈的内容:第2次进入F 后,Display 内容为:5. 对如下的Pascal 程序,画出程序执行到(1)和(2)点时的运行栈。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1、 编译程序的任务是把源语言程序翻译成目标程序, 有些编译程序在编译过程中,不产生中间语言,而 是直接从源语言程序翻译成目标语言程序。
源程序
编译程序
目标代码
以上编译过程省略了中间语言,它不利于编译所产生的目 标代码的优化.为了产生高质量的代码,可以将源语言程序首 先翻译成一种特殊形式的中间语言代码形式,并对其进行优化, 然后再将它翻译成最终的目标代码。
rop为: =,<>,<= <,>=,>
3.转向语句的四元式: 有以下三种跳转四元式:
•(jnz , a , - , p) 表示 if a goto p; •(jrop , x , y , p) 表示 if x rop y goto p; •( j , - , - , p) 表示 goto p;
4.条件语句的四元式: 例1:if a<b then x:=a+b else x:=a-b 对应的四元式为: (1) (j< , a , b , 3 ) 回填 (2) (j , - , - , 6 ) 回填 (3) (+ , a , b , T1 ) (4) (:= , T1 , - , x ) 回填 (5) ( j , - , - , 8 ) (6) ( - , a , b , T2 ) (7) (:= , T2 , - , x ) (8) …… 例2:if a<b and e>d then x:=a+b else x:=a-b 例3:if a<b or e>d then x:=a+b else x:=a-b
#
语法制导翻译的实质
根据文法中每个产生式所蕴含的语义, 为其配备一个(或多个)语句或子程序, 对所要完成的功能进行描述,在语法分 析过程中,当分析器使用该产生式进行 语法分析时(不论是推导还是规约), 除完成语法分析动作之外,还将调用为 其配备的语义子程序,进行相应地语义 处理,完成语义翻译工作。
源程序
语法分析
中间代码
优化
优化后中间代码
目标代码
代码生成
中间代码
中间代码也叫中间语言 (Intermediate code /language)是:源 程序的一种内部表示,不依赖目标机的结构, 复杂性介于源语言和机器语言之间。
中间代码的优点
1、逻辑结构清楚; 2、利于不同目标机上实现同一种语言; 3、利于进行与机器无关的优化;
实例
表达式(中缀式): A+B*(C-D)+E/(C-D) 后缀式: A B CD- * + E CD- /+ 表达式(中缀式):
(a=0∧ b>3)∨ (e ∧x >y) ∧∨ 后缀式: a0=b3 > ∧ e xy >
结论
从以上两个例子我们可得出: 1、在两种表示中,运算对象出现的顺序相同; 2、在后缀表示中,运算符按实际计算顺序 从左到右排列,且每一运算符总是跟在运算 对象之后。 翻译成后缀式的语义描述见P167表7.1。
例
a:=b*-c+b*-c
op arg1 uminus c * b uminus c * b + := T2 T5 arg2 T1 T3 T4 result T1 T2 T3 T4 T5 a
三地址代码-三元式
三元式顾名思义就是带有三个域的记录结 构,他的一般形式为 (i)(op,arg1,arg2) 其中,(i)为三元式的编号,也代表了 该式的运算结果,op,arg1,arg2的含 义与四元式类似,区别在于arg可以是某 三元式的序号,表示用该三元式的结果作 为运算对象。
三地址代码-间接三元式
建立两个与三元式有关的表格,一个称 为三元式表,用于存放各三元式本身;另 一个称为执行表,它按照三元式的执行顺 序,依次列出相应各三元式在三元式表中 的位置,也就是说我们用一个三元式表连 同执行表来表示中间代码。通常我们称这 种表示方法为间接三元式。
例
x:=(a+b)*c b:=a+b y:=c*(a+b)
例1
a+a*(b-c)+(b-c)*d + + a a * b c c * d
b
翻译成抽象语法树的属性文法见P169表7.2
图表示法-DAG图
DAG(Directed Acyclic Graph)有向无循环图
对表达式中的每个子表达式,DAG都有一个 结点,一个内部结点代表一个操作符,他的 孩子代表操作数。在一个DAG中代表公共子 表达式的节点 具有多个父结点(与抽象语 法树中公共子表达式被表示为重复的子树不 同)
后缀式的推广 条件语句的翻译: If e THEN S1 else S2
图表示法-抽象语法树
在语法树中去掉一些对翻译不必要的信 息后,获得的更有效的源程序的中间表示, 这种经过变换后的语法树称为抽象语法树。 在抽象语法树中,操作符和关键字都不 作为叶子节点出现,而是把它们作为内部 节点,即这些叶子节点的父节点。
由此可见:抽象文法符号的具体语义信息,是在语法分析同 步的语义处理过程中获取和加工的。
属性文法
将语义以“属性”的形式附加到各 文法符号上,再根据产生式所蕴含的语 义,给出每个文法符号的属性的求值规 则,从而形成一种带有语义属性的前后 文无关文法,即属性文法。
属性
一个文法符号X的语义信息我们称之为语义 属性或简称为属性(Atrributes)
X.TYPE表示为X的类型 X.VAL表示为X的值
例:
对于文法: E →E+T | T T→ digit
产生式 语义子程序
1、E→ E(1)+T {E.Val=E(1).Val+T.Val 2、E→ T {E.Val=T.Val} 3、T→ digit {T.Val=digit}
例
语法分析栈 语义信息栈 T + E … # T.Val ‘ +’ E(1).Val … E … E.Val …
三地址码的各种形式:P170
1. 2. 3. 4. x:=y op z Goto L Param x x:=y[i] x := op z if x relop y goto L call p,n x[i]:=y x:=*y x:=y if a goto L return y *x:=y
5. x:=&y
三元式
x:=(a+b)*c b:=a+b y:=c*(a+b)
(1)(+,a,b) (5) (+,a,b) (2)(*,(1),c) (6)(*,c,(5)) (3)(:=,x,(2)) (7)(:=,y,(6)) (4)(:=,b,(1))
间接三元式
执行表 (1) (2) (3) (4) (1) (2) (5)
1 2 3 4 5 6 7 8 9 10
…
id
assign …
a
9 … 8 …
三地址代码
三地址代码最基本的用法形式: x:=y op z 其中x、y、z为名字、常数或编译时产生的 临时变量;op代表运算符号。每个语句的右边只 能有一个运算符。 例如:x+y*z可以翻译为: T1:=y*z T2:=x+T1 T1、T2位编译时产生的临时变量
2、对同一表达式而言,所需的三元式或 四元式的个数一般都是相同的。
三元式和四元式的比较
不同点: 1、由于三元式没有result字段,且不需要临时变量, 故三元式比四元式占用的存储空间少; 2、在进行代码优化处理时,常常需要挪动一些运算 的位置,这对于三元式序列来说是很困难的,但对于 四元式来说,由于四元式之间的相互联系是通过临时 变量来实现的,所以,更改其中一些四元式给整个系 列带来的影响就比较小。
中间代码常见的几种形式
1、后缀式 2、图表示法 抽象语法树、DAG图 3、三地址代码 三元式、四元式、间接三元式
后缀式
后缀式是波兰逻辑学家卢卡西维奇 (J.Lukasiewicz)提出的一种对表达式的 表示方法:每一运算符都置于其运算对象之 后,即操作数写在前面,算符写在后面。 它的特点是:表达式中各个运算是按运算符 出现的顺序进行的,故无需用括号来指示运 算顺序,因而又称为无括号式。
赋值语句翻译为三地址码的属性文法 P171 ,表7.3
三地址代码—四元式
四元式实际上是一种“三地址语句”的 等价表示,是一个带有四个域的记录结构。 它 的一般形式为: (op,arg1,arg2,result) 需要指出的是:每个四元式只能有一个 运算符,所以,一个复杂的表达式只能由多 个四元式构成的序列表示。
例
a+a*(b-c)+(b-c)*d
+ + * a * d
b
c
抽象语法树的表示方法
1、每一个结点用一个记录来表示,该记 录包括一个运算符域和若干个指向子结 点的指针域。
例: a:=b*-c+b*-c
assign a * + * a assign + *
b
- b c 抽象语法树
c
b DAG
c
方法1
5.循环语句的四元式 待讨论循环语句的翻译时介绍。
语法制导的翻译方法:
就是对文法中的每个产生式都附加一个 语义动作或语义子程序,且在语法分析过程中, 每当需要使用一个产生式进行推导或归约时,语 法分析程序除执行相应的语法分析动作之外,还 要执行相应地语义动作或语义子程序。每个语义 子程序都指明了相应产生式中各个符号的具体含 义,并规定了使用该产生式进行分析时所应采取 的语义动作。 翻译过程见P171表7。3。 这种模式既把语法分析与语义处理分开,又 令其平行地进行,让其在同一遍扫描中同时完成 语法分析和语义处理两项工作。
语义分析
在词法分析和语法分析之后,编译 程序要完成语义分析和翻译工作。由 于编译器完成的分析是静态定义的,所 以,语义分析也可称作静态语义分析 (static semantic analysis)。