eviews面板数据模型详解
eviews面板数据模型详解
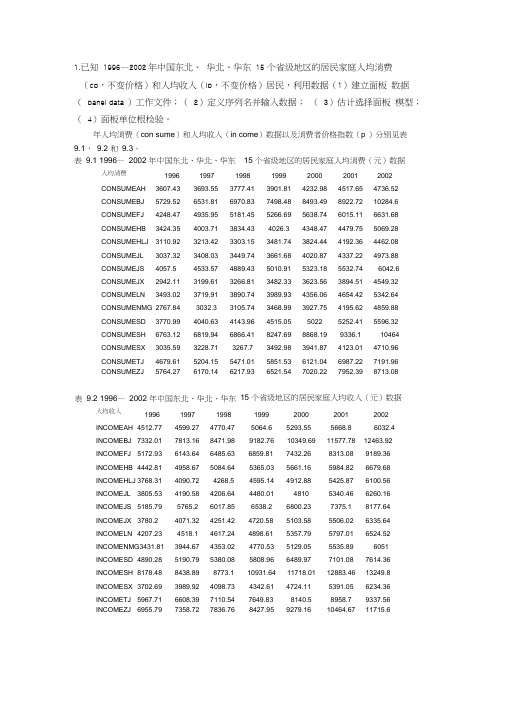
1.已知 1996—2002年中国东北、 华北、华东 15 个省级地区的居民家庭人均消费(cp ,不变价格)和人均收入(ip ,不变价格)居民,利用数据(1)建立面板 数据( panel data )工作文件;( 2)定义序列名并输入数据; ( 3)估计选择面板 模型;( 4)面板单位根检验。
年人均消费(con sume )和人均收入(in come )数据以及消费者价格指数(p )分别见表 9.1, 9.2 和 9.3。
表 9.1 1996— 2002 年中国东北、华北、华东 15 个省级地区的居民家庭人均消费(元)数据人均消费1996 1997 1998 1999 2000 2001 2002 CONSUMEAH 3607.43 3693.55 3777.41 3901.81 4232.98 4517.65 4736.52 CONSUMEBJ 5729.52 6531.81 6970.83 7498.48 8493.49 8922.72 10284.6 CONSUMEFJ 4248.47 4935.95 5181.45 5266.69 5638.74 6015.11 6631.68 CONSUMEHB3424.354003.71 3834.43 4026.3 4348.47 4479.75 5069.28 CONSUMEHLJ 3110.92 3213.42 3303.15 3481.74 3824.44 4192.36 4462.08 CONSUMEJL 3037.32 3408.03 3449.74 3661.68 4020.87 4337.22 4973.88 CONSUMEJS 4057.5 4533.57 4889.43 5010.91 5323.18 5532.74 6042.6 CONSUMEJX 2942.11 3199.61 3266.81 3482.33 3623.56 3894.51 4549.32 CONSUMELN3493.023719.91 3890.74 3989.93 4356.06 4654.42 5342.64 CONSUMENMG 2767.84 3032.3 3105.74 3468.99 3927.75 4195.62 4859.88 CONSUMESD 3770.99 4040.63 4143.96 4515.05 5022 5252.41 5596.32 CONSUMESH 6763.12 6819.94 6866.41 8247.69 8868.19 9336.1 10464 CONSUMESX 3035.59 3228.71 3267.7 3492.98 3941.87 4123.01 4710.96 CONSUMETJ 4679.61 5204.15 5471.01 5851.53 6121.04 6987.22 7191.96 CONSUMEZJ5764.276170.146217.936521.547020.227952.398713.08人均收入1996 1997 1998 1999 2000 2001 2002 INCOMEAH 4512.77 4599.27 4770.47 5064.6 5293.55 5668.86032.4INCOMEBJ 7332.01 7813.16 8471.98 9182.76 10349.69 11577.78 12463.92 INCOMEFJ 5172.93 6143.64 6485.63 6859.81 7432.26 8313.08 9189.36 INCOMEHB 4442.81 4958.67 5084.64 5365.03 5661.16 5984.82 6679.68 INCOMEHLJ 3768.31 4090.72 4268.5 4595.14 4912.88 5425.87 6100.56 INCOMEJL 3805.53 4190.58 4206.64 4480.01 4810 5340.46 6260.16 INCOMEJS 5185.79 5765.2 6017.85 6538.2 6800.23 7375.1 8177.64 INCOMEJX 3780.2 4071.32 4251.42 4720.58 5103.58 5506.02 6335.64 INCOMELN 4207.23 4518.1 4617.24 4898.61 5357.79 5797.01 6524.52 INCOMENMG3431.81 3944.67 4353.02 4770.53 5129.05 5535.89 6051 INCOMESD 4890.28 5190.79 5380.08 5808.96 6489.97 7101.08 7614.36 INCOMESH 8178.48 8438.89 8773.1 10931.64 11718.01 12883.46 13249.8 INCOMESX 3702.69 3989.92 4098.73 4342.61 4724.11 5391.05 6234.36 INCOMETJ 5967.71 6608.39 7110.54 7649.83 8140.5 8958.7 9337.56 INCOMEZJ 6955.797358.727836.768427.959279.1610464.6711715.615 个省级地区的居民家庭人均收入(元)数据表 9.2 1996— 2002 年中国东北、华北、华东< >\ Uinni«d X NewPage -/ 程如下:表9.3 1996 — 2002年中国东北、华北、华东物价指数1996 1997 1998 1999 2000 2001 2002 PAH 109.9 101.3 100 97.8 100.7 100.5 99 PBJ 111.6 105.3 102.4 100.6 103.5 103.1 98.2 PFJ 105.9 101.7 99.7 99.1 102.1 98.7 99.5 PHB 107.1 103.598.4 98.1 99.7 100.5 99 PHLJ 107.1 104.4 100.4 96.8 98.3 100.8 99.3 PJL 107.2 103.7 99.2 98 98.6 101.3 99.5 PJS 109.3 101.7 99.4 98.7 100.1 100.8 99.2 PJX 108.4 102 101 98.6 100.3 99.5 100.1 PLN 107.9 103.1 99.3 98.6 99.9 100 98.9PNMG 107.6 104.5 99.3 99.8 101.3 100.6100.2PSD 109.6 102.8 99.4 99.3 100.2 101.8 99.3 PSH 109.2 102.8 100 101.5 102.5 100 100.5 PSX 107.9 103.1 98.6 99.6 103.9 99.8 98.4 PTJ109 103.1 99.5 98.9 99.6 101.2 99.6 PZJ107.9102.899.798.810199.899.1(1)建立面板数据工作文件首先建立工作文件Tetcli from DB .Update sslectei from DB... Stor* selected to DB... Copy.s^lectedL . selectelFrijit Selected15个省级地区的消费者物价指数Ssntple: E c 回 r@sidGenerate Series. BDisplay Filter *New Obj set...建立面板数据库在窗口中输入15个不同省级地区的标识AH BJ FJHB HLJJL JS JX LNNMG SD SH sx TJ ZJI(2)定义序列名并输入数据产生3*15个尚未输入数据的变量名。
Eviews面板数据之固定效应模型

Eviews 面板数据之固定效应模型在面板数据线性回归模型中,如果对于不同的截面或不同的时间序列,只是模型的截距项是不同的,而模型的斜率系数是相同的,则称此模型为固定效应模型。
固定效应模型分为三类:1.个体固定效应模型个体固定效应模型是对于不同的纵剖面时间序列(个体)只有截距项不同的模型:2Kit i k kit it k y x u λβ==++∑ (1)从时间和个体上看,面板数据回归模型的解释变量对被解释变量的边际影响均是相同的,而且除模型的解释变量之外,影响被解释变量的其他所有(未包括在回归模型或不可观测的)确定性变量的效应只是随个体变化而不随时间变化时。
检验:采用无约束模型和有约束模型的回归残差平方和之比构造F 统计量,以检验设定个体固定效应模型的合理性。
F 模型的零假设:01231:0N H λλλλ-===⋅⋅⋅==()1(1,(1)1)(1)RRSS URSS N F F N N T K URSSNT N K --=---+--+RRSS 是有约束模型(即混合数据回归模型)的残差平方和,URSS 是无约束模型ANCOVA 估计的残差平方和或者LSDV 估计的残差平方和。
实践:一、数据:已知1996—2002年中国东北、华北、华东15个省级地区的居民家庭人均消费(cp ,不变价格)和人均收入(ip ,不变价格)居民,利用数据(1)建立面板数据(panel data)工作文件;(2)定义序列名并输入数据;(3)估计选择面板模型;(4)面板单位根检验。
年人均消费(consume)和人均收入(income)数据以及消费者价格指数(p)分别见表1,2和3。
表1 1996—2002年中国东北、华北、华东15个省级地区的居民家庭人均消费(元)数据表2 1996—2002年中国东北、华北、华东15个省级地区的居民家庭人均收入(元)数据表3 1996—2002年中国东北、华北、华东15个省级地区的消费者物价指数物价指数1996 1997 1998 1999 2000 2001 2002 PAH 109.9 101.3 100 97.8 100.7 100.5 99 PBJ 111.6 105.3 102.4 100.6 103.5 103.1 98.2 PFJ 105.9 101.7 99.7 99.1 102.1 98.7 99.5 PHB 107.1 103.5 98.4 98.1 99.7 100.5 99 PHLJ 107.1 104.4 100.4 96.8 98.3 100.8 99.3 PJL 107.2 103.7 99.2 98 98.6 101.3 99.5 PJS 109.3 101.7 99.4 98.7 100.1 100.8 99.2 PJX 108.4 102 101 98.6 100.3 99.5 100.1 PLN 107.9 103.1 99.3 98.6 99.9 100 98.9 PNMG 107.6 104.5 99.3 99.8 101.3 100.6 100.2 PSD 109.6 102.8 99.4 99.3 100.2 101.8 99.3 PSH 109.2 102.8 100 101.5 102.5 100 100.5 PSX 107.9 103.1 98.6 99.6 103.9 99.8 98.4 PTJ 109 103.1 99.5 98.9 99.6 101.2 99.6 PZJ 107.9 102.8 99.7 98.8 101 99.8 99.1二、1.输入操作:步骤:(1)File——New——Workfile步骤:(2)Start date——End date——OK步骤:(3)Object——New Object步骤:(4)Type of object——Pool步骤:(5)输入所有序列名称步骤:(6)定义各变量点击sheet—输入consume?income?p?步骤:(7)将表1、2、3中的数据复制到Eviews中2.估计操作:步骤:(1)点击poolmodel——Estimate对话框说明Dependent variable:被解释变量;Common:系数相同部分Cross-section specific:截面系数不同部分步骤:(2)将截距项选择区选Fixed effects(固定效应)Cross-section:Fixed得到如下输出结果:接下来用F 统计量检验是应该建立混合回归模型,还是个体固定效应回归模型。
EViews_6[1].0_beta面板数据模型估计,详细!
![EViews_6[1].0_beta面板数据模型估计,详细!](https://img.taocdn.com/s3/m/3e84983910661ed9ad51f3bf.png)
EViews 6.0 beta在面板数据模型估计中的应用来自免费的minixi1、进入工作目录cd d:\nklx3,在指定的路径下工作是一个良好的习惯2、建立面板数据工作文件workfile(1)最好不要选择EViews默认的blanaced panel 类型Moren_panel(2)按照要求建立简单的满足时期周期和长度要求的时期型工作文件3、建立pool对象(1)新建对象(2)选择新建对象类型并命名(3)为新建pool对象设置截面单元的表示名称,在此提示下(Cross Section Identifiers: (Enter identifiers below this line )输入截面单元名称。
,建议采用汉语拼音,例如29个省市区的汉语拼音,建议在拼音名前加一个下划线“_”,如图关闭建立的pool对象,它就出现在当前工作文件中。
4、在pool对象中建立面板数据序列双击pool对象,打开pool对象窗口,在菜单view的下拉项中选择spreedsheet (展开表)在打开的序列列表窗口中输入你要建立的序列名称,如果是面板数据序列必须在序列名后添加“?”。
例如,输入GDP?,在GDP后的?的作用是各个截面单元的占位符,生成了29个省市区的GDP的序列名,即GDP后接截面单元名,再在接时期,就表示出面板数据的3维数据结构(1变量2截面单元3时期)了。
请看工作文件窗口中的序列名。
展开表(类似excel)中等待你输入、贴入数据。
(1)打开编辑(edit)窗口(2)贴入数据(3)关闭pool窗口,赶快存盘见好就收6、在pool窗口对各个序列进行单位根检验选择单位根检验设置单位根检验单位根检验结果注意检验方法和两种检验的零假设:Null: Unit root (assumes common unit root process)各截面有相同的单位根Null: Unit root (assumes individual unit root process)允许各截面有不同单位根其中,Levin, Lin & Chu t*检验拒绝含有单位根的零假设,即拒绝非平稳7、在pool窗口对面板数据组合进行协整检验选择进行协整检验协整检验设置对话框,注意有3种检验方法(test type)协整检验结果,同样要注意两种假定(含有AR,即含有单位根,非协整),两种零假设都是非协整,小概率事件发生拒绝非协整。
EVIEWS面板数据分析操作教程及实例解析

模型选择对分析结果影响
模型适用性
根据研究目的和数据特征选择合 适的面板数据模型,如固定效应 模型、随机效应模型等。
模型假设
确保所选模型满足基本假设,如 线性关系、误差项独立同分布等 ,否则可能导致结果不准确。
模型比较与选择
通过比较不同模型的拟合优度、 参数显著性等指标,选择最优模 型进行分析。
操作规范性与结果可靠性保障措施
操作步骤规范
结果验证与解读
对分析结果进行验证,确保结果的合理性和准确性 ;同时,正确解读分析结果,避免误导读者。
严格按照EVIEWS软件的操作步骤进行分析 ,避免操作失误或遗漏关键步骤。
数据分析报告
编写详细的数据分析报告,包括数据来源、 处理方法、模型选择、分析结果及解读等, 以便读者全面了解分析过程。
方和来估计模型参数。
广义最小二乘法(GLS)
02
当存在异方差性或自相关性时,采用广义最小二乘法进行参数
估计,以提高估计效率。
最大似然法(ML)
03
适用于随机效应模型等复杂面板数据模型,通过最大化似然函
数来估计模型参数。
模型诊断与检验
残差分析
检查残差是否满足独立同分布等假设条件, 以评估模型的拟合效果。
07 EVIEWS面板数 据分析操作注意 事项
数据质量对分析结果影响
数据来源
确保数据来自可靠、权威的来源,避免使用不准确或存在偏见的数 据。
数据完整性
检查数据是否存在缺失值、异常值或重复值,这些问题可能导致分 析结果失真。
数据处理
对数据进行适当的预处理,如清洗、转换和标准化,以提高数据质量 和一致性。
增强了解决实际问题的能力
通过实例解析和操作演示,学员们学会了如何运用所学知识解决实际问题,提高了分析 问题和解决问题的能力。
Eviews面板数据模型估计

4361.555
3890.580 4077.961 5317.862 3612.722 4360.420 3877.345 5011.976 8651.893 3793.908 6145.622
4457.463
4159.087 4281.560 5488.829 3914.080 4654.420 4170.596 5159.538 9336.100 4131.273 6904.368
4571.439 6624.316 4787.606 4968.164 4780.090
4997.843
4878.296 6793.437 5088.315 5363.153 5063.228
5382.808
5271.925 7316.567 5533.688 5797.010 5502.873
6143.565
建立好Pool对象以后,选择View/Spreadsheet (stacked data),EViews会要求输入序列名列表。
大多数情况下,不同截面成员的数据从上到下依次堆积,每一 列代表一个变量,每一列内数据都是按年排列的。如果数据按年排 列,要确保各年内截面成员的排列顺序要一致。
生成新的序列
• 打开原始pool数据,点击工具栏中的poolgenr键,在 弹出的对话框中输入要生成的公式,如: cp?=consume?/p?,ip?=income?/p?
4.如何估计Pool方程
单击Pool工具栏的Estimate选项打开如下对话框:
(1)因变量 在因变量对话框中输入Pool变量或Pool变量表达式。 (2)估计方法 Fixed and Random下: Cross-secti(个体效应)有三个选项,分别表示无、固定和随机个 体效应。 Period(时点效应)有三个选项,分别表示无、有固定和有随机时 点效应。 Weights有五个选项,分别表示无加权、个体的GLS法、个体SUR法、 时点GLS法和时点SUR法。 (3)估计设置 Method有两个选项:LS和TSLS Sample为样本区间。
Eviews:面板数据模型

3个变量:
要创建Pool对象,选择Objects/New Object/Pool…并在编 辑窗口中输入截面成员的识别名称:
对截面成员的识别名称没有特别要求,但必须能使用这 些识别名称建立合法的EViews序列名称。此处推荐在每个识
别名中使用“_”字符,它不是必须的,但把它作为序列名的
一部分,可以很容易找到识别名称。
指标)信息的数据结构称为时间序列/截面数据,有的书 中也称为平行数据或面板数据( panel data )。我们也 称这些数据为联合利用时间序列/截面数据(Pooled time series,cross section)。
经典线性计量经济学模型在分析时只利用了时间序列/截 面数据中的某些二维数据信息,例如使用若干经济指标的时间 序列建模或利用横截面数据建模。然而,在实际经济分析中, 这种仅利用二维信息的模型在很多时候往往不能满足人们分析 问题的需要。例如,在生产函数分析中,仅利用横截面数据只 能对规模经济进行分析,仅利用混有规模经济和技术革新信息 的时间序列数据只有在假设规模收益不变的条件下才能实现技 术革新的分析,而利用时间序列/截面数据可以同时分析企业 的规模经济(选择同一时期的不同规模的企业数据作为样本观 测值)和技术革新(选择同一企业的不同时期的数据作为样本 观测值),可以实现规模经济和技术革新的综合分析。 时间序列/截面数据含有横截面、时间和指标三维信息, 利用时间序列/截面数据模型可以构造和检验比以往单独使用 横截面数据或时间序列数据更为真实的行为方程,可以进行更 加深入的分析。正是基于实际经济分析的需要,作为非经典计 量经济学问题,同时利用横截面和时间序列数据的模型已经成 为近年来计量经济学理论方法的重要发展之一。
(一)创建Pool对象 在本讲中,使用的是一个研究投资需求的例子值的时间序列:
详细的EVIEWS面板数据分析操作

详细的EVIEWS面板数据分析操作引言EVIEWS是一款专业的经济统计软件,广泛应用于经济学和金融领域的数据分析和建模。
EVIEWS提供了丰富的面板数据分析功能,可以帮助用户进行面板数据的处理、描述统计、回归分析等操作。
本文将详细介绍EVIEWS中面板数据分析的操作流程和常用功能。
EVIEWS面板数据的导入首先,我们需要将面板数据导入到EVIEWS中进行分析。
EVIEWS支持多种数据格式的导入,包括Excel、CSV、数据库等。
在导入面板数据时,需要保证数据具有正确的格式,例如面板数据应包含个体(cross-sectional)和时间(time-series)的维度,且面板数据的变量应按照一定的顺序排列。
在导入面板数据后,我们可以利用EVIEWS提供的数据操作命令对数据进行处理和调整。
例如,可以通过group命令将数据按照个体或时间进行分组,通过sort命令对数据进行排序,以便后续的面板数据分析。
面板数据的描述统计分析在面板数据导入并处理完毕后,我们可以进行面板数据的描述统计分析。
EVIEWS提供了丰富的统计功能,可以计算面板数据的平均值、标准差、相关系数等指标。
下面介绍几个常用的描述统计功能:1.summary命令:该命令可以计算面板数据每个变量的平均值、标准差、最大值、最小值等统计指标,并输出到EVIEWS的结果窗口中。
2.correlation命令:该命令可以计算面板数据各变量之间的相关系数矩阵,并输出到结果窗口中。
3.tabulate命令:该命令可以对面板数据进行交叉分组统计,例如计算变量A在变量B的每个取值下的频数和比例。
通过对面板数据进行描述统计分析,可以初步了解数据的分布特征和变量间的关系,为后续的面板数据分析提供基础。
面板数据的回归分析除了描述统计分析,EVIEWS还提供了面板数据的回归分析功能。
通过面板数据回归分析,可以探究变量间的因果关系和影响程度。
下面介绍两个常用的回归分析命令:1.panel least squares(PLS)命令:该命令可以进行面板数据的最小二乘回归分析。
eviews面板数据实例分析(包会)-

eviews面板数据实例分析(包会)-Eviews是一种流行的面板数据分析软件,广泛用于经济学及财务学领域。
本文将以一个面板数据实例为例,介绍Eviews的一些基本功能及应用。
数据说明本数据集为横截面面板数据,共包含11个国家(美国、加拿大、英国、法国、德国、意大利、荷兰、比利时、奥地利、瑞典、日本)在1970年至1986年间的年度数据。
变量说明如下:- gdpercap:人均GDP- invest:投资/GDP比率- consump:消费/GDP比率- inflation:通货膨胀率- popgrowth:人口增长率- literacy:成年人识字率- female:女性劳动力占比数据导入及面板设置首先,在Eviews中新建一个工作文件,并将数据导入。
打开数据文件后,我们可以看到数据已经被正确读入。
然后,我们需要将数据设为面板数据。
在Eviews中,选择“View”菜单下的“Structure of Workfile”选项,可以进入工作文件结构设置。
在弹出的窗口中,选择“Panel Data”选项,并按照数据的属性设置面板变量。
在本例中,我们选择“Country”作为单位维度,“Year”作为时间维度。
设置完成后,Eviews会自动进行面板数据检测。
检测结果显示,数据格式符合面板数据要求。
面板数据描述及汇总统计接下来,我们可以对数据进行初步的描述性统计和汇总统计。
选择“Quick”菜单下的“Descriptive Stats”选项,Eviews会自动生成数据的描述性统计报告,展示各变量在不同国家和不同年份的均值、标准差、最小值、最大值等基本信息。
我们也可以手动计算其他统计量。
例如,选择“Proc”菜单下的“Panel Data”选项,可以对选定的变量进行面板数据汇总统计。
下面是在Eviews中计算人均GDP和消费/GDP比率两个变量的面板均值统计结果:面板数据变量之间的相关性分析在分析面板数据时,我们通常需要考虑不同变量之间的相关性。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1.已知1996—2002年中国东北、华北、华东15个省级地区的居民家庭人均消费(cp,不变价格)和人均收入(ip,不变价格)居民,利用数据(1)建立面板数据(panel data)工作文件;(2)定义序列名并输入数据;(3)估计选择面板模型;(4)面板单位根检验。
年人均消费(consume)和人均收入(income)数据以及消费者价格指数(p)分别见表9.1,9.2和9.3。
表9.1 1996—2002年中国东北、华北、华东15个省级地区的居民家庭人均消费(元)数据人均消费1996 1997 1998 1999 2000 2001 2002CONSUMEAH 3607.43 3693.55 3777.41 3901.81 4232.98 4517.65 4736.52CONSUMEBJ 5729.52 6531.81 6970.83 7498.48 8493.49 8922.72 10284.6CONSUMEFJ 4248.47 4935.95 5181.45 5266.69 5638.74 6015.11 6631.68CONSUMEHB 3424.35 4003.71 3834.43 4026.3 4348.47 4479.75 5069.28CONSUMEHLJ 3110.92 3213.42 3303.15 3481.74 3824.44 4192.36 4462.08CONSUMEJL 3037.32 3408.03 3449.74 3661.68 4020.87 4337.22 4973.88CONSUMEJS 4057.5 4533.57 4889.43 5010.91 5323.18 5532.74 6042.6CONSUMEJX 2942.11 3199.61 3266.81 3482.33 3623.56 3894.51 4549.32CONSUMELN 3493.02 3719.91 3890.74 3989.93 4356.06 4654.42 5342.64CONSUMENMG 2767.84 3032.3 3105.74 3468.99 3927.75 4195.62 4859.88CONSUMESD 3770.99 4040.63 4143.96 4515.05 5022 5252.41 5596.32CONSUMESH 6763.12 6819.94 6866.41 8247.69 8868.19 9336.1 10464CONSUMESX 3035.59 3228.71 3267.7 3492.98 3941.87 4123.01 4710.96CONSUMETJ 4679.61 5204.15 5471.01 5851.53 6121.04 6987.22 7191.96CONSUMEZJ 5764.27 6170.14 6217.93 6521.54 7020.22 7952.39 8713.08表9.2 1996—2002年中国东北、华北、华东15个省级地区的居民家庭人均收入(元)数据人均收入1996 1997 1998 1999 2000 2001 2002INCOMEAH 4512.77 4599.27 4770.47 5064.6 5293.55 5668.8 6032.4INCOMEBJ 7332.01 7813.16 8471.98 9182.76 10349.69 11577.78 12463.92INCOMEFJ 5172.93 6143.64 6485.63 6859.81 7432.26 8313.08 9189.36INCOMEHB 4442.81 4958.67 5084.64 5365.03 5661.16 5984.82 6679.68INCOMEHLJ 3768.31 4090.72 4268.5 4595.14 4912.88 5425.87 6100.56INCOMEJL 3805.53 4190.58 4206.64 4480.01 4810 5340.46 6260.16INCOMEJS 5185.79 5765.2 6017.85 6538.2 6800.23 7375.1 8177.64INCOMEJX 3780.2 4071.32 4251.42 4720.58 5103.58 5506.02 6335.64INCOMELN 4207.23 4518.1 4617.24 4898.61 5357.79 5797.01 6524.52INCOMENMG 3431.81 3944.67 4353.02 4770.53 5129.05 5535.89 6051INCOMESD 4890.28 5190.79 5380.08 5808.96 6489.97 7101.08 7614.36INCOMESH 8178.48 8438.89 8773.1 10931.64 11718.01 12883.46 13249.8INCOMESX 3702.69 3989.92 4098.73 4342.61 4724.11 5391.05 6234.36INCOMETJ 5967.71 6608.39 7110.54 7649.83 8140.5 8958.7 9337.56INCOMEZJ 6955.79 7358.72 7836.76 8427.95 9279.16 10464.67 11715.6表9.3 1996—2002年中国东北、华北、华东15个省级地区的消费者物价指数物价指数1996 1997 1998 1999 2000 2001 2002PAH 109.9 101.3 100 97.8 100.7 100.5 99(1)建立面板数据工作文件首先建立工作文件。
打开工作文件后,过程如下:建立面板数据库。
在窗口中输入15个不同省级地区的标识。
(2)定义序列名并输入数据产生3*15个尚未输入数据的变量名。
这样可以通过键盘输入或黏贴的方法数据数据。
(3)估计、选择面板模型打开一个pool 窗口,先输入变量后缀(所要使用的变量)。
点击Estimate ,打开估计窗口。
A.混合模型的估计方法左边的Common 表示相同系数,即表示不同个体有相同的斜率。
得到如下输出结果: 相应的表达式是:(2.0) (79.7) 20.98,4824588r R SSE ==上式表示15个省级地区的城镇人均指出平均占收入的76%。
B.个体固定效应回归模型的估计方法将截距项选择区选Fixed effects (固定效应) 得到如下输出结果: 相应的表达式为:(6.3) (55) 20.99,2270386r R SSE ==其中虚拟变量1215,,...,D D D 的定义是:15个省级地区的城镇人均指出平均占收入70%。
从上面的结果可以看出北京市居民的自发性消费明显高于其他地区。
接下来用F 统计量检验是应该建立混合回归模型,还是个体固定效应回归模型。
0H :i αα=。
模型中不同个体的截距相同(真实模型为混合回归模型)。
1H :模型中不同个体的截距项i α不同(真实模型为个体固定效应回归模型)。
F 统计量定义为:其中r SSE 表示约束模型,即混合估计模型的残差平方和,u SSE 表示非约束模型,即个体固定效应回归模型的残差平方和。
非约束模型比约束模型多了1N -个被估参数。
PBJ 111.6 105.3 102.4 100.6 103.5 103.1 98.2 PFJ 105.9 101.7 99.7 99.1 102.1 98.7 99.5 PHB 107.1 103.5 98.4 98.1 99.7 100.5 99 PHLJ 107.1 104.4 100.4 96.8 98.3 100.8 99.3 PJL 107.2 103.7 99.2 98 98.6 101.3 99.5 PJS 109.3 101.7 99.4 98.7 100.1 100.8 99.2 PJX 108.4 102 101 98.6 100.3 99.5 100.1 PLN 107.9 103.1 99.3 98.6 99.9 100 98.9 PNMG 107.6 104.5 99.3 99.8 101.3 100.6 100.2 PSD 109.6 102.8 99.4 99.3 100.2 101.8 99.3 PSH 109.2 102.8 100 101.5 102.5 100 100.5 PSX 107.9 103.1 98.6 99.6 103.9 99.8 98.4 PTJ 109 103.1 99.5 98.9 99.6 101.2 99.6 PZJ 107.9 102.8 99.7 98.8 101 99.8 99.1所以本例中:所以推翻原假设,建立个体固定效应回归模型更合理。
C.时点固定效应回归模型的估计方法 将时间选择为固定效应。
得到如下输出结果: 相应的表达式为:(76.6) 20.987,4028843R SSE ==其中虚拟变量127,,...,D D D 的定义是: D.个体随机效应回归模型估计截距项选择Random effects (个体随机效应) 得到如下部分输出结果: 相应的表达式是:(68.5) 20.98,2979246R SSE ==其中虚拟变量1215,,...,D D D 的定义是:接下来利用Hausman 统计量检验应该建立个体随机效应回归模型还是个体固定效应回归模型。
0H :个体效应与回归变量(it IP )无关(个体随机效应回归模型) 1H :个体效应与回归变量(it IP )相关(个体固定效应回归模型)分析过程如下:得到如下检验结果:由检验输出结果的上半部分可以看出,Hausman 统计量的值是14.79,相对应的概率是0.0001,即拒接原假设,应该建立个体固定效应模型。
检验结果的下半部分是Hausman 检验中间结果比较。
个体固定效应模型对参数的估计值为0.697561,随机效应模型对参数的估计值为0.724569。
两个参数的估计量的分布方差的差为0.000049。
综上分析,1996—2002年中国东北、华北、华东15个省级地区的居民家庭人均消费和人金收入问题应该建立个体固定效应回归模型。
人均消费平均占人均收入的70%。
随地区不同,自发消费(截距项)存在显著性差异。
(4)面板单位根检验 以cp 序列为例。
首先在工作文件窗口中打开cp 变量的15个数据组。
单位根检验过程如下: 得到如下检验结果:从上面的检验结果可以看出来,6种检验方法的结论都认为15个cp 序列存在单位根。