非常好的SPSS软件聚类分析功能介绍(修改稿)
SPSS Statistics 19_聚类分析

此外还有中间距离法(Median Clustering)、类内平均法(Within-Groups
Linkage)等
12
2 系统聚类
系统聚类
优点
聚类变量可以是分类或连续型变量; 既可以对变量聚类,也可以对数据点/记录聚类(市场细分一般都是对记录聚类); 一次运行即可得到完整的分类序列;
确定样品间相似的度量
距离度量 相似性度量
确定样本点的聚类数量
实际应用中,一般推荐4-6类(5% < 细分群体占比 < 35%)
对聚类结果进行描述和解释
验证细分方案的可接受性 描述各细分群体(交叉表分析) 市场定位(Positioning)
7
©确定目标消费群体 (Targeting) 2009 SPSS Inc.
分类变量:使用卡方(Chi-square)统计量作为距离指标 连续型变量:一般使用欧式平方距离进行距离度量
© 2009 SPSS Inc.
8
1 聚类分析
使用聚类分析时应关注的一些问题(续):
聚类方法的选择
系统聚类法(Hierarchical Clustering),也称分层聚类法 K-均值聚类法(K-means Clustering),也称快速聚类法 两步聚类法(TwoStep Clustering),一种较智能化的聚类方法
2 系统聚类练习
基本思路:综合考察城市的若干社会、经济发展指标(来源《中国城市统计 年鉴》),譬如
城市化程度 生活质量和收入水平 经济发展水平
采用系统聚类法对城市进行系统、科学的分类
【SPSS数据分析】SPSS聚类分析的软件操作与结果解读
【SPSS数据分析】SPSS聚类分析的软件操作与结果解读
在对数据进行统计分析时,我们会遇到将一些数据进行分类处理的情况,但是又没有明确分类标准,这时候就需要用到SPSS聚类分析。
SPSS聚类分析分为两种:一种为R型聚类,是针对变量进行的聚类分析;另一种为Q型聚类,是针对样本的聚类分析。
下面我们就通过实际案例先来给大家讲解Q型聚类分析。
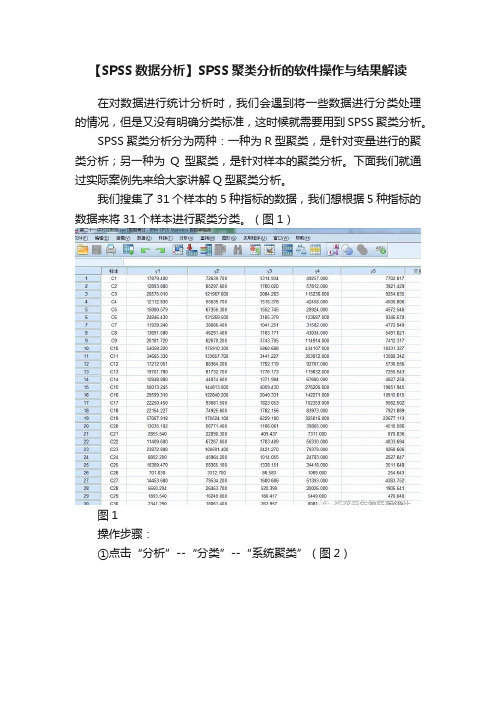
我们搜集了31个样本的5种指标的数据,我们想根据5种指标的数据来将31个样本进行聚类分类。
(图1)
图1
操作步骤:
①点击“分析”--“分类”--“系统聚类”(图2)
图2
③将“样本”选入个案标注依据,将γ1-5选入变量,并勾选下方“个案”标签(图3)
图3
④点击右侧“统计”按钮,将解的范围设置为2-4,意思为分聚为2,3,4类,这里可根据自己分类需求设置(图4)
图4
⑤点击右侧“图”,勾选“谱系图”(图5),点击右侧“方法”,将聚类方法设置为“组间联接”,将区间设置为“平方欧氏距离”(图6)
图5
图6
⑥点击“保存”,将解的范围设置为2-4(图7)
图7
⑦分析结果
图8
由上图(图8)可以看出,第一列为31个样本聚为4类的结果,第二列为31个样本聚为3类的结果,第三列为31个样本聚为2类的结果。
至于冰柱图和谱系图都是用图形化来进一步表达这个些结果,这里就不再赘述,想学习的朋友可以关注我们公众号进行深入学习。
以上就是今天所讲解的SPSS聚类分析的软件操作与分析结果详解,回顾一下重点,Q型聚类是根据变量数据针对样本进行的聚类。
然而还有R型聚类我们将在下一期中进行详细的讲解和分析。
敬请大家的关注!。
SPSS第九章 聚类分析

理解聚类分析的关键是“没有先验知识” 和“亲疏程度”
首先不知道数据到底是来自几个类; 第二不知道每个数据到底是那一类; 第三也不知道类和类的界限是什么; 所谓亲疏程度就是两个数据(变量)综合考 虑各指标后的接近程度;
9.1.2 聚类分析中的“亲疏程度”的度 量方法
数据中,个体之间的亲疏程度是非常重要 的,因为我们正是依靠这种亲疏程度来将 进行类的合并和分化; 亲疏程度的测度一般可以有两个角度:
第一步,指定聚类的数目,假设要分成K类; 第二步,确定类的初始中心;可以有两种方式指定类的 初始中心,可以用户自定义,也可以让系统自己确定; 第三步,根据距离最近原则进行聚类; 重新确定K个类的中心; 判断是否满足停止聚类分析的条件;
9.3.1 K-Means聚类分析的核心步骤
聚类分析终止的条件有两个:
9.2.4 K-Means聚类的应用举例
31个省市自治区小康和现代化指数的KMeans聚类分析,总共包含六个参数:综 合指数、社会结构指数、经济与技术发展 指数、人口素质指数、生活质量指数、法 制与治安指数; 利用Q型聚类进行分析
Initial Cluster Centers 1 79.20 90.40 86.90 65.90 86.50 59.40 Cluster 2 92.30 95.10 92.70 112.00 95.40 57.50 3 51.10 61.90 31.50 56.00 41.00 75.60
Display
Statistics Plots
Statistica...
Plots...
Methods...
Save...
9.2.3 层次聚类的基本操作(续)
SPSS数据分析教程-10 聚类分析

案
例 1 2 3 4 5 6 7 8 9 10 11
号
Model Cavalier Malibu Impala Mustang Taurus Focus Civic Accord Grand Am Corolla Camry
聚 1 3 . 3 2 . 1 2 3 1 2
类
距
离
18.262 13.093 . 18.652 16.338 . 38.008 12.773 6.133 21.783 11.101
10.3 10.4 10.5 10.6
类之间的距离 系统聚类算法过程 系统聚类案例 K-均值聚类
10.6.1 K-均值法简介 10.5.2 K-均值法案例 10.7.1 两步法简介 10.7.2 两步法案例分析
10.7 两步法聚类
10.8 聚类分析注意事项
本章学习目标
类 3 113.369 12.760 21.560 3.8 190 101.3 73.1 183.2 3.203 15.7 24
245.815 10.055 17.885 3.0 155 108.5 73.0 197.6 3.368 16.0 24
案 例 号 1 2 3 4 5 6 7 8 9 10 11
类 3 113.369 12.760 21.560 3.8 190 101.3 73.1 183.2 3.203 15.7 24
245.815 10.055 17.885 3.0 155 108.5 73.0 197.6 3.368 16.0 24
聚 1 Sales in thousands 4-year resale value Price in thousands Engine size Horsepower Wheelbase Width Length Curb weight Fuel capacity Fuel efficiency 145.519 9.250 13.260 2.2 115 104.1 67.9 180.9 2.676 14.3 27 2
spss的聚类分析

• [例]假定我们对A、B、C、D四个样品分别测量 两个变量和得到结果见表:
样品 变量
X1
A B C D 5 -1 1 -3
X2
3 1 -2 -2
• 试将以上的样品聚成两类。K=2
• 第一步:按要求取K=2,为了实施均值法聚类,我们将这些 样品随意分成两类,比如(A、B)和(C、D),然后计算 这两个聚类的中心坐标,
k 1
p
q
1
q
(Block) 当q=1时: d ij (1) x ik x jk ,称为绝对距离
k 1
d ij (2) ( x ik x jk ) ,称为欧氏距离 (Eudidem) 当q=2时:
1 2 k 1
p
2
当q=∞时
d ij () max x ik x kj ,称为切比雪夫距离
Method
j
D1
xi G p
(x x
i xk G p Gq
p
) '( xi x p ), D2
x j Gq
(x
xq ) '( x j xq ),
D1 2
( xk x ) '( xi x ) Dpq D1 2 D1 D2
它的思想来源于方差分析 此外,还有中间距离法、类内平均法等。
聚为一类;
如何衡量这个“相近程度”?就是要根据
“距离”来确定。
这 里 的 距 离 含 义 很 广 , 凡 是 满 足 4 个 条 件
(后面讲)的都是距离,如欧氏距离、马氏距 离…,相似系数也可看作为距离。
距离
距离
什么是距离? 首先我们看
x1p x 2p ,即X x ij n p x n2 x np 设:d j个样品之间的距离 ij表示第i个样品与第 x12 x 22 x11 x 21 X x n1
SPSS软件之聚类分析

1.4 结果分析
从右边的红色直线截取这个图形 的话,我们可以把北京18区分成 了三类,第一类是:西城、宣武、 朝阳、房山;第二类:丰台、通县、 海淀、石景山、东城、崇文、昌 平、大兴、怀柔、密云、门头沟、 延庆;第三类:顺义、平谷。
过渡页
3 1
快速聚类的方法
简介 案例操作 结果分析
2.1 简介
1.3 案例与操作步骤
ห้องสมุดไป่ตู้
对北京地区18区县中等职业教育发展水平进 行聚类。聚类的依据是,x1:每万人中职在 校生数; x2:每万人中职招生数; x3:每万人 中职毕业生数; x4:每万人中职专任教师数; x5:本科以上学校教师占专任教师的比例; x6:高级教师占专任教师的比例数; x7:学校 平均在校生; x8:国家财政预算中职经费占 国内生产总值的比例; x9:生均教育经费;
2.4 结果分析
表明对于x1(每万人中职在校 生数)变量,4个类区县之间存 在着显著的差异
THE END
THANK YOU!
聚类分析
—SPSS数据分析软件
内容
1
聚类分析简介
2 3
层次聚类分析
快速聚类分析
过渡页
1
聚类分析的简介
聚类分析的概念 聚类分析的类型
1.1 聚类分析的概念
所谓聚类分析(Cluster Analysis)是 根据事物本身的特性研究个体分类的方法。 首先将每个样本当作一类,然后根据样 本之间的相似程度并类,并计算新类与 其他类之间的距离,再选择相近者并类, 每合并一次减少一类,继续这一过程, 直到所有样本都并成一类为止。 在聚类分析中,同一类中的个体有较大 的相似性,不同类的个体差异较大。
在大样本的情况下,可以采用快速 聚类分析的方法。快速聚类分析是 由用户指定类别数的大样本资料的 逐步聚类分析。它先对数据进行初 始分类,然后逐步调整,得到最终 分类。 与层次聚类不同:层次聚类可以对 不同的聚类类数产生一系列的聚类 解,而快速聚类只能产生固定类数 的聚类解,类数需要用户事先指定。
SPSS聚类分析详解

1
按就近原则将每个观测量选入一个类中,然后计算各个类的中 心位置,即均值,作为新的聚心。 3、使用计算出来的新聚心重新进行分类,分类完毕后继续计 算各类的中心位置,作为新的聚心,如此反复操作,直到两次 迭代计算的聚心之间距离的最大改变量小于初始聚类心间最小 距离的倍数时,或者到达迭代次数的上限时,停止迭代。
对于任意两个样品Xi和Xj的相似程度可用这两个向量之间 的夹角余弦 Cos ij 来表示: 相似密切
0 Cos Cos 0 1 ij Xi和Xj相重合时,夹角 ij 0 相似程度为
相似程度为 Xi和Xj相互垂直时, ij Cos ij Cos 0 2 2
应用范围有限,要求用户制定分类数目(要告知),只能对 观测量(样本)聚类,而不能对变量聚类,且所使用的聚类变 量必须都是连续性变量。
基本原理
具体做法 1、按照指定的分类数目n,按某种方法选择某些观测量,设为 {Z1,Z2,…Zn},作为初始聚心。 2、计算每个观测量到各个聚心的欧氏距离。即
2 m 2 d ij xi z j xik x jk k 1
2、FASTCLUS对于坐标数据,用K-均值法对观测值进 行逐步聚类,当观测值很多时,则先用FACTCLUS过程 对其进行初步聚类,然后再用CLUSTER过程进行系统 聚类。 3、VARCLUS通过斜交多组分量分析对变量进行系统聚 类或逐步聚类。 4、TREE为CLUSTER或VARCLUS过程产生的输出画 树状图。
3、步骤:1)首先给出度量“相似”或“关系密切”的 统计指标
指标:(1)统计指标是相似系数。 根据相似性归为一类,否则为另一类。 (2)统计指标是样品(空间的点)之间的距离 将距离近的点归成一类,否则为另一类。 (3)相关系数
SPSSAU聚类分析步骤说明

聚类分析聚类分析:聚类分析是通过数据建模简化数据的一种方法。
“物以类聚,人以群分”正是对聚类分析最好的诠释。
一、聚类分析可以分为:对样本进行聚类分析(Q型聚类),此类聚类的代表是K-means聚类方法;对变量(标题)进行聚类分析(R型聚类),此类聚类的代表是分层聚类。
常见为样本聚类,比如有500个人,这500个人可以聚成几个类别。
下面具体阐述对样本进行聚类分析的方法说明(分层聚类将在之后的文章中介绍):聚类分析(Q型聚类)用于将样本进行分类处理,通常是以定量数据作为分类标准。
如果是按样本聚类,则使用SPSSAU的进阶方法模块中的“聚类分析”功能,其会自动识别出应该使用K-means聚类算法还是K-prototype聚类算法。
二、Q型聚类分析的优点:1、可以综合利用多个变量的信息对样本进行分类;2、分类结果是直观的,聚类谱系图非常清楚地表现其数值分类结果;3、聚类分析所得到的结果比传统分类方法更细致、全面、合理。
三、分析思路以下分析思路为对样本进行聚类分析(1)指标归类当研究人员并不完全确定题项应该分为多少个变量,或者研究人员对变量与题项的对应关系并没有充分把握时,可以使用探索性因子分析将各量表题项提取为多个因子(变量),利用提取得到的因子进行后续的聚类分析。
特别提示:分析角度上,通过探索性因子分析,将各量表题项提取为多个因子,提取出的因子可以在后续进行聚类分析。
比如:可先讲20个题做因子分析,并且得到因子得分。
将因子得分在进一步进行聚类分析。
最终聚类得到几个类别群体。
再去对比几个类别群体的差异等。
(2)聚类分析第一步:进行聚类分析设置如果使用探索性因子分析出来的因子进行聚类分析,当提取出五个因子时,应该首先计算此五个因子对应题项的平均分,分别使用平均得分代表此五个因子(比如因子1对应三个题项,则计算此三个题项的平均值去代表因子1),利用计算完成平均得分后得到的因子进行聚类分析。
第二步:结合不同聚类类别人群特征进行类别命名聚类分析完成后,每个类别的样本应该如何称呼,或者每个类别样本的名字是什么,软件并不能进行判断。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第9章SPSS软件的聚类分析功能介绍
1 SPSS软件简介
1.1当前较为流行的统计分析软件包
SPSS(Statistical Package for Social Science)是由美国SPSS公司于20世纪80年代推出的统计分析软件包,分为SPSS/PC(DOS版)和SPSS for Windows(Windows版),是一个适用于社会科学的统计分析软件包,广泛用于教育、心理、经济及科学等领域,是世界上著名的统计分析软件之一。
SAS—Statistical Analysis System,是一个适用于化学、生物、心理以及农、医等学科领域的统计分析软件。
Statgragh—Statistical Graphics,是一个适用于财政、金融等方面的统计分析软件。
Systal_—System Statistical,是一个广泛用于各种统计分析的软件包。
1.2 SPSS软件功能简介
SPSS软件的功能很强大,可以实现数据的输入与编辑、数据的一般性管理、各种统计分析、图形与输出报告等。
其中,统计分析包括常见的统计描述(频次、均值等)、T检验、方差分析、相关分析、回归分析和聚类分析。
此外,SPSS与Excel、Word等有很好的兼容性,可以读取Excel表格数据,也可以将SPSS的结果拷贝到Excel和Word。
但是SPSS软件不是一个独立的文献分析软件,因为它进行聚类分析的基础是共现关系矩阵,需要通过其他途径获得,比如Bibexcel等。
而且SPSS软件做聚类分析时显示的效果不是很理想,数据量应该控制在100以内,否则软件无法进行处理。
SPSS最早的版本是基于DOS系统的,现在已有多个适用于Windows系统的版本,最新版本是SPSS for Windows 20.0。
SPSS for Windows 13.0及以上的版本都可实现聚类分析,本章中采用的是SPSS for Windows 16.0。
SPSS可以读取英文和汉语的数据,也有汉化版本专门分析汉语的数据以免处理过程中出现乱码。
2 SPSS软件的下载与安装
2.1 SPSS软件的下载
SPSS for Windows 16.0的下载地址为::8088/down.asp,,点击“SPSS V16.0”即可下载软件,如图9.1所示。
图9.1 SPSS软件下载界面图将压缩包解压后,如图9.2所示。
图9.2 压缩包解压后的界面图
2.2 SPSS软件的安装
双击解压后的文件夹,出现如图9.3所示的界面。
图9.3双击文件夹后的界面图
需要注意的是,如9.3所示,文件中包含了三个“setup”的图标,这三个图标都不是正确的安装途径,读者若点击其中一个,则会出现9.4所示的错误安装界面。
图9.4点击“setup”后的错误界面
而正确的安装方法是点击图9.3中的“SPSS 16.0”这个图标,如图9.5所示。
图9.5正确的安装界面
需要运行时双击应用程序图标即可,出现如下数据编辑(Data Editor)窗口。
点击“Open an existing data source”就可进入到导入数据界面。
图9.6 数据导入界面
3 SPSS软件的聚类分析方法
3.1 共现关系矩阵的导入
SPSS中能达到聚类分析效果的有分层聚类分析和多维尺度分析两种方法,它们分析的对象都是共现关系矩阵。
本章中用第8章里Bibexcel和Ucient联用获得的文献共现关系矩阵作为分析对象。
第8章3.2中提到当用Ucient打开共现关系矩阵记事本文件,生成.##d和.##h文件的同时,会得到一个output.log1记事本文件。
将记事本中的矩阵拷入一个新的记事本中,再用excel打开该记事本文件,用“Tab”键分隔数据后会得到Excel形式的共现关系矩阵。
为了使文章标题出现在行中,需要转置行与列。
将数据全部选中后,右击任意空白表格处,在弹出的窗口选择“选择性粘贴”。
这里需要读者注意的是,先选择所有数据,然后一定要复制,最好新建一个EXCEL,粘贴后再继续。
如图9.7所示。
图9.7 选择性粘贴界面图
在弹出的窗口中,勾选上“转置”,将共现关系矩阵的行与列转置。
如图9.8所示。
图9.8转置界面图
最后得到下图所示的文献共现关系矩阵的excel数据。
如图9.9所示。
图9.9共现关系矩阵界面图
在选择“Open an existing data source”后,或者点击“File—Open—Data”,就进入到数据导入界面。
在“Files of type”中选择“Excel”,然后再选中数据文件,点击“Open”就导入共现关系矩阵数据了。
如图9.10所示。
图9.10 导入共现关系矩阵数据界面图
接下来,在SPSS软件中选择相应的分析选项,就可以实现用SPSS进行分层聚类分析(Hierarchical Cluster)和多维尺度分析(Multidimensional Scaling)了。
下面将用SPSS16.0软件和10篇关于“Nature of Science”的文献进行示范操作过程。