汇编语言学习笔记
DSP汇编指令学习笔记

Knowledge问题谁在DSP的汇编语言中加入了NOP指令?NOP指令加入的条件是什么?About DSP1.DSP是实时数字信号处理的核心和标志。
2.DSP分为专用和通用两种类型。
专用DSP一般采用定点数据结构(一般不支持小数),数据结构简单,处理速度快;通用DSP灵活性好,但是处理速度有所降低。
3.DSP采用取指、译码、执行三个阶段的流水线(Pipeline)技术,缩短了执行时间,提高了运行速率。
DSP具有8个Functional unit,如果并行处理的话,以600MHz的时钟计算,如果执行的指令是single cycle指令,则可以4800MIPS(指令每秒)。
4.DSP的8个functional Unit,具有独特的功能,对滤波、矩阵运算、FFT(傅里叶变换)具有哈弗结构把指令空间与数据空间隔离的存储方式。
这样实现是为了实现指令的连续读取,而实现pipeline流水线结构。
传统哈弗结构:两个独立的存储空间,还使用独立总线。
让取指与执行存储独立,加快执行速度。
改进型哈弗结构:指令与数据的存储空间还是独立的。
但是使用公共的总线(地址总线与数据总线)。
这样实现的原因是因为出现了CACHE,数据的存储动作大部分被内部的CACHE 总线承接了,所以总线冲突的情况会大大减少。
同时让总线的结构与控制变得简单,CACHE 存储的速度也明显快于外设存储器。
冯诺依曼结构:是指令空间与数据空间共享的存放方式。
它不能实现pipeline的执行过程。
Pipeline(流水线)技术是把指令的取指-译码和指令的执行独立开来的技术。
虽然每条指令的过程还是要经过取指-译码-执行三个阶段最少3个CPU Cycle。
但是多个指令同时并行先后进行,保证总体的指令吞吐速率理想情况下可以保证在每个指令只要一个CPU CYCLE。
Pipeline技术必须要有哈弗结构支持,即必须把指令空间与数据空间隔离存放。
流水线阻断流水线中阻断现象也十分普遍,下面就各种阻断情况下的流水线性能进行详细分析。
《汇编语言》学习笔记6——伪指令

《汇编语⾔》学习笔记6——伪指令1.伪指令⼜称伪操作,即不能像汇编指令⼀样⽣成可执⾏的⼆进制机器代码,⽽是在汇编程序对汇编语⾔源程序进⾏汇编(编译)期间,由汇编程序执⾏。
它与C中的说明性语⾔的含义类似,起到说明作⽤,⽤来指出程序分段、数据定义、存储分配、程序开始和结束等信息,这些信息在汇编(编译)完成后就不⽤了。
但程序中没伪指令,则系统就⽆法完成编译。
2.段定义伪指令:⽤来定义各种类型的段 1.格式:段名 SEGMENT [类型参数] ...... 段名 ENDS 1.其中SEGMENT和ENDS必须成对出现,表⽰段的开始和结束。
⼀般的,段名和段的意义⼀致,便于识别。
2.段名实际就是段地址,在汇编过程中,系统给出具体的地址值,⼀个段必须有⼀个名字来标识。
3.参数是可选项(可有可⽆),⽤于指出段的边界、段的组合、类别标识,⼀般⽤于多模块程序设计中。
2.类型参数 1.定位类型 PARA 该段的起始地址必须为⼩段的⾸地址,即起始地址的16进制数最低位为0 BYTE 该段可以从任意地址开始 WORD 该段必须从字边界开始,即起始地址为偶数 DWORD 该段必须从双字边界开始,即起始地址的16进制数为最低应为4的倍数 PAGE 该段必须从页边界开始,即起始地址的16进制数最低两位为00(能被256整除) 若不指定定位类型,系统默认为PARA 2.组合类型 PRIVATE 该段为私有段,连接时不与其他同名段合并 PUBLIC 连接时可与其他模块中的同名段按顺序连接成⼀个段 COMMON 表⽰该段与其他模块中的同名段有相同的起始地址,如果连接将产⽣覆盖,连接后段的长度为同名段中的最长者 STACK 表⽰该段为堆栈段 AT 表达式 该段直接定位在表达式指出的位置上 若不指定组合类型,默认为PRIVATE 3.类型标识:在引号中给出段的类型名。
在连接时,类别标识相同的段放在连续的存储区中。
(如:"STACK"⽤啦标识该段为堆栈段) 4.END:结束标记,若碰到伪指令END则停⽌编译3.ASSUME伪指令:⽤于指明段寄存器与段的对应关系 1.格式:ASSUME 段寄存器:段名,[段寄存器:段名,段寄存器:.....]【[]中标识可选项】 2.除了代码段寄存器CS不能⽤MOV指令赋值外,其他段寄存器都可⽤MOV指令进⾏初始化。
第1章汇编语言知识学习基本知识

第1章汇编语⾔知识学习基本知识第1章汇编语⾔基础知识本章介绍学习汇编语⾔程序设计所必须具备的基本知识,主要包括汇编语⾔的基本概念及计算机中数据的表⽰⽅法。
通过本章的学习,读者应能了解汇编语⾔概念及其使⽤的进位计数制、不同进位计数制之间的转换、计算机编码以及基本数据类型。
本章内容要点:汇编语⾔的概念汇编语⾔的特点不同进位计数制之间的转换计算机编码1.1汇编语⾔概述1.1.1 汇编语⾔基本概念⾃然语⾔是具有特定语⾳和语法等规范的、⽤于⼈类表达思想并实现相互交流的⼯具。
⼈与⼈之间只有使⽤同⼀种语⾔才能进⾏直接交流,否则就必须通过翻译。
要使计算机为⼈类服务,⼈们就必须借助某种⼯具,告诉计算机“做什么”甚⾄“怎么做”,这种⼯具就是程序设计语⾔。
程序设计语⾔通常分为三类:机器语⾔、汇编语⾔和⾼级语⾔。
⽽前两种语⾔与机器密切相关,统称为低级语⾔。
1.机器语⾔机器语⾔是计算机第⼀代语⾔,它全部由0、1代码组成,是能够直接被机器所接受的语⾔,是最底层的计算机语⾔。
机器语⾔不容易记忆,程序编写难度⼤,调试修改繁琐,且不易移植,现在程序员很少⽤。
但机器语⾔执⾏速度最快,它是⼀种⾯向机器的程序设计语⾔。
2.汇编语⾔为了克服机器语⾔难以记忆、表达和阅读的缺点,⼈们采⽤具有⼀定含义的符号作为助忆符,⽤指令助忆符、符号地址等组成的符号指令称为汇编格式指令(或汇编指令)。
例如,⽤ADD表⽰加法指令,SUB表⽰减法指令,MOV表⽰传送指令等。
汇编语⾔是汇编指令集、伪指令集和使⽤它们规则的统称。
伪指令的概念将在第4章介绍。
汇编语⾔⽐机器语⾔直观,容易记忆和理解,⽤汇编语⾔编写的程序也⽐机器语⾔程序易读、易检查、易修改。
对于不同的计算机,针对同⼀问题所编写的汇编语⾔源程序是互不通⽤的。
⽤汇编语⾔编写的程序执⾏效率⽐较⾼,但通⽤性与可移植性仍然⽐较差。
计算机不能直接识别⽤汇编语⾔编写的程序,必须由⼀种专门翻译程序将汇编语⾔程序翻译成机器语⾔程序,计算机才能执⾏。
32位汇编语言学习笔记3leal和算术运算指令

32位汇编语言学习笔记3leal和算术运算指令32位汇编语言学习笔记在学习汇编语言的过程中,我们已经了解了一些基本指令和寄存器的用法。
本文将继续介绍两个重要的指令:leal指令和算术运算指令。
通过深入了解和学习这两个指令,我们将更好地理解和掌握汇编语言编程的技巧和方法。
一、leal指令leal指令用于将一个有效地址(Effective Address,EA)加载到目标操作数中。
它的一般格式为:leal Source, Destination。
在这个指令中,Source表示源操作数,可以是寄存器、内存或立即数。
Destination表示目标操作数,只能是寄存器。
leal指令在源操作数的基础上进行计算,将计算结果存储到目标操作数中。
下面是一些leal指令的示例:1. leal (%eax,%ebx,4), %edx这条指令将地址(%eax + %ebx * 4)的结果存储到%edx寄存器中。
其中,%eax是个基址寄存器,%ebx是个变址寄存器,4表示缩放因子。
2. leal -8(%ebp), %ecx这条指令将地址(%ebp - 8)的结果存储到%ecx寄存器中。
其中,%ebp是个基址寄存器,-8是个偏移量。
需要注意的是,leal指令只能进行地址计算,并将结果存储到目标操作数中,不能进行实际的加载操作。
二、算术运算指令在汇编语言中,算术运算指令主要用于进行数值的计算和操作。
常见的算术运算指令包括add、sub、mul、div等。
这些指令可以对数据寄存器和内存中的数据进行四则运算。
下面是一些常用的算术运算指令及其示例:1. add指令:用于将两个操作数相加,并存储结果到目标操作数中。
一般格式为:add Source, Destination。
示例:add %eax, %ebx这条指令将%eax和%ebx寄存器中的值相加,结果存储到%ebx中。
2. sub指令:用于将第一个操作数减去第二个操作数,并将结果存储到目标操作数中。
汇编语言基础知识
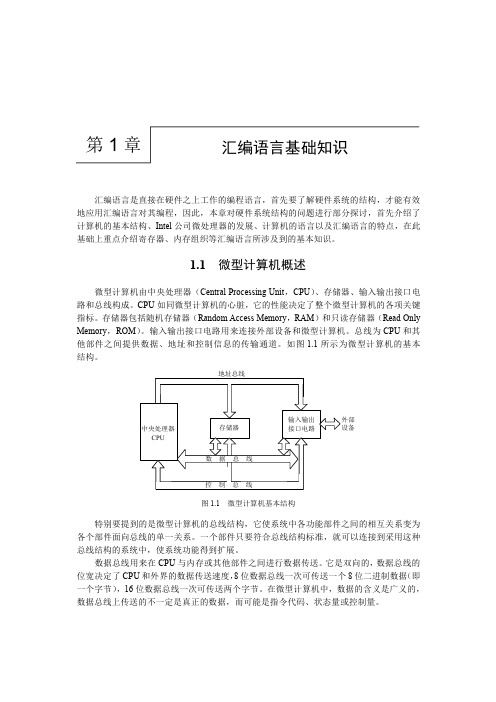
第1章汇编语言基础知识汇编语言是直接在硬件之上工作的编程语言,首先要了解硬件系统的结构,才能有效地应用汇编语言对其编程,因此,本章对硬件系统结构的问题进行部分探讨,首先介绍了计算机的基本结构、Intel公司微处理器的发展、计算机的语言以及汇编语言的特点,在此基础上重点介绍寄存器、内存组织等汇编语言所涉及到的基本知识。
1.1微型计算机概述微型计算机由中央处理器(Central Processing Unit,CPU)、存储器、输入输出接口电路和总线构成。
CPU如同微型计算机的心脏,它的性能决定了整个微型计算机的各项关键指标。
存储器包括随机存储器(Random Access Memory,RAM)和只读存储器(Read Only Memory,ROM)。
输入输出接口电路用来连接外部设备和微型计算机。
总线为CPU和其他部件之间提供数据、地址和控制信息的传输通道。
如图1.1所示为微型计算机的基本结构。
图1.1微型计算机基本结构特别要提到的是微型计算机的总线结构,它使系统中各功能部件之间的相互关系变为各个部件面向总线的单一关系。
一个部件只要符合总线结构标准,就可以连接到采用这种总线结构的系统中,使系统功能得到扩展。
数据总线用来在CPU与内存或其他部件之间进行数据传送。
它是双向的,数据总线的位宽决定了CPU和外界的数据传送速度,8位数据总线一次可传送一个8位二进制数据(即一个字节),16位数据总线一次可传送两个字节。
在微型计算机中,数据的含义是广义的,数据总线上传送的不一定是真正的数据,而可能是指令代码、状态量或控制量。
汇编语言程序设计2地址总线专门用来传送地址信息,它是单向的,地址总线的位数决定了CPU可以直接寻址的内存范围。
如CPU的地址总线的宽度为N,则CPU最多可以寻找2N个内存单元。
控制总线用来传输控制信号,其中包括CPU送往存储器和输入输出接口电路的控制信号,如读信号、写信号和中断响应信号等;也包括其他部件送到CPU的信号,如时钟信号、中断请求信号和准备就绪信号等。
汇编语言学习第4章

不同而不同。
(名字项,常称为标号) 标号是程序设计人员自己定义的表示符号,用来表示本语句的符号地址
(即该指令的偏移地址,也就是该单元与其所处段基址的偏移量)是可有
可无的,只有当需要用符号地址来访问该语句时才需要。 2.operation(操作符)
操作符项可以是指令、伪操作或宏指令的助记符。对于指令,作用是指出
1.等价语句EQU
等价语句的一般使用格式如下: SYMBOL EQU EXPRESSION
作用是用左边的符号名代表右边的表达式。
注意:等价语句不会给符号名分配存储空间,符号名不能与其它符号同名, 也不能被重新定义。
(1)用符号名代表常量或表达式
例4.14 (2)用符号名代表字符串 例4.15 (3)用符号名代表关键字或指令助记符 例4.16
例4.21
2.定义字变量的伪指令为DW
一个变量占一个字空间
例4.22:WORD1 DW DW 89H, 1909H, -1 0ABCDH, ?, 0
上面的定义语句经汇编后所产生出的内存单元分配情况如下:
… 89 00 09 19 FF FF CD AB --00 00 …
例4.23
3.双字变量定义伪指令DD 每个双字变量占用二个连续的字单元(四个字节)。
功能和作用,而不应该只写出指令的动作。
4.2运算符号
4.2.1算术运算符
算术运算符有:+、-、*、/和MOD。 其中: +、-、*、/就是我们算术中常用的加、减、乘、除。 MOD算符是模运算。指除法运算后得到的余数。 例如:5 MOD 2为1。 注意:算术运算符可以用于数字表达式或地址表达式中,但当它用于地址 表达式时,只有当其结果有明确的物理意义时才是有效的。 例如:将两个地址相乘或相除是无意义的。地址可以做加减运算,但也必 须注意物理意义。例如把两个不同段的地址相加减也是无意义的。 例4.1 例4.2
集合知识点总结[汇编]
![集合知识点总结[汇编]](https://img.taocdn.com/s3/m/a3cb041b11661ed9ad51f01dc281e53a59025143.png)
集合知识点总结[汇编]一、汇编语言基础1、汇编语言是一种低级的机器语言,它是由机器指令和操作数构成的。
汇编语言帮助计算机硬件完成如输入/输出操作和内存管理等操作;2、汇编语言与高级语言的最大区别是,汇编语言的执行效率更高,但是在程序的开发上需要更多的努力,需要使用许多汇编指令来实现;3、汇编语言是由一系列指令构成的,指令可以被分为四种:控制指令、储存器操作指令、数据传输指令、计算指令等;4、汇编语言有许多共同的特点,如易于学习,编写简单,可以轻松实现多种操作等;5、汇编语言中有许多指令,如:MOV指令用于对寄存器的操作,ADD指令用于实现二进制数的加法,CMP指令用于实现二进制数的比较等;二、汇编语言的数据类型1、汇编语言的数据类型有无符号数据、有符号数据、比特(bit)、字节(byte)、字(word)、双字(double word)、四字(quad word)等;2、无符号数据是指没有正负号,即汇编语言中只用二进制;3、有符号数据是指含有正负号;4、比特是指由0或1组成的一个二进制数据,也就是最小的数据单位;5、字节是汇编中的一个基本数据单位,由8个比特组成;6、字是汇编中的一个基本数据单位,由16个比特组成;7、双字是汇编中的一个基本数据单位,由32个比特组成;4、四字是汇编中的一个基本数据单位,由64个比特组成。
三、汇编语言指令1、单操作数指令:单操作数指令是指汇编语言中只有一个操作数的指令,如INC、DEC、PUSH、POP等;2、双操作数指令:双操作数指令是指汇编语言中有两个操作数的指令,如MOV、ADD、SUB等;3、控制指令:控制指令是指能实现程序的控制、跳转和循环的指令,如JMP、LOOP、JB、JZ等;4、汇编关键字:汇编关键字是与汇编中的指令和数据有关的一些字,如DB、DW、DD 等;5、立即数指令:立即数指令是指指令的操作数是一个数值而不是地址的指令,如MOV AL,78H等。
汇编语言学习笔记段寄存器

汇编语言学习笔记段寄存器一、CPU 的典型构成•CPU 中有很多部件,但一般最主要的有:寄存器运算器控制器 ,如下图是CPU 的主要结构:CPU 的典型构成.png(1)寄存器: 存东西的,比如我们做加法计算 20 + 30 ,那么数据20 和30 先存在寄存器中,在运算器中计算后再存储到寄存器中.CPU 中的寄存器,运算器等部件通过CPU中的控制器(总线)与外面的内存等其他部件相连.•对于程序员来说,CPU中最主要的部件是寄存器,可以通过改变寄存器的内容来实现对CPU的控制.(汇编学的好不好和寄存器学的好不好直接相关)•不同的CPU,寄存器的个数 \ 结构是不同的,8086 是16位的结构的CPU,但是地址总线是20位,可以访问1M的存储空间.•8086 有14个寄存器(都是16位的寄存器(可以存放2个字节))8086的14个寄存器.png二、通用寄存器•AX BX CX DX 这4个寄存器通常用来存放一般性的数据(eg: int a = 10 , int b =10 ) 称为通用寄存器(有时也有特殊用途).•通常,CPU会先将内存中的数据存储到通用寄存器中,然后在对通用寄存器中的数据进行运算.•假如,内存中有块红色内存空间的值是3,现在想把他加1,并将结果存储到内存中的蓝色内存空间,那么处理流程大致如下:数据操作流程.png1.CPU 首先会将红色内存空间中的值放到 AX 寄存器中(通用寄存器)中,即: movax , 红色内存空间 (将右边边红色内存空间的值存到左边AX 中 )2.然后让AX 寄存器(通用寄存器)与1相加.即: add ax ,1 (将右边的值1,与左边AX中的值相加并将结果存入左边AX中)3.最后将值(结果)赋值给蓝色内存空间.即: mov 蓝色内存空间, AX (将右侧AX中的值移动到左侧蓝色内存中)•AX BX CX DX 这4个通用寄存器都是16位的,可以存储2个字节,如下如: 8086通用寄存器.png•注意: 上一代8086 的寄存器都是8位的,为了保证兼容, AX BX CX DX 都可以分为2个8位的寄存器来使用.如下图:通用寄存器的拆分.png高8位低8位的拆分.png三、字节与字•在汇编的数据存储中,有两个比较常用的单位:字节和字. (相当于高级语言中的 int,long,float等数据类型).因此我们在汇编中只能定义两种数据类型的数据,字节类型(byte类型),字类型(word 类型))字节: byte ,1个byte 由8个bit组成,可以存储在8位寄存器中.字:word,1个字由两个字节组成,这两个字节分别称为字的高字节和低字节. •比如数据20000 (4E20H,01001110 00100000B),高字节值78,低字节值32. 字表示.png•1个字可以存储在一个16位寄存器中,这个字的高字节\低字节分别存储在这个存储器的高8位和低8位寄存器中.四、段寄存器•8086 在访问内存时要由相关部件提供内存单元的段地址和偏移地址送入地址加法器合成物理地址•是什么部件提供段地址? 答:段地址在8086的段寄存器中存放. (段segment )代码段寄存器: CS (code segment) 存放代码的数据段寄存器: DS (datasegment ) 存放数据的堆栈段寄存器: SS (stack segment ) 对象放堆里面,局部对象放栈里面附加段寄存器: ES (Extra segment)8086段寄存器.png•8086 有4个段寄存器,CS DS SS ES,当要访问内存时由这4个段寄存器提供内存单元段地址.•每个段寄存的具体作用是什么呢?一旦程序运行装载到内存当中,所有的代码\全局变量\局部变量\对象都装载到了内存当中,所以内存当中存在具体的代码和数据,也存在堆栈等等 ,那么CPU想访问内存段代码,那么他会访问法代码段寄存器,如果CPU想想问堆栈中的数据那么他会访问栈寄存器,依次类推就是这样的.。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
汇编语言学习笔记《汇编语言》--王爽前言学习汇编目的:充分获得底层编程体验;深刻理解机器运行程序的机理。
原则:没有通过监测点不要向下学习;没有完成当前实验不要向下学习。
第一章基础知识有三类指令组成汇编语言:汇编指令;伪指令;其他符号。
8bit = 1byte = 一个存储单元有n根地址线,则可以寻址2的n次方个内存单元。
1.1节--1.10节小结(1)汇编指令是机器指令的助记符,同机器指令一一对应。
(2)每一种cpu都有自己的汇编指令集。
(3)cpu可以直接使用的信息在存储器中存放。
(4)在存储器中指令和数据没有任何区别,都是二进制信息。
(5)存储单元从零开始顺序编号。
(6)一个存储单元可以存储8个bit,即八位二进制数。
(7)每一个cpu芯片都有许多管脚,这些管脚和总线相连。
也可以说,这些管脚引出总线。
一个cpu可以引出的三种总线的宽度标志了这个cpu不同方面的性能。
地址总线的宽度决定了cpu的寻址能力;数据总线的宽度决定了cpu与其他器件进行数据传送时的一次数据传送量;控制总线的宽度决定了cpu对系统中其他器件的控制能力。
监测点:1KB的存储器有1024个存储单元?存储单元的编号从0到1023.内存地址空间:最终运行程序的是cpu,我们用汇编编程时,必须要从cpu的角度思考问题。
对cpu来讲,系统中的所有存储器中的存储单元都处于一个统一的逻辑存储器中,它的容量受cpu寻址能力的限制。
这个逻辑存储器即是我们所说的内存地址空间。
第二章寄存器(cpu的工作原理)mov ax, 2add ax, axadd ax, axadd ax, ax(1)cpu中的相关部件提供两个16位的地址,一个称为段地址,另一个称为偏移地址;(2)段地址和偏移地址通过内部总线送人一个称为地址加法器的部件;(3)地址加法器将两个16位地址合成为一个20位的物理地址;(4)地址加法器通过内部总线将20位物理地址送人输入输出控制电路;(5)输入输出控制电路将20位物理地址送上地址总线;(6)20位物理地址被地址总线传送到存储器;段地址*16+偏移地址= 物理地址的本质含义内存并没有分段,段的划分来自cpu。
以后编程时可以根据需要,将若干地址连续的内存单元看做一个段,用段地址*16定位段的起始地址,用偏移地址定位段的内存单元。
一个段的起始地址一定是16的倍数,一个段的最大长度为64kB。
当然也没有办法定义一个起始地址不是16的倍数的段。
cpu可以用不同的段地址和偏移地址形成同一物理地址。
在8086cpu加电启动或复位后cs和ip被设置为cs = f000h,ip = ffffh,即ffff0h单元中的指令是8086pc机开机后执行的第一条指令。
(??应该是fffffh吧??)cpu将cs:ip指向的内存单元看做指令。
在cpu中,程序员能够用指令读写的部件只有寄存器,程序员可以通过改变寄存器中的内容实现对cpu的控制。
mov指令称为传送指令,cpu中大部分寄存器的值都可以通过mov指令改变。
除了cs:ip 8086没给他这样的功能。
cs:ip可以用转移指令来改变。
jmpjmp cs:ip 用指令给出的段地址修改cs,偏移地址修改ipjmp 某一寄存器的功能为:用寄存器中的值修改ipjmp ax 含义类似于mov ip,ax段地址在8086pc机的段寄存器存放。
当8086cpu要访问内存时,由段寄存器提供内存单元的段地址。
8086cpu有四个段寄存器,其中cs用来存放指令的段地址。
cs存放指令的段地址,ip存放指令的偏移地址。
8086机中,任意时刻,cpu将cs:ip指向的内容当作指令执行。
8086cpu的工作过程:1.从cs:ip指向内存单元读取指令,读取的指令进入指令缓冲器;2.ip指向下一条指令3.执行8086提供转移指令修改cs:ip的内容debug的使用查看,修改cpu中寄存器的内容:r命令查看内存中的命令:d命令修改内存中的内容:e命令(可以写入数据,指令,在内存中,它们实际上没有区别)将内存中的命令解释为机器指令和相应的汇编指令:u命令执行cs:ip指向的内存单元处的命令:t命令以汇编指令的形式向内存中写入指令:a命令第三章寄存器(内存访问)3.1内存中字的存储高八位存放在高字节中,低八位存放在低字节中3.2DS和【address】3.3字传送3.4MOV ADD SUB3.5数据段3.6栈栈是一种具有特殊的访问方式的存储空间。
它的特殊性就在于,最后进入这个空间的数据,最先出去。
栈有两个基本的操作:入栈和出栈。
栈的这种操作规则被称为:lifo(last in first out,后进先出)。
cpu如何知道10000H--1000fH这段空间被当作栈使用?push pop指令在执行时必须知道哪个单元是栈顶单元,可是如何知道呢?栈顶的段地址存放在ss中,偏移地址存放在sp中。
任意时刻,ss:sp指向栈顶单元。
push和pop指令执行时,cpu从ss和sp中得到栈顶的地址。
入栈时,栈顶从高地址向低地址方向增长。
如何定义一个栈的大小?mov ax, 1000hmov ss, axmov sp, 0010h ;则栈顶为1000f 栈底为10000******************************************mov ax, 1000hmov ds, axmov ax, 2266hmov [0], ax************************mov ax,1000hmov ss, axmov sp, 0002hmov ax, 2266hpush ax栈顶的变化范围最大为:0--ffffh栈的综述(1)8086cpu提供了栈操作机制,方案如下:在ss、sp中存放栈顶的段地址和偏移地址;提供入栈和出栈指令,他们根据ss、sp指示的地址,按照栈的方式访问内存单元。
(2)push指令的执行步骤:1)sp=sp-2;2)向ss:sp指向的字单元送人数据;(3)pop指令的执行步骤:1)从ss:sp指向的字单元中读取数据;2)sp=sp+2(4)任意时刻,ss:sp指向栈顶元素。
(5)8086cpu只记录栈顶,栈空间的大小我们要自己管理。
(6)用栈来暂存以后需要恢复的寄存器的内容时,寄存器出栈的顺序要和入栈的顺序相反。
(7)push、pop指令实质上是一种内存传送指令,注意他们的灵活运用。
一个栈段最大可以设为64k段的综述我们可以将一段内存定义为一个段,用一个段地址指示段,用偏移地址访问段内的单元。
这完全是我们的安排。
用一个段存放代码,即代码段用一个段存放数据,即数据段用一个段当栈,即栈段对于数据段,把段地址放在ds中,用mov,add,sub等访问内存单元的指令时,cpu就将我们定义的数据段内容当做数据来访问;对于代码段,把段地址放在cs:ip中,用mov,add,sub等访问内存单元的指令时,cpu 就将执行我们定义的代码段的指令;对于栈段,把段地址放在ss:sp中,用push pop 等访问内存单元的指令时,cpu就将其当作堆栈来访问;debug的t命令在执行修改器ss的指令时,下一条指令也紧接着被执行了。
3.7栈超界问题8086cpu不保证我们对栈的操作不会超界。
也就是说,8086cpu只知道栈顶在何处而不知道我们安排的栈空间有多大,这点就好像,cpu只知道当前要执行的指令在何处,而不知道要执行的指令有多少。
从这两点我们可以看出cpu的工作机理,它只考虑当前情况:当前的栈在何处,当前要执行的指令是哪一条。
对于超界问题我们可以做到就是小心。
第五章【bx】和loop指令我们完整的描述一个内存单元,需要两种信息:(1)内存单元的地址;(2)内存单元存放数据的类型;inc bx的含义是bx中的内容加一[bx]寄存器bx中所包含的地址中存放的内容[bx]表示一个内存单元,他的偏移地址在bx中。
loop指令执行的时候,要进行两步操作:1;(cx)=(cx)- 1;2;判断cx中的值,不为零则转至标号处执行。
“通常”我们用loop实现循环功能,cx中存放循环次数。
用cx和loop指令相配合实现循环功能的三个要点:(1)再cx中存放循环次数;(2)loop指令中的标号所标识地址要在前面;(3)要循环执行的程序段,要写在标号和loop指令的中间。
在汇编源程序中,数据不能以字母开头。
所以对于大于9fffh的数,均在前面加上0。
mov cx,11s: add ax,axloop sassume cs:codecode segment..mov ax,4c00hint 21hcode endsendffff:6单元是一个字节单元,ax是一个十六位寄存器,数据长度不一样,如何赋值?注意我们说的是“赋值”,就是说,让ax中的数据的值(数据的大小)和ffff:0006单元中的数据的值(数据的大小)相等。
八位数据01h和16位数据0001h的数据长度不一样,但他们的值是相等的。
设ffff:0006单元中的的数据是xxh,若要ax中的值和ffff:0006单元中的值相等,ax中的数据应为00xxh。
所以,若实现ffff:0006单元向ax赋值,我们应该令(ah)=0,(al)=(ffff6H).若希望程序能从cs:0012处执行,可以用g命令。
“g 0012”。
他表示程序执行到0012处。
若希望程序能跳出循环,用p命令5.4 debug和汇编编译器masm对指令的不同处理。
在汇编源程序中,mov al,[0]会被编译器解释成为:mov al,0所以要这样表达:mov bx,0mov al,[bx]或者 mov al,ds:[0]第一,我们在汇编源程序中,如果用指令访问一个内存单元,则在指令中必须用[...]来表示内存单元,如果在[]里用一个常量idata直接给出内存单元的偏移地址,就要在[]的前面显示地给出段地址所在的段寄存器。
第二,如果在[]里用寄存器,比如bx,间接给出内存单元的偏移地址,则段寄存器默认在ds中。
第六章包含多个段的程序程序取得所需段的方法有两种:一是在加载程序的时候为程序分配,再就是程序在执行的过程中向系统申请。
dw的含义是定义字型数据即define word 字型数据间以逗号隔开。
程序运行的时候cs存放代码段的段地址,所以我们可以从cs中得到它们的段地址。
dw定义的数据处于代码段的最开始,所以偏移地址为零。
dw 0123h,5604h,1234hstart :指令end start我们在程序的第一条指令的前面加了一个标号start:并在end的后面再次加入。
end除了通知编译器程序结束外,还可以通知编译器程序的入口在什么地方。
在单任务系统中,可执行文件中的程序执行如下:(1)由其他的程序(debug、command或其他程序)将可执行文件中的程序加载入内存;(2)设置cs:ip指向程序的第一条要执行的指令(即程序的入口),从而使程序得以运行;(3)程序运行结束后,返回到加载者;描述信息可执行文件由描述信息和程序组成,程序来源于源程序中的汇编指令和定义的数据;描述信息则主要是编译连接程序对原程序中相关伪指令进行处理所得到的信息。