针对外显子设计PCR测序引物教程
PCR引物设计详细步骤

PCR引物设计详细步骤引言PCR(聚合酶链式反应)是一种在分子生物学中常用的技术,用于放大DNA片段。
在PCR过程中,引物的选择非常重要,因为引物的设计质量直接影响到PCR反应的效率和准确性。
本文将详细介绍PCR引物设计的步骤。
步骤1. 确定目标序列首先,需要确定所要放大的目标序列。
这可以是任何你感兴趣的DNA片段,如某个基因的编码区域,特定的DNA序列等。
2. 提取目标序列从已有的DNA样本中提取目标序列。
可以通过DNA提取试剂盒等方法进行提取,确保获得纯净的DNA。
3. 序列比对使用BLAST等工具将目标序列与已知的序列数据库进行比对,以确认目标序列的唯一性和可能存在的变异。
4. 引物设计原则根据目标序列,设计符合以下原则的引物:•引物长度通常在18-25个碱基对之间。
•碱基组成均匀,避免引物中存在大量的G或C碱基,以及连续多个重复的碱基。
•引物之间的互补性尽量避免,以防止二聚体的形成。
•避免引物末端存在碱基的互补序列,以防止非特异性扩增。
5. 引物设计工具使用引物设计工具,如Primer3、NCBI Primer-BLAST等,在目标序列中选择合适的引物。
这些工具可以根据给定的参数,自动设计合适的引物。
6. 引物评估对设计的引物进行评估,包括检查引物的反向互补性、引物的Tm值(熔解温度)、引物的二聚体和自身结构等。
确保引物的质量达到实验要求。
7. 引物合成将设计好的引物发送给合成公司进行合成。
确保引物的纯度和浓度符合要求。
8. PCR反应使用合成的引物进行PCR反应,按照标准的PCR反应体系和条件进行。
根据实验需求调整PCR反应的温度、时间等参数。
9. PCR产物验证通过凝胶电泳等方法验证PCR反应产物的大小和纯度。
确保PCR反应成功,并且没有非特异扩增的产物。
结论PCR引物设计是PCR反应成功的关键。
通过遵循引物设计的原则,结合引物设计工具的辅助,可以设计出合适的引物,弥补PCR技术在DNA放大中的巨大优势,为实验研究提供有效的工具。
PCR引物设计

PCR引物设计PCR(聚合酶链式反应)是一种常用的分子生物学方法,用于扩增特定的DNA片段。
PCR引物的设计对PCR反应的成功与否至关重要。
下面将详细介绍PCR引物的设计过程。
第一步,选择目标序列。
在设计PCR引物之前,首先需要确定要扩增的目标序列。
目标序列可以来自已知基因的特定片段,也可以通过测序等方法获得。
第二步,引物长度和温度。
PCR引物通常为单链DNA片段,一般长度在18-30个碱基对之间。
引物长度过短容易引起非特异性扩增,引物长度过长则会导致特异性降低。
此外,引物的长度还会影响PCR反应的温度。
一般情况下,引物的长度越长,PCR反应的温度就需要越高。
通常,引物的长度最好在20-24个碱基对之间。
第三步,引物序列的选择。
为了确保PCR反应的特异性,引物的选择至关重要。
引物应具有与目标序列完全互补的碱基序列,以确保引物能够精确结合到目标序列上。
此外,引物的序列还应避免序列内部的反向重复和结合位点之间的重复序列。
第四步,引物的熔解温度(Tm)的确定。
引物的熔解温度是引物与模板DNA结合的温度。
引物的熔解温度应该尽量接近反应的最低温度,以确保引物能够与目标序列特异性结合。
引物的Tm可以通过以下公式计算:Tm = 69.3 + 0.41 * (G+C%) - 650/length其中G+C%表示引物中鸟嘌呤(G)和胞嘧啶(C)的百分含量,length表示引物的长度。
第五步,特异性分析。
在设计引物之前,可以通过生物信息学工具对引物进行特异性分析。
特异性分析可以通过引物序列与目标序列的比对来进行。
引物在目标序列上应有唯一的结合位点,并且不应该与其他非目标序列有任何重复的位点。
第六步,引物的杂交性能。
为了确保引物的杂交性能,引物应具有适当的糖尖端修饰和杂交性能。
糖尖端修饰可以增强引物的杂交性能,并减少非特异性结合。
此外,引物的GC含量应该适中,过高或过低都可能导致非特异性结合的问题。
第七步,引物的交叉反应。
pcr操作流程测序方法

pcr操作流程测序方法PCR(Polymerase Chain Reaction)是一种常用的分子生物学技术,用于扩增DNA片段。
PCR操作流程通常包括DNA模板的提取、PCR试剂的配制、PCR反应的进行和PCR产物的分析等步骤。
在PCR反应中,DNA模板通过热循环反复复制,最终得到大量目标DNA片段。
PCR技术在基因克隆、基因检测、疾病诊断等领域有着广泛的应用。
PCR操作流程的第一步是DNA模板的提取。
DNA模板可以是从细胞、组织、血液等样本中提取的DNA。
提取DNA的方法包括酚氯仿法、琼脂糖凝胶法、商业DNA提取试剂盒等。
提取的DNA需要经过定量和纯化处理,以确保PCR反应的准确性和稳定性。
第二步是PCR试剂的配制。
PCR反应需要包括DNA模板、引物、核酸酶、缓冲液、dNTPs等组分。
引物是PCR反应的关键组分,它们是用于引导DNA合成的短寡核苷酸序列。
引物的设计需要考虑到目标DNA片段的长度、GC含量、Tm值等因素。
在配制PCR试剂时,需要根据实验设计和引物设计的要求,精确称量和混合试剂。
第三步是PCR反应的进行。
PCR反应通常在热循环仪中进行,包括三个步骤:变性、退火和延伸。
在变性步骤中,反应体系被加热至95℃,使DNA双链解旋成单链。
在退火步骤中,反应体系被降温至引物的Tm值,引物与DNA模板结合。
在延伸步骤中,核酸酶在适温下合成新的DNA链。
这三个步骤循环进行,每个循环会使目标DNA片段数量倍增。
最后一步是PCR产物的分析。
PCR产物可以通过琼脂糖凝胶电泳、实时荧光定量PCR、测序等方法进行分析。
琼脂糖凝胶电泳可以用于检测PCR产物的大小和纯度。
实时荧光定量PCR可以用于定量PCR产物的数量。
测序可以用于确定PCR产物的序列。
通过这些分析方法,可以验证PCR反应的成功性和准确性。
总的来说,PCR操作流程是一个重要的实验技术,可以用于扩增DNA片段、检测基因变异、诊断疾病等。
熟练掌握PCR技术的操作流程,可以为科研工作和临床诊断提供有力的支持。
针对外显子设计PCR测序引物教程

针对外显子设计PCR测序引物教程在园子搜索后,没有看到长基因(大与1000base)最简洁方法,而我现在欧洲实验室里从事这方面工作,作了大量这方面的工作。
自乐不如同乐,愿将我们设计引物技巧与大家分享,敲字很辛苦,请斑竹给点分。
可能有战友说了,我们的长基因都是交给测序公司用鸟枪法来测全基因的。
当然,您有钱当然可以这样做。
我们的方法适用于基因测序筛查突变,步骤相对简便,比较经济。
另外,本实验室最近的一偏文章采用该法发在了NEMJ上,可见该法已经是经典成熟的。
(1)基础知识我们知道gDNA由非编码区,外显子,内含子构成。
我们关心的基因是否突变在非编码区,外显字以及临近外显子的一小段内含子上。
至于其他的内含子(gDNA中的大头),发生突变与否并不是我们关心的,其临床意义也相当小。
因此我们只要设计引物来PCR上面三个重点区域就可以了。
(2)设计软件在线设计软件exon primerhttp://ihg2.helmholtz-muenchen.de/ihg/ExonPrimer.html大家从上图可以看到,网页提示我们现在需要输入两个序列,一个是cDNA,一个是gDNA。
由于我们还要考虑非编码区,而CDNA是没有非编码区UTR的。
因此,我们必须要用mRNA 输入网页中的cDNA栏。
否则我们得到的引物不会包含UTR。
要是有看官还看不懂的话,建议看下分子生物学教材关于cDNA和mRNA的区别。
下面我们以smurf2基因来说明如何设计针对外显子的测序引物。
(2)找到smurf2 mRNA打开gene bank/,注意要在database中选nucleotide如下图蹦出一大串序列。
找到我们要的人类的smurf2Homo sapiens SMAD specific E3 ubiquitin protein ligase 2 (SMURF2), mRNA直接点我们要的序列名字,就得到了mRNA了,Format:GenBank FASTA Graphics More Formats选项中当然要求点选FASTA形式了把mRNA序列拖选,拷贝下来再拷贝入在线设计软件exon primer (见第一贴)http://ihg2.helmholtz-muenchen.de/ihg/ExonPrimer.html好了。
(完整word版)PCR引物流程设计详解
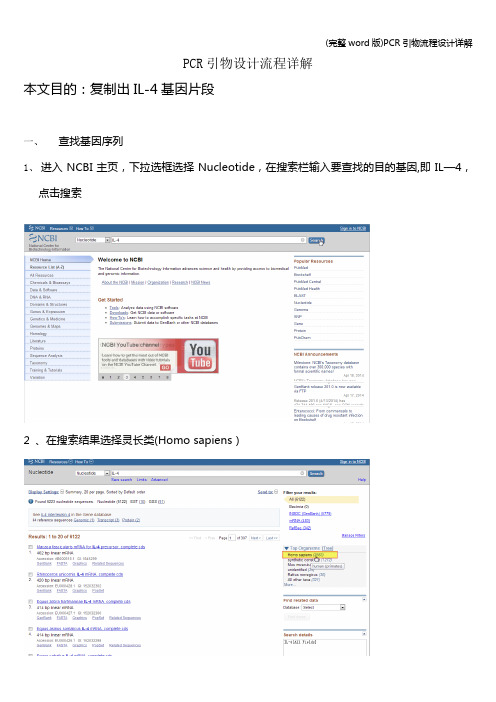
PCR引物设计流程详解本文目的:复制出IL-4基因片段一、查找基因序列1、进入NCBI主页,下拉选框选择Nucleotide,在搜索栏输入要查找的目的基因,即IL—4,点击搜索2 、在搜索结果选择灵长类(Homo sapiens)2、在灵长类IL-4基因中选择需要的mRNA序列3、查看基因的相关信息外显子区域CDs区域4、点击FASTA格式,并将序列保存到文档二、使用primer premier 5。
0设计引物1、建立新文件,将所得的序列复制进输入框内2、点击搜索按钮,搜索引物3、设置引物设计参数(因为在之前查找基因序列的时候获知,外显子区域分别为:1—200、201-248、249-425、426-618,又知在引物设计时引物位置最好跨越一个内含子,PCR产物长度通常为100—150bp,故设定上游引物位置为201—248,下游引物位置为249—425,产物长度为100-150bp)4、确认条件后,显示搜索结果4、双击选中得分最高的引物查看引物情况(上图为上游引物情况,下图为下游引物情况)5、将设计的上下游引物复制出来,保存到文档中三、使用oligo 6.0对设计的引物进行评价1、建立新文件,将从cnki上获得的cDNA复制进输入框,并点击accept接收2、接收后显示出该序列的相关信息3、点击edit按钮录入用primer设计的上游引物,每一次输入新数据后都需要点击accept按钮接收4、同理,录入下游引物5、分析上下游引物二聚体形成情况6、分析上下游引物发卡形成情况7、分析上下游引物GC%8、检测上下游引物与PCR模板其它位置错配情况9、分析PCR整体情况四、引物特异性检验(primer blast)1、进入NCBI主页,并选择blast2、选择primer blast3、在输入框内输入模板序列和上下游引物,并设定对比数据库,点击get primer进行对比4、查看blast结果Blast 结果显示,尽管IL—4与其它基因有相似区,但是引物的3’端没有完全互补。
全外显子测序实验的步骤详解

全外显子测序实验的步骤详解全外显子测序实验的步骤详解在这篇文章中,我将详细介绍全外显子测序实验的步骤。
全外显子测序是一种高通量测序技术,可以同时检测一个个体的所有外显子区域。
这项技术的广泛应用在生物医学研究、基因组学和临床诊断中。
通过全外显子测序,我们可以深入了解人类基因组和其他物种的遗传变异,从而加深对遗传疾病的认识,并为个体化医疗提供重要的支持。
全外显子测序实验的步骤一般可分为DNA提取、文库构建、测序和数据分析四个主要阶段。
下面我将详细介绍每一步的操作和技术。
第一步:DNA提取DNA提取是全外显子测序的首要步骤。
正确的DNA提取方法可以确保样本中的DNA完整性和纯度。
常用的DNA提取方法包括酚氯仿法、琼脂糖柱法和磁珠法等。
在这一步中,我们需要从样品中提取出高质量的基因组DNA,并通过比较纯净的样本质量和测序需求来选择适当的提取方法。
第二步:文库构建文库构建是全外显子测序的关键步骤之一。
在这一步中,我们需要将待测样本的DNA片段转化为可供测序的文库。
常用的文库构建方法包括PCR扩增、聚合酶链式反应(PCR)和各种商业化试剂盒。
在这一步中,我们需要优化文库构建的条件,包括选择合适的引物、调整反应体系、控制文库的片段大小和避免文库重组等。
第三步:测序测序是全外显子测序实验的核心步骤。
现代高通量测序技术包括Illumina测序、Ion Torrent测序和PacBio测序等。
在这一步中,我们将文库中的DNA片段与测序仪中的荧光标记引物结合,通过测序仪的扫描和记录,得到DNA片段的序列信息。
在测序过程中,我们需要合理选择测序深度,以保证测序质量和覆盖度的平衡。
第四步:数据分析数据分析是全外显子测序实验的最后关键步骤。
现代测序技术产生的数据量非常大,需要通过生物信息学分析来提取有用的信息。
数据分析的主要内容包括序列质量控制、序列比对、突变检测和功能注释等。
在这一步中,我们可以利用各种生物信息学工具和数据库对序列进行处理和解读,从而获得与个体的遗传特征、功能突变和疾病相关的信息。
PCR引物设计原理及方法

PCR引物设计基本思路1.根据实验需要,确定需要扩增的DNA序列,并知道其CDS区序列(编码结构基因区,即从起始密码子区至终止密码子区)ncbi网站查询RBS149..153/gene="eryF"CDS158..1372/gene="eryF"1ggatcccgat cgtgtcggag gaagaggcca agtcgcgccg ccccgaccag ctgctggtgc61tgccctggat ctaccgcgac gggttcgtcg aacgcgagca ggagttcctc gctggcggcg121gaaagctgat cttcccccta ccccgactgg aagtcgtatg acgaccgttc ccgatctcga181aagcgactcc ttccacgtcg actggtaccg cacctacgcc gagctgcgcg agaccgcgcc241ggtgacgccg gtgcgcttcc tcggccagga cgcgtggctg gtcaccggct acgacgaggc301gaaggccgcg ctgagcgacc tgcgcctgag cagcgacccg aagaagaagt acccgggcgt361ggaggtcgag ttcccggcat acctcggttt ccccgaggac gtgcggaact acttcgccac421caacatgggc accagcgacc cgccgaccca cacccggctg cgcaagctgg tgtcgcagga481gttcaccgtc cgccgcgtgg aggcgatgcg gccccgcgtc gagcagatca ccgcggagct541gctcgacgag gtgggcgact ccggcgtggt cgacatcgtc gaccgcttcg cccacccgct601gcccatcaag gtcatctgcg agctgctcgg cgtcgacgag aagtaccgcg gggagttcgg661gcggtggagc tcggagatcc tggtcatgga cccggagcgg gccgaacagc gcgggcaggc721ggccagggag gtcgtcaact tcatcctcga cctggtcgag cgccgccgca ccgagcccgg781cgacgacctg ctgtccgcgc tgatcagggt ccaggacgac gatgacggtc ggctcagcgc841cgacgagctg acctccatcg cgctggtgct gctgctggcc ggtttcgagg cgtcggtgag901cctcatcggg atcggcacct acctgctgct cacccacccg gaccagctcg cgctggtgcg 961gcgggacccg tcggcgctgc ccaacgccgt cgaggagatc ctgcgctaca tcgctccgcc 1021ggagaccacc acgcgcttcg ccgcggagga ggtggagatc ggcggtgtcg cgatccccca 1081gtacagcacg gtgctggtcg cgaacggcgc ggccaaccgc gacccgaagc agttcccgga 1141cccccaccgc ttcgacgtca cccgcgacac ccgcggccac ctgtcgttcg ggcagggcat 1201ccacttctgc atgggccggc cgctggccaa gctggagggc gaggtggcgc tgcgggcgct 1261gttcggccgc ttccccgctc tgtcgctggg aatcgacgcc gacgacgtgg tgtggcggcg 1321ttcgctgctg ctgcggggca tcgaccacct accggtgcgg ctcgacggat gagcacctgg 1381ctgcggcggt tcggtcctcc cgtcgagcac cgggcgcggc tggtgtgctt cccgcacgcg 1441ggagccgcgg ccgactccta cctcgacctc gcgcgcgcct tggcgcccga gatcgacgtg 1501cacgccgtgc agtacccggg gcgccaggac cgccgcgacg aggagcccct gggcaccgcc 1561ggcgagatcg ccgacgaggt ggccgccgtg ctgcgcgcgt cgggcggcga cggcccgttc 1621gccctgttcg ggcacagcat gggcgcgttg atcgcctacg agacggcgcg caggctcgaa 1681cgcgagcccg gcggcgggcc gctgcggctg ttcgtgtccg ggcagaccgc cccgcgcgtg 1741cacgagcgcc gcaccgacct gcccggcgac gacggtctgg tggacgagct gcgccggctc 1801ggcaccagcg aggcggcgct ggccgacgag gccctgctcg ccatgtcgct gccggtgctg 1861cgcgccgact accgcgtgct gcgctcctac gcctgggcgg acggaccacc gctgcgggcc 1921ggcatcaccg cgctgtgcgg cgacgccgac ccgctgaccg cgaccgggga cgccgagcgc 1981tggttgcagc actcggtcat ccccggccgg accaggacct tccccggcgg gcacttctac 2041ctgggtgaac aggtcaccga ggtggccggt gccgtgcgcc gggacctgct acgcgccggg 2101cttgcgggct gaggcgatca cgaagtcgag cgcgggcagc tcgcccttca tgcccgagtc 2161gctggtcagc gaccgcttga cctggctgta gaagagcctg ctcacgctct tcttgaacga2221ctcgtcctgc aggcacctgg ctg2.选择所需的载体,确定合适的酶切位点。
PCR引物设计方法及步骤

PCR引物设计方法及步骤查找目的基因序列并不能直接用于我们研究所用,因为查找到的基因序列只能算是基因的电子序列,并不是我们研究要用的现实中的序列,如何获得现实的基因序列呢?这就需要我们根据基因的电子序列来设计引物了,通过引物借助PCR方法才能获得我们的目的基因序列。
接下来,我们将介绍一下PCR方法并讲述如何设计引物。
PCR(polymerase chain reaction),即聚合酶链反应,又称基因体外扩增技术,是由一对引物介导、能在体外对特定DNA 片段进行快速酶促扩增的技术。
PCR能把很微量的遗传物质在数小时内扩增数百万倍达到检测水平.使原来无法进行分析和检测的许多项目得以完成。
PCR引物设计的目的是找到一对合适的核苷酸片段,使其能有效地扩增模板DNA序列。
引物的优劣直接关系到PCR的特异性与成功与否。
对引物的设计不可能有一种包罗万象的规则确保PCR的成功,但遵循某些原则,则有助于引物的设计。
1.引物的特异性引物与非特异扩增序列的同源性不要超过70%或有连续8个互补碱基同源。
2.避开产物的二级结构区某些引物无效的主要原因是引物重复区DNA二级结构的影响,选择扩增片段时最好避开二级结构区域。
用有关计算机软件可以预测估计mRNA的稳定二级结构,有助于选择模板。
实验表明,待扩区域自由能(△G°)小于58.6lkJ/mol时,扩增往往不能成功。
若不能避开这一区域时,用7-deaza-2′-脱氧GTP取代dGTP对扩增的成功是有帮助的。
3.长度寡核苷酸引物长度为15~30bp,一般为20~27mer。
引物的有效长度:Ln=2(G+C)+(A+T)Ln值不能大于38,因为>38时,最适延伸温度会超过T aq DNA聚合酶的最适温度(74℃),不能保证产物的特异性。
4.G+C含量G+C含量一般为40%~60%。
其Tm值是寡核苷酸的解链温度,即在一定盐浓度条件下,50%寡核苷酸双链解链的温度,有效启动温度,一般高于Tm值5~10℃。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
针对外显子设计PCR测序引物教程
在园子搜索后,没有看到长基因(大与1000base)最简洁方法,而我现在欧洲实验室里从事这方面工作,作了大量这方面的工作。
自乐不如同乐,愿将我们设计引物技巧与大家分享,敲字很辛苦,请斑竹给点分。
可能有战友说了,我们的长基因都是交给测序公司用鸟枪法来测全基因的。
当然,您有钱当然可以这样做。
我们的方法适用于基因测序筛查突变,步骤相对简便,比较经济。
另外,本实验室最近的一偏文章采用该法发在了NEMJ上,可见该法已经是经典成熟的。
(1)基础知识
我们知道gDNA由非编码区,外显子,内含子构成。
我们关心的基因是否突变在非编码区,外显字以及临近外显子的一小段内含子上。
至于其他的内含子(gDNA中的大头),发生突变与否并不是我们关心的,其临床意义也相当小。
因此我们只要设计引物来PCR上面三个重点区域就可以了。
(2)设计软件
在线设计软件exon primer
http://ihg2.helmholtz-muenchen.de/ihg/ExonPrimer.html
大家从上图可以看到,网页提示我们现在需要输入两个序列,一个是cDNA,一个是gDNA。
由于我们还要考虑非编码区,而CDNA是没有非编码区UTR的。
因此,我们必须要用mRNA 输入网页中的cDNA栏。
否则我们得到的引物不会包含UTR。
要是有看官还看不懂的话,建议看下分子生物学教材关于cDNA和mRNA的区别。
下面我们以smurf2基因来说明如何设计针对外显子的测序引物。
(2)找到smurf2 mRNA
打开gene bank
/,注意要在database中选nucleotide
如下图
蹦出一大串序列。
找到我们要的人类的smurf2
Homo sapiens SMAD specific E3 ubiquitin protein ligase 2 (SMURF2), mRNA
直接点我们要的序列名字,就得到了mRNA了,Format:GenBank FASTA Graphics More Formats选项中当然要求点选FASTA形式了
把mRNA序列拖选,拷贝下来
再拷贝入在线设计软件exon primer (见第一贴)
http://ihg2.helmholtz-muenchen.de/ihg/ExonPrimer.html
好了。
下面就要找gDNA了。
(3)ensembl在线查找gDNA
/Homo_sapiens/Info/Index
进入人类基因序列库
输入smurf2
得到下面的信息
点击Ensembl protein_coding Gene: ENSG00000108854 (HGNC (automatic): SMURF2
得到两段序列,201和202,其实两段序列是不同机构作出来的,大同小异.点第一个
得到如下页面
点页面里的supporting evidence,再点exon,就得到了smurf2的全基因序列,我们可以看到大写的碱基为外显子,小写的碱基为内含字.其实ensembl不同于ncbi的最大优势在于分开了外显字和内含字.我们设计的引物就知道是在外显子还是内含子上了.
现在将全部的gDNA用鼠标拖选起来,大家注意到两点(1)务必使内涵子全部显示,我们在页面左下角的
Configure this page里有这个选项.(2)鼠标拖选后,里面会有一些页面里的单词,比如ENSE00001331843什么的,必须把这类字母过滤掉.
可以用DNA-Star 工具软件里的Editseq(网上有下),将序列过滤,仅保留ATCG字母.或者用下列在线过滤工具
/sms/index.html
将过滤后的ATCG拷入
在线设计软件exon primer 的gDNA栏中(见第一贴)
http://ihg2.helmholtz-muenchen.de/ihg/ExonPrimer.html
默认的参数不变. done!
就得到了我们要的外显子引物了.大家可以发现我们的引物cover了非编码区,外显字以及临近外显子的一小段内含子.大功告成!(全文完)。