语法分析器构造
LR语法分析器的实现代码(python)

LR语法分析器的实现代码(python)•构造LR(0)项目集:–构造I的闭包CLOSURE(I)的算法如下:i.I的任何项目都属于CLOSURE(I);ii.若A→α•Bβ属于CLOSURE(I),对任何产生式B→γ,B→•γ也属于CLOSURE(I);iii.重复执行上述两步骤直至CLOSURE(I)不再增大为止。
iv.实现代码如下def get_CLOSURE(tmp): # 生成闭包 CLOSURE = [] for it in tmp:if(it not in CLOSURE): CLOSURE.append(it) x, y = it.split(".") if(y == ""): continue v = y[0] if(v in VN): res = get_VN_gram(v) # 返回非终结符产生的A->.aBb形式 forre in res: if(re not in CLOSURE): CLOSURE.append(re) return CLOSURE–Go(I,a)函数构造算法i.I为当前状态,X为文法符号,J为I中所有形如A->α·Xβ的项目的后续项目所组成的集合,而CLOSURE(J)就是项目集I关于X的后续状态ii.实现代码如下def go(item, v): #生成并返回下一个item tmp = [] for it in item: x, y = it.split(".") if(y!=""): if(y[0] == v): new_it = x + y[0] + "." + y[1:] tmp.append(new_it) if(len(tmp)!=0): new_item = get_CLOSURE(tmp) #print(tmp) #print("go(item, "+v + ") = " + str(new_item)) return new_item–判别LR项目集是否合法:•无移进项目和规约项目并存•无多个规约项目并存•代码如下:def lr_is_legal(: # 判别lr是否合法 has_protocol = 0 #是否存在规约项目 has_shift = 0 #是否存在移进项目 for item in items: for it in item: x, y = it.split(".") if(y ==""): if(has_protocol != 0 or has_shift != 0): return False has_protocol = 1 else: if(y[0] in VT): has_shift = 1 return True•构造LR(0)分析表–构造算法:i.假定项目集规范族C={I0,I1,…,In}。
C语言词法分析器构造实验报告
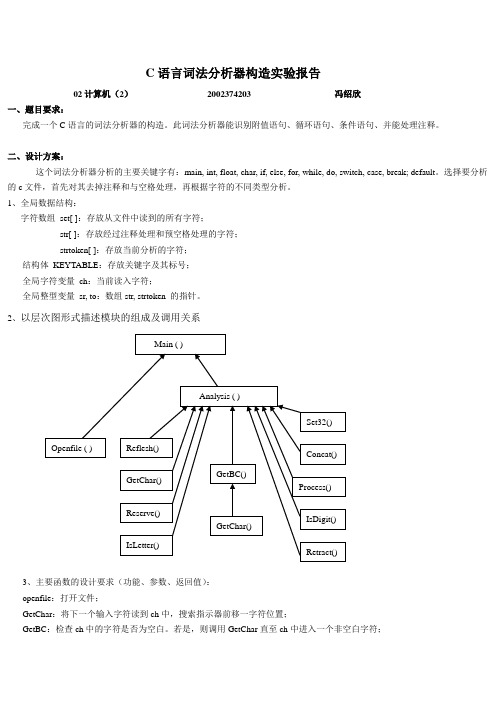
C语言词法分析器构造实验报告02计算机(2)2002374203 冯绍欣一、题目要求:完成一个C语言的词法分析器的构造。
此词法分析器能识别附值语句、循环语句、条件语句、并能处理注释。
二、设计方案:这个词法分析器分析的主要关键字有:main, int, float, char, if, else, for, while, do, switch, case, break; default。
选择要分析的c文件,首先对其去掉注释和与空格处理,再根据字符的不同类型分析。
1、全局数据结构:字符数组set[ ]:存放从文件中读到的所有字符;str[ ]:存放经过注释处理和预空格处理的字符;strtoken[ ]:存放当前分析的字符;结构体KEYTABLE:存放关键字及其标号;全局字符变量ch:当前读入字符;全局整型变量sr, to:数组str, strtoken 的指针。
2、以层次图形式描述模块的组成及调用关系3、主要函数的设计要求(功能、参数、返回值):openfile:打开文件;GetChar:将下一个输入字符读到ch中,搜索指示器前移一字符位置;GetBC:检查ch中的字符是否为空白。
若是,则调用GetChar直至ch中进入一个非空白字符;Concat:将ch中的字符连接到strtoken之后;IsLetter 和IsDigit:布尔函数过程,分别判断ch中的字符是否为字母和数字;Reserve:整型函数过程,对strtoken中的字符串查找关键字表,若是关键字则返回编码,否则返回-1;Retract:将搜索指示器回调一个字符位置,将ch置为空白字符;reflesh:刷新,把strtoken数组置为空;prearrange1:将注释部分置为空格;prearrange2:预处理空格,去掉多余空格;analysis:词法分析;main:主函数。
4、状态转换图:字符a包括:= , & , | , + , --字符b包括:-- , < , > , | , *字符c包括:, , : , ( , ) , { , } , [ , ] , ! ,# , % , ” , / , * , + , -- , > , <, .三、源代码如下:#include <stdio.h>#include <string.h>char set[1000],str[500],strtoken[20];char sign[50][10],constant[50][10];char ch;int sr,to,id=0,st=0;typedef struct keytable /*放置关键字*/{char name[20];int kind;}KEYTABLE;KEYTABLE keyword[]={ /*设置关键字*/{"main",0},{"int",1},{"float",2},{"char",3},{"if",4},{"else",5},{"for",6},{"while",7},{"do",8},{"switch",9},{"case",10},{"break",11},{"default",12},};openfile() /*打开文件*/{FILE *fp;char a,filename[10];int n=0;printf("Input the filename:");gets(filename);if((fp=fopen(filename,"r"))==NULL){printf("cannot open file.\n");exit(0);}elsewhile(!feof(fp)) /*文件不结束,则循环*/{a=getc(fp); /*getc函数带回一个字符,赋给a*/set[n]=a; /*文件的每一个字符都放入set[]数组中*/n++;}fclose(fp); /*关闭文件*/set[n-1]='\0';printf("\n\n-------------------Source Code--------------------------\n\n");puts(set);printf("\n--------------------------------------------------------\n");}reflesh() /*清空strtoken数组*/{to=0; /*全局变量to是strtoken的指示器*/strcpy(strtoken," ");}prearrange1() /*预处理程序1*/{int i,a,b,n=0;do{if(set[n]=='/' && set[n+1]=='*'){a=n; /*记录第一个注释符的位置*/while(!(set[n]=='*' && set[n+1]=='/'))n++;b=n+1; /*记录第二个注释符的位置*/for(i=a;i<=b;i++) /**/set[i]=' '; /*把注释的内容换成空格,等待第二步预处理*/ }n++;}while(set[n]!='\0');}prearrange2() /*预处理程序2*/{int j=0;sr=0; /*全局变量sr是str[]的指示器*/do{if(set[j]==' ' || set[j]=='\n'){while(set[j]==' ' || set[j]=='\n') /*扫描到有连续的空格或换行符*/j++;str[sr]=' '; /*用一个空格代替扫描到的连续空格和换行符放入str[]*/sr++;}else{str[sr]=set[j]; /*若当前字符不为空格或换行符就直接放入str[]*/sr++;j++;}}while(set[j]!='\0');str[sr]='\0';}char GetChar() /*把字符读入全局变量ch中,指示器sr前移*/{ch=str[sr];sr++;return(str[sr-1]);}void GetBC() /*开始读入符号,直至第一个不为空格*/{while(ch==' '){ch=GetChar();}}Concat() /*把ch中的字符放入strtoken[]*/{strtoken[to]=ch;to++; /*全局变量to是strtoken的指示器*/strtoken[to]='\0';}int IsLetter() /*判断是否为字母*/{if((ch>=65 && ch<=90)||(ch>=97 && ch<=122))return(1);else return(0);}int IsDigit() /*判断是否为数字*/{if(ch>=48 && ch<=57)return(1);else return(0);}int Reserve() /*对strtoken中的字符串查找保留字表,若是则返回它的编码,否则返回-1*/ {int i,k=0;for(i=0;i<=20;i++){if(strcmp(strtoken,keyword[i].name)==0){ k=1;return(keyword[i].kind);}}if(k!=1)return(-1);}void Retract() /*指示器sr回调一个字符位置,把ch置为空*/{sr--;}int InsertId(){int i,k;for(i=0;i<id;i++){k=strcmp(strtoken,sign[i]);if(k==0)return(i);}strcpy(sign[id],strtoken); /*插入标识符*/id++;return(id-1);}int InsertConst(){int i,k;for(i=0;i<st;i++){k=strcmp(strtoken,constant[i]);if(k==0)return(i);}strcpy(constant[st],strtoken); /*插入常数*/st++;return(st-1);}void analysis(){int value;reflesh(); /*清空strtoken数组*/prearrange1(); /*预处理,使注释内容换成单个空格,放回set[]中*/prearrange2(); /*预处理,使set[]中连续的空格置换成单个空格,并把set[]的内容放到str[]中*/GetChar();GetBC(); /*读取第一个字符*/while(ch!='\0') /*当不等于结束符,继续执行*/{if(IsLetter()){while(IsLetter() || IsDigit()) /*若第一个是字符,继续读取,直到出现空格*/{Concat();GetChar();}Retract(); /*指示器sr回调一个字符位置,把ch置为空*/value=Reserve(); /*对strtoken中的字符串查找保留字表,若是则返回它的编码,否则返回-1*/ if(value==-1) /*如果返回值是-1,那就是变量,把它输出*/{InsertId(); /*插入标识符*/printf("\n%s",strtoken);getch();}else /*否则就是关键字,也输出*/{printf("\n%s",strtoken);getch();}reflesh();}else if(IsDigit()){while(IsDigit()) /*否则,若第一个是数字,继续读取,知道出现空格*/{Concat();GetChar();}Retract();InsertConst(); /*插入常数*/printf("\n%s",strtoken);getch();reflesh();}elseswitch(ch) /*否则,若是下面的符号,就直接把它输出*/{case ',':case ';':case '(':case ')':case '{':case '}':case '[':case ']':case '!':case '#':case '%':case '"':case '/':case '*':Concat();printf("\n'%s'",strtoken);getch();reflesh();break;default:if(ch=='=' || ch=='&' || ch=='|' || ch=='+' || ch=='-') /*如果是这些符号,继续读取下一个*/ {Concat(); /*判断是否为==,&&,||,++,--的情况*/GetChar();if(ch==strtoken[0])Concat();elseRetract();printf("\n'%s'",strtoken);getch();reflesh();break;}else if(ch=='+' || ch=='-' || ch=='<' || ch=='>' || ch=='!' || ch=='*'){Concat(); /*判断是否为+=,-=,<=,>=,!=,*=的情况*/GetChar();if(ch=='=')Concat();elseRetract();printf("\n'%s'",strtoken);getch();reflesh();break;}else{printf("Error!");getch();break;}}GetChar();GetBC();}}main(){clrscr();openfile();analysis();printf(“analysis is over!”);}五、测试结果:1、分析文件test1.c中的程序:Input the filename:test.c*****************Original Code************************/* HELLO.C -- Hello, world */#include "stdio.h"#include "conio.h"main(){printf("Hello, world\n");getch();}*****************************************************'#'include'"'stdio'.'h'"''#'include'"'conio'.'h'"'main'('')''{'printf'(''"'Hello','worldError!n'"'')'';'getch'('')'';''}'Analysis is over!六、实验总结:这个程序主要参考书上关于词法分析器的设计。
编译原理实验二LL(1)语法分析实验报告

专题3_LL(1)语法分析设计原理与实现李若森 13281132 计科1301一、理论传授语法分析的设计方法和实现原理;LL(1) 分析表的构造;LL(1)分析过程;LL(1)分析器的构造。
二、目标任务实验项目实现LL(1)分析中控制程序(表驱动程序);完成以下描述算术表达式的 LL(1)文法的LL(1)分析程序。
G[E]:E→TE’E’→ATE’|εT→FT’T’→MFT’|εF→(E)|iA→+|-M→*|/设计说明终结符号i为用户定义的简单变量,即标识符的定义。
加减乘除即运算符。
设计要求(1)输入串应是词法分析的输出二元式序列,即某算术表达式“专题 1”的输出结果,输出为输入串是否为该文法定义的算术表达式的判断结果;(2)LL(1)分析程序应能发现输入串出错;(3)设计两个测试用例(尽可能完备,正确和出错),并给出测试结果。
任务分析重点解决LL(1)表的构造和LL(1)分析器的实现。
三、实现过程实现LL(1)分析器a)将#号放在输入串S的尾部b)S中字符顺序入栈c)反复执行c),任何时候按栈顶Xm和输入ai依据分析表,执行下述三个动作之一。
构造LL(1)分析表构造LL(1)分析表需要得到文法G[E]的FIRST集和FOLLOW集。
构造FIRST(α)构造FOLLOW(A)构造LL(1)分析表算法根据上述算法可得G[E]的LL(1)分析表,如表3-1所示:表3-1 LL(1)分析表主要数据结构pair<int, string>:用pair<int, string>来存储单个二元组。
该对照表由专题1定义。
map<string, int>:存储离散化后的终结符和非终结符。
vector<string>[][]:存储LL(1)分析表函数定义init:void init();功能:初始化LL(1)分析表,关键字及识别码对照表,离散化(非)终结符传入参数:(无)传出参数:(无)返回值:(无)Parse:bool Parse( const vector<PIS> &vec, int &ncol );功能:进行该行的语法分析传入参数:vec:该行二元式序列传出参数:emsg:出错信息epos:出错标识符首字符所在位置返回值:是否成功解析。
实验5---语法分析器(自下而上):LR(1)分析法

实验5---语法分析器(自下而上):LR(1)分析法一、实验目的构造LR(1)分析程序,利用它进行语法分析,判断给出的符号串是否为该文法识别的句子,了解LR(K)分析方法是严格的从左向右扫描,和自底向上的语法分析方法。
二、实验内容程序输入/输出示例(以下仅供参考):对下列文法,用LR(1)分析法对任意输入的符号串进行分析:(1)E->E+T(2)E->E—T(3)T->T*F(4)T->T/F(5)F-> (E)(6)F->i输出的格式如下:(1)LR(1)分析程序,编制人:姓名,学号,班级(2)输入一个以#结束的符号串(包括+—*/()i#):在此位置输入符号串(3)输出过程如下:3.对学有余力的同学,测试用的表达式事先放在文本文件中,一行存放一个表达式,同时以分号分割。
同时将预期的输出结果写在另一个文本文件中,以便和输出进行对照。
三、实验方法1.实验采用C++程序语言进行设计,文法写入程序中,用户可以自定义输入语句;2.实验开发工具为DEV C++。
四、实验步骤1.定义LR(1)分析法实验设计思想及算法①若ACTION[sm , ai] = s则将s移进状态栈,并把输入符号加入符号栈,则三元式变成为:(s0s1…sm s , #X1X2…Xm ai , ai+1…an#);②若ACTION[sm , ai] = rj则将第j个产生式A->β进行归约。
此时三元式变为(s0s1…sm-r s , #X1X2…Xm-rA , aiai+1…an#);③若ACTION[sm , ai]为“接收”,则三元式不再变化,变化过程终止,宣布分析成功;④若ACTION[sm , ai]为“报错”,则三元式的变化过程终止,报告错误。
2.定义语法构造的代码,与主代码分离,写为头文件LR.h。
3.编写主程序利用上文描述算法实现本实验要求。
五、实验结果1. 实验文法为程序既定的文法,写在头文件LR.h中,运行程序,用户可以自由输入测试语句。
编译原理实验报告《LL(1)语法分析器构造》(推荐文档)

《LL(1)分析器的构造》实验报告一、实验名称LL(1)分析器的构造二、实验目的设计、编制、调试一个LL(1)语法分析器,利用语法分析器对符号串的识别,加深对语法分析原理的理解。
三、实验内容和要求设计并实现一个LL(1)语法分析器,实现对算术文法:G[E]:E->E+T|TT->T*F|FF->(E)|i所定义的符号串进行识别,例如符号串i+i*i为文法所定义的句子,符号串ii+++*i+不是文法所定义的句子。
实验要求:1、检测左递归,如果有则进行消除;2、求解FIRST集和FOLLOW集;3、构建LL(1)分析表;4、构建LL分析程序,对于用户输入的句子,能够利用所构造的分析程序进行分析,并显示出分析过程。
四、主要仪器设备硬件:微型计算机。
软件: Code blocks(也可以是其它集成开发环境)。
五、实验过程描述1、程序主要框架程序中编写了以下函数,各个函数实现的作用如下:void input_grammer(string *G);//输入文法Gvoid preprocess(string *G,string *P,string &U,string &u,int &n,int &t,int &k);//将文法G预处理得到产生式集合P,非终结符、终结符集合U、u,int eliminate_1(string *G,string *P,string U,string *GG);//消除文法G中所有直接左递归得到文法GGint* ifempty(string* P,string U,int k,int n);//判断各非终结符是否能推导为空string* FIRST_X(string* P,string U,string u,int* empty,int k,int n);求所有非终结符的FIRST集string FIRST(string U,string u,string* first,string s);//求符号串s=X1X2...Xn的FIRST集string** create_table(string *P,string U,string u,int n,int t,int k,string* first);//构造分析表void analyse(string **table,string U,string u,int t,string s);//分析符号串s2、编写的源程序#include<cstdio>#include<cstring>#include<iostream>using namespace std;void input_grammer(string *G)//输入文法G,n个非终结符{int i=0;//计数char ch='y';while(ch=='y'){cin>>G[i++];cout<<"继续输入?(y/n)\n";cin>>ch;}}void preprocess(string *G,string *P,string &U,string &u,int &n,int &t,int &k)//将文法G预处理产生式集合P,非终结符、终结符集合U、u,{int i,j,r,temp;//计数char C;//记录规则中()后的符号int flag;//检测到()n=t=k=0;for( i=0;i<50;i++) P[i]=" ";//字符串如果不初始化,在使用P[i][j]=a时将不能改变,可以用P[i].append(1,a)U=u=" ";//字符串如果不初始化,无法使用U[i]=a赋值,可以用U.append(1,a) for(n=0;!G[n].empty();n++){ U[n]=G[n][0];}//非终结符集合,n为非终结符个数for(i=0;i<n;i++){for(j=4;j<G[i].length();j++){if(U.find(G[i][j])==string::npos&&u.find(G[i][j])==string::npos)if(G[i][j]!='|'&&G[i][j]!='^')//if(G[i][j]!='('&&G[i][j]!=')'&&G[i][j]!='|'&&G[i][j]!='^')u[t++]=G[i][j];}}//终结符集合,t为终结符个数for(i=0;i<n;i++){flag=0;r=4;for(j=4;j<G[i].length();j++){P[k][0]=U[i];P[k][1]=':';P[k][2]=':';P[k][3]='=';/* if(G[i][j]=='('){ j++;flag=1;for(temp=j;G[i][temp]!=')';temp++);C=G[i][temp+1];//C记录()后跟的字符,将C添加到()中所有字符串后面}if(G[i][j]==')') {j++;flag=0;}*/if(G[i][j]=='|'){//if(flag==1) P[k][r++]=C;k++;j++;P[k][0]=U[i];P[k][1]=':';P[k][2]=':';P[k][3]='=';r=4;P[k][r++]=G[i][j];}else{P[k][r++]=G[i][j];}}k++;}//获得产生式集合P,k为产生式个数}int eliminate_1(string *G,string *P,string U,string *GG)//消除文法G1中所有直接左递归得到文法G2,要能够消除含有多个左递归的情况){string arfa,beta;//所有形如A::=Aα|β中的α、β连接起来形成的字符串arfa、betaint i,j,temp,m=0;//计数int flag=0;//flag=1表示文法有左递归int flagg=0;//flagg=1表示某条规则有左递归char C='A';//由于消除左递归新增的非终结符,从A开始增加,只要不在原来问法的非终结符中即可加入for(i=0;i<20&&U[i]!=' ';i++){ flagg=0;arfa=beta="";for(j=0;j<100&&P[j][0]!=' ';j++){if(P[j][0]==U[i]){if(P[j][4]==U[i])//产生式j有左递归{flagg=1;for(temp=5;P[j][temp]!=' ';temp++) arfa.append(1,P[j][temp]);if(P[j+1][4]==U[i]) arfa.append("|");//不止一个产生式含有左递归}else{for(temp=4;P[j][temp]!=' ';temp++) beta.append(1,P[j][temp]);if(P[j+1][0]==U[i]&&P[j+1][4]!=U[i]) beta.append("|");}}}if(flagg==0)//对于不含左递归的文法规则不重写{GG[m]=G[i]; m++;}else{flag=1;//文法存在左递归GG[m].append(1,U[i]);GG[m].append("::=");if(beta.find('|')!=string::npos) GG[m].append("("+beta+")");else GG[m].append(beta);while(U.find(C)!=string::npos){C++;}GG[m].append(1,C);m++;GG[m].append(1,C);GG[m].append("::=");if(arfa.find('|')!=string::npos) GG[m].append("("+arfa+")");else GG[m].append(arfa);GG[m].append(1,C);GG[m].append("|^");m++;C++;}//A::=Aα|β改写成A::=βA‘,A’=αA'|β,}return flag;}int* ifempty(string* P,string U,int k,int n){int* empty=new int [n];//指示非终结符能否推导到空串int i,j,r;for(r=0;r<n;r++) empty[r]=0;//默认所有非终结符都不能推导到空int flag=1;//1表示empty数组有修改int step=100;//假设一条规则最大推导步数为100步while(step--){for(i=0;i<k;i++){r=U.find(P[i][0]);if(P[i][4]=='^') empty[r]=1;//直接推导到空else{for(j=4;P[i][j]!=' ';j++){if(U.find(P[i][j])!=string::npos){if(empty[U.find(P[i][j])]==0) break;}else break;}if(P[i][j]==' ') empty[r]=1;//多步推导到空else flag=0;}}}return empty;}string* FIRST_X(string* P,string U,string u,int* empty,int k,int n){int i,j,r,s,tmp;string* first=new string[n];char a;int step=100;//最大推导步数while(step--){// cout<<"step"<<100-step<<endl;for(i=0;i<k;i++){//cout<<P[i]<<endl;r=U.find(P[i][0]);if(P[i][4]=='^'&&first[r].find('^')==string::npos) first[r].append(1,'^');//规则右部首符号为空else{for(j=4;P[i][j]!=' ';j++){a=P[i][j];if(u.find(a)!=string::npos&&first[r].find(a)==string::npos)//规则右部首符号是终结符{first[r].append(1,a);break;//添加并结束}if(U.find(P[i][j])!=string::npos)//规则右部首符号是非终结符,形如X::=Y1Y2...Yk{s=U.find(P[i][j]);//cout<<P[i][j]<<":\n";for(tmp=0;first[s][tmp]!='\0';tmp++){a=first[s][tmp];if(a!='^'&&first[r].find(a)==string::npos)//将FIRST[Y1]中的非空符加入first[r].append(1,a);}}if(!empty[s]) break;//若Y1不能推导到空,结束}if(P[i][j]==' ')if(first[r].find('^')==string::npos)first[r].append(1,'^');//若Y1、Y2...Yk都能推导到空,则加入空符号}}}return first;}string FIRST(string U,string u,string* first,string s)//求符号串s=X1X2...Xn的FIRST集{int i,j,r;char a;string fir;for(i=0;i<s.length();i++){if(s[i]=='^') fir.append(1,'^');if(u.find(s[i])!=string::npos&&fir.find(s[i])==string::npos){ fir.append(1,s[i]);break;}//X1是终结符,添加并结束循环if(U.find(s[i])!=string::npos)//X1是非终结符{r=U.find(s[i]);for(j=0;first[r][j]!='\0';j++){a=first[r][j];if(a!='^'&&fir.find(a)==string::npos)//将FIRST(X1)中的非空符号加入fir.append(1,a);}if(first[r].find('^')==string::npos) break;//若X1不可推导到空,循环停止}if(i==s.length())//若X1-Xk都可推导到空if(fir.find(s[i])==string::npos) //fir中还未加入空符号fir.append(1,'^');}return fir;}string** create_table(string *P,string U,string u,int n,int t,int k,string* first)//构造分析表,P为文法G的产生式构成的集合{int i,j,p,q;string arfa;//记录规则右部string fir,follow;string FOLLOW[5]={")#",")#","+)#","+)#","+*)#"};string **table=new string*[n];for(i=0;i<n;i++) table[i]=new string[t+1];for(i=0;i<n;i++)for(j=0;j<t+1;j++)table[i][j]=" ";//table存储分析表的元素,“ ”表示error for(i=0;i<k;i++){arfa=P[i];arfa.erase(0,4);//删除前4个字符,如:E::=E+T,则arfa="E+T"fir=FIRST(U,u,first,arfa);for(j=0;j<t;j++){p=U.find(P[i][0]);if(fir.find(u[j])!=string::npos){q=j;table[p][q]=P[i];}//对first()中的每一终结符置相应的规则}if(fir.find('^')!=string::npos){follow=FOLLOW[p];//对规则左部求follow()for(j=0;j<t;j++){if((q=follow.find(u[j]))!=string::npos){q=j;table[p][q]=P[i];}//对follow()中的每一终结符置相应的规则}table[p][t]=P[i];//对#所在元素置相应规则}}return table;}void analyse(string **table,string U,string u,int t,string s)//分析符号串s{string stack;//分析栈string ss=s;//记录原符号串char x;//栈顶符号char a;//下一个要输入的字符int flag=0;//匹配成功标志int i=0,j=0,step=1;//符号栈计数、输入串计数、步骤数int p,q,r;string temp;for(i=0;!s[i];i++){if(u.find(s[i])==string::npos)//出现非法的符号cout<<s<<"不是该文法的句子\n";return;}s.append(1,'#');stack.append(1,'#');//’#’进入分析栈stack.append(1,U[0]);i++;//文法开始符进入分析栈a=s[0];//cout<<stack<<endl;cout<<"步骤分析栈余留输入串所用产生式\n";while(!flag){// cout<<"步骤分析栈余留输入串所用产生式\n"cout<<step<<" "<<stack<<" "<<s<<" ";x=stack[i];stack.erase(i,1);i--;//取栈顶符号x,并从栈顶退出//cout<<x<<endl;if(u.find(x)!=string::npos)//x是终结符的情况{if(x==a){s.erase(0,1);a=s[0];//栈顶符号与当前输入符号匹配,则输入下一个符号cout<<" \n";//未使用产生式,输出空}else{cout<<"error\n";cout<<ss<<"不是该文法的句子\n";break;}}if(x=='#'){if(a=='#') {flag=1;cout<<"成功\n";}//栈顶和余留输入串都为#,匹配成功else{cout<<"error\n";cout<<ss<<"不是该文法的句子\n";break;}}if(U.find(x)!=string::npos)//x是非终结符的情况{p=U.find(x);q=u.find(a);if(a=='#') q=t;temp=table[p][q];cout<<temp<<endl;//输出使用的产生式if(temp[0]!=' ')//分析表中对应项不为error{r=9;while(temp[r]==' ') r--;while(r>3){if(temp[r]!='^'){stack.append(1,temp[r]);//将X::=x1x2...的规则右部各符号压栈i++;}r--;}}else{cout<<"error\n";cout<<ss<<"不是该文法的句子\n";break;}}step++;}if(flag) cout<<endl<<ss<<"是该文法的句子\n";}int main(){int i,j;string *G=new string[50];//文法Gstring *P=new string[50];//产生式集合Pstring U,u;//文法G非终结符集合U,终结符集合uint n,t,k;//非终结符、终结符个数,产生式数string *GG=new string[50];//消除左递归后的文法GGstring *PP=new string[50];//文法GG的产生式集合PPstring UU,uu;//文法GG非终结符集合U,终结符集合uint nn,tt,kk;//消除左递归后的非终结符、终结符个数,产生式数string** table;//分析表cout<<" 欢迎使用LL(1)语法分析器!\n\n\n";cout<<"请输入文法(同一左部的规则在同一行输入,例如:E::=E+T|T;用^表示空串)\n";input_grammer(G);preprocess(G,P,U,u,n,t,k);cout<<"\n该文法有"<<n<<"个非终结符:\n";for(i=0;i<n;i++) cout<<U[i];cout<<endl;cout<<"该文法有"<<t<<"个终结符:\n";for(i=0;i<t;i++) cout<<u[i];cout<<"\n\n 左递归检测与消除\n\n";if(eliminate_1(G,P,U,GG)){preprocess(GG,PP,UU,uu,nn,tt,kk);cout<<"该文法存在左递归!\n\n消除左递归后的文法:\n\n"; for(i=0;i<nn;i++) cout<<GG[i]<<endl;cout<<endl;cout<<"新文法有"<<nn<<"个非终结符:\n";for(i=0;i<nn;i++) cout<<UU[i];cout<<endl;cout<<"新文法有"<<tt<<"个终结符:\n";for(i=0;i<tt;i++) cout<<uu[i];cout<<endl;//cout<<"新文法有"<<kk<<"个产生式:\n";//for(i=0;i<kk;i++) cout<<PP[i]<<endl;}else{cout<<"该文法不存在左递归\n";GG=G;PP=P;UU=U;uu=u;nn=n;tt=t;kk=k;}cout<<" 求解FIRST集\n\n";int *empty=ifempty(PP,UU,kk,nn);string* first=FIRST_X(PP,UU,uu,empty,kk,nn);for(i=0;i<nn;i++)cout<<"FIRST("<<UU[i]<<"): "<<first[i]<<endl;cout<<" 求解FOLLOW集\n\n";for(i=0;i<nn;i++)cout<<"FOLLOW("<<UU[i]<<"): "<<FOLLOW[i]<<endl; cout<<"\n\n 构造文法分析表\n\n"; table=create_table(PP,UU,uu,nn,tt,kk,first);cout<<" ";for(i=0;i<tt;i++) cout<<" "<<uu[i]<<" ";cout<<"# "<<endl;for( i=0;i<nn;i++){cout<<UU[i]<<" ";for(j=0;j<t+1;j++)cout<<table[i][j];cout<<endl;}cout<<"\n\n 分析符号串\n\n";cout<<"请输入要分析的符号串\n";cin>>s;analyse(table,UU,uu,tt,s);return 0;}3、程序演示结果(1)输入文法(2)消除左递归(3)求解FIRST和FOLLOW集(4)构造分析表(5)分析符号串匹配成功的情况:匹配失败的情况五、思考和体会1、编写的LL(1)语法分析器应该具有智能性,可以由用户输入任意文法,不需要指定终结符个数和非终结符个数。
语法分析器生成器YACC
E : num num
再分析3++5
5
分析器动作 移进 num,转向state 3 按(2)“E : num”归约,goto State 1 移进 +,转向State 4 移进error,转向 state 2 按(3)“E : error”归约,goto State 5, 按(1)“E : E‘+’E”归约,goto State 1 移进 +,转向State 4 移进 num,转向 State 3 按(2)“E : num”归约,goto State 5 按(1)“E : E‘+’E”归约,goto State 1 接受
2.2.3.2 YACC对语义的支持
分析器工作原理:
记号流 归约前栈顶 归约后栈顶 $3 E $2 + $1($$) E ... ... 驱动器 分析表 输出
语义栈对语法制导翻译提供直接支持。语义栈的 类型决定了文法符号的属性,语义栈类型表示能力的 强弱决定了YACC的能力。
<1> YACC默认的语义值类型 YACC语义栈与yylval同类型,并以终结符的yylval 值作为栈中的初值。因为yylval的默认类型为整型,所 以,当用户所需文法符号的语义类型是整型时,无需定 义它的类型。如在下述表达式的产生式中: E :E '+' E | E '*' E | num ; { $$=$1+$3;} { $$=$1*$3;}
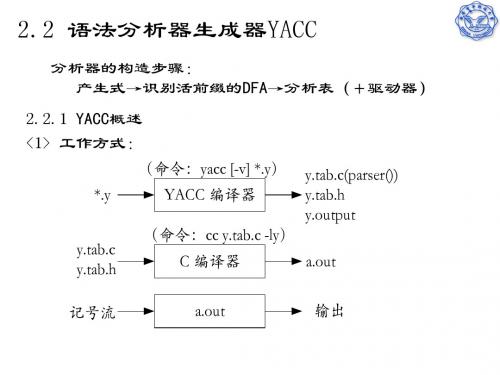
2.2.1 YACC概述
利用YACC进行语法分析器设计的关键,也是如何编写 YACC源程序。 下边首先介绍YACC源程序的基本结构,然后着重讨论 YACC的产生式、YACC解决产生式冲突的方法、以及YACC对语 义的支持和对错误的处理等。
语法分析器实验报告

词法分析器实验报告实验名称:语法分析器实验内容:利用LL(1)或LR(1)分析语句语法,判断其是否符合可识别语法。
学会根据状态变化、first、follow或归约转移思想构造状态分析表,利用堆栈对当前内容进行有效判断实验设计:1.实现功能可对一段包含加减乘除括号的赋值语句进行语法分析,其必须以$为终结符,语句间以;隔离,判断其是否符合语法规则,依次输出判断过程中所用到的产生式,并输出最终结论,若有错误可以报错并提示错误所在行数及原因2.实验步骤3.算法与数据结构a)LLtable:left记录产生式左端字符;right记录产生式右端字符;ln记录产生式右端字符长度Status:记录token分析情况Token:category,类型;value,具体内容b)根据LL(1)算法,手工构造分析表,并将内容用数组存储,便于查找c)先将当前语句的各token按序存储,当前处理语句最后一个token以#标记,作为输入流与产生式比较,堆栈中初始放入#,x,a为处理输入流中当前读头内容✓若top=a=‘#‘表示识别成功,退出分析程序✓若top=a!=‘#‘表示匹配,弹出栈顶符号,读头前进一个✓若top为i或n,但top!=a,出错,输出当前语句所在行,出错具体字符✓若top不为i或n,查预测分析表,若其中存放关于top产生式,则弹出top,将产生式右部自右向左压入栈内,输出该产生式,若其中没有产生式,出错,输出当前语句所在行,出错具体字符d)以;作为语句终结,每次遇到分号则处理之前语句并清空后预备下语句处理,当遇到$表示该段程序结束,停止继续处理4.分析表构造过程a)x->i=ee->e+t|e-t|tt->t*f|t/f|ff->(e)|i|nnote: i表示变量,n表示数字,!表示空串b)提取左公因子x->i=ee->ea|ta->+t|-tt->tb|fb->*f|/ff->(e)|i|nc)消除左递归x->i=ee->tcc->ac|!a->+t|-tt->fdd->bd|!b->*e|/ff->(e)|i|n5.类class parser{public:LLtable table[100][100]; //LL(1)表void scanner(); //扫描输入流中内容并分析parser(istream& in); //初始化,得到输入文件地址int getLine() const; //得到当前行数private:int match(); //分析语法stack <char> proStack; //分析堆栈void constructTable(); //建立LL(1)表int getRow(char ch); //取字符所在表中行int getCol(char ch); //取字符所在表中列istream* pstream; //输入流void insertToken(token& t); //插入当前tokenstatus getToken(token& t); //找到tokenint getChar(); //得到当前字符int peekChar(); //下一个字符void putBackChar(char ch); //将字符放回void skipChar(); //跳过当前字符void initialization(); //初始化堆栈等int line; //当前行数token tokens[1000]; //字符表int counter; //记录当前字符表使用范围}6.主要代码void parser::constructTable() //建立LL(1)表{for (int i=0;i<8;i++){for (int j=0;j<9;j++){table[i][j].left=' ';for (int k=0;k<3;k++)table[i][j].right[k]=' ';}}table[0][6].left='x';table[0][6].ln=3;table[0][6].right[0]='i';table[0][6].right[1]='=';table[0][6].right[2]='e';table[1][4].left='e';table[1][4].ln=2;table[1][4].right[0]='t';table[1][4].right[1]='c';table[1][6].left='e';table[1][6].ln=2;table[1][6].right[0]='t';table[1][6].right[1]='c';table[1][7].left='e';table[1][7].ln=2;table[1][7].right[0]='t';table[1][7].right[1]='c';table[2][0].left='c';table[2][0].ln=2;table[2][0].right[0]='a';table[2][0].right[1]='c';table[2][1].left='c';table[2][1].ln=2;table[2][1].right[0]='a';table[2][1].right[1]='c';table[2][5].left='c';table[2][5].ln=0;table[2][5].right[0]='!';table[2][8].left='c';table[2][8].ln=0;table[2][8].right[0]='!';table[3][0].left='a';table[3][0].ln=2;table[3][0].right[0]='+'; table[3][0].right[1]='t'; table[3][1].left='a';table[3][1].ln=2;table[3][1].right[0]='-'; table[3][1].right[1]='t'; table[4][4].left='t';table[4][4].ln=2;table[4][4].right[0]='f'; table[4][4].right[1]='d'; table[4][6].left='t';table[4][6].ln=2;table[4][6].right[0]='f'; table[4][6].right[1]='d'; table[4][7].left='t';table[4][7].ln=2;table[4][7].right[0]='f'; table[4][7].right[1]='d'; table[5][0].left='d';table[5][0].ln=0;table[5][0].right[0]='!'; table[5][1].left='d';table[5][1].ln=0;table[5][1].right[0]='!'; table[5][2].left='d';table[5][2].ln=2;table[5][2].right[0]='b'; table[5][2].right[1]='d'; table[5][3].left='d';table[5][3].ln=2;table[5][3].right[0]='b'; table[5][3].right[1]='d'; table[5][5].left='d';table[5][5].ln=0;table[5][5].right[0]='!'; table[5][8].left='d';table[5][8].ln=0;table[5][8].right[0]='!'; table[6][2].left='b';table[6][2].ln=2;table[6][2].right[0]='*'; table[6][2].right[1]='f'; table[6][3].left='b';table[6][3].ln=2;table[6][3].right[0]='/'; table[6][3].right[1]='f'; table[7][4].left='f';table[7][4].ln=3;table[7][4].right[0]='(';table[7][4].right[1]='e';table[7][4].right[2]=')';table[7][6].left='f';table[7][6].ln=1;table[7][6].right[0]='i';table[7][7].left='f';table[7][7].ln=1;table[7][7].right[0]='n';}int parser::match() //分析语法{ofstream ofs("out.txt",ios::app);char a;int i=0;for (int p=0;p<counter;p++){cout<<tokens[p].value;ofs<<tokens[p].value;}cout<<endl;ofs<<endl<<"ANALYSIS:"<<endl;while(1){if(tokens[i].category=='n' || tokens[i].category=='i')a=tokens[i].category;elsea=(tokens[i].value)[0];if(a==proStack.top()){if(a=='#'){cout<<"This is valid!"<<endl<<endl;ofs<<"This is valid!"<<endl<<endl;return 0;}else{proStack.pop();i++;}}else{if(proStack.top() =='n'|| proStack.top() =='i'){if(a!='#'){cout<<"ERROR(LINE "<<getLine()<<" ): "<<a<<" cannot be matched"<<endl;ofs<<"ERROR(LINE "<<getLine()<<" ): "<<a<<" cannot be matched"<<endl;}else{cout<<"ERROR(LINE "<<getLine()<<" ): Unexpected ending"<<endl;ofs<<"ERROR(LINE "<<getLine()<<" ): Unexpected ending"<<endl;}cout<<"This is invalid!"<<endl<<endl;ofs<<"This is invalid!"<<endl<<endl;return 0;}else{if((table[getRow(proStack.top())][getCol(a)]).left!=' '){char pst=proStack.top();int n=table[getRow(pst)][getCol(a)].ln;int k=0;ofs<<table[getRow(pst)][getCol(a)].left<<"->"<<table[getRow(pst)][getCol(a)].right[0]<<table[getRow(pst)][g etCol(a)].right[1]<<table[getRow(pst)][getCol(a)].right[2]<<endl;proStack.pop();while (n>0){//cout<<n<<" "<<table[getRow(pst)][getCol(a)].right[n-1]<<endl;proStack.push(table[getRow(pst)][getCol(a)].right[n-1]);n--;}}else{if(a!='#'){cout<<"ERROR(LINE "<<getLine()<<" ): "<<a<<" cannot be matched"<<endl;ofs<<"ERROR(LINE "<<getLine()<<" ): "<<a<<" cannot be matched"<<endl;}else{cout<<"ERROR(LINE "<<getLine()<<" ): Unexpected ending"<<endl;ofs<<"ERROR(LINE "<<getLine()<<" ): Unexpected ending"<<endl;}cout<<"This is invalid!"<<endl<<endl;ofs<<"This is invalid!"<<endl<<endl;return 0;}}}}}实验结果:●输入(in.txt)●输出1输出2(out.txt)实验总结:原本以为处理四则运算赋值将会很困难,但在使用LL(1)后发现,思路还是挺清晰简单的,但在实验过程中,由于LL(1)不能出现左递归和左公因子,不得不将其消除,原本简单的产生式一下变多了,而在产生式理解上也没有原来直观,不过其状态复杂度没有LR高,故仍选择该方法。
语法分析器设计实验报告

学号《编译原理》实验2:语法分析器设计学生姓名专业、班级指导教师赵璐成绩计算机与信息工程学院2018 年11 月27 日一、实验目的1.理解语法分析程序的功能。
2.熟悉语法分析程序的设计原理和构造方法。
3.掌握递归下降语法分析程序的构造方法。
4.设计一个递归下降的语法分析器,作为实验一构造的词法分析器的下一步编译工具,能语法分析前一步词法分析器输出的单词符号序列。
二、实验要求1.根据书P206给出的简单语言的语法规则,编写C或C++语言源程序,实现针对该简单语言的递归下降的语法分析器;2.独立做实验,输入、调试所编程序;3.实验结束后,根据实验报告模板编写实验报告。
三、实验内容和步骤用Visual C++作为实验开发环境,创建一个Win32 Console Application工程,工程名为你的学号,添加三个文件:(1)存储结构定义:以ParserDef.h和LexerDef.h为文件名;(2)基本操作的算法:以ParserAlgo.h和LexerAlgo.h为文件名;(3)调用基本操作的主程序:以ParserMain.cpp为文件名。
编写程序:(1)文件LexerDef.h和LexerAlgo.h为实验一的内容。
(2)文件ParserDef.h定义语法分析所需的全局变量等。
(3)文件ParserAlgo.h实现对语法规则中各语法成分的分析子算法。
(4)文件ParserMain.cpp实现针对P206简单语言语法规则的递归下降语法分析器。
源程序代码:=============================ParserDef.h================================ int kk;#define _KEY_WORD_END "waiting for your expanding"char * rwtab[]={"begin","if","then","while","do","end",_KEY_WORD_END};char input[255];char token[255]="";int p_input;int p_token;char ch;============================ParserAlgo.h================================ char prog[80];int syn,p,m,n,sum=0;void scaner() {m=0;for(n=0; n<8; n++) token[n]=NULL;ch=prog[p++];while(ch==' ') ch=prog[p++];if((ch>='a' && ch<='z') ||(ch>='A' && ch<='Z')) {while((ch>='a' && ch<='z') ||(ch>='A' && ch<='Z')||(ch>='0' && ch<='9')) {token[m++]=ch;ch=prog[p++];}token[m++]='\0';syn=10;p=p-1; //回退一个字符for(n=0; n<6; n++) {if(strcmp(token,rwtab[n])==0) {syn=n+1;break;}}} else if(ch>='0' && ch<='9') {sum=0;while(ch>='0' && ch<='9') {sum=sum*10+ch-'0';ch=prog[p++];}p=p-1;syn=11;} else {switch(ch) {case '<':m=0;token[m++]=ch;ch=prog[p];if(ch=='>') {syn=21;token[m++]=ch;} else if(ch=='=') {syn=22;token[m++]=ch;} else {syn=20;p=p-1;}p=p+1;token[m]='\0';break;case '>':m=0;token[m++]=ch;ch=prog[p++];if(ch=='=') {syn=24;token[m++]=ch;} else {syn=23;p=p-1;}break;case ':':m=0;token[m++]=ch;ch=prog[p++];if(ch=='=') {syn=18;token[m++]=ch;} else {syn=17;p=p-1;}break;case '+':syn=13;token[0]=ch;break;case '-':syn=14;token[0]=ch;break;case '*':syn=15;token[0]=ch;break;case '/':syn=16;token[0]=ch;break;case ';':syn=26;token[0]=ch;break;case '(':syn=27;token[0]=ch;break;case ')':syn=28;token[0]=ch;break;case '=':syn=25;token[0]=ch;break;case '#':syn=0;token[0]=ch;break;default:syn=-1;}}}============================ParserMain.cpp============================== #include<stdio.h>#include<stdlib.h>#include<string.h>#include"LexerDef.h"#include"ParserDef.h"#include"LexerAlgo.h"#include"ParserAlgo.h"void lrparser();void yucu();void statement();void expression();void term();void factor();void lrparser() {if (syn==1) { //beginscaner();yucu();if (syn==6) { //endscaner();if (syn==0 && kk==0) printf("success \n");} else {if(kk!=1) printf("error,lose 'end' ! \n");kk=1;}} else {printf("error,lose 'begin' ! \n");kk=1;}return;}void yucu() {statement();while(syn==26) {scaner();statement();}return;}void statement() {if (syn==10) { //为标识符scaner();if (syn==18) { //为:=scaner();expression();} else {printf("error!");kk=1;}} else {printf("error!");kk=1;}return;}void expression() {term();while(syn==13 || syn==14) {scaner();term();}return;}void term() {factor();while(syn==15 || syn==16) {scaner();factor();}return;}void factor() {if(syn==10 || syn==11)scaner(); //为标识符或整常数时,读下一个单词符号else if(syn==27) {scaner();expression();if(syn==28)scaner();else {printf(" ')' 错误\n");kk=1;}} else {printf("表达式错误\n");kk=1;}return;}void main() {p=0;printf("********************语法分析程序***************\n");printf("请输入源程序:\n");do {scanf("%c",&ch);prog[p++]=ch;} while(ch!='#');p=0;scaner();lrparser();printf("语法分析结束!\n");}四、解答下列问题(1)简述该语法分析器的算法思想。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
编译原理实验报告实验题目:语法分析器构造
~
指导教师:
姓名:
班级:
学号:。
实验成绩:
实验题目语法分析器构造
?
实验目的和要求借助于词法分析程序提供的分析结果,编写一个算符优先语法分析程序,程序能进行语法结构分析和错误检查并产生相应的归约信息。
同时给出出错信息和错误类型,从而加深对语法分析的理解。
设计思想与框架*
main函数:
算术表达式函数:
算符优先算法:
核心算法主要数据结构说明:
符号栈:stack[N]
栈顶指针:top
】
记录归约步骤号:No[N]
输入字符串:strings[N]
算术表达式:old_strings[N]
记录下一个输入符号:a
可归约字符串:*word[6]
手动生成的算符优先表:x[9][9]
查找算符表达式:expression(char *str)
入栈:push(char ch)
int top=-1;
int k=0;表示项.F表示因子.i表示变量或常数.\n");
printf(" 优先表\n");
printf(" + - * / ( ) i #\n");
printf(" + > > < < < > < >\n");
printf(" - > > < < < > < >\n");
printf(" * > > > > < > < >\n");
printf(" / > > > > < > < >\n");
printf(" ( < < < < < = < e1\n");
…
printf(" ) > > > > e2 > e2 >\n");
printf(" i > > > > e2 > e2 >\n");
printf(" # < < < < < e3 < =\n");
if((fp=fopen("预处理.txt","r"))==NULL)
{
printf("文件打开失败!");
exit(0);
}
char ch[4048]={'\0'};
int i=0,j=0;
—
ch[0]=fgetc(fp);
while(ch[i]!='#')//将预处理文件的内容读入至数组ch中
ch[++i]=fgetc(fp);
ch[++i]='\0';
fclose(fp);
i=0;
while(ch[i]!='#')
{
memset(strings,0,sizeof(strings));//输入表达式strings初始化
memset(old_strings,0,sizeof(old_strings));。
expression(ch);//查找算术表达式
if(ch[sr]=='\0')
break;
printf("算术表达式%d为:%s\n",id,old_strings);
printf("转换为输入串:%s\n",strings);
printf(" 步骤号符号栈优先关系当前分析符剩余输入串动作\n");
analysis();//算符优先分析
int n=0;
printf("\n算术表达式%d的归约产生式步骤号为:",id++);
while(No[n])
》
{
实验结果
实验心得这次实验让我更进一步弄清楚了算符优先文法的概念,弄懂了从找出终结符firstVT集合、lastVT集合,到构造算符优先表,再到查
找句型的最左素短语,最后进行算符优先归约这一整个过程,让我
对语法分析器的构造有了深刻的理解。
也锻炼了我利用C语言编写。