编译原理教程第八章课后习题答案
编译原理第8章作业及习题参考答案
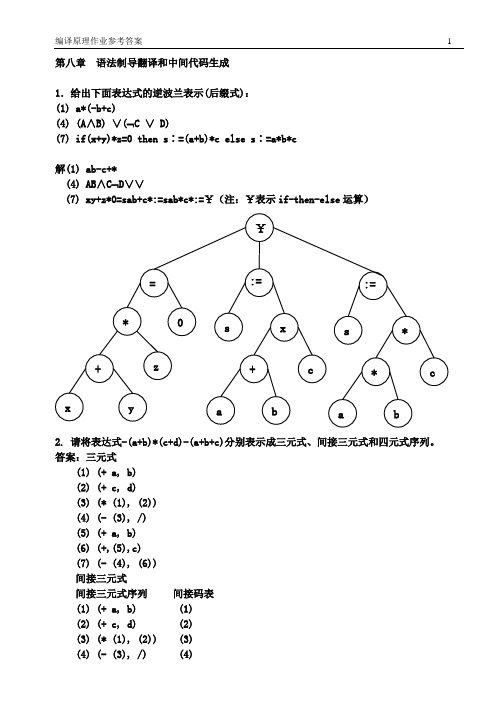
第八章 语法制导翻译和中间代码生成1.给出下面表达式的逆波兰表示(后缀式): (1) a*(-b+c)(4) (A ∧B) ∨(⌝C ∨ D)(7) if(x+y)*z=0 then s ∶=(a+b)*c else s ∶=a*b*c解(1) ab-c+*(4) AB ∧C ⌝D ∨∨(7) xy+z*0=sab+c*:=sab*c*:=¥(注:¥表示if-then-else 运算)2. 请将表达式-(a+b)*(c+d)-(a+b+c)分别表示成三元式、间接三元式和四元式序列。
答案:三元式(1) (+ a, b) (2) (+ c, d)(3) (* (1), (2)) (4) (- (3), /) (5) (+ a, b)(6) (+,(5),c) (7) (- (4), (6)) 间接三元式间接三元式序列 间接码表 (1) (+ a, b) (1) (2) (+ c, d) (2) (3) (* (1), (2)) (3) (4) (- (3), /) (4)¥= :=*:=+ xyzs +cxa bs* c*a b(5) (- (4), (1)) (1)(6) (- (4), (5)) (5)(6)四元式(1) (+, a, b, t1) (2) (+, c, d, t2) (3) (*, t1, t2, t3) (4) (-, t3, /, t4)(5) (+, a, b, t5) (6) (+, t5, c, t6) (6) (-, t4, t6, t7)3. 采用语法制导翻译思想,表达式E 的"值"的描述如下: 产生式 语义动作(0) S ′→E {print E.VAL}(1) E →E1+E2 {E.VAL ∶=E1.VAL+E2.VAL} (2) E →E1*E2 {E.VAL ∶=E1.VAL*E2.VAL} (3) E →(E1) {E.VAL ∶=E1.VAL} (4) E →n {E.VAL ∶=n.LEXVAL}如果采用LR 分析法,给出表达式(5 * 4 + 8) * 2的语法树并在各结点注明语义值VAL 。
编译原理一些习题答案

第2章形式语言基础2.2 设有文法G[N]: N -> D | NDD -> 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9(1)G[N]定义的语言是什么?(2)给出句子0123和268的最左推导和最右推导。
解答:(1)L(G[N])={(0|1|2|3|4|5|6|7|8|9)+} 或L(G[N])={α| α为可带前导0的正整数}(2)0123的最左推导:N ⇒ ND ⇒ NDD ⇒ NDDD ⇒ DDDD ⇒ 0DDD ⇒ 01DD ⇒ 012D ⇒ 0123 0123的最右推导:N ⇒ ND ⇒ N3 ⇒ ND3 ⇒ N23 ⇒ ND23 ⇒ N123 ⇒ D123 ⇒ 0123268的最左推导:N ⇒ ND ⇒ NDD ⇒ DDD ⇒ 2DDD ⇒ 26D ⇒ 268268的最右推导:N ⇒ ND ⇒ N8 ⇒ ND8 ⇒ N68 ⇒ D68 ⇒ 2682.4 写一个文法,使其语言是奇数的集合,且每个奇数不以0开头。
解答:首先分析题意,本题是希望构造一个文法,由它产生的句子是奇数,并且不以0开头,也就是说它的每个句子都是以1、3、5、7、9中的某个数结尾。
如果数字只有一位,则1、3、5、7、9就满足要求,如果有多位,则要求第1位不能是0,而中间有多少位,每位是什么数字(必须是数字)则没什么要求,因此,我们可以把这个文法分3部分来完成。
分别用3个非终结符来产生句子的第1位、中间部分和最后一位。
引入几个非终结符,其中,一个用作产生句子的开头,可以是1-9之间的数,不包括0,一个用来产生句子的结尾,为奇数,另一个则用来产生以非0整数开头后面跟任意多个数字的数字串,进行分解之后,这个文法就很好写了。
N -> 1 | 3 | 5 | 7 | 9 | BNB -> 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | B02.7 下面文法生成的语言是什么?G1:S->ABA->aA| εB->bc|bBc G2:S->aA|a A->aS解答:B ⇒ bcB ⇒ bBc⇒ bbccB ⇒ bBc⇒ bbBcc ⇒ bbbccc……A ⇒εA ⇒ aA ⇒ aA ⇒ aA ⇒ aaA ⇒ aa……∴S ⇒ AB ⇒ a m b n c n , 其中m≥0,n≥1即L(G1)={ a m b n c n | m≥0,n≥1} S ⇒ aS ⇒ aA ⇒ aaS ⇒ aaaS ⇒ aA ⇒ aaS ⇒ aaaA ⇒aaaaS ⇒ aaaaa ……∴S ⇒ a2n+1 , 其中n≥0即L(G2)={ a2n+1 | n≥0}2.11 已知文法G[S]: S->(AS)|(b)A->(SaA)|(a)请找出符号串(a)和(A((SaA)(b)))的短语、简单短语和句柄。
编译原理,清华大学,第2版_第8章 语法制导翻译和中间代码生成

将if-then-else看作一个完整的操作符,则e、x和 y 分别是三个操作数,这显然是一个三元运算。根据后缀式 的特点,它的后缀式可以写为:
exy if-then-else(记为: exy¥) 但是,这样的表示有个弱点。按照算法的计算次序,e、 x和y均需计算,而实际上,根据条件e的取值,计算x则不 计算y,计算y则不计算x。
一、逆波兰表示 典型特征是操作数在前,操作符紧跟其后。 特点:由于操作符紧跟操作数之后,因此只要知道操作 符有几个操作数,每一步的运算就可以确定。
1、 表达式的表示:
例:a+b 例:-a+b*c 例: (a+b)*c ab+ a@bc*+ ab+c* <左部><表达式的逆波兰式> ::=
2、 赋值语句的逆波兰表示:
E → E1 + E2
E → E1 * E2 E → (E1) E → num
E.val := E1.val + E2.val;
val[top] := val[top]+val[top+2];
E.val := E1.val * E2.val; E.val := E1.val; E.val := num.lexval;
第八章 语法制导翻译和中间代码生成
• 教学要求:本章介绍编译程序的第三个阶段语 义分析及中间代码生成的设计原理和实现方法,
要求理解语法制导翻译、语义动作的基本概念;
掌握语义规则和中间代码的表示形式。 • 教学重点:语义规则,中间代码的表示形式, 自下而上分析制导翻译概述。
语义处理功能: • 1、静态语义审查:验证语法结构合理 的程序是否真正有意义。 • 2、解释执行动态语义、生成代码:执 行真正的翻译(生成中间代码或目标代 码)。
编译原理清华大学出版社第8章习题重点题解答

1、已知文法:A → aAd|aAb|ξ判断该文法是否是SLR(1)文法,若是构造相应分析表,并对输入串 #ab# 给出分析过程。
解:(0) A’→ A(1)A → aAd(2) A → aAb(3) A →ξ构造该文法的活前缀DFA:由上图可知该文法是SLR(1)文法。
构造SLR(1)的分析表:3、考虑文法:S →AS|b A→SA|aFollow(A) = first(S) = {b}+first(A)= {a,b}(1)列出这个文法的所有LR(0)项目(2)按(1)列出的项目构造识别这个文法活前缀的NFA,把这个NFA确定化为DFA,说明这个DFA的所有状态全体构成这个文法的LR(0)规范族。
(3)这个文法是SLR的吗?若是,构造出它的SLR分析表。
(4)这个文法是LALR或LR(1)的吗?解:(0)S’→S (1)S→AS (2)S→b (3)A→SA (4)A→a(1)列出所有LR(0)项目:S’→·S S→·b A→·a S’→ S· S→b· A→a·S →·AS A→·SAS →A·S A→S·AS →AS· A→SA·(3)构造该文法的活前缀NFA:由上可知:I1 I3 I5 中存在着移进和归约冲突在I1中含项目:S’→ S·归约项 Follow(S’)={#}A →·a 移进项 Follow(S’)∩{a}=∮S →·b 移进项 Follow(S’)∩{b}=∮在I3中含项目:A →SA·归约项 Follow(A)={a,b}S →·b 移进项 Follow(A) ∩ {b}≠∮A →·a 移进项 Follow(A) ∩ {a}≠∮在I5中含项目:S →AS·归约项 Follow(S)={#,a,b}A →·a 移进项 Follow(S) ∩ {a}≠∮S →·b 移进项 Follow(S) ∩ {b }≠∮由此可知,I3、I5的移进与归约冲突不能解决,所以这个文法不是SLR (1)文法。
胡元义版编译原理课后习题答案

则文法G[S′]的LR(0)项目集示范族为 I0:S′→·S I4:S→a· I10:L→S;·L I5 : S→while e· do s I6 : S→begin L·end I7 : L→S· S→·while e do S L→·S S→·begin L end L→·S;L S→·a S→·while e do S
所有外层分程序的符号表都无法找到此标识符,则表
明程序中使用了一个未经说明 ( 定义 )的标识符,此时 可按语法错误予以处理。
8.4 对下列程序,当编译程序编译到箭头所指位 置时,画出其层次表(分程序索引表)和符号表: program stack(output); var m, n:integer; r:real;
w h ile L S ; I4 I7 a s I1 0 I6 b eg in en d I9 w h ile L I1 2 a
图8-2 习题8.5中文法G[S′]的DFA
在 LR(0) 项 目 集 规 范 族 中 , 只 有 I7 含 有 “ 移 进”/“归约”冲突,且该冲突可用SLR(1)方法解决。
图8-1 分程序索引表和符号表示意图
8.5 已知文法G[S]: S→while (e) S S→{L}
S→a
L→S;L L→S
/*a代表赋值句*/
构造该文法的LR型的错误校正分析程序。
【解答】 首先将文法G[S]拓广为G[S′]:(0) S′→S (1) S→while e do S
(2) S→begin L end
号的处理,这就需要用到语法符号的相关属性。为了在需
要时能找到这些语法成分及其相关属性,就必须使用一些 表格来保存这些语法成分及其属性,这些表格就是符号表。
编译原理 第八章

② for(i=6,j=0; j<i; ++j) fun(i); 在六次循环中,i的值保持为6,则可优化为: for(i=6,j=0;j<6; ++j) fun(6);
3. 综合使用常数传播和常数合并进行优化处理 为了对保持定值的所有变量之值进行跟踪,建立一个局部符号表,使 每一个活动的变量在该表中有一个登记项,每当对这些变量进行再定 值时,就相应的修改其登记项中的内容。 例: t1=1; t1+=5; 优化为: t1=6; t2=t1; t2=6;
一. 强度削弱
用一种(或一串)执行时间较短的操作去等价的代替一个操作。 1. x*2n 替换为 x<<n (乘法用左移运算替换) x/2n 替换为 x>>n x%2n 替换为 x&(2n-1) 2. 乘以一个较小的整数可以用多个加法代替 x*=3 替换为 x1=x; x+= x1; x+= x1; 3. 较大整数的乘法可以联合使用位移和加法进行强度削弱优化 x*=9 替换为 x1=x; x*=27 替换为 x1=x; x1<<=3; x1<<=1; x+= x1; x+= x1; x1<<=2; x+= x1; x1<<=1; 4. 对于非算术运算进行强度削弱的情形 x+= x1; 例如:许多机器有多种形式的转移指令, 优化程序可以从其中选择效率更高的指令。
三. 无用变量与无用代码的删除
1. 无用变量:变量的最后一次引用到对该变量再置初值期间,可视为无用 变量。在变量的无用期间,对该变量的所有定值(如赋值)指令均可删去。 例: t=a; t+=5; x=t; …… /*此后的一个时间间隔内,t成为无用变量*/ t=c; /*在t的无用期内,对t的定值可以删除*/ …… t=b; /*t被再次置初值,无用期结束*/ y=t+a;
编译原理第八章
2013年8月21日2时45分
(3) 在符号表的信息栏中引入一个指针域(previous)用以 链接它在同一过程内的前一域名字在表中的下标(相对位 置)。每一层的最后一个域名字,其previous之值为0。这 样,每当需要查找一个新名字时,就能通过DISPLAY找出 当前正在处理的最内层的过程及所有外层的子符号表在栈 符号表中的位置。然后,通过previous可以找到同一过程 内的所有被说明的名字。
2013年8月21日2时45分
8.4 符号表的内容
符号表的信息栏中登记了每个名字的有关的性质,如类型、 种属、大小以及相对数。 对于变量名、数组名和过程名,信息栏中一般有下列信息: (1)变量 类型(整数、实、双实、布尔、字符、复、标号 或指针); 种属(简单变量、数组或记录结构); 长度(所需的存储单元数); 相对数(存储单元数); 若为数组,则记录其内情况向量。
2013年8月21日2时45分
杂凑技术
对于表格处理来说,根本问题在于如何保证查表与填表两 方面的工作都能高效地进行。对于线性表来说,填表快, 查表慢。而对于对折法而言,则填表慢,查表快。杂凑法 正是一种争取查表、填表两方面都能高速进行的统一技术。 这种办法是:假定有一个足够大的区域,这个区域以填写 一张含N项的符号表。构造一个地址函数H。对于地址函 数H有两点要求:第一,函数的计算要简单、高效;第二, 函数值能比较均匀地分布。对于杂凑技术还应设法解决 “地址冲突”的问题。
2013年8月21日2时45分
8.2 整理与查找
符号表作为一个多元组,表中元组的排列组织是构造符号 表的重要成分。在编译程序的整个工作过程中,符号表被 频繁地用来建立表项,找查表项,填充和引用表项的属性 。因此表项的排列组织对该系统运行的效率起着十分重要 的作用。在编译程序中,符号表项的组织传统上采用三种 构造方法。即线性法,二分法及散列法。
编译原理课后题答案【清华大学出版社】ch8
如果题目是 S::=L.L | L L::=LB | B B::=0 | 1 则写成: S`::=S {print(S.val);} S::=L1.L2 { S.val:=L1.val+L2.val/2L2.length ;} S::= L { S.val:=L.val; } L::=L1B { L.val:=L1.val*2+B.val; L.length:=L1.length+1; } L::=B { L.val:=B.val; L.length:=1;} B::=0 { B.val:=0; } B::=1 { B.val:=1;}
如采用 LR 分析方法,给出表达式(5*4+8)*2 的语法树并在各结点注明语义值 VAL。
答案:
计算机咨询网()陪着您
5
缄默TH浩的小屋
《编译原理》课后习题答案第八章
采用语法制导翻译思想,表达式 E 的“值”的描述如下:
产生式
语义动作
(0) S′→E
{print E.VAL}
四元式:
100 (+, a, b, t1) 101 (+, c, d, t2) 102 (*, t1, t2, t3) 103 (-, t3, /, t4) 104 (+, a, b, t5) 105 (+, t5, c, t6) 106 (-, t4, t6, t7)
树形:
计算机咨询网()陪着您
计算机咨询网()陪着您
6
缄默TH浩的小屋
《编译原理》课后习题答案第八章
第5题
令 S.val 为下面的文法由 S 生成的二进制数的值(如,对于输入 101.101,S.val=5.625); SÆL.L | L LÆLB | B BÆ0 | 1
编译原理习题答案,1-8章龙书第二版7.8章
第七章
习题7.2.6 :C语言函数f的定义如下:
Int f(int x, *py, **ppz){
**ppz +=1;*py +=2;x +=3; return x+*py+**ppz;
}
变量a是一个指向b的指针;变量b是一个指向c的指针,而c是一个当前值为4的整数变量。
如果我们调用f(c,b,a),返回值是什么?
答:x是传值,而b和c是传地址方式;由函数定义可以得到:b=&c,a=&b, 而**a=**a+1=c+1=5 => c=5; *b=*b+2=c+2=7 =>c=7,**a=7;c=c+3=4+3=7
所以调用f(c,b,a)返回值是7+7+ 7=21
练习7.3.2:假设我们使用显示表来实现下图中的函数。
请给出对fib0(1)的第一次调用即将返回时的显示表。
同时指明那时在栈中的各种活动记录中保存的显示表条目
答:结果如下
第八章
练习8.2.1:假设所有的变量都存放在内存中,为下面的三地址语句生成代码:
5)下面的两个语句序列
X=b*c
Y=a+X
答:生成的代码如下
练习8.5.1:为下面的基本块构造构造DAG
d=b*c
e=a+b
b=b*c
a=e-d
答:DAG如下
练习8.6.1:为下面的每个C语言赋值语句生成三地址代码1)x=a+b*c
答:生成的三地址代码如下。
编译原理练习题及答案
第一章练习题(绪论)一、选择题1.编译程序是一种常用的软件。
A) 应用B) 系统C) 实时系统D) 分布式系统2.编译程序生成的目标代码程序是可执行程序。
A) 一定B) 不一定3.编译程序的大多数时间是花在上。
A) 词法分析B) 语法分析C) 出错处理D) 表格管理4.将编译程序分成若干“遍”将。
A)提高编译程序的执行效率;B)使编译程序的结构更加清晰,提高目标程序质量;C)充分利用内存空间,提高机器的执行效率。
5.编译程序各个阶段都涉及到的工作有。
A) 词法分析B) 语法分析C) 语义分析D) 表格管理6.词法分析的主要功能是。
A) 识别字符串B) 识别语句C) 识别单词D) 识别标识符7.若某程序设计语言允许标识符先使用后说明,则其编译程序就必须。
A) 多遍扫描B) 一遍扫描8.编译方式与解释方式的根本区别在于。
A) 执行速度的快慢B) 是否生成目标代码C) 是否语义分析9.多遍编译与一遍编译的主要区别在于。
A)多遍编译是编译的五大部分重复多遍执行,而一遍编译是五大部分只执行一遍;B)一遍编译是对源程序分析一遍就立即执行,而多遍编译是对源程序重复多遍分析再执行;C)多遍编译要生成目标代码才执行,而一遍编译不生成目标代码直接分析执行;D)多遍编译是五大部分依次独立完成,一遍编译是五大部分交叉调用执行完成。
10.编译程序分成“前端”和“后端”的好处是A)便于移植B)便于功能的扩充C)便于减少工作量D)以上均正确第二章练习题(文法与语言)一、选择题1.文法 G 产生的 (1) 的全体是该文法描述的语言。
A.句型B. 终结符集C. 非终结符集D. 句子2.若文法 G 定义的语言是无限集,则文法必然是 (2) A递归的 B 上下文无关的 C 二义性的 D 无二义性的3. Chomsky 定义的四种形式语言文法中, 0 型文法又称为(A)文法;1 型文法又称为(C)文法;2 型语言可由(G) 识别。
A 短语结构文法B 上下文无关文法C 上下文有关文法D 正规文法E 图灵机F 有限自动机G 下推自动机4.一个文法所描述的语言是(A);描述一个语言的文法是(B)。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
编译原理作业第八章符号表与错误处理
8.1 完成下列选择题:
(1) 编译程序使用b区别标识符的作用域。
a. 说明标识符的过程或函数名
b. 说明标识符的过程或函数的静态层次
c. 说明标识符的过程或函数的动态层次
d. 标识符的行号
(2) 在目标代码生成阶段,符号表用于 d 。
a. 目标代码生成
b. 语义检查
c. 语法检查
d. 地址分配
(3) 错误的局部化是指c。
a. 把错误理解成局部的错误
b. 对错误在局部范围内进行纠正
c. 当发现错误时,跳过错误所在的语法单位继续分析下去
d. 当发现错误时立即停止编译,待用户改正错误后再继续编译
【解答】(1) b (2) d (3) c
8.2 在编译过程中为什么要建立符号表?
答:在编译过程中始终要涉及到对一些语法符号的处理,这就需要用到语法符号的相关属性。
为了在需要时能找到这些语法成分及其相关属性,就必须使用一些表格来保存这些语法成分及其属性,这些表格就是符号表。
8.3 对出现在各个分程序中的标识符,扫描时是如何处理的?
答:对扫描到各分程序中的标识符的处理方法如下:
(1) 当在一个分程序首部某说明中扫描到一个标识符时,就以此标识符查找相应于本层分程序的符号表。
如果符号表中已有此名字的登记项,则表明此标识符已被重复说明(定义),应按语法错误进行处理;否则,在符号表中新登记一项并将此标识符及有关信息(种属、类型、所分配的内存单元地址等)填入。
(2) 当在一分程序的语句中扫描到一个标识符时,首先在该层分程序的符号表中查找此标识符;若查不到,则继续在其外层分程序的符号表中查找。
如此下去,一旦在某一外层分程序的符号表中找到标识符,则从表中取出有关的信息并作相应的处理;如果查遍所有外层分程序的符号表都无法找到此标识符,则表明程序中使用了一个未经说明(定义)的标识符,此时可按语法错误予以处理。
8.4 对下列程序,当编译程序编译到箭头所指位置时,画出其层次表(分程序索引表)和符号表:
program stack(output);
var m, n:integer;
r:real;
procedure setup(ns:integer, check:real);
var k, l:integer;
function total(var at:integer, nt:integer):integer;
var i, sum:integer;
begin
for i:=1 to nt do sum:=sum+at[i]; total:=sum; end; begin
l:=27+total(a,ns); <----------------- end; begin n:=4; setup(n,5.75)
end.
答: 编译程序编译到箭头所指位置时,其层次表(分程序索引表)和符号表如图8-1所示。
图8-1 分程序索引表和符号表示意图
8.5 已知文法G[S]: S →while (e) S S →{L}
S →a /*a 代表赋值句*/ L →S;L L →S
构造该文法的LR 型的错误校正分析程序。
答:首先将文法G[S]拓广为G[S ′]:(0) S ′→S (1) S →while e do S (2) S →begin L end (3) S →a (4) L →S
1110987654321
符号表
表
(5) L →S ;L
则文法G[S ′]的LR(0)项目集示范族为 I0:S ′→·S I4:S →a· I10:L →S ;·L S →·while e do S I5:S →while e· do s L →·S S →·begin L end I6:S →begin L·end L →·S ;L S →·a I7:L →S·
S →·while e do S
I1:S ′→S· L →S· ;L S →·begin L end I2:S →while·e do s I8:S →while e do·S S →·a I3:S →begin·L end S →· while e do s I 11:S →while e do S· L →·S S →·begin L end I12:L →S ;L·
L →·S ;L S →·a S →·while e do s I9:S →begin L end· S →·begin L end
S →·a 将这些项目集的转换函数G O 表示为如图8-2所示的DFA 。
图8-2 习题8.5中文法G[S ′]的DFA
在LR(0)项目集规范族中,只有I7含有“移进”/“归约”冲突,且该冲突可用SLR(1)方法解决。
为此计算文法G[S ′]中每个非终结符的FOLLOW 集如下: FOLLOW(S ′)={#}
FOLLOW(S)={end,;,#} FOLLOW(L)={end}
由此构造出包括错误校正处理子程序的SLR(1)分析表如表8-1所示。
a
表8-1 习题8.5的SLR(1)分析表
由表中可以看出,在状态7面对输入符号为“;”时移进,而面对输入符号为“end”时为归约。
表中ei(i=1~7)代表不同的错误处理子程序,其含义和功能分别如下:
(1) 输出符号错处理程序e0:删除当前输入符号,显示出错信息“输入符号错”。
(2) 输入不匹配错误处理程序e1:去除栈顶状态和栈顶符号,显示出错信息“输入不匹配”。
(3) 缺语句错误处理程序e2:将假想符号a与状态4压栈,显示出错信息“缺少语句”。
(4) while语句缺少布尔量处理程序e3:将假想符号e与状态5压栈,显示出错信息“缺布尔量”。
(5) 缺少分号错误处理程序e4:将分号“;”插入未扫描的输入串首,显示出错信息“缺少分号”。
(6) while语句缺少do处理程序e5:将符号“do”与状态8压栈,显示出错信息“缺少do”。
(7) begin与end不配对,缺少end处理程序e6:将符号“end”与状态9压栈,显示出错信息“缺少end”。
(8) 缺少语句错误处理e7:将假想符号a插入未扫描的输入串首,显示出错信息“缺少语句”。