贝叶斯实验报告
《模式识别》实验报告-贝叶斯分类

《模式识别》实验报告---最小错误率贝叶斯决策分类一、实验原理对于具有多个特征参数的样本(如本实验的iris 数据样本有4d =个参数),其正态分布的概率密度函数可定义为112211()exp ()()2(2)T d p π-⎧⎫=--∑-⎨⎬⎩⎭∑x x μx μ 式中,12,,,d x x x ⎡⎤⎣⎦=x 是d 维行向量,12,,,d μμμ⎡⎤⎣⎦=μ是d 维行向量,∑是d d ⨯维协方差矩阵,1-∑是∑的逆矩阵,∑是∑的行列式。
本实验我们采用最小错误率的贝叶斯决策,使用如下的函数作为判别函数()(|)(),1,2,3i i i g p P i ωω==x x (3个类别)其中()i P ω为类别i ω发生的先验概率,(|)i p ωx 为类别i ω的类条件概率密度函数。
由其判决规则,如果使()()i j g g >x x 对一切j i ≠成立,则将x 归为i ω类。
我们根据假设:类别i ω,i=1,2,……,N 的类条件概率密度函数(|)i p ωx ,i=1,2,……,N 服从正态分布,即有(|)i p ωx ~(,)i i N ∑μ,那么上式就可以写为1122()1()exp ()(),1,2,32(2)T i i dP g i ωπ-⎧⎫=-∑=⎨⎬⎩⎭∑x x -μx -μ对上式右端取对数,可得111()()()ln ()ln ln(2)222T i i i i dg P ωπ-=-∑+-∑-i i x x -μx -μ上式中的第二项与样本所属类别无关,将其从判别函数中消去,不会改变分类结果。
则判别函数()i g x 可简化为以下形式111()()()ln ()ln 22T i i i i g P ω-=-∑+-∑i i x x -μx -μ二、实验步骤(1)从Iris.txt 文件中读取估计参数用的样本,每一类样本抽出前40个,分别求其均值,公式如下11,2,3ii iii N ωωω∈==∑x μxclear% 原始数据导入iris = load('C:\MATLAB7\work\模式识别\iris.txt'); N=40;%每组取N=40个样本%求第一类样本均值 for i = 1:N for j = 1:4w1(i,j) = iris(i,j+1); end endsumx1 = sum(w1,1); for i=1:4meanx1(1,i)=sumx1(1,i)/N; end%求第二类样本均值 for i = 1:N for j = 1:4 w2(i,j) = iris(i+50,j+1);end endsumx2 = sum(w2,1); for i=1:4meanx2(1,i)=sumx2(1,i)/N; end%求第三类样本均值 for i = 1:N for j = 1:4w3(i,j) = iris(i+100,j+1); end endsumx3 = sum(w3,1); for i=1:4meanx3(1,i)=sumx3(1,i)/N; end(2)求每一类样本的协方差矩阵、逆矩阵1i -∑以及协方差矩阵的行列式i ∑, 协方差矩阵计算公式如下11()(),1,2,3,41i ii N i jklj j lk k l i x x j k N ωωσμμ==--=-∑其中lj x 代表i ω类的第l 个样本,第j 个特征值;ij ωμ代表i ω类的i N 个样品第j 个特征的平均值lk x 代表i ω类的第l 个样品,第k 个特征值;iw k μ代表i ω类的i N 个样品第k 个特征的平均值。
人工智能主观贝叶斯分析实验

人工智能主观贝叶斯分析实验YUKI was compiled on the morning of December 16, 2020人工智能实验报告西安交大一、实验目的(1)学习了解java编程语言,掌握基本的算法实现;(2)深入理解贝叶斯理论和不确定性推理理论;(3)学习运用主观贝叶斯公式进行不确定推理的原理和过程二、实验题目用java语言实现运用主观贝叶斯公式进行不确定性推理的过程:根据初始证据E的概率P(E)及LS、LN的值,把H的先验概率P(H)更新为后验概率P(H/E)或者P(H/﹁E)。
要求如下:(1)充分考虑各种证据情况:证据肯定存在、证据肯定不存在、观察与证据无关、其他情况;(2)考虑EH公式和CP公式两种计算后验概率的方法;(3)给出EH公式的分段线性插值图;三、实验原理1、知识的不确定性在主观贝叶斯方法中,只是是如下形式的产生式规则表示:IF E THEN (LS,LN) H (P(H))LS是充分性度量。
其定义为:LS=P(E|H)/P(E|¬H)。
LN是必要性度量,其定义为:LN=P(¬E|H)/P(¬E|¬H)=(1-P(E|H))/(1-P(E|¬H))。
2、证据不确定时的计算公式⎪⎪⎩⎪⎪⎨⎧≤≤---+<≤⌝-+⌝=1)S /E (P )E (P ))E (P )S /E (P (*)E (P 1)H (P )E /H (P )H (P )E (P )S /E (P 0)S /E (P *)E (P )E /H (P )H (P )E /H (P )S /H (P 当当四、实验代码import .*;import .*;public class bayes extends JFrame implements ActionListener{JPanel panel =new JPanel();JLabel ph =new JLabel("P(H)");JTextField PH =new JTextField("",3);JLabel pe =new JLabel("P(E)");JTextField PE =new JTextField("",3);JLabel ls =new JLabel("LS");JTextField LS =new JTextField("",3);JLabel ln =new JLabel("LN");JTextField LN =new JTextField("",3);Button compute =new Button("COMPUTE");static double t_ph ;static double t_pe ;static double t_ln ;static double t_ls ;static double ph_e ; //P(E/S)=0 时 PHSstatic double phe ; //P(E/S)=1 时 PHSpublic bayes(){setLayout(new BorderLayout());(new FlowLayout()); (ph );(PH);(pe);(PE);(ln);(LN);(ls);(LS);(panel);(this);(compute,;}public static void main(String [] args){bayes a=new bayes();(400,250);(true);(EXIT_ON_CLOSE);}@Overridepublic void actionPerformed(ActionEvent arg0) {// TODO Auto-generated method stubt_ph=new Double());t_pe=new Double());t_ls=new Double());t_ln=new Double());ph_e=t_ln*t_ph/((t_ln-1)*t_ph+1);phe=t_ls*t_ph/((t_ls-1)*t_ph+1);display c=new display();}}class draw extends JPanel{public void paint(Graphics g){(g);(50, 350, 350, 350);(50, 50, 50, 350 );(50, 350-(int)*300), 50+(int)*300),350-(int)*300));(50+(int)*300),350-(int)*300),350,350-(int)*300));}}class display extends JFrame{public display(){draw b=new draw();(b);;(true);(400,400);}}五、实验结果输入初始值:图像结果显示:六、实验总结由于本次实验是第一次使用java语言进行编程,在领略到java语言的方便与强大功能的同时,也有有很多不尽如人意的地方。
朴素贝叶斯最优性实验

朴素贝叶斯的最优性1报告目的:1) 学习朴素贝叶斯和贝叶斯网络相关知识。
2) 验证属性间依赖分布对朴素贝叶斯分类器分类效果的影响。
3) 在二变量高斯分布下验证朴素贝叶斯最优条件r 系数。
2实验过程本实验通过贝叶斯网络模型构造二属性值的分类样本数据集,并在该数据集上分别用贝叶斯网络和朴素贝叶斯的方法分类,比较其分类准确性,并分析两种分类器准确性与该数据集的r 指标和D(fb,fnb)的关系,验证文章的结论。
并使用泊松分布的数据集来验证文章的结论。
2.1实验模型构造一个如下图所示的贝叶斯网络模型,根据该模型生成一组含有4000个样本的数据集。
设X 为属性集{12,X X }1X 表示属性Rain ,2X 表示属性Sprinkle; 设E 为属性值{12,x x };设C 代表类变量取值为+,-,+表示wet 类,-表示non-wet 类; 则根据属性值E 分类为c 的概率为P(c|E)=p(E|c)p(c)/p(E);贝叶斯网络分类器:121121(|)(|,)(|)()()(|)()(|)(|,)p x p x x p C E p C f E p C E p C p x p x x ++=+=+===-=---朴素贝叶斯分类器:21(|)(|)()()(|)()(|)i n i i p x C p C E p C f E p C E p C p x C ==+=+=+===-=-=-∏2.2实验结果1)变化R 的概率,S 取W 取通过改变P(R),得到不同的属性依赖关系,并产生不同的数据集,分别计算贝叶斯网络和朴素贝叶斯分类器在这些数据集上的分类准确性和r 值。
表1为部分实验结果;图1,图2分别为r 值和D 值与两种分类准确性的散点分布图。
表1 变化R 的概率时贝叶斯网络和朴素贝叶斯分类准确率比较图1 贝叶斯网络和朴素贝叶斯分类性能随r的变化情况从图1中看出,当r足够小时,朴素贝叶斯的分类效果接近甚至等同于贝叶斯网络,随着r增大,朴素贝叶斯分类性能逐渐下降。
贝叶斯实验报告范文

贝叶斯实验报告范文一、实验目的掌握贝叶斯推断的基本原理和方法,通过实验研究贝叶斯公式在实际问题中的应用。
二、实验原理贝叶斯推断是一种通过先验概率和观测数据来推断未知变量的方法。
根据贝叶斯公式,我们可以通过已知的先验概率和条件概率来推导后验概率,从而对未知变量进行推断。
三、实验过程1.实验准备:准备一个贝叶斯实验案例,例如:假设有一个盒子里有红球和蓝球,我们不知道红球和蓝球的比例。
先验概率分别是P(R)=0.5和P(B)=0.52.实验步骤:a)假设我们从盒子里随机取了一个球,结果是红色,我们要计算取到红色球的概率。
根据贝叶斯公式:P(R,D)=P(D,R)*P(R)/P(D)其中,P(R,D)代表在已知取到红色球的条件下,取到红色球的概率;P(D,R)代表在已知取到红色球的条件下,取到红色球的概率;P(R)代表取到红色球的概率;P(D)代表取到红色球的概率。
根据已知条件,P(D,R)=1,P(D)=P(D,R)*P(R)+P(D,B)*P(B),P(B)=1-P(R)。
将上述条件代入贝叶斯公式,计算P(R,D)的值。
b)假设我们从盒子里随机取了一个球,结果是红色,然后再从盒子里取了一个球,结果也是红色,我们要计算从盒子里取到的两个球都是红色球的概率。
根据贝叶斯公式:P(R2,R1)=P(R1,R2)*P(R2)/P(R1)其中,P(R2,R1)代表在已知第一个球是红色球的条件下,第二个球是红色球的概率;P(R1,R2)代表在已知第二个球是红色球的条件下,第一个球是红色球的概率;P(R2)代表第二个球是红色球的概率;P(R1)代表第一个球是红色球的概率。
根据已知条件,P(R1,R2)=1,P(R1)=P(R1,R2)*P(R2)+P(R1,B2)*P(B2),P(B2)=1-P(R2)。
将上述条件代入贝叶斯公式,计算P(R2,R1)的值。
四、实验结果根据贝叶斯公式的计算,可以得到实验结果。
五、实验分析通过实验研究,我们可以发现贝叶斯推断在解决实际问题时能够有效地利用已知的先验概率和观测数据,从而对未知变量进行推断。
山东大学计算机学院机器学习实验一贝叶斯分类
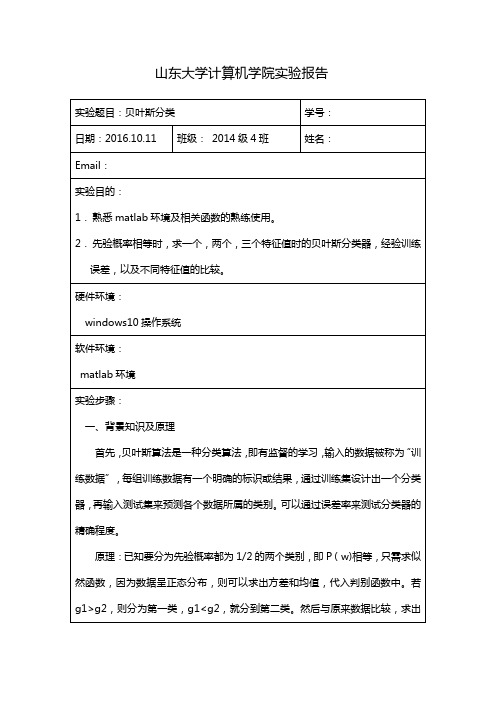
公式:
二、实验步骤
1.因为以前经常使用微软的Azure平台,这次仍然想用这个平台实验一下。分别测试使用一个,两个,三个特征值时用贝叶斯算法求出的准确率和召回率等。
1.熟悉matlab环境及相关函数的熟练使用。
2.先验概率相等时,求一个,两个,三个特征值时的贝叶斯分类器,经验训练误差,以及不同特征值的比较。
硬件环境:
windows10操作系统
软件环境:
matlab环境
实验步骤:
一、背景知识及原理
首先,贝叶斯算法是一种分类算法,即有监督的学习,输入的数据被称为“训练数据”,每组训练数据有一个明确的标识或结果,通过训练集属的类别。可以通过误差率来测试分类器的精确程度。
三、实验结果
1.一个特征值:分类错误率为0.3,界定误差0.473999
2.两个特征值:分类误差率0.45,界定误差为0.460466
3.三个特征值:分类误差率0.15,界定误差为0.411926
4.讨论:对于一有限的数据集,是否有可能在更高的数据维数下经验误差会增加
——我觉得如果数据维数高的话,误差是有可能相对于低维数的反而增加的。因为可能会产生比如这次实验的情况,两维数据的时候第二个特征值特别乱,误差很大,结果误差率比一个特征值的时候还要高了。
结论分析与体会:
刚开始感觉这个题无从下手,不知道要做出来的分类器是个什么样子,虽然知道该怎么在纸上计算后验概率,但是拿到matlab上面编写程序就不会了。
Bayes分类器设计实验报告

模式识别实验报告题目: Bayes 分类器设计学 院 计算机科学与技术 专 业 xxxxxxxxxxxxxxxx 学 号 xxxxxxxxxxxx 姓 名 xxxx 指导教师 xxxx2015年xx 月xx 日装 订 线Bayes分类器设计一、实验目的对模式识别有一个初步的理解,能够根据自己的设计对贝叶斯决策理论算法有一个深刻地认识,理解二类分类器的设计原理。
二、实验原理最小风险贝叶斯决策可按下列步骤进行:(1)在已知及给出待识别的X的情况下,根据贝叶斯公式计算出后验概率:(2)利用计算出的后验概率及决策表,按下面的公式计算出采取的条件风险(3)对(2)中得到的a个条件风险值进行比较,找出使其条件风险最小的决策,即则就是最小风险贝叶斯决策。
三、实验内容假定某个局部区域细胞识别中正常和非正常两类先验概率分别为正常状态:P(w1)=0.9;异常状态:P(w2)=0.1。
现有一系列待观察的细胞,其观察值为x:-3.9847 -3.5549 -1.2401 -0.9780 -0.7932 -2.8531-2.7605 -3.7287 -3.5414 -2.2692 -3.4549 -3.0752-3.9934 2.8792 -0.9780 0.7932 1.1882 3.0682-1.5799 -1.4885 -0.7431 -0.4221 -1.1186 4.2532已知类条件概率是的曲线如下图:类条件概率分布正态分布分别为N(-2,0.25)、N(2,4)试对观察的结果进行分类。
四、实验要求1)用matlab完成基于最小错误率的贝叶斯分类器的设计,要求程序相应语句有说明文字,要求有子程序的调用过程。
2)根据例子画出后验概率的分布曲线以及分类的结果示意图。
3)如果是最小风险贝叶斯决策,决策表如下:最小风险贝叶斯决策表:请重新设计程序,完成基于最小风险的贝叶斯分类器,画出相应的条件风险的分布曲线和分类结果,并比较两个结果。
贝叶斯分类算法实验报告
贝叶斯分类算法实验报告贝叶斯分类算法是一种基于统计学原理的分类算法,在文本分类、垃圾邮件过滤和情感分析等领域得到了广泛应用。
本实验通过使用Python语言和sklearn库实现了贝叶斯分类算法,并在果蔬分类数据集上进行了实验。
实验数据果蔬分类数据集是一个有监督的分类数据集,包含了81个样本和9个特征。
特征包括水分、纤维、硬度、色泽、含糖量、口感、储存期、气味和价格。
样本的分类标签包括红萝卜、西红柿和黄瓜三种类型。
实验过程首先,我们需要将数据集划分为训练集和测试集,我们选择将数据集的70%用作训练集,30%用作测试集。
然后,我们需要对数据进行预处理,包括特征选择和标准化。
对于特征选择,我们可以使用卡方检验进行特征评估。
```pythonfrom sklearn.feature_selection import SelectKBest, chi2对于标准化,我们可以使用z-score标准化方法进行处理。
最后,我们可以使用sklearn库中的GaussianNB类实现高斯朴素贝叶斯分类算法。
结果分析我们使用准确率和混淆矩阵来评估算法的性能。
首先,我们计算了算法在测试集上的准确率,结果为0.8。
accuracy = accuracy_score(y_test, y_pred)print('Accuracy: {:.2f}%'.format(accuracy * 100))```混淆矩阵可以用来查看分类器在每个类别中的表现,包括正确分类数和错误分类数。
混淆矩阵的行表示实际分类结果,列表示预测分类结果。
混淆矩阵结果为:```[[8 0 1][1 5 0][2 0 9]]```我们可以看到,分类器在红萝卜和黄瓜两个类别上表现良好,但在西红柿一类中有错误分类。
这可能是由于数据集中这个类别的样本数量较少,导致算法对于这个类别的分类效果较差。
总结。
《模式识别》实验报告-贝叶斯分类
《模式识别》实验报告-贝叶斯分类一、实验目的通过使用贝叶斯分类算法,实现对数据集中的样本进行分类的准确率评估,熟悉并掌握贝叶斯分类算法的实现过程,以及对结果的解释。
二、实验原理1.先验概率先验概率指在不考虑其他变量的情况下,某个事件的概率分布。
在贝叶斯分类中,需要先知道每个类别的先验概率,例如:A类占总样本的40%,B类占总样本的60%。
2.条件概率后验概率指在已知先验概率和条件概率下,某个事件发生的概率分布。
在贝叶斯分类中,需要计算每个样本在各特征值下的后验概率,即属于某个类别的概率。
4.贝叶斯公式贝叶斯公式就是计算后验概率的公式,它是由条件概率和先验概率推导而来的。
5.贝叶斯分类器贝叶斯分类器是一种基于贝叶斯定理实现的分类器,可以用于在多个类别的情况下分类,是一种常用的分类方法。
具体实现过程为:首先,使用训练数据计算各个类别的先验概率和各特征值下的条件概率。
然后,将测试数据的各特征值代入条件概率公式中,计算出各个类别的后验概率。
最后,取后验概率最大的类别作为测试数据的分类结果。
三、实验步骤1.数据集准备本次实验使用的是Iris数据集,数据包含150个Iris鸢尾花的样本,分为三个类别:Setosa、Versicolour和Virginica,每个样本有四个特征值:花萼长度、花萼宽度、花瓣长度、花瓣宽度。
2.数据集划分将数据集按7:3的比例分为训练集和测试集,其中训练集共105个样本,测试集共45个样本。
计算三个类别的先验概率,即Setosa、Versicolour和Virginica类别在训练集中出现的频率。
对于每个特征值,根据训练集中每个类别所占的样本数量,计算每个类别在该特征值下出现的频率,作为条件概率。
5.测试数据分类将测试集中的每个样本的四个特征值代入条件概率公式中,计算出各个类别的后验概率,最后将后验概率最大的类别作为该测试样本的分类结果。
6.分类结果评估将测试集分类结果与实际类别进行比较,计算分类准确率和混淆矩阵。
贝叶斯分类器报告
实验报告一、实验目的通过上机编程加深对贝叶斯分类器分类过程的理解,同时提高分析问题、解决问题、实际操作的能力。
二、实验数据说明实验数据来源于/ml/,详细说明请见附件一。
数据源的完整名称是Wine Data Set,是对3种不同的酒进行分类。
这三种酒包括13种不同的属性。
13种属性分别为:Alcohol,Malic acid,Ash,Alcalinity of ash,Magnesium,Total phenols,Flavanoids,Nonflavanoid phenols,Proanthocyanins,Color intensity,Hue,OD280/OD315 of diluted wines,Proline。
在“wine.data”文件中,每行代表一种酒的样本,共有178个样本;一共有14列,其中,第一列为类标志属性,共有三类,分别记为“1”,“2”,“3”;后面的13列为每个样本的对应属性的样本值。
其中第1类有59个样本,第2类有71个样本,第3类有48个样本。
三、朴素贝叶斯分类算法分析贝叶斯分类器是用于分类的贝叶斯网络。
该网络中应包含类结点C,其中C 的取值来自于类集合( c1 , c2 , ... , cm),还包含一组结点X = ( X1 , X2 , ... , Xn),表示用于分类的特征。
对于贝叶斯网络分类器,若某一待分类的样本D,其分类特征值为x = ( x1 , x2 , ... , x n) ,则样本D 属于类别ci 的概率P( C = ci | X1 = x1 , X2 = x 2 , ... , Xn = x n) ,( i = 1 ,2 , ... , m) 应满足下式:P( C = ci | X = x) = Max{ P( C = c1 | X = x) , P( C = c2 | X = x ) , ... , P( C = cm | X = x ) } 而由贝叶斯公式:P( C = ci | X = x) = P( X = x | C = ci) * P( C = ci) / P( X = x)其中,P( C = ci) 可由领域专家的经验得到,而P( X = x | C = ci) 和P( X = x) 的计算则较困难。
贝叶斯分类实验报告doc
贝叶斯分类实验报告篇一:贝叶斯分类实验报告实验报告实验课程名称数据挖掘实验项目名称贝叶斯分类年级XX级专业信息与计算科学学生姓名学号 1207010220理学院实验时间:XX年12月2日学生实验室守则一、按教学安排准时到实验室上实验课,不得迟到、早退和旷课。
二、进入实验室必须遵守实验室的各项规章制度,保持室内安静、整洁,不准在室内打闹、喧哗、吸烟、吃食物、随地吐痰、乱扔杂物,不准做与实验内容无关的事,非实验用品一律不准带进实验室。
三、实验前必须做好预习(或按要求写好预习报告),未做预习者不准参加实验。
四、实验必须服从教师的安排和指导,认真按规程操作,未经教师允许不得擅自动用仪器设备,特别是与本实验无关的仪器设备和设施,如擅自动用或违反操作规程造成损坏,应按规定赔偿,严重者给予纪律处分。
五、实验中要节约水、电、气及其它消耗材料。
六、细心观察、如实记录实验现象和结果,不得抄袭或随意更改原始记录和数据,不得擅离操作岗位和干扰他人实验。
七、使用易燃、易爆、腐蚀性、有毒有害物品或接触带电设备进行实验,应特别注意规范操作,注意防护;若发生意外,要保持冷静,并及时向指导教师和管理人员报告,不得自行处理。
仪器设备发生故障和损坏,应立即停止实验, 并主动向指导教师报告,不得自行拆卸查看和拼装。
八、实验完毕,应清理好实验仪器设备并放回原位,清扫好实验现场,经指导教师检查认可并将实验记录交指导教师检查签字后方可离去。
九、无故不参加实验者,应写出检查,提出申请并缴纳相应的实验费及材料消耗费,经批准后,方可补做。
十、自选实验,应事先预约,拟订出实验方案,经实验室主任同意后,在指导教师或实验技术人员的指导下进行。
H^一、实验室内一切物品未经允许严禁带出室外,确需带出,必须经过批准并办理手续。
学生所在学院:理学院专业:信息与计算科学班级: 信计121篇二:数据挖掘-贝叶斯分类实验报告实验报告实验课程名称数据挖掘实验项目名称贝叶斯的实现年级专业学生姓名学号00学院实验时间:年月曰13篇三:模式识别实验报告贝叶斯分类器模式识别理论与方法课程作业实验报告实验名称:Generating Pattern Classes 实验编号:Proj02-01规定提交日期:XX年3月30日实际提交日期:XX年3 月24日摘要:在熟悉贝叶斯分类器基本原理基础上,通过对比分类特征向量维数差异而导致分类正确率发生的变化,验证了“增加特征向量维数,可以改善分类结果”。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
贝叶斯实验报告Document serial number【UU89WT-UU98YT-UU8CB-UUUT-UUT108】HUNAN UNIVERSITY人工智能实验报告题目实验三:分类算法实验学生姓名匿名学生学号 02xx专业班级智能科学与技术1302班指导老师袁进一.实验目的1.了解朴素贝叶斯算法的基本原理;2.能够使用朴素贝叶斯算法对数据进行分类3.了解最小错误概率贝叶斯分类器和最小风险概率贝叶斯分类器4.学会对于分类器的性能评估方法二、实验的硬件、软件平台硬件:计算机软件:操作系统:WINDOWS10应用软件:C,Java或者Matlab相关知识点:贝叶斯定理:表示事件B已经发生的前提下,事件A发生的概率,叫做事件B发生下事件A 的条件概率,其基本求解公式为:贝叶斯定理打通了从P(A|B)获得P(B|A)的道路。
直接给出贝叶斯定理:朴素贝叶斯分类是一种十分简单的分类算法,叫它朴素贝叶斯分类是因为这种方法的思想真的很朴素,朴素贝叶斯的思想基础是这样的:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。
朴素贝叶斯分类的正式定义如下:1、设为一个待分类项,而每个a为x的一个特征属性。
2、有类别集合。
3、计算。
4、如果,则。
那么现在的关键就是如何计算第3步中的各个条件概率。
我们可以这么做:1、找到一个已知分类的待分类项集合,这个集合叫做训练样本集。
2、统计得到在各类别下各个特征属性的条件概率估计。
即3、如果各个特征属性是条件独立的,则根据贝叶斯定理有如下推导:因为分母对于所有类别为常数,因为我们只要将分子最大化皆可。
又因为各特征属性是条件独立的,所以有:整个朴素贝叶斯分类分为三个阶段:第一阶段: 准备工作阶段,这个阶段的任务是为朴素贝叶斯分类做必要的准备,主要工作是根据具体情况确定特征属性,并对每个特征属性进行适当划分,然后由人工对一部分待分类项进行分类,形成训练样本集合。
这一阶段的输入是所有待分类数据,输出是特征属性和训练样本。
这一阶段是整个朴素贝叶斯分类中唯一需要人工完成的阶段,其质量对整个过程将有重要影响,分类器的质量很大程度上由特征属性、特征属性划分及训练样本质量决定。
第二阶段: 分类器训练阶段,这个阶段的任务就是生成分类器,主要工作是计算每个类别在训练样本中的出现频率及每个特征属性划分对每个类别的条件概率估计,并将结果记录。
其输入是特征属性和训练样本,输出是分类器。
这一阶段是机械性阶段,根据前面讨论的公式可以由程序自动计算完成。
第三阶段: 应用阶段。
这个阶段的任务是使用分类器对待分类项进行分类,其输入是分类器和待分类项,输出是待分类项与类别的映射关系。
这一阶段也是机械性阶段,由程序完成。
三、实验内容及步骤实验内容:A.利用贝叶斯算法进行数据分类操作,并统计其预测正确率,数据集:汽车评估数据集(learn作为学习集,test作为测试集合)B.随机产生10000组正样本和20000负样本高斯分布的数据集合(维数设为二维),要求正样本:均值为[1;3],方差为[2 0;0 2];负样本:均值为[10;20],方差为[10 0;0 10].先验概率按样本量设定为1/3和2/3.分别利用最小错误概率贝叶斯分类器和最小风险概率贝叶斯分类器对其分类。
(假设风险程度正样本分错风险系数为,负样本分错风险为,该设定仅用于最小风险分析)相关概念:1.贝叶斯法则机器学习的任务:在给定训练数据D时,确定假设空间H中的最佳假设。
最佳假设:一种方法是把它定义为在给定数据D以及H中不同假设的先验概率的有关知识下的最可能假设。
贝叶斯理论提供了一种计算假设概率的方法,基于假设的先验概率、给定假设下观察到不同数据的概率以及观察到的数据本身。
2.先验概率和后验概率用P(h)表示在没有训练数据前假设h拥有的初始概率。
P(h)被称为h的先验概率。
先验概率反映了关于h是一正确假设的机会的背景知识如果没有这一先验知识,可以简单地将每一候选假设赋予相同的先验概率。
类似地,P(D)表示训练数据D的先验概率,P(D|h)表示假设h 成立时D的概率。
机器学习中,我们关心的是P(h|D),即给定D时h的成立的概率,称为h 的后验概率。
3.贝叶斯公式贝叶斯公式提供了从先验概率P(h)、P(D)和P(D|h)计算后验概率P(h|D)的方法p(h|D)=P(D|H)*P(H)/P(D)P(h|D)随着P(h)和P(D|h)的增长而增长,随着P(D)的增长而减少,即如果D独立于h时被观察到的可能性越大,那么D对h的支持度越小。
4.极大后验假设学习器在候选假设集合H中寻找给定数据D时可能性最大的假设h,h被称为极大后验假设(MAP)确定MAP的方法是用贝叶斯公式计算每个候选假设的后验概率,计算式如下:h_map=argmax P(h|D)=argmax (P(D|h)*P(h))/P(D)=argmax P(D|h)*p(h) (h属于集合H)C.编写一个贝叶斯分类器。
输入为:均指向量、先验概率、协方差矩阵、输入学习数据X,测试数据类别XLABEL,测试数据Y.输出为Y对应的类别。
(选做)。
四、实验步骤:1.仔细阅读并了解实验数据集;2.使用任何一种熟悉的计算机语言(比如C,Java或者matlab)实现朴素贝叶斯算法;3.利用朴素贝叶斯算法在训练数据上学习分类器,训练数据的大小分别设置为:前100个数据,前200个数据,前500个数据,前700个数据,前1000个数据,前1350个数据;4.利用测试数据对学习的分类器进行性能评估;5.统计分析实验结果并上交实验报告;A源代码:package Bayes;import class NaiveBayesTool {/** 申明全局变量ength;j++){buy_Vlaue_gl[i][j]=(float)buy[i][j]/ClassValues[j];maint_Value_gl[i][j]=(float)maint[i][j]/ClassValues[j];door_Value_gl[i][j]=(float)door[i][j]/ClassValues[j];}for(int i=0;i<;i++)for(int j=0;j<person_Value_gl[0].length;j++){person_Value_gl[i][j]=(float)person[i][j]/ClassValues[j];lugboot_Value_gl[i][j]=(float)lug_boot[i][j]/ClassValues[j];safe_Value_gl[i][j]=(float)safe[i][j]/ClassValues[j];}}/** 获取测试数据* */public void TestData() throws IOException{BufferedReader br=new BufferedReader(new FileReader(""));String temp;temp=();String []str = null;Property Car = null;while(temp!=null){str=(",");Car=newProperty(str[0],str[1],str[2],str[3],str[4],str[5],str[6]);predictTotal++;(Car);calculate(Car);temp=();}}/*** 对分类器进行性能测试,判断其成功率为多少 * @param car*/public void calculate(Property car){ultiply(bigDecimal[j]);loatValue();[i] = itemGl + "\t";if (MaxGl < itemGl) {MaxGl = itemGl;t = i;}}验A中的分类器的优缺点。
可能存在0概率问题存在准确度问题,朴素贝叶斯分类器是基于样本属性条件独立的假设的前提下的,但是实际情况可能并不成立,这样也就缺失准确性了.解决朴素贝叶斯准确性问题提出的一种方法叫做:贝叶斯网络(Bayesian Belief Networks )2.评价最小错误概率贝叶斯分类器和最小风险概率贝叶斯分类器基于最小错误率的贝叶斯决策实质:通过观察x把状态的先验概率P(wi)转化为后验概率判别错误率的问题基于最小风险的贝叶斯决策考虑到各种错误照成的损失不同而提出的一种决策规则最小风险的贝叶斯决策的计算方法:1)根据贝叶斯公式,计算出后验概率2)利用后验概率和决策表,计算出条件风险3)比较2中的计算结果,找出使条件风险最小的决策Ak,则它就是最小风险的贝叶斯决策两者之间的关系:基于最小错误率的决策是基于最小风险决策的一个特例3.计算实验B中叶斯分类器和最小风险概率贝叶斯分类器的分类临界值[x1 x2],比较差别,并统计两种正确率。
(同上)4. 提出一种提高分类器性能的方法并通过实验验证。
Adaboost:基于错误提升分类器的性能Adaboost是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器,即弱分类器,然后把这些弱分类器集合起来,构造一个更强的最终分类器,比起弱分类器,这个“强”分类器的错误率会低很多。
Adaboost算法本身是改变数据分布实现的,它根据每次训练集之中的每个样本的分类是否正确,以及上次的总体分类的准确率,来确定每个样本的权值。
将修改权值的新数据送给下层分类器进行训练,然后将每次训练得到的分类器融合起来,作为最后的决策分类器。
以下给出 Adaboost算法的运行过程:1.训练数据中的每个样本,并赋予其一个权重,这些权重构成向量D,一开始时权重D初始化为相等的值;2.先在训练样本上训练得到第一个弱分类器并计算分类器的错误率;3.在同一数据集上再次训练弱分类器,在分类器的二次训练中,会重新调整每个样本的权重,其中第一次分类正确的样本的权重将会降低,而分类错误的样本权重将会提高;4.为了从所有弱分类器中得到最终的分类结果,Adaboost为每个分类器都分配了一个权重值alpha,这一组值是基于每个弱分类器的错误率进行计算的。
其中,错误率由以下公式定义:。