人工智能6第六章-与或树的搜索策略_搜索的完备性与效率 (2)
人工智能博弈树的搜索.pptx
正在与深蓝下棋的卡斯帕罗夫
1.概述
博弈问题特点: 双人对弈,轮流走步。 信息完备,双方所得到的信息是一样的。 零和,即对一方有利的棋,对另一方肯定 是不利的,不存在对双方均有利或无利的 棋。
1.概述
博弈的特性 ① 两个棋手交替地走棋 ; ② 比赛的最终结果,是赢、输和平局中的
一种; ③ 可用图搜索技术进行,但效率很低; ④ 博弈的过程,是寻找置对手于必败态的
若P是MAX获胜的格局,则f(p)=+∞ ; 若P是MIN获胜的格局,则f(p)=-∞ 。
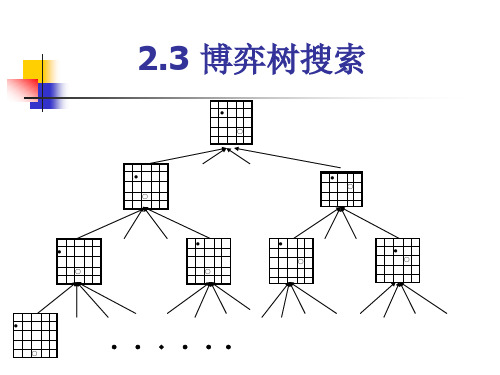
3.极小极大搜索过程
当前棋局f(p)=2
估计函数 f(p)=(所有空格都放上MAX的棋子之后,MAX的三子 成线(行、列、对角)数)-(所有空格都放上MIN的棋子之后, MIN的三子成线(行、列、对角)的总数)
MAX节点和MIN节点
命名博弈的双方,一方为“正方”,对每 个状态的评估都是对应于该方的输赢的。 例如,赢2个,输1个等,都是指正方的。 正方每走一步,都在选择使自己赢得更多 的节点,因此这类节点称为“MAX”节点;
3Байду номын сангаас极小极大搜索过程
另一方为“反方”,对每个状态的评估 都是对应于对手的输赢的。例如,赢2个, 输一个,其实是指自己输2个,赢1个的。 反方每走一步,都在选择使对手输得更 多的节点,因此这类节点称为“MIN”节 点。
对各个局面进行评估
评估的目的:对后面的状态提前进行考虑,并 且以各种状态的评估值为基础作出最好的走棋 选择。
评估的方法:用评价函数对棋局进行评估。赢 的评估值设为+∞,输的评估值设为-∞,平局 的评估值设为0。
评估的标准:由于下棋的双方是对立的,只能 选择其中一方为评估的标准方。
人工智能之搜索策略介绍课件

实现搜索策略的优化
2
步骤:初始化种群、计算适应 度、选择、交叉、变异、迭代
3
优点:全局搜索能力强,能够 找到最优解
4
缺点:计算复杂度高,收敛速 度慢,容易陷入局部最优解
搜索策略的优化
优化目标
01 提高搜索效率:减少搜索 时间,提高搜索结果的准 确性
01
02
03
信息检索:搜索引擎、 路径规划:地图导航、 问题求解:数学问题、
学术论文检索等
物流配送等
逻辑问题等
04
05
06
游戏AI:棋类游戏、 电子游戏等
机器人控制:自主导 航、路径规划等
优化问题:生产调度、 资源分配等
搜索策略的实现
启发式搜索
概念:根据问题特点,选择 合适的搜索策略,提高搜索
效率
01
03
02
剪枝策略:提前 终止无效或低效 的搜索路径,提 高搜索效率
04
自适应搜索:根 据搜索过程中的 反馈信息,动态 调整搜索策略, 提高搜索效果
优化效果评估
准确率:衡量搜索 结果的准确性
召回率:衡量搜索 结果中相关结果的
比例
速度:衡量搜索算 法的执行效率
稳定性:衡量搜索 算法在不同数据集
上的表现一致性
演讲人
人工智能之搜索策略介 绍课件
目录
01. 搜索策略概述 02. 搜索策略的实现 03. 搜索策略的优化 04. 搜索策略的应用案例
搜索策略概述
搜索策略的定义
搜索策略是指在解
1 决一个问题时,如 何找到最优解或近 似最优解的方法。
搜索策略可以分
2 为两类:无信息 搜索和有信息搜 索。
人工智能概论知识表示(与或树表示法)

2. 问题归约的与/或树表示
(6)解树 • 解树是一个由可解节点构成,并
且可由这些可解节点推出初始节 点(它对应着原始问题)也为可 解节点的子树。在解树中一定包 含初始节点。 • 例如,在图所给出的与/或树中, 用粗线表示的子树就是它的一个 解树。 • 该图中的节点P为原始问题节点, 标有t的节点是终止节点。由可 解节点的定义,可以容易推知原 始问题P为可解节点。
知识表示
与/或树表示法
与/或树表示法
• 与/或树是不同于状态空间法的另外一种用于表示问题及 其求解过程的形式化方法,通常用于表示比较复杂的问题 求解。
• 在现实的问题求解过程中,当所要求解的问题比较复杂时, 如果采取直接求解的方法,往往比较困难,这时,人们通 常会采取一种分解或变换的思想,将复杂问题分解或转化 为一系列本原问题,然后通过对这些本原问题的求解来实 现对原问题的求解。
2.把一个复杂问题变换为若干个与之等价的 新问题时,可用一个“或树”来表示这种变 换。例如,设问题P可以变换为三个新问题 P1、P2、P3中的任何一个,即它与这三 个新问题中的任何一个等价,则P与它们之 间的关系可用如图所示的一个“或树”来表 示。在这个“或”树中,用相应的节点表示 P、P1、P2、P3;并用三条有向边分别 将P和P1、P2、P3连接起来,它表示P 1、P2、P3是与P等价的三个新问题。图 中的有向边不用小弧线连接,它表示P1、 P2、P3之间是“或”的关系,即节点P 为“或”节点。
该节点是一个终止节点。 该节点是一个“或”节点,且其子节点中至少有一个为可解
节点。 该节点是一个“与”节点,且其子节点全部为可解节点。
• 同样,满足下列条件之一的节点为不可解节点:
该节点是一个端节点,但却不是终止节点。 该节点是一个“或”节点,但其子节点中没有一个是可解节
人工智能6第六章-与或树的搜索策略_搜索的完备性与效率 (2)

希望树
希望树的定义
选择待扩展节点时,挑选有希望成为最优 解树一部分的节点进行扩展,保证任一时刻 求出的部分解树的代价都是最小的。
例:与/或树的宽度优先搜索
Step3:扩展3得到5、B,都不是终叶节点,接 着扩展4。
Step4:扩展4得到A、t2。
t过2是程终标叶出节4、点2,均标为示可4解为节可点解。节点。应用可解标示
还不能确定1为可解节点。此时5号节点是OPEN表 中的第一个待考察的节点,所以下一步扩展5号节 点。
OPEN ……
– 如果x是“或”节点,y1, y2, …, yn是它的子节点,则具有
min
1i n
c x, yi h yi
值的那个子节点yi也应在希望树中。
– 如果x是“与”节点,则它的全部子节点都应在希望树中。
有序搜索算法流程
(1)把初始节点S放入OPEN表中。 (2)根据当前搜索树中节点的代价求出以S为根的希望
如果x不可扩展,且不是终叶节点,则定义:h(x)=
如果x是“或”节点,y1, y2, …, yn是它的子节点,则x的代价为:
h
x
min
1i n
c
x,
yi
h
yi
如果x是“与”节点.则x的代价有两种计算方法:
※和代价法
n
h x c x, yi h yi i 1
※最大代价法
h
x
max
1i n
c
x,
宽度优先搜索算法流程
搜索策略

6.1.3 与/或树表示法
与/或树是用于表示问题及其求解过程的另一种方法,通 常用于表示比较复杂问题的求解。 对于一个复杂问题,直接求解往往比较困难。此时可通过 下述方法进行简化:
分解 把一个复杂问题分解为若干个较为简单的子问题,每个子问题又 可继续分解。重复此过程,直到不需要再分解或者不能再分解为 止。如此形成“与”树。 等价变换 利用同构或同态的等价变换,把原问题变换为若干个较为容易求 解的新问题。如此形成“或”树。
2,3 3,3 1,3 1,2 3,2 A(3,2) 2,2
采用状态空间表示方法,首先要把问题的一切状态都表示出 来,其次要定义一组算符。 问题的求解过程是一个不断把算符作用于状态的过程。如果 在使用某个算符后得到的新状态是目标状态,就得到了问题 的一个解。这个解就是从初始状态到目标状态所采用算符的 序列。使用算符最少的解称为最优解。 对任何一个状态,可使用的算符可能不止一个。这样由一个 状态所生成的后继状态就可能有多个。此时首先对哪一个状 态进行操作,就取决于搜索策略。
7. 8.
按某种搜索策略对OPEN表中的节点进行排序; 转第2步。
一些说明
一个节点经一个算符操作后一般只生成一个子节点。但适用于 一个节点的算符可能有多个,此时就会生成一组子节点。这些 子节点中可能有些是当前扩展节点的父节点、祖父节点等,此 时不能把这些先辈节点作为当前扩展节点的子节点。 一个新生成的节点,它可能是第一次被生成的节点,也可能是 先前已作为其它节点的子节点被生成过,当前又作为另一个节 点的子节点被再次生成。此时,它究竟应选择哪个节点作为父 节点?一般由原始节点到该节点的代价来决定,处于代价小的 路途上的那个节点就作为该节点的父节点。 在搜索过程中,一旦某个被考察的节点是目标节点就得到了一 个解。该解是由从初始节点到该目标节点路径上的算符构成。 如果在搜索中一直找不到目标节点,而且OPEN表中不再有可 供扩展的节点,则搜索失败。 通过搜索得到的图称为搜索图,搜索图是状态空间图的一个子 集。由搜索图中的所有节点及反向指针所构成的集合是一棵树, 称为搜索树。根据搜索树可给出问题的解。
与或树的搜索策略搜索的完备性与效率(PPT43张)

……
……
例:与/或树的宽度优先搜索
Step3:扩展3得到5、B,都不是终叶节点,接着扩展4。
Step4:扩展4得到A、t2。
t2是终叶节点,标示4为可解节点。应用可解标示过程标出4、 2均为可解节点。 还不能确定1为可解节点。此时5号节点是OPEN表中的第一 个待考察的节点,所以下一步扩展5号节点。
深度优先搜索规定一个深度界限,使搜索在规定范围内
进行。
有界深度优先搜索算法流程
1. 2. 3. 4.
把初始节点S放人OPEN表。
把OPEN表中第一个节点n取出,放入CLOSLD表。
如果n的深度深度界限,转第(5)步的第①点。 如果n 可扩展,做下列工作: ①扩展n,将子节点放入OPEN表首部,配置父指针,在 标示过程使用。 ②若子节点中有终叶节点,标示其为可解节点,对其先辈 节点应用可解标示过程进行标示。若S被标示为可解, 得到解树,成功退出搜索;若无法确定S为可解节点, 从OPEN表中删去有可解先辈的节点。 ③转第(2)步。
有界深度优先搜索算法流程
5.
如果n不可扩展,则做下列工作:
①标示n为不可解节点。
②应用不可解标示过程对 n的先辈节点中不可解节点进行 标示。如果S被标示为不可解节点,则搜索失败退出;如 果不能确定S为不可解节点,则从OPEN表中删去有不可 解先辈的节点。 ③转第(2)步。
例:与/或树的深度优先搜索
一般搜索过程流程
(1)把原始问题作为初始节点S,并把它作为当前节点。
(2)应用分解或等价变换算符对当前节点进行扩展。
(3)为每个子节点设置指向父节点的指针。 (4)选择合适子节点作为当前节点,反复执行第(2)、(3)步, 在此期间多次调用可解标示过程和不可解标示过程,直 到初始节点被标示为可解节点或不可解节点为止。
人工智能课后习题第6章 参考答案

第6章不确定性推理参考答案6.8 设有如下一组推理规则:r1: IF E1THEN E2 (0.6)r2: IF E2AND E3THEN E4 (0.7)r3: IF E4THEN H (0.8)r4: IF E5THEN H (0.9)且已知CF(E1)=0.5, CF(E3)=0.6, CF(E5)=0.7。
求CF(H)=?解:(1) 先由r1求CF(E2)CF(E2)=0.6 × max{0,CF(E1)}=0.6 × max{0,0.5}=0.3(2) 再由r2求CF(E4)CF(E4)=0.7 × max{0, min{CF(E2 ), CF(E3 )}}=0.7 × max{0, min{0.3, 0.6}}=0.21(3) 再由r3求CF1(H)CF1(H)= 0.8 × max{0,CF(E4)}=0.8 × max{0, 0.21)}=0.168(4) 再由r4求CF2(H)CF2(H)= 0.9 ×max{0,CF(E5)}=0.9 ×max{0, 0.7)}=0.63(5) 最后对CF1(H )和CF2(H)进行合成,求出CF(H)CF(H)= CF1(H)+CF2(H)+ CF1(H) × CF2(H)=0.6926.10 设有如下推理规则r1: IF E1THEN (2, 0.00001) H1r2: IF E2THEN (100, 0.0001) H1r3: IF E3THEN (200, 0.001) H2r4: IF H1THEN (50, 0.1) H2且已知P(E1)= P(E2)= P(H3)=0.6, P(H1)=0.091, P(H2)=0.01, 又由用户告知:P(E1| S1)=0.84, P(E2|S2)=0.68, P(E3|S3)=0.36请用主观Bayes方法求P(H2|S1, S2, S3)=?解:(1) 由r1计算O(H1| S1)先把H1的先验概率更新为在E1下的后验概率P(H1| E1)P(H1| E1)=(LS1× P(H1)) / ((LS1-1) × P(H1)+1)=(2 × 0.091) / ((2 -1) × 0.091 +1)=0.16682由于P(E1|S1)=0.84 > P(E1),使用P(H | S)公式的后半部分,得到在当前观察S1下的后验概率P(H1| S1)和后验几率O(H1| S1)P(H1| S1) = P(H1) + ((P(H1| E1) – P(H1)) / (1 - P(E1))) × (P(E1| S1) – P(E1))= 0.091 + (0.16682 –0.091) / (1 – 0.6)) × (0.84 – 0.6)=0.091 + 0.18955 × 0.24 = 0.136492O(H1| S1) = P(H1| S1) / (1 - P(H1| S1))= 0.15807(2) 由r2计算O(H1| S2)先把H1的先验概率更新为在E2下的后验概率P(H1| E2)P(H1| E2)=(LS2×P(H1)) / ((LS2-1) × P(H1)+1)=(100 × 0.091) / ((100 -1) × 0.091 +1)=0.90918由于P(E2|S2)=0.68 > P(E2),使用P(H | S)公式的后半部分,得到在当前观察S2下的后验概率P(H1| S2)和后验几率O(H1| S2)P(H1| S2) = P(H1) + ((P(H1| E2) – P(H1)) / (1 - P(E2))) × (P(E2| S2) – P(E2))= 0.091 + (0.90918 –0.091) / (1 – 0.6)) × (0.68 – 0.6)=0.25464O(H1| S2) = P(H1| S2) / (1 - P(H1| S2))=0.34163(3) 计算O(H1| S1,S2)和P(H1| S1,S2)先将H1的先验概率转换为先验几率O(H1) = P(H1) / (1 - P(H1)) = 0.091/(1-0.091)=0.10011再根据合成公式计算H1的后验几率O(H1| S1,S2)= (O(H1| S1) / O(H1)) × (O(H1| S2) / O(H1)) × O(H1)= (0.15807 / 0.10011) × (0.34163) / 0.10011) × 0.10011= 0.53942再将该后验几率转换为后验概率P(H1| S1,S2) = O(H1| S1,S2) / (1+ O(H1| S1,S2))= 0.35040(4) 由r3计算O(H2| S3)先把H2的先验概率更新为在E3下的后验概率P(H2| E3)P(H2| E3)=(LS3× P(H2)) / ((LS3-1) × P(H2)+1)=(200 × 0.01) / ((200 -1) × 0.01 +1)=0.09569由于P(E3|S3)=0.36 < P(E3),使用P(H | S)公式的前半部分,得到在当前观察S3下的后验概率P(H2| S3)和后验几率O(H2| S3)P(H2| S3) = P(H2 | ¬ E3) + (P(H2) – P(H2| ¬E3)) / P(E3)) × P(E3| S3)由当E3肯定不存在时有P(H2 | ¬ E3) = LN3× P(H2) / ((LN3-1) × P(H2) +1)= 0.001 × 0.01 / ((0.001 - 1) × 0.01 + 1)= 0.00001因此有P(H2| S3) = P(H2 | ¬ E3) + (P(H2) – P(H2| ¬E3)) / P(E3)) × P(E3| S3)=0.00001+((0.01-0.00001) / 0.6) × 0.36=0.00600O(H2| S3) = P(H2| S3) / (1 - P(H2| S3))=0.00604(5) 由r4计算O(H2| H1)先把H2的先验概率更新为在H1下的后验概率P(H2| H1)P(H2| H1)=(LS4× P(H2)) / ((LS4-1) × P(H2)+1)=(50 × 0.01) / ((50 -1) × 0.01 +1)=0.33557由于P(H1| S1,S2)=0.35040 > P(H1),使用P(H | S)公式的后半部分,得到在当前观察S1,S2下H2的后验概率P(H2| S1,S2)和后验几率O(H2| S1,S2)P(H2| S1,S2) = P(H2) + ((P(H2| H1) – P(H2)) / (1 - P(H1))) × (P(H1| S1,S2) – P(H1))= 0.01 + (0.33557 –0.01) / (1 – 0.091)) × (0.35040 – 0.091)=0.10291O(H2| S1,S2) = P(H2| S1, S2) / (1 - P(H2| S1, S2))=0.10291/ (1 - 0.10291) = 0.11472(6) 计算O(H2| S1,S2,S3)和P(H2| S1,S2,S3)先将H2的先验概率转换为先验几率O(H2) = P(H2) / (1 - P(H2) )= 0.01 / (1-0.01)=0.01010再根据合成公式计算H1的后验几率O(H2| S1,S2,S3)= (O(H2| S1,S2) / O(H2)) × (O(H2| S3) / O(H2)) ×O(H2)= (0.11472 / 0.01010) × (0.00604) / 0.01010) × 0.01010=0.06832再将该后验几率转换为后验概率P(H2| S1,S2,S3) = O(H1| S1,S2,S3) / (1+ O(H1| S1,S2,S3))= 0.06832 / (1+ 0.06832) = 0.06395可见,H2原来的概率是0.01,经过上述推理后得到的后验概率是0.06395,它相当于先验概率的6倍多。
人工智能概论(新)
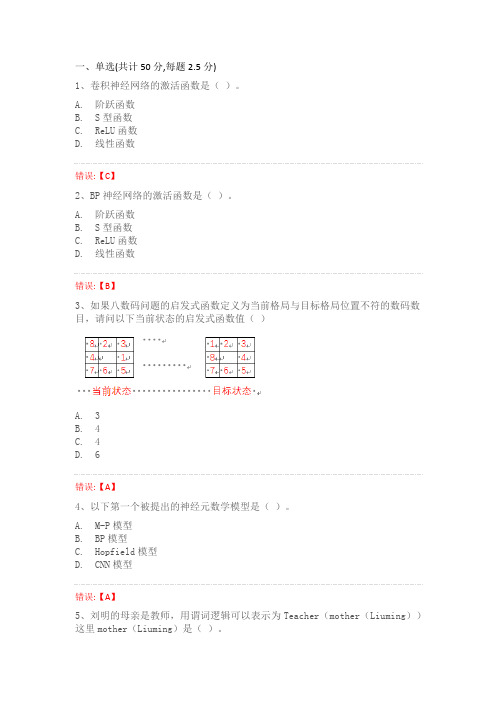
一、单选(共计50分,每题2.5分)1、卷积神经网络的激活函数是()。
A. 阶跃函数B. S型函数C. ReLU函数D. 线性函数错误:【C】2、BP神经网络的激活函数是()。
A. 阶跃函数B. S型函数C. ReLU函数D. 线性函数错误:【B】3、如果八数码问题的启发式函数定义为当前格局与目标格局位置不符的数码数目,请问以下当前状态的启发式函数值()A. 3B. 4C. 4D. 6错误:【A】4、以下第一个被提出的神经元数学模型是()。
A. M-P模型B. BP模型C. Hopfield模型D. CNN模型错误:【A】5、刘明的母亲是教师,用谓词逻辑可以表示为Teacher(mother(Liuming))这里mother(Liuming)是()。
A. 常量B. 变元C. 函数D. 一元谓词错误:【C】6、轮盘选择方法中,适应度函数与选择概率的关系是()。
A. 正比例相关B. 负比例相关C. 指数相关D. 不相关错误:【A】7、已知CF1(H)=-0.5 CF2(H)=0.3,请问结论H不确定性的合成CF1,,2(H)=?()。
A. -0.2B. -0.15C. -0.8D. -0.29错误:【D】8、MYCIN系统中使用不确定推理,规则E→H由专家指定其可信度CF(H,E),若E不支持结论H为真,那么可以得到以下结论?()。
A. CF(H,E)=0B. CF(H,E)>0C. CF(H,E)<0D. CF(H,E)=-1错误:【C】9、李明的父亲是教师,用谓词逻辑可以表示为Teacher(father(Liming))这里father(Liming)是()。
A. 常量B. 变元C. 函数D. 一元谓词错误:【C】10、在遗传算法中,将所有妨碍适应度值高的个体产生,从而影响遗传算法正常工作的问题统称为()。
A. 优化问题B. 迭代问题C. 功能问题D. 欺骗问题错误:【D】11、在当前人工智能领域主要使用的程序设计语言是()。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
例:与/或树的深度优先搜索
对与/或树进行有界深度优先搜索,并规定深度界 限为4,则扩展节点的顺序是:1,3,B,5,2,4
解树与宽度优先搜索相同。
与/或树的深度、宽度优先搜索特点
• 都是盲目搜索。
• 搜索从初始节点开始,先自上而下进行搜索,寻找 终叶节点及端点节,然后再自下而上进行标示。一 旦初始节点被标示为可解或不可解节点,搜索就不 再继续进行。
宽度优先搜索算法流程
宽度优先搜索算法流程
例:与/或树的宽度优先搜索
例:终设叶有节如点图,所A和示B的是与不/可或解树的,端其节中点t1,。t2,t3,t4均为 试采用与/或树的宽度优先搜索法对该图进行搜索。
例:与/或树的宽度优先搜索
Step1:扩展1号节点,得到2、3号节点。
2、3都不是终叶节点,接着扩展2。
3.2 与/或树的搜索策略
• 一般搜索过程 • 宽度优先搜索 • 深度优先搜索 • 有序搜索 • 博弈树搜索
• -剪枝技术
可解节点与不可解节点
在与/或树上执行搜索过程,目的在于表明起始节点有解或无解。
可解节点的递归定义为:
终叶节点是可解节点,直 接和本原问题相关连;
非终叶节点含有“或”子 节点时,只要子节点中有 一个是可解节点,该非终 叶节点便为可解节点;
节点应用可解标示过程进行标示。若S被标示为可 解,
得到解树,成功退出搜索;若无法确定S为可解节 点,
从OPEN表中删去有可解先辈的节点。 ③转第(2)步。
有界深度优先搜索算法流程
5. 如果n不可扩展,则做下列工作:
①标示n为不可解节点。
②应用不可解标示过程对n的先辈节点中不可 解节点进行标示。如果S被标示为不可解节点, 则搜索失败退出;如果不能确定S为不可解节 点,则从OPEN表中删去有不可解先辈的节点。
OPEN 1 2,3 3
CLOSED
1 2,1
例:与/或树的宽度优先搜索
Step3:扩展2,得到4、t1。 t1是终叶节点,标示为可解节点,应用可解标
示过程,对其先辈节点中的可解节点进行标示。
t1的父节点是“与”节点,仅由t1可解不能确 定2是否可解,应继续搜索。
OPEN …… 3,4
……
CLOSED …… 2,1 t1,2,1 ……
– 由这个搜索过程所形成的节点和指针结构称为搜索树。 – 搜索中,通过可解标示过程确定初始节点是可解的,
则由此初始节点及其下属的可解节点就构成了解树。
提高与/或树搜索效率的两个性质
与/或搜索有两个特有性质,可用来提高搜索效率:
• 如果已确定某个节点为可解节点,其不可解的后裔节点不再有 用,可从搜索树中删去;
非终叶节点含有“与”子 节点时,只有子节点全为 可解节点时,该非终叶节 点才是可解节点。
不注可意解:终节叶点节的点定一义定为是:端节点,
但端关节于点可不解一定节是点终的叶三节个点条。件全 部不满足的节点,称为不可解 节点;
由可解子节点来确定先辈节点是 否为可解节点的过程称为可解标 示过程。
由不可解子节点来确定先辈节点 是否为可解节点的过程称为不可 解标示过程。
4 5 ……
CLOSED …… 3,t1,2,1
t2,4,3,t1,2,1 ……
例:与/或树的宽度优先搜索
Step5:扩展5得到t3、t4。
都是终叶节点,标示5为可解节点。 应用可解标示过程得到5、3、1均为可解节点。
Step6:搜索成功,得到解树。
OPEN ……
CLOSED ……
5,t2,4,3,t1,2,1
• 若已确定某个节点是不可解节点,其全部后裔节点都不再有用, 可从搜索树中删去。但当前这个不可解节点还不能删去,在判 断其先辈节点的可解性时还要用到。
宽度优先搜索算法流程
基本思想:先产生的节点先扩展,先进先出。
1. 把初始节点S放入OPEN表。 2. 把OPEN表中的第一个节点(记为节点n)取出放入CLOSLD表。 3. 如果n可扩展,则做下列工作:
例:与/或树的宽度优先搜索
Step3:扩展3得到5、B,都不是终叶节点,接 着扩展4。
Step4:扩展4得到A、t2。
t过2是程终标叶出节4、点2,均标为示可4解为节可点解。节点。应用可解标示
还不能确定1为可解节点。此时5号节点是OPEN表 中的第一个待考察的节点,所以下一步扩展5号节 点。
OPEN ……
有界深度优先搜索算法流程
1. 把初始节点S放人OPEN表。 2. 把OPEN表中第一个节点n取出,放入CLOSLD表。 3. 如果n的深度深度界限,转第(5)步的第①点。 4. 如果n 可扩展,做下列工作:
①扩展n,将子节点放入OPEN表首部,配置父指针, 在
标示过程使用。 ②若子节点中有终叶节点,标示其为可解节点,对 其先辈
……
……
深度优先搜索的几点说明
• 与/或树的深度优先搜索和宽度优先搜索过程基本 相同。只要把第(3)步的第①点改为“扩展节点n, 将其子节点放入OPEN表的首部,并为每个子节点 配置父指针,以备标示过程使用”,就可使后产生 的节点先被扩展。
• 也可像状态空间的有界深度优先搜索那样,为与/ 或树的深度优先搜索规定一个深度界限,使搜索在 规定范围内进行。
③转步骤2。
宽度优先搜索算法流程
4. 如果n不可扩展,则做下列工作: ①标示n为不可解节点。 ②应用不可解标示过程对n的先辈节点中不可 解的节点进行标示。如果S被标示为不可解节 点,则搜索失败,原始问题无解,退出搜索 过程;如果无法确定S不可解,则从OPEN表中 删去具有不可解先辈的节点。
③转步骤2。
①扩展n,将其子节点放入OPEN表的尾部,并为每个子节点配置父指 针,以备标示过程使用。
②考察子节点中是否有终叶节点。若有,则标示这些终叶节点为可解 节点,并应用可解标示过程对其先辈节点中的可解节点进行标示。 若S也被标示为可解节点,就得到了解树,搜索成功,退出搜索过程; 若无法确定S可解,则从OPEN表中删去具有可解先辈的节点。
一般搜索过程流程
(1)把原始问题作为初始节点S,并把它作为当前节点。 (2)应用分解或等价变换算符对当前节点进行扩展。 (3)为每个子节点设置指向父节点的指针。 (4)选择合适子节点作为当前节点,反复执行第(2)、(标示为可解节点或不可解节 点为止。