数据分析(梅长林)第1章习 题答案
第三章数据分析(梅长林)习题答案
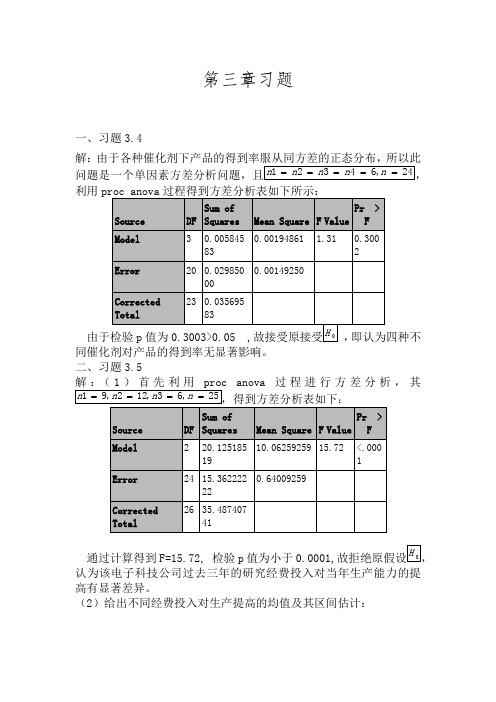
第三章习题一、习题3.4解:由于各种催化剂下产品的得到率服从同方差的正态分布,所以此利用proc anova过程得到方差分析表如下所示:同催化剂对产品的得到率无显著影响。
二、习题3.5anova过程进行方差分析,其通过计算得到F=15.72, 检验p值为小于0.0001,认为该电子科技公司过去三年的研究经费投入对当年生产能力的提高有显著差异。
(2)给出不同经费投入对生产提高的均值及其区间估计:为95%的置信区间为:95%的Bonferroni 同时置信区间为:Bonferroni 同时置信区间都位于负值区间可知随着三年科研经费的投入越高,当年生产能力的改善越显著。
三、习题3.6解:(1)首先利用SAS 的proc anova 过程的means 语句,求出各水平的均值和标准差:如下所示:由上表可知,(a1,b1)组合和(a1,b3)组合的标准差分别为2.030875、2.8067751与其他组合的标准差相差较大,所以我认为假定误差的等方差性不太合理。
故不能直接进行方差分析。
(2)由(1)可知直接进行方差分析是不合理的,所以对观测数据做对数变换,首先来分析个水平组合是否是方差齐性的。
由以上结果可以看出各组合水平上的标准差趋于一致,各组之间的标准差差异比较小。
说明各组合的离散程度比较接近。
故可以利用变换之后的数据在进行方差分析。
(3)由SAS系统的proc anova过程对进行自然对数变换后的数据进行方差分析,得到如下的误差分析表:x1*x2的影响是不显著的,检验P=0.3143>0.05,即两种铁离子残留量的百分比差异在不同剂量水平下可认为是相同的。
而由因素A和因素B对残留量的百分比的影响均显著,检验P值分别为0.0161和<.0001,所以两种铁离子残留量的百分比是有显著差异的,不同剂量水平下残留量的百分比也是有显著差异的。
(4)求出各因素在不同水平下的均值以及估计区间:SAS系统的proc anova过程对数据进行方差分析,得到各因素两两的Bonferroni同时置信区间为:均值之差的置信度为95%(注:可编辑下载,若有不当之处,请指正,谢谢!)。
数据分析方法实验(范金城梅长林)习题报告

习题4.5实验报告一、实验目的问题描述:在习题1.5表1.9中,列出了历年人口出生率、死亡率和自然增长率(单位:%)。
设对应于人口出生率、人口死亡率、自然增长率的数据变量分别为x1,x2,x3。
(1)分别从样本协方差矩阵S及样本相关矩阵R出发,求x1,x2,x3的样本主成分y1,y2,计算各样本主成分的贡献率。
(2)分别从样本协方差矩阵S及样本相关矩阵R出发,将第一样本主成分y1从小到大排序,并给与分析。
二、所用方法及工具(1)主成分分析法与贡献率:主成分分析法即构造原变量的一系列线性组合,使各线性组合在彼此不相关的前提下尽可能多地反映原变量的信息,即使其方差最大。
求的各主成分,等价于求它的协方差矩阵的各特征值及相应的正交单位化特征向量.按特征值由大到小所对应的正交单位化特征向量为组合系数的X,Xz ,…,X,的线性组合分别为X的第一,第二、直至第p个主成分,而各主成分的方差等于相应的特征值。
(2)SAS编程:SAS语言是一种专用的数据管理与分析语言,它提供了一种完善的编程语言。
类似于计算机的高级语言,SAS用户只需要熟悉其命令、语句及简单的语法规则就可以做数据管理和分析处理工作。
因此,掌握SAS编程技术是学习SAS的关键环节。
在SAS中,把大部分常用的复杂数据计算的算法作为标准过程调用,用户仅需要指出过程名及其必要的参数。
这一特点使得SAS编程十分简单。
三、实验内容本次实验采用SAS编程实现,代码如下:data a;set sjfx.rk1;run;proc princomp n=2 cov out=out1;var x1 x2 x3;run;proc sort data=out1 out=a1;by prin1;run;proc print data=a1;run;proc princomp n=2 out=out2;var x1 x2 x3;run;proc sort data=out2 out=a2;by prin1;run;proc print data=a2;run;实验结果:PRINCOMP 过程。
数据分析答案完整版(整理)

x n n x j ( x j x) n 1 n 1 n 1
n2
x j x( j ) x j
服 从 正 态 分 布 。 故 有 E xi x E i
1 n j 0 , n j 1
1 n 1 n n 1 2 D xi x D i j E i j ,故 xi x 服从分 n n n j 1 j 1
N (0, 2 I n ) , (1 , 2 ,
, n ) ,则
,1 .
N (0, 2 ( I n H n )) 。其中:
1
1 1 n 1 , H n n 1, n 1 1
n n 1
n 1 n 2 n n 1 2
——证毕—— 3.条件同第 2 题,证明: (1) x N 0, n
2
(2) N 1 S 2 / 2 x2 n 1 , (4 ) t n
x t n 1
由与此变换为正交变换知, yi 2 xi 2 ,同时 x1 , x2 , , xn 为相互独
i 1 i 1
n
n
立的正态分布。
密度函数 f x1 , x2 ,
xi 1 2 2 i 1 由于正交的雅可比行列 , xn e 2 n
2
1 , n 1 , 1 ,由正交性有 n 1
2 , 3n,
a
第2章 数据分析(梅长林)习题题答案
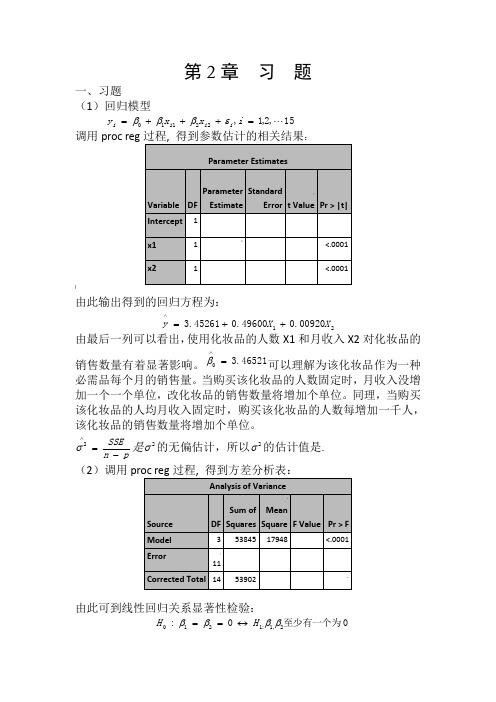
第2章 习 题一、习题(1)回归模型15,2,1,22110 =+++=i x x y i i i i εβββ调用proc reg:]由此输出得到的回归方程为:2100920.049600.045261.3X X y ++=∧由最后一列可以看出,使用化妆品的人数X1和月收入X2对化妆品的销售数量有着显著影响。
46521.30=∧β可以理解为该化妆品作为一种必需品每个月的销售量。
当购买该化妆品的人数固定时,月收入没增加一个一个单位,改化妆品的销售数量将增加个单位。
同理,当购买该化妆品的人均月收入固定时,购买该化妆品的人数每增加一千人,该化妆品的销售数量将增加个单位。
pn SSE-=∧2σ是2σ的无偏估计,所以2σ的估计值是. (2)调用由此可到线性回归关系显著性检验:0至少有一个为0:2,1:1210ββββH H ↔==的统计量/(1)/()SSR p MSRF SSE n p MSE-==-的观测值47.56790=F ,检验的p 值0001.0)(000<>==F F p p H另外9989.053902538452===SST SSR R ,2R 描述了由自由变量的线性关系函数值所能反映的Y 的总变化量的比例。
2R 越大,表明线性关系越明显。
这些结果均表明Y 与X1,X2之间的回归关系高度显著。
(3)若置信水平05.0=α,由17881.2)12(975.0=t ,利用参数估计值得到21,0,βββ的置信区间分别为:对,0β2942.54516.343065.21781.245216.3±=⨯±,即)7458.8,8426.1(-) 对1β:01318.049600.000605.01781.249600.0±=⨯±,即)50198.0,48282.0( )2β:0021.000920.00009681.01781.200920.0±=⨯±,即)00113.0,0071.0(-(4)首先检验X1对Y 是否有显著性影:假设其约简模型为:15,2,1,220 =++=i x y i i i εββ 由观测数据并利用proc reg 过程拟合此模型求得:88137.484)(=R SSE 13215=-=R f 88357.56)(=F SSE 12315=-=R f由[()()]()()/R F FSSE R SSE F f f F SSE F f --=求得检验统计量的值为:3.9012/88357.5688357.5688137.4840=-=F05.0))13,1(()(0000<>==>==F F P F F p p H由此拒绝原假设,所以x2对Y 有显著影响。
数据分析方法课后答案

数据分析方法课后答案【篇一:数据的分析练习题及答案】、选择题:(每题3分,共15分)1.小明家要买台电脑,下面是甲、乙、丙三种电脑近几年来的销量,如果小明想买一台近期比较流行的电脑,他应买()a.甲b.乙c.丙2.小李是个彩票迷,为了能得奖,他特意询问了前15天的中奖号码分别是:519、、706、328、556、768、215、435、741、624、307、821、696、741、471、285. 你认为这样的观点是否合理()a.不合理b.合理3.小靖想买双好的运动鞋,于是她上网查找有关资料,得到下表:她想买一双价格在300-600元之间,且她喜欢白色、红白相间、浅绿或淡黄色, 并且防水性能很好,那么她应选()a.甲b.乙c.丙d.丁4.为了计算植树节时本班同学所种植的30棵树苗的平均高度, 三位同学先将所有树苗的然后,他们分别这样计算这30棵树苗的平均高度:130130列式正确的是()a.(1)b.(1)和(2);c.(1)和(3)d.(2)和(3)5.某班在一次物理测试中的成绩为:100分7人,90分14人,80分17人,70分8人, 60分2人,50分2人.则该班此次测试的平均成绩为() a.82分b.62分c.64分d.75分二、填空题:(每题4分,共20分)6.一次知识竞赛中,36名参赛选手的得分情况为:5人得75分,8人得80分,6 人得85分,8人得90分,7人得95 分, 2 人得100 分, 要计算他们的平均得分, 可列算式:_____________.(1)7.某校九年级6个班级的学生的人数和平均体重如下表:要计算全校学生的平均体重,可列算式________,平均体重约为__________.8.某家庭搬进新居后,又添置了新的家用电器,为了了解用电量的大小, 该家庭在6月初连续几天观察电表的度数,如下表所示:9.为了解我国14岁男孩的平均身高,从北方抽取了300个男孩,平均身高1.60m; 从南方抽取了200个男孩,平均身高为1.50m;若北方14岁男孩数与南方14岁男孩数的比为3:2,由此可推断我国14岁男孩的平均身高约为______m.10.小明先用5千米/时的速度行驶3小时后,又用4千米/时的速度行驶5小时到达目的地,则小明的平均速度为________. 三、解答题:(每题9分,共54分)11.某同学对他在本学期的自我检测成绩进行了统计:95分的有12次,90 分的有10次,85分的有15次,80分的有3次,75分的有1次,65分的有3次.试计算该同学本学期自我检测的平均成绩..12.超市里要举行转盘摇奖活动,转盘如图所示,买满100元可摇奖一次,有人说:如果大家都摇到自行车,那么超市岂不是亏本了?如果你是超市决策者,会不会因此而改变有奖销售的方案呢?说说你的理由?自行车300元洗洁精2.80元酱油5.0元西红柿2.00元墨水3.50元13.请你根据上表比较这两个国家的数据,你能得出什么结论?14.由于水资源贫乏,节约用水非常重要,请你调查一下,本班每位学生所在家庭的月人均用水量,并据此制作频数分布图,同时估计一下当地家庭的月人均用水量.15.爸爸给小明一串钥匙,共有4把,小明决定先试试哪把是防盗门的钥匙. 请你用模拟实验方法估计一下,他第1次试开就成功的机会有多大?16.转动如图所示的转盘两次,每次指针都指向一个数字. 如果两次所指的数字之积是质数,游戏者a得10分;乘积不是质数,游戏者b得10分.你认为这个游戏公平吗?如果你认为这个游戏不公平,你愿意做游戏者a还是游戏者b?为什么?31246517.有人对记忆和遗忘的规律进行研究,人在记忆过某些知识后, 在不同时间段对其进行测试,结果如下表:分析测试结果,在图中绘制曲线图,并回答遗忘在数量上的变化规律.记忆效果1%记忆的保持曲线图答案:一、1.b 2.a 3.d 4.d 5.a148?50?49.8?46?50.2?55?49.5?48?51?52?50.3?547., 49.8kg50?46?55?48?52?54358.387.75 9.1.56 10.千米/时8三、144所以,美国的吸烟总人数和每天吸烟的总数都大于日本,但吸烟人口占总人口的比例小于日本.14.列出调查表,对本班学生实事求是地进行调查以获得真实的信息.15.可用4个相同的球,1个白的,3个黑的,每次抽1个,则第1次抽到白球的概率为所求概率,1为. 41516.不公平,愿做b 解:乘积是质数的概率是,乘积不是质数的概率是, 游戏不公平,故66愿做b.17.遗忘曲线表明了遗忘在数量上的变化规律,遗忘的数量随时间的前进而递增;这种递增先快后慢,在识记后的短时间内特别迅速,然后逐渐缓慢下来.二、6.记忆效果1%/d记忆的保持曲线图【篇二:定性数据分析第三章课后答案】9、对72个可疑患者用两种不同的方法进行检测,检测结果如下:问:检测方法1阳性和阴性的比例是否与检测方法2阳性和阴性的比例相同?解:(1)提出原假设根据题意,我们假设检测方法1阳性和阴性的比例与检测方法2阳性和阴性的比例是相同。
数据分析答案梅长林

数据分析答案梅长林【篇一:1.1一维数据数字特征】013学年第一学期主讲教师李晓燕课程名称数据分析课程类别专业限选课学时及学分 68;4授课班级信息101 102使用教材《数据分析方法》系(院.部) 数理系教研室(实验室) 信息和计算科学教研室数据分析总学时:68 理论38.上机28 适用专业:信息和计算科学内容:? sas软件介绍 3学时 ? 数据的描述性分析10学时 ? 线性回归分析 13学时 ? 方差分析 10学时 ? 主成分分析和典型相关分析8学时? 判别分析 8学时 ? 聚类分析 8学时 ? 学生报告 8学时教材:《数据分析方法》,梅长林、范金城编,高等教育出版社.2006. 参考资料:《实用统计方法》,梅长林编,科学出版社;《使用多元统计分析》,高惠璇编,北京大学出版社,2005;《使用统计方法和sas系统》,高惠璇编,北京大学出版社,2001;《多元统计分析》(二版),何晓群编,中国人民大学出版社,2008;《使用回归分析》(二版),何晓群编,中国人民大学出版社,2007;《统计建模和r软件》,薛毅编著,清华大学出版社,2007. 考核:期末成绩(闭卷测试+上机测试):70%。
平时成绩(平时作业+考勤+大报告):30%。
课程作业(1)作业题目在网络教学平台公布,按格式要求,以电子版方式通过平台提交。
(2)大报告:2-3人一组,每组一个选题,成员按相同的成绩计分。
收集数据,撰写小论文,做ppt讲解。
每组讲10-20分钟,提问环节。
同学打分。
课时授课计划课次序号: 01一、课题:1.1 一维数据的数字特征及相关系数二、课型:新授课三、目的要求:1.掌握数据的数字特征(均值、方差等);2.掌握几种描述性分析的sas过程和作图过程计算这些数字特征及进行描述性分析.四、教学重点:均值、方差等数字特征.教学难点:基本概念的理解.五、教学方法及手段:传统教学和上机实验相结合.六、参考资料:1.《实用统计方法》,梅长林,周家良编,科学出版社;2.《sas统计分析使用》,董大钧主编,电子工业出版社.七、作业:1.1八、授课记录:九、授课效果分析:0 绪论0.1 课程内涵数据分析(即多元统计学statistics):是以数据为依据,以统计方法为理论、计算机及软为工具,研究多变量问题、挖掘数据的统计规律的学科. 通过收集数据、整理数据、分析数据和由数据得出结论的一组概念、原则和方法。
数据分析参考答案

数据分析参考答案数据分析参考答案数据分析是一项重要的技能,它帮助我们从大量的数据中提取有用的信息和洞察力。
在当今信息爆炸的时代,数据分析已经成为了各行各业的必备技能。
无论是企业决策、市场营销还是科学研究,数据分析都扮演着重要的角色。
在本文中,我将提供一些数据分析的参考答案,帮助读者更好地理解和应用数据分析。
首先,数据分析的第一步是数据清洗和整理。
在进行数据分析之前,我们需要确保数据的质量和准确性。
这包括删除重复数据、处理缺失值、解决异常值等。
只有经过清洗和整理的数据才能真正反映出问题的本质和规律。
其次,数据分析需要选择合适的方法和工具。
根据问题的性质和数据的类型,我们可以选择不同的数据分析方法。
常见的数据分析方法包括描述性统计、推断统计、机器学习等。
同时,我们还需要选择适合的数据分析工具,如Excel、Python、R等。
选择合适的方法和工具可以提高数据分析的效率和准确性。
第三,数据可视化是数据分析的重要环节。
通过数据可视化,我们可以将抽象的数据转化为直观的图表和图形,更好地理解数据的分布和趋势。
数据可视化不仅可以提高数据分析的效果,还可以帮助我们向他人传达分析结果。
在进行数据可视化时,我们需要选择适当的图表类型,如柱状图、折线图、散点图等,以及合适的颜色和字体。
第四,数据分析需要进行合理的假设和推断。
在进行数据分析时,我们需要建立合理的假设,并通过数据进行验证。
通过统计方法和推断统计学,我们可以对数据进行推断和预测。
然而,我们需要注意的是,数据分析只能提供相关性而非因果性的结论。
因此,在进行数据分析时,我们需要谨慎解读结果,并避免错误的推断。
最后,数据分析需要不断的学习和实践。
数据分析是一个不断发展和演进的领域,新的方法和工具不断涌现。
为了保持竞争力,我们需要不断学习新的数据分析技术,并将其应用到实际问题中。
同时,我们还需要通过实践不断提高自己的数据分析能力,不断优化分析结果和方法。
综上所述,数据分析是一项重要的技能,它帮助我们从大量的数据中提取有用的信息和洞察力。
最新第2章 数据分析(梅长林)习题题答案
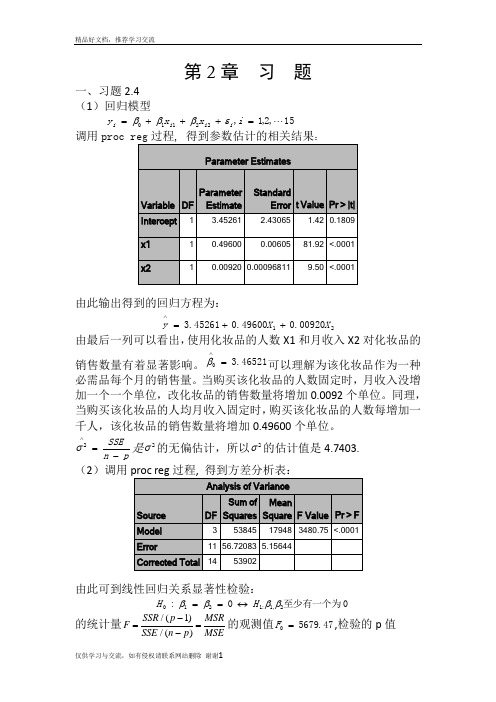
第2章 习 题一、习题2.4 (1)回归模型15,2,1,22110 =+++=i x x y i i i i εβββ调用:由此输出得到的回归方程为:2100920.049600.045261.3X X y ++=∧由最后一列可以看出,使用化妆品的人数X1和月收入X2对化妆品的销售数量有着显著影响。
46521.30=∧β可以理解为该化妆品作为一种必需品每个月的销售量。
当购买该化妆品的人数固定时,月收入没增加一个一个单位,改化妆品的销售数量将增加0.0092个单位。
同理,当购买该化妆品的人均月收入固定时,购买该化妆品的人数每增加一千人,该化妆品的销售数量将增加0.49600个单位。
pn SSE-=∧2σ是2σ的无偏估计,所以2σ的估计值是4.7403. (2)调用由此可到线性回归关系显著性检验:0至少有一个为0:2,1:1210ββββH H ↔== 的统计量/(1)/()SSR p MSRF SSE n p MSE-==-的观测值47.56790=F ,检验的p 值0001.0)(000<>==F F p p H另外9989.053902538452===SST SSR R ,2R 描述了由自由变量的线性关系函数值所能反映的Y 的总变化量的比例。
2R 越大,表明线性关系越明显。
这些结果均表明Y 与X1,X2之间的回归关系高度显著。
(3)若置信水平05.0=α,由17881.2)12(975.0=t ,利用参数估计值得到21,0,βββ的置信区间分别为:对,0β2942.54516.343065.21781.245216.3±=⨯±,即)7458.8,8426.1(-) 对1β:01318.049600.000605.01781.249600.0±=⨯±,即)50198.0,48282.0( 2β:0021.000920.00009681.01781.200920.0±=⨯±,即)00113.0,0071.0(-(4)首先检验X1对Y 是否有显著性影:假设其约简模型为:15,2,1,220 =++=i x y i i i εββ 由观测数据并利用proc reg 过程拟合此模型求得:88137.484)(=R SSE 13215=-=R f 88357.56)(=F SSE 12315=-=R f由[()()]()()/R F FSSE R SSE F f f F SSE F f --=求得检验统计量的值为:3.9012/88357.5688357.5688137.4840=-=F05.0))13,1(()(0000<>==>==F F P F F p p H由此拒绝原假设,所以x2对Y 有显著影响。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第1章 习 题
一、习题1.1
解:(1)利用题目中的数据,通过SAS 系统proc univariate 过程计算得到:
139.0=x 7.06387S =
49.898312=S 0.142众数=
51.0g 1-= 08192.5=CV
126129.0g 2-=由得到的数据特征可知道,偏度为负,所以呈做偏态,
峰度为负,所以均值两侧的极端值较少。
(2) 139.0=M 31.0=R
0.135Q 1= 5.144Q 3= 5.9R 131=-=Q Q
375.1394
1
2141M 31=++=
∧
Q M Q (3) 通过SAS 系统proc capability 得到直方图,并拟合正态分布曲线:
(4) 通过SAS 系统proc univariate 可以画出茎叶图,从茎叶图可以看出数据大致呈对称分布,由于所给数据都是整数,所以叶所代表的小位数都是0。
(5) 通过SAS 系统proc univariate 过程计算得到:
0.971571W 0= 00()H p P W W =≤= 0.1741
取0.05=α,因α>=0.1742p ,故不能拒绝0H ,认为样本来自正态总体分布。
通过画QQ图和经验分布曲线和理论分布函数曲线,从图中可以看出QQ图近似的在一条直线上,经验分布曲线的拟合程度也相当好,所以可以进一步说明此样本来自正态总体分布。
二、习题1.2
7.8574027=x 1.62568785 S =
2.642860982=S
0.13721437g 1= 20.6898884=CV -1.4238025g 2=
由得到的数据特征可知道,偏度为正,所以呈右偏态,峰度为负,所以均值两侧的极端值较少。
(2)
7.636800=M 5.03650=R
6.5859 Q 1= 9.3717Q 3= 2.78580R 131=-=Q Q
809.74
1
2141M 31=++=
∧
Q M Q (3)通过SAS 系统proc capability 得到直方图,SAS 系统自动将数据分为中值为4.5,5.5,6.5,7.5,8.5,9.5,10.5的7组,图中纵坐标代表了各个区间的频数占总数的百分比。
(4)通过SAS 系统proc univariate 可以画出茎叶图,从图中可以看出数据散乱分布,没有明显的对称等特征。
三、习题3.3
(1)
全国居民的消费的均值、标准差、变异系数、偏度、峰度:
1117.000=x 1016 S =
10316802=S
1.02485g 1= 933.90=CV -0.457g 2=
农村居民的消费均值、标准差、变异系数、偏度、峰度:
747.864=x 632.1976 S =
399673.8382=S
1.01256g 1= 84.54=CV -0.414g 2=
城市居民的消费均值、标准差、变异系数、偏度、峰度
2336.41=x 2129.82 S =
4536136.442=S
0.97046g 1= 91.158=CV -0.57316g 2=
(2)
全国居民消费的中位数、上下四分位数、四分位极差、三均值:
727.500=M 2996=R
311.0 Q 1= 1746.0Q 3= 1435R 131=-=Q Q
8784
1
2141M 31=++=
∧
Q M Q
农村居民消费的中位数、上下四分位数、四分位极差、三均值:
530.5=M 1836=R
246.0 Q 1= 1118.0Q 3= 872R 131=-=Q Q
6064
1
2141M 31=++=
∧
Q M Q 城市居民消费的中位数、上下四分位数、四分位极差、三均值
1449.500=M 6246=R
603 Q 1= 3891.0Q 3= 3288R 131=-=Q Q
5.16974
1
2141M 31=++=
∧
Q M Q (3)
全国居民消费直方图
农村居民消费直方图
城市居民消费直方图
(4)全国居民消费茎叶图:由图中可以看出,在我国居民消费水平参差不齐,其中低消费水平的居民占绝大多数,这说明我国经济水平还是比较落后的。
农村居民消费茎叶图:由图中可以看出,在我国农村居民消费水平普遍比较低,其中消费水平差异很大,有一部分的消费水平相对较高,而另一部分消费水平相对较低,因此农村发展要均衡,先富带动后富,最终共同加快农村发展。
城市居民消费茎叶图:由图中可以看出,在我国城市居民消费水平差距很大,虽然普遍高于农村,但是绝大多数人的消费水平是远远低于高消费人群。
(5)通过计算可以得到全国居民消费水平的山下截断点分别为-1841.5和3898。
5,所以全国居民消费水平无异常值。
全国居民消费水平的山下截断点分别为-1062和2488,所以全国农村居民消费水平无异常值。
全国居民消费水平的山下截断点分别为-4329和8823,所以全国城市居民消费水平无异常值。
四、习题1.4 (1)
11月预收入的均值、标准差、变异系数、偏度、峰度:
19.166=x 19.780 S =
392.0312=S
2.51535g 1= 304.103=CV 8.267g 2=
1-11月预收入的均值、标准差、变异系数、偏度、峰度:
246.139=x 232.972 S =
54275.9982=S
1.916g 1= 630.94=CV -4.385g 2=
(2)11月预收入的中位数、上下四分位数、四分位极差、三均值:
14.77=M 98.55=R
6.24 Q 1= 120.32Q 3= 14.10R 131=-=Q Q
025.394
1
2141M 31=++=
∧
Q M Q 1-11月预收入的中位数、上下四分位数、四分位极差、三均值:
179.41=M 1074=R
103.81 Q 1= 273.29Q 3= 169.48R 131=-=Q Q
98.1834
1
2141M 31=++=
∧
Q M Q (3)
11月预收入x1的的直方图:
1-11月预收入x2的直方图:
(4)
11月预收入x1的经验分布函数曲线:
通过画QQ图和经验分布曲线和理论分布函数曲线,从图中可以看出QQ图近似的在直线右下方,所以偏度<0,经验分布曲线的拟合程度也不好,所以不能说明此样本来自正态总体分布。
1-11月预收入x2的经验分布函数曲线:
通过画QQ图和经验分布曲线和理论分布函数曲线,从图中可以看出QQ图近似的在直线右下方,所以偏度<0,经验分布曲线的拟合程度也不好,所以不能说明此样本来自正态总体分布。
(5)利用proc corr 过程计算数据的Pearson 相关系数:
0.97625 21 x x r
检验p 值小于0.0001,故X1,X2的相关性是显著的。
利用proc corr 过程计算数据的Spearman 相关系数:
0.92782 21=x x r
检验p 值小于0.0001,故X1,X2的相关性是显著的。
五、习题1.5
(1)总体均值μ的估计
)76667.3350476.486667.2721905.18(=∧
μ
(2)总体协方差矩阵∑的估计(只写出了上三角的部分):
⎥
⎥
⎥
⎥
⎦
⎤
⎢⎢⎢
⎢
⎣
⎡=0323.47397.19985.12893.11387
.13.5593 1.26571.1094
2.7072
3.5086S
六、习题1.6
(1)由proc corr 过程求得的中位数向量M :
)10000.3480000.440000.271000.18(=M
(2)由proc corr 得到的Pearson 相关系数矩阵R:
(3) 由proc corr 得到的Spearman 相关系数矩阵Q:
(4)由Pearson 相关矩阵的输出结果看,显著性水平取0.1=α,则
3424231312,,,,r r r r r 的p 值皆小于0.1=α,故认为各相应随机变量的显
著相关。
由Spearman 相关矩阵的输出结果看,显著性水平取0.1=α,则
342423141312,,,,,q q q q q q 的p 值皆小于0.1=α,故认为各相应随机变量的
显著相关。
七、习题1.7 (1)数据均值向量:
)23.402.1641.14(=x
数据的中位数向量:
)00.400.1500.15(M =
(2)由proc corr 求得的Pearson 相关系数矩阵:
由proc corr 求得的Spearman 相关系数矩阵:
(3) 由Pearson 相关矩阵的输出结果看,显著性水平取0.05=α,则
231312,,r r r 的p 值皆小于0.05=α,故认为各相应随机变量的显著相关。
由Spearman 相关矩阵的输出结果看,显著性水平取0.05=α,则
,,,231312q q q 的p 值皆小于0.05=α,故认为各相应随机变量的显著相
关,和利用Spearson 相关矩阵的结果一样。
因此这些随机变量显著相关。