2.2 一个简单的词法分析器示例
编译原理(2)词法_2(NFA、DFA的确定化和化简)

第 3 讲
主讲教师:赵建邦
本讲目标
第二章《词法分析》2.3-2.5节
2.3 2.4 2.5
正规表达式与有限自动机简介 正规表达式到优先自动机的构造 词法分析器的自动生成
重点掌握
有限自动机理论 有限自动机的构造、确定化和化简
第二章 词法分析
2.1 2.2
• DFA是一个五元组,Md= (S, ∑, f, s0 , Z) ,其中: (1) S是一个有限状态集合,它的每个元素称为一个状态 (2) ∑是一个有穷字母表,它的每个元素称为一个输入字符 (3) f是一个从S×∑至S的单值映射,也叫状态转移函数 (4) s0∈S 是唯一的初态 (5) Z S 是一个终态集
J中的每一个状态经过任意条 ε通路得到ε_CLOSURE(J) =
4
Ia= {5,6,2,3,8,4,7}
2.4
正规表达式到有限自动机的构造
2.4.2:NFA的确定化(子集法)
(1) 构造一张转换表,第一列记为状态子集I,对于不同的符号
(a∈Σ),在表中单设一列Ia ; (2) 表的首行首列置为ε_CLOSURE(s0),其中s0为初始状态; (3) 根据首行首列的I,为每个a求其Ia 并记入对应的Ia 列中, 如果此Ia 不同于第一列中已存在的所有状态子集I,则将其
si
r1 r2 r1 *
sj sj
si
si
sj
si
2.4
正规表达式到有限自动机的构造
例2.6 对给定正规表达式 b*(d|ad)(b|ab)+ 构造其NFA M [解答] 先用R+=RR*改造正规表达式 b*(d|ad)(b|ab)+ = b*(d|ad)(b|ab)(b|ab)* 按照正规式从左到右构造NFA: b X ε 1 ε 2 a 3
2.2 一个简单的词法分析器示例

(4)concatenation( ): 将token中字符串与 character中字符连接作为token中的新 字符串。 (5)letter( )和digit( ): 判断character中的字 符是否为字母和数字的布尔函数,若是 则返回true, 否则返回false。 (6)reserve( ): 按token数组中的字符串查 保留字表, 若是保留字则返回其编码, 否则返回0。
2014-9-26 5
对保留字专设对应的状态转换图:
C语言子集对应的状态转换图如下:
6
2014-9-26
空白 字母或数字
开始 0
字母 1 非字母数字 2 * 返回(id, id在符号表中位置)
数字 数字 3 4 * 非数字 + 5 - 6 * < = ; 其它
2014-9-26
或返回(保留字, -)
2014-9-26 8
2.2.3 状态转换图的实现 状态转换图易于用程序实现,最简单的 办法是让每个状态对应一小段程序。对于 图2–5,首先引进一组变量和过程: (1)character: 字符变量,存放最新读入 的源程序字符。 (2)token: 字符数组,存放构成单词符号 的字符串。 (3)getbe( ): 若character中字符为空,则 调用getchar( ),直至character为非空。
2014-9-26 15
case '=': getchar ( ); if (character=='=') return(relop,EQ); else { retract ( ); return ('=', _ ); } break; case ';': return (';', -); break; default: error ( ); }
第2章 词法分析-sxw

正规表达式是典型的词法规则描述工具.
正规式也称正则表达式. 正规表达式(regular expression)是说明单词的模 式(pattern)的一种重要的表示法(记号),是定义正 规集的数学工具.我们用以描述单词符号.下面是 正规式和它所表示的正规集的递归定义.
第2章 词法分析
程序语言中使用的标识符是一个以字母开头的字 母数字串,如果字母用letter表示,数字用digit表示, 则标识符可表示为 letter (letter∣digit)* 其中,letter与 (letter∣digit)*的并置表示两者的连 接;括号中的"∣"表示letter或digit两者选一;"*" 表示零次或多次引用由"*"标记的表达式; (letter∣digit)*是letter∣digit的零次或多次并置,即表 示 一 长 度 为 0 , 1 , 2 , … 的 字 母 数 字 串 ; letter (letter∣digit)*表示以字母开头的字母数字串,也即标 识符集.letter (letter∣digit)*就是表示标识符的正规式, 而标识符集就是这个正规式所表示的正规集.
第2章 词法分析
retract ( ); c=reserve ( ); if (c==0) { buildlist ( );
/*扫描指针回退一个字符*/
/*将标识符登录到符号表中*/
return (id,指向id的符号表入口指针); } else return (保留字码,null); break;
第2章 词法分析
x i y
j
k
图2–2 不同输入字符的状态转换
第2章 词法分析
简单的词法分析器
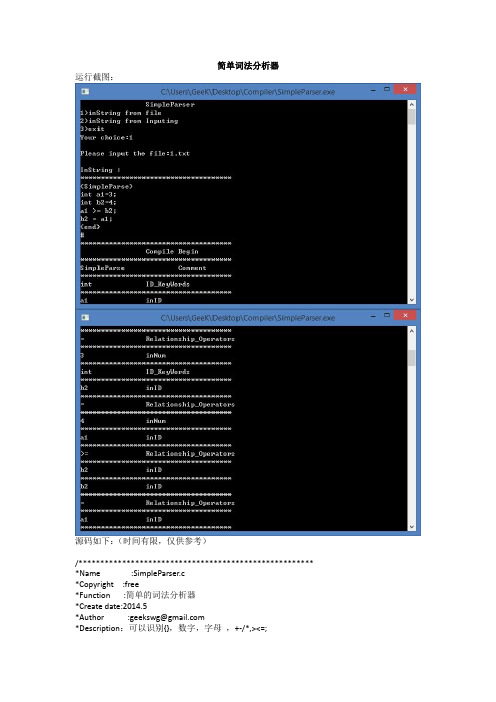
简单词法分析器运行截图:源码如下:(时间有限,仅供参考)/****************************************************** *Name :SimpleParser.c*Copyright :free*Function :简单的词法分析器*Create date:2014.5*Author :geekswg@*Description:可以识别{},数字,字母,+-/*,><=;******************************************************/ #include<stdio.h>//#include<stdbool.h>//C99包含bool头文件,VC6.0报错#include<memory.h>#include<string.h>//包含strcmp()函数//宏定义bool类型兼容VC6.0#define bool char#define true 1#define false 0#define MAXSIZE 500#define SOC '{' //start of comment#define EOC '}' //end of comment/*#define ADD +#define MIN -#define MUL *#define DIV /*/char inStr[MAXSIZE];//bool型,是否是关键字,是返回truebool isKeyword(char s1[],char s2[]){if(!strcmp(s1,s2))return true;elsereturn false;}//bool型,是否是数字,是返回truebool isDigit(char c){if(c > 47 && c<58){//ASCII(0-9)return true;}elsereturn false;}//bool型,是否是字符,是返回truebool isLetter(char c){if((c > 64 && c < 91) || (c >96 && c <123)){//A-Z,a-z)return true;}elsereturn false;}//读入待分析的字符串;void inFile(char inStr[]){FILE *fp;//文件指针int i = 0;char filename[50]; //文件名memset(filename,0,sizeof(filename)); //清空数组;printf("\nPlease input the file:");scanf("%s",&filename);// printf("\n%s",filename);while((fp = fopen(filename,"r"))==NULL){//以只读方式打开文件printf("\nCan't Find file!Input again:");scanf("%s",&filename);}while(!feof(fp)){//直到文件结束符停止fscanf(fp,"%c",&inStr[i]);//将文件中的数据写到inStr中i++;}inStr[i]='\0';fclose(fp);}//录入待分析的字符串;void inString(char inStr[]){//录入函数int i=0;char inchar;printf("SimpleParser For Test \n");printf("Please Inpuet Strings:(End of '#')\n:");while( inchar !='#'){//以#为结束符标志;scanf("%c",&inchar);inStr[i++] = inchar;}}/**********************************//打印数组//参数待分析字符串,备注信息字符串//***********************************/void display(char inStr[],char info[]){//打印数组int i = 0;printf("\n*************************************\n");while( inStr[i] != '\0' ){//直到数组结束标志printf("%c",inStr[i++]);//打印元素}printf("\t\t%s",info);// printf("\n*************************************\n");// printf("#\n");}/**********************************//parser for comment//参数待分析字符串,位置下标int i// 返回值位置下标int i***********************************/int parser_com(char inStr[],int i){//parser for comment"{}"char temp[MAXSIZE] ;//存放{}内的字符串memset(temp,0,sizeof(temp)); //清空数组,以防止第二次调用时有上次的字符串;int t=0;while(inStr[++i] != EOC){temp[t]=inStr[i];t++;}// printf("Comment \t:");display(temp,"Comment");return i;}/**********************************//parser for letter//参数待分析字符串,位置下标int i// 返回值位置下标int i***********************************/int parser_letter(char inStr[],int i){int t = 0;char temp[MAXSIZE];memset(temp,0,sizeof(temp)); //清空数组;while(isDigit(inStr[i]) || isLetter(inStr[i])){//如果是数字或字母temp[t++] = inStr[i];i++;}//判断是否是关键字,如需添加关键字添加else if即可//若使用关键字表应该效果更好if(isKeyword(temp,"int")){display(temp,"ID_KeyWords");}else if(isKeyword(temp,"char")){display(temp,"ID_KeyWords");}// printf("Letter \t:");else{display(temp,"inID");}return --i;}int parser_digit(char inStr[],int i){int t = 0;char temp[MAXSIZE];memset(temp,0,sizeof(temp)); //清空数组;while(inStr[i] != ' ' && inStr[i] != '\n' && isDigit(inStr[i])){ temp[t++] = inStr[i];i++;}// printf("Digit \t:");display(temp,"inNum");return --i;}/*// prasers for operators like "+,-,* /"//之后放入了parser()中了int parser_ops(char inStr[],int i){int t = 0;char temp[MAXSIZE];memset(temp,0,sizeof(temp)); 清空数组;return i;}*/// prasers for relationship operators like ">,<,="int parser_rel(char inStr[],int i){int t = 0;char temp[MAXSIZE];memset(temp,0,sizeof(temp)); //清空数组;while(inStr[i]=='>' || inStr[i]=='<' || inStr[i]=='='){temp[t] = inStr[i];t++;i++;}// printf("\nRelationship_Operator\t:");display(temp,"Relationship_Operators");return --i;}/**********************************//词法分析主程序,//参数待分析字符串//***********************************/void parser(char inStr[]){int i = 0;while(inStr[i] != '#'){/*switch(inStr[i]){case '{': i = pareser_com(inStr,i);break;//如果是{,使用case ' ': ;break; //如果是空格跳过case '+':;break;default:;break; //}*///之前使用switch,后来觉得if ,else更方便if(inStr[i] == SOC){//SOC'{'-start of commenti = parser_com(inStr,i);//如果是{,使用pareser_com;}else if(inStr[i] == '+'){display("+","Operator");}else if(inStr[i] == '-'){display("-","Operator");}else if(inStr[i] == '*'){display("*","Operator");}else if(inStr[i] == '/'){display("/","Operator");}else if(inStr[i]=='>' || inStr[i]=='=' || inStr[i]=='<'){i = parser_rel(inStr,i);//parser for relationship;}/*else if(inStr[i] > 47 && inStr[i] <58){//0-9;i = parser_digit(inStr,i);}*/else if(isDigit(inStr[i])){i = parser_digit(inStr,i);}/*else if((inStr[i] >64 && inStr[i]<91)|| (inStr[i]>96 && inStr[i] <123)){//A-Z,a-zi = parser_letter(inStr,i);}*/else if(isLetter(inStr[i])){i = parser_letter(inStr,i);}i++;}memset(inStr,0,sizeof(inStr));//清空数组;}//主菜单;void menu(){char choice;printf("\t\tSimpleParser\n");printf("1)inString from file\n2)inString from Inputing\n3)exit\n");printf("Your choice:");scanf("%c",&choice);while(choice!='1'&& choice!='2' && choice!='0' ){printf("\nerror,Your choice:");scanf("%c",&choice);}switch(choice){case '0':{system("PAUSE");exit(0);};break;case '1':inFile(inStr); break;case '2':inString(inStr); break;default:;break;}}int main(){/*inString(inStr);inFile(inStr);*/menu();printf("\nInString :");display(inStr,"\n*************************************");printf("\n\t\tCompile Begin");parser(inStr);system("PAUSE"); //调用系统暂停return 0;}。
(完整版)词法分析器(c语言实现)

词法分析c实现一、实验目的设计、编制并调试一个词法分析程序,加深对词法分析原理的理解。
二、实验要求2.1 待分析的简单的词法(1)关键字:begin if then while do end所有的关键字都是小写。
(2)运算符和界符:= + - * / < <= <> > >= = ; ( ) #(3)其他单词是标识符(ID)和整型常数(SUM),通过以下正规式定义:ID = letter (letter | digit)*NUM = digit digit*(4)空格有空白、制表符和换行符组成。
空格一般用来分隔ID、SUM、运算符、界符和关键字,词法分析阶段通常被忽略。
2.2 各种单词符号对应的种别码:输入:所给文法的源程序字符串。
输出:二元组(syn,token或sum)构成的序列。
其中:syn为单词种别码;token为存放的单词自身字符串;sum为整型常数。
例如:对源程序begin x:=9: if x>9 then x:=2*x+1/3; end #的源文件,经过词法分析后输出如下序列:(1,begin)(10,x)(18,:=)(11,9)(26,;)(2,if)……三、词法分析程序的C语言程序源代码:#include <stdio.h>#include <string.h>char prog[80],token[8],ch;int syn,p,m,n,sum;char *rwtab[6]={"begin","if","then","while","do","end"};scaner();main(){p=0;printf("\n please input a string(end with '#'):/n");do{scanf("%c",&ch);prog[p++]=ch;}while(ch!='#');p=0;do{scaner();switch(syn){case 11:printf("( %-10d%5d )\n",sum,syn);break;case -1:printf("you have input a wrong string\n");getch();exit(0);default: printf("( %-10s%5d )\n",token,syn);break;}}while(syn!=0);getch();}scaner(){ sum=0;for(m=0;m<8;m++)token[m++]=NULL;ch=prog[p++];m=0;while((ch==' ')||(ch=='\n'))ch=prog[p++];if(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A'))){ while(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A'))||((ch>='0')&&(ch<='9'))) {token[m++]=ch;ch=prog[p++];}p--;syn=10;for(n=0;n<6;n++)if(strcmp(token,rwtab[n])==0){ syn=n+1;break;}}else if((ch>='0')&&(ch<='9')) { while((ch>='0')&&(ch<='9')) { sum=sum*10+ch-'0';ch=prog[p++];}p--;syn=11;}else switch(ch){ case '<':token[m++]=ch;ch=prog[p++];if(ch=='='){ syn=22;token[m++]=ch;}else{ syn=20;p--;}break;case '>':token[m++]=ch;ch=prog[p++];if(ch=='='){ syn=24;token[m++]=ch;}else{ syn=23;p--;}break;case '+': token[m++]=ch;ch=prog[p++];if(ch=='+'){ syn=17;token[m++]=ch;}else{ syn=13;p--;}break;ch=prog[p++];if(ch=='-'){ syn=29;token[m++]=ch;}else{ syn=14;p--;}break;case '!':ch=prog[p++];if(ch=='='){ syn=21;token[m++]=ch;}else{ syn=31;p--;}break;case '=':token[m++]=ch;ch=prog[p++];if(ch=='='){ syn=25;token[m++]=ch;}else{ syn=18;p--;}break;case '*': syn=15;token[m++]=ch;break;case '/': syn=16;token[m++]=ch;break;case '(': syn=27;token[m++]=ch;break;case ')': syn=28;break;case '{': syn=5;token[m++]=ch;break;case '}': syn=6;token[m++]=ch;break;case ';': syn=26;token[m++]=ch;break;case '\"': syn=30;token[m++]=ch;break;case '#': syn=0;token[m++]=ch;break;case ':':syn=17;token[m++]=ch;break;default: syn=-1;break;}token[m++]='\0';}四、结果分析:输入begin x:=9: if x>9 then x:=2*x+1/3; end # 后经词法分析输出如下序列:(begin 1)(x 10)(:17)(= 18)(9 11)(;26)(if 2)……如图5-1所示:。
第3章 词法分析(3)

3.4 正规式与有穷自动机的等价性
1. NFA M正规式R
在消结过程中,逐步用正规式来标记弧, 规则如下:
1.对于
1
2.对于
R1
2
R2
代之为
3
1
R1 R2
3
代之为 R1 R1| R2 1 2 1 2 R2 R2 3.对于 代之为 R1R2﹡R3 R 1 R 3 1 3 1 2 3
例如:有NFA M如图3.14,求其等价的正规式R。
a,b a 3
x ε 0 b 1 a|b a|b x ε 0
aa
a
4
ε
b
y (a|b)*(aa|bb)(a|b)* x y ε 2 a,b a|b aa(a|b) * y bb(a|b) *
4
ε y x
bb
2
ε
a|b
ε
0
3.4 正规式与有穷自动机的等价性
课堂练习 求以下NFA的正规式 a a 3 a 1 2 b
第一步
a
5 6 b
b
4
b
a
a
3
a
a
s
1 2
b
5 b
4 b
6 b
z
3.4 正规式与有穷自动机的等价性
第二步
a|b s 1 2
aa bb aa|bb 5
a|b
6
z
第三步
s
第四步
(a|b)*
2
5
(a|b)*
z
s
(a|b)*(aa|bb)(a|b)*
z
课堂讲解
• 【例5.12】第72页 • 【例5.13】第73页
实验一、词法分析器(含源代码)

词法分析器实验报告一、实验目的及要求本次实验通过用C语言设计、编制、调试一个词法分析子程序,识别单词,实现一个C语言词法分析器,经过此过程可以加深对编译器解析单词流的过程的了解。
运行环境:硬件:windows xp软件:visual c++6.0二、实验步骤1.查询资料,了解词法分析器的工作过程与原理。
2.分析题目,整理出基本设计思路。
3.实践编码,将设计思想转换用c语言编码实现,编译运行。
4.测试功能,多次设置包含不同字符,关键字的待解析文件,仔细察看运行结果,检测该分析器的分析结果是否正确。
通过最终的测试发现问题,逐渐完善代码中设置的分析对象与关键字表,拓宽分析范围提高分析能力。
三、实验内容本实验中将c语言单词符号分成了四类:关键字key(特别的将main说明为主函数)、普通标示符、常数和界符。
将关键字初始化在一个字符型指针数组*key[]中,将界符分别由程序中的case列出。
在词法分析过程中,关键字表和case列出的界符的内容是固定不变的(由程序中的初始化确定),因此,从源文件字符串中识别出现的关键字,界符只能从其中选取。
标识符、常数是在分析过程中不断形成的。
对于一个具体源程序而言,在扫描字符串时识别出一个单词,若这个单词的类型是关键字、普通标示符、常数或界符中之一,那么就将此单词以文字说明的形式输出.每次调用词法分析程序,它均能自动继续扫描下去,形成下一个单词,直到整个源程序全部扫描完毕,从而形成相应的单词串。
输出形式例如:void $关键字流程图、程序流程图:程序:#include<string.h>#include<stdio.h>#include<stdlib.h>#include<ctype.h>//定义关键字char*Key[10]={"main","void","int","char","printf","scanf","else","if","return"}; char Word[20],ch; // 存储识别出的单词流int IsAlpha(char c) { //判断是否为字母if(((c<='z')&&(c>='a'))||((c<='Z')&&(c>='A'))) return 1;else return 0;}int IsNum(char c){ //判断是否为数字if(c>='0'&&c<='9') return 1;else return 0;}int IsKey(char *Word){ //识别关键字函数int m,i;for(i=0;i<9;i++){if((m=strcmp(Word,Key[i]))==0){if(i==0)return 2;return 1;}}return 0;}void scanner(FILE *fp){ //扫描函数char Word[20]={'\0'};char ch;int i,c;ch=fgetc(fp); //获取字符,指针fp并自动指向下一个字符if(IsAlpha(ch)){ //判断该字符是否是字母Word[0]=ch;ch=fgetc(fp);i=1;while(IsNum(ch)||IsAlpha(ch)){ //判断该字符是否是字母或数字Word[i]=ch;i++;ch=fgetc(fp);}Word[i]='\0'; //'\0' 代表字符结束(空格)fseek(fp,-1,1); //回退一个字符c=IsKey(Word); //判断是否是关键字if(c==0) printf("%s\t$普通标识符\n\n",Word);//不是关键字else if(c==2) printf("%s\t$主函数\n\n",Word);else printf("%s\t$关键字\n\n",Word); //输出关键字 }else //开始判断的字符不是字母if(IsNum(ch)){ //判断是否是数字Word[0]=ch;ch=fgetc(fp);i=1;while(IsNum(ch)){Word[i]=ch;i++;ch=fgetc(fp);}Word[i]='\0';fseek(fp,-1,1); //回退printf("%s\t$无符号实数\n\n",Word);}else //开始判断的字符不是字母也不是数字{Word[0]=ch;switch(ch){case'[':case']':case'(':case')':case'{':case'}':case',':case'"':case';':printf("%s\t$界符\n\n",Word); break;case'+':ch=fgetc(fp);Word[1]=ch;if(ch=='='){printf("%s\t$运算符\n\n",Word);//运算符“+=”}else if(ch=='+'){printf("%s\t$运算符\n\n",Word); //判断结果为“++”}else {fseek(fp,-1,1);printf("%s\t$运算符\n\n",Word); //判断结果为“+”}break;case'-':ch=fgetc(fp);Word[1]=ch;if(ch=='='){printf("%s\t$运算符\n\n",Word); }else if(ch=='-'){printf("%s\t$运算符\n\n",Word); //判断结果为“--”}else {fseek(fp,-1,1);printf("%s\t$运算符\n\n",Word); //判断结果为“-”}break;case'*':case'/':case'!':case'=':ch=fgetc(fp);if(ch=='='){printf("%s\t$运算符\n\n",Word);}else {fseek(fp,-1,1);printf("%s\t$运算符\n\n",Word);}break;case'<':ch=fgetc(fp);Word[1]=ch;if(ch=='='){printf("%s\t$运算符\n\n",Word); //判断结果为运算符“<=”}else if(ch=='<'){printf("%s\t$运算符\n\n",Word); //判断结果为“<<”}else {fseek(fp,-1,1);printf("%s\t$运算符\n\n",Word); //判断结果为“<”}break;case'>':ch=fgetc(fp);Word[1]=ch;if(ch=='=') printf("%s\t$运算符\n\n",Word);else {fseek(fp,-1,1);printf("%s\t$运算符\n\n",Word);}break;case'%':ch=fgetc(fp);Word[1]=ch;if(ch=='='){printf("%s\t$运算符\n\n",Word);}if(IsAlpha(ch)) printf("%s\t$类型标识符\n\n",Word);else {fseek(fp,-1,1);printf("%s\t$取余运算符\n\n",Word);}break;default:printf("无法识别字符!\n\n"); break;}}}main(){char in_fn[30]; //文件路径FILE *fp;printf("\n请输入源文件名(包括路径和后缀名):");while(1){gets(in_fn);//scanf("%s",in_fn);if((fp=fopen(in_fn,"r"))!=NULL) break; //读取文件内容,并返回文件指针,该指针指向文件的第一个字符else printf("文件路径错误!请重新输入:");}printf("\n******************* 词法分析结果如下 *******************\n");do{ch=fgetc(fp);if(ch=='#') break; //文件以#结尾,作为扫描结束条件else if(ch==' '||ch=='\t'||ch=='\n'){} //忽略空格,空白,和换行else{fseek(fp,-1,1); //回退一个字节开始识别单词流scanner(fp);}}while(ch!='#');return(0);}4.实验结果解析源文件:void main(){int a=3;a+=b;printf("%d",a);return;}#解析结果:5.实验总结分析通过本次实验,让再次浏览了有关c语言的一些基本知识,特别是对文件,字符串进行基本操作的方法。
第二章 词法分析

8
单词种别表示单词的种类, (1) 单词种别表示单词的种类,是语法分 析所需要的信息。 析所需要的信息。 一个语言的单词符号如何划分种类、 一个语言的单词符号如何划分种类、分为 几类、如何编码都属于技术性问题, 几类、如何编码都属于技术性问题,主要取 决于处理上的方便。 决于处理上的方便。 通常让每种单词对应一个整数码, 通常让每种单词对应一个整数码,这样可 最大限度地把各个单词区别开来。 最大限度地把各个单词区别开来。
6
(4) 运 算 符 : 如 “ +” 、 “ − ” 、 “ * ” 、 /”、 >”、 <”等 “/”、“>”、“<”等。 (5) 界符:在语言中是作为语法上的分界符 界符: 号使用的, 号使用的 , 如“ , ”、 “ ;” 、 “( ” 、 “ ) ” 等。 一个程序语言的保留字、 一个程序语言的保留字、运算符和界符 的个数是确定的, 的个数是确定的,而标识符或常数的使用则 不限定个数。 不限定个数。
24
终态一般对应一个return( 语句。 终态一般对应一个return( )语句。 return意味着从词法分析器返回到调用段 return意味着从词法分析器返回到调用段 一般指返回到语法分析器。 ,一般指返回到语法分析器。
图2–4 含有分支或回路的状态示意 (a) 含分支的状态 ;(b) 含回路的状态 含分支的状态i; 含回路的状态i
(3,’if’) (1,指向 的符号表入口) 指向i (1,指向i的符号表入口) (4,’=’) (2,’5’) (3,’then’) (1,指向 的符号表入口) 指向x (1,指向x的符号表入口) (4,’:=’) (1,指向 的符号表入口) 指向y (1,指向y的符号表入口) (5,’;’)
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
2014-9-26 17
(5) 若作为一个主程序,须加一层while循环控制: while (1= =1) { token= ' '; /*对token数组初始化*/ getchar( ); getbe( ); /*滤除空格…*/ if (character!=EOF) { switch (character) … } else break; /* end of if */ } /*end of while */
2014-9-26 14
case '+': return ('+',null); break; case‘-': return (‘-',null); break; case '*': return ('*',null); break; case '<': getchar ( ); if (character== '=') return(relop,LE); else { retract ( ); return (relop,LT); } break;
大多数程序语言的单词符号都可用 状态转换图予以识别。下面构造一个 C 语言子集的简单词法分析器,该 C 语言 子集的所有单词符号及其种别编码和内 码值如下表所示。 由于直接使用整数编码不利于记忆, 故采用一些助记符表示种别编码。
2014-9-26 3
表2.1 C语言子集的单词符号及内码值 单词符号 种别编码 while 1 if 2 else 3 switch 4 case 5 6 标识符 7 常数 + 8 − 9 * 10 <= 11 < 11 == 11 = 12 13 ;
2014-9-26
13
case '0': case '1': … case '9': while (digit ( )) { concatenation ( ); getchar ( ); } retract ( ); buildlist ( ); /*将常数登录到常数表中*/ return (num, num的常数表入口指针); break;
2014-9-26 9
(4)concatenation( ): 将token中字符串与 character中字符连接作为token中的新 字符串。 (5)letter( )和digit( ): 判断character中的字 符是否为字母和数字的布尔函数,若是 则返回true, 否则返回false。 (6)reserve( ): 按token数组中的字符串查 保留字表, 若是保留字则返回其编码, 否则返回0。
2014-9-26 15
case '=': getchar ( ); if (character=='=') return(relop,EQ); else { retract ( ); return ('=', _ ); } break; case ';': return (';', -); break; default: error ( ); }
2014-9-26 19
2014-9-26
20
编 译 原 理 Principle of Compiling14-9-26 1
2.2 一个简单的词法分析器示例
2.2.1 C语言子集的单词符号表示 2.2.2 C语言子集对应的状态转换图的设计
2.2.3 状态转换图的实现
2014-9-26
2
2.2.1 C语言子集的单词符号表示
的字符送入token数组*/
12
}
2014-9-26
retract ( ); /*扫描指针回退一个字符*/ c=reserve ( ); if (c==0) { buildlist ( ); /*将标识符登录到符号表*/ return (id, id在符号表中的入口指针); } else return (保留字码, null) ; break;
2014-9-26 5
对保留字专设对应的状态转换图:
C语言子集对应的状态转换图如下:
6
2014-9-26
空白 字母或数字
开始 0
字母 1 非字母数字 2 * 返回(id, id在符号表中位置)
数字 数字 3 4 * 非数字 + 5 - 6 * < = ; 其它
2014-9-26
或返回(保留字, -)
2014-9-26 18
(6) 考虑不使用retract()、不回退字符,每次情况处 理后多读一个字符留下次直接进行判断处理。 getchar( ); while (1= =1) { token= ' '; /*对token数组初始化*/ getbe( ); /*滤除空格…*/ if (character!=EOF) { switch (character) … /* 去掉每条retract()语句;没有 retract()的case情况加一个getchar();*/ } else break; /* end of if */ } /*end of while */
返回(num, num在常数表中位置) 返回(+, -) 返回(-, -)
7 8
11
=
其它
返回(*, -)
9 返回(relop, LE) 返回(relop, EQ) 返回(=, -) 返回(; , -) 非法字符错 10 * 返回(relop, LT)
=
其它
12
13 *
14
15
*
7
注意: (1) 状态 2 识别出一个单词符号后需先 查保留字表 , 若匹配则为保留字 , 否则为标 识符。若为标识符 , 还需查符号表 , 看表中 是否有此标识符。若符号表中无此标识符, 则先将它登录到符号表中,再返回它在符号 表中入口地址作为内码值;若表中有此标识 符,则直接返回其入口地址作为内码值。 (2) 状态 4 识别出一个常数后可以将它 转换成二进制常数再登录到常数表,然后返 回它在常数表中的入口指针作为内码值。
2014-9-26 11
C语言子集对应的的词法分析器如下: token= ' '; /*对token数组初始化*/ getchar( ); getbe( ); /*滤除空格*/ switch (character) { case 'a': … case 'z': while (letter ( )‖digit ( )) { concatenation ( ); /*将当前读入 getchar ( );
2014-9-26
助记符 while if else switch case id num + − * relop relop relop = ;
id在符号表中位置
num在常数表中位置
内码值 — — — — —
— — — LE LT EQ — —
4
2.2.2 C语言子集对应的状态转换图的设计 首先对输入串做预处理。 即剔除多余的空格、注释、制表符和 换行符等。 其次把保留字作为一类特殊标识符处理。 即对保留字不专设对应的状态转换图, 当状态转换图识别出一个标识符时就去查 表,确定它是否为一个保留字。
2014-9-26 10
(7) retract( ): 扫描指针回退一个字符, 同
时将character置为空白。
(8)buildlist( ): 将标识符登录到符号表或将常数
登录到常数表;若登录表中已存在该标识符
或常数,则返回相关信息。
(9)error( ): 进行出错处理。
(10)getchar():把下一个输入字符读到character中, 读入源程序字符的指针前移一个字符。
2014-9-26 16
注意:编程实现过程中, (1)return(…):该程序作为语法分析的子 程序,返回相关信息给语法分析程序; 若单独作为一个主程序,return当作print 相关信息。 (2)getbe():可增加功能:跳过注释、制 表符和换行符等,碰到换行符则 LineNo (记录行号的变量)增加1。 (3)error():利用LineNo,可告诉用户错误 所在的行号,并适当提供纠错信息。 (4)增加功能:识别含“_”的标识符、无 符号小数、无符号数、符号数(负号)。
2014-9-26 8
2.2.3 状态转换图的实现 状态转换图易于用程序实现,最简单的 办法是让每个状态对应一小段程序。对于 图2–5,首先引进一组变量和过程: (1)character: 字符变量,存放最新读入 的源程序字符。 (2)token: 字符数组,存放构成单词符号 的字符串。 (3)getbe( ): 若character中字符为空,则 调用getchar( ),直至character为非空。