统计学第三章 统计整理
合集下载
3第三章统计整理

(3)适用性审核 弄清楚数据的来源、数据的口径以及有关的背景材料 确定这些数据是否符合自己分析研究的需要
(4)时效性审核 应尽可能使用最新的统计数据
(5)确认是否必要做进一步的加工整理
统计学
河南科技大学
第三章 统计整理
(二)差错的更正与处理
通过上述审核,如发现有缺报、缺份和缺项等情况, 应及时催报、补报;如有不正确之处,则应分别不同 情况作如下处理:
10. 爱尔兰 拥有大学学位人群所总人口占比例:37% 年增速 (2000-2010年): 7.3% (最高)
9. 澳大利亚 拥有大学学位人群所占总人口比例:38% 8. 芬兰 拥有大学学位人群所占总人口比例:38% 7. 英国 拥有大学学位人群所占总人口比例:38% 6. 韩国 拥有大学学位人群所占总人口比例:40%
统计学
第三章 统计整理
河南科技大学 历次人口普查中,每10万人中各种文化程度的人数
大专及以上 高中
初中
小学
1982 1990 2000 2010
615 1422 3611 8930
Hale Waihona Puke 6779 8039 11146 14032
17892 23344 33961 38788
35237 37057 35701 26779
统计学
河南科技大学
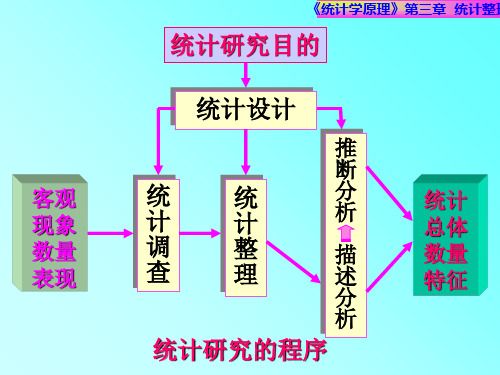
三、统计整理的程序
第三章 统计整理
统计资料的审核
资料的分组和汇总
编制统计表或绘制统计图
统计资料的积累、保管和公布
统计学
河南科技大学 数据审核
第三章 统计整理
统计工作的基本程序
收集 数据
真实 数据
虚假 数据
科学地计 算与分析
假数真算
(4)时效性审核 应尽可能使用最新的统计数据
(5)确认是否必要做进一步的加工整理
统计学
河南科技大学
第三章 统计整理
(二)差错的更正与处理
通过上述审核,如发现有缺报、缺份和缺项等情况, 应及时催报、补报;如有不正确之处,则应分别不同 情况作如下处理:
10. 爱尔兰 拥有大学学位人群所总人口占比例:37% 年增速 (2000-2010年): 7.3% (最高)
9. 澳大利亚 拥有大学学位人群所占总人口比例:38% 8. 芬兰 拥有大学学位人群所占总人口比例:38% 7. 英国 拥有大学学位人群所占总人口比例:38% 6. 韩国 拥有大学学位人群所占总人口比例:40%
统计学
第三章 统计整理
河南科技大学 历次人口普查中,每10万人中各种文化程度的人数
大专及以上 高中
初中
小学
1982 1990 2000 2010
615 1422 3611 8930
Hale Waihona Puke 6779 8039 11146 14032
17892 23344 33961 38788
35237 37057 35701 26779
统计学
河南科技大学
三、统计整理的程序
第三章 统计整理
统计资料的审核
资料的分组和汇总
编制统计表或绘制统计图
统计资料的积累、保管和公布
统计学
河南科技大学 数据审核
第三章 统计整理
统计工作的基本程序
收集 数据
真实 数据
虚假 数据
科学地计 算与分析
假数真算
统计学第三章统计整理

7
第三章 统计整理
第一节 统计整理的概念、原则和步骤(4)
四、统计整理的组织形式
1、逐级汇总:自下而上一级一级地汇总本地区、
本系统、本单位的调查资料。
2、集中汇总:把全部调查资料集中在一个机关或
最高统计机关进行汇总。
3、综合汇总:对各地区和各级都需要的基本资料
进行逐级汇总,对全国的总的数字和其他需要在全 国范围内进行加工的资料或本系统的全面资料则实 行集中汇总。
第三节 次数分布(3)
(二)变量数列(单项数列和组距数列)
按数量标志分组形成为变量数列。 1、单项数列是总体按单项式分组而形成的变量 数列,每个变量值是一个组,顺序排列。
拥有发电机组(套) 发电厂数(个)
1
35
比重(%) 28.0
2 3 4 5 合计
48
38.4
26
20.8
12
9.6
4
3.2
125
100.0
9
第三章 统计整理
统计分组图示
分组前
分组后
25% 33% 42%
10
第三章 统计整理
第二节 统计分组(2)
二 作用p.40
(一)划分现象的类型 (二)揭示现象的内部结构 (三)分析现象之间的依存关系
三 分组标志的选择p.43
(一)根据统计研究的目的,选择反映事物本质 的标志;例如:
(二)结合具体时间地点条件来选择反映事物本 质的标志。
[注三]东、中、西部的划分:东部包括北京、天津、河北、 辽宁、上海、江苏、浙江、福建、山东、广东、广西、海南 省;中部包括山西、内蒙古、吉林、黑龙江、安徽、江西、 河南、湖北、湖南省;西部包括重庆、四川、贵州、云南、 西藏、陕西、甘肃、青海、宁夏、新疆。
第三章 统计整理
第一节 统计整理的概念、原则和步骤(4)
四、统计整理的组织形式
1、逐级汇总:自下而上一级一级地汇总本地区、
本系统、本单位的调查资料。
2、集中汇总:把全部调查资料集中在一个机关或
最高统计机关进行汇总。
3、综合汇总:对各地区和各级都需要的基本资料
进行逐级汇总,对全国的总的数字和其他需要在全 国范围内进行加工的资料或本系统的全面资料则实 行集中汇总。
第三节 次数分布(3)
(二)变量数列(单项数列和组距数列)
按数量标志分组形成为变量数列。 1、单项数列是总体按单项式分组而形成的变量 数列,每个变量值是一个组,顺序排列。
拥有发电机组(套) 发电厂数(个)
1
35
比重(%) 28.0
2 3 4 5 合计
48
38.4
26
20.8
12
9.6
4
3.2
125
100.0
9
第三章 统计整理
统计分组图示
分组前
分组后
25% 33% 42%
10
第三章 统计整理
第二节 统计分组(2)
二 作用p.40
(一)划分现象的类型 (二)揭示现象的内部结构 (三)分析现象之间的依存关系
三 分组标志的选择p.43
(一)根据统计研究的目的,选择反映事物本质 的标志;例如:
(二)结合具体时间地点条件来选择反映事物本 质的标志。
[注三]东、中、西部的划分:东部包括北京、天津、河北、 辽宁、上海、江苏、浙江、福建、山东、广东、广西、海南 省;中部包括山西、内蒙古、吉林、黑龙江、安徽、江西、 河南、湖北、湖南省;西部包括重庆、四川、贵州、云南、 西藏、陕西、甘肃、青海、宁夏、新疆。
统计学 第3章 统计数据的整理

统计分组的标志
第三章 统计数据的整理
统计分组的标志:分组标志就是将总体分为各个性质不同的标准或根据。
根
据分组标志的特征不同,总体可按属性标志分组,也可按数量标志分组。
1.按属性标志分组
以属性标志作为分组标志,并在属性标志的变异范围内划分各组界限,将总体 分为若干组。属性标志划分,概念明确,容易确定分组组数,如性别。
2.按数量标志分组
以数量标志作为分组标志,并在数量标志的变异范围内划分各组界限,将总体 分为若干组。如工资。
第三章 统计数据的整理
(五)简单分组和复合分组
在统计分组时,根据统计研究目的不同,分组标志的选择可以是一个标志,也可以是 两个或两个以上的标志,这样就有简单分组和复合分组之分:
1.简单分组 对总体只按一个标志分组称为简单分组。
第三章 统计数据的整理
数量次数分布的编制方法
在组距次数分布中,各组组距相同的次数分布称为等距次数分 布(表3-8)。各组组距不同的次数分布称为异距次数分布。
等距次数分布一般在现象性质差异变动比较均衡的条件下使用。
优点:
• 易于掌握次数分布的特性。
• 各组次数可以直接比较。
组数= 全距/组距
组距=全距/组数
100.00
提问:这是单 项次数分布还 是组距次数分 布?
第三章 统计数据的整理
数量次数分布的编制方法
例:对某工厂某月50名工人装配零件(件)情况进行调查, 得到下列初级资料:
106 81 98 111 91 107 86 105 93 106 82 108 114 122 109 104 125 103 113 102 106 84 128 104 91 112 85 96 115 89 97 105 92 111 107 97 105 124 106 86 96 110 112 103 108 110 109 125 101 119
第三章--统计整理-幻灯片(1)
如某班学生按年龄分组:17岁,18岁,19岁, 20岁, 21岁,22岁。
组距式分组
将作为分组依据的数量标志的整个取 值范围依次划分为若干个满足互斥性
和包容性的区间,用这些数值区间作
为组的名称。
某班学生统计 学原理成绩分 组
60分以下 60—70分 70—80分 80—90分 90分以上
组距式分组中的一些概念 《统计学原理》第三章 统计整理
对教师 的分类
按性别分类
男性 女性
高级 按职称分类 中级 共计7组
初级 2+3+2
青年 按年龄分类
中年
复合分组体系
对教师 的分类
按性别 分类
按职称 分类
按年龄 分类
《统计学原理》第三章 统计整理
共计12组 男 2×3×2
女 高级
中级
初级 青年 中年
《统计学原理》第三章 统计整理
统计资料的再分组
• 统计资料的再分组就是把统计分 组资料按某种要求,重新划定各 组界限,再将资料中的单位数或 比重分布重新做出调整。
对总体单位而言,是“合”,即将性质相同的 个体组合起来,在同一组内则保持着相同的性 质。
分组
《统计学原理》第三章 统计整理
25%
33%
分组前
分组后
42%
作用:1·区分事物的性质
例:按所有制性质划分,我国现有8种经济类型:
国有经济;集体经济;私营经济;个体经济 联营经济;股份制经济;外商投资经济;港 澳台投资经济
将统计调查得到的原始资料进行科
统计整理 学的分类和汇总,使之成为系统化、
条理化的综合资料,以反映研究总 体的特征。
地位 是统计调查的继续,统计分析的前提 和基础,起着承前启后的作用。
统计学原理(第七版)第三章统计整理

比重(%) 6
10 17 28 22 17 100
二 变量数列的种类
(二)组距变量数列
当变量值较多,变量值变动的范围也比较大时,编制单项变量数列会使 分组数过多,总体单位过于分散,不便于分析问题,这时应当采用组距 变量数列。
组距变量数列是按照数量标志分组后,用变量值变动的一定范围(即组 距)代表一个组所形成的数列(见表3-4)。
审核
(四) 编制统计表或绘
制统计图
(一) 设计和编制统计
资料整理方案
(三) 对原始资料进行统 计分组和统计汇总
02 PART TWO
第二节
统计分组
一 统计分组的概念
统计分组是根据所研究事物的特点和统计研究的目的,按照某一标志将统计 总体划分为若干个组成部分的一种统计方法。统计总体的这些组成部分称为 “组”。通过统计分组,使同一组内的各单位性质更加相同,不同组的各单 位性质更加相异。能够对统计总体进行分组,是由总体单位所具有的“差异 性”特点决定的。统计总体中的各个单位,一方面在某一个或某一些标志上 具有相同的性质,可以结合在同一性质的总体中;另一方面,又在其他一些 标志上具有彼此相异的性质,从而又可以被区分为性质不同的若干个组成部 分。例如,在工业企业这个总体中,我们可以按照企业的生产规模将工业企 业划分为大型企业、中型企业、小型企业和小微型企业四个组。每一组内各 企业的生产规模相近,组与组之间的企业的生产规模差异较大。
统计学 原理
(第七版)
01 第一章 总论
02 第二章 统计设计和统计调查
03 第三章 统计整理
04
第四章 总量指标和相对指标
05
第五章 平均指标和变异指标
06
第六章 动态数列
统计学第3章统计整理

14
7.0 21 10.5 193 96.5
4 90 —100 31 15.5 52 26.0 179 89.5 5 100—110 65 32.5 117 58.5 148 74.0
6 110—120 52 26.0 169 84.5 83 41.5
7 120—130 8 130—140
23 11.5 192 96.0 31 15.5
一、分配数列的概念和种类
1.概念
统计总体按照某一标志分组以后, 用以反映总体各单位分配情况的统计 数列,称分配数列,又可称次数分配, 或次数分布。
它由两部分组成: 总体所分的各个组和各组所拥有的 单位数(次数或频数)。
例
月工资分组(元) 工人数(人) 占总数比重(%)
1000 以下
210
39.6
1000-1500
组距式 分组
以变量值变动的一个区间作为一组,区间的 距离称为组距。适用于连续型变量和离散型 变量的变量值较多的情况。
第三章 统计整理
在进行组距分组时,会涉及到一 些问题,包括:等距分组和不等距分 组、组限、组中值。
第三章 统计整理
等距 分组
不等距 分组
各组组距均相等。如: 10—20 20—30 30—40
组中值 = (上限值+下限值)÷2
开口组组中值的计算: 缺下限:组中值=本组上限— 相邻组组距/2
缺上限:组中值=本组下限+ 相邻组组距/2
例
产值(万元)
第一组组中值:
50以下 50 — 60 60 — 70 70以上
50-(10÷2)= 45 最后一组组中值: 70+(10÷2)= 75
第二节 分配数列
较合适是? (c)
《统计学概论》第三章 统计整理

70 ~ 80
80 ~ 90
90 ~ 100
合
计
学生人数
(人)
5 15 18 10
2 50
由表3-1可见,整理后的学生考 STAT 分资料,较整理前的考分资料明 显要条理、系统。由上表可见, 在学生总体中,60分以下和90分 以上的学生人数都较少,绝大多 数学生的考分分布在60—90分之 间。
所以,统计整理是统计调查的继续,是统计分析的前提, 它实现了从个别单位的标志表现(标志值)向总体综合指标 的过渡,在统计研究中起着承前启后重要的作用。
编制步骤:
⒈求变异全距 R X max X min 139 107 32(百万元)
⒉确定组距及组数 R≤组距(d) ×组数(m)
确定组距的原则:
要能区分各组的性质差异 要能反映总体资料的分布特征 为方便计算,尽可能为5或10的整数倍
编少)
要求编制组距数列。
STAT
• 排序结果为
• 107 108 108 110 112 112 113 114 115 117 117 117 118 118 118 119 120 120 121 122 122 122 122 123 123 123 123 124 124 124 125 125 126 126 127 127 127 128 128 129 130 131 133 133 134 134 135 137 139 139
合计
频数(人) 3 5 8 14 10 6 4
50
频率(%) 6 10 16 28 20 12 8
100
统计分组方法
选择反映事物属性差异的标
按品质标志分组 志作为分组标志,如性别、
所有制类型
统计学(第三章)

四、统计分组方法 统计分组的关键在于选择分组标志和 划分各组界限。划分各组界限,就是要在 分组标志的变异范围内,划定各相邻组之 间的性质界限和数量界限。 (一)按品质标志分组的方法 选择反映事物属性差异的标志作为分 组标志,界限比较明确,类型比较稳定。 如,企业按所有制分组、人口按性别分组 等。
(二)按数量标志分组的方法 数量标志有离散型和连续型之分,其分 组的方法和形式也不同。 1、按离散型变量标志分组其形式有2个 (单项式分组和组距式分组); 2、按连续型变量标志分组其形式只有一 个(组距式分组)。
某班级学生按性别分组 学生按性别分组 男 女 合 计 人数(人) 60 40 100
2、按数量标志分组。按数量标志分组 就是选择反映事物数量差异的数量标志作 为分组标志,并在数量标志的变异范围内 划定各组界限,将总体划分为性质不同的 若干组成部分。 3、根据分组选择标志的多少不同,统 计分组又可分为简单分组和复合分组。 简单分组。简单分组是指对统计总体 仅按一个标志进行分组。
二、统计整理的步骤 1.设计统计整理方案 2.对原始资料进行审核 3.对原始资料进行分组和汇总 4.编制统计表或绘制统计图 综上所述,设计整理方案、对原始资 料进行审核是整理的前提,统计分组是统 计整理的基础,统计汇总是统计整理的中 心环节,编制统计表或绘制统计图是统计 整理的结果。
1.2、统计分组 一、统计分组的意义 统计分组既是统计认识问题的一种基 本方法,又是统计整理工作的具体内容之 一,因此它在整个统计工作过程中具有十 分重要的作用。
4、次数分配的类型
对称分布
右偏分布
左偏分布
正J型分布
反J型分布
几种常见的频数分布
U型分布
1、钟形分布 钟形分布的特征是“中间多,两边少”,这类 分布是以平均值为中心的,越接近中心,分配的次 数越多,离中心越远,分配的次数越少,其曲线就 像一口古钟。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第三章 统计整理
一、统计数据的预处理 二、数据分组与频数分布 三、统计表和统计图
统计数据的整理(summarizing data)是指 对所搜集的数据进行加工整理、使之系统化、 条理化,以符合分析的需要。 统计数据的整理通常包括: 数据的预处理 分类或分组 汇总
一、数据的预处理 数据的审核、筛选与排序
(一)品质数据的分组与频数分布
例6: 50个计算机购买者所购买的不同品牌的机型数据
IBM Gateway200 IBM Apple Compaq IBM Apple Compaq Apple Table, Data from a sample of 50 computer purchases(11/15,1994) IBM Packard Bell Compaq IBM Packard Bell Packard Bell Apple Compaq Apple Apple IBM Apple Compaq Compaq Compaq Gateway2000 Packard Bell Apple Apple Compaq Compaq IBM Compaq Packard Bell Gateway2000 IBM Packard Bell Gateway200 Packard Bell Packard Bell Apple Packard Bell Packard Bell Gateway200 Packard Bell Apple Compaq IBM Apple Apple Compaq
1. 数据的审核
发现数据中的错误 找出符合条件的数据
2. 数据的筛选 3. 数据排序
发现数据的基本特征 升序和降序
数据的审核
审核的内容 1. 完整性审核
– – – – – 检查应调查的单位或个体是否有遗漏 所有的调查项目或指标是否填写齐全 检查数据是否真实反映客观实际情况,内 容是否符合实际 检查数据是否有错误,计算是否正确等 如:文化程度:小学 职业:大学教师
将某些不符合要求的数据或有明显错误的数
据予以剔除 将符合某种特定条件的数据筛选出来,而不 符合特定条件的数据予以剔出
数据的排序
(要点)
1. 按一定顺序将数据排列,以发现一些明显 的特征或趋势,找到解决问题的线索
2. 排序有助于对数据检查纠错,以及为重新 归类或分组等提供依据 3. 在某些场合,排序本身就是分析的目的之 一 4. 排序可借助于计算机完成
分组与求频数 : Table, Frequency Distribution/Relative and Percentage Frequency of Computer Purchases
Company Apple Compaq Gatewy2000 IBM Packard Bell Total Frequency 13 12 5 9 11 50 Relative Frequency 0.26 0.24 0.10 0.18 0.22 1.00 Percentage Frequency 26 24 10 18 22 100
三、频数/次数分配的图示
品质数据往往使用柱状图(Bar graphs)和饼状图(Pie Charts); 数值数据往往使用直方图(Histograms)、折线图(Polygon)、茎 叶图(Stem-and-leaf display) 。 Fig1, Bar Graph of Computer Purchases
(二)数值数据的分组与频数分布
可先将数据进行排序,然后根据需要分组; 对较少的数据也可不排序直接根据需要分组。 ◐分组计频基本步骤:
确定组数 确定组距(按组)整理成分布频数表
例:一会计事务所对其20家客户(clients)年底帐目 辑核(audits)时间(天)统计如下表:
12 22 Table Year-End Audit Times(in days) 14 19 18 15 15 18 17 20 27 23 22 21 33 28 14 18 16 13
14 12
Fre que nc y
10 8 6 4 2 0
A
p
e pl C
om
q pa G at ew
2 ay
0 00
IB
M c a P k
d ar
B
l el
• 柱状图是一种图形方法,用于描述已经 被汇总为频数分布、相对频数分布或百 分比频数分布的数据。 • 在图的横轴上,规定对数据分组(类) 的标记。在纵轴上标有频数、相对频数 分布或百分比频数的刻度。
◎ 频数分布或次数分布(Frequency distribution): 全部数据按其分组标志在各组内的分布状况。 分布在各组内的数据个数称为频数或次数。 A frequency distribution is a tabular summary of a set of data showing the frequency (or number) of items in each of several nonoverlapping classes. ◎相对频数(Relative frequency)/频率/比重:各组频 数与全部频数之和的比重。 The relative frequency of a class is the proportion of the total number of data items belonging to the class.(=Frequency of the class/n) ◎百分数频数(Percentage frequency):is the relative frequency multiplied by 100.
其中N为数据的个数(总体单位数或样本数), 一般对结果取整数。
上例中:K=1+lg20/lg2=1+4.32=5.325
第二步,确定组距(Width of classes):组距是 一个组的上限与下限之差,可根据全部数据的最 大值和最小值及所分的组数来确定:
组距=(最大值 - 最小值)/组数
上例中,组距=(33-12)/5=4.2,可取整数5为最 后选定的组距。 第三步,确定各组组限(Class limits)并据此整 理频数分布表。
22%
26% Apple Compaq Gatewy 2000 IBM packard Bell 24%
18% 10%
Fig 1 Pie Chart of Computer Purchases
• 饼状图是另一种表示相对频数和百分比 频数分布的图形方法。饼状图中的每一 部分所显示的数值可以是频数、相对频 数、或者百分比频数。
上例是离散型数据(天),采用组限间断方法,因此可得 频数分布表如下: Table, Frequency distribution, relative frequency and percent frequency distribution for the audit-time data Audit Frequency Relative Percent Time(days) Frequency Frequency 10~14 4 0.20 20 15~19 8 0.40 40 20~24 5 0.25 25 25~29 2 0.10 10 30~34 1 0.05 5 Total 20 1.00 100
(二)茎叶图
茎叶图是一种既给出数据的分布状况,又能 显示每一个原始数值的图形。 A stem-and-leaf display can be used to rank order data and provide an idea of the shape of the distribution of a set of quantitative data. 茎叶图由两部分组成:茎(stem)与叶(leaf) 茎:通常由每组数的高位数值(leading digits) 形成,按组竖立在左边; 叶:通常由每组数的低位数值(last digits)形成, 按组横排在“茎”的右边。
The objective in developing a frequency distribution is to provide insights about the data that cannot be quickly obtained by looking only at the original data.
▼注意: 1、分组所遵循的主要原则是“不重不漏”(each data value belongs to one class and only one class)。因 此, 最低组限(The lower class limit) 数据的最小值, 最大组限(The upper class limit) 数据的最大值; 另外,数据在每组中的归属习惯上采用“上组限 不在内”。 2、对离散型数据,可采用相邻两组组限间断的办 法解决“不重”的问题(如6~10,11~15,16~20 等); 对连续型数据,往往采用相邻两组组限重叠, 根据“上限不在内原则”解决“不重”问题(如 [5,10),[10,15),[15,20)等)。
数据的排序
(方法)
1. 定类数据的排序 字母型数据,排序有升序降序之分,但习惯上
用升序 汉字型数据,可按汉字的首位拼音字母排列, 也可按笔画排序,其中也有笔画多少的升序降 序之分
2. 定距和定比数据的排序
–
–
递增排序:设一组数据为 X1 , X2 , … , XN ,递 增排序后可表示为:X(1)<X(2)<…<X(N) 递减排序可表示为:X(1)>X(2)>…>X(N)
2. 准确性审核
数据的审核
(原始数据)
审核数据准确性的方法
1. 逻辑检查
– – – – 从定性角度,审核数据是否符合逻辑,内容是否 合理,各项目或数字之间有无相互矛盾的现象 主要用于对定类数据和定序数据的审核 检查调查表中的各项数据在计算结果和计算方法 上有无错误 主要用于对定距和定比数据的审核
一、统计数据的预处理 二、数据分组与频数分布 三、统计表和统计图
统计数据的整理(summarizing data)是指 对所搜集的数据进行加工整理、使之系统化、 条理化,以符合分析的需要。 统计数据的整理通常包括: 数据的预处理 分类或分组 汇总
一、数据的预处理 数据的审核、筛选与排序
(一)品质数据的分组与频数分布
例6: 50个计算机购买者所购买的不同品牌的机型数据
IBM Gateway200 IBM Apple Compaq IBM Apple Compaq Apple Table, Data from a sample of 50 computer purchases(11/15,1994) IBM Packard Bell Compaq IBM Packard Bell Packard Bell Apple Compaq Apple Apple IBM Apple Compaq Compaq Compaq Gateway2000 Packard Bell Apple Apple Compaq Compaq IBM Compaq Packard Bell Gateway2000 IBM Packard Bell Gateway200 Packard Bell Packard Bell Apple Packard Bell Packard Bell Gateway200 Packard Bell Apple Compaq IBM Apple Apple Compaq
1. 数据的审核
发现数据中的错误 找出符合条件的数据
2. 数据的筛选 3. 数据排序
发现数据的基本特征 升序和降序
数据的审核
审核的内容 1. 完整性审核
– – – – – 检查应调查的单位或个体是否有遗漏 所有的调查项目或指标是否填写齐全 检查数据是否真实反映客观实际情况,内 容是否符合实际 检查数据是否有错误,计算是否正确等 如:文化程度:小学 职业:大学教师
将某些不符合要求的数据或有明显错误的数
据予以剔除 将符合某种特定条件的数据筛选出来,而不 符合特定条件的数据予以剔出
数据的排序
(要点)
1. 按一定顺序将数据排列,以发现一些明显 的特征或趋势,找到解决问题的线索
2. 排序有助于对数据检查纠错,以及为重新 归类或分组等提供依据 3. 在某些场合,排序本身就是分析的目的之 一 4. 排序可借助于计算机完成
分组与求频数 : Table, Frequency Distribution/Relative and Percentage Frequency of Computer Purchases
Company Apple Compaq Gatewy2000 IBM Packard Bell Total Frequency 13 12 5 9 11 50 Relative Frequency 0.26 0.24 0.10 0.18 0.22 1.00 Percentage Frequency 26 24 10 18 22 100
三、频数/次数分配的图示
品质数据往往使用柱状图(Bar graphs)和饼状图(Pie Charts); 数值数据往往使用直方图(Histograms)、折线图(Polygon)、茎 叶图(Stem-and-leaf display) 。 Fig1, Bar Graph of Computer Purchases
(二)数值数据的分组与频数分布
可先将数据进行排序,然后根据需要分组; 对较少的数据也可不排序直接根据需要分组。 ◐分组计频基本步骤:
确定组数 确定组距(按组)整理成分布频数表
例:一会计事务所对其20家客户(clients)年底帐目 辑核(audits)时间(天)统计如下表:
12 22 Table Year-End Audit Times(in days) 14 19 18 15 15 18 17 20 27 23 22 21 33 28 14 18 16 13
14 12
Fre que nc y
10 8 6 4 2 0
A
p
e pl C
om
q pa G at ew
2 ay
0 00
IB
M c a P k
d ar
B
l el
• 柱状图是一种图形方法,用于描述已经 被汇总为频数分布、相对频数分布或百 分比频数分布的数据。 • 在图的横轴上,规定对数据分组(类) 的标记。在纵轴上标有频数、相对频数 分布或百分比频数的刻度。
◎ 频数分布或次数分布(Frequency distribution): 全部数据按其分组标志在各组内的分布状况。 分布在各组内的数据个数称为频数或次数。 A frequency distribution is a tabular summary of a set of data showing the frequency (or number) of items in each of several nonoverlapping classes. ◎相对频数(Relative frequency)/频率/比重:各组频 数与全部频数之和的比重。 The relative frequency of a class is the proportion of the total number of data items belonging to the class.(=Frequency of the class/n) ◎百分数频数(Percentage frequency):is the relative frequency multiplied by 100.
其中N为数据的个数(总体单位数或样本数), 一般对结果取整数。
上例中:K=1+lg20/lg2=1+4.32=5.325
第二步,确定组距(Width of classes):组距是 一个组的上限与下限之差,可根据全部数据的最 大值和最小值及所分的组数来确定:
组距=(最大值 - 最小值)/组数
上例中,组距=(33-12)/5=4.2,可取整数5为最 后选定的组距。 第三步,确定各组组限(Class limits)并据此整 理频数分布表。
22%
26% Apple Compaq Gatewy 2000 IBM packard Bell 24%
18% 10%
Fig 1 Pie Chart of Computer Purchases
• 饼状图是另一种表示相对频数和百分比 频数分布的图形方法。饼状图中的每一 部分所显示的数值可以是频数、相对频 数、或者百分比频数。
上例是离散型数据(天),采用组限间断方法,因此可得 频数分布表如下: Table, Frequency distribution, relative frequency and percent frequency distribution for the audit-time data Audit Frequency Relative Percent Time(days) Frequency Frequency 10~14 4 0.20 20 15~19 8 0.40 40 20~24 5 0.25 25 25~29 2 0.10 10 30~34 1 0.05 5 Total 20 1.00 100
(二)茎叶图
茎叶图是一种既给出数据的分布状况,又能 显示每一个原始数值的图形。 A stem-and-leaf display can be used to rank order data and provide an idea of the shape of the distribution of a set of quantitative data. 茎叶图由两部分组成:茎(stem)与叶(leaf) 茎:通常由每组数的高位数值(leading digits) 形成,按组竖立在左边; 叶:通常由每组数的低位数值(last digits)形成, 按组横排在“茎”的右边。
The objective in developing a frequency distribution is to provide insights about the data that cannot be quickly obtained by looking only at the original data.
▼注意: 1、分组所遵循的主要原则是“不重不漏”(each data value belongs to one class and only one class)。因 此, 最低组限(The lower class limit) 数据的最小值, 最大组限(The upper class limit) 数据的最大值; 另外,数据在每组中的归属习惯上采用“上组限 不在内”。 2、对离散型数据,可采用相邻两组组限间断的办 法解决“不重”的问题(如6~10,11~15,16~20 等); 对连续型数据,往往采用相邻两组组限重叠, 根据“上限不在内原则”解决“不重”问题(如 [5,10),[10,15),[15,20)等)。
数据的排序
(方法)
1. 定类数据的排序 字母型数据,排序有升序降序之分,但习惯上
用升序 汉字型数据,可按汉字的首位拼音字母排列, 也可按笔画排序,其中也有笔画多少的升序降 序之分
2. 定距和定比数据的排序
–
–
递增排序:设一组数据为 X1 , X2 , … , XN ,递 增排序后可表示为:X(1)<X(2)<…<X(N) 递减排序可表示为:X(1)>X(2)>…>X(N)
2. 准确性审核
数据的审核
(原始数据)
审核数据准确性的方法
1. 逻辑检查
– – – – 从定性角度,审核数据是否符合逻辑,内容是否 合理,各项目或数字之间有无相互矛盾的现象 主要用于对定类数据和定序数据的审核 检查调查表中的各项数据在计算结果和计算方法 上有无错误 主要用于对定距和定比数据的审核