(完整版)社会统计学复习题(有答案),DOC
《社会统计学》练习题考试题库与答案

《社会统计学》练习题一.选择题1.在日常中会话中,有这样的说法:(1)"统计得怎么样了?"(2)"你统计的可靠吗?" (3)"你统计怎么样?”关于这三种说法指涉内容正确的是:[单选题]*A.说法一是指统计资料B.说法二是指统计工作C.说法三是指统计学*D.以上指涉内容有误2 .对于社会工作而言,社会统计学的功能是:[单选题]*A.服务需要评估的出发点之一*B.难以理解服务对象生活世界的工具C.社会工作实务研究的可有可无部分D.有助于研究者,无助于实务者3 .在了解社会工作服务对象基本情况时,作为变量的出生年代属于:[单选题]*A.定比变量B.定距变量C.定序变量D.定类变量*4 .作为变量的社区居民满意度取值是a.满意、b.一般、C.不满意等三种类型,这一变量的特征是:[单选题*A.因为a>b , b>c ,所以,a<c0B.因为a>b , b>c ,所以,a>c*C.因为a-c>b ,所以,b+c=aD.因为a-b>c ,所以f b+c=a5 .某社工机构对社区居民参加服务次数进行统计,仅适合该类变量的统计图是:[单选题]*A.圆瓣图B.条形图C.直方图*D.扇形图6 .用最小平方法拟合直线趋势方程,若b为负数,则该现象趋势为()[单选题]*A.上升趋势B.下降趋势*C.水平趋势D不定7.某市近五年各年T恤衫销售量大体持平,年平均为1200万件,7月份的季节比率为220% , 9月份月平均销售量比7月份低45% ,那么,正常情况下9月份的销售量应该是()[单选题]*AlOO万件B.220万件C.121万件*8 .在年度时间序列中,不可能存在()[单选题]*A.趋势因素9 .季节因素*C.循环因素D.不规则因素10 判定系数R2是说明回归方程拟合度的一个统计量,它的计算公式为()[单选题]A. SSR/SST*B. SSR/SSEC. SSE/SSTD. SST/SSR11 .某种股票的价格周二上涨了10% ,周三上涨了5% ,两天累计张幅达()[单选题]*A. 15%B. 15.5%*C. 4.8%D. 5%12 .根据近几年数据计算所的,某种商品第二季度销售量季节比率为1.7 ,表明该商品第二季度销售(\[单选题]*A.处于旺季*C.增长了70%D.增长了170%13 .某百货公司今年与去年相比,所有商品的价格平均提高了10% ,销售量平均下降了10% ,则商品销售额()[单选题]*A.上升14 下降*C.保持不变D.可能上升也可能下降13、构成时间序列的统计指标数值,可以是(I *A、全面调查所搜集到的统计资料*B、非全面调杳所搜集到的统计资料*C、抽样调查资料*D、计算口径不一致的资料E、总体范围不一致的资料14.对于按季记录的时间序列资料,季节指数必须满足的条件是()*A.各季节指数之和为1B.各季节指数之和为4*C.各季节指数之和为12D.各季节指数平均为0E.各季节指数平均为1*15指数平滑法的特点是()*A.包含最近k个时期的数据信息B.包含全部数据信息*C.对所有数据给予同样权数D.对近期数据给予较大权数*E.对远期数据给予较大权数二、是非题1 .移动平均不仅能消除季节变动,还能消除循环变动。
社会统计学试题及答案

社会统计学试题及答案一、单项选择题(每题2分,共20分)1. 社会统计学中,用来描述一组数据集中趋势的指标是()。
A. 众数B. 中位数C. 均值D. 方差答案:C2. 以下哪个选项不属于描述统计学的内容?()A. 数据收集B. 数据整理C. 数据分析D. 数据预测答案:D3. 在统计学中,用来衡量数据离散程度的指标是()。
A. 标准差B. 均值C. 众数D. 中位数答案:A4. 以下哪个概念不是社会统计学的研究对象?()A. 人口数量B. 收入水平C. 股票价格D. 家庭结构答案:C5. 社会统计学中,用来衡量两个变量之间相关关系的强度的指标是()。
A. 相关系数B. 回归系数C. 标准差D. 方差答案:A6. 以下哪个选项不是社会统计学中常用的数据收集方法?()A. 问卷调查B. 观察法C. 实验法D. 文献分析答案:C7. 在统计学中,用来衡量数据集中程度的指标是()。
A. 标准差B. 均值C. 众数D. 中位数答案:B8. 以下哪个选项是社会统计学中常用的数据整理方法?()A. 频数分布表B. 回归分析C. 假设检验D. 相关分析答案:A9. 社会统计学中,用来描述一组数据分布形态的指标是()。
A. 偏度B. 峰度C. 均值D. 方差答案:A10. 以下哪个概念是社会统计学中用来描述数据的离散程度的?()A. 标准差B. 均值C. 众数D. 中位数答案:A二、多项选择题(每题3分,共15分)1. 社会统计学中,用来描述一组数据的指标包括()。
A. 均值B. 众数C. 方差D. 标准差E. 中位数答案:ABDE2. 以下哪些是社会统计学中常用的数据分析方法?()A. 描述性分析B. 推断性分析C. 回归分析D. 假设检验E. 相关分析答案:ABCDE3. 社会统计学中,用来衡量数据离散程度的指标包括()。
A. 标准差B. 方差C. 偏度D. 峰度E. 极差答案:ABE4. 以下哪些是社会统计学中常用的数据收集方法?()A. 问卷调查B. 观察法C. 实验法D. 文献分析E. 访谈法答案:ABDE5. 社会统计学中,用来描述一组数据分布形态的指标包括()。
(有答案)社会统计学试卷

社会统计学试卷社会工作与管理(本)专业一、单项选择题(每小题1分,共15分)1.在下列两两组合的平均指标中,哪一组的两个平均数完全不受极端数值的影响? 【 】A .算术平均数和调和平均数B .几何平均数和众数C .调和平均数和众数D .众数和中位数2.抽样推断的目的是 【 】A .以样本指标推断总体指标B .取得样本指标C .以总体指标估计样本指标D .以样本的某一指标推断另一指标3.下列哪两个变量之间的相关程度高 【 】A .商品销售额和商品销售量的相关系数是0.9;B .商品销售额与商业利润率的相关系数是0.84;C .平均流通费用率与商业利润率的相关系数是-0.94;D .商品销售价格与销售量的相关系数是-0.91。
4. 在抽样推断中,可以计算和控制的误差是 【 】A .抽样实际误差B .抽样标准误差C .非随机误差D .系统性误差5.不重复抽样的抽样标准误公式比重复抽样多了一个系数 【 】A .n N N --1B .1++N nNC .1--N n ND .n N N ++16.估计标准误说明回归直线的代表性,因此 【 】A .估计标准误数值越大,说明回归直线的代表性越大;B .估计标准误数值越大,说明回归直线的代表性越小;C .估计标准误数值越小,说明回归直线的代表性越小;D .估计标准误数值越小,说明回归直线的实用价值越小。
7.平均差与标准差的主要区别是 【 】A .意义有本质的不同B .适用条件不同C .对离差的数学处理方法不同D .反映的变异程度不同8.“统计”一词的含义可以包括的是 【 】A .统计工作、统计资料、统计学B .统计工作、统计资料、统计方法C .统计资料、统计学、统计方法D .统计工作、统计学、统计方法9.已知甲数列的算术平均数为100,标准差为20;乙数列的算术平均数为50,标准差为9。
由此可以认为 【 】A .甲数列算术平均数的代表性好于乙数列B .乙数列算术平均数的代表性好于甲数列C .两数列算术平均数的代表性相同D .两数列算术平均数的代表性无法比较10.变量x 与y 之间的负相关是指 【 】A. x 数值增大时y 也随之增大B. x 数值减少时y 也随之减少C. x 数值增大时y 随之减少D. y 的取值几乎不受x 取值的影响11.次数数列各组变量值都增加2倍,每组次数减少2倍,中位数 【 】A .减少2倍B .增加2倍C .减少1倍D .不变12.第一类错误是在下列条件下发生 论 【 】A. 原假设为真B. 原假设为假C. 显著性水平较小D. 显著性水平较大13.设()2,~σμN X ,b aX Y -=,其中a 、b 为常数,且0≠a ,则~Y 【 】A. ()222,b a b a N +-σμB.()222,b a b a N -+σμC.()22,σμa b a N +D. ()22,σμa b a N -14.设随机变量),(~2σμN X ,则随σ增大,{}σμ<-X P 【 】A.单调增大B.单调减小C.保持不变D.增减不定15.设随机变量,X Y 相互独立,)1,0(~N X ,)1,1(~N Y ,则 【 】A.2/1)0(=≤+Y X PB.2/1)1(=≤+Y X PC.2/1)0(=≤-Y X PD.2/1)1(=≤-Y X P二、填空题(每空1分,共10分)1.社会调查资料有 、统计规律性的特点。
社会统计学基本公式及社会统计学复习整理及社会统计学复习题(有答案)
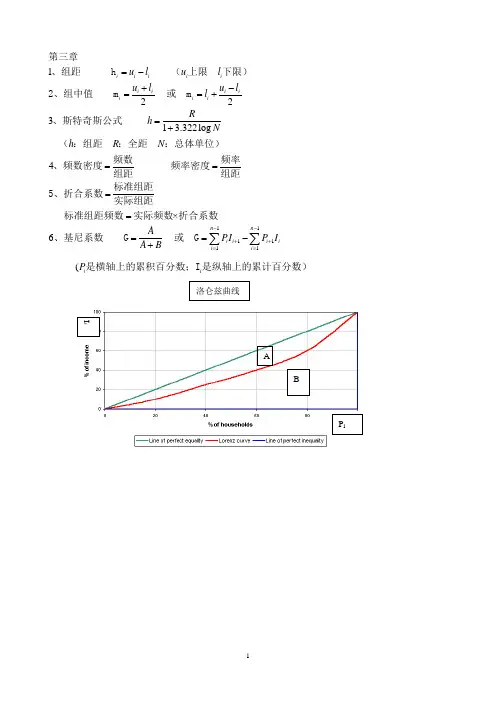
12231 3.322log 4×6i i i i i i i i i i i i u l u l u l u ll Rh N h R N AA B =-+-==+=+=====+第三章、组距 h (上限 下限)2、组中值 m 或 m 、斯特奇斯公式 (:组距 :全距 :总体单位)频数频率、频数密度 频率密度组距组距标准组距5、折合系数实际组距标准组距频数实际频数折合系数、基尼系数 G 111111n n i i i ii i PI P I --++===-∑∑ 或 G(i i P 是横轴上的累积百分数;I 是纵轴上的累计百分数)洛仑兹曲线P iI iAB1(2))(1)1221222d d X X X N fXX fN NN NN F L ==++-=+∑∑∑第四章1、算术平均数()()未分组资料 分组资料 注:对于单项数列分组,X即为变量值,若为组距式分组,则X为组中值 f:各组频数2、中位数(M 未分组资料 若N为奇数,则取第位上的变量值为中位数,若为偶数,则取第 位和第位上的两个变量值的平均数作为中位数()分组资料 M 112h h L : 2m m d m m m m m N F U f f f F F N---⨯=-⨯或 M 中位数所在组的下限: 中位数所在组的频数: 小于中位数所在组的各组频数之和(向上累计) h : 中位数所在组的组距 U: 中位数所在组的上限: 包括中位数所在组的各组频数之和(向上累计) 注: 中位数所在组由确定11111111133333334h :h 34h :N F l f F l f NF l f F l -=+⨯-=+⨯3、四分位数(1)第一四分位数 Q :小于第一四分位数所在组的各组累计频数(向上累计) 第一四分位数所在组的下限 :第一四分位数所在组的组距 :第一四分位数所在组的组距(2)第三四分位数 Q :小于第三四分位数所在组的各组累计频数(向上累计) 第三四分位数所在组的3311212h 1h :h 5o o o oo o f L L ∆=+⨯∆+∆∆∆下限 :第三四分位数所在组的组距 :第三四分位数所在组的组距4、众数(M )()未分组资料 先将所有数据顺序排列,观察某些变量值出现的次数最多,这些变量值就 是众数(2)分组资料 M 众数所在组的下限:众数所在组频数与前一组频数之差 :众数所在组频数与后一组频数之差 :众数所在组的组距、几何平均数11lg lg anti(lg )(2)1lg lg anti(lg )g g g g g gg g g X Nf X NX ========∑∑(M )()简单几何平均数 M 或 M M M 加权几何平均数M 或 M M M 注:若为组距式分组,则为组中值3112316)(1)111111...(2):312=23h h N h d o g h N Q Q NX X X X XNNf XX f X X -==++++==-≥≥-⋅∑∑、调和平均数(M 简单调和平均数(未分组) M 加权调和平均数(分组)M 注:若为组距式分组,为组中值 各组频数7、各种平均数的关系2M M M M 第五章、全距 R=X X 、四分位差 Q D、平均差=2=::X X Nf X XfX f X f -⋅-⋅∑∑(1)未分组资料 A D ()分组资料 A D 注:若为组距式分组,为组中值 各组频数4、标准差(S)(1)未分组资料(2)分组资料 注:若为组距式分组,为组中值 各组X X S-频数5、标准分 Z=社会统计学复习整理一、变量的测量层次61(2)37=1:83(o o oR R M M M o d o R X X SXN f f NNf X M X M X M S Sαα⋅⋅=-⋅=----==A D 、变异系数()全距系数 V =A D平均差系数 V =()标准差系数 V 、异众比率(非众数的频数与总体单位数的比值) V R 众数的频数、偏态系数())偏态=二、判断变量层次的技巧1.首先所有的变量都是定类变量。
社会统计学试题及答案

社会统计学试题及答案一、选择题1. 社会统计学是研究和分析社会现象和社会问题的科学方法。
下列哪项不是社会统计学的研究对象?A. 人口B. 社会经济C. 政治D. 音乐答案:D2. 下列哪项是进行社会统计学研究时常用的数据收集方法?A. 实地调研B. 实验研究C. 文献研究D. 理论推导答案:A3. 下列哪项不是社会统计学常用的数据分析方法?A. 描述统计B. 回归分析C. 实证研究D. 主观评价答案:D二、简答题1. 什么是抽样调查?请简要描述抽样调查的步骤。
抽样调查是根据一定的抽样原则和抽样方法,从总体中选出少部分元素进行调查的方法。
抽样调查的步骤包括:定义研究目标和调查问题、确定研究对象和总体范围、选择适当的抽样方法、制定抽样方案、实施调查、数据收集和分析、得出结论并进行推断。
2. 什么是社会统计指标?请举例说明一个社会统计指标。
社会统计指标是用于衡量和描述社会现象、问题或变量的量化指标。
例如,人口增长率是一个常用的社会统计指标,用于表示某一地区或国家人口数量在某一时期内的增长速度。
三、论述题社会统计学在社会科学研究中的应用社会统计学作为一门综合性的学科,广泛应用于社会科学研究中。
它通过收集、分析和解释社会数据,提供了量化的研究工具和方法,对社会现象和问题进行客观的测量和评估。
首先,社会统计学在人口学研究中发挥了重要作用。
通过对人口数量、结构、分布等进行统计分析,可以揭示出不同地区、不同群体的人口变化趋势和特点。
人口统计数据还为制定人口政策、规划资源分配等提供了科学的依据。
其次,社会统计学在社会经济学研究中具有重要意义。
通过对收入分布、贫富差距、就业率等指标的统计分析,可以帮助我们了解社会经济现象和问题,并为政府和决策者提供制定经济政策的依据。
此外,社会统计学在社会学、教育学、卫生学等学科中也得到了广泛的应用。
它帮助研究者揭示社会结构、社会关系、社会变迁等方面的规律,为社会科学研究提供了重要的数据支持。
社会统计学复习题.(DOC)

《社会统计学》复习题考试题型:一、填空(1*20=20)二、单选(1*10=10)三、多选(2*5=10)四、判断(2*5=10)五、计算题(5*8=40)六、分析题(1*10=10)一、填空题1、大量观察法之所以称为统计上特有的方法,是与()的作用分不开的。
2、大数定律的一般意义是:在综合大量社会现象的数量特征时,个别单位偶然的数量差异会(),使大量社会现象的数量特征借助于()形式,接近用确定的数值显示出必然的规律性。
3、要了解有个班级学生的学习情况,则总体是(),总体单位是()。
4、凡是相邻的两个变量值之间可以连续不断分割的变量,称为()。
凡是各变量值之间是以整数断开的变量,称为()。
5、统计按其内容主要包括两个方面:描述统计和()。
6、推论统计有两个基本内容:参数估计和()。
7、通过抽样得到的用以推断总体特征的那个“部分”,在统计学上称为()。
样本中所含的单位数,在统计学上称为样本大小,也叫做()。
8、()是指由调查者直接搜集的、未经加工整理而保持其原本状态的资料。
()是指经他人加工整理,可以在一定程度上被引用来说明总体特征的资料。
9、()误差,是指在调查和统计过程中由于各种主客观因素而引起的技术性、操作性误差以及由于责任心缘故而造成的误差等。
()误差,是指由调查方式本身所决定的统计指标和总体指标之间存在的差数。
10、统计调查从调查范围上分,可分为()和()。
11.()误差是在遵守随机原则的条件下,用样本指标代表总体指标不可避免存在的误差,它表示抽样估计的精度。
12基尼系数为(),表示收入绝对不平均;基尼系数为(),表示收入绝对平均。
13、统计表通常有一定格式,统计表各部位的名称分别是()、横行标题、纵栏标题、()。
14、实际收入分配情况则由洛仑兹曲线表示,一般表现为一条下凹的弧线,下凹程度愈大,收入分配(),反之,则收入分配()。
相关:洛仑兹曲线是一种用来反映社会收入分配平均程度的累计百分数曲线。
社会统计学复习题答案
社会统计学复习题答案社会统计学是一门应用广泛的学科,它涉及到数据的收集、处理、分析和解释,以帮助我们更好地理解社会现象。
以下是一些社会统计学的复习题及其答案,供参考:一、选择题1. 社会统计学的主要研究对象是什么?A. 个体行为B. 社会现象C. 经济活动D. 政治事件答案:B2. 以下哪个是描述性统计的主要内容?A. 推断总体参数B. 描述数据分布C. 预测未来趋势D. 建立因果关系答案:B3. 抽样调查与普查的主要区别是什么?A. 抽样调查成本高B. 普查不具有代表性C. 抽样调查结果不可靠D. 普查可以得到全面数据答案:D二、填空题4. 社会统计学中,________是用来衡量数据集中趋势的指标。
答案:均值5. 标准差是衡量数据________的指标。
答案:离散程度6. 相关系数的取值范围在________之间。
答案:-1到1三、简答题7. 简述抽样误差和非抽样误差的区别。
答案:抽样误差是指由于样本不能完美代表总体而产生的误差,它可以通过增大样本量来减少。
非抽样误差则包括测量误差、非响应误差等,这些误差与抽样方法无关,通常与数据收集和处理过程中的偏差有关。
8. 描述统计与推断统计的区别。
答案:描述统计主要关注对数据集的描述,如计算均值、中位数、方差等,它不涉及对总体的推断。
推断统计则是基于样本数据来推断总体特征,如估计总体均值、进行假设检验等。
四、计算题9. 给定一组数据:10, 12, 14, 16, 18, 20,计算其均值和标准差。
答案:均值 = (10+12+14+16+18+20)/6 = 15;标准差 =√[(Σ(xi - 均值)^2) / (n-1)] = √[(10+4+0+4+0+5)/5] ≈ 3.0310. 如果一个总体的均值为50,标准差为10,样本均值为55,样本量为100,进行单样本t检验,假设总体方差未知,计算t值。
答案:首先计算样本标准差,然后使用t检验公式:t = (样本均值 - 总体均值) / (样本标准差/ √样本量)。
最新社会统计学期末复习题与答案整理
社会统计学期末复习训练一、单项选择题(20=2×10)1.为了解IT行业从业者收入水平,某研究机构从全市IT行业从业者随机抽取800人作为样本进行调查,其中44%回答他们的月收入在6000元以上,30%回答他们每月用于娱乐消费在1000元以上。
此处800人是.样本2.某地区政府想了解全市332.1万户家庭年均收入水平,从中抽取3000户家庭进行调查,以推断所有家庭的年均收入水平。
这项研究的总体是 332.1户家庭的年均收入3.学校后勤集团想了解学校22000学生的每月生活费用,从中抽取2200名学生进行调查,以推断所有学生的每月生活费用水平。
这项研究的总体是 22000名学生的每月生活费用4.为了解地区的消费,从该地区随机抽取5000户进行调查,其中30%回答他们的月消费在5000元以上,40%回答他们每月用于通讯、网络的费用在300元以上。
此处5000户是样本5.从变量分类看,下列变量属于定序变量的是产品等级6.下列变量属于数值型变量的是工资收入7.从含有N个元素的总体中,抽取n个元素作为样本,同时保证总体中每个元素都有相同的机会入选样本,这样的抽样方式称为.简单随机抽样8.某班级有60名男生,40名女生,为了了解学生购书支出,从男生中抽取12名学生,从女生中抽取8名学生进行调查。
这种调查方法属于分层抽样9.先将总体按某标志分为不同的类别或层次,然后在各个类别中采用简单随机抽样或系统抽样的方式抽取子样本,这样的抽样方式称为分层抽样10.某班级有100名学生,为了了解学生消费水平,将所有学生按照学习成绩排序后,在前十名学生中随机抽出成绩为第3名的学生,后面依次选出第13、23、33、43、53、63、73、83、93九名同学进行调查。
这种调查方法属于系统抽样11.在频数分布表中,某一小组中数据个数占总数据个数的比例称为频率12.在频数分布表中,将各个有序类别或组的百分比逐级累加起来称为累积频率13.在频数分布表中,频率是指各组频数与总频数之比14.在频数分布表中,比率是指不同小组的频数之比15.如果用一个图形描述比较两个或多个样本或总体的结构性问题时,适合选用环形图16.某地区2001-2010年人口总量(单位:万人)分别为98,102,103,106,108,109,110,111,114,115,下列哪种图形最适合描述这些数据线图17.当我们用图形描述甲乙两地区的人口年龄结构时,适合选用哪种图形环形图18.在某市随机抽取10家企业,7月份利润额(单位:万元)分别为72.0、63.1、20.0、23.0、54.7、54.3、23.9、25.0、26.9、29.0,那么这10家企业7月份利润额均值为 39.19 19.某班级10名同学期末统计课考试分数分别为76、93、95、80、92、83、88、90、92、72,那么该班考试成绩的中位数是 8920.某企业职工的月收入水平分为五组:1)1500元及以下;2)1500-2000元;3)2000-2500元;4)2500-3000元;5)3000元及以上,则3000元及以上这一组的组中值为 3250元21.为了解某行业12月份利润状况,随机抽取5家企业,12月份利润额(单位:万元)分别为65、23、54、45、39,那么这5家企业12月份利润额均值为 45.222.某专业共8名同学,他们的统计课成绩分别为86、77、97、94、82、90、83、92,那么该班考试成绩的中位数是8823.某班级学生平均每天上网时间可以分为以下六组:1)1小时及以下;2)1-2小时;3)2-3小时;4)3-4小时;5)4-5小时;6)5小时及以上,则5小时及以上这一组的组中值近似为5.5小时24.对于左偏分布,平均数、中位数和众数之间的关系是众数>中位数>平均数25.对于右偏分布,平均数、中位数和众数之间的关系是平均数>中位数>众数26.离散系数的主要目的是比较多组数据的离散程度27.两组数据的平均数不相等,但是标准差相等。
(完整word版)社会统计学简答题与计算题复习资料
社会统计学复习材料简答题1、统计数据的质量要求:1、精度:最低的抽样误差或随机误差;2、准确性:最小的非抽样误差或偏差;3、关联性:满足用户决策、管理和研究的需要;4、及时性:在最短的时间里取得并公布数据;5、一致性:保持时间序列的可比性;6、最低成本:以最经济的方式取得数据。
2、抽样误差及其影响因素:1、由于抽样的随机性所带来的误差;2、所有样本可能的结果与总体真值之间的平均性差异;3、影响抽样误差的大小的因素:样本量的大小,总体的变异性。
3、判断计量优劣的评判标准:用样本的估计量直接作为总体参数的估计值,无偏性:估计量抽样分布的数学期望等于被估计的总体参数;有效性:对同一总体参数的两个无偏点估计量,有更小标准差的估计量更有效;一致性:随着样本容量的增大,估计量的值越来越接近被估计的总体参数。
4、假设检验的一般步骤:(1)陈述原假设和备择假设;(2)从所研究的总体中抽出一个随机样本;(3)确定一个适当的检验统计量,并利用样本数据算出其具体数值;(4)确定一个适当的显著性水平,并计算出其临界值,指定拒绝域;(5)将统计量的值与临界值进行比较,作出决策;(6)统计量的值落在拒绝域,拒绝H0,否则不拒绝H0。
5、假设检验中的两类错误及其之间的关系错误:1、第Ⅰ类错误(弃真错误)原假设为真时拒绝原假设,第Ⅰ类错误的概率记为a,即显著性水平;2、第Ⅱ类错误(取伪错误)原假设为假时未拒绝原假设,第Ⅱ类错误的概率记为b。
a和b的关系就像翘翘板,a小b就大,a大b就小。
因此,在样本容量n固定情况下,不能同时减少两类错误!一般采用增加样本容量的办法来解决。
关系:当显著性水平a减小时,由于拒绝域的减小,弃真的错误会减小,但由此而来的是接受域增大了,因此纳伪的概率b要增大。
反之亦然(P235)。
也就是说如果要减小b,就增大显著性水平a。
6、置信区间与置信度的关系表达式:称作置信区间。
称作置信度,可信度,或置信水平。
社会统计学复习题(有答案)
社会统计学课程期末复习题一、填空题(计算结果一般保留两位小数)1、第五次人口普查南京市和上海市的人口总数之比为 比较 相对指标;某企业男女职工人数之比为 比例 相对指标;某产品的废品率为 结构 相对指标;某地区福利机构网点密度为 强度 相对指标。
2、各变量值与其算术平均数离差之和为 零 ;各变量值与其算术平均数离差的平方和为 最小值 。
3、在回归分析中,各实际观测值y 与估计值y ˆ的离差平方和称为 剩余 变差。
4、平均增长速度= 平均发展速度 —1(或100%)。
5、 正J 形 反J 形 曲线的特征是变量值分布的次数随变量值的增大而逐步增多; 曲线的特征是变量值分布的次数随变量值的增大而逐步减少。
6、调查宝钢、鞍钢等几家主要钢铁企业来了解我国钢铁生产的基本情况,这种调查方式属于 重点 调查。
7、要了解某市大学多媒体教学设备情况,则总体是 该市大学中的全部多媒体教学设备 ;总体单位是 该市大学中的每一套多媒体教学设备; 。
8、若某厂计划规定A 产品单位成本较上年降低6%,实际降低了7%,则A 产品单位成本计划超额完成程度为100%7%A 100%1.06%100%6%-=-=-产品单位成本计划超额完成程度 ;若某厂计划规定B产品产量较上年增长5%,实际增长了10%,则B 产品产量计划超额完成程度为100%10%100%4.76%100%5%+=-=+B 产品产量计划超额完成程度 。
9、按照标志表现划分,学生的民族、性别、籍贯属于 品质 标志;学生的体重、年龄、成绩属于 数量 标志。
10、从内容上看,统计表由 主词 和 宾词 两个部分组成;从格式上看,统计表由总标题 、 横行标题 、 纵栏标题 和 指标数值(或统计数值);四个部分组成。
11、从变量间的变化方向来看,企业广告费支出与销售额的相关关系,单位产品成本与单位产品原材料消耗量的相关关系属于 正 相关;而市场价格与消费者需求数量的相关关系,单位产品成本与产品产量的相关关系属于 负 相关。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
g o o 海量资源,欢迎共阅社会统计学课程期末复习题一、填空题(计算结果一般保留两位小数)1、第五次人口普查南京市和上海市的人口总数之比为比较相对指标;某企业男女职工人数之比为比例相对指标;某产品的废品率为结构相对指标;某地区福利机构网点密度为强度相对指标。
2最小值。
345、正J 6于重点7;总8计划超额完成程度为;若某100%7%A 100% 1.06%100%6%-=-=-产品单位成本计划超额完成程度厂计划规定B 产品产量较上年增长5%,实际增长了10%,则B 产品产量计划超额完成程度为。
100%10%100% 4.76%100%5%+=-=+B 产品产量计划超额完成程度9、按照标志表现划分,学生的民族、性别、籍贯属于品质标志;学生的体重、年龄、成绩属于数量标志。
海量资源,欢迎共阅10、从内容上看,统计表由主词和宾词两个部分组成;从格式上看,统计表由总标题、横行标题、纵栏标题和指标数值(或统计数值);四个部分组成。
11、从变量间的变化方向来看,企业广告费支出与销售额的相关关系,单位产品成本与单位产品原材料消耗量的相关关系属于正相关;而市场价格与消费者需求数量的相关关系,单位131100%,)234、有意识地选择十个具有代表性的城市调查居民消费情况,这种调查方式属于典型调查。
(√)5、统计调查按调查范围划分可以分为全面调查和非全面调查。
(√)6、用移动平均法修匀时间数列时,如果移动项数为偶数项,只要进行一次移动平均;如果移动项数为奇数项,则要进行二次移动平均。
(×;答案提示:用移动平均法修匀时间数列时,如果移动项数为奇数项,只要进行一次移动平均;如果移动项数为偶数项,则要进行二海量资源,欢迎共阅次移动平均。
)7、对人们收入的测量可采用定距尺度,对人们智商水平的测量可采用定比尺度。
(×;答案)提示:对人们收入的测量可采用定比尺度,对人们智商水平的测量可采用定距尺度。
8、若按月平均计算,则各季度季节比率之和为400%。
(×;答案提示:若按月平均计算,Array11、在抽样推断中,总体是确定的,总体参数的值是不变的;而样本总体是不确定的,样本统计量的值是变化的。
(√)(×;12、商品库存额和职工人数属于时期指标,而商品销售额和职工工资总额属于时点指标。
答案提示:商品库存额和职工人数属于时点指标,而商品销售额和职工工资总额属于时期指标。
)海量资源,欢迎共阅三、单项选择题1、统计调查按调查登记的时间是否连续划分,可以分为(D)。
A全面调查和非全面调查B一般调查和专项调查C抽样调查和普遍调查D经常性调查和一次性调查yˆy2、在回归分析中,估计值与各实际观测值的平均数的离差平方和称为(A)。
A回归变差B剩余变差C判定变差D总变差3A M4A M56、(CA7收入每提高1元时,家庭月支出平均(B)。
A减少2元B增加2元C减少3元D增加3元8、异众比率越大,各变量值相对于众数越(A)。
A离散B集中C离散或集中D无法判断。
9、(B)是在遵守随机原则的条件下,用样本指标代表总体指标不可避免存在的误差A登记性误差B随机误差C系统性误差D非随机误差d 海量资源,欢迎共阅10、如掌握的是分组资料中各组标志总量而缺少各组次数的资料,则可以采用(C )公式计算平均数。
A 位置平均数B 算术平均数C 调和平均数D 几何平均数11、若按季平均计算,则各季度季节比率之和为(A )。
A400%B800%C1200%D1600%四、简答题123451场12因为20a a 2、调查某社区60户居民,获得其家庭人口资料如下表所示,试用两种方法计算该社区平均每户的家庭人口数。
某社区60户家庭人口统计表按家庭人口数分组(人)户数(户)各组户数占总户数比重(%)o df o r s o 海量资源,欢迎共阅123456362415935104025155合计601002、时间总产值(万元)月末工人数(人)上年12月1月22024080100g oo d f or s o 海量资源,欢迎共阅2月3月3003601101205、答:该企业第一季度月平均劳动生产率为2.90万元/人。
6、某福利单位今年第一季度职工工资和职工人数资料如下表所示,试求该单位第一季度月人均工资。
产品名称计量单位(%)(万元)(万元)甲乙吨件102955020952093.137221.05261海量资源,欢迎共阅丙箱100100120120合计——170235234.1898解:答:三种产品的产值总指数约为138.24%%;三种产品的价格总指数为100.35%,由于价格水平的下降使得产值减少0.8102元;三种产品的产量总指数约为137.76%。
解:答:三种商品的销售额总指数为104.17.%;三种商品的销售量总指数为114.06%,销售量变动对销售额变动影响的绝对额为2700元;三种商品销售价格总指数为91.33%。
df 海量资源,欢迎共阅9、某福利企业1996-2005年的产值资料如下表所示:年度1996199719981999200020012002200320042005产值(万元)75113128121136152189184190212要求:(1)以最小平方法拟合直线趋势方程,并估计2006年的产值。
(2)以半数平均法拟合直线趋势方程,并估计2006年的产值。
9、(1)解①:某福利企业1996~2005年产值趋势分析计算表答:以最小平方法拟合直线趋势方程为;2006年的产值约为225.73万元。
解②:某福利企业1996~2005年产值趋势分析计算表年份t150055742.666513.769774.2667101010ˆ74.266713.7697t t y t a b n n yt =-=-⨯=≈=+∑∑∴t y t t y ⋅2t ˆ74.266713.7697t y t =+海量资源,欢迎共阅1.什么是统计学?怎样理解统计学与统计数据的关系?答:统计学是一门收集、整理、显示和分析统计数据的科学,其目的是探索数据内在的数量规律性。
统计学与统计数据存在密切关系,统计学阐述的统计方法来源于对统计数据的研究,目的也在于对统计数据的研究,离开了统计数据,统计方法乃至统计学就失去了其存在意义。
3.简要说明抽样误差和非抽样误差ds 海量资源,欢迎共阅答:统计调查误差可分为非抽样误差和抽样误差。
非抽样误差是由于调查过程中各有关环节工作失误造成的,从理论上看,这类误差是可以避免的。
抽样误差是利用样本推断总体时所产生的误差,它是不可避免的,但可以计量和控制的。
4(先分为集中趋势与分散程度,再继续细分,即综述7、8)7.多时才有意义,数据量较少时不宜使用。
主要适合作为信息利用不够充分,当数据的分布偏斜较大时,使用中位数也许不错。
主要适合作为顺序数据的集中趋势测度值。
;均值数据对数值型数据计算的,而且利用了全部数据信息,提取的信息最充分,当数据呈对称分布或近似对称分布时,三个代表值相等或相近,此时应选择平均数。
但受极端数据的影响,对于偏态分布的数据,平均数的代表性较差,海量资源,欢迎共阅此时应考虑中位数或众数。
8.标准差和方差反映数据的什么特征反映数据离散程度的特征. 标准差反应数据的变化幅度,即上下左右波动的剧烈程度。
在统计中可以用来计算某变量值的区间范围(即置信区间)。
方差:即标准差的平方。
验,所得到的频率可以各不相同,但只要n相当大,频率与概率是会非常接近的.因此,概率是可以通过频率来“测量”的,频率是概率的一个近似.概率是频率稳定性的依据,是随机事件规律的一个体现.实际中,当概率不易求出时,人们常通过作大量试验,用事件出现的频率去近似概率.当实验次数趋向于无穷时,频率的极限就是概率。
2概率的三种定义各有什么应用场合和局限性o o 海量资源,欢迎共阅1古典概率 实验的基本事件总数有限,每个基本事件出现的可能性相同; 要求样本空间是有限并且是已知的。
机会游戏的很多问题可以满足这些条件;但现实生活的实际问题样本空间或者出现的结果无限或者未知,因此具有较强的局限性2统计概率 历史上同类事物发生的稳定频率。
在日常生活与工作中,应用较,但有336随机变量的数学期望和方差与第二章所讲的均值和方差有何区别,联系数学期望又称均值,实质上是随机变量所有可能取值的一个加权平均,其权数就是取值的概率,方差一样12解释总体分布、样本分布和抽样分布的含义总体分布:所有元素出现概率的分布e i ng 海量资源,欢迎共阅样本分布:样本n 个观察值的概率分布。
抽样分布:由样本n 个观察值计算的统计量的概率分布1.简述评价估计量好坏的标准1、无偏性:估计量抽样分布的数学期望等于被估计的总体参数2、有效性:对同一总体参数的两个无偏点估计量,有更小标准差的估计量更有效 .简述样本容量与置信水平、总体方差、允许误差的关系答:以估计总体均值时样本容量的确定公式为例:样本容量与置信水平成正比、与总体方差成正比、与述述置信区间和显著性水平的关系即:求接受域就是求置信区间,所以假设检验和区间估计本质是一回事。
1.理解原假设与备择假设的含义,并归纳常见的几种建立原假设与备择假设的原则.答:原假设通常是研究者想收集证据予以反对的假设;而备择假设通常是研究者想收集证据予以支持的假设。
建立两个假设的原则有:(1)原假设和备择假设是一个完备事件组,而且相互对立。
(2)一般先确定备择假设。
再确定原假设。
(3)等号“=”总是放在原假设上。
(4)假设的确定g o r 海量资源,欢迎共阅带有一定的主观色彩。
(5)假设检验的目的主要是收集证据来拒绝原假设。
3.什么是显著性水平?它对于假设检验决策的意义是什么?答:假设检验中犯第一类错误的概率被称为显著性水平。
显著性水平通常是人们事先给出的一个值,用于检验结果的可靠性度量,但确定了显著性水平等于控制了犯第一错误的概率,对检验结果的可靠性起一H0:u ≤u0H1:u>u0或H0:u<u0H1:u ≤u0。
(3)否定的区域不同,双侧检验的否定区域是|Z|>Za/2;单侧检验的否定区域是Z<-Za 或Z>Za 1什么是方差分析?它研究的是什么?方差分析是检验多个总体均值是否相等的统计方法,来判断分类型自变量对数值型因变量是否有显著影响。
海量资源,欢迎共阅它所研究的是分类型自变量对数值型因变量的影响。
2方差分析中有哪些基本假定每个总体都应服从正态分布;每个总体的方差必须相同;观测值是独立的3简述方差分析的基本思想通过分析研究不同来源的变异对总变异的贡献大小,从而确定可控因素对研究映1具有共同的研究对象,都是对变量间相关关系的分析,二者可以相互补充。
相关分析可以表明变量间相关关系的性质和程度,只有当变量间存在相当程度的相关关系时,进行回归分析去寻找变量间相关的具体数学形式才有实际的意义。