模式识别课程报告
模式识别与智能系统概论课程报告

课程报告一、人工智能与模式识别的研究已有多年,但似乎公认的观点认为它仍然非常困难。
在查阅文献或网络的基础上,试对你所熟悉的任一方向(如人像识别、语音识别、字符识别、自然语言理解、无人驾驶等等)的发展状况进行描述。
并设想如果你将从事该方向的研究,你打算如何着手,以建立有效的理论和方法;或者你认为现在的理论和方法有何缺陷,有什么办法来进行改进?(10分)语音识别属于感知智能,而让机器从简单的识别语音到理解语音,则上升到了认知智能层面,机器的自然语言理解能力如何,也成为了其是否有智慧的标志,而自然语言理解正是目前难点。
总结目前语音识别的发展现状,dnn、rnn、lstm和cnn算是语音识别中几个比较主流的方向。
长短时记忆网络可以说是目前语音识别应用最广泛的一种结构,这种网络能够对语音的长时相关性进行建模,从而提高识别正确率。
双向LSTM网络可以获得更好的性能,但同时也存在训练复杂度高、解码时延高的问题,尤其在工业界的实时识别系统中很难应用。
语音识别发展现状面临窘境:1)噪声鲁棒性:做声环境下的鲁棒语音识别一直是语音识别大规模应用的主要绊脚石,我们如何在一些噪声场景比较大的情况下,比如说我们的马路、咖啡厅,公共汽车,飞机场,以及会议室,大巴上等等,使得得到很高的识别精度,这是非常具有挑战性的。
环境感知的深度模型以及神经网络的快速自适应方法,它使得我们一般的深度模型可以对环境进行一个实时的感知和自适应调整,来提高实现系统性能,就像人耳一样。
另外我们也将极深卷积神经网络用于抗噪的语音识别得到巨大的系统性能的提升。
2)多类复杂性:过去的大部分语音识别系统的设计主要是针对一些单一环境、单一场景下进行设计的,如何做多类别复杂场景下的通用的语音识别是非常困难的,比如说在Youtube或者BBC上的一些数据,可以来自各种各样的语境和场景,有新闻广播、新闻采访、音乐会、访谈、电影等等。
3)低数据资源与多语言:目前大部分语音识别的研究和应用,主要是基于一些大语种,比如说英语、汉语、阿拉伯语和法语等等,我们知道世界上一共有6900多种语言,如何快速的实现一套基于任何语言的语言识别系统是非常困难的,它也具有重大的战略意义。
模式识别实验报告(一二)

信息与通信工程学院模式识别实验报告班级:姓名:学号:日期:2011年12月实验一、Bayes 分类器设计一、实验目的:1.对模式识别有一个初步的理解2.能够根据自己的设计对贝叶斯决策理论算法有一个深刻地认识3.理解二类分类器的设计原理二、实验条件:matlab 软件三、实验原理:最小风险贝叶斯决策可按下列步骤进行: 1)在已知)(i P ω,)(i X P ω,i=1,…,c 及给出待识别的X 的情况下,根据贝叶斯公式计算出后验概率:∑==cj iii i i P X P P X P X P 1)()()()()(ωωωωω j=1,…,x2)利用计算出的后验概率及决策表,按下面的公式计算出采取ia ,i=1,…,a 的条件风险∑==cj j jii X P a X a R 1)(),()(ωωλ,i=1,2,…,a3)对(2)中得到的a 个条件风险值)(X a R i ,i=1,…,a 进行比较,找出使其条件风险最小的决策ka ,即()()1,min k i i aR a x R a x ==则ka 就是最小风险贝叶斯决策。
四、实验内容假定某个局部区域细胞识别中正常(1ω)和非正常(2ω)两类先验概率分别为 正常状态:P (1ω)=; 异常状态:P (2ω)=。
现有一系列待观察的细胞,其观察值为x :已知先验概率是的曲线如下图:)|(1ωx p )|(2ωx p 类条件概率分布正态分布分别为(-2,)(2,4)试对观察的结果进行分类。
五、实验步骤:1.用matlab 完成分类器的设计,说明文字程序相应语句,子程序有调用过程。
2.根据例子画出后验概率的分布曲线以及分类的结果示意图。
3.最小风险贝叶斯决策,决策表如下:结果,并比较两个结果。
六、实验代码1.最小错误率贝叶斯决策 x=[] pw1=; pw2=; e1=-2; a1=; e2=2;a2=2;m=numel(x); %得到待测细胞个数pw1_x=zeros(1,m); %存放对w1的后验概率矩阵 pw2_x=zeros(1,m); %存放对w2的后验概率矩阵results=zeros(1,m); %存放比较结果矩阵for i = 1:m%计算在w1下的后验概率pw1_x(i)=(pw1*normpdf(x(i),e1,a1))/(pw1*normpdf(x(i),e1,a1)+pw2*normp df(x(i),e2,a2)) ;%计算在w2下的后验概率pw2_x(i)=(pw2*normpdf(x(i),e2,a2))/(pw1*normpdf(x(i),e1,a1)+pw2*normp df(x(i),e2,a2)) ;endfor i = 1:mif pw1_x(i)>pw2_x(i) %比较两类后验概率result(i)=0; %正常细胞elseresult(i)=1; %异常细胞endenda=[-5::5]; %取样本点以画图n=numel(a);pw1_plot=zeros(1,n);pw2_plot=zeros(1,n);for j=1:npw1_plot(j)=(pw1*normpdf(a(j),e1,a1))/(pw1*normpdf(a(j),e1,a1)+pw2*no rmpdf(a(j),e2,a2));%计算每个样本点对w1的后验概率以画图pw2_plot(j)=(pw2*normpdf(a(j),e2,a2))/(pw1*normpdf(a(j),e1,a1)+pw2*no rmpdf(a(j),e2,a2));endfigure(1);hold onplot(a,pw1_plot,'co',a,pw2_plot,'r-.');for k=1:mif result(k)==0plot(x(k),,'cp'); %正常细胞用五角星表示elseplot(x(k),,'r*'); %异常细胞用*表示end;end;legend('正常细胞后验概率曲线','异常细胞后验概率曲线','正常细胞','异常细胞');xlabel('样本细胞的观察值');ylabel('后验概率');title('后验概率分布曲线');grid onreturn%实验内容仿真:x = [, ,,, , ,, , , ,,,,,,, ,,,,,,, ]disp(x);pw1=;pw2=;[result]=bayes(x,pw1,pw2);2.最小风险贝叶斯决策x=[]pw1=; pw2=;m=numel(x); %得到待测细胞个数R1_x=zeros(1,m); %存放把样本X判为正常细胞所造成的整体损失R2_x=zeros(1,m); %存放把样本X判为异常细胞所造成的整体损失result=zeros(1,m); %存放比较结果e1=-2;a1=;e2=2;a2=2;%类条件概率分布px_w1:(-2,) px_w2(2,4)r11=0;r12=2;r21=4;r22=0;%风险决策表for i=1:m%计算两类风险值R1_x(i)=r11*pw1*normpdf(x(i),e1,a1)/(pw1*normpdf(x(i),e1,a1)+pw2*norm pdf(x(i),e2,a2))+r21*pw2*normpdf(x(i),e2,a2)/(pw1*normpdf(x(i),e1,a1) +pw2*normpdf(x(i),e2,a2));R2_x(i)=r12*pw1*normpdf(x(i),e1,a1)/(pw1*normpdf(x(i),e1,a1)+pw2*norm pdf(x(i),e2,a2))+r22*pw2*normpdf(x(i),e2,a2)/(pw1*normpdf(x(i),e1,a1) +pw2*normpdf(x(i),e2,a2));endfor i=1:mif R2_x(i)>R1_x(i) %第二类比第一类风险大result(i)=0; %判为正常细胞(损失较小),用0表示elseresult(i)=1; %判为异常细胞,用1表示endenda=[-5::5] ; %取样本点以画图n=numel(a);R1_plot=zeros(1,n);R2_plot=zeros(1,n);for j=1:nR1_plot(j)=r11*pw1*normpdf(a(j),e1,a1)/(pw1*normpdf(a(j),e1,a1)+pw2*n ormpdf(a(j),e2,a2))+r21*pw2*normpdf(a(j),e2,a2)/(pw1*normpdf(a(j),e1, a1)+pw2*normpdf(a(j),e2,a2))R2_plot(j)=r12*pw1*normpdf(a(j),e1,a1)/(pw1*normpdf(a(j),e1,a1)+pw2*n ormpdf(a(j),e2,a2))+r22*pw2*normpdf(a(j),e2,a2)/(pw1*normpdf(a(j),e1, a1)+pw2*normpdf(a(j),e2,a2))%计算各样本点的风险以画图endfigure(1);hold onplot(a,R1_plot,'co',a,R2_plot,'r-.');for k=1:mif result(k)==0plot(x(k),,'cp');%正常细胞用五角星表示elseplot(x(k),,'r*');%异常细胞用*表示end;end;legend('正常细胞','异常细胞','Location','Best');xlabel('细胞分类结果');ylabel('条件风险');title('风险判决曲线');grid onreturn%实验内容仿真:x = [, ,,, , ,, , , ,,,,,,, ,,,,,,, ]disp(x);pw1=;pw2=;[result]=bayes(x,pw1,pw2);七、实验结果1.最小错误率贝叶斯决策后验概率曲线与判决显示在上图中后验概率曲线:带红色虚线曲线是判决为异常细胞的后验概率曲线青色实线曲线是为判为正常细胞的后验概率曲线根据最小错误概率准则,判决结果显示在曲线下方:五角星代表判决为正常细胞,*号代表异常细胞各细胞分类结果(0为判成正常细胞,1为判成异常细胞):0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 1 1 1 0 0 0 1 0 12. 最小风险贝叶斯决策风险判决曲线如上图所示:带红色虚线曲线是异常细胞的条件风险曲线;青色圆圈曲线是正常细胞的条件风险曲线根据贝叶斯最小风险判决准则,判决结果显示在曲线下方:五角星代表判决为正常细胞,*号代表异常细胞各细胞分类结果(0为判成正常细胞,1为判成异常细胞):1 0 0 0 0 0 0 0 0 0 0 0 1 1 0 1 1 1 0 0 0 1 0 1八、实验分析由最小错误率的贝叶斯判决和基于最小风险的贝叶斯判决得出的图形中的分类结果可看出,样本、在前者中被分为“正常细胞”,在后者中被分为“异常细胞”,分类结果完全相反。
模式识别专业实践报告(2篇)

第1篇一、实践背景与目的随着信息技术的飞速发展,模式识别技术在各个领域得到了广泛应用。
作为人工智能领域的一个重要分支,模式识别技术对于图像处理、语音识别、生物识别等领域的发展具有重要意义。
为了更好地理解和掌握模式识别技术,提高实际应用能力,我们组织了一次为期一个月的模式识别专业实践。
本次实践旨在通过实际操作,加深对模式识别理论知识的理解,提高解决实际问题的能力。
二、实践内容与过程1. 实践内容本次实践主要包括以下几个方面:(1)图像识别:利用深度学习算法进行图像分类、目标检测等。
(2)语音识别:实现语音信号处理、特征提取和识别。
(3)生物识别:研究指纹识别、人脸识别等生物特征识别技术。
(4)模式分类:运用机器学习算法进行数据分类和聚类。
2. 实践过程(1)理论学习:在实践开始前,我们首先对模式识别的基本理论进行了系统学习,包括图像处理、信号处理、机器学习等相关知识。
(2)项目准备:根据实践内容,我们选取了具有代表性的项目进行实践,如基于深度学习的图像识别、基于HMM的语音识别等。
(3)实验设计与实施:在导师的指导下,我们设计了实验方案,包括数据预处理、模型选择、参数调整等。
随后,我们使用Python、C++等编程语言进行实验编程,并对实验结果进行分析。
(4)问题分析与解决:在实验过程中,我们遇到了许多问题,如数据不足、模型效果不佳等。
通过查阅文献、请教导师和团队成员,我们逐步解决了这些问题。
三、实践成果与分析1. 图像识别我们使用卷积神经网络(CNN)对CIFAR-10数据集进行了图像分类实验。
实验结果表明,经过多次迭代优化,模型在测试集上的准确率达到89.5%,优于传统机器学习方法。
2. 语音识别我们采用HMM(隐马尔可夫模型)对TIMIT语音数据集进行了语音识别实验。
实验结果表明,经过特征提取和模型训练,模型在测试集上的词错误率(WER)为16.3%,达到了较好的识别效果。
3. 生物识别我们研究了指纹识别和人脸识别技术。
神经网络与模式识别课程报告

神经网络与模式识别课程报告卷积神经网络(CNN)算法研究摘要随着信息技术的迅速发展,验证码作为一种安全验证手段广泛应用于网络平台。
然而,复杂的验证码对自动识别技术提出了挑战。
近年来,深度学习特别是卷积神经网络(CNN)在图像识别领域显示出了强大的能力。
本研究旨在探索利用CNN算法进行验证码识别的可能性和有效性。
通过设计并实现一个基于CNN的验证码识别系统,本研究评估了不同训练策略及数据增强技术对验证码识别准确率的影响。
关键词:验证码识别;卷积神经网络;深度学习;图像处理;目录摘要 .......................................................................................... I I第1章概要设计 (1)第2章程序整体设计说明 (4)第3章程序运行效果 (15)第4章设计中遇到的重点及难点 (18)第5章本次设计存在不足与改良方案 (18)结论 (20)参考文献 (21)第1章概要设计1.1 设计目的人工神经网络是深度学习之母。
随着深度学习技术的兴起及其在阿尔法围棋程序等实际应用的精彩表现,神经网络已经广泛地应用于图像的分割和对象的识别、分类问题中。
伴随人工神经网络的发展,神经网络在模式识别领域中起着越来越重要的作用。
通过本课程的学习,让大家从算法的视角,掌握神经网络与模式识别这两个彼此紧密联系的人工智能分支中的基础理论、问题、思路与方法,并理解神经网络与模式识别的研究前沿。
1.2 选题验证码(CAPTCHA)是一种常见的用于区分人类和机器的技术,常用于网站、APP用户登陆时输入一些数字或字符以验证其身份。
本文将介绍如何使用卷积神经网络(CNN)来识别常见的字符验证码。
选择使用卷积神经网络(CNN)用于验证码识别方向的原因有以下几点:1. 强大的图像处理能力:CNN是一种特别适用于处理图像数据的深度学习模型。
它具有多层结构,可以自动学习和提取图像中的特征,如边缘、纹理和形状等。
模式识别课程报告

模式识别实验报告学生姓名:班学号:指导老师:机械与电子信息学院2014年 6月基于K-means算法的改进算法方法一:层次K均值聚类算法在聚类之前,传统的K均值算法需要指定聚类的样本数,由于样本初始分布不一致,有的聚类样本可能含有很多数据,但数据分布相对集中,而有的样本集却含有较少数据,但数据分布相对分散。
因此,即使是根据样本数目选择聚类个数,依然可能导致聚类结果中同一类样本差异过大或者不同类样本差异过小的问题,无法得到满意的聚类结果。
结合空间中的层次结构而提出的一种改进的层次K均值聚类算法。
该方法通过初步聚类,判断是否达到理想结果,从而决定是否继续进行更细层次的聚类,如此迭代执行,生成一棵层次型K均值聚类树,在该树形结构上可以自动地选择聚类的个数。
标准数据集上的实验结果表明,与传统的K均值聚类方法相比,提出的改进的层次聚类方法的确能够取得较优秀的聚类效果。
设X = {x1,x2,…,xi,…,xn }为n个Rd 空间的数据。
改进的层次结构的K均值聚类方法(Hierarchical K means)通过动态地判断样本集X当前聚类是否合适,从而决定是否进行下一更细层次上的聚类,这样得到的最终聚类个数一定可以保证聚类测度函数保持一个较小的值。
具体的基于层次结构的K均值算法:步骤1 选择包含n个数据对象的样本集X = {x1,x2,…,xi,…,xn},设定初始聚类个数k1,初始化聚类目标函数J (0) =0.01,聚类迭代次数t初始化为1,首先随机选择k1个聚类中心。
步骤2 衡量每个样本xi (i = 1,2,…,n)与每个类中心cj ( j = 1,2,…,k)之间的距离,并将xi归为与其最相似的类中心所属的类,并计算当前聚类后的类测度函数值J (1) 。
步骤3 进行更细层次的聚类,具体步骤如下:步骤3.1 根据式(5)选择类半径最大的类及其类心ci :ri = max ||xj - ci||,j = 1,2,…,ni且xj属于Xj(5)步骤3.2 根据距离公式(1)选择该类中距离类ci最远的样本点xi1,然后选择该类中距离xi1最远的样本点xi2。
计算机视觉与模式识别实训课程学习总结实践计算机视觉与模式识别算法

计算机视觉与模式识别实训课程学习总结实践计算机视觉与模式识别算法计算机视觉与模式识别是目前计算机科学领域中的热门技术之一。
通过模式识别算法可以实现对图像、视频等视觉数据的自动分析和理解。
在计算机视觉与模式识别实训课程中,我深入学习了相关算法和工具,同时也进行了一些实践项目,本文将对我在这门课程中的学习经验进行总结与分享。
首先,在实践过程中,我充分了解了计算机视觉与模式识别的基本原理和常用算法。
课程中,我学习了图像处理、特征提取、目标检测、目标跟踪等方面的知识。
通过学习,我掌握了图像处理的基本方法,如灰度变换、滤波等,以及特征提取的常用算法,如SIFT、HOG等。
此外,我还学习了基于机器学习的目标检测算法,如支持向量机(SVM)、卷积神经网络(CNN)等。
这些知识为我理解和实践计算机视觉与模式识别算法打下了坚实的基础。
其次,在实践项目中,我运用所学知识解决了一些真实世界的问题。
其中一个具体的项目是目标检测与跟踪。
我选择了YOLO(You Only Look Once)算法作为目标检测器,并通过训练自己的数据集得到了一个高性能的目标检测模型。
在目标跟踪方面,我使用了OpenCV库中的相关函数,实现了基于传统的物体跟踪算法,如卡尔曼滤波器和均值漂移算法。
通过这些实践项目,我深入理解了计算机视觉与模式识别算法在实际应用中的价值和挑战。
除了实践项目,课程还提供了一些编程实验,帮助我们熟悉常用的计算机视觉与模式识别工具。
例如,我使用了Python编程语言和OpenCV库进行图像处理和分析。
这些实验使我熟悉了一些计算机视觉开发的常用工具和技巧,例如图像读取、显示、保存,以及基本的图像处理操作。
同时,我也通过实验了解了各种算法的实现原理和使用方法。
在学习过程中,我遇到了一些挑战,比如算法理论的理解和实践的转化。
我通过课堂讲解、教材阅读以及与同学们的讨论,逐渐克服了这些困难。
我还参考了一些学术论文和相关的代码实现,加深了对算法和实践的理解。
模式识别课程报告2.0

3 3 深度检测技术演进 5 5 讨论与致谢
2
1 卷积神经网络
R-CNN算法
Fast R-CNN
z
第一阶段
第三阶段
第二阶段
R-CNN Faster R-CNN z
3 深度检测技术演进
R-CNN算法的核心思想
深度对象检测的开山之作——R-CNN(Regions with CNN)
对每个区域通过CNN提取特征,然后接上一个分类器预测这个
3 深度检测技术演进
R-CNN算法的工作流程
1 2 3 4
候选区域生成:一张图像用SS方法生成1K~2K个候选区域
特征提取: 对每个候选区域,使用深度卷积网络提取特征(CNN) 类别判断: 特征送入每一类的SVM 分类器,判别是否属于该类 位置精修: 使用回归器精细修正候选框位置
3 深度检测技术演进
3 深度检测技术演进
深度网络提取特征
使用两个数据库: 一个较大的识别库(ImageNet ILSVC 2012):标定每张图片中物体的类
别;
一个较小的检测库(PASCAL VOC 2007):标定每张图片中,物体的类别
和位置。
使用识别库进行预训练得到CNN(有监督预训练),而后用检测库调优 参数,最后在检测库上评测。
3 深度检测技术演进
Fast R-CNN算法
发现问题
每一个ROI由四元 组 (r,c,h,w)表示, 其中(h,w)代表 高度和宽度 introduction
解决方案
核心思路
工作流程
效果对比
Roi_pool层的作用
Roi_pool层将每个候选区域均匀分成M×N块,对每块进行max pooling操作 将特征图上大小不一的候选区域转变为大小统一的数据,送入下一层
哈工大模式识别实验报告
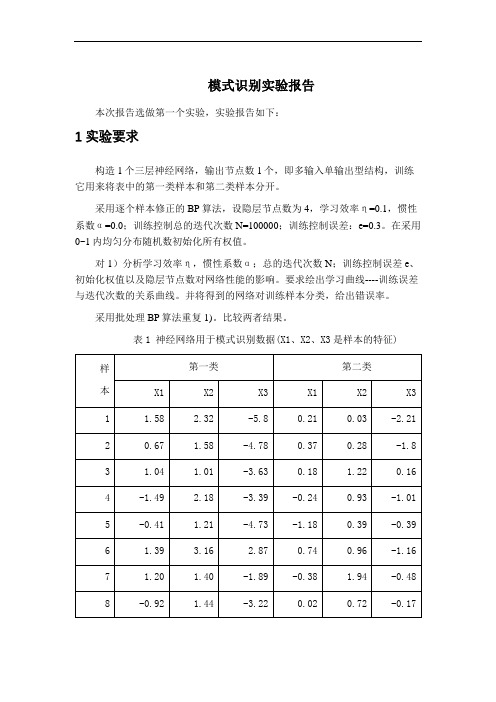
模式识别实验报告本次报告选做第一个实验,实验报告如下:1 实验要求构造1个三层神经网络,输出节点数1个,即多输入单输出型结构,训练它用来将表中的第一类样本和第二类样本分开。
采用逐个样本修正的BP算法,设隐层节点数为4,学习效率η=0.1,惯性系数α=0.0;训练控制总的迭代次数N=100000;训练控制误差:e=0.3。
在采用0~1内均匀分布随机数初始化所有权值。
对1)分析学习效率η,惯性系数α;总的迭代次数N;训练控制误差e、初始化权值以及隐层节点数对网络性能的影响。
要求绘出学习曲线----训练误差与迭代次数的关系曲线。
并将得到的网络对训练样本分类,给出错误率。
采用批处理BP算法重复1)。
比较两者结果。
表1 神经网络用于模式识别数据(X1、X2、X3是样本的特征)2 BP 网络的构建三层前馈神经网络示意图,见图1.图1三层前馈神经网络①网络初始化,用一组随机数对网络赋初始权值,设置学习步长η、允许误差ε、网络结构(即网络层数L 和每层节点数n l );②为网络提供一组学习样本; ③对每个学习样本p 循环a .逐层正向计算网络各节点的输入和输出;b .计算第p 个样本的输出的误差Ep 和网络的总误差E ;c .当E 小于允许误差ε或者达到指定的迭代次数时,学习过程结束,否则,进行误差反向传播。
d .反向逐层计算网络各节点误差)(l jp δ如果l f 取为S 型函数,即xl e x f -+=11)(,则 对于输出层))(1()()()()(l jp jdp l jp l jp l jp O y O O --=δ 对于隐含层∑+-=)1()()()()()1(l kj l jp l jp l jp l jp w O O δδe .修正网络连接权值)1()()()1(-+=+l ip l jp ij ij O k W k W ηδ式中,k 为学习次数,η为学习因子。
η取值越大,每次权值的改变越剧烈,可能导致学习过程振荡,因此,为了使学习因子的取值足够大,又不至产生振荡,通常在权值修正公式中加入一个附加动量法。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
模式识别课程报告什么是模式识别引用Anil K. Jain的话对模式识别下定义:Pattern recognition is the study of how machines can observe the environment, learn to distinguish patterns of interest from their background, and make sound and reasonable decisions about the categories of the patterns.什么是Pattern 呢,Watanabe defines a pattern “as opposite of achaos; it is an entity, vaguely defined, that could be given a name.”比如说一张指纹图片,一个手写的文字,一张人脸,一个说话的信号,这些都可以说是一种模式。
识别在现实生活中是时时刻刻发生的,识别就是再认知(Re-Cognition),识别主要做的是相似和分类的问题,按先验知识的分类,可以把识别分为有监督的学习和没有监督的学习,下面主要介绍的支持向量机就是属于一种有监督的学习。
模式识别与统计学、人工智能、机器学习、运筹学等有着很大的联系,而且各行各业的工作者都在做着识别的工作,一个模式识别系统主要有三部分组成:数据获取和预处理,数据表达和决策。
模式识别的研究主要集中在两方面,一是研究生物体( 包括人)是如何感知对象的,二是在给定的任务下,如何用计算机实现模式识别的理论和方法。
前者是生理学家、心理学家、生物学家、神经生理学家的研究内容,属于认知科学的范畴;后者通过数学家、信息学专家和计算机科学工作者近几十年来的努力,已经取得了系统的研究成果。
模式识别的方法介绍:模式识别方法(Pattern Recognition Method)是一种借助于计算机对信息进行处理、判决分类的数学统计方法。
应用模式识别方法的首要步骤是建立模式空间。
所谓模式空间是指在考察一客观现象时,影响目标的众多指标构成的多维空间。
每个指标代表一个模式参量。
假设一现象有几个事件(样本) 组成,每一个事件都有P个特征参量(X1 , X2 ,. . . Xp ),则它就构成P维模式空间,每一个事件的特征参量代表一个模式。
模式识别就是对多维空间中各种模式的分布特点进行分析,对模式空间进行划分,识别各种模式的聚类情况,从而做出判断或决策。
分析方法就利用“映射”和“逆映射”技术。
映射是指将多维模式空间进行数学变换到二维平面,多维空间的所有模式(样本点) 都投影在该平面内。
在二维平面内,不同类别的模式分布在不同的区域之间有较明显的分界域。
由此确定优化方向返回到多维空间(原始空间) ,得出真实信息,帮助人们找出规律或做出决策,指导实际工作或实验研究。
针对不同的对象和不同的目的,可以用不同的模式识别理论、方法,目前主流的技术方法是:统计模式识别、句法模式识别、模糊模式识别、神经网络法、逻辑推理法。
(1)统计模式识别统计模式识别方法也称为决策论模式识别方法,它是从被研究的模式中选择能足够代表它的若干特征(设有d个) ,每一个模式都由这d个特征组成的在d维特征空间的一个d维特征向量来代表,于是每一个模式就在d维特征空间占有一个位置。
一个合理的假设是同类的模式在特征空间相距较近,而不同类的模式在特征空间则相距较远。
如果用某种方法来分割特征空间,使得同一类模式大体上都在特征空间的同一个区域中,对于待分类的模式,就可根据它的特征向量位于特征空间中的哪一个区域而判定它属于哪一类模式。
这类识别技术理论比较完善。
方法也很多,通常较为有效,现已形成了完整的体系。
尽管方法很多,但从根本上讲,都是直接利用各类的分布特征,即利用各类的概率分布函数、后验概率或隐含地利用上述概念进行分类识别。
其中基本的技术为聚类分析、判别类域界面法、统计判决等。
1)聚类分析在聚类分析中,利用待分类模式之间的“相似性”进行分类,更相似的作为一类,更不相似的作为另外一类。
在分类过程中不断地计算所分划的各类的中心,下一个待分类模式以其与各类中心的距离作为分类的准则。
聚类准则的确定,基本上有两种方式。
一种是试探方式。
凭直观和经验,针对实际问题定义一种相似性测度的阈值,然后按最近邻规则指定某些模式样本属于某一聚类类别。
例如欧氏距离测度,它反映样本间的近邻性,但将一个样本分到两个类别中的一个时,必须规定一距离测度的阈值作为聚类的判别准则,按最近邻规则的简单试探法和最大最小聚类算法就是采用这种方式。
另一种是聚类准则函数法。
定一种准则函数,其函数值与样品的划分有关。
当取得极小值时,就认为得到了最佳划分。
实际工作中采用得最多的聚类方法之一是系统聚类法。
它将模式样本按距离准则逐步聚类,类别由多到少,直到合适的分类要求为止。
2)判别类域界面法判别类域界面法中,用已知类别的训练样本产生判别函数,这相当于学习或训练。
根据待分类模式代入判别函数后所得值的正负而确定其类别。
判别函数提供了相邻两类判决域的界面,最简单、最实用的判别函数是线性判别函数。
线性判别函数的一般表达为下述矩阵式:01()()t n d x w x w +=+其中,012(,,...,)t n w w w w =,称为权向量,12(,,...,)t n x x x x =为n 维特征向量的样本,1n w +为阈值权。
()d x 判别函数是n 维特征空间中某个x 点到超平面的距离。
若以p x 表示x 到超平面H 的投影向量;r 为到超平面H 的垂直距离;0||||w 为权向量0w 的绝对值;0/0||||w w 为0w 方向上的单位向量, 则有'0001000,()()p p n w w x x d x w x w w w w γγγ+=+=++= 利用线性判别函数进行决策就是用一个超平面对特征空间进行分割。
超平面H 的方向由权向量决定,而位置由阈值权的数值确定,H 把特征空间分割为两个决策区域。
当()0d x >时,x 在H 的正侧;()0d x <时,x 在H 的负侧。
3)统计判别在统计判决中,在一些分类识别准则下严格地按照概率统计理论导出各种判决准则,这些判决准则要用到各类的概率密度函数、先验概率或条件概率,即贝叶斯法则。
贝叶斯判别原则有两种形式, 一种是基于最小错误率, 即若(|)(|),(,1,2,...,;)i j i p w x p w x x w i j n i j >∀∈=≠则但,换言之,要求最小错误率,就是要求(|)i p w x 为最大。
另一种是基于最小风险,对于某个x 取值采取决策所带来的风险定义为:i i j 1R(|x)=E (,w )(,)(|)ni j i i w P w x αλαλα=⎡⎤=⎣⎦∑,其中(,)i j w λα表示对于某一样品j x w ∈,而采取决策i α时的损失。
基于最小风险的贝叶斯规则为:若(|)min (|)k i R x R x αα=,则k αα=。
也就是说,对于所有x 取值的条件风险(|)i R x α,最小风险(损失) 的决策是使(|)i R x α取得最小值时的决策。
4)支持向量机统计学习理论是一种专门的小样本统计理论,为研究有限样本情况下的统计模式识别和更广泛的机器学习问题建立了一个较好的理论框架,同时也发展了一种新的模式识别方法——支持向量机,能够较好的解决小样本学习问题。
基于数据的机器学习是现代智能技术中的重要方面, 研究从观测数据(样本)出发寻找规律,利用这些规律对未来数据或无法观测的数据进行预测。
包括模式识别、神经网络等在内,现有机器学习方法共同的重要理论基础之一是统计学。
传统统计学研究的是样本数目趋于无穷大时的渐近理论,现有学习方法也多是基于此假设,但在实际问题中,样本数往往是有限的,因此一些理论上很优秀的学习方法实际中表现却可能不尽人意。
与传统统计学相比, 统计学习理论(Stat ist ical L earn ing Theo ry 或SL T ) 是一种专门研究小样本情况下机器学习规律的理论. V . V apn ik 等人从六、七十年代开始致力于此方面研究,到九十年代中期,随着其理论的不断发展和成熟,也由于神经网络等学习方法在理论上缺乏实质性进展,统计学习理论开始受到越来越广泛的重视,统计学习理论是建立在一套较坚实的理论基础之上的, 为解决有限样本学习问题提供了一个统一的框架。
它能将很多现有方法纳入其中,有望帮助解决许多原来难以解决的问题(比如神经网络结构选择问题、局部极小点问题等),同时,在这一理论基础上发展了一种新的通用学习方法——支持向量机(Support Vector Machine 或SVM ),它已初步表现出很多优于已有方法的性能。
一些学者认为,SL T 和SVM 正在成为继神经网络研究之后新的研究热点,并将有力地推动机器学习理论和技术的发展我国早在八十年代末就有学者注意到统计学习理论的基础成果,但之后较少研究,目前只有少部分学者认识到这个重要的研究方向。
本文旨在向国内介绍统计学习理论和支持向量机方法的基本思想和特点,以使更多的学者能够看到它们的优势从而积极进行研究。
支持向量机基本过程:(基于LIBSVM 工具箱)一、支持向量机是解决数据分类问题的一种流行技术,甚至有人认为它用起来比神经网络还要好用,但是,使用者对SVM 不熟悉常常得到不理想的结果,这里我们介绍一下如何使用支持向量机来得到较理想的结果。
我们介绍的主要是对SVM 研究者的一个指导,并不是说要得到最好的精度,我们也没有打算解决什么有挑战或者有难度的问题,我们的目的是让SVM 研究者们掌握一个能有快又好的得到可行解得秘诀。
尽管使用者不用彻底理解SVM 的理论,但是,我们简要介绍SVM 的基础,因为这些东西对于后面的解释是有必要的。
一项分类工作通常包含训练数据和测试数据,这些数据就是一些例子,每个例子又包括它的类别和它的一些特性。
建立SVM 的目的就是建立一个模版,这个模版可以预测训练数据集中的数据属于哪一类。
给定一组训练数据(,),1,...,,,{1,1}n l i i i x y i l x R y =∈∈-,SVM 需要解决下面的最优化问题:这里i x 通过φ函数影射到了一个高维或者无穷维的空间,SVM 找到一个线性可分的超平面,使得这个超平面在高维空间有最大的边界值。
C>0是对于错误部分的惩罚参数。
此外,被称作核函数,尽管研究者不断的提出新的核函数,初学者可以在介绍SVM 的课本上找到四个基本的核函数:这里,,r γd 都是核函数的参数。