数据结构课程设计(内部排序算法比较-C语言)
数据结构-内排序

Shell排序的性能分析
Shell排序的时间复杂度在O(nlog2n)和O(n2)间, Knuth的 统计结论是,平均比较次数和记录平均移动次数在n1.25与 1.6n1.25之间
Shell排序是一种不稳定的排序方法
最后谈一下delta的取法。 Shell最初的方案是delta=n/2, delta=delta/2,直到delta=1。Knuth的方案是delta=delta/3 +1。其它方案有:都取奇数为好;或delta互质为好等等。 而使用象1, 2, 4, 8, …或1, 3, 6, 9, …这样的增量序列就不太 合适,因为这样会使几个元素多次被分到一组中,从而造 成重复排序,产生大量无用的比较操作
另外,在无序子表中向前移动的过程中,如果没 有交换元素,则说明无序子表已有序,无须再做 排序
24
冒泡排序算法实现
1 void bubble_sort(RecType R[ ], int n) { 2 //待排序元素用一个数组R表示,数组有n个记录
3 int i, j; 4 bool swap=TRUE; //判断无序子表是否已有序的变量
内排序和外排序 按照排序过程中使用内、外存的不 同将排序方法分为内排序和外排序。若待排序记录全 部在内存中,称为内排序;若待排序记录的数量很大, 以致内存一次不能容纳全部记录,在排序过程中需要 进行内、外存交换,称为外排序。本章仅讨论内排序
内排序可分为五大类:插入排序、交换排序、选择排 序、归并排序和基数排序
直接插入排序(straight insert sort) 折半插入排序(binary insert sort) Shell排序(Shell sort)
10
10.2.1 直接插入排序举例
数据结构c语言课设-二叉树排序

题目:二叉排序树的实现1 内容和要求1)编程实现二叉排序树,包括生成、插入,删除;2)对二叉排序树进展先根、中根、和后根非递归遍历;3)每次对树的修改操作和遍历操作的显示结果都需要在屏幕上用树的形状表示出来。
4)分别用二叉排序树和数组去存储一个班(50 人以上)的成员信息(至少包括学号、姓名、成绩3 项),比照查找效率,并说明在什么情况下二叉排序树效率高,为什么?2 解决方案和关键代码2.1 解决方案:先实现二叉排序树的生成、插入、删除,编写DisplayBST函数把遍历结果用树的形状表示出来。
前中后根遍历需要用到栈的数据构造,分模块编写栈与遍历代码。
要求比照二叉排序树和数组的查找效率,首先建立一个数组存储一个班的成员信息,分别用二叉树和数组查找,利用clock〔〕函数记录查找时间来比照查找效率。
2.2关键代码树的根本构造定义及根本函数typedef struct{KeyType key;} ElemType;typedef struct BiTNode//定义链表{ElemType data;struct BiTNode *lchild, *rchild;}BiTNode, *BiTree, *SElemType;//销毁树int DestroyBiTree(BiTree &T){if (T != NULL)free(T);return 0;}//清空树int ClearBiTree(BiTree &T){if (T != NULL){T->lchild = NULL;T->rchild = NULL;T = NULL;}return 0;}//查找关键字,指针p返回int SearchBST(BiTree T, KeyType key, BiTree f, BiTree &p) {if (!T){p = f;return FALSE;}else if EQ(key, T->data.key){p = T;return TRUE;}else if LT(key, T->data.key)return SearchBST(T->lchild, key, T, p);elsereturn SearchBST(T->rchild, key, T, p);}二叉树的生成、插入,删除生成void CreateBST(BiTree &BT, BiTree p){int i;ElemType k;printf("请输入元素值以创立排序二叉树:\n");scanf_s("%d", &k.key);for (i = 0; k.key != NULL; i++){//判断是否重复if (!SearchBST(BT, k.key, NULL, p)){InsertBST(BT, k);scanf_s("%d", &k.key);}else{printf("输入数据重复!\n");return;}}}插入int InsertBST(BiTree &T, ElemType e){BiTree s, p;if (!SearchBST(T, e.key, NULL, p)){s = (BiTree)malloc(sizeof(BiTNode));s->data = e;s->lchild = s->rchild = NULL;if (!p)T = s;else if LT(e.key, p->data.key)p->lchild = s;elsep->rchild = s;return TRUE;}else return FALSE;}删除//某个节点元素的删除int DeleteEle(BiTree &p){BiTree q, s;if (!p->rchild) //右子树为空{q = p;p = p->lchild;free(q);}else if (!p->lchild) //左子树为空{q = p;p = p->rchild;free(q);}else{q = p;s = p->lchild;while (s->rchild){q = s;s = s->rchild;}p->data = s->data;if (q != p)q->rchild = s->lchild;elseq->lchild = s->lchild;delete s;}return TRUE;}//整棵树的删除int DeleteBST(BiTree &T, KeyType key) //实现二叉排序树的删除操作{if (!T){return FALSE;}else{if (EQ(key, T->data.key)) //是否相等return DeleteEle(T);else if (LT(key, T->data.key)) //是否小于return DeleteBST(T->lchild, key);elsereturn DeleteBST(T->rchild, key);}return 0;}二叉树的前中后根遍历栈的定义typedef struct{SElemType *base;SElemType *top;int stacksize;}SqStack;int InitStack(SqStack &S) //构造空栈{S.base = (SElemType*)malloc(STACK_INIT_SIZE *sizeof(SElemType));if (!S.base) exit(OVERFLOW);S.top = S.base;S.stacksize = STACK_INIT_SIZE;return OK;}//InitStackint Push(SqStack &S, SElemType e) //插入元素e为新栈顶{if (S.top - S.base >= S.stacksize){S.base = (SElemType*)realloc(S.base, (S.stacksize + STACKINCREMENT)*sizeof(SElemType));if (!S.base) exit(OVERFLOW);S.top = S.base + S.stacksize;S.stacksize += STACKINCREMENT;}*S.top++ = e;return OK;}//Pushint Pop(SqStack &S, SElemType &e) //删除栈顶,应用e返回其值{if (S.top == S.base) return ERROR;e = *--S.top;return OK;}//Popint StackEmpty(SqStack S) //判断是否为空栈{if (S.base == S.top) return TRUE;return FALSE;}先根遍历int PreOrderTraverse(BiTree T, int(*Visit)(ElemType e)) {SqStack S;BiTree p;InitStack(S);p = T;while (p || !StackEmpty(S)){if (p){Push(S, p);if (!Visit(p->data)) return ERROR;p = p->lchild;}else{Pop(S, p);p = p->rchild;}}return OK;}中根遍历int InOrderTraverse(BiTree T, int(*Visit)(ElemType e)) {SqStack S;BiTree p;InitStack(S);p = T;while (p || !StackEmpty(S)){if (p){Push(S, p);p = p->lchild;}else{Pop(S, p);if (!Visit(p->data)) return ERROR;p = p->rchild;}}return OK;}后根遍历int PostOrderTraverse(BiTree T, int(*Visit)(ElemType e)) {SqStack S, SS;BiTree p;InitStack(S);InitStack(SS);p = T;while (p || !StackEmpty(S)){if (p){Push(S, p);Push(SS, p);p = p->rchild;}else{if (!StackEmpty(S)){Pop(S, p);p = p->lchild;}}}while (!StackEmpty(SS)){Pop(SS, p);if (!Visit(p->data)) return ERROR;}return OK;}利用数组存储一个班学生信息ElemType a[] = { 51, "陈继真", 88,82, "黄景元", 89,53, "贾成", 88,44, "呼颜", 90,25, "鲁修德", 88,56, "须成", 88,47, "孙祥", 87, 38, "柏有患", 89, 9, " 革高", 89, 10, "考鬲", 87, 31, "李燧", 86, 12, "夏祥", 89, 53, "余惠", 84, 4, "鲁芝", 90, 75, "黄丙庆", 88, 16, "李应", 89, 87, "杨志", 86, 18, "李逵", 89, 9, "阮小五", 85, 20, "史进", 88, 21, "秦明", 88, 82, "杨雄", 89, 23, "刘唐", 85, 64, "武松", 88, 25, "李俊", 88, 86, "卢俊义", 88, 27, "华荣", 87, 28, "杨胜", 88, 29, "林冲", 89, 70, "李跃", 85, 31, "蓝虎", 90, 32, "宋禄", 84, 73, "鲁智深", 89, 34, "关斌", 90, 55, "龚成", 87, 36, "黄乌", 87, 57, "孔道灵", 87, 38, "张焕", 84, 59, "李信", 88, 30, "徐山", 83, 41, "秦祥", 85, 42, "葛公", 85, 23, "武衍公", 87, 94, "范斌", 83, 45, "黄乌", 60, 67, "叶景昌", 99, 7, "焦龙", 89, 78, "星姚烨", 85, 49, "孙吉", 90, 60, "陈梦庚", 95,};数组查询函数void ArraySearch(ElemType a[], int key, int length){int i;for (i = 0; i <= length; i++){if (key == a[i].key){cout << "学号:" << a[i].key << " 姓名:" << a[i].name << " 成绩:" << a[i].grade << endl;break;}}}二叉树查询函数上文二叉树根本函数中的SearchBST()即为二叉树查询函数。
数据结构课程设计—内部排序算法比较

数据结构课程设计—内部排序算法比较在计算机科学领域中,数据的排序是一项非常基础且重要的操作。
内部排序算法作为其中的关键部分,对于提高程序的运行效率和数据处理能力起着至关重要的作用。
本次课程设计将对几种常见的内部排序算法进行比较和分析,包括冒泡排序、插入排序、选择排序、快速排序和归并排序。
冒泡排序是一种简单直观的排序算法。
它通过重复地走访要排序的数列,一次比较两个数据元素,如果顺序不对则进行交换,并一直重复这样的走访操作,直到没有要交换的数据元素为止。
这种算法的优点是易于理解和实现,但其效率较低,在处理大规模数据时性能不佳。
因为它在最坏情况下的时间复杂度为 O(n²),平均时间复杂度也为O(n²)。
插入排序的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入,直到整个序列有序。
插入排序在数据量较小时表现较好,其平均时间复杂度和最坏情况时间复杂度也都是 O(n²),但在某些情况下,它的性能可能会优于冒泡排序。
选择排序则是每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(或最大)元素,然后放到已排序序列的末尾。
以此类推,直到全部待排序的数据元素排完。
选择排序的时间复杂度同样为O(n²),但它在某些情况下的交换操作次数可能会少于冒泡排序和插入排序。
快速排序是一种分治的排序算法。
它首先选择一个基准元素,将数列分成两部分,一部分的元素都比基准小,另一部分的元素都比基准大,然后对这两部分分别进行快速排序。
快速排序在平均情况下的时间复杂度为 O(nlogn),最坏情况下的时间复杂度为 O(n²)。
然而,在实际应用中,快速排序通常表现出色,是一种非常高效的排序算法。
归并排序也是一种分治算法,它将待排序序列分成若干个子序列,每个子序列有序,然后将子序列合并成一个有序序列。
C语言八大排序算法
C语⾔⼋⼤排序算法C语⾔⼋⼤排序算法,附动图和详细代码解释!来源:C语⾔与程序设计、⽵⾬听闲等⼀前⾔如果说各种编程语⾔是程序员的招式,那么数据结构和算法就相当于程序员的内功。
想写出精炼、优秀的代码,不通过不断的锤炼,是很难做到的。
⼆⼋⼤排序算法排序算法作为数据结构的重要部分,系统地学习⼀下是很有必要的。
1、排序的概念排序是计算机内经常进⾏的⼀种操作,其⽬的是将⼀组“⽆序”的记录序列调整为“有序”的记录序列。
排序分为内部排序和外部排序。
若整个排序过程不需要访问外存便能完成,则称此类排序问题为内部排序。
反之,若参加排序的记录数量很⼤,整个序列的排序过程不可能在内存中完成,则称此类排序问题为外部排序。
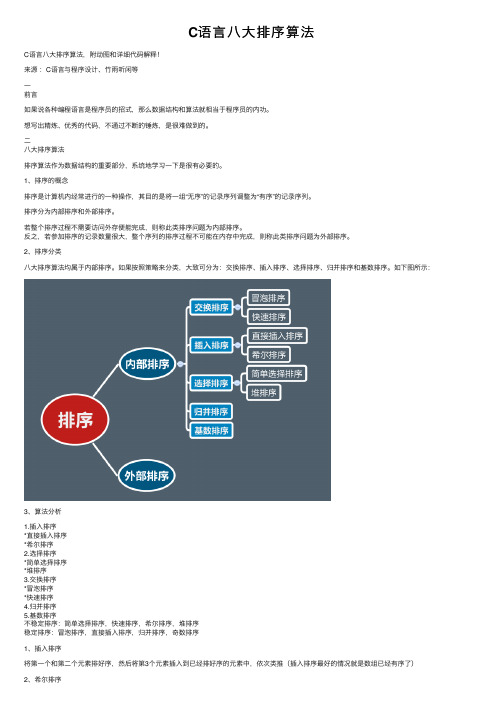
2、排序分类⼋⼤排序算法均属于内部排序。
如果按照策略来分类,⼤致可分为:交换排序、插⼊排序、选择排序、归并排序和基数排序。
如下图所⽰:3、算法分析1.插⼊排序*直接插⼊排序*希尔排序2.选择排序*简单选择排序*堆排序3.交换排序*冒泡排序*快速排序4.归并排序5.基数排序不稳定排序:简单选择排序,快速排序,希尔排序,堆排序稳定排序:冒泡排序,直接插⼊排序,归并排序,奇数排序1、插⼊排序将第⼀个和第⼆个元素排好序,然后将第3个元素插⼊到已经排好序的元素中,依次类推(插⼊排序最好的情况就是数组已经有序了)因为插⼊排序每次只能操作⼀个元素,效率低。
元素个数N,取奇数k=N/2,将下标差值为k的数分为⼀组(⼀组元素个数看总元素个数决定),在组内构成有序序列,再取k=k/2,将下标差值为k的数分为⼀组,构成有序序列,直到k=1,然后再进⾏直接插⼊排序。
3、简单选择排序选出最⼩的数和第⼀个数交换,再在剩余的数中⼜选择最⼩的和第⼆个数交换,依次类推4、堆排序以升序排序为例,利⽤⼩根堆的性质(堆顶元素最⼩)不断输出最⼩元素,直到堆中没有元素1.构建⼩根堆2.输出堆顶元素3.将堆低元素放⼀个到堆顶,再重新构造成⼩根堆,再输出堆顶元素,以此类推5、冒泡排序改进1:如果某次冒泡不存在数据交换,则说明已经排序好了,可以直接退出排序改进2:头尾进⾏冒泡,每次把最⼤的沉底,最⼩的浮上去,两边往中间靠16、快速排序选择⼀个基准元素,⽐基准元素⼩的放基准元素的前⾯,⽐基准元素⼤的放基准元素的后⾯,这种动作叫分区,每次分区都把⼀个数列分成了两部分,每次分区都使得⼀个数字有序,然后将基准元素前⾯部分和后⾯部分继续分区,⼀直分区直到分区的区间中只有⼀个元素的时候,⼀个元素的序列肯定是有序的嘛,所以最后⼀个升序的序列就完成啦。
数据结构课程设报告—各种排序算法的比较

数据结构课程设计报告几种排序算法的演示1、需求分析:运行环境:Microsoft Visual Studio 20052、程序实现功能:3、通过用户键入的数据, 经过程序进行排序, 最后给予数据由小到大的输出。
排序的方式包含教材中所介绍的几种常用的排序方式:直接插入排序、折半插入排序、冒泡排序、快速排序、选择排序、堆排序、归并排序。
每种排序过程中均显示每一趟排序的细节。
程序的输入:输入所需排序方式的序号。
输入排序的数据的个数。
输入具体的数据元素。
程序的输出:输出排序每一趟的结果, 及最后排序结果1、设计说明:算法设计思想:a交换排序(冒泡排序、快速排序)交换排序的基本思想是: 对排序表中的数据元素按关键字进行两两比较, 如果发生逆序(即排列顺序与排序后的次序正好相反), 则两者交换位置, 直到所有数据元素都排好序为止。
b插入排序(直接插入排序、折半插入排序)插入排序的基本思想是: 每一次设法把一个数据元素插入到已经排序的部分序列的合适位置, 使得插入后的序列仍然是有序的。
开始时建立一个初始的有序序列, 它只包含一个数据元素。
然后, 从这个初始序列出发不断插入数据元素, 直到最后一个数据元素插到有序序列后, 整个排序工作就完成了。
c选择排序(简单选择排序、堆排序)选择排序的基本思想是: 第一趟在有n个数据元素的排序表中选出关键字最小的数据元素, 然后在剩下的n-1个数据元素中再选出关键字最小(整个数据表中次小)的数据元素, 依次重复, 每一趟(例如第i趟, i=1, …, n-1)总是在当前剩下的n-i+1个待排序数据元素中选出关键字最小的数据元素, 作为有序数据元素序列的第i个数据元素。
等到第n-1趟选择结束, 待排序数据元素仅剩下一个时就不用再选了, 按选出的先后次序所得到的数据元素序列即为有序序列, 排序即告完成。
d归并排序(两路归并排序)1、两路归并排序的基本思想是: 假设初始排序表有n个数据元素, 首先把它看成是长度为1的首尾相接的n个有序子表(以后称它们为归并项), 先做两两归并, 得n/2上取整个长度为2的归并项(如果n为奇数, 则最后一个归并项的长度为1);再做两两归并, ……, 如此重复, 最后得到一个长度为n的有序序列。
c语言数组排序由大到小

c语言数组排序由大到小C语言数组排序由大到小在C语言中,数组是一种非常常见且重要的数据结构,用于存储一系列相同类型的数据。
而对数组进行排序操作是程序设计中的常见需求之一。
本篇文章将介绍如何使用C语言对数组进行排序,具体而言是由大到小的排序。
排序是将一组数据按照一定的规则重新排列的过程,可以按照升序或降序的方式进行。
而本文将以降序排序为例,即将数组中的元素从大到小进行排列。
我们需要了解一下C语言中的排序算法。
常见的排序算法有冒泡排序、选择排序、插入排序、快速排序等。
在这里,我们将使用冒泡排序算法对数组进行降序排序。
冒泡排序是一种简单直观的比较交换排序算法。
其基本思想是通过相邻元素的比较和交换,将较大的元素逐渐“冒泡”到数组的末尾。
具体实现如下:```cvoid bubbleSort(int arr[], int n) {for (int i = 0; i < n - 1; i++) {for (int j = 0; j < n - 1 - i; j++) {if (arr[j] < arr[j + 1]) {int temp = arr[j];arr[j] = arr[j + 1];arr[j + 1] = temp;}}}}```以上是冒泡排序算法的C语言实现。
其中,arr为待排序的数组,n 为数组的长度。
通过嵌套的for循环,依次比较相邻的两个元素,如果前者大于后者,则进行交换。
通过多次遍历,将最大的元素逐渐交换到数组的末尾,从而实现降序排序。
接下来,我们可以编写一个简单的程序来测试这个排序算法。
```c#include <stdio.h>void bubbleSort(int arr[], int n);int main() {int arr[] = {9, 5, 7, 3, 1};int n = sizeof(arr) / sizeof(arr[0]);bubbleSort(arr, n);printf("排序后的数组:");for (int i = 0; i < n; i++) {printf("%d ", arr[i]);}return 0;}```在这个程序中,我们首先定义了一个包含5个整数的数组arr,并计算了数组的长度n。
数据结构c语言版课程设计
数据结构c语言版课程设计数据结构是计算机科学中的一个重要概念,它研究数据的组织、存储和管理方式,以及数据之间的关系和操作。
在C语言中,数据结构是通过各种不同的数据类型和数据结构来实现的。
本文将以数据结构C语言版课程设计为标题,介绍数据结构在C语言中的基本概念、常用数据结构及其实现,并结合实例进行说明。
一、引言数据结构是计算机科学的基础,它为我们处理和管理数据提供了重要的支持。
C语言作为一种高效、灵活的编程语言,广泛应用于系统开发、嵌入式程序和算法实现等领域。
掌握C语言中的数据结构是每个程序员必备的基本功。
二、基本概念1. 数据类型在C语言中,数据类型是指数据的种类和对应的操作。
常见的数据类型包括整型、浮点型、字符型等。
数据类型的选择要根据实际需求进行,以提高程序的效率和可读性。
2. 变量变量是存储数据的基本单元,通过变量名来访问其中的数据。
在C 语言中,变量必须先定义后使用,定义变量时需要指定其数据类型。
3. 数组数组是一种存储相同类型数据的集合。
在C语言中,数组的声明需要指定数组的大小,可以通过下标来访问数组中的元素。
数组的大小是固定的,一旦定义就不能改变。
4. 结构体结构体是一种自定义的数据类型,可以将不同类型的数据组合在一起。
在C语言中,结构体的定义使用关键字"struct",通过"."操作符来访问结构体成员。
三、常用数据结构1. 链表链表是一种动态数据结构,它通过指针将不同的节点连接起来。
每个节点包含数据和指向下一个节点的指针。
链表的插入和删除操作比较灵活,但查找元素的效率比较低。
2. 栈栈是一种后进先出(LIFO)的数据结构,只能在栈顶进行插入和删除操作。
在C语言中,可以使用数组或链表来实现栈。
3. 队列队列是一种先进先出(FIFO)的数据结构,只能在队尾插入元素,在队头删除元素。
在C语言中,可以使用数组或链表来实现队列。
4. 树树是一种分层结构的数据结构,由节点和边组成。
数据结构(C语言版)实验报告 (内部排序算法比较)
《数据结构与算法》实验报告一、需求分析问题描述:在教科书中,各种内部排序算法的时间复杂度分析结果只给出了算法执行时间的阶,或大概执行时间。
试通过随机数据比较各算法的关键字比较次数和关键字移动次数,以取得直观感受。
基本要求:(l)对以下6种常用的内部排序算法进行比较:起泡排序、直接插入排序、简单选择排序、快速排序、希尔排序、堆排序。
(2)待排序表的表长不小于100000;其中的数据要用伪随机数程序产生;至少要用5组不同的输入数据作比较;比较的指标为有关键字参加的比较次数和关键字的移动次数(关键字交换计为3次移动)。
(3)最后要对结果作简单分析,包括对各组数据得出结果波动大小的解释。
数据测试:二.概要设计1.程序所需的抽象数据类型的定义:typedef int BOOL; //说明BOOL是int的别名typedef struct StudentData { int num; //存放关键字}Data; typedef struct LinkList { int Length; //数组长度Data Record[MAXSIZE]; //用数组存放所有的随机数} LinkList int RandArray[MAXSIZE]; //定义长度为MAXSIZE的随机数组void RandomNum() //随机生成函数void InitLinkList(LinkList* L) //初始化链表BOOL LT(int i, int j,int* CmpNum) //比较i和j 的大小void Display(LinkList* L) //显示输出函数void ShellSort(LinkList* L, int dlta[], int t,int* CmpNum, int* ChgNum) //希尔排序void QuickSort (LinkList* L, int* CmpNum, int* ChgNum) //快速排序void HeapSort (LinkList* L, int* CmpNum, int* ChgNum) //堆排序void BubbleSort(LinkList* L, int* CmpNum, int* ChgNum) //冒泡排序void SelSort(LinkList* L, int* CmpNum, int* ChgNum) //选择排序void Compare(LinkList* L,int* CmpNum, int* ChgNum) //比较所有排序2 .各程序模块之间的层次(调用)关系:二、详细设计typedef int BOOL; //定义标识符关键字BOOL别名为int typedef struct StudentData //记录数据类型{int num; //定义关键字类型}Data; //排序的记录数据类型定义typedef struct LinkList //记录线性表{int Length; //定义表长Data Record[MAXSIZE]; //表长记录最大值}LinkList; //排序的记录线性表类型定义int RandArray[MAXSIZE]; //定义随机数组类型及最大值/******************随机生成函数********************/void RandomNum(){int i; srand((int)time(NULL)); //用伪随机数程序产生伪随机数for(i=0; i小于MAXSIZE; i++) RandArray[i]<=(int)rand(); 返回;}/*****************初始化链表**********************/void InitLinkList(LinkList* L) //初始化链表{int i;memset(L,0,sizeof(LinkList));RandomNum();for(i=0; i小于<MAXSIZE; i++)L->Record[i].num<=RandArray[i]; L->Length<=i;}BOOL LT(int i, int j,int* CmpNum){(*CmpNum)++; 若i<j) 则返回TRUE; 否则返回FALSE;}void Display(LinkList* L){FILE* f; //定义一个文件指针f int i;若打开文件的指令不为空则//通过文件指针f打开文件为条件判断{ //是否应该打开文件输出“can't open file”;exit(0); }for (i=0; i小于L->Length; i++)fprintf(f,"%d\n",L->Record[i].num);通过文件指针f关闭文件;三、调试分析1.调试过程中遇到的问题及经验体会:在本次程序的编写和调试过程中,我曾多次修改代码,并根据调试显示的界面一次次调整代码。
数据结构课程设计-学生-21个题目
选题一:迷宫与栈问题【问题描述】以一个mXn的长方阵表示迷宫,0和1分别表示迷宫中的通路和障碍。
设计一个程序,对任意设定的迷宫,求出一条从入口到出口的通路,或得出没有通路的结论。
【任务要求】1)首先实现一个以链表作存储结构的栈类型,然后编写一个求解迷宫的非递归程序。
求得的通路以三元组(i,j,d)的形式输出。
其中:(i,j)指示迷宫中的一个坐标,d表示走到下一坐标的方向。
如,对于下列数据的迷宫,输出一条通路为:(1,1,1),(1,2,2),(2,2,2),(3,2,3),(3,1,2),…。
2)编写递归形式的算法,求得迷宫中所有可能的通路。
3)以方阵形式输出迷宫及其通路。
【测试数据】迷宫的测试数据如下:左上角(0,1)为入口,右下角(8,9)为出口。
出口出口选题二:算术表达式与二叉树【问题描述】一个表达式和一棵二叉树之间,存在着自然的对应关系。
写一个程序,实现基于二叉树表示的算术表达式的操作。
【任务要求】假设算术表达式Expression内可以含有变量(a~z)、常量(0~9)和二元运算符(+,-,*,/,^(乘幂))。
实现以下操作:1)ReadExpre(E)—以字符序列的形式输入语法正确的前缀表达式并构造表达式E。
2)WriteExpre(E)—用带括弧的中缀表达式输出表达式E。
3)Assign(V,c)—实现对变量V的赋值(V=c),变量的初值为0。
4)Value(E)—对算术表达式E求值。
5)CompoundExpr(P,E1,E2)--构造一个新的复合表达式(E1)P(E2)【测试数据】1)分别输入0;a;-91;+a*bc;+*5^x2*8x;+++*3^x3*2^x2x6并输出。
2)每当输入一个表达式后,对其中的变量赋值,然后对表达式求值。
选题三:银行业务模拟与离散事件模拟【问题描述】假设某银行有4个窗口对外接待客户,从早晨银行开门(开门9:00am,关门5:00pm)起不断有客户进入银行。
c语言排序方法
c语言排序方法C语言是一种高效的编程语言,其基础算法和数据结构内容是必备的知识。
排序算法是其中一种重要的基础算法,是C语言程序开发中常用的一种技能,可以帮助我们对数据进行有序处理,更好地解决问题。
在C语言中,排序算法分为内部排序和外部排序。
内部排序是指将需要排序的数据都放在内存中进行排序,主要适用于数据量较小的情况。
而外部排序则是指需要对大数据集进行排序,需要借助外部存储器进行排序。
在此我们主要讨论内部排序算法。
内部排序可以分为以下几类:1. 插入排序插入排序包括直接插入排序、希尔排序等。
直接插入排序是将一个记录插入到有序表中形成一个新的有序表;而希尔排序是通过缩小元素间的间隔,并对每个子序列分别进行插入排序来完成整个排序过程。
插入排序方法简单,适用于小数组或部分有序的数组,是稳定排序方法。
2. 选择排序选择排序包括简单选择排序、堆排序等。
简单选择排序是通过不断的在剩余元素中找到最小元素,并将其放在已排好序的数组末尾进行排序,是不稳定排序方法;而堆排序则是通过将待排序数组看作一个完全二叉树,不断将根节点放到其正确位置上进行排序,是不稳定排序方法。
3. 交换排序交换排序包括冒泡排序、快速排序等。
冒泡排序是通过不断比较相邻的两个数,将较小(或较大)数向前(或向后)交换,在每一次外循环中确定一个元素的位置的排序方法,是稳定排序方法;而快速排序则是通过不断地将待排序数组分成两部分,分别进行递归排序,再将两部分合并成一个有序的数组,是不稳定排序方法。
4. 合并排序合并排序是将待排序数组分成若干个子数组,将每个子数组排好序,再将排好序的子数组合并成最终有序的数组。
合并排序是稳定排序方法,主要优化点在于合并有序数组的过程中需要有额外的空间存放有序的数据。
在实际开发中,我们需要选择适合当前情况的排序方法,优化算法的实现,提高算法的效率。
另外,在使用排序算法的过程中,我们还需要注意以下几点:1. 数据量的大小决定了排序算法的选择。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
`
课题:内部排序算法比较…
第一章问题描述
排序是数据结构中重要的一个部分,也是在实际开发中易遇到的问题,所以研究各种排算法的时间消耗对于在实际应用当中很有必要通过分析实际结合算法的特性进行选择和使用哪种算法可以使实际问题得到更好更充分的解决!该系统通过对各种内部排序算法如直接插入排序,冒泡排序,简单选择排序,快速排序,希尔排序,堆排序、二路归并排序等,以关键码的比较次数和移动次数分析其特点,并进行比较,估算每种算法的时间消耗,从而比较各种算法的优劣和使用情况!排序表的数据是多种不同的情况,如随机产生数据、极端的数据如已是正序或逆序数据。
比较的结果用一个直方图表示。
第二章系统分析
界面的设计如图所示:
!
|******************************|
|-------欢迎使用---------|
|-----(1)随机取数-------|
|-----(2)自行输入-------|
|-----(0)退出使用-------|
|******************************|
~
请选择操作方式:
如上图所示该系统的功能有:
(1):选择 1 时系统由客户输入要进行测试的元素个数由电脑随机选取数字进行各种排序结果得到准确的比较和移动次数并打印出结果。
(2)选择 2 时系统由客户自己输入要进行测试的元素进行各种排序结果得到准确的比较和移动次数并打印出结果。
(3)选择0 打印“谢谢使用!!”退出系统的使用!!
、
第三章系统设计
(I)友好的人机界面设计:(如图所示)
|******************************|
|-------欢迎使用---------|
|-----(1)随机取数-------|
|-----(2)自行输入-------|
|-----(0)退出使用-------|
|******************************|
:
()
(II)方便快捷的操作:用户只需要根据不同的需要在界面上输入系统提醒的操作形式直接进行相应的操作方式即可!如图(所示)
|******************************|
|-------欢迎使用---------|
|-----(1)随机取数-------|
|-----(2)自行输入-------|
|-----(0)退出使用-------|
|******************************|
;
请选择操作方式:(用户在此输入操作方式)
()
(III)系统采用定义结构体数组来存储数据。
(IV)功能介绍:
(1)操作功能:a .当用户选择随即电脑随机取数时
系统将弹出——>请输入你要输入的个数:(用户在此输入要电脑取数的个
数)要是用户输入的数据过大系统将提醒错误——>超出范围重新输入!!!
b . .当用户选择自行输入时
系统将弹出——>请输入你要输入的个数(不大于于30的整数):
[
当用户输完元素的个数之后系统将提示用户依次输入各个元素。
——>请输入各个元素:
(2)排序功能:系统有简单选择排序,冒泡排序,堆排序,二路归并排序,快速
排序的功能。
(3)打印清晰:系统会打印出在排序操作之前电脑随机取数或者用户输入的原始排列顺序;并将排序操作之后的有序数据打印在原始数据的下面以便用户的
对比。
在排序操作结束之后系统将以直方图的形式打出排序过程中比较和移
动次数让客户一目了然地看到排序的结果:
第四章系统实现
(一)定义结构体数组:
~
typedef struct
{ int key;
} datatype;
datatype R[MAXNUM];ey<R[i-1].key)
{R[0]=R[i]; mn[0]++;
for(j=i-1; R[0].key<R[j].key; j--)
R[j+1]=R[j];
R[j+1]=R[0]; mn[0]+=2;
}
}
}
}
(三)简单选择排序:
void Select_Sort(datatype R[ ],int n)ey<R[k].key) '
k=j;
}
if (i=k)
{ R[0]=R[k];
R[k]=R[i];
R[i]=R[0]; mn[1]+=3; }
}
!
}
(四)冒泡排序:
void Bubble_Sort (datatype R[ ], int n)ey<R[j+1].key) {R[0]=R[j];
R[j]=R[j+1];
R[j+1]=R[0]; mn[2]+=3;
swap=1;
《
}}
if(swap==0) break;
}
}
~
(五)堆排序:
void HeapAdjust(datatype R[ ], int s, int t)
{
datatype rc;
int i,j ;
rc=R[s];
i=s;
for(j=2*i; j<=t; j=2*j)
^
{ cn[3]++;
if(j<t && R[j].key<R[j+1].key)j=j+1;
if > R[j].key) break;
R[i]=R[j]; mn[3]++;
i=j;
}
R[i]=rc;
(
}
void HeapSort(datatype R[ ], int n)ey<R[j].key)
{ R1[k++]=R[i++]; mn[4]++;}
else
{ R1[k++]=R[j++]; mn[4]++;}
}
while (i<=m) { R1[k++]=R[i++]; mn[4]++; }
while (j<=t) { R1[k++]=R[j++]; mn[4]++;}
,
}
void MSort(datatype R[ ], datatype R1[ ], int s, int t) {
int m;
if(s==t) { R1[s]=R[s]; mn[4]++;}
else {m=(s+t)/2;
MSort(R, R1, s, m);
MSort(R, R1, m+1, t);
(
Merge(R1, R, s, m, t);
}
}
void MergeSort(datatype R[ ], datatype R1[ ], int n)ey>=R[0].key) {cn[5]++; high--;}
if(low<high) { R[low]=R[high]; low++; mn[5]++; }
while(low<high&&R[low].key<R[0].key) { mn[5]++; low++; }
,
if(low<high) {R[high]=R[low]; high--; mn[5]++; }
}
R[low]=R[0]; mn[5]++;
return low;
}
(七)快速排序:
void Quick_Sort(datatype R[ ], int s, int t)ey);
<
printf("\n");
D_InsertSort(R,n);ey);
printf("排序前元素顺序为:");
for(i=1;i<n+1;i++) printf("%d ",R1[i].key);
printf("\n");
D_InsertSort(R1,n);
'
@
作者:张晓莉王苗《数据结构与算法》机械工业出版社 2008年7月
2. 作者:杨升《数据结构》厦门大学出版社 2009年6月
教师评语和成绩
2010 年 6 月。