编译原理lxy第11章
编译原理 课件第十一章

11.2 局部优化:基本块内的优化 局部优化:
基本块:是指程序中一顺序执行的语句序列, 基本块:是指程序中一顺序执行的语句序列,其中只有一个 入口语句和一个出口语句。 入口语句和一个出口语句。 入口语句: 入口语句: 1. 程序的第一个语句;或者, . 程序的第一个语句;或者, 2. 条件转移语句或无条件转移语句的转移目标语句;或者 . 条件转移语句或无条件转移语句的转移目标语句; 3. 紧跟在条件转移语句后面的语句。 . 紧跟在条件转移语句后面的语句。
main() { int x, y, z; x = (1+20)*( -x); ( ) y = x*x+(x/y); y = z = (x/y)/(x*x); }
tmp1 = 1 + 20 ; tmp2 = -x ; x = tmp1 * tmp2 ; tmp3 = x * x ; tmp4 = x / y ; y = tmp3 + tmp4 ; tmp5 = x / y ; tmp6 = x * x ; z = tmp5 / tmp6 ; y = z ;
11.1 11.2 11.3 11.4
什么是代码优化 局部优化 控制流程分析和循环 数据流分析举例
11.1 优化技术简介
何谓代码优化: 宗旨: 获得较好性能的代码 宗旨: 等价 意图,结果, 意图,结果,权衡 目标代码优化 阶段: source front I.R code target code generator code 用户 中间代码优化
第十一章 代码优化
为了让编译程序能够生成效率高的目标代码, 为了让编译程序能够生成效率高的目标代码, 应对中间代码进行优化 注意:优化≠ 注意:优化≠最佳化 要求:相对合理性。 要求:相对合理性。应考虑空间和时间上的 取舍,及二者的平衡。 取舍,及二者的平衡。 本章将介绍基于结构信息的优化 基于结构信息的优化。 本章将介绍基于结构信息的优化。 假定 优化对象是四元式序列的中间代码
编译原理课后答案-第二版
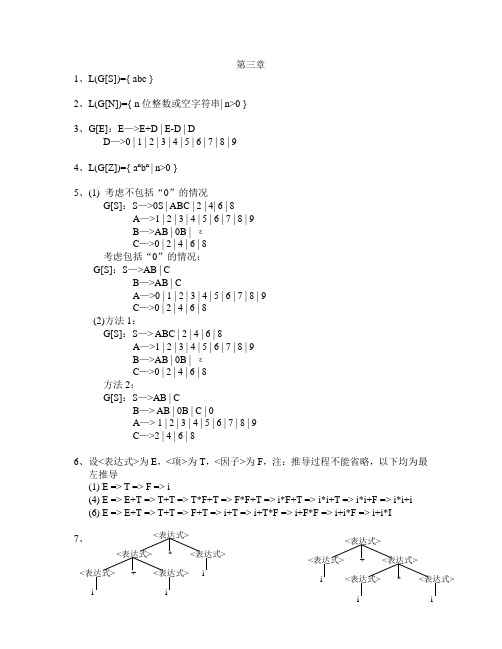
第三章1、L(G[S])={ abc }2、L(G[N])={ n位整数或空字符串| n>0 }3、G[E]:E—>E+D | E-D | DD—>0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 94、L(G[Z])={ a n b n | n>0 }5、(1) 考虑不包括“0”的情况G[S]:S—>0S | ABC | 2 | 4| 6 | 8A—>1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9B—>AB | 0B | εC—>0 | 2 | 4 | 6 | 8考虑包括“0”的情况:G[S]:S—>AB | CB—>AB | CA—>0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9C—>0 | 2 | 4 | 6 | 8(2)方法1:G[S]:S—> ABC | 2 | 4 | 6 | 8A—>1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9B—>AB | 0B | εC—>0 | 2 | 4 | 6 | 8方法2:G[S]:S—>AB | CB—> AB | 0B | C | 0A—> 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9C—>2 | 4 | 6 | 86、设<表达式>为E,<项>为T,<因子>为F,注:推导过程不能省略,以下均为最左推导(1) E => T => F => i(4) E => E+T => T+T => T*F+T => F*F+T => i*F+T => i*i+T => i*i+F => i*i+i(6) E => E+T => T+T => F+T => i+T => i+T*F => i+F*F => i+i*F => i+i*I7、<表达式><表达式>*<表达式><表达式>+<表达式>i i i<表达式><表达式>+<表达式>i <表达式>*<表达式>i i8、是有二义性的,因为句子abc 有两棵语法树(或称有两个最左推导或有两个最右推导)最左推导1:S => Ac => abc 最左推导2:S => aB => abc 9、(1)(2) 该文法描述了变量a 和运算符+、*组成的逆波兰表达式10、(1) 该文法描述了各种成对圆括号的语法结构(2) 是有二义性的,因为该文法的句子()()存在两种不同的最左推导: 最左推导1:S => S(S)S => (S)S => ()S => ()S(S)S => ()(S)S => ()()S => ()()最左推导2:S => S(S)S => S(S)S(S)S => (S)S(S)S=> ()S(S)S => ()(S)S => ()()S => ()()11、(1) 因为从文法的开始符E 出发可推导出E+T*F ,推导过程如下:E => E+T =>E+T*F ,所以E+T*F 是句型。
编译原理 11章

11.2 优化举例
6:循环中不变式的外提 • Tl=2*j外提 • 由于这里的循环中不 变式的外提是在非线 性块上的优化,所以 是全局优化。 • 经这两步优化后,便 得到图11.4中所示的 中间程序。
① i:=1; ② T1:=2*j; ③ T2:=T1;
④ T2:=100+T2; ⑤ R1:=B[T2]; ⑥ A[T5]:=R1+15.708; ⑦ i:=i+1; ⑧ if i≤100 then goto ② ≤
11.2 优化举例
3:常量合并
① i:=1;
② T1:=2*j; ③ T2:=100i+T1; ④ T3:=5*3.1416; ⑤ R1:=B[T2]; ⑥ T4:=2*j; ⑦ T5:=100*i+T4; ⑧ A[T5]:=R1+T3; ⑨ i:=i+1; ⑩ if i≤100 then goto ② ≤
n4 n3
图11.6 环路图
11.5 借助 借助DAG进行优化 进行优化
2: 无环有向图描述四元式
• 可用无环有向图来描述四元式。 例如,与四元式(op B C A)对应的DAG如图11.7所示。 利用DAG来进行优化的主要思想是: 将一基本块中的每一个四元式依次表示成对应的一个DAG, 该基本块就对应一较大的DAG(即其中各个四元式的DAG的合成)。 再按原来构造DAG结点的顺序重写四元式序列,便可得到“合并 了已知量”、“删除了无用赋值”、“删除了多余运算”的等价 的基本块——优化了的基本块。
11.1 基本块及其求法
• 1:基本块 基本块: 一个入口(第一语句) 一个出口(最后一语句) 入口语句集: 程序的第一个语句号; goto语句的下一条语句号; goto语句转到的语句号。 基本块划分: 入口语句集排序后每一入口语句到下一入口语句号 的前一语句。 最后一基本块为最后入口语句号到最后语句。
编译原理第11章

W:= V + U
ADD R0 , R1
R0含有W
W在R0中
§11.3一个简单的代码生成器
§11.4寄存器分配
一、问题引入:如何有效的利用寄存器; 1、基本块内: ①运算对象的值在寄存器中,则把该寄存器作为操作数地址; ②尽可能把各变量的现行值保存在寄存器中; ③基本块中不再引用的变量所占用的寄存器及早释放; 2、循环内: 按执行代价把寄存器固定分配给几个变量单独使用; 二、指令的执行代价 1、定义:指令的执行代价=指令访问内存单元的次数+1 2、例:op Ri,Ri执行代价为1; op Ri,M执行代价为2; op Ri,*Ri执行代价为2; op Ri,*M执行代价为3 3、应用:对循环中每个变量计算把某寄存器分配给它时执行代 价能节省多少,以决定寄存器的固定分配方案;
三、寄存器描述和地址描述 1、寄存器描述数组RValue:记录寄存器使用情况(空闲或已分配) 2、变量地址描述数组AValue:记录各变量现行值的存放位置(在 寄存器或内存单元); 四、基本块内代码生成算法 对块内每个中间代码 i: A:= B op C,依次执行:
调用GetReg(i:A:=B op C)得一寄存器R,用以存放A现行值; 利用AValue[B]和AValue[C]确定B和C现行值的存放位置B 和C 若B ≠R 则生成目标代码:LD R,B 和op R,C 若B =R 则生成op R,C 若B 或C 为R 则删除AValue[B]或AValue[C]中的R 令AValue[A]={R},RValue[R]={A} 若B或C的现行值在块内不再被引用且也不是块出口后的活跃变量 (由中间代码i的附加信息可知)且现行值在某寄存器Rk中 则删除RValue[Rk]中的B或C及AValue[B]或AValue[C]中的Rk
编译原理课后第十一章答案

对假设(2) B:=3 D:=A+C E:=A*C F:=D+E K:=B*5 L:=K+F
计算机咨询网()陪着您
10
《编译原理》课后习题答案第十一章
第7题 分别对图 11.25 和 11.26 的流图: (1) 求出流图中各结点 n 的必经结点集 D(n)。 (2) 求出流图中的回边。 (3) 求出流图中的循环。
(1) (2) (3) (4) (5) (6) (7) (8) (9) (10) (11) (12) (13)
i:=m-1 j:=n t1:=4*n v:=a[t1] i:=i+1 t2:=4*i t3:=a[t2] if t3< v goto (5) j:=j-1 t5:=4*j t5:=a[t4] if t5> v goto (9) if i >=编译原理》课后习题答案第十一章
第 5 题: 如下程序流图(图 11.24)中,B3 中的 i∶=2 是循环不变量,可以将其提到前置结点吗? 你还能举出一些例子说明循环不变量外移的条件吗?
图 11.24 答案: 不能。因为 B3 不是循环出口 B4 的必经结点。 循环不变量外移的条件外有: (a)(I)s 所在的结点是 L 的所有出口结点的必经结点 (II)A 在 L 中其他地方未再定值 (III)L 中所有 A 的引用点只有 s 中 A 的定值才能到达 (b)A 在离开 L 之后不再是活跃的,并且条件(a)的(II)和(III)成立。所谓 A 在离开 L 后不再是活跃的是指,A 在 L 的任何出口结点的后继结点的入口处不是活跃的(从此点后 不被引用) (3)按步骤(1)所找出的不变运算的顺序,依次把符合(2)的条件(a)或(b)的 不变运算 s 外提到 L 的前置结点中。如果 s 的运算对象(B 或 C)是在 L 中定值的,则只有 当这些定值四元式都已外提到前置结点中时,才可把 s 也外提到前置结点。
编译原理第十一章

这种DAG可用来描述计算过程,又称为描 述计算过程的DAG 一个基本块,可用一个DAG来表示。下图 列出各种四元式及相对应的DAG的结点形 式。图中ni为结点编号,结点下面的符号 (运算符、标识符或常数)是各结点的标 记,各结点右边的标识符是结点的附加标 识符。
28
(0)A:=B (:=,B,-,A)
原来:G (1) T0∶=3.14 (2) T1∶=2 * T0 (3) T2∶=R + r (4) A∶=T1 * T2 (5) B∶=A (6) T3∶=2 * T0 (7) T4∶=R + r (8) T5∶=T3 * T4 (9) T6∶=R - r (10) B∶=T5 * T6
1. G中的代码(2)和(6)的已知量都已合并。 2. G中(5)的无用赋值已被删除。 3. G中(3)和(7)的公共子表达式R+r只被计算一次,删除了多余运算。 35 所以G′是G的优化结果。
32
例 试构造以下基本块G的DAG。 (1) T0∶=3.14 (2) T1∶=2 * T0 (3) T2∶=R + r (4) A∶=T1 * T2 (5) B∶=A (6) T3∶=2 * T0 (7) T4∶=R + r (8) T5∶=T3 * T4 (9) T6∶=R - r (10) B∶=T5 * T6
21
再进行复写传播和删除无用赋值等变换后得到: t3 := a * 1 t4 := t3 * 2 t5 := b + t4 c := t5 * t5 接着使用代数变换后有: t3 := a t4 := t3 * 2 t5 := b + t4 c := t5 * t5
22
使用复写传播和删除无用赋值变换后又有: t4 := a * 2 t5 := b + t4 c := t5 * t5 再使用代数变换: t4 := a + a t5 := b + t4 c := t5 * t5
编译原理lxy第1章

本章内容简介
· · · · · 程序的翻译 编译程序的工作过程 编译程序的结构 编译程序的组织方式 编译程序的构造
1.1 程序的翻译
1.1.1 程序设计语言 · · ·
问题: 问题: 计算机只能识别二进制数0 计算机只能识别二进制数0、1表示的指令和数构成的本计算机系统的 机器语言。如何让计算机执行高级语言程序呢? 机器语言。如何让计算机执行高级语言程序呢?
编译原理
计算机科学系
学习中应注意的问题
‧一定要预习 一定要预习 ‧上课专心致志 上课专心致志 ‧重视习题 重视习题 ‧确立好学习的角度 确立好学习的角度 ‧重视实践 重视实践
急功近利是学习的一大敌人! 急功近利是学习的一大敌人!
与课程有关的问题
时间安排: ‧ 时间安排: 讲课:48学时 讲课:48学时 实验: 实验:8学时
‧作业:每章所讲内容布置1-2道习题 作业:每章所讲内容布置1 ‧成绩 :以考试为主,参考平时成绩(作业、实践等) 以考试为主,参考平时成绩(作业、实践等)
与课程有关的问题
‧本课程的性质、目的和任务 : 本课程的性质、 本课程是计算机类专业的专业课, 本课程是计算机类专业的专业课,目的是使学生了解并掌握编译程序 的基本理论和方法,具有分析和实现编译程序的初步能力。 的基本理论和方法,具有分析和实现编译程序的初步能力。
中间语言程序(中间代码) 中间语言程序(中间代码)
• 中间语言程序是介于源程序和目标程序之间的一 中间语言程序是介于源程序和目标程序之间的一 种中间形式的程序, 种中间形式的程序,编译程序首先将源程序转换 成中间代码,再将中间代码转换成目标程序, 成中间代码,再将中间代码转换成目标程序,中 间代码的表示形式取决于编译程序下一步将如何 使用和加工它。 使用和加工它。 • 一般来说,对于多趟扫描的编译程序,越到后面 一般来说,对于多趟扫描的编译程序, 的阶段所产生的中间代码形式上越接近于目标程 序。
编译原理lxy第11章

第2页
编译原理 11.1
代码生成器的输入
基本问题
目标程序
指令选择寄存器分配
计算顺序选择
第3页
编译原理 11.2 目标机器模型
假设目标计算机有下列指令形式
第4页
编译原理 指令的意义: 指令的意义:
第5页
编译原理 11.3 一个简单的代码生成器
将每条中间代码变换成目标代码,并在一个基本块范围内考虑充分利用寄存器问题。 将每条中间代码变换成目标代码, 并在一个基本块范围内考虑充分利用寄存器问题。 A:=(B+C)*D+E 例: 高级语言 中间代码 T1:=B+C T2:=T1*D A:=T2+E (1) LD ) R,B (2) ADD R,C (3) ST R,T1 (4) LD R,T1 (5) MUL R,D (6) ST R,T2 (7) LD R,T2 (8) ADD R,E R,A (9)ST 优化: (1) 优化: ) (2) (3) 3 ( 4) (5) LD ADD MUL ADD ST R,B R,C R,D R,E R,A
代码生成算法 假设中间代码形为: 假设中间代码形为: A:=B op C 基本块代码生成算法:对每个中间代码依次执行: 基本块代码生成算法:对每个中间代码依次执行: 315页 (见P315页)
第11页
编译原理 目标代码: 目标代码:
对例11.1假设只有 和R1是可用寄存器,用上算法生成的目标代码和相 假设只有R0和 是可用寄存器 是可用寄存器, 对例 假设只有 应的RVALUE和AVALUE如下表: 如下表: 应的 和 如下表
第7页
编译原理
考察基本块: 考察基本块: T:=A-B U:=A-C V:=T+U W:=V+U W是基本块出口的活跃变量,则有下表
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
代码生成算法 假设中间代码形为: 假设中间代码形为: A:=B op C 基本块代码生成算法:对每个中间代码依次执行: 基本块代码生成算法:对每个中间代码依次执行: 315页 (见P315页)
第11页
编译原理 目标代码: 目标代码:
对例11.1假设只有 和R1是可用寄存器,用上算法生成的目标代码和相 假设只有R0和 是可用寄存器 是可用寄存器, 对例 假设只有 应的RVALUE和AVALUE如下表: 如下表: 应的 和 如下表
目标指令
第6页
编译原理
待用信息 计算变量待用信息算法 1、开始,将基本块中各变量的符号表登记项中的待用信息栏填为“非待 用”,并根据该变量在基本块出口之后是否活跃填写活跃信息栏。 2、从基本块出口到基本块入口由后往前依次处理各中间代码,对每一中间 代码 i:A:=B op C 依次执行: a)将符号表中变量A的待用信息和活跃信息附加到中间代码i上; b)将符号表中变量A的待用信息和活跃信息分别置为“非待用”和 “非活跃”; c)将符号表中变量B和C的待用信息和活跃信息附加到中间代码i上; d)将符号表中变量B和C的待用信息均置为i,活跃信息均置为“活 跃”。 注意:次序不可颠倒。 如果中间代码形式为 A:= op B 或 A:= B 除 不涉及C外步骤完全相同。
第2页
编译原理 11.1
代码生成器的输入
基本问题
目标程序
指令选择.2 目标机器模型
假设目标计算机有下列指令形式
第4页
编译原理 指令的意义: 指令的意义:
第5页
编译原理 11.3 一个简单的代码生成器
将每条中间代码变换成目标代码,并在一个基本块范围内考虑充分利用寄存器问题。 将每条中间代码变换成目标代码, 并在一个基本块范围内考虑充分利用寄存器问题。 A:=(B+C)*D+E 例: 高级语言 中间代码 T1:=B+C T2:=T1*D A:=T2+E (1) LD ) R,B (2) ADD R,C (3) ST R,T1 (4) LD R,T1 (5) MUL R,D (6) ST R,T2 (7) LD R,T2 (8) ADD R,E R,A (9)ST 优化: (1) 优化: ) (2) (3) 3 ( 4) (5) LD ADD MUL ADD ST R,B R,C R,D R,E R,A
第12页
编译原理 各中间代码对应的目标代码
第13页
编译原理 11.4 寄存器分配
如何更有效的分配寄存器。 如何更有效的分配寄存器。
指令执行代价: 指令执行代价:
每条指令的执行代价=每条指令访问主存单元次数+1 每条指令的执行代价=每条指令访问主存单元次数+
对下循环程序段设R0、R1、R2江固定分给某三个变量使用,下面确定这 江固定分给某三个变量使用, 对下循环程序段设 、 、 江固定分给某三个变量使用 三个变量并生成该循环的目标代码。 三个变量并生成该循环的目标代码。
第7页
编译原理
考察基本块: 考察基本块: T:=A-B U:=A-C V:=T+U W:=V+U W是基本块出口的活跃变量,则有下表
设
第8页
编译原理 符号表中的待用及活跃信息
第9页
编译原理
第10页
编译原理
寄存器描述和地址描述 寄存器描述数组RVALUE动态记录个寄存器信息。 RVALUE动态记录个寄存器信息 寄存器描述数组RVALUE动态记录个寄存器信息。 变量地址描述数组AVALUE AVALUE动态记录各变量现行值的 变量地址描述数组AVALUE动态记录各变量现行值的 存放位置。 存放位置。
编译原理
第十一章
目标代码生成
编译原理 目标代码的形式
机器语言代码 所有地址已定位,可立即执行 所有地址已定位, 待装配的机器语言模块 汇编语言代码
代码生成考虑(执行速度): 代码生成考虑(执行速度): 如何使生成的代码较短 如何利用计算机的寄存器, 如何利用计算机的寄存器,减少目标代码中访问存储单元的 次数
第19页
编译原理
第20页
第14页
编译原理
第15页
编译原理
第16页
编译原理 11.5 DAG的目标代码 的目标代码
为生成更有效的目标代码,对基本块中间代码序列,应按怎样的次序生成 为生成更有效的目标代码,对基本块中间代码序列, 器目标代码 例: 基本块中间代码序列为G: 基本块中间代码序列为G: T1:= A+B T2:= C+D E-T2 T3:= E-T2 -T3 T4:= T1-T3
其DAG图如下: DAG图如下 图如下:
第17页
编译原理
第18页
编译原理
用DAG把其改写为G‘: DAG把其改写为 把其改写为G T2:= T3:= T1:= T4:=
C+D E-T2 E-T2 A+B -T3 T1-T3
设R0和R1是两个可使用的寄存器,T4是基本块出口之后的活跃变量, 是两个可使用的寄存器,T4是基本块出口之后的活跃变量, ,T 则生成的目标代码如下: 则生成的目标代码如下: