编译原理语法制导翻译翻译方案SDT
合集下载
06第6章 语法制导翻译技术PPT课件

② E→T
③ T→T*F ⑦ F→b
③ T→T*F@*
④ T→F
⑧ F→c
④ T→F
⑤ F→(E) ⑥ F→a@a ⑦ F→b@b ⑧ F→c@c
➢把中缀表达式文法叫做输入文法;
➢在输入文法上添加动作后形成的文法叫做翻译文法
➢使用中缀表达式文法推导得到终结符号串叫做输入序列;
➢使用翻译文法推导得到的符号串称为活动序列。
E→TE’ E’ →+T@+E’|ε T→FT’
-用T1表示T’
T’ →*F @* T’|ε
T1 ()
F→(E)|a@a| b@b| c@c
{if(ch==‘*’)
{ ch = getnextsymbol();
F ();OUT(“*”); T1 ();
}
else if(ch∈FOLLOW(E’))return;
2020/7/29
#
19
6.5 属性翻译文法
▪ 属性:指与文法符号的类型和值等有关的一些语义信 息,在编译中用属性描述被处理对象的语义特征。
▪ 属性代表与文法符号相关的语义信息。
▪ 属性的设置和语法结构的语义以及翻译程序的需要有
关。例如:
注:教材中用箭头↑和 ↓代替.
➢ 文法符号X的类型属性:X.type
第6章 语法制导翻译技术
2020/7/29
1
标题添加
点击此处输入相 关文本内容
标题添加
点击此处输入相 关文本内容
总体概述
点击此处输入 相关文本内容
点击此处输入 相关文本内容
2
内容提要
➢ 引言 ➢ 翻译文法 ➢ 语法制导翻译 ➢ 自顶向下语法制导翻译 ➢ 属性翻译文法 ➢ 属性文法的自顶向下翻译 ➢ 自底向上语法制导翻译
编译原理课件语法制导翻译__SDD_定义__例__表达式的解释执行
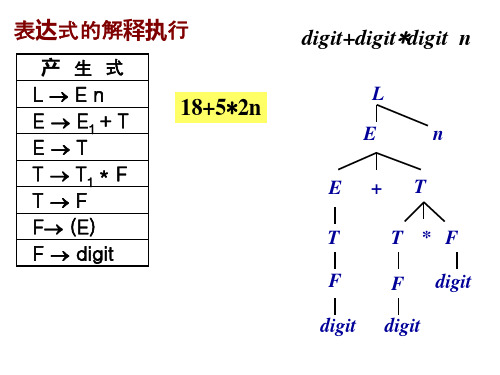
表达式的解释执行
产 生 式 LEn E E1 + T ET T T1 * F TF F (E) F digit
digit+digit*digit n
L E E T F digit +
18+5*2n
n T
T * F F digit digit
语法制导定义 SDD Syntax-Directed Definition
F.val := digit.lexval
E .val = 8
T.val = 8 F.val = 8
+
T .val = 10 T .val = 5 *
F.val = 5 F .val = 2 digit .lexval = 2
digit .lexval = 8
digit .lexval = 5
SDD与属性文法
• 副作用 • 引用透明
LEn
print (E.val)
E E1 + T E.val := E1 .val + T.val
ET
T T1 * F TF
E.val := T.val
T.val := T1.val * F.val T.val := F.val
F (E)
F digit
F.val := E.val
TF
F(E) Fdigit
翻译输入 3*5+4n 所作的动作
L E n { print (statck[top-1].val ); top = top -1; } EE1 + T { statck[top-2].val = statck[top-2].val + statck[top].val; top = top -2; } TT1 * F { statck[top-2].val = statck[top-2].val * statck[top].val; top = top -2; } { statck[top-2].val = F(E) statck[top-1].val top = top -2; }
产 生 式 LEn E E1 + T ET T T1 * F TF F (E) F digit
digit+digit*digit n
L E E T F digit +
18+5*2n
n T
T * F F digit digit
语法制导定义 SDD Syntax-Directed Definition
F.val := digit.lexval
E .val = 8
T.val = 8 F.val = 8
+
T .val = 10 T .val = 5 *
F.val = 5 F .val = 2 digit .lexval = 2
digit .lexval = 8
digit .lexval = 5
SDD与属性文法
• 副作用 • 引用透明
LEn
print (E.val)
E E1 + T E.val := E1 .val + T.val
ET
T T1 * F TF
E.val := T.val
T.val := T1.val * F.val T.val := F.val
F (E)
F digit
F.val := E.val
TF
F(E) Fdigit
翻译输入 3*5+4n 所作的动作
L E n { print (statck[top-1].val ); top = top -1; } EE1 + T { statck[top-2].val = statck[top-2].val + statck[top].val; top = top -2; } TT1 * F { statck[top-2].val = statck[top-2].val * statck[top].val; top = top -2; } { statck[top-2].val = F(E) statck[top-1].val top = top -2; }
语法制导翻译【共41张PPT】

一个属性文法称为L-属性文法,如果对于每个产生式
int T_val, R_i, R_s; int E_val;
AX1X2Xn,其中每条语义规则中的每个属性或者
是综合属性,或者是X (1jn)的一个继承属性且这 (3) E→(E(1))
val[ntop]= val[top–1]
使用标记非终结符M和N改写为
2. 函数过程A的代码(指用符号形式表示的数据和程序)
要根据当前的输入符号来决定使用哪一个产生式。
3. 与每一个产生式有关的代码,从左到右根椐产生式右部是
终结符(单词符号)、非终结符号还是语义动作,分别处 理:
保存下来,以便以后语义子程序引用这些信息。
原LR分析器的分析栈也加以扩充,存放三类信息:分析
状态、文法符号及文法符号对应的语义值。
top
sk
Xk
Xk.val
... ... ...
s1
X1
X1.val
s0
#
_
状态 文法符号 语义值
扩充后的LR分析栈
例6-3 考虑下面的语法制导定义
产生式
语义规则
9–5+2的带语义动作的分析树
设计翻译模式(根据语法制导定义)
语法制导定义是L-属性文法 保证语义动作不会引用还没有计算的属性值。
只需要综合属性的情况
为每一个语义规则建立一个包含赋值的动作,并把这个 动作放在相应的产生式右边的末尾。
例如:T T(1)*F T.val:=T(1).val*F.val
产生式 语义规则 A LM L.i:=l(A.i)
M.i:=m(L.s) A.s:=f(M.s) A QR R.i:=r(A.i) Q.i:=q(R.s) A.s:=f(Q.s)
编译第七章语法制导翻译

16
第一节 概述
-------树形表示法
-------三元式
-------四元式:最常用的形式
精选PPT
第七章中间代码的生成 1 2
第一节 概述
❖ 二、翻译方法
1、语法制导翻译
----在语法分析的基础上进行边分析边翻译。
●注:1)语法制导翻译时会根据文法产生式右部符 号串的含义进行翻译,翻译的结果是生成相应中间 代码。
精选PPT
15
第一节 概述
❖ 四、常见的中间代码形式 ❖ 2.三元式 ❖ (Operator,Operand1, Operand2) ❖ 注:1)这里三元式本身作为存放结果的单元。
2)为了在其它三元式中利用当前三元式的结果, 需要对三元式进行遍号。三元式的编号就作为相应 三元式的结果值。
精选PPT
第七章语法制导翻 译和中间代码生成
精选PPT
1
第一节 概述
❖ 语法分析之后,编译的任务是由已识别为正确的源程 序生成一组规格一致,便于计算机加工的指令形式。
一、中间代码生成方法
语法制导翻译,属性文法制导翻译
二、中间代码
●中间代码:不是机器语言,便于生成机器语言,便于代 码优化。
●中间代码的形式:
-------逆波兰式
S3
S2
r4
r4
S3
S2
S3
S2
S4
S5
r1(S4) S5(r1)
r1(S4) r2(S5)
r3
r3
精选PPT
)#
acc
r4 r4
S9 r1 r1 r2 r2 r3 r3
GOTO S 1 6 7 8
13
步骤 状态
编译原理 第5章语法制导的翻译

属性和文法符号相关联 规则和产生式相关联
根据需要,将文法符号和某些属性相关联, 并通过语义规则来描述如何计算属性的值
E→E1+T E.code=E1.code || T.code || ‘+’ code表示了我们关心的表达式的逆波兰表示,规则说明 加法表达式的逆波兰表示由两个分量的逆波兰表示并置, 然后加上‘+’得到。
digitlexval=3
18
适用于自顶向下分析的SDD
前面的表达式文法存在直接左递归,因 此无法直接用自顶向下方法处理。 消除左递归之后,无法直接使用属性val 进行处理:
比如规则:T→FT’ T’→*FT’ T对应的项中,第一个因子对应于F, 而运算符在T’中。
19
相同表达式的不同文法的比较
38
例5.15 分析栈实现的例子
假设语法分析栈存放在一个被称为stack 的记录数组中,下标top指向栈顶;
stack[top]指向这个栈的栈顶;stack[top-1] 指向栈顶下一个位置; 如果不同的文法符号有不同的属性集合,我 们可以使用union来保存这些属性值。(归 约时,我们知道栈顶向下的各个符号分别是 什么)
语义翻译的流程
输 入 符 号 串 分 析 树 依 赖 图
语
义
规
则
的 计
实际上,编译中语义翻译的实现并不是 按图中的流程处理的;而是随语法分析 的进展,识别出一个语法结构,就对它 的语义进行分析和翻译。
算
9
5.1 语法制导定义
4.什么是语法制导定义(SDD) 上下文无关文法和属性/规则的结合;
第五章++语法制导翻译(2)

X.x Y.y Z.z top
编译原理
4
L→En E → E1 + T E→T T → T1 * F T→F F→ (E) → F → digit
{ print (E.val); } { E.val := E1 .val + T.val;} { E.val := T.val;} { T.val := T1.val × F.val ;} { T.val := F.val; } { F.val := E.val; } { F.val := digit.lexval; }
编译原理 31
表达式9 5+2的计算 表达式9-5+2的计算
E val T.val=9 num.val=9 i=9Rs
-
T.val=5
i=4Rs i=6Rs
num.val=5 + T.val=2 num.val=2
编译原理
ε
32
例5.15 转换后的构造语法树的翻译模式
E→T R R→+ T R1 R→T R1 R→ε T→( E ) T → id T → num
A → A1Y A→X { A.a := g (A1.a, Y.y) } { A.a := f (X.x) }
消除左递归后: A→X { R.i := f (X.x) } R { A.a := R.s } R→Y { R1.i := g (R.i, Y.y) } R1 { R.s := R1.s } R→ε { R.s := R.i }
编译原理
8
例5.16 翻译为前缀表达式
L→En E → {print(‘+’)} E1+ T E→T T → {print(‘*’)} T1* F T→F F → (E) F → digit {print(digit.lexval)}
属性文法和语法制导翻译

赋值语句的语法树
assignment variable expression
在语法树中,运算符号和关键字都不在叶结 点,而是在内部结点中出现。
《编译技术》课程 北京大学信息科学技术学院
2015年春季学期
5
具体语法树 vs. 抽象语法树
if (x+y) { while (z) z=z+1 od; x =8 } else z = 7 fi $ 的具体语法树 (分析树)
北京大学信息科学技术学院 2015年春季学期 《编译技术》
第5章 语法制导翻译(2)
Syntax-Directed Translation 【第5.3, 5.4节】
回顾:语法制导定义(SDD)
为每个符号X添加相应的属性X.x,对于产生 式A->XYZ
综合属性:A.a = f (A.i, X.x, Y.y, Z.z) 继承属性:Y.i = g (A.a, X.x, Y.y, Z.z)
2015年春季学期
《编译技术》课程
北京大学信息科学技术学院
26
top
state ... X Y Z
val ... X.x Y.y Z.z
state
val ... A.a
top
... A
定义 A.a=f(X.x, Y.y, Z.z)(抽象表示)对应的动作 stack[top-2].val = f(stack[top-2].val, stack[top-1].val, stack[top].val); top = top-2;
把语义动作看成终结符号,输入 9-5+2, 其分析树见 下页,当按深度优先遍历它,执行遍历中访问的语 义动作,将输出
编译原理课件语法制导翻译__翻译方案_SDD

语法制导翻译
描述一棵语法树中结点的属性之间的 相互依赖关系 词法分析 语法分析 依赖图 输入串 语法树 语义规则计算次序 ( 拓扑排序) 树遍历
一遍扫描:在语法分析的同时完成语义规则的 计算, 无需构造实际的语法树
1. 依赖图的拓扑排序
• 依赖图 • 拓扑排序
2. 树遍历的属性计算方法
练习: 以下SDD是L-属性的吗?
产生式 语义规则
ALM
AQR
L.i := l(A.i) M.i := m(L.s) A.s := f(M.s) R.i := r(A.i) Q.i := q(R.s) A.s := f(Q.s)
• 表达式2 ☆
dependencygraph edges can go from left to right
(2) 产生式 Xj 的左边符号 X1,X2,…,Xj-l 的属性
(3) Xj 自己的属性
• S-属性文法一定是L-属性文法 表达式 ☆
Example 非L-属性文法
产生式 A BC 语义规则 A.s = B.b B.i = f ( C.c , A.s )
Fig. Syntax-directed definition of a simple desk calculator
L-属性文法 D TL 和自上而下 T int 语法分析 T real
L L1, id D T .type = real real
综T.type T. type := integer T. type := real L1.in := L.in; addtype (id.entry,L.in ) addtype (id.entry,L.in )
(a)初始状态 (b)VisitNode(S)第一次调用后 (c)VisitNode(S)第二次调用后 (d)VisitNode(S)第三次调用后 的最终状态
描述一棵语法树中结点的属性之间的 相互依赖关系 词法分析 语法分析 依赖图 输入串 语法树 语义规则计算次序 ( 拓扑排序) 树遍历
一遍扫描:在语法分析的同时完成语义规则的 计算, 无需构造实际的语法树
1. 依赖图的拓扑排序
• 依赖图 • 拓扑排序
2. 树遍历的属性计算方法
练习: 以下SDD是L-属性的吗?
产生式 语义规则
ALM
AQR
L.i := l(A.i) M.i := m(L.s) A.s := f(M.s) R.i := r(A.i) Q.i := q(R.s) A.s := f(Q.s)
• 表达式2 ☆
dependencygraph edges can go from left to right
(2) 产生式 Xj 的左边符号 X1,X2,…,Xj-l 的属性
(3) Xj 自己的属性
• S-属性文法一定是L-属性文法 表达式 ☆
Example 非L-属性文法
产生式 A BC 语义规则 A.s = B.b B.i = f ( C.c , A.s )
Fig. Syntax-directed definition of a simple desk calculator
L-属性文法 D TL 和自上而下 T int 语法分析 T real
L L1, id D T .type = real real
综T.type T. type := integer T. type := real L1.in := L.in; addtype (id.entry,L.in ) addtype (id.entry,L.in )
(a)初始状态 (b)VisitNode(S)第一次调用后 (c)VisitNode(S)第二次调用后 (d)VisitNode(S)第三次调用后 的最终状态