空间面板数据分析——R的splm包资料
空间统计方法-空间面板模型及案例分析,R实现代码

空间分析方法-空间面板模型及案例分析1.1 空间面板模型我们生活在时间和空间中,每个事件都在一定的时间和地点发生,因而可以标度出时间和空间坐标,这样的数据可以称为空间面板数据,它是指一定空间单元的时间序列观测。
在研究实际问题时,空间面板数据本身具有更大自由度、更丰富的信息量、更多的变异。
空间面板模型(Spatial Panel Model )是针对空间面板数据分析而提出的模型。
相对于一般的回归模型及空间回归模型,它能够提参数高估计的有效性。
空间模型在寻求科学解释方面有着重要的作用。
通过空间面板模型,可以更好地结合研究对象的时空分布特征,发现其影响因素及规律。
空间面板模型可分为两类:空间滞后模型和空间误差模型。
(1)空间滞后模型(Spatial Lag Model)空间滞后模型的基础形式为1N 'it ij jt it i itj y W y X δβμε==+++∑(6.2)其中,δ:空间自相关系数,表示空间个体之间的相互作用W :空间权重矩阵,含义与第七章所述的空间权重矩阵相同123i ,,,N =…,:横截面上的个体(某一区域、范围等),共有N 个 123t ,,,T =…,:表示时间序列上的时点(某一时刻),共有T 个 it y :在区域i 、时刻t 上的被解释变量itX :在区域i 、时刻t 上的解释变量 i μ:空间的个体的效应,反映不受时间影响的空间特质。
β:回归系数it ε:与时间和空间都有关系的随机误差项,其均值为0,方差为2σ,独立同分布。
空间滞后模型主要在传统面板模型的基础上考虑了空间上的自相关,可以度量不同空间个体的相互影响。
(2) 空间误差模型(Spatial Error Model )空间误差模型基本形式为'it it i ity X βμϕ=++ 1N it ij jt itj W ϕρϕε==+∑其中:ρ:空间自相关系数,反映回归残差之间空间相关性的程度。
时空 数据 r语言

时空数据 r语言时空数据R语言时空数据是指具有时间和空间属性的数据,它广泛存在于各个领域,如气象、交通、环境监测等。
处理和分析时空数据对于许多应用领域都是非常重要的。
R语言作为一种强大的统计计算和图形化工具,提供了多种工具包用于处理和分析时空数据。
1. 空间数据处理包:- sp包:提供了空间矢量数据类(如点、线、多边形等)的创建、访问、子集等操作。
- rgdal包:用于读写矢量空间数据格式,如ESRI shapefile、GeoJSON 等。
- raster包:用于读写和处理栅格空间数据。
- sf包:提供了简单特征接口,用于高效处理简单特征集合数据。
2. 时间序列处理包:- zoo包:提供了规整和不规整时间序列数据的处理。
- xts包:扩展了zoo包,用于处理具有时间戳的数据。
- forecast包:用于时间序列预测建模和可视化。
3. 时空数据处理包:- spacetime包:用于处理时空数据,如轨迹数据、点过程等。
- gstat包:用于空间和时空数据的kriging插值。
- trajectories包:用于分析和可视化移动对象轨迹数据。
4. 可视化包:- leaflet包:基于Leaflet JavaScript库的交互式Web地图可视化。
- tmap包:静态地图可视化,支持多种投影方式。
- mapview包:提供了交互式静态地图和动画可视化。
使用R语言处理时空数据的一般步骤包括:数据导入、数据预处理、探索性分析、建模分析和可视化展示。
通过合理选择和组合不同的R包,可以高效地完成时空数据的各种处理和分析任务。
偏最小二乘法结构方程模型r包

偏最小二乘法结构方程模型r包
偏最小二乘法结构方程模型r包是一个用于数据分析和建模的
工具,它采用了偏最小二乘法(PLS)和结构方程模型(SEM)的方法。
PLS 是一种多元统计分析方法,适用于变量之间存在高度相关性的情况,可以有效地压缩数据信息,提高建模效率。
SEM则是一种通过观察变量之间的关系来构建模型的方法,它可以帮助研究者理解变量之间的因果关系和影响机制。
偏最小二乘法结构方程模型r包提供了一些常用的函数和工具,可以帮助用户进行数据分析和建模。
其中包括PLS-SEM分析、路径分析、因子分析、模型实现和拟合、模型诊断和比较等功能。
用户可以根据自己的数据和分析目标选择相应的函数和工具,进行数据预处理、模型构建、模型拟合和模型诊断等操作,最终得到合理的数据分析结果和模型解释。
偏最小二乘法结构方程模型r包的使用需要一定的统计学和数
据分析基础,研究者应该根据自己的实际情况选择合适的方法和工具,避免误用和滥用。
同时,研究者应该对结果进行合理的解释和论证,不断完善自己的研究方法和理论体系。
- 1 -。
R语言-面板数据分析步骤及流程-
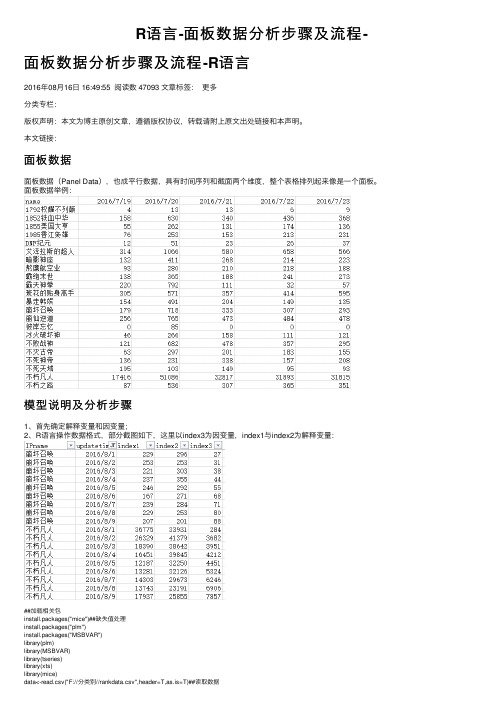
R语⾔-⾯板数据分析步骤及流程-⾯板数据分析步骤及流程-R语⾔2016年08⽉16⽇ 16:49:55 阅读数 47093 ⽂章标签:更多分类专栏:版权声明:本⽂为博主原创⽂章,遵循版权协议,转载请附上原⽂出处链接和本声明。
本⽂链接:⾯板数据⾯板数据(Panel Data),也成平⾏数据,具有时间序列和截⾯两个维度,整个表格排列起来像是⼀个⾯板。
⾯板数据举例:模型说明及分析步骤1、⾸先确定解释变量和因变量;2、R语⾔操作数据格式,部分截图如下,这⾥以index3为因变量,index1与index2为解释变量:##加载相关包install.packages("mice")##缺失值处理install.packages("plm")install.packages("MSBVAR")library(plm)library(MSBVAR)library(tseries)library(xts)library(mice)data<-read.csv("F://分类别//rankdata.csv",header=T,as.is=T)##读取数据123456789102、单位根检验:数据平稳性为避免伪回归,确保结果的有效性,需对数据进⾏平稳性判断。
何为平稳,⼀般认为时间序列提出时间趋势和不变均值(截距)后,剩余序列为⽩噪声序列即零均值、同⽅差。
常⽤的单位根检验的办法有LLC检验和不同单位根的Fisher-ADF检验,若两种检验均拒绝存在单位根的原假设则认为序列为平稳的,反之不平稳(对于⽔平序列,若⾮平稳,则对序列进⾏⼀阶差分,再进⾏后续检验,若仍存在单位根,则继续进⾏⾼阶差分,直⾄平稳,I(0)即为零阶单整,I(N)为N阶单整)。
##单位根检验tlist1<-xts(data$index1,as.Date(data$updatetime))adf.test(tlist1)tlist2<-xts(data$index2,as.Date(data$updatetime))adf.test(tlist2)123453、协整检验/模型修正单位根检验之后,变量间是同阶单整,可进⾏协整检验,协整检验是⽤来考察变量间的长期均衡关系的⽅法。
R语言常用计量分析包

R语言常用计量分析包CRAN任务视图:计量经济学线形回归模型(Linear regression models)线形模型可用stats包中lm()函数通过OLS来拟合,该包中也有各种检验方法用来比较模型,如:summary() 和anova()。
lmtest包里的coeftest()和waldtest()函数是也支持渐近检验(如:z检验而不是检验,卡方检验而不是F检验)的类似函数。
car包里的linear.hypothesis()可检验更一般的线形假设。
HC和HAC协方差矩阵的这些功能可在sandwich包里实现。
car和lmtest包还提供了大量回归诊断和诊断检验的方法。
工具变量回归(两阶段最小二乘)由AER包中的ivreg()提供,其另外一个实现sem包中的tsls()。
微观计量经济学(Microeconometrics)许多微观计量经济学模型属于广义线形模型,可由stats包的glm()函数拟合。
包括用于选择类数据(choice data)的Logit和probit模型,用于计数类数据(count data)的poisson模型。
这些模型回归元的值可用effects获得并可视化。
负二项广义线形模型可由MASS包的glm.nb()实现。
aod包提供了负二项模型的另一个实现,并包含过度分散数据的其它模型。
边缘(zero-inflated)和hurdle计数模型可由pscl包提供。
多项响应(Multinomial response):特定个体协变量(individual-specific covariates)多项模型只能由nnet包中multinom()函数提供。
mlogit包实现包括特定个体和特定选择(choice-specific)变量。
多项响应的广义可加模型可由VGAM包拟合。
针对多项probit模型的贝叶斯方法由MNP包提供,各种贝叶斯多项模型(包括logit和probit)在bayesm包中可得。
在R语言中进行面板数据分析

在R语言中进行面板数据分析面板数据(Panel Data)是截面数据与时间序列数据综合起来的一种数据类型。
它有时间序列和截面两个维度,当这类数据按两个维度排列时,是排在一个平面上,与只有一个维度的数据排在一条线上有着明显的不同,整个表格像是一个面板,所以把panel data译作“面板数据”。
面板数据模型的选择通常有三种形式:第一种是混合估计模型(Pooled Regression Model)。
如果从时间上看,不同个体之间不存在显著性差异;从截面上看,不同截面之间也不存在显著性差异,那么就可以直接把面板数据混合在一起用普通最小二乘法(OLS)估计参数。
第二种是固定效应模型(Fixed Effects Regression Model)。
如果对于不同的截面或不同的时间序列,模型的截距不同,则可以采用在模型中添加虚拟变量的方法估计回归参数。
该模型刻画了不同个体的特殊影响,而且这个影响不随样本变化。
第三种是随机效应模型(Random Effects Regression Model)。
如果固定效应模型中的截距项包括了截面随机误差项和时间随机误差项的平均效应,并且这两个随机误差项都服从正态分布,则固定效应模型就变成了随机效应模型。
该模型刻画了不同个体的特殊影响,但这个影响会随样本变化。
首先载入程序包和数据library(plm)将数据转成可处理的面板格式,特别要注意标明个体名和时间名pgr <- plm.data(data, index = c("firm", "year"))先用混合估计模型进行估计gr_pool <- plm(LOGOUT ~ LOGLABOR + LOGKAP, data = pgr,model = "pooling")再用固定效应模型进行估计gr_fe <- plm(LOGOUT ~ LOGLABOR + LOGKAP, data = pgr,model = "within")如果要判断固定效应模型是否比混合估计模型更好,可采用F检验pFtest(gr_fe, gr_pool)最后我们用随机效应模型进行估计gr_re <- plm(LOGOUT ~ LOGLABOR + LOGKAP, data = pgr,model = "random", random.method = "swar")summary(gr_re)要判断随机效应模型是否与固定效应模型有区别,可采用Hausman检验phtest(gr_re, gr_fe)1 / 1。
在R语言中进行面板数据分析

在R语言中进行面板数据分析面板数据分析是一种统计方法,用于分析面板数据集,也称为长期时间序列数据。
面板数据集包含多个个体(如公司、城市或个人)在多个时间点上的多个变量观测值。
面板数据分析可以提供更多的信息,因为它能够考虑到个体之间的差异、时间的趋势以及个体与时间的交互作用。
1. plm包:plm包是一个用于面板数据分析的强大工具包。
它提供了一些常用的面板数据分析函数,例如固定效应模型(Fixed Effects Model)、随机效应模型(Random Effects Model)和差分法(First Difference)等。
使用plm包,可以进行面板数据的描述性统计、可视化和回归分析等。
2. pglm包:pglm包是一个用于面板数据的广义线性模型工具包。
它能够处理具有不同误差分布的面板数据集,例如二项分布、泊松分布和负二项分布等。
pglm包还提供了一些有用的函数,例如对数似然比检验、预测和模型诊断等。
3. panelvar包:panelvar包是一个用于面板向量自回归模型(Panel Vector Autoregression Model,PVAR)分析的工具包。
PVAR模型是一种可以同时考虑面板数据内外部动态关系的方法。
使用panelvar 包,可以估计和预测面板数据的VAR模型,并进行脉冲响应分析等。
4. felm函数:felm函数是plm包中的一个常用函数,用于估计固定效应模型。
固定效应模型是一种在面板数据分析中常用的方法,用于控制个体固定效应的影响。
felm函数可以进行固定效应模型的估计,并提供了一些有用的统计量,例如系数估计值和显著性检验等。
在进行面板数据分析时,通常需要先进行数据准备和变换,然后根据具体问题选择适当的模型和方法。
以下是一个面板数据分析的基本步骤:1.数据准备:首先,将面板数据导入R环境中,并进行必要的数据处理和变换。
例如,处理缺失值、删除异常值、标准化变量等。
2. 描述性统计和可视化:对面板数据进行描述性统计和可视化,以了解数据的基本特征和趋势。
R的应用领域包介绍

R的应用领域包介绍 By R-FoxAnalysis of Pharmacokinetic Data 药物(代谢)动力学数据分析网址:/web/views/Pharmacokinetics.html维护人员:Suzette Blanchard版本:2008-02-15翻译:R-fox, 2008-04-12药物(代谢)动力学数据分析的主要目的是用非线性浓度时间曲线(concentration time curve)或相关的总结(如曲线下面积)确定给药方案(dosing regimen)和身体对药物反应间的关系。
R基本包里的nls()函数用非线性最小二乘估计法估计非线性模型的参数,返回nls类的对象,有 coef(),formula(), resid(),print(), summary(),AIC(),fitted() and vcov()等方法。
在主要目的实现后,兴趣就转移到研究属性(如:年龄、体重、伴随用药、肾功能)不同的人群是否需要改变药物剂量。
在药物(代谢)动力学领域,分析多个个体的组合数据估计人群参数被称作群体药动学(population PK)。
非线性混合模型为分析群体药动学数据提供了自然的工具,包括概率或贝叶斯估计方法。
nlme包用Lindstrom和Bates提出的概率方法拟合非线性混合效应模型(1990, Biometrics 46, 673-87),允许nested随机效应(nested random effects),组内误差允许相关的或不等的方差。
返回一个nlme类的对象表示拟合结果,结果可用print(),plot()和summary() 方法输出。
nlme对象给出了细节的结果信息和提取方法。
nlmeODE包组合odesolve包和nlme包做混合效应建模,包括多个药动学/药效学(PK/PD)模型。
面版数据(panel data)的贝叶斯估计方法在CRAN的Bayesian Inference任务列表里有所描述(/web/views/Bayesian.html)。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
空间面板数据分析——R的splm包(任建辉,暨南大学)The splm package provides methods for fitting spatial panel data by maximum likelihood and GM.安装R软件及其编辑器Rstudio网址:/下载好Rstudio以后,操作都可以Rstudio中完成了,包括命令的编写、命令运行、图形展示,最方便的要数查看数据了。
R界面Rstudio界面,形如matlab下面进入正题,了解splm包中的数据、命令及结果展示。
所有命令都写在编辑窗口(studio 左上区域),可以单独的运行每行命令,也可选取一段一起执行,点run按钮。
1、首先,安装splm包并导入,命令如下:intall.packages(“splm”),选择最近的下载点library(splm)> library(splm)载入需要的程辑包:MASS载入需要的程辑包:nlme载入需要的程辑包:spdep载入需要的程辑包:sp载入需要的程辑包:Matrix载入需要的程辑包:plm载入需要的程辑包:bdsmatrix载入程辑包:‘bdsmatrix’下列对象被屏蔽了from ‘package:base’:backsolve载入需要的程辑包:Formula载入需要的程辑包:sandwich载入需要的程辑包:zoo载入程辑包:‘zoo’下列对象被屏蔽了from ‘package:base’:as.Date, as.Date.numeric载入需要的程辑包:spam载入需要的程辑包:gridSpam version 0.40-0 (2013-09-11) is loaded.Type 'help( Spam)' or 'demo( spam)' for a short introductionand overview of this package.Help for individual functions is also obtained by adding thesuffix '.spam' to the function name, e.g. 'help( chol.spam)'.载入程辑包:‘spam’下列对象被屏蔽了from ‘package:bdsmatrix’:backsolve下列对象被屏蔽了from ‘package:base’:backsolve, forwardsolve载入需要的程辑包:ibdreg载入需要的程辑包:car载入需要的程辑包:lmtest载入需要的程辑包:Ecdat载入程辑包:‘Ecdat’下列对象被屏蔽了from ‘package:car’:Mroz下列对象被屏蔽了from ‘package:nlme’:Gasoline下列对象被屏蔽了from ‘package:MASS’:SP500下列对象被屏蔽了from ‘package:datasets’:Orange载入需要的程辑包:maxLik载入需要的程辑包:miscToolsPlease cite the 'maxLik' package as:Henningsen, Arne and Toomet, Ott (2011). maxLik: A package for maximum likelih ood estimation in R. Computational Statistics 26(3), 443-458. DOI 10.1007/s001 80-010-0217-1.If you have questions, suggestions, or comments regarding the 'maxLik' package, please use a forum or 'tracker' at maxLik's R-Forge site:https:///projects/maxlik/Warning message:程辑包‘Matrix’是用R版本3.0.3 来建造的注意:在导入splm时,如果发现还有其他配套的包没有安装,需要先安装。
2、接着,查看数据及结构,命令如下:data(Produc,package=”Ecdat”)View(Produc)3、引入空间权重矩阵(spatial weights matrix),命令如下data(usaww)Views(usaww)4、空间面板数据的广义矩估计,命令spgmGM<-spgm(log(gsp)~log(pcap)+log(pc)+log(emp)+unemp, data=Produc,listw=usaww, moments=”fullweights”, spatial.error=TRUE) summary(GM)> GM<-spgm(log(gsp)~log(pcap)+log(pc)+log(emp)+unemp,data=Produc,+ listw=usaww,moments="fullweights",spatial.error=TRUE)> summary(GM)Spatial panel fixed effects GM modelCall:spgm(formula = log(gsp) ~ log(pcap) + log(pc) + log(emp) + unemp,data = Produc, listw = usaww, spatial.error = TRUE, moments = "fullweights ")Residuals:Min. 1st Qu. Median 3rd Qu. Max.-0.14000 -0.01950 -0.00316 0.01530 0.16800Estimated spatial coefficient, variance components and theta:Estimaterho 0.3277625sigma^2_v 0.0012179Coefficients:Estimate Std. Error t-value Pr(>|t|)log(pcap) -0.0022435 0.0262646 -0.0854 0.9319295log(pc) 0.2414979 0.0235826 10.2405 < 2.2e-16 ***log(emp) 0.7813276 0.0283855 27.5256 < 2.2e-16 ***unemp -0.0036026 0.0010094 -3.5691 0.0003582 ***---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 15、空间面板极大似然估计,命令spmlfm<- log(gsp)~log(pcap)+log(pc)+log(emp)+unemp## fixed effects panel with spatial errorsFespaterr<-spml(fm,data=Produc,listw=mat2listw(usaww),model=”within”,spatial.error=”b”,hess=FALSE)summary(Fespaterr)> fm<-log(gsp)~log(pcap)+log(pc)+log(emp)+unemp> Fespaterr<-spml(fm,data=Produc,listw=mat2listw(usaww),model="within",+ spatial.error="b",hess=FALSE)> summary(Fespaterr)Spatial panel fixed effects error modelCall:spml(formula = fm, data = Produc, listw = mat2listw(usaww), model = "within", spatial.error = "b", hess = FALSE)Residuals:Min. 1st Qu. Median 3rd Qu. Max.-0.1250 -0.0238 -0.0035 0.0171 0.1880Coefficients:Estimate Std. Error t-value Pr(>|t|)rho 0.5574013 0.0329554 16.9138 < 2e-16 ***log(pcap) 0.0051438 0.0250724 0.2052 0.83745log(pc) 0.2053026 0.0231996 8.8494 < 2e-16 ***log(emp) 0.7822540 0.0278741 28.0638 < 2e-16 ***unemp -0.0022317 0.0010735 -2.0788 0.03764 *---S ignif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1##random effects panal with spatial lagRespatlag<-spml(fm,data=Produc,listw=mat2listw(usaww),model=”random”,spatial.error=”none”,lag=TRUE)summary(Respatlag)> Respatlag<-spml(fm,data=Produc,listw=mat2listw(usaww),model="random",+ spatial.error="none",lag=TRUE)> summary(Respatlag)Spatial panel random effects ML modelCall:spreml(formula = formula, data = data, index = index, w = listw2mat(listw), w2 = listw2mat(listw2), lag = lag, errors = errors, cl = cl)Residuals:Min. 1st Qu. Median Mean 3rd Qu. Max.1.38 1.57 1.70 1.70 1.802.13Error variance parameters:Estimate Std. Error t-value Pr(>|t|)phi 21.3175 8.3017 2.5678 0.01023 *Spatial autoregressive coefficient:Estimate Std. Error t-value Pr(>|t|)lambda 0.161615 0.029099 5.554 2.793e-08 ***Coefficients:Estimate Std. Error t-value Pr(>|t|)(Intercept) 1.65814995 0.15071855 11.0016 < 2.2e-16 ***log(pcap) 0.01294505 0.02493997 0.5190 0.6037log(pc) 0.22555376 0.02163422 10.4258 < 2.2e-16 ***log(emp) 0.67081075 0.02642113 25.3892 < 2.2e-16 ***unemp -0.00579716 0.00089175 -6.5009 7.984e-11 ***---S ignif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 16、伴有随机效应和序列误差相关的空间面板模型的极大似然估计,命令speml##random effects panel with spatial lag and serial error correlation##optimization method set to “BFGS“Sarsrmod<-spreml(fm,data=Froduc,w=usaww,error=”sr”,lag=TRUE,method=”BFGS”) summary(Sarsrmod)> Sarsrmod<-spreml(fm,data=Produc,w=usaww,error="sr",lag=TRUE,method="BFGS") > summary(Sarsrmod)Spatial panel random effects ML modelCall:spreml(formula = fm, data = Produc, w = usaww, lag = TRUE, errors = "sr",method = "BFGS")Residuals:Min. 1st Qu. Median Mean 3rd Qu. Max.2.663.02 3.18 3.18 3.31 3.77Error variance parameters:Estimate Std. Error t-value Pr(>|t|)psi 0.99726353 0.00082138 1214.1 < 2.2e-16 ***Spatial autoregressive coefficient:Estimate Std. Error t-value Pr(>|t|)lambda 0.302942 0.030376 9.973 < 2.2e-16 ***Coefficients:Estimate Std. Error t-value Pr(>|t|)(Intercept) 1.23670293 0.22777554 5.4295 5.652e-08 ***log(pcap) 0.08257977 0.03617371 2.2829 0.02244 *log(pc) 0.01509919 0.01977324 0.7636 0.44510log(emp) 0.73882021 0.02934144 25.1801 < 2.2e-16 ***unemp -0.00270962 0.00065851 -4.1148 3.875e-05 ***---Signi f. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 17、模型检验(1)bsjktest,Baltigi,Song,Jung, and Koh LM test for spatial panels> bsjktest(fm, data=Produc, listw = usaww, test="C.1")Baltagi, Song, Jung and Koh C.1 conditional testdata: log(gsp) ~ log(pcap) + log(pc) + log(emp) + unempLM = 0.2617, df = 1, p-value = 0.609alternative hypothesis: spatial dependence in error terms, sub RE and serial c orr.(2)bsktest,Baltigi,Song and Koh LM test for spatial panels> bsktest(fm,data=Produc, listw = mat2listw(usaww),+ test="LM1", standardize=TRUE)Baltagi, Song and Koh SLM1 marginal testdata: log(gsp) ~ log(pcap) + log(pc) + log(emp) + unempSLM1 = 0.083, p-value = 0.9338alternative hypothesis: Random effects(3)Covariance extractor method for splm objects> sarremod<-spml(fm,data=Produc,listw=mat2listw(usaww),model="random",+ lag=TRUE,spatial.error="none")> library(lmtest)> coeftest(sarremod)z test of coefficients:Estimate Std. Error z value Pr(>|z|)(Intercept) 1.65814995 0.15071855 11.0016 < 2.2e-16 ***log(pcap) 0.01294505 0.02493997 0.5190 0.6037log(pc) 0.22555376 0.02163422 10.4258 < 2.2e-16 ***log(emp) 0.67081075 0.02642113 25.3892 < 2.2e-16 ***unemp -0.00579716 0.00089175 -6.5009 7.984e-11 ***---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1> library(car)> lht(sarremod,"log(pcap)=log(pc)")Linear hypothesis testHypothesis:log(pcap) - log(pc) = 0Model 1: restricted modelModel 2: function (x, ...)UseMethod("formula")Df Chisq Pr(>Chisq)12 1 36.268 1.719e-09 ***---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1(更多详情请查看splm的help文档以及文后列的参考文献)参考文献1.Baltagi,B.H.,Song,S.H.,Jung B. and Koh, W.(2007) Testing panel data regression models with spatial and serial error correlation. Journal of Econometrics,140,5-512.Baltagi,B.H.,Song,S.H and Koh, W.(2003) Testing panel data regression models with spatial error correlation. Journal of Econometrics,117,123-150lo,G.,Piras,G.(2012) splm:Spatial Panel Data Models in R. Journal of Statistical Software,47(1),1-38.URL /v47/i01/4.Elhorst, J.P (2003) Specification and estimation of spatial panel data models, InternationalRegional Science Review,26,pages 244-2685.Elhorst, J.P(2009) Spatial panel data models, In Fisher,M.M. and Getis,A.(eds),Handbook of Applied Spatial Analysis Springer,Berlin6.Giovanni Millo and Gaetano Carmeci,(2011) “Non-life insurance consumption in Italy: a subregional panel data analysis”, Journal of Geographical Systems,13:273-2987.Qu Feng and William C. Horrace,(2012)”Alternative Measures of Technical Efficiency :Skew,Bias and Scale”, Journal of Applied Econometrics, Forthcoming.8.Kapoor,M.,Kelejian,H.H. and Prucha,I.R.(2007) Panel data model with spatially correlated error components,Journal of Econometrics,140,pages 97-1309.Mutl,J.,and Pfaffermayr,M.(2011) The Hausman test in a Cliff and Ord panel model,Econometrics Journal,14,pages 48-7610.Kelejian,H.H. and Prucha,I.R.(1999) A Generalied Moments Estimator for the Autoregressive Parameter in a Spatial Model, International Economic Reviews,40, pages509-53311. Kelejian,H.H. and Prucha,I.R.(1999) A Generalied Spatial Two Stage Least Square Procedure for Estimating a Spatial Autoregressive Model with Autoregressive Disturbances,Journal of Real Estate Finance and Economics,17,pages99-122lo,G.(2013) Maximum likelihood estimation of spatially and serially correlated panel with random effects. Computational Statistics and Data Analysis, forthcoming.13.Zeileis,A(2006)Object-Oriented Computation of Sandwich Estimators. Journal of Statistical Software,16(9),1-16。