应用多元统计分析习题解答 第七章讲解学习
应用多元统计分析课后习题答案高惠璇

x1 y2 (2)第二次配方.由于 x y y 1 2 2
14
第二章
2 1 2 2 2 1 2 1 2 2
多元正态分布及参数的估计
2 x x 2 x1 x2 22x1 14x2 65 y y 22 y2 14( y1 y2 ) 65 y 14 y1 49 y 8 y2 16 ( y1 7) ( y2 4)
X 1 X 2 ~ N ( 1 2 ,2 (1 ));
2
X 1 X 2 ~ N ( 1 2 ,2 (1 )).
2
5
第二章
多元正态分布及参数的估计
1 2 , 2 1
2-3 设X(1)和X(2) 均为p维随机向量,已知
3 解三:两次配方法
2 1 2 2 2 (1)第一次配方: 2 x12 2 x1 x2 x2 ( x1 x2 ) 2 x12
2 1 x1 2 1 1 1 1 1 因2 x 2 x1 x2 x ( x1 , x2 ) , 而 BB, 1 1 x2 1 1 1 0 1 0 y1 1 1 x1 x1 x2 2 2 2 2 令y , 则 2 x 2 x x x y y 1 1 2 2 1 2 y x x 1 0 2 1 2
12
第二章
1 2
多元正态分布及参数的估计
2 1
解二:比较系数法 1 1 f ( x , x ) exp 设 ( 2 x 2 2
1 21 2
2 x2 2 x1 x2 22x1 14x2 65)
第七章 多元统计分析(1)1

Cov( Ax, By ) = ACov( x, y ) BT
二、多元正态分布 定义
若p维随机变量 x = ( x1 , x2 ,..., x p )′ 的概率密度函 维随机变量 数为
f ( x1 , x 2 , L , x p ) = 1 (2π ) | Σ |
1 n x = ∑ x(i ) n i =1 1 k nα (α ) = ∑∑ x(i ) n α =1 i =1 1 k (α ) = ∑ nα x n α =1 1 x = X ′1 n
1 n x j = ∑ xij ( j = 1,2, L, p) n i =1
1 (α ) = ∑∑ xij n α =1 i =1
为第i个 设p维随机变量 x = ( x1 , x2 ,..., x p )′ E(xi)为第 个 维随机变量 , 为第 随机变量的数学期望(或均值)( )(i=1,2,…,p),则称 随机变量的数学期望(或均值)( )
E ( x) = ( E ( x1 ), E ( x2 ),L , E ( x p ) )′ = µ ˆ
( )
nα × p
, (α = 1,2, L , k ; i = 1,2, L , nα ; j = 1,2, L , p )
常见统计量
(1)总体 (1)总体Gα的样本均值 总体 向量表示法 矩阵表示法 分量表示法
( x (α ) = ( x1(α ) , x2(α ) ,..., x pα ) )′
x
(α ) ij
个总体G 第α个总体 α的样本矩阵
( X (α ) = ( x1(α ) , x2α ) , L , x (pα ) ) (α x(′1()α ) x11 ) , (α ) (α ) x(′2 ) x21 , = = M M ( ( ) x(′nα )) xnα 1 , α α (α x12 ) , L , (α x22 ) , L ,
《应用多元统计分析》第五版PPT(第七章)-简化版(JMP13.1)

y1* 和 y2*累计贡献率3为 3
1* 2* 2.114 0.646 0.920
3
3
➢ 现比较本例中从R出发和例7.2.2中从 Σ出发的主成分
计算结果。从R出发的 y1*的贡献率0.705明显小于从Σ 出发的y1的贡献率0.938,事实上,原始变量方差之 间的差异越大,这一点也就倾向于越明显。
2
❖ 习题7.6 下表给出的是美国50个州每100 000个人中 七种犯罪的比率数据。这七种犯罪是:
x1:杀人罪
x5 :夜盗罪
x2:强奸罪
x6 :盗窃罪
x3:抢劫罪
x7 :汽车犯罪
x4:伤害罪
试图用降维的方式对50个州的犯罪情况进行比较分
析。
3
state Alabama Alaska Arizona Arkansas California Colorado Connecticut Delaware Florida Georgia Hawaii Idaho Illinois Indiana Iowa Kansas Kentucky Louisiana Maine
第七章 主成分分析
❖ §7.1 引言 ❖ §7.2 总体的主成分 ❖ §7.3 样本的主成分 ❖ §7.4 若干补充及应用中需注意的问题
1
§7.1 引言
❖ 主成分分析由皮尔逊(Pearson,1901)首先引入, 后来被霍特林(Hotelling,1933)发展了。
❖ 主成分分析是一种通过降维技术把多个变量化为少 数几个主成分(综合变量)的统计分析方法。这些 主成分能够反映原始变量的绝大部分信息,它们通 常表示为原始变量的某种线性组合,且彼此不相关。
153.5 1086.2 2498.7
《应用多元统计分析》课后习题第七章答案

《应用多元统计分析》第七章课后习题答案
P128_7.7
解:由spss软件得“方差贡献率表”如下:(此处只提取了两个公因子)
由上表可见:提取两个公因子的方差累积贡献率已达75.26%,并且题目中要求分析学生适合学文科还是理科,所以提取两个公因子是比较好的选择。
旋转后的因子载荷矩阵如下:
成份
1 2
x1 -.245 .795
x2 -.152 .698
x3 -.099 .815
x4 .867 -.335
x5 .904 -.209
x6 .953 -.072
从上述因子载荷矩阵可以看出,因子1与X4(语文),X5(历史),X6(英语)的相关性强,所以命名为“文科因子”;因子2与X1(数学),X2(物理),X3(化学)的相关性强,所以命名为“理科因子”。
P129_7.8
解:由spss软件得“方差贡献率表”如下:(由于前两个因子的累积方差贡献率已达
x8 .776 .477
x9 -.629 -.638
从上述因子载荷矩阵可以看出,因子1与X1(价格),X2(发动机),X3(功率),X8(燃料容量),X9(燃料效率)的相关性强,所以命名为“汽车价格及性能因子”;因子2与X4(轴距),X5(宽),X6(长),X7(轴距)的相关性强,所以命名为“汽车外观因子”。
从而,将题中的指标体系简化成了两个指标,即:“汽车价格及性能”和“汽车外观”。
应用多元统计第七章实验题答案
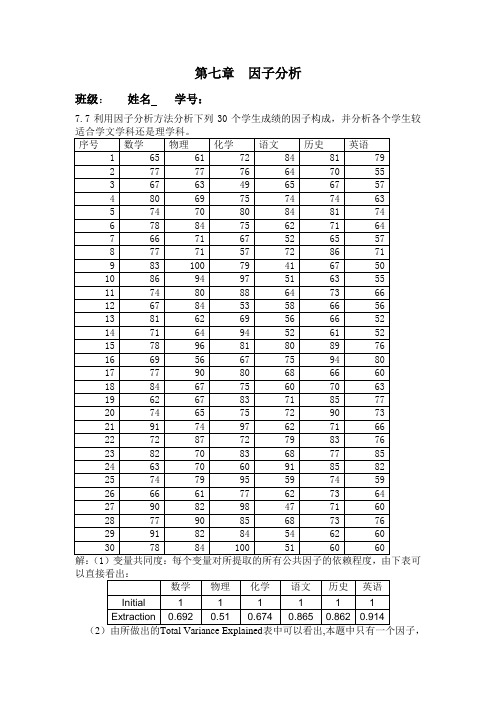
第七章因子分析班级:姓名学号:7.7利用因子分析方法分析下列30个学生成绩的因子构成,并分析各个学生较(2则由上表可写出每个原始变量的因子表达式:X1=-0.662F1+0.503F2;X2=-0.53F1+0.478F2;X6=0.816F1+0.498F2;(4)由Rotated Component Matrix表可以给出旋转后的因子载荷矩阵(见下表),第一个公共因子在指标语文、历史、英语上有较大的载荷,说明这三个指标有较强的相关性,可以归为一类,从分科情况来看,这三个指标属于学生较适合学文学科;第二个公共因子在指标为数学、物理、化学上有较大载荷,同样可以归为一类,这三个指标同属于学生较适合学理科。
(5)根据因子得分系数矩阵与原始变量的标准化值可以计算每个观测值的各F1=F2=0.439X1+0.4X2+0.484X3-0.01X4+0.073X5+0.169X6;则将学生成绩按顺序对应分别带入上面两个式子可以判定,当F1>F2时,该学生适合学文科,当F1<F2时,该学生适合学理科。
24、26的学生适合学文科;学生标号为:2、6、7、9、10、11、13、14、17、18、21、25、27、28、29、30的学生适合学理科。
7.8某汽车组织欲根据一系列指标来预测汽车的销售情况,为了避免有些指标之间的相关关系影响预测结果,须首先进行因子分析来简化系统。
下表是抽查欧洲某汽车市场7个品牌不同型号的汽车的各种指标数据,试用因子分析法找出其简X1=0.794F1;X2=0.879F1;X9=-0.893F1;(4)因为只有一个因子,因此不能被旋转。
(5)根据因子得分系数矩阵与原始变量的标准化值可以计算每个观测值的各因子的得分数,则根据下表可得出该题中的因子得分表达式即为所求的指标系统为:27X8-0.132X9。
7.10 根据习题5.11中2003年我国省会城市和计划单列城市的主要经济指标数据,利用因子分析法对其进行排序和分类,并与聚类分析的结果进行比较。
多元统计分析第七章主成分分析习题答案

7.1 设随机变量12X(X ,X )'=的协差阵为21,12⎡⎤∑=⎢⎥⎣⎦试求X的特征根和特征向量,并写出主成分。
解:先求X的特征根λ,λ满足方程:21012-λ=-λ,即2(2)10-λ-=,因此两个特征根分别为123, 1.λ=λ=设13λ=对应的单位特征向量为()1121a ,a ',则()1121a ,a '满足:1121a 110a 110-⎛⎫⎡⎤⎛⎫= ⎪ ⎪⎢⎥-⎣⎦⎝⎭⎝⎭,故可以取1121a a ⎛⎛⎫ = ⎪ ⎝⎭ ⎝,其对应主成分为:112F X X 22=+;设21λ=对应的单位特征向量为()1222a ,a ',则()1222a ,a '满足:1222a 110a 110⎛⎫⎡⎤⎛⎫=⎪ ⎪⎢⎥⎣⎦⎝⎭⎝⎭,故可以取1222a a ⎛⎫⎛⎫ ⎪= ⎪ ⎝⎭- ⎝,其对应的主成分为:212F 22=-.7.2设随机变量123X (X ,X ,X )'=的协差阵为120250,002-⎡⎤⎢⎥∑=-⎢⎥⎢⎥⎣⎦试求X的主成分及主成分对变量X的贡献率。
解:先求X的特征根λ,λ满足方程:12025002-λ---λ=-λ,即()2(2)610-λλ-λ+=,因此三个特征根分别为1235.8284,2,0.1716λ=λ=λ=设1 5.8284λ=对应的单位特征向量为()112131a ,a ,a ',则它满足:1121314.828420a 020.82840a 000 3.8284a 0--⎡⎤⎛⎫⎛⎫⎪ ⎪⎢⎥--=⎪ ⎪⎢⎥ ⎪ ⎪⎢⎥-⎣⎦⎝⎭⎝⎭,故可以取 112131a 10.38271a 2.41420.92392.6131a 00⎛⎫⎛⎫⎛⎫⎪ ⎪ ⎪=-=- ⎪ ⎪ ⎪ ⎪ ⎪ ⎪⎝⎭⎝⎭⎝⎭,其对应主成分为: 112F 0.3827X 0.9239X =-,其贡献率为5.828472.86%5.828420.1716=++;设22λ=对应的单位特征向量为()122232a,a ,a ',则它满足:122232120a 0230a 0000a 0--⎡⎤⎛⎫⎛⎫ ⎪ ⎪⎢⎥-= ⎪ ⎪⎢⎥ ⎪ ⎪⎢⎥⎣⎦⎝⎭⎝⎭,故可以取122232a 0a 0a 1⎛⎫⎛⎫⎪ ⎪= ⎪ ⎪ ⎪ ⎪⎝⎭⎝⎭,其对应主成分为: 23F X =,其贡献率为225%5.828420.1716=++;设30.1716λ=对应的单位特征向量为()132333a ,a ,a ',则它满足:1323330.828420a 02 4.82840a 000 1.8284a 0-⎡⎤⎛⎫⎛⎫⎪ ⎪⎢⎥-=⎪ ⎪⎢⎥ ⎪ ⎪⎢⎥⎣⎦⎝⎭⎝⎭,故可以取132333a 10.92391a 0.41420.38271.0824a 00⎛⎫⎛⎫⎛⎫⎪ ⎪ ⎪== ⎪ ⎪ ⎪ ⎪ ⎪ ⎪⎝⎭⎝⎭⎝⎭,其对应主成分为: 312F 0.9239X 0.3827X =+,其贡献率为0.17162.14%5.828420.1716=++.7.3 设随机变量12X (X ,X )'=的协差阵为14,4100⎡⎤∑=⎢⎥⎣⎦试从∑和相关阵R出发求出总体主成分,并加以比较。
最新应用多元统计分析课后习题答案高惠璇PPT课件
(2) 考虑随机变量Y= X1-X2 ,显然有
YX 1X2 0 X 1X 1,当 估计
P{Y0}P{X11或 X11} P{X11}P{X11} (X1~N(0,1)) 2(1)0.317 04
若(X1 , X2 ) 是二元正态分布,则由性质4可知,
31
第三章 多元正态总体参数的检验
证明 记rk(A)=r.
若r=n,由AB=O,知B= On×n,于是 X′AX与X′BX
若r=0时,则A=0,则两个二次型也是独 立的.
以下设0<r<n.因A为n阶对称阵,存在正 交阵Γ,使得
32
第三章 多元正态总体参数的检验
其中λi≠0为A的特征值(i=1,…,r).于是
P { X 2 x } P { X 1 x } ( x )
当x≥1时, P{X2x}
P{X2 1}P{1X2 1}P{1X2 x}
P{X11}P{1X11}P{1X1x}
P{X1x}(x) 17
第二章 多元正态分布及参数的估计
当-1≤x≤1时,
P{X2 x}P{X2 1}P{1X2 x} P{X1 1}P{xX1 1} P{X1 1}P{1X1 x} P{X1 x}(x)
它的任意线性组合必为一元正态. 但Y= X1-X2 不是正态分布,故(X1 , X2 ) 不是二元正态分布.
19
第二章 多元正态分布及参数的估计
2-17 设X~Np(μ,Σ),Σ>0,X的密度函数记为 f(x;μ,Σ).(1)任给a>0,试证明概率密度等高面
f(x;μ,Σ)= a
是一个椭球面. (2) 当p=2且
比较上下式相应的系数,可得:
1
2 2
2
1 2
应用多元统计分析习题解答_因子分析
第七章 因子分析7.1 试述因子分析与主成分分析的联系与区别。
答:因子分析与主成分分析的联系是:①两种分析方法都是一种降维、简化数据的技术。
②两种分析的求解过程是类似的,都是从一个协方差阵出发,利用特征值、特征向量求解。
因子分析可以说是主成分分析的姐妹篇,将主成分分析向前推进一步便导致因子分析。
因子分析也可以说成是主成分分析的逆问题。
如果说主成分分析是将原指标综合、归纳,那么因子分析可以说是将原指标给予分解、演绎。
因子分析与主成分分析的主要区别是:主成分分析本质上是一种线性变换,将原始坐标变换到变异程度大的方向上为止,突出数据变异的方向,归纳重要信息。
而因子分析是从显在变量去提炼潜在因子的过程。
此外,主成分分析不需要构造分析模型而因子分析要构造因子模型。
7.2 因子分析主要可应用于哪些方面?答:因子分析是一种通过显在变量测评潜在变量,通过具体指标测评抽象因子的统计分析方法。
目前因子分析在心理学、社会学、经济学等学科中都有重要的应用。
具体来说,①因子分析可以用于分类。
如用考试分数将学生的学习状况予以分类;用空气中各种成分的比例对空气的优劣予以分类等等②因子分析可以用于探索潜在因素。
即是探索未能观察的或不能观测的的潜在因素是什么,起的作用如何等。
对我们进一步研究与探讨指示方向。
在社会调查分析中十分常用。
③因子分析的另一个作用是用于时空分解。
如研究几个不同地点的不同日期的气象状况,就用因子分析将时间因素引起的变化和空间因素引起的变化分离开来从而判断各自的影响和变化规律。
7.3 简述因子模型中载荷矩阵A 的统计意义。
答:对于因子模型1122i i i ij j im m i X a F a F a F a F ε=++++++ 1,2,,i p =因子载荷阵为11121212221212(,,,)m m m p p pm a a a a a a A A A a a a ⎡⎤⎢⎥⎢⎥==⎢⎥⎢⎥⎢⎥⎣⎦Ai X 与j F 的协方差为:1Cov(,)Cov(,)mi j ik k i j k X F a F F ε==+∑=1Cov(,)Cov(,)mikk j i j k aF F F ε=+∑=ij a若对i X 作标准化处理,=ij a ,因此 ij a 一方面表示i X 对j F 的依赖程度;另一方面也反映了变量iX对公共因子jF的相对重要性。
应用多元统计分析课后习题答案高惠璇第七章习题解答-20页PPT精选文档
解:
9
第七章 主成分分析
7-5 设3维总体X的协差阵为
试求总体主成分.
4 0 0
0 4 0
0 0 2
解:总体主成分为
Zi Xi(i1,2,3)
主成分向量为
Z ( X 1 ,X 2 ,X 3 ) 或 Z ( X 2 ,X 1 ,X 3 )
三个主成分的方差分别为4,4,2.
(01).
(1)
Z1 1p(X1X2Xp);
(2) 试求第一主成分的贡献率.
7
第七章 主成分分析
解:
1
8
第七章 主成分分析
7-4 设总体X=(X1,…,Xp)′~Np(μ,Σ) (Σ>0),等概率密度
椭球为
(X-μ)′Σ-1(X-μ)=C2(C为常数).
试问椭球的主轴方向是什么?
14 13
13 14 2
12
14
13
12 2
,
其中 1 21 31,421 4 21.3
试求X的主成分.
12
第七章 主成分分析
解:
13
第七章 主成分分析
7-8
14
第七章 主成分分析
15
第七章 主成分分析
7-9
16
其中ρ为X1和X2的相关系数(ρ>0). (1) 试从Σ出发求X
1
1
(2) 求X
(3) 试问当ρ取多大时才能使第一主成分的贡献率达95%以上.
解:
5
第七章 主成分分析
6
第七章 主成分分析
7-3 设p维总体X的协差阵为
21
1
应用多元统计分析习题解答_因子分析
第七章 因子分析7.1 试述因子分析与主成分分析的联系与区别。
答:因子分析与主成分分析的联系是:①两种分析方法都是一种降维、简化数据的技术。
②两种分析的求解过程是类似的,都是从一个协方差阵出发,利用特征值、特征向量求解。
因子分析可以说是主成分分析的姐妹篇,将主成分分析向前推进一步便导致因子分析。
因子分析也可以说成是主成分分析的逆问题。
如果说主成分分析是将原指标综合、归纳,那么因子分析可以说是将原指标给予分解、演绎。
因子分析与主成分分析的主要区别是:主成分分析本质上是一种线性变换,将原始坐标变换到变异程度大的方向上为止,突出数据变异的方向,归纳重要信息。
而因子分析是从显在变量去提炼潜在因子的过程。
此外,主成分分析不需要构造分析模型而因子分析要构造因子模型。
7.2 因子分析主要可应用于哪些方面? 答:因子分析是一种通过显在变量测评潜在变量,通过具体指标测评抽象因子的统计分析方法。
目前因子分析在心理学、社会学、经济学等学科中都有重要的应用。
具体来说,①因子分析可以用于分类。
如用考试分数将学生的学习状况予以分类;用空气中各种成分的比例对空气的优劣予以分类等等②因子分析可以用于探索潜在因素。
即是探索未能观察的或不能观测的的潜在因素是什么,起的作用如何等。
对我们进一步研究与探讨指示方向。
在社会调查分析中十分常用。
③因子分析的另一个作用是用于时空分解。
如研究几个不同地点的不同日期的气象状况,就用因子分析将时间因素引起的变化和空间因素引起的变化分离开来从而判断各自的影响和变化规律。
7.3 简述因子模型中载荷矩阵A 的统计意义。
答:对于因子模型1122i i i ij j im m i X a F a F a F a F ε=++++++ 1,2,,i p =因子载荷阵为11121212221212(,,,)m m m p p pm a a a a a a A A A a a a ⎡⎤⎢⎥⎢⎥==⎢⎥⎢⎥⎢⎥⎣⎦Ai X 与j F 的协方差为:1Cov(,)Cov(,)mi j ik k i j k X F a F F ε==+∑=1Cov(,)Cov(,)mikk j i j k aF F F ε=+∑=ij a若对i X 作标准化处理,=ij a ,因此 ij a 一方面表示i X 对j F 的依赖程度;另一方面也反映了变量iX 对公共因子jF 的相对重要性。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
应用多元统计分析习题解答第七章第七章 因子分析7.1 试述因子分析与主成分分析的联系与区别。
答:因子分析与主成分分析的联系是:①两种分析方法都是一种降维、简化数据的技术。
②两种分析的求解过程是类似的,都是从一个协方差阵出发,利用特征值、特征向量求解。
因子分析可以说是主成分分析的姐妹篇,将主成分分析向前推进一步便导致因子分析。
因子分析也可以说成是主成分分析的逆问题。
如果说主成分分析是将原指标综合、归纳,那么因子分析可以说是将原指标给予分解、演绎。
因子分析与主成分分析的主要区别是:主成分分析本质上是一种线性变换,将原始坐标变换到变异程度大的方向上为止,突出数据变异的方向,归纳重要信息。
而因子分析是从显在变量去提炼潜在因子的过程。
此外,主成分分析不需要构造分析模型而因子分析要构造因子模型。
7.2 因子分析主要可应用于哪些方面?答:因子分析是一种通过显在变量测评潜在变量,通过具体指标测评抽象因子的统计分析方法。
目前因子分析在心理学、社会学、经济学等学科中都有重要的应用。
具体来说,①因子分析可以用于分类。
如用考试分数将学生的学习状况予以分类;用空气中各种成分的比例对空气的优劣予以分类等等②因子分析可以用于探索潜在因素。
即是探索未能观察的或不能观测的的潜在因素是什么,起的作用如何等。
对我们进一步研究与探讨指示方向。
在社会调查分析中十分常用。
③因子分析的另一个作用是用于时空分解。
如研究几个不同地点的不同日期的气象状况,就用因子分析将时间因素引起的变化和空间因素引起的变化分离开来从而判断各自的影响和变化规律。
7.3 简述因子模型中载荷矩阵A 的统计意义。
答:对于因子模型1122i i i ij j im m i X a F a F a F a F ε=++++++ 1,2,,i p =因子载荷阵为11121212221212(,,,)m m m p p pm a a a aa a A A A a a a ⎡⎤⎢⎥⎢⎥==⎢⎥⎢⎥⎢⎥⎣⎦Ai X 与j F 的协方差为:1Cov(,)Cov(,)mi j ik k i j k X F a F F ε==+∑=1Cov(,)Cov(,)mik k j i j k a F F F ε=+∑=ij a若对iX作标准化处理,=ija,因此ija一方面表示iX对jF的依赖程度;另一方面也反映了变量i X对公共因子jF的相对重要性。
变量共同度2211,2,,mi ijjh a i p===∑2221122()()()()()i i i im m iD X a D F a D F a D F Dε=++++22i ihσ=+说明变量iX的方差由两部分组成:第一部分为共同度2ih,它描述了全部公共因子对变量iX的总方差所作的贡献,反映了公共因子对变量iX的影响程度。
第二部分为特殊因子iε对变量iX的方差的贡献,通常称为个性方差。
而公共因子jF对X的贡献2211,2,,pj ijig a j m===∑表示同一公共因子jF对各变量所提供的方差贡献之总和,它是衡量每一个公共因子相对重要性的一个尺度。
7.4 在进行因子分析时,为什么要进行因子旋转?最大方差因子旋转的基本思路是什么?答:因子分析的目标之一就是要对所提取的抽象因子的实际含义进行合理解释。
但有时直接根据特征根、特征向量求得的因子载荷阵难以看出公共因子的含义。
这种因子模型反而是不利于突出主要矛盾和矛盾的主要方面的,也很难对因子的实际背景进行合理的解释。
这时需要通过因子旋转的方法,使每个变量仅在一个公共因子上有较大的载荷,而在其余的公共因子上的载荷比较小。
最大方差旋转法是一种正交旋转的方法,其基本思路为:①A其中令***(),/ij p m ij ij ia d a h⨯===A AΓ211pj ijid dp==∑*A的第j列元素平方的相对方差可定义为2211()pj ij jiV d dp==-∑②12mV V V V=+++最大方差旋转法就是选择正交矩阵Γ,使得矩阵*A所有m个列元素平方的相对方差之和达到最大。
7.5 试分析因子分析模型与线性回归模型的区别与联系。
答:因子分析模型是一种通过显在变量测评潜在变量,通过具体指标测评抽象因子的统计分析方法的模型。
而线性回归模型回归分析的目的是设法找出变量间的依存(数量)关系, 用函数关系式表达出来。
因子分析模型中每一个变量都可以表示成公共因子的线性函数与特殊因子之和。
即1122i i i im m iX a F a F a Fε=++++,(1,2,,i p=)该模型可用矩阵表示为:=+X AFε而回归分析模型中多元线性回归方程模型为:其中是常数项,是偏回归系数,是残差。
因子模型满足:(1)m p≤;(2)(,)0Cov=F ε,即公共因子与特殊因子是不相关的;(3)101()01F mD⎡⎤⎢⎥⎢⎥===⎢⎥⎢⎥⎣⎦D F I,即各个公共因子不相关且方差为1;(4)21222()pDεσσσ⎡⎤⎢⎥⎢⎥==⎢⎥⎢⎥⎢⎥⎣⎦Dε,即各个特殊因子不相关,方差不要求相等。
而回归分析模型满足(1)正态性:随机误差(即残差)e服从均值为 0,方差为σ2的正态分布;(2)等方差:对于所有的自变量x,残差e的条件方差为σ2,且σ为常数;(3)独立性:在给定自变量x的条件下,残差e的条件期望值为0(本假设又称零均值假设);(4)无自相关性:各随机误差项e互不相关。
两种模型的联系在于都是线性的。
因子分析的过程就是一种线性变换。
7.6 设某客观现象可用X=()’来描述,在因子分析时,从约相关阵出发计算出特征值为由于,所以找前两个特征值所对应的公共因子即可,又知对应的正则化特征向量分别为(0.707,-0.316,0.632)’及(0,0.899,0.4470)’,要求:(1)计算因子载荷矩阵A,并建立因子模型。
(2)计算共同度。
(3)计算第一公因子对X的“贡献”。
解:(1)根据题意,A==建立因子模型为(2)(3)因为是从约相关阵计算的特征值,所以公共因子对X的“贡献”为。
7.7 利用因子分析方法分析下列30个学生成绩的因子构成,并分析各个学生较适合学文科序号数学物理化学语文历史英语1 65 61 72 84 81 792 77 77 76 64 70 553 67 63 49 65 67 574 80 69 75 74 74 635 74 70 80 84 81 746 78 84 75 62 71 647 66 71 67 52 65 578 77 71 57 72 86 719 83 100 79 41 67 5010 86 94 97 51 63 5511 74 80 88 64 73 6612 67 84 53 58 66 5613 81 62 69 56 66 5214 71 64 94 52 61 5215 78 96 81 80 89 7616 69 56 67 75 94 8017 77 90 80 68 66 6018 84 67 75 60 70 6319 62 67 83 71 85 7720 74 65 75 72 90 7321 91 74 97 62 71 6622 72 87 72 79 83 7623 82 70 83 68 77 8524 63 70 60 91 85 8225 74 79 95 59 74 5926 66 61 77 62 73 6427 90 82 98 47 71 6028 77 90 85 68 73 7629 91 82 84 54 62 6030 78 84 100 51 60 60X5,英语为1234X1,用spss分析学生成绩的因子构成的步骤如下:1. 在SPSS窗口中选择Analyze→Data Reduction→Factor,调出因子分析主界面,并将六个变量移入Variables框中。
图7.1 因子分析主界面2. 点击Descriptives按钮,展开相应对话框,见图7.2。
选择Initial solution复选项。
这个选项给出各因子的特征值、各因子特征值占总方差的百分比以及累计百分比。
单击Continue按钮,返回主界面。
图7.2 Descriptives子对话框3. 点击Extraction按钮,设置因子提取的选项,见图7.3。
在Method下拉列表中选择因子提取的方法,SPSS提供了七种提取方法可供选择,一般选择默认选项,即“主成分法”。
在Analyze栏中指定用于提取因子的分析矩阵,分别为相关矩阵和协方差矩阵。
在Display栏中指定与因子提取有关的输出项,如未旋转的因子载荷阵和因子的碎石图。
在Extract栏中指定因子提取的数目,有两种设置方法:一种是在Eigenvalues over后的框中设置提取的因子对应的特征值的范围,系统默认值为1,即要求提取那些特征值大于1的因子;第二种设置方法是直接在Number of factors后的矩形框中输入要求提取的公因子的数目。
这里我们均选择系统默认选项,单击Continue按钮,返回主界面。
图7.3 Extraction子对话框4.点击Rotation按钮,设置因子旋转的方法。
这里选择Varimax(方差最大旋转),并选择Display栏中的Rotated solution复选框,在输出窗口中显示旋转后的因子载荷阵。
单击Continue按钮,返回主界面。
图7.4 Rotation子对话框5.点击Scores按钮,设置因子得分的选项。
选中Save as variables复选框,将因子得分作为新变量保存在数据文件中。
选中Display factor score coefficient matrix复选框,这样在结果输出窗口中会给出因子得分系数矩阵。
单击Continue按钮返回主界面。
图7.5 Scores子对话框6. 单击OK按钮,运行因子分析过程。
结果分析:表7.1 旋转前因子载荷阵表7.2 旋转后因子载荷阵成份矩阵a成份1 2x1 -.662 .503x2 -.530 .478x3 -.555 .605x4 .900 .233从表7.1中可以看出,每个因子在不同原始变量上的载荷没有明显的差别,为了便于对因子进行命名,需要对因子载荷阵进行旋转,得表7.2。
经过旋转后的载荷系数已经明显地两极分化了。
第一个公共因子在后三个指标上有较大载荷,说明这三个指标有较强的相关性,可以归为一类,属于文科学习能力的指标;第二个公共因子在前三个指标上有较大载荷,同样可以归为一类,这三个指标同属于理科学习能力的指标。
根据表7.3易得:6432.05378.04332.03137.02085.01064.01XXXXXXF+++++=6169.05073.04014.03484.02400.01439.02XXXXXXF+++++=表7.3 因子得分系数矩阵将每个学生的六门成绩分别代入F1、F2,比较两者的大小,F1大的适合学文,F2大的适合学理。