【精选资料】NOIP提高组复赛试题与简解转载
NOIP2012提高组day1
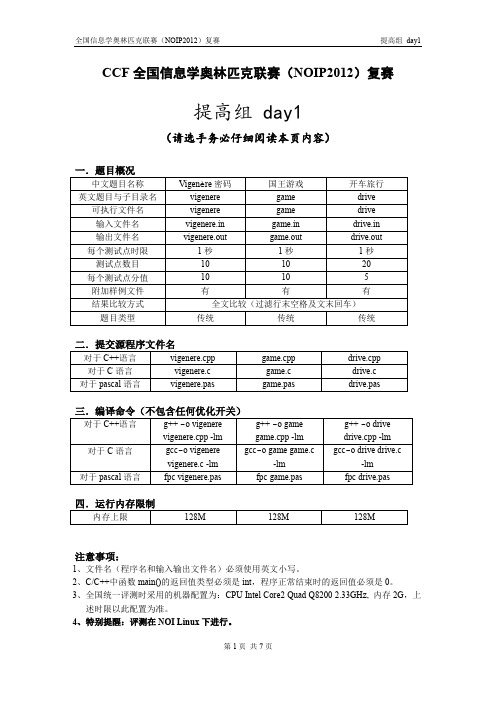
CCF全国信息学奥林匹克联赛(NOIP2012)复赛提高组 day1(请选手务必仔细阅读本页内容)注意事项:1、文件名(程序名和输入输出文件名)必须使用英文小写。
2、C/C++中函数main()的返回值类型必须是int,程序正常结束时的返回值必须是0。
3、全国统一评测时采用的机器配置为:CPU Intel Core2 Quad Q8200 2.33GHz, 内存2G,上述时限以此配置为准。
4、特别提醒:评测在NOI Linux下进行。
1.Vigenère密码(vigenere.cpp/c/pas)【问题描述】16世纪法国外交家Blaise de Vigenère设计了一种多表密码加密算法——Vigenère密码。
Vigenère密码的加密解密算法简单易用,且破译难度比较高,曾在美国南北战争中为南军所广泛使用。
在密码学中,我们称需要加密的信息为明文,用M表示;称加密后的信息为密文,用C表示;而密钥是一种参数,是将明文转换为密文或将密文转换为明文的算法中输入的数据,记为k。
在Vigenère密码中,密钥k是一个字母串,k=k1k2…k n。
当明文M=m1m2…m n时,得到的密文C=c1c2…c n,其中c i=m i®k i,运算®的规则如下表所示:®【输入】输入文件名为vigenere.in。
输入共2行。
第一行为一个字符串,表示密钥k,长度不超过100,其中仅包含大小写字母。
第二行为一个字符串,表示经加密后的密文,长度不超过1000,其中仅包含大小写字母。
【输出】输出文件名为vigenere.out。
输出共1行,一个字符串,表示输入密钥和密文所对应的明文。
对于100%的数据,输入的密钥的长度不超过100,输入的密文的长度不超过1000,且都仅包含英文字母。
2.国王游戏(game.cpp/c/pas)【问题描述】恰逢H国国庆,国王邀请n位大臣来玩一个有奖游戏。
NOIP2008提高组复赛试题及题解

全国信息学奥林匹克联赛(NOIP2008)复赛提高组一、题目概览二、提交源程序文件名三、编译命令(不包含任何优化开关)四、运行内存限制注意事项:1. 文件名(程序名和输入输出文件名)必须使用大写。
2. C/C++中函数main()的返回值类型必须是int,程序正常结束时的返回值必须是0。
3. 全国统一评测时采用的机器配置为:CPU 1.9GHz,内存512M,上述时限以此配置为准。
各省在自测时可根据具体配置调整时限。
1. 笨小猴(word.pas/c/cpp)【问题描述】笨小猴的词汇量很小,所以每次做英语选择题的时候都很头疼。
但是他找到了一种方法,经试验证明,用这种方法去选择选项的时候选对的几率非常大!这种方法的具体描述如下:假设maxn是单词中出现次数最多的字母的出现次数,minn 是单词中出现次数最少的字母的出现次数,如果maxn-minn是一个质数,那么笨小猴就认为这是个Lucky Word,这样的单词很可能就是正确的答案。
【输入】输入文件word.in只有一行,是一个单词,其中只可能出现小写字母,并且长度小于100。
【输出】输出文件word.out共两行,第一行是一个字符串,假设输入的的单词是Lucky Word,那么输出“Lucky Word”,否则输出“No Answer”;第二行是一个整数,如果输入单词是Lucky Word,输出maxn-minn的值,否则输出0。
【输入输出样例1】【输入输出样例1解释】单词error中出现最多的字母r出现了3次,出现次数最少的字母出现了1次,3-1=2,2是质数。
【输入输出样例2】【输入输出样例2解释】单词olympic中出现最多的字母i出现了2次,出现次数最少的字母出现了1次,2-1=1,1不是质数。
基本的字符串处理,细心一点应该没问题的,不过判断素数时似乎需要考虑下0和1的情况。
var a:array['a'..'z']of integer;s:string;l,i,max,min,n:integer;ch:char;flag:boolean;beginassign(input,'word.in');reset(input);assign(output,'word.out');rewrite(output);readln(s);l:=length(s);fillchar(a,sizeof(a),0);for i:=1 to l doinc(a[s[i]]);max:=0;min:=100;for ch:='a'to 'z' doif a[ch]>0 then beginif a[ch]>max then max:=a[ch];if a[ch]<min then min:=a[ch];end;n:=max-min; flag:=true;if(n=0) or (n=1) then flag:=falseelsefor i:=2 to trunc(sqrt(n)) doif n mod i =0 then begin flag:=false;break;end;if flag then begin writeln('Lucky Word'); writeln(n);endelse begin writeln('No Answer');writeln(0);end;close(output);close(input);end.2. 火柴棒等式(matches.pas/c/cpp)【问题描述】给你n根火柴棍,你可以拼出多少个形如“A+B=C”的等式?等式中的A、B、C是用火柴棍拼出的整数(若该数非零,则最高位不能是0)。
NOIP提高组复赛题目

第一题题库NOIP20071.统计数字(count.pas/c/cpp)【问题描述】某次科研调查时得到了n个自然数,每个数均不超过1500000000(1.5*109)。
已知不相同的数不超过10000个,现在需要统计这些自然数各自出现的次数,并按照自然数从小到大的顺序输出统计结果。
【输入】输入文件count.in包含n+1行:第1行是整数n,表示自然数的个数。
第2~n+1行每行一个自然数。
【输出】输出文件count.out包含m行(m为n个自然数中不相同数的个数),按照自然数从小到大的顺序输出。
每行输出两个整数,分别是自然数和该数出现的次数,其间用一个空格隔开。
【输入输出样例】【限制】40%的数据满足:1<=n <=100080%的数据满足:1<=n <=50000100%的数据满足:1<=n <=200000,每个数均不超过1 500 000 000(1.5*109)NOIP20081. 笨小猴(wird.pas/c/cpp)【问题描述】笨小猴的词汇量很小,所以每次做英语选择题的时候都很头疼。
但是他找到了一种方法,经试验证明,用这种方法去选择选项的时候选对的几率非常大!这种方法的具体描述如下:假设maxn 是单词中出现次数最多的字母的出现次数,minn 是单词中出现次数最少的字母的出现次数,如果maxn-minn 是一个质数,那么笨小猴就认为这是个Lucky Word ,这样的单词很可能就是正确的答案。
【输入】输入文件word.in 只有一行,是一个单词,其中只可能出现小写字母,并且长度小于100。
【输出】输出文件word.out 共两行,第一行是一个字符串,假设输入的的单词是Lucky Word ,那么输出“Lucky Word ”,否则输出“No Answer ”;第二行是一个整数,如果输入单词是Lucky Word,输出maxn-minn 的值,否则输出0。
noip2004 提高组复赛试题及参考程序(pascal)

第十届信息学奥林匹克联赛复赛试题(NOIP2004)一、津津的储蓄计划(save.pas/c/cpp)【问题描述】津津的零花钱一直都是自己管理。
每个月的月初妈妈给津津300元钱,津津会预算这个月的花销,并且总能做到实际花销和预算的相同。
为了让津津学习如何储蓄,妈妈提出,津津可以随时把整百的钱存在她那里,到了年末她会加上20%还给津津。
因此津津制定了一个储蓄计划:每个月的月初,在得到妈妈给的零花钱后,如果她预计到这个月的月末手中还会有多于100元或恰好100元,她就会把整百的钱存在妈妈那里,剩余的钱留在自己手中。
例如11月初津津手中还有83元,妈妈给了津津300元。
津津预计11月的花销是180元,那么她就会在妈妈那里存200元,自己留下183元。
到了11月月末,津津手中会剩下3元钱。
津津发现这个储蓄计划的主要风险是,存在妈妈那里的钱在年末之前不能取出。
有可能在某个月的月初,津津手中的钱加上这个月妈妈给的钱,不够这个月的原定预算。
如果出现这种情况,津津将不得不在这个月省吃俭用,压缩预算。
现在请你根据2004年1月到12月每个月津津的预算,判断会不会出现这种情况。
如果不会,计算到2004年年末,妈妈将津津平常存的钱加上20%还给津津之后,津津手中会有多少钱。
【输入文件】输入文件save.in包括12行数据,每行包含一个小于350的非负整数,分别表示1月到12月津津的预算。
【输出文件】输出文件save.out包括一行,这一行只包含一个整数。
如果储蓄计划实施过程中出现某个月钱不够用的情况,输出-X,X表示出现这种情况的第一个月;否则输出到2004年年末津津手中会有多少钱。
【样例输入1】29023028020030017034050908020060【样例输出1】-7【样例输入2】29023028020030017033050908020060【样例输出2】1580二、合并果子(fruit.pas/c/cpp)【问题描述】在一个果园里,多多已经将所有的果子打了下来,而且按果子的不同种类分成了不同的堆。
NOIP提高组复赛题解

样例 输入: 33 039 285 570 输出: 34 数据规模: 30%的数据满足:1<=m,n<=10 100%的数据满足:1<=m,n<=50
思路: 首先想到搜索,但是对于只考虑一条路线来说, 每一步有两种状态 一共要走m+n步,搜索整棵树的 时间复杂度为O(2^(m+n)),如果两条路线都考虑的 话,时间复杂度为O(4^(m+n)),即使是30%的数据, 即m+n=20,4^20≈10^12,这样的数据规模也还是太 大了。
4维动态规划 本题可以使用动态规划法解决。 设f[i,j,k,l]为第一条线走到(I,j),第二条线走到 (k,l)时的最优值(方便起见,两条线都看作从左上角 开始,右下角结束)。 动态转移方程: f[i-1,j,k-1,l] (i>1) f[i,j,k,l]=min f[i-1,j,k,l-1] (i>1) +s[i,j]+s[k,l] f[i,j-1,k-1,l] (j>1)且(k>i+1) f[I,j-1,k,j-1] (j>1) 同时,由于两条线不能交叉,有k>i。
输入格式: 输入文件matches.in共一行,有一个整数n(n<=24)。 * 输出格式: 输出文件matches.out共一行,表示能拼成的不同等 式的数目。
样例1 输入:
14 输出: 2 解释: 2个等式为0+1=1和1+0=1。
样例2 输入: 18 输出: 9 解释: 9个等式为: 0+4=4、0+11=11、1+10=11、2+2=4、 2+7=9、4+0=4、7+2=9、10+1=11、11+0=11
NOIP2007 提高组 复赛试题
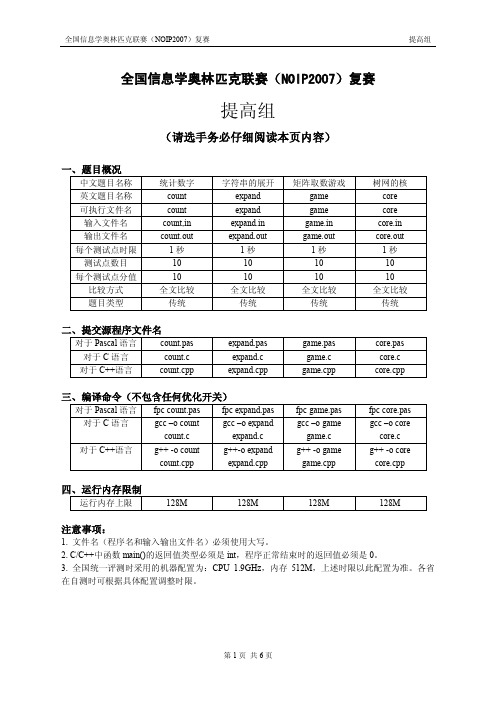
【输出】
输出文件 core.out 只有一个非负整数,为指定意义下的最小偏心距。
【输入输出样例 1】
core.in 5 2 1 2 5 2 3 2 2 4 4 2 5 3 core.out 5
【输入输出样例 2】
core.in 8 6 1 3 2 2 3 2 3 4 6 4 5 3 4 6 4 4 7 2 7 8 3 core.out 5
【输入输出样例 2】
expand.in 2 3 2 a-d-d expand.out aCCCBBBd-d
【输入输出样例 3】
expand.in 3 4 2 di-jkstra2-6 expand.out dijkstra2************6
【限制】
40%的数据满足:字符串长度不超过 5 100%的数据满足:1<=p1<=3, 1<=p2<=8, 1<=p3<=2。字符串长度不超过 100
【输入】
输入文件 game.in 包括 n+1 行: 第 1 行为两个用空格隔开的整数 n 和 m。 第 2~n+1 行为 n*m 矩阵,其中每行有 m 个用单个空格隔开的非负整数。
【输出】
输出文件 game.out 仅包含 1 行,为一个整数,即输入矩阵取数后的最大得分。
【输入输出样例 1】
game.in 2 3 1 2 3 3 4 2 game.out 82
【输入】
输入文件 count.in 包含 n+1 行: 第 1 行是整数 n,表示自然数的个数。 第 2~n+1 行每行一个自然数。
【输出】
输出文件 count.out 包含 m 行(m 为 n 个自然数中不相同数的个数) ,按照自然数从小到大 的顺序输出。每行输出两个整数,分别是自然数和该数出现的次数,其间用一个空格隔开。
NOIP2010年提高组复赛试题

题目描述小晨的电脑上安装了一个机器翻译软件,他经常用这个软件来翻译英语文章。
这个翻译软件的原理很简单,它只是从头到尾,依次将每个英文单词用对应的中文含义来替换。
对于每个英文单词,软件会先在内存中查找这个单词的中文含义,如果内存中有,软件就会用它进行翻译;如果内存中没有,软件就会在外存中的词典内查找,查出单词的中文含义然后翻译,并将这个单词和译义放入内存,以备后续的查找和翻译。
假设内存中有M 个单元,每单元能存放一个单词和译义。
每当软件将一个新单词存入内存前,如果当前内存中已存入的单词数不超过M−;;1,软件会将新单词存入一个未使用的内存单元;若内存中已存入M 个单词,软件会清空最早进入内存的那个单词,腾出单元来,存放新单词。
假设一篇英语文章的长度为N 个单词。
给定这篇待译文章,翻译软件需要去外存查找多少次词典?假设在翻译开始前,内存中没有任何单词。
【数据范围】对于10%的数据有M=1,N≤ 5。
对于100%的数据有0<M≤ 100,0<N ≤ 1000。
输入格式in,输入文件共2 行。
每行中两个数之间用一个空格隔开。
第一行为两个正整数M 和N,代表内存容量和文章的长度。
第二行为N 个非负整数,按照文章的顺序,每个数(大小不超过1000)代表一个英文单词。
文章中两个单词是同一个单词,当且仅当它们对应的非负整数相同。
输出格式共1 行,包含一个整数,为软件需要查词典的次数。
【输入输出样例1】3 71 2 1 5 4 4 1【输入输出样例2】2 108 824 11 78 11 78 11 78 8 264【输入输出样例1】5【输入输出样例2】6题目:[NOIP2010]乌龟棋问题编号:599题目描述小明过生日的时候,爸爸送给他一副乌龟棋当作礼物。
乌龟棋的棋盘是一行N 个格子,每个格子上一个分数(非负整数)。
棋盘第1 格是唯一的起点,第N 格是终点,游戏要求玩家控制一个乌龟棋子从起点出发走到终点。
NOIP提高组复赛试题汇编(1998-2010)

NOIP 19981.火车从始发站(称为第1站)开出,在始发站上车的人数为a ,然后到达第2站,在第2站有人上、下车,但上、下车的人数相同,因此在第2站开出时(即在到达第3站之前)车上的人数保持为a 人。
从第3站起(包括第3站)上、下车的人数有一定规律:上车的人数都是前两站上车人数之和,而下车人数等于上一站上车人数,一直到终点站的前一站(第n-1站),都满足此规律。
现给出的条件是:共有N 个车站,始发站上车的人数为a ,最后一站下车的人数是m (全部下车)。
试问x 站开出时车上的人数是多少?2.设有n 个正整数(n ≤20),将它们联接成一排,组成一个最大的多位整数。
例如:n=3时,3个整数13,312,343联接成的最大整数为:34331213又如:n=4时,4个整数7,13,4,246联接成的最大整数为:74246133.著名科学家卢斯为了检查学生对进位制的理解,他给出了如下的一张加法表,表中的字母代表数字。
例如:其含义为:L+L=L ,L+K=K ,L+V=V ,L+E=E K+L=K ,K+K=V ,K+V=E ,K+E=KLE+E=KV根据这些规则可推导出:L=0,K=1,V=2,E=3同时可以确定该表表示的是4进制加法NOIP 1999第一题拦截导弹某国为了防御敌国的导弹袭击,发展出一种导弹拦截系统。
但是这种导弹拦截系统有一个缺陷:虽然它的第一发炮弹能够到达任意的高度,但是以后每一发炮弹都不能高于前一发的高度。
某天,雷达捕捉到敌国的导弹来袭。
由于该系统还在试用阶段,所以只有一套系统,因此有可能不能拦截所有的导弹。
输入导弹依次飞来的高度(雷达给出的高度数据是不大于30000的正整数),计算这套系统最多能拦截多少导弹,如果要拦截所有导弹最少要配备多少套这种导弹拦截系统。
样例:INPUTOUTPUT389207155300299170158656(最多能拦截的导弹数)2(要拦截所有导弹最少要配备的系统数)输入:a ,n ,m 和x输出:从x 站开出时车上的人数。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Day1铺地毯【问题描述】为了准备一个独特的颁奖典礼,组织者在会场的一片矩形区域(可看做是平面直角坐标系的第一象限)铺上一些矩形地毯。
一共有n 张地毯,编号从1 到n。
现在将这些地毯按照编号从小到大的顺序平行于坐标轴先后铺设,后铺的地毯覆盖在前面已经铺好的地毯之上。
地毯铺设完成后,组织者想知道覆盖地面某个点的最上面的那张地毯的编号。
注意:在矩形地毯边界和四个顶点上的点也算被地毯覆盖。
【输入】输入文件名为 carpet.in。
输入共 n+2 行。
第一行,一个整数 n,表示总共有n 张地毯。
接下来的 n 行中,第i+1 行表示编号i 的地毯的信息,包含四个正整数a,b,g,k,每两个整数之间用一个空格隔开,分别表示铺设地毯的左下角的坐标(a,b)以及地毯在x轴和y 轴方向的长度。
第 n+2 行包含两个正整数x 和y,表示所求的地面的点的坐标(x,y)。
【输出】输出文件名为 carpet.out。
输出共 1 行,一个整数,表示所求的地毯的编号;若此处没有被地毯覆盖则输出-1。
【输入输出样例 1】【输入输出样例说明】如下图,1 号地毯用实线表示,2 号地毯用虚线表示,3 号用双实线表示,覆盖点(2,2)的最上面一张地毯是3 号地毯。
【输入输出样例 2】【输入输出样例说明】如上图,1 号地毯用实线表示,2 号地毯用虚线表示,3 号用双实线表示,点(4,5)没有被地毯覆盖,所以输出-1。
【数据范围】对于 30%的数据,有n≤2;对于 50%的数据,0≤a, b, g, k≤100;对于 100%的数据,有0≤n≤10,000,0≤a, b, g, k≤100,000。
【一句话题意】给定n个按顺序覆盖的矩形,求某个点最上方的矩形编号。
【考察知识点】枚举【思路】好吧我承认看到图片的一瞬间想到过二维树状数组和二维线段树。
置答案ans=-1,按顺序枚举所有矩形,如果点在矩形内则更新ans。
注意题中给出的不是对角坐标,实际上是(a,b)与(a+g,b+k)。
还有一种办法可以从n到1枚举矩形,一旦在矩形内就直接输出,可能会快一点。
不过对于这题的范围什么都是浮云。
恩,写完这题一看还没过8:30【时间复杂度】O(n)选择客栈【问题描述】丽江河边有 n 家很有特色的客栈,客栈按照其位置顺序从1 到n 编号。
每家客栈都按照某一种色调进行装饰(总共k 种,用整数0 ~ k-1 表示),且每家客栈都设有一家咖啡店,每家咖啡店均有各自的最低消费。
两位游客一起去丽江旅游,他们喜欢相同的色调,又想尝试两个不同的客栈,因此决定分别住在色调相同的两家客栈中。
晚上,他们打算选择一家咖啡店喝咖啡,要求咖啡店位于两人住的两家客栈之间(包括他们住的客栈),且咖啡店的最低消费不超过p。
他们想知道总共有多少种选择住宿的方案,保证晚上可以找到一家最低消费不超过p元的咖啡店小聚。
【输入】输入文件 hotel.in,共n+1 行。
第一行三个整数 n,k,p,每两个整数之间用一个空格隔开,分别表示客栈的个数,色调的数目和能接受的最低消费的最高值;接下来的 n 行,第i+1 行两个整数,之间用一个空格隔开,分别表示i 号客栈的装饰色调和i 号客栈的咖啡店的最低消费。
【输出】输出文件名为 hotel.out。
输出只有一行,一个整数,表示可选的住宿方案的总数。
【输入输出样例 1】【输入输出样例说明】2 人要住同样色调的客栈,所有可选的住宿方案包括:住客栈①③,②④,②⑤,④⑤,但是若选择住4、5 号客栈的话,4、5 号客栈之间的咖啡店的最低消费是4,而两人能承受的最低消费是3 元,所以不满足要求。
因此只有前3 种方案可选。
【数据范围】对于 30%的数据,有n≤100;对于 50%的数据,有n≤1,000;对于 100%的数据,有2≤n≤200,000,0<k≤50,0≤p≤100, 0≤最低消费≤100。
【一句话题意】合法区间[l,r]定义:l,r的色调相同,且[l,r]之间存在一个最低消费不超过p。
求合法区间总数。
【考察知识点】二分查找/枚举【思路】贴吧神吐槽:CCF收了丽江多少钱?看完题目后不知所云,再多看几遍,一个O(n^3)的算法有了一点雏形。
用两层循环枚举区间的左右端点l、r,再用一层循环判断区间内是否有可行的咖啡店,累计即可。
这个算法思维难度和编程难度都非常低,但是只能过30%的数据,可以作为对拍程序备份。
再仔细思考,发现题中合法区间的限制条件其实很强。
首先区间端点的色调必须相同,其次区间内必须要存在一个咖啡店最低消费不超过P。
因此,如果我们用一层循环枚举左端点,并很快找到右端点的可行数,那么题目就能解决了。
这里置答案为变量ans,千万注意类型要为int64,昨天我就手抽打模板时直接打了ans:longint,超级大杯具!!!这里首先要用到区间部分和优化。
设sum [i,j]为前i个客栈中,色调为j的客栈总数,那么:sum[i,j]=sum[i-1,j] (color[i]<>j)sum[i,j]=sum[i-1,j]+1 (color[i]=j)这里要用O(NK)的复杂度,是算法的瓶颈所在,不过对于题中的数据范围已经足够了。
并且具体实现可以先用数组赋值sum[i]=sum[i-1],然后再为sum[i,color[i]]+1,应该会快很多。
我们还需要解决的问题就是,已知了L,如何快速找到R的可行范围?再次注意区间内必须要存在一个咖啡店最低消费不超过P。
因此,如果L就是一个最低消费不超过P的咖啡店,那么R可以取到[L+1,n]中所有色调为color[L]的客栈,即ans=ans+sum[n,color[L]]-sum[L,color[L]];如果L是一个最低消费超过P的咖啡店,那么我们要找到一个T∈[L+1,n],且咖啡店T的最低消费不超过P,那么R就可以取到[T,n]中所有色调为color[L]的客栈,即ans=ans+sum[n,color[L]]-sum[T-1,color[L]]。
问题是我们如何找到这个T,其实很简单,二分查找即可。
再次预设一个数组,保存所有最低消费不超过P的咖啡店序号,二分查找L即可。
注意这里L一定不存在这个数组中,因此找到的应该是最靠近L且大于L的序号,细节处理很重要。
找不到返回-1,不用累加ans就是了。
目测写完这题已经只剩1:30时间,且未对拍,第三题鸭梨巨大。
【时间复杂度】O(nk+nlogn)mayan 游戏【问题描述】Mayan puzzle 是最近流行起来的一个游戏。
游戏界面是一个7 行5 列的棋盘,上面堆放着一些方块,方块不能悬空堆放,即方块必须放在最下面一行,或者放在其他方块之上。
游戏通关是指在规定的步数内消除所有的方块,消除方块的规则如下:1、每步移动可以且仅可以沿横向(即向左或向右)拖动某一方块一格:当拖动这一方块时,如果拖动后到达的位置(以下称目标位置)也有方块,那么这两个方块将交换位置(参见输入输出样例说明中的图6 到图7);如果目标位置上没有方块,那么被拖动的方块将从原来的竖列中抽出,并从目标位置上掉落(直到不悬空,参见下面图1 和图2);2、任一时刻,如果在一横行或者竖列上有连续三个或者三个以上相同颜色的方块,则它们将立即被消除(参见图1 到图3)。
注意:a) 如果同时有多组方块满足消除条件,几组方块会同时被消除(例如下面图4,三个颜色为1 的方块和三个颜色为2 的方块会同时被消除,最后剩下一个颜色为2 的方块)。
b) 当出现行和列都满足消除条件且行列共享某个方块时,行和列上满足消除条件的所有方块会被同时消除(例如下面图5 所示的情形,5 个方块会同时被消除)。
3、方块消除之后,消除位置之上的方块将掉落,掉落后可能会引起新的方块消除。
注意:掉落的过程中将不会有方块的消除。
上面图 1 到图3 给出了在棋盘上移动一块方块之后棋盘的变化。
棋盘的左下角方块的坐标为(0, 0),将位于(3, 3)的方块向左移动之后,游戏界面从图1 变成图2 所示的状态,此时在一竖列上有连续三块颜色为4 的方块,满足消除条件,消除连续3 块颜色为4 的方块后,上方的颜色为3 的方块掉落,形成图3 所示的局面。
【输入】输入文件 mayan.in,共6 行。
第一行为一个正整数 n,表示要求游戏通关的步数。
接下来的 5 行,描述7*5 的游戏界面。
每行若干个整数,每两个整数之间用一个空格隔开,每行以一个0 结束,自下向上表示每竖列方块的颜色编号(颜色不多于10 种,从1 开始顺序编号,相同数字表示相同颜色)。
输入数据保证初始棋盘中没有可以消除的方块。
【输出】输出文件名为 mayan.out。
如果有解决方案,输出n 行,每行包含3 个整数x,y,g,表示一次移动,每两个整数之间用一个空格隔开,其中(x,y)表示要移动的方块的坐标,g 表示移动的方向,1 表示向右移动,-1 表示向左移动。
注意:多组解时,按照x 为第一关健字,y 为第二关健字,1优先于-1,给出一组字典序最小的解。
游戏界面左下角的坐标为(0,0)。
如果没有解决方案,输出一行,包含一个整数-1。
【输入输出样例 1】mayan.in mayan.out31 02 1 02 3 4 03 1 02 434 02 1 13 1 13 0 1【输入输出样例说明】按箭头方向的顺序分别为图 6 到图11样例输入的游戏局面如上面第一个图片所示,依次移动的三步是:(2,1)处的方格向右移动,(3,1)处的方格向右移动,(3,0)处的方格向右移动,最后可以将棋盘上所有方块消除。
【数据范围】对于 30%的数据,初始棋盘上的方块都在棋盘的最下面一行;对于 100%的数据,0 < n≤5。
【一句话题意】给定一个存在重力的矩阵,每次只能向左或右交换方块,连续3个或以上的方块群会被消除。
求操作次数为N时的操作步骤。
【考察知识点】DFS【思路】我实在是忍不住吐槽了,第三题竟然是iPhone上Mayan Puzzle游戏的完全复制。
见贴吧此帖子。
威锋上果然有完全题解啊,第14关果然是样例啊有木有!!!人类智力威武,Orz…………..对于这种完全裸搜索,固定搜索顺序,掐死搜索深度,基本无任何剪枝的题目彻底无语。
恩,吐槽完毕。
注意注意,第一页描述这题每个测试点时间限制是3S,我当时就震惊了!首先马上确定这是搜索题目,抛弃所有动规贪心等等。
然后锁定DFS,因为题中已经限定搜索深度,BFS是自找MLE。
再确定状态存储方式,我是将输入逆时针转90°后用数组保存,因此坐标之类的要特别注意。
然后,然后就没什么特别的了,搜素顺序题目已经给了。
设过程down(i),表示将第i列的所有方块下沉。
设函数clear,分行列清空后返回是否可以清空,这里用到连续区间指针l、r优化,类似前向星分组时的操作。