《多元统计分析》目录2016
《多元统计分析》PPT课件

gi (Y ) 2y1i i1i
将上式中提-2,得
gi
(Y )
2(y
1 i
0.5i1i)
令 fi (Y ) (y1i 0.5i1i)
则距离判别法的判别函数为:
§2 距离判别
(一)马氏距离
距离判别的最直观的想法是计算样品到第i类 总体的平均数的距离,哪个距离最小就将它判 归哪个总体,所以,我们首先考虑的是是否能 够构造一个恰当的距离函数,通过样本与某类 别之间距离的大小,判别其所属类别。
设 x (x1, x2,, xm )和 y ( y1, y2,, ym ) 是从
样本,来检验方法是否稳定的问题。
判类
原类
G1 G2 Gk
G1
G2
合计
Gk
m11
m12
m1k
n1
m21
m22
m2k
n2
mk1
mk 2
mkk
nk
简单错判率:p
1 n
k i 1
k
mij
j 1
ji
加权错判率:
设qi是第i类的先验概率, pi是第i类的错判 概率,则加权错判率为
1 1
1
1 1
)
2y1(1 2 ) (1 2 )1(1 2 )
2[y
(1
2
2
)]1 (1
2
)
令 1 2
2
1(1 2 ) (a1, a2,, ap )
《多元统计分析》课件

采用L1正则化,通过惩罚项来选择最重要 的自变量,实现特征选择和模型简化。
比较
应用场景
岭回归适用于所有自变量都对因变量有影 响的情况,而套索回归更适用于特征选择 和模型压缩。
适用于数据集较大、自变量之间存在多重 共线性的情况,如生物信息学数据分析、 市场细分等。
主成分回归与偏最小二乘回归
主成分回归
适用于自变量之间存在多重 共线性的情况,同时要求高 预测精度,如金融市场预测 、化学计量学等。
06 多元数据的典型相关分析
典型相关分析的基本思想
01
典型相关分析是一种研究多个 随机变量之间相关性的多元统 计分析方法。
02
它通过寻找一对或多个线性组 合,使得这些线性组合之间的 相关性达到最大或最小,从而 揭示多个变量之间的关系。
原理
基于最小二乘法原理,通过最小化预 测值与实际值之间的平方误差来估计 回归系数。
应用场景
适用于因变量与自变量之间存在线性 关系的情况,如预测房价、股票价格 等。
注意事项
需对自变量进行筛选和多重共线性诊 断,以避免模型的不稳定性和误差。
岭回归与套索回归
岭回归
套索回归
是一种用于解决多重共线性的回归方法, 通过引入一个小的正则化项来稳定系数估 计。
层次聚类
01
步骤
02
1. 将每个数据点视为一个独立的集群。
2. 计算任意两个集群之间的距离或相似度。
03
层次聚类
01 3. 将最相近的两个集群合并为一个新的集群。 02 4. 重复步骤2和3,直到满足终止条件(如达到预
设的集群数量或最大距离阈值)。
03 应用:适用于探索性数据分析,帮助研究者了解 数据的分布和结构。
考试科目参考书目录
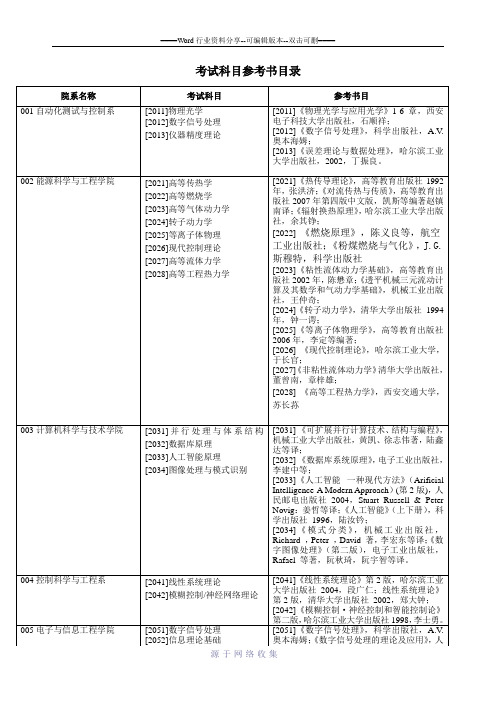
[2101]高级统计学
[2102]高级经济学
[2101]《多元统计分析》,中国人民大学出版社,何晓群;《应用统计》,清华大学出版,陆璇;
[2102]《微观经济学十八讲》,北京大学出版社,2001年第1版,平新乔;《微观经济学:现代观点》,上海人民出版社.2006第6版,哈尔·R.范里安;《宏观经济学》,人民大学出版社:北京.2005年第4版,格里高利•曼昆
[2217]半导体器件物理
[2218]微波技术
[2211]《高等物理光学》中国科技大学出版社杨国光、宋菲军;
[2212]《光学》,北京大学出版社,赵凯华钟锡华;
[2213]《激光物理基础》,哈尔滨工业大学出版社,王雨三等;
[2214]《非线性光学》,西安电子科大出版社,石顺祥等;
[2215]《傅里叶光学引论》,科学出版社,古德曼著;《小波分析与分数傅里叶变换及应用》,国防工业出版社,冉启文,谭立英著;《分数傅里叶光学导论》,科学出版社,冉启文,谭立英著;
012数学系
[2121]泛函分析
[2122]抽象代数
[2123]现代数值分析
[2124]概率论
[2121]《泛函分析》上册,北京大学出版社,张恭庆等;
[2122]《Algebra》,Springer-Verbag,New York,Heidelberg Berlin,T.W.Hungerford;《抽象代数》,东北师范大学出版社,张海权、游宏;
[2085]《微型计算机原理及应用》,哈尔滨工业大学出版社,王承发;《微处理器应用—实时测试与控制》,科学出报社,蔡鹤皋译;
[2086]《车辆动力学与控制》,人民交通出版社2004,喻凡;《汽车系统动力学》,同济大学出版社1996,张洪欣;
《多元统计分析》目录

《多元统计分析》目录前言第一章基本知识﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍5 §1·1总体,个体与样本﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍5 §1·2样本数字特征与统计量﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍6 §1·3一些统计量的分布﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍9 第二章统计推断﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍15 §2·1参数估计﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍15 §2·2假设检验﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍19 第三章方差分析﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍32 §3·1一个因素的方差分析﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍32 §3·2二个因素的方差分析﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍37 §3·3用方差分析进行地层对比﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍44 第四章回归分析﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍49 §4·1概述﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍49 §4·2回归方程的确定﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍49 §4·3相关系数及其显着性检验﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍52 §4·4回归直线的精度﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍55 §4·5多元回归分析﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍56 §4·6应用实例﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍60 第五章逐步回归分析﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍65 §5·1概述﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍65 §5·2“引入”和“剔除”变量的标准﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍66 §5·3矩阵变换法﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍67 §5·4回归系数,复相关系数和剩余标准差的计算﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍69 §5·5逐步回归计算方法﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍70§5·6实例﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍74 第六章趋势面分析﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍80 §6·1概述﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍80 §6·2图解汉趋势面分析﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍81 §6·3计算法趋势面分析﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍83 第七章判别分析﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍90 §7·1概述﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍90 §7·2判别变量的选择﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍91 §7·3判别函数﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍92 §7·4判别方法﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍96 §7·5多类判别分析﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍104 第八章逐步判别分析﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍110 §8·1概述﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍110 §8·2变量的判别能力与“引入”变量的统计量﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍110 §8·3矩阵变换与“剔除”变量的统计量﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍113 §8·4计算步聚与实例﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍115 第九章聚类分析﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍ 125 §9·1概述﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍125 §9·2数据的规格化(标准化)﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍125 §9·3相似性统计量﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍126 §9·4聚类分析方法﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍131 §9·5实例﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍134 §9·6最优分割法﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍134 第十章因子分析﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍142 §10·1概述﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍142 §10·2因子的几何意义﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍143 §10·3因子模型﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍145§10·4初始因子载荷矩阵的求法﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍147 §10·5方差极大旋围﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍152 §10·6计算步聚﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍156 §10·7实例﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍157 附录﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍162 附录1标准正态分布函数量﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍162 附录2正态分布临界值u a表﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍164 附录3t分布临界值t a表﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍165 附录4(a)F分布临界值Fa表(a=0·1)﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍附录4(b)F分布临界值Fa表 (a=0·05) ﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍附表4(c)F分布临界值Fa表(a=0·01)﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍附表5 x2分布临界值xa2表﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍﹍第一章基本知识§1·1总体、个体与样本总体(母体)、个体一(样本点)和样本(子样)是统计分析中常用的名词。
[统计学]多元统计分析(何晓群 中国人民大学)5第五章主成分分析
![[统计学]多元统计分析(何晓群 中国人民大学)5第五章主成分分析](https://img.taocdn.com/s3/m/71b4f5042f60ddccdb38a008.png)
1 μ 2
则上述二元正态分布的密度函数有如下矩阵形式:
2019/1/20
中国人民大学六西格玛质量管理研究中心
16
目录 上页 下页 返回 结束
§5.2 主成分分析的几何意义
1 1 / 2 ( X μ )'Σ 1 ( X μ ) f ( X1, X 2 ) e 1/ 2 2 | Σ |
Y1 X 1 cos X 2 sin Y2 X 1 sin X 2 cos
2019/1/20
中国人民大学六西格玛质量管理研究中心
13
目录 上页 下页 返回 结束
§5.2 主成分分析的几何意义
其矩阵形式为:
Y1 cos Y2 sin sin X1 U X cos X 2
2012318中国人民大学六西格玛质量管理研究中心11目录上页下页返回结束52主成分分析的几何意义由第一节的介绍我们知道在处理涉及多个指标问题的时候为了提高分析的效率可以不直接对个指标构成的随机向量进行分析而是先对向量进行线性变换形成少数几个新的综合变量使得各综合变量之间相互独立且能解释原始变量尽可能多的信息这样在以损失很少部分信息为代价的前提下达到简化数据结构提高分析效率的目的
U 为旋转变换矩阵,由上式可知它是正交阵, 其中, 即满足
U' U1 ,
U 'U I
2019/1/20
中国人民大学六西格玛质量管理研究中心
14
目录 上页 下页 返回 结束
§5.2 主成分分析的几何意义
经过这样的旋转之后,N 个样品点在 Y1 轴上的离散程度最 大,变量 Y1代表了原始数据绝大部分信息,这样,有时在研 究实际问题时,即使不考虑变量 Y2 也无损大局。因此,经过 上述旋转变换就可以把原始数据的信息集中到 Y1 轴上,对数 据中包含的信息起到了浓缩的作用。进行主成分分析的目的 就是找出转换矩阵 U ,而进行主成分分析的作用与几何意义 也就很明了了。下面我们用遵从正态分布的变量进行分析, 以使主成分分析的几何意义更为明显。为方便,我们以二元 正态分布为例。对于多元正态总体的情况,有类似的结论。
《多元统计分析讲义》第四章判别分析

**
**
目录 上页 下页 返回 结束
§4.6 判别分析方法步骤及框 图 研究者首先应该关注被解释变量。被解释变量的组数可以是
两个或更多,但这些组必须具有相互排斥性和完全性。被解 释变量有时确实是定性的变量。然而也有一些情况,即使被 解释变量不是真的定性变量,判别分析也是适用的。我们可 能有一个被解释变量是顺序或者间隔尺度的变量,而要作为 定性变量使用。这种情况下我们可以创建一个定性变量。
*
*
目录 上页 下页 返回 结束
§4.1 判别分析的基本理
论
判别分析的假设之一,是每一个判别变量(解释变量)不 能是其他判别变量的线性组合。即不存在多重共线性问题。 判别分析的假设之二,是各组变量的协方差矩阵相等。判 别分析最简单和最常用的形式是采用线性判别函数,它们 是判别变量的简单线性组合。在各组协方差矩阵相等的假 设条件下,可以使用很简单的公式来计算判别函数和进行 显著性检验。 判别分析的假设之三,是各判别变量之间具有多元正态分 布,即每个变量对于所有其他变量的固定值有正态分布。 在这种条件下可以精确计算显著性检验值和分组归属的概 率。当违背该假设时,计算的概率将非常不准确。
**
目录 上页 下页 返回 结束
§4.3 Bayes判别
**
XXX
**
目录 上页 下页 返回 结束
§4.4 Fisher判别
**
**
目录 上页 下页 返回 结束
§4.4 Fisher判别
**
**
目录 上页 下页 返回 结束
§4.4 Fisher判别
**
**
目录 上页 下页 返回 结束
§4.4 Fisher判别
**
**
多元统计分析之主成分分析(2016)

根据旋转变换的公式:
y1 y2
x1 cos x2 sin x1 sin x2 cos
y1 cos sin x1 Ux y2 sin cos x2
U为旋转变换矩阵,它是正交矩阵,即有
U U1,UU I
k
p
i i
i 1
i 1
来描述,称为累积贡献率。
我们进行主成分分析的目的之一是希望用尽可能少 的主成分F1,F2,…,Fk(k≤p)代替原来的P个指标。 到底应该选择多少个主成分,在实际工作中,主成分 个数的多少取决于能够反映原来变量80%以上的信息量 为依据,即当累积贡献率≥80%时的主成分的个数就足 够了。最常见的情况是主成分为2到3个。
所以 u2u1 0
则,对 p 维向量u2 ,有
V
(F2 )
u2 u2
ip1i u2u i ui u 2
p
i 1
i
(u2ui
)
2
2
p
(u2ui
)2
i2
2 ip1u2uiuiu2 2u2UUu2 2u2u2 2
所以如果取线性变换: F2 u12 X1 u22 X 2 u p2 X p 则 F2的方差次大。
up
)
u21
u22
u2
p
u p1
up2
u
pp
X ( X1, X 2 ,, X p )
§4 主成分的性质
一、均值 E(Ux) U
二、方差为所有特征根之和
p
多元统计分析(数学建模)ppt课件

体现了正相关趋
50
势
年龄
40
30 800
性别
女职工
男职工
900
1000
1100
基本工资
8
绘制散点图
(二)基本操作步骤 (1)菜单选项:graphs->scatter (2)选择散点图类型:
simple:简单散点图(显示一对变量的散点图) overlay:重叠散点图(显示多对变量的散点图)
(3)选择x轴和y轴的变量 (4)选择分组变量(set markers by):分别以不同颜色
2020/6/4
2266
目录 上页 下页 返回 结束
图10-1是一个简单的路径路,A是父亲智商,B是母亲智商, C1、C2是两个成年子女的智商,e1, e2是与A,B不相关的另外原因变 量。一般来说,父母亲的智商之间不存在关系;父母亲的智商对 子女的智商存在因果关系,用单箭头表示,子女的之间,存在相关 关关系,用双箭头表示。箭头上的字母表示路径系数,路径系数反 应原因变量对结果变量的相对影响大小。在路径分析中一般采用
2020/6/4
3300
目录 上页 下页 返回 结束
其他变量(A)对内生变量(B)的影响有两种情况 :若A直接通过单向箭头对B具有因果影响,称A 对B有 直接作用(direct effect);若A 对B的作用是间接地通 过其他变量(C)起作用,称A 对B有间接作用( indirect effect),称C为中间变量(mediator variable) 。变量间的间接作用常常由多种路径最终总合而成。图 10-2中,四个外生变量耐用性、操作的简单性、通话效 果和价格既对忠诚度有直接作用,同时通过感知价值对 忠诚度具有间接作用。
tow-tailed:输出双尾概率P. one-tailed:输出单尾概率P