英汉字典源代码
C语言电子词典程序设计

C语言电子词典程序设计```c#include <stdio.h>#include <stdlib.h>#include <string.h>#define MAX_WORD_LEN 100#define MAX_DEF_LEN 500typedef struct DictEntrychar word[MAX_WORD_LEN];char definition[MAX_DEF_LEN];} DictEntry;int maiint numEntries;DictEntry* dict;char searchWord[MAX_WORD_LEN];printf("请输入词典条目数量:");scanf("%d", &numEntries);dict = (DictEntry*)malloc(numEntries * sizeof(DictEntry)); //输入词典条目for (int i = 0; i < numEntries; i++)printf("请输入词汇:");scanf("%s", dict[i].word);printf("请输入词汇的定义:");scanf(" %[^\n]s", dict[i].definition);}//查询词汇printf("请输入要查询的词汇:");scanf("%s", searchWord);for (int i = 0; i < numEntries; i++)if (strcmp(dict[i].word, searchWord) == 0) printf("查询结果:\n");printf("词汇:%s\n", dict[i].word);printf("定义:%s\n", dict[i].definition); break;}}free(dict);return 0;```以上是一个简单的C语言电子词典程序设计示例,它通过结构体数组存储词汇和对应的定义。
数据结构 C++ 简单英汉字典 实验报告

实验报告:简单英汉字典2011-12-22实现目标及要求:1)利用散列表实现英汉字典;2) 实现散列表类,要求实现一种散列表:•散列函数选取建议:将单词转成整数,再用除留余数法获得散列地址。
•冲突解决方法可采用开散列法。
3)实现字典类,字典数据存放在内存,字典类中有两个重要数据成员:•字典数组:存放字典数据的数组(或线性表)。
•散列表对象:作为字典数据索引的散列表。
–散列表元素结构包含单词和对应字典数据在字典数组中的下标,可通过散列表直接获得单词在字典数组的下标。
4)利用上面两个类实现英汉字典。
5)界面要求:键盘输入单词,屏幕输出解释:–界面菜单项:•1.添加新词•2.删除单词•3.查字典–查字典界面:•请输入英文单词:China•中文翻译:中国实验环境与工具:使用Microsoft Visual Studio 2010 在Windows7 64位环境下进行实验。
实验思路:分如下N步:1.先实现链结点类的结构。
2.实现字典类的结构。
3.实现词条类的结构。
4.实现词条的散列表分类方法。
5.整合功能。
主要的数据结构如下://Hash_head.h#include<assert.h>#include<string>#include<stdlib.h>using namespace std;const int defaultDicSize=10;const int defaultTableSize=10;class ChainNode{public:Entry<string> EntryLink;ChainNode *link;};template<class E>class Dictionary{public:Dictionary(E e[]);~Dictionary(){delete []ht;}bool search(string,string &);bool search(string,string &,ChainNode *&);bool insert(E);bool insert(string,string);bool remove(string);void dicPos(E e[]);void outputDic();private:ChainNode *ht;int dicSize;//总词条数int tableSize;//每个索引容量};template<class E>Dictionary<E>::Dictionary(E e[]){//计算词条数,作为字典最大长度dicSize=0;while(e[dicSize].chinese!=""){dicSize++;}//初始化字典ht=new ChainNode[dicSize];for(int i=0;i<dicSize;i++){ht[i].link=NULL;ht[i].EntryLink=Entry<string>();}}template<class E>void Dictionary<E>::dicPos(E e[]){int i;ChainNode *p;for(i=0;i<dicSize;i++){insert(e[i]);}}template<class E>bool Dictionary<E>::insert(E ent){int k;ChainNode *p1,*p2;tableSize=5;k=ent.firstLetter()%tableSize;p1=&ht[k];if(p1->link!=NULL){p1=p1->link;while(p1->link!=NULL){p1=p1->link;}}p2=new ChainNode;p2->EntryLink=ent;p2->link=NULL;p1->link=p2;return 0;}template<class E>bool Dictionary<E>::insert(string str1,string str2){ Entry<string> *e=new Entry<string> (str1,str2);insert(*e);return 1;}template<class E>void Dictionary<E>::outputDic(){int i;ChainNode *p1;for(i=0;i<tableSize;i++){//cout<<"************************************"<<endl;//cout<<i<<endl;//cout<<"****"<<endl;if(ht[i].link!=NULL){p1=&ht[i];while(p1->link!=NULL){p1=p1->link;p1->EntryLink.output();}}}//cout<<"************************************"<<endl;}template<class E>bool Dictionary<E>::remove(string str){string result;ChainNode *ptr;if(search(str,result,ptr)==1){ptr->link=ptr->link->link;return 1;}else{return 0;}}template<class E>bool Dictionary<E>::search(string str,string &result){ChainNode *ptr;return search(str,result,ptr);}template<class E>bool Dictionary<E>::search(string str,string &result,ChainNode *&ptr){ int k;ChainNode *p1,*p2;Entry<string> strEnt(str);k=strEnt.firstLetter()%dicSize;p1=&ht[k];if(p1->link!=NULL){do{ptr=p1;p1=p1->link;if(p1->EntryLink.word==strEnt.word){result=p1->EntryLink.chinese;return 1;}}while(p1->link!=NULL);return 0;}else{return 0;}}//Entry_head.h#include<assert.h>#include<string>#include<stdlib.h>using namespace std;template<class K>class Entry{public:K word;K chinese;public:Entry(K,K);Entry();Entry(K);void output();int firstLetter();};template<class K>Entry<K>::Entry(K w,K c){word=w;chinese=c;};template<class K>Entry<K>::Entry(){word="";chinese="";};template<class K>Entry<K>::Entry(K w){word=w;chinese="";};template<class K>void Entry<K>::output(){cout<<"英文:"<<word<<endl;cout<<"中文:"<<chinese<<endl<<endl;}template<class K>int Entry<K>::firstLetter(){char *strv = strdup (word.c_str());//stringתcharreturn int(strv[0]);}主要代码结构://Hash_main.cpp#include<iostream>#include<string>#include"Entry_head.h"#include"Hash_head.h"using namespace std;const int deafaultSize=10+1;int main(){cout<<"********************************************"<<endl;cout<<"***** *****"<<endl;cout<<"***** 大猫哥*****"<<endl;cout<<"***** Make By LJDe.de *****"<<endl;cout<<"***** E-mail:**********************"<<endl;cout<<"***** *****"<<endl;cout<<"********************************************"<<endl;Entry<string> e[deafaultSize]={Entry<string>("eliminate","消除"),Entry<string>("accommodation ","招待设备"),Entry<string>("convince ","使确信"),Entry<string>("conscience ","良心"),Entry<string>("lantern ","灯笼"),Entry<string>("procession ","队伍"),Entry<string>("quit","离开"),Entry<string>("pudding ","布丁"),Entry<string>("reaction ","反应"),Entry<string>("shrink ","收缩"),Entry<string>()};Dictionary< Entry<string> > dic(e);int deed;string str1,str2;Entry<string> *eLit;dic.dicPos(e);do{cout<<endl<<"*************************************************************** *************"<<endl;cout<<"1.查看已有的字典词条。
python如何制作英文字典

python如何制作英⽂字典本⽂实例为⼤家分享了python制作英⽂字典的具体代码,供⼤家参考,具体内容如下功能有添加单词,多次添加单词的意思,查询,退出,建⽴单词⽂件。
keys=[]dic={}def rdic():fr = open('dic.txt','r')for line in fr:line = line.replace("\n",'')v = line.split(':')dic[v[0]] = v[1]keys.append(v[0])fr.close()def centre():n = input("请输⼊进⼊相应模块(添加、查询、退出):")if n == "添加":key= input("plsease input English:")if key not in keys:value=input("please input Chinese:")dic[key]=valuekeys.append(key)else :t=input("如果添加新的意思请输⼊ Y,否则输⼊N:")if ( t=='Y'):temp=""temp=temp+dic[key]key1= input("请输⼊中⽂")temp=temp+","+key1print(temp)#keys.append(temp)dic[key]=tempprint(dic)return 0else:return 0elif n== "查询":key= input("plsease input English:")print(keys)print(dic)if key not in keys:print("the english not in the dic.")else :print(dic[key])elif n == "退出" :return 1else :print("输⼊有误")return 0def wdic():#print("!")with open('dic.txt','w') as fw:for k in keys:fw.write(k+':'+dic[k]+'\n')def main():rdic()while True:print(keys)print(dic)n=centre()print(keys)print(dic)if n==1:breakif n==0:continuewdic()main()以上就是本⽂的全部内容,希望对⼤家的学习有所帮助,也希望⼤家多多⽀持。
Java英汉电子字典课程设计源代码

Java英汉电子字典课程设计源代码————————————————————————————————作者:————————————————————————————————日期:用户需求分析:英汉词典作为一个常用的学习工具,是我们经常要使用的。
该系统能完成一个简单的电子词的功能。
该系统主要用于实现英汉互译的功能,系统拥有自己的数据库。
1.英译汉功能:我们可以先选择让系统进行英译汉功能,然后在查找框中输入想要查询的英文单词,系统将自动在数据库中查找匹配记录并给出相对应的汉语意思。
2.汉译英功能:我们可以在系统中选择汉译英功能,然后在查找框中输入想要查询的汉语意思,系统将自动在数据库中查找匹配记录并给出相对应的英文单词3.词汇的添加功能:用户可以添加词库内没有的单词及其解释。
添加成功后该单词将在次库内保存,以便下次查询。
4.词汇的修改功能;用户可以实现对词库中已有单词及其解释的修改。
修改后的结果将保存在词库中。
5.词汇的删除功能;用户可自行删除词库中已有的单词,同时次单词的解释也将被一同删除。
6.其他功能:此外,系统还具有帮助和关于等功能,用来辅助用户更方便简洁的使用电子词典。
package dianzicidian;import java.awt.*;import .*;import java.sql.*;import java.awt.event.*;import javax.swing.JOptionPane;import java.io.*;import sun.audio.*;class dzcd extends Frame implements ActionListener{MenuBar menubar=new MenuBar();//菜单Menu fileMenu,editMenu,helpMenu;MenuItem fileenglish,filechinese,exit,editAdd,editmod,editDel;TextField inputtext;TextArea txt;Label label1,label2;Button btn1,btnsound;Panel p,p1,p2,p3;dzcd(){super("电子词典");setBounds(200,300,350,400);setMenuBar(menubar);fileMenu=new Menu("文件");editMenu=new Menu("编辑");helpMenu=new Menu("帮助");fileenglish=new MenuItem("英汉词典");filechinese=new MenuItem("汉英词典");exit=new MenuItem("退出");editAdd=new MenuItem("添加词汇");editmod=new MenuItem("修改词汇");editDel=new MenuItem("删除词汇");menubar.add(fileMenu);menubar.add(editMenu);menubar.add(helpMenu);fileMenu.add(fileenglish);fileMenu.add(filechinese);fileMenu.addSeparator();fileMenu.add(exit);editMenu.add(editAdd);editMenu.add(editmod);editMenu.add(editDel);inputtext=new TextField("",10);txt=new TextArea(10,10);label1=new Label("输入要查询的英语单词:");label2=new Label("查询结果:");btn1=new Button("查询");btnsound=new Button("发音");p=new Panel(new BorderLayout());p2=new Panel(new FlowLayout(FlowLayout.LEFT,5,0));p2.add(label1);p2.add(inputtext);p2.add(btn1);p2.add(btnsound);add(p2,"North");p.add(label2,"North");p.add(txt,"Center");add(p,"Center");setVisible(true);setResizable(false);validate();fileenglish.addActionListener(this);filechinese.addActionListener(this);exit.addActionListener(this);editAdd.addActionListener(this);editmod.addActionListener(this);editDel.addActionListener(this);btn1.addActionListener(this);btnsound.addActionListener(this);addWindowListener(new WindowAdapter(){public void windowClosing(WindowEvent e){System.exit(0);}});}public void actionPerformed(ActionEvent e){if(e.getSource()==fileenglish)//英汉(外观变化){label1.setText("输入要查询的英语单词:");label2.setText("查询结果:");txt.setText("");btn1.setLabel("查询");btnsound.setVisible(true);}else if(e.getSource()==filechinese)//汉英(外观变化){label1.setText("输入要查询的汉语词语:");label2.setText("查询结果:");txt.setText("");btn1.setLabel("查询");btnsound.setVisible(true);}else if(e.getSource()==exit)//退出{System.exit(0);}else if(e.getSource()==btn1){if(btn1.getLabel().equals("查询"))//实现查询功能(包括英汉或汉英){txt.setText(null);try{Listwords();}catch(SQLException ee){}}else if(btn1.getLabel().equals("提交"))//实现添加功能{try{addwords();}catch(SQLException ee){}}else if(btn1.getLabel().equals("更新"))//实现修改功能{try{modwords();}catch(SQLException ee){}}else if(btn1.getLabel().equals("删除"))//实现删除功能{try{delwords();}catch(SQLException ee){}}}else if(e.getSource()==editAdd)//添加(外观变化){label1.setText("输入新单词:");label2.setText("输入中文解释:");btn1.setLabel("提交");btnsound.setVisible(false);}else if(e.getSource()==editmod)//修改(外观变化){label1.setText("输入要修改的单词:");label2.setText("输入更新后的解释:");btn1.setLabel("更新");btnsound.setVisible(false);}else if(e.getSource()==editDel)//删除(外观变化){label1.setText("输入要删除的单词:");label2.setText("");btn1.setLabel("删除");btnsound.setVisible(false);}else if(e.getSource()==btnsound)//发音{if(inputtext.getText()!=null){try{InputStream is=getClass().getResource("sound//"+inputtext.getText().trim()+".wav").openStream();AudioPlayer.player.start(is);}catch(IOException e1){}}}}public void Listwords() throws SQLException//查询实现过程{String cname,ename;try{Class.forName("sun.jdbc.odbc.JdbcOdbcDriver");}catch(ClassNotFoundException e){}Connection Ex1Con=DriverManager.getConnection("jdbc:odbc:words","","");Statement Ex1Stmt=Ex1Con.createStatement();ResultSet rs=Ex1Stmt.executeQuery("SELECT * FROM words");boolean boo=false;while((boo=rs.next())==true){ename=rs.getString("英语");cname=rs.getString("汉语");if(ename.equals(inputtext.getText())&&label1.getText().equals("输入要查询的英语单词:")){txt.append(cname);break;}else if(cname.equals(inputtext.getText())&&label1.getText().equals("输入要查询的汉语词语:")){txt.append(ename);break;}}Ex1Con.close();if(boo==false){JOptionPane.showMessageDialog(this,"查无此单词!","警告",JOptionPane.W ARNING_MESSAGE);}}public void addwords() throws SQLException//向数据库添加新词汇{String cname,ename;try{Class.forName("sun.jdbc.odbc.JdbcOdbcDriver");}catch(ClassNotFoundException e){}Connection Ex1Con=DriverManager.getConnection("jdbc:odbc:words","","");Statement Ex1Stmt=Ex1Con.createStatement();ResultSet rs=Ex1Stmt.executeQuery("SELECT * FROM words");boolean boo=false;while((boo=rs.next())==true){ename=rs.getString("英语");cname=rs.getString("汉语");if(ename.equals(inputtext.getText())&&cname.equals(txt.getText())){JOptionPane.showMessageDialog(this,"此词汇已存在!","警告",JOptionPane.W ARNING_MESSAGE);break;}}if(boo==false){Ex1Stmt.executeUpdate("INSERT INTO words (英语,汉语) V ALUES ('"+inputtext.getText().trim()+"','"+txt.getText().trim()+"')");JOptionPane.showMessageDialog(this,"添加成功!","恭喜",JOptionPane.W ARNING_MESSAGE);}Ex1Con.close();}public void modwords() throws SQLException//修改词库中记录{String ename;try{Class.forName("sun.jdbc.odbc.JdbcOdbcDriver");}catch(ClassNotFoundException e){}Connection Ex1Con=DriverManager.getConnection("jdbc:odbc:words","","");Statement Ex1Stmt=Ex1Con.createStatement();ResultSet rs=Ex1Stmt.executeQuery("SELECT * FROM words");boolean boo=false;while((boo=rs.next())==true){ename=rs.getString("英语");if(ename.equals(inputtext.getText())){Ex1Stmt.executeUpdate("UPDA TE words SET 汉语='"+txt.getText().trim()+"' WHERE 英语='"+inputtext.getText().trim()+"'");JOptionPane.showMessageDialog(this,"记录修改成功!","恭喜",JOptionPane.W ARNING_MESSAGE);break;}}Ex1Con.close();if(boo==false){JOptionPane.showMessageDialog(this,"不存在此单词!","警告",JOptionPane.W ARNING_MESSAGE);}}public void delwords() throws SQLException//删除词库中记录{@SuppressWarnings("unused")String cname,ename;try{Class.forName("sun.jdbc.odbc.JdbcOdbcDriver");}catch(ClassNotFoundException e){}ConnectionEx1Con=DriverManager.getConnection("jdbc:odbc:wordskechengsheji","","");Statement Ex1Stmt=Ex1Con.createStatement();ResultSet rs=Ex1Stmt.executeQuery("SELECT * FROM words");boolean boo=false;while((boo=rs.next())==true){ename=rs.getString("英语");cname=rs.getString("汉语");if(ename.equals(inputtext.getText())){Ex1Stmt.executeUpdate("DELETE FROM words WHERE 英语='"+inputtext.getText().trim()+"'");JOptionPane.showMessageDialog(this,"成功删除记录!","恭喜",JOptionPane.W ARNING_MESSAGE);break;}}Ex1Con.close();if(boo==false){JOptionPane.showMessageDialog(this,"不存在此单词!","警告",JOptionPane.W ARNING_MESSAGE);}}public static void main(String args[]){new dzcd();}}。
Java学习期末项目词典项目完整源码
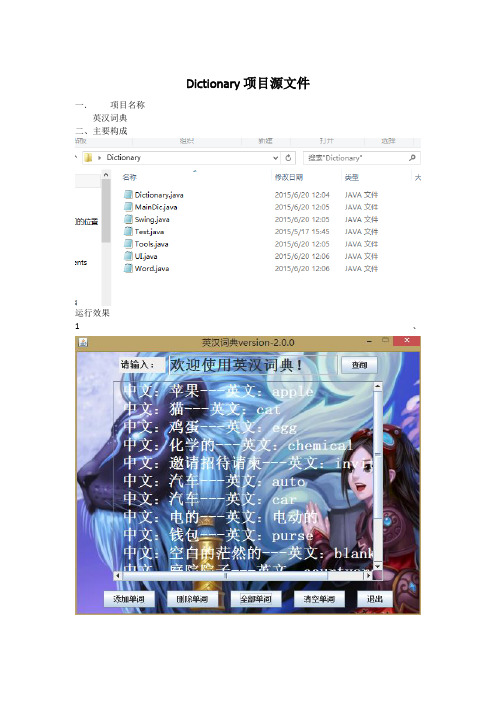
Dictionary项目源文件一.项目名称英汉词典二、主要构成运行效果1、三、项目介绍本项目使用文件存储数据1、Dictionary类,包含对单词的各种操作,如添加单词,查询单词,删除单词2、Swing类,窗体界面类运行效果图如下3、Tools类,文件储存工具类4、Word单词属性类5、UI,此UI为控制台版本词典,如不需窗体可以使用此类,运行效果Dictionary类源代码package Dictionary;/***引用请注明原作者-爱露YS***/import java。
util.*;public class Dictionary {List〈Word〉list =new ArrayList〈Word〉();//建立动态链表public List<Word〉getList() {return list;}public void setList(List〈Word〉list) {this。
list = list;}public Dictionary() {super();}public Dictionary(Word word) {}public Word addWord(Word word) {//1、增加单词list.add(word) ;//输出新增加的单词return word;}public Word searchWord(String str ) {//2、查找单词// if (input_ce !=null) 不需要判空for (int j = 0;j 〈list。
size(); j++)if((str。
equals(((Word)list。
get(j)).getcWord()))||((Word) list。
get(j)).geteWord().equalsIgnoreCase(str))return (Word) list。
get(j);return null;}public String sysoAllWrod() {//3、输出全部单词List <Word> list= getList();for(Word word :list)return word。
一个完整的从语言写的电子字典源码

C语言项目——查字典【项目需求描述】一、单词查询给定文本文件“dict.txt”,该文件用于存储词库。
词库为“英-汉”,“汉-英”双语词典,每个单词和其解释的格式固定,如下所示:#单词Trans:解释1@解释2@…解释n每个新单词由“#”开头,解释之间使用“@”隔开。
一个词可能有多个解释,解释均存储在一行里,行首固定以“Trans:”开头。
下面是一个典型的例子:#abyssinianTrans:a. 阿比西尼亚的@n. 阿比西尼亚人;依索比亚人该词有两个解释,一个是“a. 阿比西尼亚的”;另一个是“n. 阿比西尼亚人;依索比亚人”。
要求编写程序将词库文件读取到内存中,接受用户输入的单词,在字典中查找单词,并且将解释输出到屏幕上。
用户可以反复输入,直到用户输入“exit”字典程序退出。
程序执行格式如下所示:./app –test2-test2表示使用文本词库进行单词查找。
二、建立索引,并且使用索引进行单词查询要求建立二进制索引,索引格式如下图所示。
将文本文件“dict.txt”文件转换为上图所示索引文件“dict.dat”,使用索引文件实现单词查找。
程序执行格式如下:./app –index-index表示使用文本词库dict.txt建立二进制索引词库dict.dat./app –test2-test2表示使用二进制索引词库进行单词查找。
三、支持用户自添加新词用户添加的新词存放在指定文件中。
如果待查单词在词库中找不到,则使用用户提供的词库。
用户的词库使用文本形式保存,便于用户修改。
程序执行格式图1-1所示。
./app 词库选择选项-f 用户词库文件名词库选项为-test1,或者-test2,表示使用文本词库或者二进制索引词库。
-f为固定参数,用来指定用户词库文件名。
图1-1【项目要求】❑尽量考虑程序执行的效率,尽量减少开销,提高程序速度❑尽量考虑模块化程序设计思想,能够引入面向对象的设计模式和方法❑保证代码的可读性,紧凑的组织代码❑清晰设计思想和设计思路,代码实现尽量简洁❑可以完成相应的拓展功能,例如用户自添加单词,建立索引以提高查找速度等【考察知识点】(1)变量数据类型(2)数组(3)结构体(4)typedef关键字的使用(5)控制结构(6)函数接口设计(7)static关键字的使用(8)文件拆分与代码组织(9)模块化设计思想(10)简单的面向对象程序设计思想(11)指针与指针控制(12)const关键字的使用(13)C语言程序的命令行参数(14)多文件符号解析(15)头文件包含(16)宏(17)条件编译(18)字符串操作(19)malloc函数(20)常用的字符串库函数(21)文件操作(22)简单的出错处理(23)排序算法和二分查找算法(24)二进制文件和文本文件的区别(25)链表操作(26)makefile的使用(27)编程工具的使用(vi,gcc,gdb)(28)文档组织和项目规划【未考察到的知识点】(1)变参函数(2)函数指针(3)泛型算法(4)复杂链表的链表操作(5)栈和队列(6)二叉树。
python在生词本查单词的译文

python在生词本查单词的译文
Python(也称为蟒蛇)是一种非常流行的编程语言,其有着广泛的应用,包括数据科学、人工智能、网络编程等领域。
在Python中,可以使用内置的函数或第三方库来查询生词的译文。
例如,使用Googletrans库可以将英语单词翻译为中文,该库可以通过在命令行中使用pip install googletrans来安装。
使用该库的示例代码如下:from googletrans import Translator
# 创建翻译器对象
translator = Translator()
# 要查询的单词
word = "apple"
# 调用翻译函数并输出翻译结果
result = translator.translate(word, dest='zh-CN').text
print(result)
在上述代码中,首先导入了Googletrans库,然后创建了一个翻译器对象。
接着定义要查询的单词,然后调用翻译函数并指定目标语言为中文,最后输出翻译结果。
在实际使用中,还可以将该功能和其他库或API结合起来,实现更多的自动化和批量查询功能。
Python字典(Dictionary)

Python字典(Dictionary)Python中字典与类表类似,也是可变序列,不过与列表不同,他是⽆序的可变序列,保存的内容是以键 - 值对的形式存放的。
类似我们的新华字典,他可以把拼⾳和汉字关联起来,通过⾳节表可以快速的找到想要的字。
新华字典中的⾳节相当于(key),⽽对应的汉字,相当于值(value)。
键是唯⼀的,⽽值可以有多个。
⽰例代码:dictionary = {"key1": "value1", "key2": "value2".....}分析:key:表⽰元素的键,必须是唯⼀的并且不可变,可以是字符串、数字或元组等value:表⽰值,可以是任何类型数据,不是唯⼀的。
字典的创建和删除⽰例代码:dicts = {"name": "张三", "sex": "男", "age": 18}print(dicts)执⾏结果:{"name": "张三", "sex": "男", "age": 18}创建空字典:dictionary = {}或dictionary = dict()将列表合并为字典dictionary = dict(zip(list1,list2))dictionary:字典的名称zip()函数:⽤于将多个列表或元组对应的位置的元素组合为元组,并返回⽩喊这些内容的zip对象,如果想获取元组,可以将zip对象使⽤tuple()函数转换为这个元组;如果想获取列表,则可以使⽤list()函数将其转换为列表。
⽰例代码:name = ["⼩王", "⼩明", "⼩张"]class1 =["⼀班", "⼆班", "三班"]dictionary = dict(zip(name,class1))print(dictionary)执⾏结果:{'⼩王': '⼀班', '⼩明': '⼆班', '⼩张': '三班'}通过给定的"键-值队:创建字典⽰例代码:dictionary = dict(张三="⽔平座", 李四="射⼿座")print(dictionary)执⾏结果:{'张三': '⽔平座', '李四': '射⼿座'}创建值为空的字典⽰例代码:name = ["张三", "李四"]dictionary = dict.fromkeys(name)print(dictionary)执⾏结果:{'张三': None, '李四': None}通过元组和列表创建字典⽰例代码:name = ("张三", "李四")age = [18, 20]dictionary = {name:age}print(dictionary)执⾏结果:{('张三', '李四'): [18, 20]}注意两个对象都为列表会报错:name = ["张三", "李四"]age = [18, 20]dictionary = {name:age}print(dictionary)执⾏结果:Traceback (most recent call last):File "D:/xuexi/python/Demo.py", line 3, in <module>dictionary = {name:age}TypeError: unhashable type: 'list'删除字典同列表与元组⼀样使⽤del删除字典⽰例代码:name = {"张三": 18, "李四": 20}print(name)del nameprint(name)执⾏结果:Traceback (most recent call last):{'张三': 18, '李四': 20}File "D:/xuexi/python/Demo.py", line 4, in <module>print(name)NameError: name 'name' is not defined访问字典直接指定key访问⽰例代码:name = {"张三": 18, "李四": 20}print(name["李四"])执⾏结果:20使⽤get()⽅法访问⽰例代码:name = {"张三": 18, "李四": 20}print(name.get("李四"))执⾏结果:20key不存在出现报错解决办法如果key不存在会出现KeyError: 'value'报错,下⾯提供两个解决⽅式:*使⽤3元运算符判断key是否存在使⽤dictionary[value] if value in dictionary else "⾃定义不存在返回值",如果value在字典中则返回value如果不存在返回⾃定义值。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
字典最快速的实现方法是trie tree。
这个树是专门用来实现字典的。
但是trie tree的删除操作比较麻烦。
用二叉查找树可以实现,速度也可以很快。
AVL tree只不过是平衡的二叉树,在字典这个应用上没有客观的速度提升,因为字典不会产生极端化的二叉树(链表)。
下面是我的二叉查找树的代码。
二叉查找树的优点是实现容易,而且它的inorder traverse 既是按照字母顺序的输出。
//binary search tree, not self-balancing
//by Qingxing Zhang, Dec 28,2009. prep for google interview
#include <iostream>
using namespace std;
struct BST
{
int data;
BST *left;
BST *right;
};
//runtime: O(logn) on average, O(n) worst case
bool search(BST *&root, int key)//return false if the key doesn't exist
{
if(root==NULL)
return false;
if(key < root->data)
return search(root->left,key);
else if(key > root->data)
return search(root->right,key);
else
return true;
}
//runtime: O(logn)on average, O(n) worst case
bool insert(BST *&root, int key)//return false if the key already exists
{
if(root==NULL)
{
BST *node = new BST;
node->data = key;
node->left = node->right = NULL;
root = node;
return true;
}
else if(key < root->data)
return insert(root->left,key);
else if(key > root->data)
return insert(root->right,key);
else
return false;
}
//runtime:O(logn) on average, O(n) worst case
bool remove(BST *&root,int key)//return false if the key doesn't exist.
{
if(root==NULL)//no such key
return false;
else if(key < root->data)
return remove(root->left,key);
else if(key > root->data)
return remove(root->right,key);
else//node found
{
if((root->left==NULL)&&(root->right==NULL))//no child(leaf node)
{
BST *tmp = root;
root = NULL;
delete tmp;
}
else if((root->left==NULL)||(root->right==NULL))//one child
{
BST *tmp = root;
if(root->left==NULL)
root = root->right;
else
root = root->left;
delete tmp;
}
else//two children:replace node value with inorder successor and delete that node {
BST *tmp = root->right;
while(tmp->left!=NULL)
tmp = tmp->left;
int tmpdata = tmp->data;
remove(root,tmpdata);
root->data = tmpdata;
}
return true;
}
}
//runtime:O(n)
void inorder(BST *&node) {
if(node!=NULL)
{
inorder(node->left);
cout << node->data << " ";
inorder(node->right);
}
}
//runtime:O(n)
void preorder(BST *&node) {
if(node!=NULL)
{
cout << node->data << " ";
preorder(node->left);
preorder(node->right);
}
}
//runtime:O(n)
void postorder(BST *&node) {
if(node!=NULL)
{
postorder(node->left);
postorder(node->right);
cout << node->data << " "; }
}
int main()
{
bool b;
BST *root = NULL;
b = insert(root,1);
b = insert(root,7);
b = insert(root,5);
b = insert(root,77);
b = insert(root,10);
b = insert(root,4);
b = insert(root,13);
//inorder
cout << "In-order:";
inorder(root);
cout << endl;
//preorder
cout << "Pre-order:";
preorder(root);
cout << endl;
//postorder
cout << "Post-order:";
postorder(root);
cout << endl;
// search for 7
if(search(root,7))
cout << "7 found!" << endl;
else
cout << "7 doesn't exist!" << endl;
b = remove(root,7);
cout << "----------------" << endl;
//inorder
cout << "In-order:";
inorder(root);
cout << endl;
//preorder
cout << "Pre-order:";
preorder(root);
cout << endl;
//postorder
cout << "Post-order:";
postorder(root);
cout << endl;
cout << "7 found!" << endl;
else
cout << "7 doesn't exist!" << endl; return 0;
}。