社会统计学习题和答案--相关与回归分析报告
社会统计学(第四版)课后习题详解

社会统计学(第四版)课后习题详解导读:就爱阅读网友为您分享以下“社会统计学(第四版)课后习题详解”资讯,希望对您有所帮助,感谢您对 的支持!《社会统计学》课程练习题(1)答案一、略二、(1)对立事件(2)互不相容事件(3)互不相容事件(1)对立事件三、50 25 200 525(元)40 25M0 400 200 516.28(元)25 18Md 40025 10 200 400.00(元)1575 65Q3 600 200 690.91(元) 22Q Q3 Q1 690.91 400 290.91(元)Q1 2002 nb2ii ( nibi)2NN225.66(元)25260032760000 100 5092400 50924 100100四、(1)极差R=1529-65=1464(百元)(2)将数据从小到大排序:65 92 106 118 122 135 148 174 185 1529 10 1 2.7543 (10 1)Q3的位置 8.254Q1 92 (106 92) 0.75 102.5(百元)Q1的位置Q3 174 (185 174) 0.25 176.75(百元)四分互差Q 176.75-102.5 74.25(百元)(3)百元) 10五、 x2i ( xi)2 N267422495204 .64 421.92(80 0.810020P(B) 0.210012P(B/A) 0.158012P(A/B) 0.62012P(AB) 0.1210040P(C) 0.410032P(C/A) 0.48012P(/) 0.158032 P(AC) 0.32 100P(A)六、4157P(B) 151P(AB) 10P(AB)115P(A/B) 0.214P(B)107P(AB)115P(B/A) 0.375P(A)104P(A)P(A B) P(A) P(B) P(AB)七、471 0.63315151010 (1)10口井皆产油的概率为:P( 10) C10 0.3100.70 0.00000590(2) 10口井皆不产油的概率为:P( 0) C100.300.710 0.0282501(3)该公司赢利的机会为:P( 2) 1 C100.300.710 C100.310.79 0.85069八、444P(x 2) e 8 2.71828 0.14652!九、1.371.3701.371.3711.37P(0 x 1) P(x 0) P(x 1) e e 0.60220!1!十、0.10.10 0.1 10.1(Z) ( 1) 1 (1) 1 0.8413 0.1587Z投资人投资于此种股票保证不亏的概率为:1 0.1587 0.8413。
社会统计学答案

一、单选题 (共5题,60.0分)1、西方统计学认为近代统计学之父的是()。
1.威廉·配弟2.阿道夫·凯特勒3.海尔曼·康令4.约翰·格朗特标准答案:B2、为了检验两个总体的方差是否相等,所使用的变量抽样分布是()。
1.F分布2.Z分布3.t分布4.方差分布标准答案:A3、在中国台湾的一项《夫妻对电视传播媒介观念差距的研究》中,访问了30对夫妻,其中丈夫所受教育X(以年为单位)的数据如下: 18 20 16 6 16 17 12 14 16 18 14 14 16 9 20 18 12 15 13 16 16 2l 2l 9 16 20 14 14 16 16 ,问10.5年的教育在第几百分位数上?1.第10个百分位数上3.第15个百分位数上4.第20个百分位数上标准答案:A4、身高和体重之间的关系是()。
1.函数关系2.无相关3.共变关系4.严格的依存关系标准答案:C5、抽样调查中,无法消除的误差是()。
1.登记性误差2.系统性误差3.随机误差4.责任心误差标准答案:C1.2.无关系4.不存在线性相关标准答案:D5、某市连续五年人口增长数是稳定的,五年里其人口环比增长速度()。
1.降低的2.提高的3.稳定不变的4.先升后降的标准答案:A一、单选题 (共5题,60.0分)1、抽样调查中,无法消除的误差是()。
1.登记性误差2.系统性误差3.随机误差4.责任心误差标准答案:C2、在中国台湾的一项《夫妻对电视传播媒介观念差距的研究》中,访问了30对夫妻,其中丈夫所受教育X(以年为单位)的数据如下: 18 20 16 6 16 17 12 14 16 18 14 14 16 920 18 12 15 13 16 16 2l 2l 9 16 20 14 14 16 16 ,问10.5年的教育在第几百分位数上?1.第10个百分位数上2.第5个百分位数上3.第15个百分位数上4.第20个百分位数上标准答案:A一、单选题 (共5题,60.0分)1、两变量的线性相关系数为0,表明两变量之间()。
《社会统计学》练习题考试题库与答案

《社会统计学》练习题一.选择题1.在日常中会话中,有这样的说法:(1)"统计得怎么样了?"(2)"你统计的可靠吗?" (3)"你统计怎么样?”关于这三种说法指涉内容正确的是:[单选题]*A.说法一是指统计资料B.说法二是指统计工作C.说法三是指统计学*D.以上指涉内容有误2 .对于社会工作而言,社会统计学的功能是:[单选题]*A.服务需要评估的出发点之一*B.难以理解服务对象生活世界的工具C.社会工作实务研究的可有可无部分D.有助于研究者,无助于实务者3 .在了解社会工作服务对象基本情况时,作为变量的出生年代属于:[单选题]*A.定比变量B.定距变量C.定序变量D.定类变量*4 .作为变量的社区居民满意度取值是a.满意、b.一般、C.不满意等三种类型,这一变量的特征是:[单选题*A.因为a>b , b>c ,所以,a<c0B.因为a>b , b>c ,所以,a>c*C.因为a-c>b ,所以,b+c=aD.因为a-b>c ,所以f b+c=a5 .某社工机构对社区居民参加服务次数进行统计,仅适合该类变量的统计图是:[单选题]*A.圆瓣图B.条形图C.直方图*D.扇形图6 .用最小平方法拟合直线趋势方程,若b为负数,则该现象趋势为()[单选题]*A.上升趋势B.下降趋势*C.水平趋势D不定7.某市近五年各年T恤衫销售量大体持平,年平均为1200万件,7月份的季节比率为220% , 9月份月平均销售量比7月份低45% ,那么,正常情况下9月份的销售量应该是()[单选题]*AlOO万件B.220万件C.121万件*8 .在年度时间序列中,不可能存在()[单选题]*A.趋势因素9 .季节因素*C.循环因素D.不规则因素10 判定系数R2是说明回归方程拟合度的一个统计量,它的计算公式为()[单选题]A. SSR/SST*B. SSR/SSEC. SSE/SSTD. SST/SSR11 .某种股票的价格周二上涨了10% ,周三上涨了5% ,两天累计张幅达()[单选题]*A. 15%B. 15.5%*C. 4.8%D. 5%12 .根据近几年数据计算所的,某种商品第二季度销售量季节比率为1.7 ,表明该商品第二季度销售(\[单选题]*A.处于旺季*C.增长了70%D.增长了170%13 .某百货公司今年与去年相比,所有商品的价格平均提高了10% ,销售量平均下降了10% ,则商品销售额()[单选题]*A.上升14 下降*C.保持不变D.可能上升也可能下降13、构成时间序列的统计指标数值,可以是(I *A、全面调查所搜集到的统计资料*B、非全面调杳所搜集到的统计资料*C、抽样调查资料*D、计算口径不一致的资料E、总体范围不一致的资料14.对于按季记录的时间序列资料,季节指数必须满足的条件是()*A.各季节指数之和为1B.各季节指数之和为4*C.各季节指数之和为12D.各季节指数平均为0E.各季节指数平均为1*15指数平滑法的特点是()*A.包含最近k个时期的数据信息B.包含全部数据信息*C.对所有数据给予同样权数D.对近期数据给予较大权数*E.对远期数据给予较大权数二、是非题1 .移动平均不仅能消除季节变动,还能消除循环变动。
社会统计学试题及答案

社会统计学试题及答案一、单项选择题(每题2分,共20分)1. 社会统计学中,用来描述一组数据集中趋势的指标是()。
A. 众数B. 中位数C. 均值D. 方差答案:C2. 以下哪个选项不属于描述统计学的内容?()A. 数据收集B. 数据整理C. 数据分析D. 数据预测答案:D3. 在统计学中,用来衡量数据离散程度的指标是()。
A. 标准差B. 均值C. 众数D. 中位数答案:A4. 以下哪个概念不是社会统计学的研究对象?()A. 人口数量B. 收入水平C. 股票价格D. 家庭结构答案:C5. 社会统计学中,用来衡量两个变量之间相关关系的强度的指标是()。
A. 相关系数B. 回归系数C. 标准差D. 方差答案:A6. 以下哪个选项不是社会统计学中常用的数据收集方法?()A. 问卷调查B. 观察法C. 实验法D. 文献分析答案:C7. 在统计学中,用来衡量数据集中程度的指标是()。
A. 标准差B. 均值C. 众数D. 中位数答案:B8. 以下哪个选项是社会统计学中常用的数据整理方法?()A. 频数分布表B. 回归分析C. 假设检验D. 相关分析答案:A9. 社会统计学中,用来描述一组数据分布形态的指标是()。
A. 偏度B. 峰度C. 均值D. 方差答案:A10. 以下哪个概念是社会统计学中用来描述数据的离散程度的?()A. 标准差B. 均值C. 众数D. 中位数答案:A二、多项选择题(每题3分,共15分)1. 社会统计学中,用来描述一组数据的指标包括()。
A. 均值B. 众数C. 方差D. 标准差E. 中位数答案:ABDE2. 以下哪些是社会统计学中常用的数据分析方法?()A. 描述性分析B. 推断性分析C. 回归分析D. 假设检验E. 相关分析答案:ABCDE3. 社会统计学中,用来衡量数据离散程度的指标包括()。
A. 标准差B. 方差C. 偏度D. 峰度E. 极差答案:ABE4. 以下哪些是社会统计学中常用的数据收集方法?()A. 问卷调查B. 观察法C. 实验法D. 文献分析E. 访谈法答案:ABDE5. 社会统计学中,用来描述一组数据分布形态的指标包括()。
统计学7-10章课后作业答案

第7章 相关与回归分析1、设销售收入x 为自变量,销售成本y 为因变量。
现已根据某百货公司某年12个月的有关资料计算出以下数据(单位:万元):2()425053.73ix x -=∑ 647.88x =2()262855.25iy y -=∑549.8y =()()334229.09iix x y y --=∑(1)拟合简单线性回归方程,并对方程中回归系数的经济意义作出解释。
(2)计算可决系数和回归估计的标准误差。
(3)对回归系数进行显著性水平为5%的显著性检验。
(4)假定下年一月销售收入为800万元,利用拟合的回归方程预测销售成本,并给出置信度为95%的预测区间。
解:(1)定性分析可知,销售收入影响销售成本,以销售收入为自变量,销售成本为因变量拟合线性回归方程i i i y x u αβ=++,采用最小二乘法估计回归参数得:22()()(,)334229.09ˆ0.7863()425053.73ii xix x y y Cov x y x x βσ--===≈-∑∑ˆˆ549.80.7863647.8840.372y x αβ=-=-⨯= 因此,拟合的回归方程为:ˆˆˆ40.3720.7863i i iy x x αβ=+=+ 其中,回归系数β表示自变量每变动一个单位,因变量的平均变量幅度。
在此,表示销售收入每增加1万元,销售成本平均增加0.7863万元。
(2)可决系数22222[()()]334229.090.9998()()425053.73262855.25i i i i x x y y SSR R SST x x y y --===≈-⋅-⨯∑∑∑ (本问接下来的计算不做要求:为计算回归系数的标准误差,根据离差平方和分解,可知:2222222[()()]ˆˆˆˆˆˆ()[()()]()()334229.09262811.68425053.73i i i iiix x y y SSR y y x x x x x x αβαββ--=-=+-+=-=-==∑∑∑∑∑22ˆ()()262855.25262811.6843.57i i SSE SST SSR y y yy =-=---=-=∑∑因此有ˆ()0.0032S β===≈) (3)陈述假设:01:0 :0H H ββ=≠在原假设成立的前提下,构造t 检验统计量245.598t ===在5%的双侧检验显著性水平下,查自由度为10的t 分布表,得临界值0.025(10) 2.228t t =<,因此拒绝原假设。
回归分析练习题与参考标准答案

回归分析练习题与参考答案————————————————————————————————作者:————————————————————————————————日期:1 下面是7个地区2000年的人均国内生产总值(GDP)与人均消费水平的统计数据:地区人均GDP/元人均消费水平/元北京辽宁上海江西河南贵州陕西 224601122634547485154442662454973264490115462396220816082035求:(1)人均GDP作自变量,人均消费水平作因变量,绘制散点图,并说明二者之间的关系形态。
(2)计算两个变量之间的线性相关系数,说明两个变量之间的关系强度。
(3)求出估计的回归方程,并解释回归系数的实际意义。
(4)计算判定系数,并解释其意义。
(5)检验回归方程线性关系的显著性(0.05α=)。
(6)如果某地区的人均GDP为5000元,预测其人均消费水平。
(7)求人均GDP为5000元时,人均消费水平95%的置信区间与预测区间。
解:(1)可能存在线性关系。
(2)相关系数:系数a模型非标准化系数标准系数t Sig.相关性B 标准误差试用版零阶偏部分1 (常量) 734.693 139.540 5.265 .003人均GDP .309 .008 .998 36.492 .000 .998 .998 .998 a. 因变量: 人均消费水平有很强的线性关系。
(3)回归方程:734.6930.309y x=+系数a模型非标准化系数标准系数t Sig.相关性B 标准误差试用版零阶偏部分1 (常量) 734.693 139.540 5.265 .003人均GDP .309 .008 .998 36.492 .000 .998 .998 .998 a. 因变量: 人均消费水平回归系数的含义:人均GDP没增加1元,人均消费增加0.309元。
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%注意:图标不要原封不动的完全复制软件中的图标,要按规范排版。
统计学高教版相关与回归分析课后习题答案
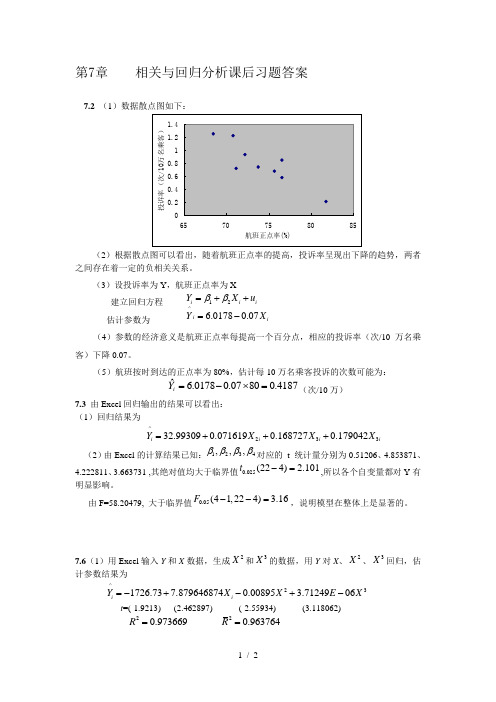
第7章 相关与回归分析课后习题答案7.2 (1)数据散点图如下:(2)根据散点图可以看出,随着航班正点率的提高,投诉率呈现出下降的趋势,两者之间存在着一定的负相关关系。
(3)设投诉率为Y ,航班正点率为X建立回归方程 12i i i Y X u ββ=++估计参数为 ^6.01780.07i i Y X =-(4)参数的经济意义是航班正点率每提高一个百分点,相应的投诉率(次/10万名乘客)下降0.07。
(5)航班按时到达的正点率为80%,估计每10万名乘客投诉的次数可能为: 4187.08007.00178.6ˆ=⨯-=i Y (次/10万)7.3 由Excel 回归输出的结果可以看出:(1)回归结果为^23332.993090.0716190.1687270.179042i i i i Y X X X =+++(2)由Excel 的计算结果已知:1234,,,ββββ对应的 t 统计量分别为0.51206、4.853871、4.222811、3.663731 ,其绝对值均大于临界值0.025(224) 2.101t -=,所以各个自变量都对Y 有明显影响。
由F=58.20479, 大于临界值0.05(41,224) 3.16F --=,说明模型在整体上是显著的。
7.6(1)用Excel 输入Y 和X 数据,生成2X 和3X 的数据,用Y 对X 、2X 、3X 回归,估计参数结果为^231726.737.8796468740.00895 3.7124906i i Y X X E X =-+-+- t =(-1.9213) (2.462897) (-2.55934) (3.118062)20.973669R = 20.963764R =(2)检验参数的显著性:当取0.05α=时,查t 分布表得0.025(124) 2.306t -=,与t 统计量对比,除了截距项外,各回归系数对应的t 统计量的绝对值均大于临界值,表明在这样的显著性水平下,回归系数显著不为0。
统计学课后习题答案第七章相关分析与回归分析报告

统计学课后习题答案第七章相关分析与回归分析报告第七章相关分析与回归分析一、单项选择题1.相关分析是研究变量之间的A.数量关系B.变动关系C.因果关系D.相互关系的密切程度2.在相关分析中要求相关的两个变量A.都是随机变量B.自变量是随机变量C.都不是随机变量D.因变量是随机变量3.下列现象之间的关系哪一个属于相关关系?A.播种量与粮食收获量之间关系B.圆半径与圆周长之间关系C.圆半径与圆面积之间关系D.单位产品成本与总成本之间关系4.正相关的特点是A.两个变量之间的变化方向相反B.两个变量一增一减C.两个变量之间的变化方向一致D.两个变量一减一增5.相关关系的主要特点是两个变量之间A.存在着确定的依存关系B.存在着不完全确定的关系C.存在着严重的依存关系D.存在着严格的对应关系6.当自变量变化时, 因变量也相应地随之等量变化,则两个变量之间存在着A.直线相关关系B.负相关关系C.曲线相关关系D.正相关关系7.当变量X值增加时,变量Y值都随之下降,则变量X和Y之间存在着A.正相关关系B.直线相关关系C.负相关关系D.曲线相关关系8.当变量X值增加时,变量Y值都随之增加,则变量X和Y之间存在着A.直线相关关系B.负相关关系C.曲线相关关系D.正相关关系9.判定现象之间相关关系密切程度的最主要方法是A.对现象进行定性分析B.计算相关系数C.编制相关表D.绘制相关图10.相关分析对资料的要求是A.自变量不是随机的,因变量是随机的B.两个变量均不是随机的C.自变量是随机的,因变量不是随机的D.两个变量均为随机的11.相关系数A.既适用于直线相关,又适用于曲线相关B.只适用于直线相关C.既不适用于直线相关,又不适用于曲线相关D.只适用于曲线相关12.两个变量之间的相关关系称为A.单相关B.复相关C.不相关D.负相关13.相关系数的取值围是A.-1≤r≤1B.-1≤r≤0C.0≤r≤1D. r=014.两变量之间相关程度越强,则相关系数A.愈趋近于1B.愈趋近于0C.愈大于1D.愈小于115.两变量之间相关程度越弱,则相关系数A.愈趋近于1B.愈趋近于0C.愈大于1D.愈小于116.相关系数越接近于-1,表明两变量间A.没有相关关系B.有曲线相关关系C.负相关关系越强D.负相关关系越弱17.当相关系数r=0时,A.现象之间完全无关B.相关程度较小B.现象之间完全相关 D.无直线相关关系18.假设产品产量与产品单位成本之间的相关系数为-0.89,则说明这两个变量之间存在A.高度相关B.中度相关C.低度相关D.显著相关19.从变量之间相关的方向看可分为A.正相关与负相关B.直线相关和曲线相关C.单相关与复相关D.完全相关和无相关20.从变量之间相关的表现形式看可分为A.正相关与负相关B.直线相关和曲线相关C.单相关与复相关D.完全相关和无相关21.物价上涨,销售量下降,则物价与销售量之间属于A.无相关B.负相关C.正相关D.无法判断22.配合回归直线最合理的方法是A.随手画线法B.半数平均法C.最小平方法D.指数平滑法23.在回归直线方程y=a+bx中b表示A.当x增加一个单位时,y增加a的数量B.当y增加一个单位时,x增加b的数量C.当x增加一个单位时,y的平均增加量D.当y增加一个单位时, x的平均增加量24.计算估计标准误差的依据是A.因变量的数列B.因变量的总变差C.因变量的回归变差D.因变量的剩余变差25.估计标准误差是反映A.平均数代表性的指标B.相关关系程度的指标C.回归直线的代表性指标D.序时平均数代表性指标26.在回归分析中,要求对应的两个变量A.都是随机变量B.不是对等关系C.是对等关系D.都不是随机变量27.年劳动生产率(千元)和工人工资(元)之间存在回归方程y=10+70x,这意味着年劳动生产率每提高一千元时,工人工资平均A.增加70元B.减少70元C.增加80元D.减少80元28.设某种产品产量为1000件时,其生产成本为30000元,其中固定成本6000元,则总生产成本对产量的一元线性回归方程为:A.y=6+0.24xB.y=6000+24xC.y=24000+6xD.y=24+6000x29.用来反映因变量估计值代表性高低的指标称作A.相关系数B.回归参数C.剩余变差D.估计标准误差二、多项选择题1.下列现象之间属于相关关系的有A.家庭收入与消费支出之间的关系B.农作物收获量与施肥量之间的关系C.圆的面积与圆的半径之间的关系D.身高与体重之间的关系E.年龄与血压之间的关系2.直线相关分析的特点是A.相关系数有正负号B.两个变量是对等关系C.只有一个相关系数D.因变量是随机变量E.两个变量均是随机变量3.从变量之间相互关系的表现形式看,相关关系可分为A.正相关B.负相关C.直线相关D.曲线相关E.单相关和复相关4.如果变量x与y之间没有线性相关关系,则A.相关系数r=0B.相关系数r=1C.估计标准误差等于0D.估计标准误差等于1E.回归系数b=05.设单位产品成本(元)对产量(件)的一元线性回归方程为y=85-5.6x,则A.单位成本与产量之间存在着负相关B.单位成本与产量之间存在着正相关C.产量每增加1千件,单位成本平均增加5.6元D.产量为1千件时,单位成本为79.4元E.产量每增加1千件,单位成本平均减少5.6元6.根据变量之间相关关系的密切程度划分,可分为A.不相关B.完全相关C.不完全相关D.线性相关E.非线性相关7.判断现象之间有无相关关系的方法有A.对现象作定性分析B.编制相关表C.绘制相关图D.计算相关系数E.计算估计标准误差8.当现象之间完全相关的,相关系数为A.0B.-1C.1D.0.5E.-0.59.相关系数r =0说明两个变量之间是A.可能完全不相关B.可能是曲线相关C.肯定不线性相关D.肯定不曲线相关E.高度曲线相关10.下列现象属于正相关的有A.家庭收入愈多,其消费支出也愈多B.流通费用率随商品销售额的增加而减少C.产量随生产用固定资产价值减少而减少D.生产单位产品耗用工时,随劳动生产率的提高而减少E.工人劳动生产率越高,则创造的产值就越多11.直线回归分析的特点有A.存在两个回归方程B.回归系数有正负值C.两个变量不对等关系D.自变量是给定的,因变量是随机的E.利用一个回归方程,两个变量可以相互计算12.直线回归方程中的两个变量A.都是随机变量B.都是给定的变量C.必须确定哪个是自变量,哪个是因变量D.一个是随机变量,另一个是给定变量E.一个是自变量,另一个是因变量13.从现象间相互关系的方向划分,相关关系可以分为A.直线相关B.曲线相关C.正相关D.负相关E.单相关14.估计标准误差是A.说明平均数代表性的指标B.说明回归直线代表性指标C.因变量估计值可靠程度指标D.指标值愈小,表明估计值愈可靠E.指标值愈大,表明估计值愈可靠15.下列公式哪些是计算相关系数的公式16.用最小平方法配合的回归直线,必须满足以下条件A.∑(y-y c )=最小值B.∑(y-y c )=0C.∑(y-y c )2=最小值D.∑(y-y c )2=0E.∑(y-y c )2=最大值17.方程y c =a+bx222222)()(.)()())((...))((.y y n x x n y x xy n r E y y x x y y x x r D L L L r C L L L r B n y y x x r A xx xy xy yy xx xy yx ∑-∑?∑-∑∑?∑-∑=-∑?-∑--∑===--∑=σσA.这是一个直线回归方程B.这是一个以X为自变量的回归方程C.其中a是估计的初始值D.其中b是回归系数E.y c是估计值18.直线回归方程y c=a+bx中的回归系数bA.能表明两变量间的变动程度B.不能表明两变量间的变动程度C.能说明两变量间的变动方向D.其数值大小不受计量单位的影响E. 其数值大小受计量单位的影响19.相关系数与回归系数存在以下关系A.回归系数大于零则相关系数大于零B.回归系数小于零则相关系数小于零C.回归系数等于零则相关系数等于零D.回归系数大于零则相关系数小于零E.回归系数小于零则相关系数大于零20.配合直线回归方程的目的是为了A.确定两个变量之间的变动关系B.用因变量推算自变量C.用自变量推算因变量D.两个变量相互推算E.确定两个变量之间的相关程度21.若两个变量x和y之间的相关系数r=1,则A.观察值和理论值的离差不存在B.y的所有理论值同它的平均值一致C.x和y是函数关系D.x与y不相关E.x与y是完全正相关22.直线相关分析与直线回归分析的区别在于A.相关分析中两个变量都是随机的;而回归分析中自变量是给定的数值,因变量是随机的B.回归分析中两个变量都是随机的;而相关分析中自变量是给定的数值,因变量是随机的C.相关系数有正负号;而回归系数只能取正值D.相关分析中的两个变量是对等关系;而回归分析中的两个变量不是对等关系E.相关分析中根据两个变量只能计算出一个相关系数;而回归分析中根据两个变量只能计算出一个回归系数三、填空题1.研究现象之间相关关系称作相关分析。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第十二章 相关与回归分析第一节 变量之间的相关关系相关程度与方向·因果关系与对称关系 第二节 定类变量的相关双变量交互分类(列联表)·削减误差比例(PRE )·λ系数与τ系数 第三节 定序变量的相关分析同序对、异序对和同分对·Gamma 系数·肯德尔等级相关系数(τa 系数、τb 与τc 系数)·萨默斯系数(d 系数)·斯皮尔曼等级相关(ρ相关)·肯德尔和谐系数第四节 定距变量的相关分析相关表和相关图·积差系数的导出和计算·积差系数的性质 第五节 回归分析线性回归·积差系数的PRE 性质·相关指数R 第六节 曲线相关与回归可线性化的非线性函数·实例分析(二次曲线指数曲线)一、填空1.对于表现为因果关系的相关关系来说,自变量一般都是确定性变量,依变量则一般是( 随机性 )变量。
2.变量间的相关程度,可以用不知Y 与X 有关系时预测Y 的全部误差E 1,减去知道Y 与X 有关系时预测Y 的联系误差E 2,再将其化为比例来度量,这就是( 削减误差比例 )。
3.依据数理统计原理,在样本容量较大的情况下,可以作出以下两个假定:(1)实际观察值Y 围绕每个估计值c Y 是服从( );(2)分布中围绕每个可能的c Y 值的( )是相同的。
4.在数量上表现为现象依存关系的两个变量,通常称为自变量和因变量。
自变量是作为( 变化根据 )的变量,因变量是随( 自变量 )的变化而发生相应变化的变量。
5.根据资料,分析现象之间是否存在相关关系,其表现形式或类型如何,并对具有相关关系的现象之间数量变化的议案关系进行测定,即建立一个相关的数学表达式,称为( 回归方程 ),并据以进行估计和预测。
这种分析方法,通常又称为( 回归分析 )。
6.积差系数r 是( 协方差 )与X 和Y 的标准差的乘积之比。
二、单项选择1.当x 按一定数额增加时,y 也近似地按一定数额随之增加,那么可以说x 与y 之间 存在( A )关系。
A 直线正相关B 直线负相关C 曲线正相关D 曲线负相关2.评价直线相关关系的密切程度,当r在0.5~0.8之间时,表示( C )。
A 无相关B 低度相关C 中等相关D 高度相关3.相关分析和回归分析相辅相成,又各有特点,下面正确的描述有( D )。
A在相关分析中,相关的两变量都不是随机的;B在回归分析中,自变量是随机的,因变量不是随机的;C在回归分析中,因变量和自变量都是随机的;D在相关分析中,相关的两变量都是随机的。
4.关于相关系数,下面不正确的描述是( B )。
≤r1时,表示两变量不完全相关;A当0≤B当r=0时,表示两变量间无相关;C两变量之间的相关关系是单相关;D如果自变量增长引起因变量的相应增长,就形成正相关关系。
5.欲以图形显示两变量X和Y的关系,最好创建( D )。
A 直方图B 圆形图C 柱形图D 散点图6.两变量X和Y的相关系数为0.8,则其回归直线的判定系数为( C )。
A 0.50B 0.80C 0.64D 0.907.在完成了构造与评价一个回归模型后,我们可以( D )。
A 估计未来所需样本的容量B 计算相关系数和判定系数C 以给定的因变量的值估计自变量的值D 以给定的自变量的值估计因变量的值8.两变量的线性相关系数为0,表明两变量之间( D )。
A 完全相关B 无关系C 不完全相关D 不存在线性相关9.身高和体重之间的关系是( C )。
A 函数关系B 无关系C 共变关系D 严格的依存关系10.在相关分析中,对两个变量的要( A )。
A 都是随机变量B 都不是随机变量C 其中一个是随机变量,一个是常数D 都是常数11.在回归分析中,两个变量( D )。
A 都是随机变量B 都不是随机变量C 自变量是随机变量D 因变量是随机变量12.一元线性回归模型和多元线性回归模型的区别在于只有一个( B )。
A 因变量B 自变量C 相关系数D 判定系数13.以下指标恒为正的是( D )。
A 相关系数rB 截距aC 斜率bD 复相关系数14.下列关系中,属于正相关关系得是( A )。
A 身高与体重B 产品与单位成本C 正常商品的价格和需求量D 商品的零售额和流通费率三、多项选择1.关于积差系数,下面正确的说法是( ABCD )。
A 积差系数是线性相关系数B 积差系数具有PRE性质C 在积差系数的计算公式中,变量X和Y是对等关系D 在积差系数的计算公式中,变量X和Y都是随机的2.关于皮尔逊相关系数,下面正确的说法是()。
A 皮尔逊相关系数是线性相关系数B 积差系数能够解释两变量间的因果关系C r公式中的两个变量都是随机的D r的取值在1和0之间E 皮尔逊相关系数具有PRE性质,但这要通过r2加以反映3.简单线性回归分析的特点是( ABE )。
A 两个变量之间不是对等关系B 回归系数有正负号C 两个变量都是随机的D 利用一个回归方程,两个变量可以互相推算E 有可能求出两个回归方程4.反映某一线性回归方程y=a+bx好坏的指标有( ABD )。
A 相关系数B 判定系数C b的大小D 估计标准误E a的大小5.模拟回归方程进行分析适用于( ACDE )。
A 变量之间存在一定程度的相关系数B 不存在任何关系的几个变量之间C 变量之间存在线性相关D 变量之间存在曲线相关E 时间序列变量和时间之间6.判定系数r2=80%和含义如下( ABC )。
A 自变量和因变量之间的相关关系的密切程度B 因变量y的总变化中有80%可以由回归直线来解释和说明C 总偏差中有80%可以由回归偏差来解释D 相关系数一定为0.64E 判定系数和相关系数无关7.回归分析和相关分析的关系是( ABE )。
A 回归分析可用于估计和预测B 相关分析是研究变量之间的相互依存关系的密切程度C 回归分析中自变量和因变量可以互相推导并进行预测D 相关分析需区分自变量和因变量E 相关分析是回归分析的基础8.以下指标恒为正的是( BC )。
A 相关系数B 判定系数C 复相关系数D 偏相关系数E 回归方程的斜率9.一元线性回归分析中的回归系数b可以表示为(BC)A 两个变量之间相关关系的密切程度B 两个变量之间相关关系的方向C 当自变量增减一个单位时,因变量平均增减的量D 当因变量增减一个单位时,自变量平均增减的量E 回归模型的拟合优度10.关于回归系数b ,下面正确的说法是( )。
A b 也可以反映X 和Y 之间的关系强度。
; B 回归系数不解释两变量间的因果关系; C b 公式中的两个变量都是随机的;D b 的取值在1和-1之间;E b 也有正负之分。
四、名词解释1.消减误差比例变量间的相关程度,可以用不知Y 与X 有关系时预测Y 的误差0E ,减去知道Y 与X 有关系时预测Y 的误差1E ,再将其化为比例来度量。
将削减误差比例记为PRE 。
2. 确定性关系当一个变量值确定后,另一个变量值夜完全确定了。
确定性关系往往表现成函数形式。
3.非确定性关系在非确定性关系中,给定了一个变量值,另一个变量值还可以在一定围变化。
4.因果关系变量之间的关系满足三个条件,才能断定是因果关系。
1)连个变量有共变关系,即一个变量的变化会伴随着另一个变量的变化;2)两个变量之间的关系不是由其他因素形成的,即因变量的变化是由自变量的变化引起的;3)两个变量的产生和变化有明确的时间顺序,即一个在前,另一个在后,前者称为自变量,后者称为因变量。
5.单相关和复相关单相关只涉及到两个变量,所以又称为二元相关。
三个或三个以上的变量之间的相关关系则称为复相关,又称多元相关。
6.正相关与负相关正相关与负相关:正相关是指一个变量的值增加时,另一变量的值也增加;负相关是指一个变量的值增加时,另一变量的值却减少。
7.散点图散点图:将相关表所示的各个有对应关系的数据在直角坐标系上画出来,以直观地观察X 与Y 的相互关系,即得相关图,又称散点图。
8.皮尔逊相关系数r皮尔逊相关系数是协方差与两个随机变量X 、Y 的标准差乘积的比率。
9.同序对在观察X 序列时,如果看到i j X X <,在Y 中看到的是i j Y Y <,则称这一配对是同序对。
10.异序对在观察X 序列时,如果看到i j X X <,在Y 中看到的是i j Y >Y ,则称这一配对是异序对。
11.同分对如果在X 序列中,我们观察到i j X =X (此时Y 序列中无i j Y =Y ),则这个配对仅是X 方向而非Y 方向的同分对;如果在Y 序列中,我们观察到i j Y =Y (此时X 序列中无i j X =X ),则这个配对仅是Y 方向而非X 方向的同分对;我们观察到i j X =X ,也观察到i j Y =Y ,则称这个配对为X 与Y 同分对。
五、判断题1.由于削减误差比例的概念不涉及变量的测量层次,因此它的优点很明显,用它来定义相关程度可适用于变量的各测量层次。
(√)2.不管相关关系表现形式如何,当r=1时,变量X和变量Y都是完全相关。
(√)3.不管相关关系表现形式如何,当r=0时,变量X和变量Y都是完全不相关。
(×)4.通过列联表研究定类变量之间的关联性,这实际上是通过相对频数条件分布的比较进行的。
而如果两变量间是相关的话,必然存在着Y的相对频数条件分布相同,且和它的相对频数边际分布相同。
(×) 5.如果众数频数集中在条件频数分布列联表的同一行中, 系数便会等于0,从而无法显示两变量之间的相关性。
(√)6.从分析层次上讲,相关分析更深刻一些。
因为相关分析具有推理的性质,而回归分析从本质上讲只是对客观事物的一种描述,知其然而不知其所以然。
(×)六、计算题1.对某市市民按老中青进行喜欢民族音乐情况的调查,样本容量为200人,调查结果示于下表,试把该频数列联表:①转化为相对频数的联合分布列联表②转化为相对频数的条件分布列联表;③指出对于民族音乐的态度与被调查者的年岁有无关系,并说明理由。
2.已知十名学生身高和体重资料如下表,(1)根据下述资料算出身高和体重的皮尔逊相关系数和斯皮尔曼相关系数;(2)根据下述资料求出两变量之间的回归方程(设身高为自变量,体重为因变量)。
3.假定有不同文化程度的35~45岁育龄妇女100人的生育情况如下表,求文化程度与平均生育数的相关系数r。
4.某市有12所大专院校,现组织一个评审委员会对各校校园及学生体质进行评价,结果如下,试求环境质量与学生体质的关系的斯皮尔曼相关系数和肯得尔等级相关系数。
【斯皮尔曼相关系数:0.94,肯德尔等级相关系数:0.83】5.以下是婚姻美满与文化程度的抽样调查的结果,请计算婚姻美满与文化程度之Gamma 【τc =0.18】 6.以下为两位评判员对10名参赛人名次的打分。