OCR文字识别系统
OCR简介演示

性能分析方法
对比分析
通过与其他OCR系统或算法进行对比,可以直观地评估出本系统 在性能上的优劣。
误差分析
通过对识别结果进行误差分析,找出导致性能下降的关键因素,为 后续的性能优化提供依据。
瓶颈分析
通过对OCR系统各个模块的性能进行瓶颈分析,找出制约整体性能 的短板,从而有针对性地进行优化。
性能优化建议
算机可编辑和检索的格式的技术
。
应用广泛
这种技术主要应用于扫描和识别 印刷或手写文档,使得这些文档 能够被计算机处理和分析。
OCR发展历程
初期阶段
OCR技术最初在20世纪60年代 开始发展,当时的技术基于传统 的图像处理方法和模式识别算法
。
技术演进
随着深度学习技术的快速发展, 现代的OCR系统大多基于深度学 习模型,如卷积神经网络(CNN )和循环神经网络(RNN)。
特征提取
提取字符的特征,如线条 、拐角和闭合区域等,用 于后续的分类和识别。
分类识别
利用机器学习或深度学习 算法,将提取的特征与已 知的字符库进行匹配,实 现字符的识别。
后处理
校验和修正
对识别结果进行校验,对 于识别错误的字符进行修 正,提高整体识别率。
格式转换
将识别的结果转换为所需 的格式,如TXT、DOC或 PDF等,以满足用户的不 同需求。
总结与展望 OCR技术总结
跨语言识别
随着全球化进程的加速,OCR技术将更加注重跨语言识别,支持更多语种和字符 集,促进国际间的信息交流与合作。
与其他技术融合
OCR技术将与自然语言处理、计算机视觉等技术进一步融合,实现更加智能化的 文本识别和理解,推动人工智能技术的整体进步。
THANKS
ocr文字识别技术总结

ocr文字识别技术总结OCR文字识别技术总结随着数字化时代的到来,大量的纸质文档需要转化为电子文件,使得OCR(Optical Character Recognition,光学字符识别)技术逐渐成为热门技术。
OCR技术的发展,为我们提供了一种高效、准确的方式来将纸质文档转化为可编辑的电子文件。
本文将对OCR文字识别技术进行总结,并探讨其应用领域和未来发展方向。
一、OCR文字识别技术简介OCR文字识别技术是指利用计算机对图像中的文字进行自动识别和转化为可编辑文本的技术。
其核心原理是通过对图像进行分析和处理,将图像中的文字转化为计算机可以识别和处理的字符编码。
OCR技术的发展经历了多个阶段,从最初的模板匹配,到现在的基于深度学习的方法。
随着计算机计算能力和算法的不断提升,OCR 技术的准确率和速度也得到了大幅提高。
二、OCR文字识别技术的应用领域1. 文档扫描与管理:OCR技术可以将纸质文档扫描后转化为可编辑的电子文件,实现文档的数字化管理,提高工作效率。
2. 自动化办公:OCR技术可以将图片中的文字提取出来,实现自动化的文字识别和处理,减少人工干预,提高工作效率。
3. 金融和证券业:OCR技术可以用于银行、证券公司等金融机构的票据识别和数据录入,提高数据处理的准确性和效率。
4. 物流和快递业:OCR技术可以用于快递单号的自动识别和跟踪,提供更准确、更及时的物流查询服务。
5. 图书馆和档案管理:OCR技术可以用于图书馆和档案馆的文献资料数字化和检索,方便用户获取所需信息。
三、OCR文字识别技术的优势和挑战1. 优势:a. 高准确率:随着深度学习的应用,OCR技术的准确率已经达到甚至超过人眼识别。
b. 高效率:OCR技术可以对大量的文档进行自动化处理,提高工作效率。
c. 数据可编辑:OCR技术可以将图像中的文字转化为可编辑的文本,方便后续的文字处理和编辑。
2. 挑战:a. 多样性处理:OCR技术需要应对各种复杂的图像情况,如不同字体、大小、颜色、倾斜程度等,需要不断进行算法优化。
迅捷OCR文字识别软件教你如何快速提取图中文字

迅捷OCR文字识别软件教你如何快速提取图中文字
如何快速的将图片中的文字提取出来呢?相信大家在平时的生活或者工作中经常会遇到这样的问题,其实通过使用迅捷OCR文字识别软件就可以帮你解决这个问题了,那具体的操作是怎样的呢?一起来看看吧!
使用到的工具:迅捷OCR文字识别软件。
软件介绍:这款软件可以将不同文件格式的图片转换成可编辑的文本形式,支持JPG、PNG、BMP格式的图片,还可以实现CAJ、PDF 文件的转换,精准识别、自动解析、完美还原、超强纠错是这款软件的特点,所以如果想要快速提取图中文字的话,迅捷OCR文字识别软件https:///ocr就可以帮你解决这个问题了。
操作步骤:
1、首先打开电脑,在浏览器中搜素一个迅捷办公找到迅捷OCR
文字识别软件将其下载安装到自己的电脑中去,以备接下来的步骤使用。
2、打开软件,会出来这样一个页面,我们点击退出按钮退出该页
面,暂时使用不到。
3、接着点击软件上方极速识别功能,这里就可以将图中文字快速
提取出来。
4、来到图片局部识别页面,点击“添加文件”将需要转换的图片添
加进来。
5、图片添加进来之后,点击图片下方的第二个小工具在图片上框
选出想要识别的文字范围,框选完就会自动去识别了。
6、待识别完成后文字就会显示在右边区域去了,如果你想将提取
的文字翻译成其它文字的话就可以点击这个下拉款选择好想要翻译成的语种,再点击“点击翻译”按钮就好了。
7、接下来点击图片下方保存为TXT就可以将提取出来的文字保
存到TXT里面,这样整个步骤就完成了。
在迅捷OCR文字识别软件的帮助下,很快将图片中的文字提取到到TXT里面了,上述的方法你们有学会吗?。
浅谈文字识别软件OCR

浅谈文字识别软件OCR汉字识别软件的任务是研究如何使计算机能够“识字”,该系统通常是采用光电转换装置将汉字或字符转换成电信号,并送入计算机,由计算机自动辨认、阅读,因此称其为光学字符识别(OpticalCharacterRecognition),简称为OCR)。
OCR的发展简况OCR的概念是在1929年由德国科学家Tausheck最先提出来的,后来美国科学家Handel也提出了利用技术对文字进行识别的想法。
而最早对印刷体汉字识别进行研究的是IBM公司的Casey和Nagy,1966年他们发表了第一篇关于汉字识别的文章,采用了模板匹配法识别了1000个印刷体汉字。
20世纪70年代初,日本的学者开始研究汉字识别,并做了大量的工作。
我国研究汉字识别的起步比较晚,20世纪70年代末才开始进行OCR的研究工作。
早期的OCR软件,由于识别率及产品化等多方面的因素,未能达到实际要求。
同时,由于硬件设备成本高、运行速度慢,也没有达到实用的程度。
只有个别部门,如信息部门、新闻出版单位等使用OCR软件。
1986年以后我国的OCR研究有了很大进展,在汉字建模和识别方法上都有所创新,在系统研制和开发应用中都取得了丰硕的成果,不少单位相继推出了中文OCR产品。
进入20世纪90年代以后,随着平台式扫描仪的广泛应用,以及我国信息自动化和办公自动化的普及,大大推动了OCR技术的进一步发展,使OCR的识别正确率、识别速度满足了广大用户的要求。
目前,比较流行的OCR软件很多,英文OCR主要有OmniPage,中文OCR 主要有清华紫光OCR、清华文通OCR、汉王OCR、中晶尚书OCR、丹青OCR、蒙恬OCR等。
尽管汉字字量大、字形复杂,但OCR技术已经走向成熟。
许多OCR 软件不仅能识别黑白印刷体汉字,还能识别灰度和彩色印刷体汉字,识别速度很快,识别正确率达到了99%以上;可识别宋体、黑体、楷体等多种字体的简、繁体;可对多种字体、不同字号的混排进行识别;有些OCR软件还能识别图像、表格。
ocr文字识别工作原理

ocr文字识别工作原理OCR文字识别,这可是个超有趣又超级实用的技术呢!OCR的全称为光学字符识别(Optical Character Recognition)。
它的工作原理啊,就像是一场精心策划的探秘之旅。
首先呢,图像采集是第一步。
无论是扫描仪还是摄像头,它们的任务就是把含有文字的图像捕捉下来。
比如说,你想要把一本旧书上的文字转化为电子文档,你用扫描仪一扫,这就完成了图像采集这一环节。
这时候得到的图像呢,其实就是由很多的像素点组成的,就像一幅由无数小方块拼成的拼图。
接下来,图像预处理就登场啦。
这个过程可重要了呢。
因为采集到的图像可能会有各种各样的问题,像光线不均匀啊,图像有倾斜啦,或者是有一些噪点之类的。
为了解决这些问题,就需要对图像进行预处理。
比如通过灰度化处理,把彩色图像转化为灰度图像,这样可以减少计算量。
再通过二值化,让文字部分和背景部分更加分明,就像把黑白分得清清楚楚的界限一样。
要是图像有倾斜呢,还会进行倾斜校正,让文字都规规矩矩地排列着。
然后就是字符分割这个关键步骤啦。
在这个环节里,要把一整片的文字区域分割成单个的字符。
这可不容易呢,就好像要把一串紧紧挨在一起的珠子一个一个分开一样。
对于印刷体文字来说,可能相对容易一些,因为字符之间的间距相对固定。
但是对于手写体文字,那就难多了,毕竟每个人的书写习惯不同,字与字之间的连接和间距都千差万别。
不过呢,通过一些算法,比如基于连通区域的算法等,还是能够尽可能准确地把字符分割开来。
再之后就是特征提取啦。
每个字符都有自己独特的特征,就像每个人都有自己独特的外貌特征一样。
这些特征可以是字符的笔画结构、线条走向、字符的轮廓等。
通过提取这些特征,就能把字符转化为计算机能够理解的数据形式。
例如,对于一个“人”字,它的一撇一捺的走向、长短比例等都是它的特征。
最后就是分类识别啦。
这时候,计算机就会根据之前提取的特征,在预先建立好的字符库中进行匹配。
这个字符库就像是一个巨大的字典,里面存储了各种各样的字符模型。
尚书7号OCR文字识别系统完全版 Shocr7.0下

尚书7号OCR文字识别系统完全版Shocr7.0下尚书7号OCR文字识别系统完全版 Shocr7.0软件语言简体中文软件大小 44.41 MB本软件系统是应用OCR(Optical Character Recognition)技术,为满足书籍、报刊杂志、报表票据、公文档案等录入需求而设计的软件系统。
目前,许多信息资料需要转化成电子文档以便于各种应用及管理,但因信息数字化处理的方式落后,不但费时费力,而且资金耗费巨大,造成了大量文档资料的积压,因此急需一种快速高效的软件系统来满足这种海量录入需求。
本软件系统正是适用于个人、小型图书馆、小型档案馆、小型企业进行大规模文档输入、图书翻印、大量资料电子化的软件系统。
●识别字符简体字符集:国标GB2312-80的全部一、二级汉字6800多个。
纯英文字符集。
简繁字集:除了简体汉字外,还可以混识台湾繁体字5400多个以及香港繁体字和GBK汉字。
●识别字体种类能识别宋体、仿宋、楷、黑、魏碑、隶书、圆体、行楷等一百多种字体,并支持多种字体混排。
● 识别字号初号小六号字体。
●表格识别可以自动判断、拆分、识别和还原各种通用型印刷体表格。
●可支持繁体WINDOWS系统首先,尚书七号开始将整个OCR的过程,明确化了,通过程序的菜单,我们就能够知道整个OCR的过程,主要分为:“文件”、“编辑”、“识别”、“输出”等步骤。
在文件菜单中,您可以调用扫描仪,或者选择将已经扫描好的图像文件打开。
得到图像文件后,用户开始的工作,就是“编辑“菜单里面所提示的:图像页面的处理,其中包括图像页的倾斜校正(提供自动和手动实现方法),旋转等功能。
处理完毕后,就可以进入“识别过程”,该过程关键的是“版面分析”,现在尚书七号的自动版面分析功能很强,面对报纸杂志等复杂情况的版面,也是分析的正确率很高。
不再需要我们在尚书六号里面那样的建议手工划识别范围。
也正是这点,大大降低了使用者的工作量。
为了方便,“识别”菜单下,也提供了用户自己在自动版面分析后,通过修改识别范围框的属性,来决定需要识别否的功能(默认的情况下,图象属性的栏目是不用识别的。
ocr文字识别原理

ocr文字识别原理OCR文字识别原理。
OCR(Optical Character Recognition,光学字符识别)是一种通过扫描文档或图片,将其转换为可编辑文本的技术。
它的原理是通过识别图像中的文字,并将其转换为计算机可识别的字符编码,从而实现对文字信息的提取和处理。
OCR文字识别技术在各个领域都有着广泛的应用,比如数字化档案管理、自动化办公、图书馆信息管理等。
下面将介绍OCR文字识别的原理及其应用。
首先,OCR文字识别的原理是基于图像处理和模式识别技术的。
当一幅图像被输入到OCR系统中时,系统首先会对图像进行预处理,包括图像的二值化、去噪、分割等操作,以便提取出图像中的文字信息。
然后,系统会对提取出的文字进行特征提取和模式匹配,以识别出文字的具体内容。
最后,识别出的文字会被转换为计算机可识别的字符编码,比如Unicode编码,从而实现对文字信息的提取和处理。
其次,OCR文字识别技术在各个领域都有着广泛的应用。
在数字化档案管理方面,OCR文字识别可以帮助将纸质文件转换为可编辑的电子文档,实现文档的快速检索和管理。
在自动化办公方面,OCR文字识别可以实现对扫描文件的自动识别和提取,从而提高工作效率。
在图书馆信息管理方面,OCR文字识别可以帮助图书馆快速建立数字化图书馆,实现对图书信息的数字化管理和检索。
总之,OCR文字识别是一种通过识别图像中的文字,并将其转换为可编辑文本的技术。
它的原理是基于图像处理和模式识别技术的,通过对图像进行预处理、特征提取和模式匹配,最终实现对文字信息的提取和处理。
OCR文字识别技术在各个领域都有着广泛的应用,可以帮助实现文档的数字化管理、自动化办公和图书馆信息管理等。
随着科技的不断发展,相信OCR文字识别技术会在未来发挥越来越重要的作用。
ocr文字识别软件哪个好用?看这篇文章就知道了!
ocr文字识别软件哪个好用?看这篇文章就知道了!
OCR文字识别软件哪个好用?能不能识别身份证、银行卡、名片、发票、车票、回单等证件或资料?简单,下面小青介绍一款迅捷OCR文字识别PC版软件给大家瞅瞅,它的OCR文字识别技术多强!
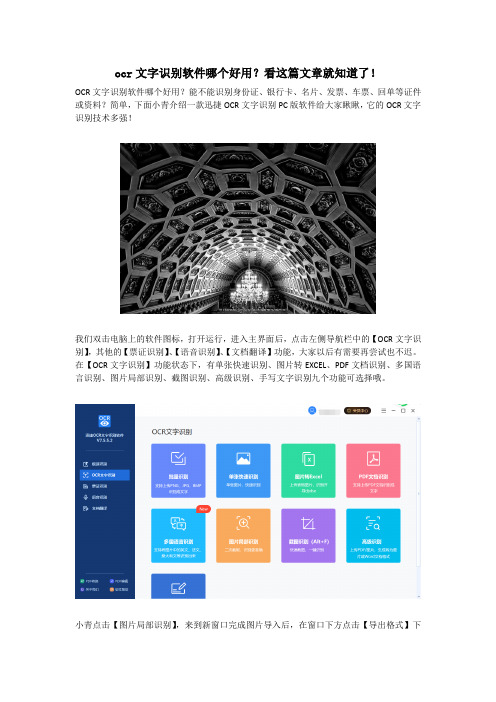
我们双击电脑上的软件图标,打开运行,进入主界面后,点击左侧导航栏中的【OCR文字识别】,其他的【票证识别】、【语音识别】、【文档翻译】功能,大家以后有需要再尝试也不迟。
在【OCR文字识别】功能状态下,有单张快速识别、图片转EXCEL、PDF文档识别、多国语言识别、图片局部识别、截图识别、高级识别、手写文字识别九个功能可选择哦。
小青点击【图片局部识别】,来到新窗口完成图片导入后,在窗口下方点击【导出格式】下
拉框,可见DOCX、DOC、TXT三种格式,大家觉得那种适合就选择哪一个,小青还是偏向默认第一个哈。
随即开始识别,看到结果后都要检查一遍,确认无误后再导出。
OCR文字识别软件哪个好用?上面就是小青给诸位的答案啦,很感谢你们的阅读哦,原创不易,你的点赞就是小青坚持的动力,谢谢!。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
授课内容及教学活动设计附注(教学方法、活动形式、辅助手段等)
2•删除识别区域
3•更改识别区域的顺序
多个识别区域的使用,可以较好处理图文混排的稿件。
活动二识别之前稿件画面的处理
在实际应用中,稿件画面并不都像sample文件夹中那样理想,
或多或多少会有小许倾斜、污点等,这会影响到最后识别的效果。
所以最好在识别之前,先对稿件画面进行一定的处理,以增加识别的准确率。
1•擦拭图像一一用“橡皮”工具擦去图像上的杂点或部分一块图像区域。
2.旋转图像一一可以对图像旋转90、180、270度的旋转。
因
为在拍摄、扫描图像的过程中,可能会出现90、180、270度的差异。
3•倾斜校正一一拍摄或扫描图像的过程中,可以会形成几度的倾斜,用此功能可以将图像校正。
活动四其它类型稿件的识别
除了对中文内容的稿件进行识别外,汉王OCR文字识别系统
还可以对繁体中文、英文、表格等内容的稿件进行有效的识别。
任务1对繁体中文、英文、表格等内容的稿件进行识别
对繁体中文、英文的识别操作与中文相冋,只是在识别之前需要在工具栏最右边的下拉列表中选择“ 繁体字集”或“纯英文识别” 的选项。
任务2对含有表格的稿件进行识别含有表格稿件的识别操作与中文稿件的识别相冋。
任务3特殊网页的识别
1 .使用屏幕硬拷贝的功能将网页画面转换成图像文件。
2.用OCR软件对此进行识别,发现效果很差。
3.用Photoshop对图像文件进行分辨率的处理。
4.再用OCR软件对此进行识别,发现效果较好。
可以使用软件自带的样例图片进行上机实验,这些图片存放在sample 文件夹中。
可以使用sample文件夹中的文件进行上机操作。
可以将学生机与因特网相联。
或将现成的网页图像提供给学生。