最新定性数据分析第五章课后答案
《统计分析和SPSS的应用(第五版)》课后练习答案与解析(第5章)
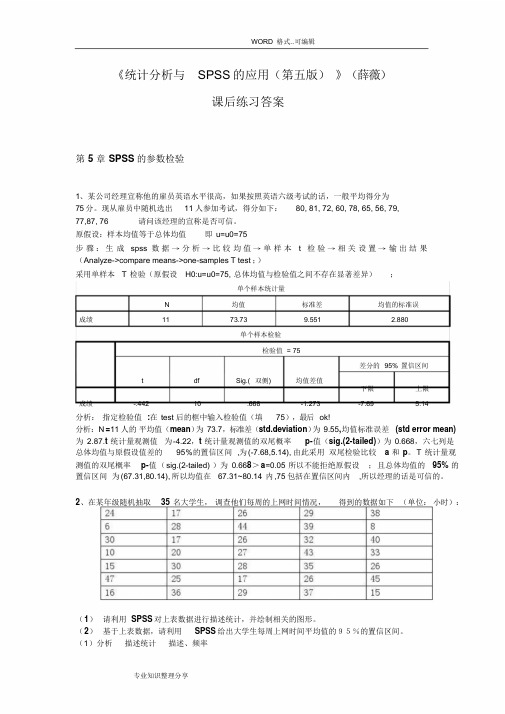
《统计分析与SPSS的应用(第五版)》(薛薇)课后练习答案第5 章SPSS的参数检验1、某公司经理宣称他的雇员英语水平很高,如果按照英语六级考试的话,一般平均得分为75分。
现从雇员中随机选出11人参加考试,得分如下:80, 81, 72, 60, 78, 65, 56, 79,77,87, 76 请问该经理的宣称是否可信。
原假设:样本均值等于总体均值即u=u0=75步骤:生成spss 数据→分析→比较均值→单样本t 检验→相关设置→输出结果(Analyze->compare means->one-samples T test ;)采用单样本T 检验(原假设H0:u=u0=75, 总体均值与检验值之间不存在显著差异);单个样本统计量N 均值标准差均值的标准误成绩11 73.73 9.551 2.880单个样本检验检验值= 75差分的95% 置信区间t df Sig.( 双侧) 均值差值下限上限成绩-.442 10 .668 -1.273 -7.69 5.14分析:指定检验值:在test 后的框中输入检验值(填75),最后ok!分析:N=11 人的平均值(mean)为73.7,标准差(std.deviation)为9.55,均值标准误差(std error mean) 为2.87.t 统计量观测值为-4.22,t 统计量观测值的双尾概率p-值(sig.(2-tailed))为0.668,六七列是总体均值与原假设值差的95%的置信区间,为(-7.68,5.14), 由此采用双尾检验比较 a 和p。
T 统计量观测值的双尾概率p-值(sig.(2-tailed) )为0.668>a=0.05 所以不能拒绝原假设;且总体均值的95% 的置信区间为(67.31,80.14), 所以均值在67.31~80.14 内,75 包括在置信区间内,所以经理的话是可信的。
2、在某年级随机抽取35 名大学生,调查他们每周的上网时间情况,得到的数据如下(单位:小时):(1)请利用SPSS 对上表数据进行描述统计,并绘制相关的图形。
定性数据知识点总结

定性数据知识点总结一、定性数据的概念定性数据是指用语言来描述的数据,通常是以文本形式存在的数据。
与定量数据相对应,定性数据没有具体的数值,而是通过描述性的语言来表达。
定性数据主要适用于调研、文本分析、社会科学等领域的数据分析。
二、定性数据的特点1. 描述性:定性数据是通过描述性的语言来表达,通常是用一些标签、符号或文字来表示,而非具体的数字。
2. 非数值化:定性数据不具有数值属性,无法进行数学计算,只能通过文字描述或分类来表示。
3. 主观性:定性数据通常包含了研究者或被调查者的主观意见、看法和感受,具有一定的主观性和个性化。
4. 多样性:定性数据的形式多样,可以是文字、图片、音视频等多种形式的信息。
5. 信息丰富:定性数据能够提供更为详尽和全面的信息,能够帮助人们更好地理解研究对象的特征和内涵。
6. 可解释性:定性数据通常具有较强的解释性,能够帮助人们理解数据背后的含义,揭示隐藏的规律和关联。
三、定性数据的分类1. 分类数据:分类数据是最常见的一种定性数据,通常是将个体或对象分为不同的类别或组别。
例如性别、学历、职业等都是分类数据。
2. 颜色数据:颜色数据是指反映事物颜色属性的数据,例如红色、黄色、蓝色等。
3. 标称数据:标称数据是用名称标识不同的类别,没有顺序关系。
例如血型(A、B、AB、O)、宠物类型(猫、狗、鸟)等都是标称数据。
4. 有序数据:有序数据是指具有一定顺序关系的数据,但没有具体的数值。
例如文化程度的高低可以分为低、中、高三个等级,这就是有序数据。
四、定性数据的收集和处理1. 数据收集:定性数据的收集通常通过调查问卷、访谈、观察等方式获取,然后进行整理、归类和记录。
2. 数据处理:定性数据的处理涉及到数据清洗、编码、分类、文本分析等步骤,以便进行深入的分析和应用。
五、定性数据的分析方法1. 描述性分析:通过统计、频数分布、交叉表等方法对定性数据进行描述性统计和分析,了解各类别的分布情况和属性特征。
数据分析笔试题及答案

数据分析笔试题及答案一、选择题(每题2分,共10分)1. 数据分析中,以下哪个指标不是描述性统计指标?A. 平均数B. 中位数C. 标准差D. 相关系数答案:D2. 在进行数据清洗时,以下哪项操作不是必要的?A. 处理缺失值B. 去除异常值C. 转换数据类型D. 增加数据量答案:D3. 以下哪个工具不是数据分析常用的软件?A. ExcelB. RC. PythonD. Photoshop答案:D4. 假设检验中,P值小于显著性水平α,我们通常认为:A. 拒绝原假设B. 接受原假设C. 无法判断D. 结果不可靠答案:A5. 以下哪个不是时间序列分析的特点?A. 趋势性B. 季节性C. 随机性D. 稳定性答案:D二、简答题(每题5分,共15分)1. 请简述数据可视化的重要性。
答案:数据可视化是数据分析中的重要环节,它能够帮助分析者直观地理解数据的分布、趋势和模式。
通过图表、图形等形式,可以更清晰地展示数据之间的关系,便于发现数据中的规律和异常点,从而为决策提供支持。
2. 描述数据挖掘中的“关联规则”是什么,并给出一个例子。
答案:关联规则是数据挖掘中用来发现变量之间有趣关系的一种方法,特别是变量之间的频繁模式、关联、相关性。
例如,在超市购物篮分析中,关联规则可能揭示“购买了牛奶的顾客中有80%也购买了面包”。
3. 解释什么是“数据的维度”以及它在数据分析中的作用。
答案:数据的维度指的是数据集中可以独立变化的属性或特征。
在数据分析中,维度可以帮助我们从不同角度观察和理解数据,进行多维度的分析和比较,从而获得更全面的数据洞察。
三、计算题(每题10分,共20分)1. 给定一组数据:2, 3, 4, 5, 6, 7, 8, 9, 10,请计算这组数据的平均数和标准差。
答案:平均数 = (2+3+4+5+6+7+8+9+10) / 9 = 5.5标准差 = sqrt(((2-5.5)^2 + (3-5.5)^2 + ... + (10-5.5)^2) / 9) ≈ 2.87232. 如果一家公司在过去5年的年销售额分别为100万、150万、200万、250万和300万,请计算该公司年销售额的复合年增长率(CAGR)。
第四版统计学课后习题答案

第四版统计学课后习题答案《统计学》第四版统计课后思考题答案第一章思考题1.1什么是统计学统计学是关于数据的一门学科,它收集,处理,分析,解释来自各个领域的数据并从中得出结论。
1.2解释描述统计和推断统计描述统计;它研究的是数据收集,处理,汇总,图表描述,概括与分析等统计方法。
推断统计;它是研究如何利用样本数据来推断总体特征的统计方法。
1.3统计学的类型和不同类型的特点统计数据;按所采用的计量尺度不同分;(定性数据)分类数据:只能归于某一类别的非数字型数据,它是对事物进行分类的结果,数据表现为类别,用文字来表述;(定性数据)顺序数据:只能归于某一有序类别的非数字型数据。
它也是有类别的,但这些类别是有序的。
(定量数据)数值型数据:按数字尺度测量的观察值,其结果表现为具体的数值。
统计数据;按统计数据都收集方法分;观测数据:是通过调查或观测而收集到的数据,这类数据是在没有对事物人为控制的条件下得到的。
实验数据:在实验中控制实验对象而收集到的数据。
统计数据;按被描述的现象与实践的关系分;截面数据:在相同或相似的时间点收集到的数据,也叫静态数据。
时间序列数据:按时间顺序收集到的,用于描述现象随时间变化的情况,也叫动态数据。
1.4解释分类数据,顺序数据和数值型数据答案同1.31.5举例说明总体,样本,参数,统计量,变量这几个概念对一千灯泡进行寿命测试,那么这千个灯泡就是总体,从中抽取一百个进行检测,这一百个灯泡的集合就是样本,这一千个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是参数,这一百个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是统计量,变量就是说明现象某种特征的概念,比如说灯泡的寿命。
1.6变量的分类变量可以分为分类变量,顺序变量,数值型变量。
变量也可以分为随机变量和非随机变量。
经验变量和理论变量。
1.7举例说明离散型变量和连续性变量离散型变量,只能取有限个值,取值以整数位断开,比如“企业数”连续型变量,取之连续不断,不能一一列举,比如“温度”。
王静龙定性数据分析 习题五

王静龙定性数据分析习题五1. 问题描述在定性数据分析中,王静龙遇到了一个问题,他想要了解一份调查问卷中的开放性问题的回答情况。
具体而言,他想要回答以下几个问题:1.开放性问题的回答内容的总体情况如何?2.开放性问题的回答内容中是否存在一些常见的关键词或主题?3.开放性问题的回答内容中是否存在一些特定的意见或情感?为了解决这个问题,王静龙希望能够进行数据分析,并得出一些有用的结论。
2. 数据准备首先,王静龙需要准备调查问卷中开放性问题的回答数据。
这些数据可以以文本文件的形式存储,每一行代表一个回答。
例如,以下是一些示例数据:1. 我觉得工作环境很好,同事们相互合作,给了我很多帮助。
2. 公司的培训计划很好,能够提高员工的技能和知识。
3. 我对公司的管理方式有一些不满意,希望能够改进。
4. 薪资待遇不够优厚,希望能够有所提升。
5. 我觉得公司的发展前景很不错,希望能够有更好的发展空间。
3. 数据分析3.1 总体情况分析为了了解开放性问题的回答内容的总体情况,王静龙可以进行以下分析:•回答的总数•回答的平均长度•回答的最长长度•回答的最短长度为了实现这些分析,可以使用Python编程语言中的文本处理库进行操作。
下面是一个示例代码,可以帮助完成上述分析:```python # 导入所需的库 import pandas as pd 读取文本文件data = pd.read_csv(’responses.txt’, header=None)计算回答的总数total_responses = len(data)计算回答的平均长度average_length = data[0].apply(len).mean()计算回答的最长长度max_length = data[0].apply(len).max()计算回答的最短长度min_length = data[0].apply(len).min()输出结果print(。
VIP中级人力专业知识与实务必刷题 第五章人力资源规划

VIP中级人力专业知识与实务必刷题第五章人力资源规划1. 公司人力资源部门制定未来几年的人力资源规划时应当首先( )。
[单选题] *A.明确组织结构和业务流程B.了解外部劳动力市场状况C.了解竞争对手的情况D.明确公司的战略规划(正确答案)答案解析:本题考查人力资源规划的概念及其主要内容和基本流程。
组织的人力资源规划是从明确组织的战略规划开始的。
2. 狭义的人力资源规划是指( )。
[单选题] *A.培训与开发规划B.人员供求与雇用规划(正确答案)C.人员需求规划D.人员供给规划答案解析:本题考查人力资源规划的概念及其主要内容和基本流程。
狭义的人力资源规划专指组织的人员供求规划或雇用规划,即根据组织未来的人力资源需求和供给分析,找出供求之间的矛盾,从而帮助组织制订平衡人力资源供求关系的各种相关计划。
3. (2022年)人工智能等新技术对人工的替代使很多行业对人力资源需求数量减少,这体现了影响人力资源需求的因素是( )。
[单选题] *A.业务外包B.组织结构调整C.组织提供的产品情况D.技术变革(正确答案)答案解析:本题考查人力资源需求预测的内容及其影响因素。
组织在未来可能会采用的新技术会影响到组织的人力资源需求,这种影响可能不仅体现在对人力资源数量的要求上,而且体现在对人力资源质量的要求上。
例如,生产的自动化、新技术的引进、人工智能的使用等,都有可能一方面减少对普通工人的需求,另一方面增加对掌握新技术工人的需求。
4. 定量的人力资源需求预测方法不包括( )。
[单选题] *A.趋势预测法B. 比率分析法C.回归分析法D.德尔菲法(正确答案)答案解析:本题考查人力资源需求预测的主要方法。
定量的人力资源需求预测方法主要包括比率分析法、趋势预测法以及回归分析法。
5. (2023年)在进行人力资源需求预测时采用的经验判断法,下列说法错误的是( )。
[单选题] *A.经验判断法适用于长期预测(正确答案)B.经验判断法是一种最简单的人力资源需求预测方法C.经验判断法要求管理者具有丰富的工作经验D.经验判断法是一种定性的方法答案解析:本题考查经验判断法。
定性数据分析第五章课后答案
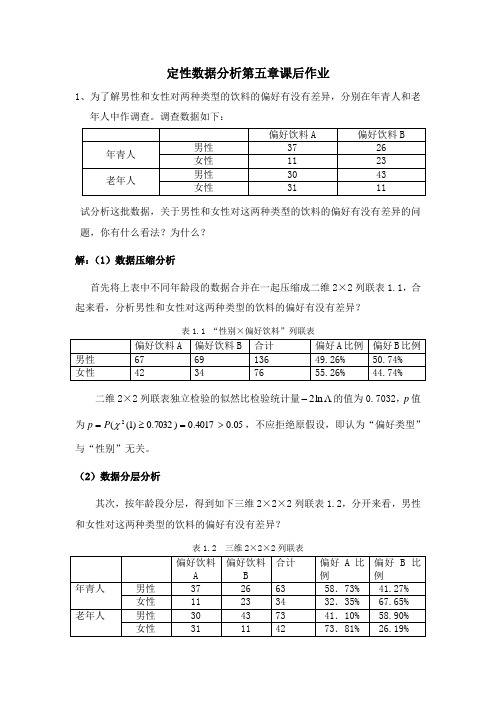
定性数据分析第五章课后作业1、为了解男性和女性对两种类型的饮料的偏好有没有差异,分别在年青人和老年人中作调查。
调查数据如下:试分析这批数据,关于男性和女性对这两种类型的饮料的偏好有没有差异的问题,你有什么看法?为什么?解:(1)数据压缩分析首先将上表中不同年龄段的数据合并在一起压缩成二维2×2列联表1.1,合起来看,分析男性和女性对这两种类型的饮料的偏好有没有差异?表1.1 “性别×偏好饮料”列联表二维2×2列联表独立检验的似然比检验统计量Λ2的值为0.7032,p值-ln为05≥==χp,不应拒绝原假设,即认为“偏好类型”(2>P4017.0)1().07032.0与“性别”无关。
(2)数据分层分析其次,按年龄段分层,得到如下三维2×2×2列联表1.2,分开来看,男性和女性对这两种类型的饮料的偏好有没有差异?表1.2 三维2×2×2列联表在上述数据中,分别对两个年龄段(即年青人和老年人)进行饮料偏好的调查,在“年青人”年龄段,男性中偏好饮料A 占58.73%,偏好饮料B 占41.27%;女性中偏好饮料A 占58.73%,偏好饮料B 占41.27%,我们可以得出在这个年龄段,男性和女性对这两种类型的饮料的偏好有一定的差异。
同理,在“老年人”年龄段,也有一定的差异。
(3)条件独立性检验为验证上述得出的结果是否可靠,我们可以做以下的条件独立性检验。
即由题意,可令C 表示年龄段,1C 表示年青人,2C 表示老年人;D 表示性别,1D 表示男性,2D 表示女性;E 表示偏好饮料的类型,1E 表示偏好饮料A ,2E 表示偏好饮料B 。
欲检验的原假设为:C 给定后D 和E 条件独立。
按年龄段分层后得到的两个四格表,以及它们的似然比检验统计量Λ-ln 2的值如下: 1C 层2C 层248.6ln 2=Λ- 822.11ln 2=Λ-条件独立性检验问题的似然比检验统计量是这两个似然比检验统计量的和,其值为07.18822.11248.6ln 2=+=Λ-由于2===t c r ,所以条件独立性检验的似然比检验统计量的渐近2χ分布的自由度为2)1)(1(=--t c r ,也就是上面这2个四格表的渐近2χ分布的自由度的和。
企业统计考试题及答案

企业统计考试题及答案一、单项选择题(每题2分,共20分)1. 统计数据的收集方法中,不包括以下哪一项?A. 观察法B. 实验法C. 调查法D. 计算法答案:D2. 以下哪一项不是统计学研究的基本要素?A. 总体B. 样本C. 个体D. 变量答案:D3. 统计分析中,描述数据集中趋势的指标不包括以下哪一项?A. 平均数B. 中位数C. 众数D. 方差答案:D4. 在统计学中,以下哪一项不是概率分布的类型?A. 正态分布B. 二项分布C. 泊松分布D. 均匀分布答案:D5. 以下哪一项不是统计图表的类型?A. 条形图B. 折线图C. 饼图D. 散点图答案:D6. 统计学中,以下哪一项不是数据的分类?A. 定性数据B. 定量数据C. 离散数据D. 连续数据答案:C7. 以下哪一项不是描述数据离散程度的统计量?A. 极差B. 方差C. 标准差D. 均值答案:D8. 以下哪一项不是统计推断的方法?A. 假设检验B. 置信区间C. 回归分析D. 数据描述答案:D9. 以下哪一项不是统计学中的数据收集方法?A. 普查B. 抽样调查C. 实验设计D. 数据整理答案:D10. 以下哪一项不是统计分析中的数据转换方法?A. 对数转换B. 平方根转换C. 倒数转换D. 标准化答案:D二、多项选择题(每题3分,共15分)1. 以下哪些是统计学中常用的数据整理方法?A. 排序B. 分组C. 编码D. 归档答案:A、B、C2. 以下哪些是描述数据分布特征的统计量?A. 均值B. 方差C. 标准差D. 极差答案:A、B、C、D3. 以下哪些是统计图表的类型?A. 条形图B. 折线图C. 饼图D. 散点图答案:A、B、C、D4. 以下哪些是统计学中的概率分布?A. 正态分布B. 二项分布C. 泊松分布D. 均匀分布答案:A、B、C5. 以下哪些是统计学中的数据类型?A. 定性数据B. 定量数据C. 离散数据D. 连续数据答案:A、B、C、D三、判断题(每题1分,共10分)1. 统计学是关于数据收集、处理、分析和解释的科学。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
定性数据分析第五章课后作业
1、为了解男性和女性对两种类型的饮料的偏好有没有差异,分别在年青人和老
试分析这批数据,关于男性和女性对这两种类型的饮料的偏好有没有差异的问 题,你有什么看法?为什么? 解:(1)数据压缩分析 首先将上表中不同年龄段的数据合并在一起压缩成二维
2X 2列联表1.1 ,合
起来看,分析男性和女性对这两种类型的饮料的偏好有没有差异?
表
1.1 “性别偏好饮料”列联表
二维2X 2列联表独立检验的似然比检验统计量 - 21 n 上的值为0.7032,p 值 为p =P( 2(1) -0.7032) =0.4017 ■ 0.05,不应拒绝原假设,即认为“偏好类型” 与“性别”无关。
(2) 数据分层分析
其次,按年龄段分层,得到如下三维 2X 2X 2列联表1.2,分开来看,男性 和女性对这两种类型的饮料的偏好有没有差异?
表1.2 三维2X 2X 2列联表
在上述数据中,分别对两个年龄段(即年青人和老年人)进行饮料偏好的调 查,在“年青人”年龄段,男性中偏好饮料A 占58. 73%偏好饮料B 占41.27%; 女性中偏好饮料A 占58. 73%偏好饮料B 占41.27%,我们可以得出在这个年 龄段,男性和女性对这两种类型的饮料的偏好有一定的差异。
同理,在“老年人”
年龄段,也有一定的差异。
(3) 条件独立性检验
为验证上述得出的结果是否可靠,我们可以做以下的条件独立性检验。
即由题意,可令C 表示年龄段,0表示年青人,C 2表示老年人;D 表示性别,D ! 表示男性,D 2表示女性;E 表示偏好饮料的类型,E !表示偏好饮料A, E 2表示 偏好饮料B 。
欲检验的原假设为:C 给定后D 和E 条件独立 按年龄段分层后得到的两个四格表,以及它们的似然比检验统计量 -21 n 上的值
如下:
条件独立性检验问题的似然比检验统计量是这两个似然比检验统计量的和,
其值
-2ln 上=6.248 11.822 =18.07 由于r = c = t = 2,所以条件独立性检验的似然比检验统计量的渐近 2分布的自 由度为r(c-1)(t-1) =2,也就是上面这
2个四格表的渐近 2分布的自由
G 层
-2ln 上=6.248 C 2层
-2ln 上=11.822
度的和。
由于p值P( 2(2) _18.07) = 0.000119165很小,所以认为条件独立性不成立,即
在年龄段给定的条件下,男性和女性对两种类型的饮料的偏好是有差异的。
(4)产生偏差的原因
&、在(1)中,将不同年龄段的数据压缩在一起合起来后分析发现男性和女性在对两种类型的饮料的偏好上是没有差异的。
但将数据以不同的年龄段分层后并分
别分析发现男性和女性在对两种类型的饮料的偏好上是有一定差异的。
合起来看
和分开来看的结果不同。
b、由此看来,年龄段在此次调查中属于混杂因素。
由于不同年龄段的人对饮料的选择也会有差异,例如现在的年青人偏好喝一些像可口可乐,美年达等这样的
碳酸饮料,而老年人则偏好喝一些红茶,绿茶等这样的非碳酸饮料,在调查中,
“老年人”年龄段共有115人,所占比例大,从而使整个结果就倾向于老年人的观点,即使得混杂因素“年龄段”起到一定的干扰作用,从而导致整个调查结果产生了偏差。
2、某工厂有三个车间。
车间主任分别为王、张和李。
过去的一年里,该工厂产
品的质量情况总结如下:
王主任将内销和外销产品合并在一起,然后计算各个车间的不合格率。
计算结
果如下:
王主任说,我负责的车间生产情况最好,其次是李主任负责的车间,最差的是
张主任负责的车间。
这样的比较是不是有偏比较?为什么?
解:不是,有偏比较是指将数据压缩后合起来看与分层后分开来看得出的结果不一致时所产生的偏差,而此题只是将数据压缩起来后相互间比较,因此这样的比较不是有偏比较。
具体分析如下:
由题知,分析车间主任与产品的质量情况之间的关系,则本题是以产品类别为层,以车间主任为行,产品的质量情况为列进行相关分析。
(1)数据压缩分析
首先将上表中不同产品类别的数据合并在一起压缩成二维3X2列联表2.1,
合起来看,分析车间主任与产品的质量情况两者之间的关系?
可计算出该表独立性检验的似然比检验统计量上的值为,值为
p=P( 2(2) 一48.612)。
应该拒绝原假设,即认为车间主任与产品的质量情
况两者是有一定相关性的
(2)数据分层分析
其次,按产品类别分层,得到如下三维2X 3X 2列联表2.2,分开来看,分析车间主任与产品的质量情况两者之间的关系?
在上述数据中,分别对两个产品类别(即内销和外销)进行分析,在“内 销”类别中,王姓主任车间的产品不合格率最高,即车间生产情况最差,张姓 主任车间的不合格率最低,即车间生产情况最好;在“外销”类别中,王姓主 任车间的产品不合格率最高,即车间生产情况最差,张姓和李姓主任车间生产 情况差不多。
(3) 条件独立性检验
为验证上述得出的结果是否可靠,我们可以做以下的条件独立性检验。
即由题意,可令A 表示产品类别,A i 表示内销,A 2表示外销;B 表示车间主任, B i 表示王姓主任,B 2表示张姓主任,B 3表示李姓主任;C 表示产品的质量情况, C i 表示合格产品数,C 2表示不合格产品数。
欲检验的原假设为:A 给定后B 和C
条件独立
按产品类别分层后得到的两张表格,以及它们的似然比检验统计量 -21 n 上的值
如下:
-21 n-l =15.289
A 2层
A ,层
条件独立性检验问题的似然比检验统计量是这两个似然比检验统计量的和,
-2ln 一1 =15.289 51.684 = 66.973
由于c = t = 2,r = 3,所以条件独立性检验的似然比检验统计量的渐近
2
分布的
自由度为r(c-1)(t-1^3,也就是上面这2个表格的渐近2分布的自由度的和。
由于p 值P( 2(3) _ 66.973) 很小,所以认为条件独立性不成立,即在产品类 别给定的条件下,车间主任与产品的质量情况两者是有一定相关性的。
(4) 结论
在(1)中,将不同产品类别的数据压缩在一起合起来后分析发现车间主任 与产品的质量情况两者是有一定相关性的;在(2)中,将数据以不同的产品类 别分层后分析发现车间主任与产品的质量情况两者也是有一定相关性的。
即合起
来看和分开来看的结果相同。
据我们所知,有偏比较是指将数据压缩后合起来看 与分层后分开来看得出的结果不一致时所产生的偏差,
而此题合起来看和分开来
看的结果都是相同的。
因此此题若是分析车间主任与产品的质量情况两者之间的 相关关系的话,贝U 该题是无偏的,即不均有有偏性,无法进行有偏比较。
-2l n_i =51.684
其值。