自上而下语法分析器设计习题1
习题与答案-5-语法分析-自上而下
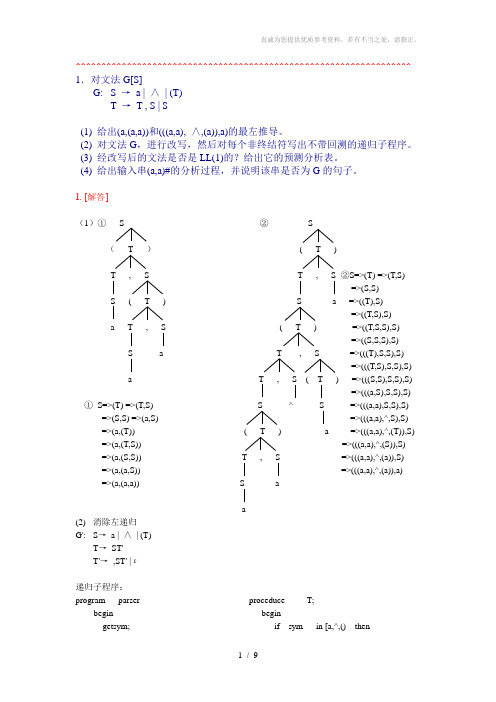
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ 1.对文法G[S]G: S →a | ∧| (T)T →T , S | S(1) 给出(a,(a,a))和(((a,a), ∧,(a)),a)的最左推导。
(2) 对文法G,进行改写,然后对每个非终结符写出不带回溯的递归子程序。
(3) 经改写后的文法是否是LL(1)的?给出它的预测分析表。
(4) 给出输入串(a,a)#的分析过程,并说明该串是否为G的句子。
1. [解答](1)①S ②S(T )( T )T , S T , S ②S=>(T) =>(T,S)=>(S,S) S ( T ) S a =>((T),S)=>((T,S),S)a T , S ( T ) =>((T,S,S),S)=>((S,S,S),S) S a T , S =>(((T),S,S),S)=>(((T,S),S,S),S)a T , S ( T ) =>(((S,S),S,S),S)=>(((a,S),S,S),S) ①S=>(T) =>(T,S) S ^ S =>(((a,a),S,S),S)=>(S,S) =>(a,S) =>(((a,a),^,S),S) =>(a,(T)) ( T ) a =>(((a,a),^,(T)),S) =>(a,(T,S)) =>(((a,a),^,(S)),S)=>(a,(S,S)) T , S =>(((a,a),^,(a)),S)=>(a,(a,S)) =>(((a,a),^,(a)),a)=>(a,(a,a)) S aa(2) 消除左递归G': S→a | ∧| (T)T→ST'T'→,ST' |ε递归子程序:program parser proceduce T;begin begingetsym; if sym in [a,^,() thenS beginend; S;proceduce S; T;begin end;if sym=’a’ or sym=’^’ then elsegetsym error;elseif sym=’(‘ end;begin getsym; proceduce T’;T; beginIf sym=’)’ then if sym=’,’ thenGetsym; beginElse getsym;Error; S;End; T;Else end;Error; elseEnd; if sym=’)’ thenelseerror;end;预测分析表不含多重定义入口, 所以该文法是LL(1)文法!(4) 分析栈余留串所用产生式或动作1 #S (a,a)# S—>(T)2 #)T( (a,a)# (匹配3 #)T a,a)# T—>ST’4 #)T’S a,a)# S—>a5 #)T’a a,a)# a匹配6 #)T’ ,a)# T’ —>,ST’7 #)T’S, ,a)# ,匹配8 #)T’S a)# S—>a9 #)T’a a)# a匹配10 #)T’ )# T’—>ε11 #) )# )匹配12 # # 接受因为(a,a)#分析成功所以(a,a)为文法的句子步骤分析栈余留串所用产生式或动作1 #S (a,a# S→(T)2 #)T( (a,a# ( 匹配3 #)T a,a# T→ST’4 #)T’S a,a# S→a5 #)T’a a,a# a 匹配6 #)T’,a# T’→,ST’7 #)T’S, ,a# , 匹配8 #)T’S a# S→a9 #)T’a a# a 匹配10 #)T’# 出错^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ 2. G: E →TE'E' →+E |εT →FT'T' →T |εF →PF'F' →*F' |εP →(E) | a | b |∧预测分析表^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ 3.已知文法G: S →MH | aH →LSo |εK →dML |εL →eHfM →K | bLM判断G是否是LL(1)文法,如果时,构造LL(1)分析表。
第四章语法分析-自上而下分析

n
N T * T,则aFIRST(X)。
T
,则 FIRST(X)={X}。 ,且有产生式Xa,aV
N
1 2 i VN , 而有产生式X Y1 ,,Yn 。当Y1 ,Y2 ,,Yi-1 都 时,(其中 1≤i≤n),则FIRST(Y1 ,)-{},,FIRFIRST(Yj )包含把加到
FOLLOW(T)= FOLLOW(T)= #,),+ FOLLOW(F)= #,),+,* 七、证明上述文法是否为LL(1)文法 对于产生式A: 1、若 ,证明侯选式,的首字符集是否相交。 FIRST()∩FIRST()= Ф 例:F(E)i FIRST(()∩FIRST(i)= Ф 2、若=ε,证明FIRST(A)和FOLLOW(A)是否相交。 FIRST(A)∩FOLLOW(A)=φ 例:E`+TE` FIRST(E`)∩FOLLOW(E`) = +, ∩ ),# =φ 八、构造分析表的算法 1、对文法G的每个产生式A→α执行第二步和第三步; 2、对每个终结符aFIRST(),把A→α加至M[A,a]中; 3、若εFIRST(α),则对任何bFOLLOW(A)把A→α(或A)加至 M[A,b]中; 4、把所有无定义的M[A,a]标上“出错标志” 例: E→TE` , E`→+TE`´|ε T→FT` , T`→*FT`´|ε F→(E)|i 求其FIRST的集合: FIRST(E)=FIRST(T)=FIRST(F)={(,i )} FIRST(E)={ +,ε},FIRST(T)={ *,ε} 求其FOLLOW的集合: FOLLOW(E)= FOLLOW(E)= #,) FOLLOW(T)= FOLLOW(T)= #,),+ FOLLOW(F)= #,),+,* 根据算法构造LL(1)的分析表:
第四章 编译原理语法分析--自上而下

消除左递归 (P69.)
(1)直接左递归:文法存在产生式 A→Aα。 (2)间接左递归:文法不存在产生式 A→Aα, 但存在推导 A + Aα。
消除直接左递归的方法:引入新的非终结符号A‘,将 关于A的如下产生式 A→Aα|β (α非ε且β不以A打头) 替换为 A →βA‘ A‘ →αA‘|ε 注意:不要掉了 A‘ →ε
4
自上而下分析法的思想(P66.)
从文法的开始符号出发,逐步向下推导,不断替换和展开非 终结符,去匹配输入符号串(终结符号串、句子),即寻找输入 串的最左推导,推出句子,(---自上而下的实质) 并按与最左推导相对应的顺序,从文法的开始符号(根结)出 发,自上而下从左到右地建立输入串的语法分析树。---其末 端节点正好与输入符号串相同
3
4.2 自上而下分析法面临的问题
. 本小节首先通过例子P67:
说明自上而下分析的思想 认识自上而下分析时所遇到的主要困难
自上而下分析的主要困难是P66-68 : 文法的左递归性,可能使分析陷入无限循环 回溯的不确定性,要求将已完成的工作推倒重来 为解决这些问题,使得自上而下分析是确定的,考 虑要消除文法左递归和避免回溯。 最后构造确定的有效的自上而下分析器:递归下降 分析器
2
4.1 语法分析器的功能(P66.)
语法分析是编译程序的核心部分。
语法分析是在词法分析识别出单词符号的基础上, 分析并判定(即识别)一串单词符号(称为输入串) 的语法结构是否符合语法规则,是否是文法的一个 句子。
分析判定的方法:
建立输入串α的从文法开始符号S出发的推导 S α1 … αn α 即建立以开始符号S为根的与输入串α相匹配(即α 中的各个符号为叶结点)的语法树
04 语法分析-自上而下分析

待分析的输入串: 待分析的输入串:i+i
只有当a 只有当a是允许出 现在非终结符A 现在非终结符A后 面的终结符时, 面的终结符时, 才可能允许A 才可能允许A自动 匹配。 匹配。
尾随集的定义: VN尾随集的定义:
=*>…Aa Aa…, FOLLOW(A)={a|S =*> Aa , a∈VT}; 特别地,如果S=*> S=*>…A 那么# FOLLOW(A)。 特别地,如果S=*> A,那么# ∈FOLLOW(A)。
例子
文法: S→xAy A→**|* 文法: 输入串:x*y 输入串: S => => => => xAy x**y xAy x*y (S→ xAy) (A→**) 回溯) (回溯) (A→*)
带回溯自上而下分析面临的问题
问题: 问题: 文法的左递归问题 回溯问题 虚假匹配问题 出错位置不确定 低效
实现思想: 实现思想:
分析程序由一组递归过程组成。 分析程序由一组递归过程组成。每一过程 对应于一个非终结符号。 对应于一个非终结符号。 每一个过程的功能是:选择正确的右部。 每一个过程的功能是:选择正确的右部。 在右部中有非终结符号时, 在右部中有非终结符号时,调用该非终结 符号对应的过程。 符号对应的过程。
消除文法的左递归
文法不含回路(形如P=+> P推导 推导) 文法不含回路(形如P=+> P推导) 不含回路 前提: 前提: 不含以ε 也不含以ε 为右部的产生式 结论: 那么可以通过执行消除文法左递 结论: 那么可以通过执行消除文法左递 归的算法消除文法的一切左递归 归的算法消除文法的一切左递归 改写后的文法可能含有以ε (改写后的文法可能含有以ε 为右部的产生式)。 为右部的产生式)。
实验5---语法分析器(自下而上):LR(1)分析法

实验5---语法分析器(自下而上):LR(1)分析法一、实验目的构造LR(1)分析程序,利用它进行语法分析,判断给出的符号串是否为该文法识别的句子,了解LR(K)分析方法是严格的从左向右扫描,和自底向上的语法分析方法。
二、实验内容程序输入/输出示例(以下仅供参考):对下列文法,用LR(1)分析法对任意输入的符号串进行分析:(1)E->E+T(2)E->E—T(3)T->T*F(4)T->T/F(5)F-> (E)(6)F->i输出的格式如下:(1)LR(1)分析程序,编制人:姓名,学号,班级(2)输入一个以#结束的符号串(包括+—*/()i#):在此位置输入符号串(3)输出过程如下:3.对学有余力的同学,测试用的表达式事先放在文本文件中,一行存放一个表达式,同时以分号分割。
同时将预期的输出结果写在另一个文本文件中,以便和输出进行对照。
三、实验方法1.实验采用C++程序语言进行设计,文法写入程序中,用户可以自定义输入语句;2.实验开发工具为DEV C++。
四、实验步骤1.定义LR(1)分析法实验设计思想及算法①若ACTION[sm , ai] = s则将s移进状态栈,并把输入符号加入符号栈,则三元式变成为:(s0s1…sm s , #X1X2…Xm ai , ai+1…an#);②若ACTION[sm , ai] = rj则将第j个产生式A->β进行归约。
此时三元式变为(s0s1…sm-r s , #X1X2…Xm-rA , aiai+1…an#);③若ACTION[sm , ai]为“接收”,则三元式不再变化,变化过程终止,宣布分析成功;④若ACTION[sm , ai]为“报错”,则三元式的变化过程终止,报告错误。
2.定义语法构造的代码,与主代码分离,写为头文件LR.h。
3.编写主程序利用上文描述算法实现本实验要求。
五、实验结果1. 实验文法为程序既定的文法,写在头文件LR.h中,运行程序,用户可以自由输入测试语句。
编译原理第4章语法分析自上而下

(e) 当(d)中所有Yi * ε,(i=1,2,…n),则 FIRST(X)=FIRST(Y1)∪FIRST(Y2)∪…∪FIRST(Yn)∪{ε}
一 . 自上而下语法分析方法
给定文法G和源程序串$。从G的开始符 号S出发,通过反复使用产生式对句型中的 非终结符进行替换(推导),逐步推导出$ 。
是一种产生的方法,面向目标的方法。 分析的主旨是选择产生式的合适的侯选 式进行推导,逐步使推导结果与$匹配。
Ch4 语法分析 4.1 语法分析程序综述 4.1.2 语法分析的方法
计算Select集:
B ε | aD C AD | b
每个产生式的Select集合计算为:D aS | c
Select(SAB)= (first (AB) -{ε}) ∪Follow(S)={b,a,#}
Select(S bC)= first (bC)={b}
因为A B
Select(Aε)=(first (ε) -{}) ∪Follow (A)={c,a,#}
A ε | b B ε | aD C AD | b D aS | c
first(C)={first(A)-{}} ∪first(D) ∪first(b)={a,b, c}
first(D)={a} ∪{c}={a,c}
➢求出每个文法符号的FIRST集合后也就不难求出一个符号 串的FIRST集合
✓若符号串α∈V*,α=X1 X2 … Xn,当X1不能
∪{ε}
ε*,则置 ∈
自上而下语法分析方法-第四章(1)

练习:求给定文法的每个候选式的First
集
SAp SBq Aa AcA Bb BdB
解:
First(S1) = First(Ap) ={ a,c } First(S2) = First(Bq)={b,d } First(A1) = {a} First(A2) = {c} First(B1) = {b} First(B2) = {d}
• 语法分析器的输出
– 分析树:表示方法? 见教材 P89 – 错误处理信息:定位、继续编译
• 语法分析器的功能
– 按照语言的语法构成规则, 识别输入的符号 串能否构成一个句子。这些规则是用文法的 产生式来定义的。
• 问题
– 对给定的一个输入串,如何判定它是不是一 个句子?
• 方法
– 根据文法的产生式规则,从开始符号出发, 看能否推导出与这个输入串匹配的句子。这 就需要建立与输入串匹配的语法分析树。
求某一非终结符A的首终结符集First(A)的算法为:
• 1.若有产生式Aaα,a∈VT,把a加到First(A)中; • 2.若有产生式Aε, 把ε加到First(A)中;
• 3.若有产生式AXα,X∈VN,把First(X)中非ε元素 加到First(A)中;
• 4.若有产生式AX*1X2X3...Xkα,其中X1X2...Xk∈VN。则 –当X1X2X3...Xi =>ε(1≤i≤k)时,把 First(Xi+1...Xkα)的非ε元素加到 First(A)中; –当X1X2X3...Xk=*>ε时,把First(α)加入First(A)中
• 在右边给定的文法中,A 的候选式有两个,其首终 结符集为:
First(A1) = {*} First(A2) = {*}
编译原理-自上而下的语法分析

高效性
由于从文法的最顶端开始分析, 一旦发现不匹配,就可以立即终 止当前分支的搜索,避免不必要 的计算,提高了编译器的效率。
易于处理左递归文
法
自上而下的分析方法可以很方便 地处理含有左递归的文法,而左 递归是许多实际编程语言的重要 特征。
局限性
无法处理左边界问题
自上而下的分析方法在处理某些含有左边界的文法时可能 会遇到问题,因为这种方法会优先匹配最左边的符号,而 左边界问题需要从右往左匹配符号。
案例三
在编译器优化中,自上而下的语法分析被用 于识别和修改源代码中的冗余和低效的语法 成分。例如,在C编译器的实现中,自上而 下的语法分析可以用于优化循环结构,减少 不必要的循环次数,提高程序的执行效率。
自上而下的语法分析还可以用于代码生成和 代码生成器的实现。通过识别和解析源代码 中的语法成分,可以生成更高效、更安全的 机器代码或字节码,提高程序的执行效率和
安全性。
THANKS
感谢观看
详细描述:递归下降分析算法易于理解,每个产生式规 则对应一个函数,函数的实现相对简单明了。
详细描述:对于每个产生式规则,需要编写相应的递归 函数,可能会导致代码冗余。
移入-规约分析算法
总结词
基于栈的算法
详细描述
移入-规约分析算法是一种自上而下的语法分 析算法,它将目标语句从左到右依次读入, 并根据文法的产生式规则进行移入或规约操 作,直到找到目标语句的语法结构。
词法分析
词法分析是编译过程的第一步,也称为扫描或词法扫描。它的任务是从左 到右读取源代码,将其分解成一个个的记号或符号。
词法分析器通常使用正则表达式或有限自动机来识别和生成记号,这些记 号可以是关键字、标识符、运算符、标点符号等。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
自上而下的语法分析器设计
1. 读取文法
/*输入:含一个文法的文本文件*/
/*输出:将文法存放到一个结构体数组中,并逐行显现在屏幕上。
*/
/*文件中文法的格式:
1)第一行:大写英文非终极符号序列,每个非终极符号都是字母,以换行符号'\n'作为结束标志;两个符号之间可以出现空格;
2)第二行:终极符号序列,每个终极符号可以字符是除了大写英文字母、空格、和控制符之外的任意一个可见的ASCII码。
3)对于空产生式,可暂用一个空格表示空串。
4)产生式每行一个。
*/
/*存放文法的结构体包括三项纪录:
1)非终极符号数组,2)终极符号数组,3)存放各产生式的结构体数组。
所存放的产生式只能含有文法符号,不能含有空格、换行符号等非文法符号,但是空产生式可以用非文法符号表示。
*/
示例:
G6.txt
SABC
abc
S-->AB
A-->aC
A-->
B-->Ab
B--> c
B-->
C-->c
2. 计算首字符集
输入:(1)一个文法的文本文件,(2)键盘输入一个文法符号串。
输出:生成该文法符号串的首字符集,并输出到显示器。
算法:
C语言程序:
#include<stdio.h>
#include<ctype.h>
void main()
{
}
3. 计算非终极符号的后字符集。