矩阵快速幂求斐波那契数列c语言
矩阵快速幂求斐波那契数列

矩阵快速幂求斐波那契数列
斐波那契数列堪称数学及计算机科学领域中一个重要的研究课题,也是一个典型的递归定义。
此数列以其独特的数字排列在计算机科学中被广泛地用于研究各种算法的性能。
如今,矩阵快速幂方法给了研究者一种新的思路,大大减少了求解斐波那契数列时的时间复杂度。
矩阵快速幂算法通过一系列矩阵乘法运算,在时间复杂度是常数级别的情况下完成斐波那契数列的求解。
因为它消除了昂贵的重复计算,使得求解斐波那契数列问题更加有效率。
该算法特别适合在对时间要求极为严格的应用场景中使用,例如:进行大规模的分析与比较,或是加密解码这样的要求熟练操作的高耗时的运算问题。
斐波那契数列的存在给了计算机程序设计者在很多方面带来了方便。
矩阵快速幂方法是一种革命性的技术,它不仅降低了斐波那契数列的求解时间复杂度,而且可以为更多新的算法开发打开大门,从而更好的利用数字技术,完善互联网的发展。
C语言中斐波那契数列的三种实现方式(递归、循环、矩阵)
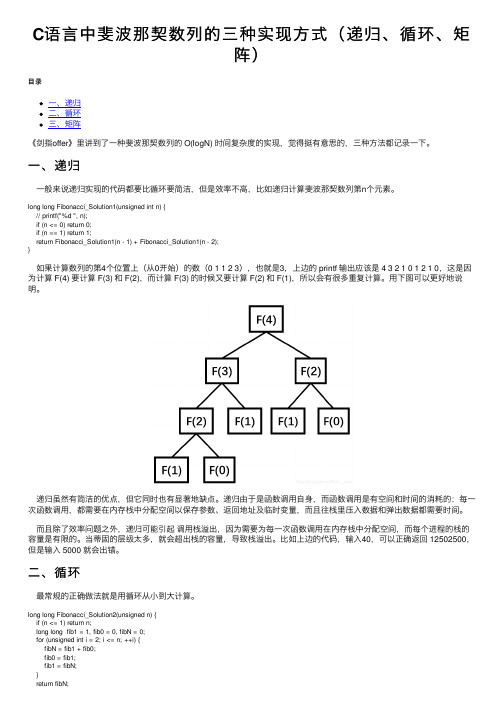
C语⾔中斐波那契数列的三种实现⽅式(递归、循环、矩阵)⽬录⼀、递归⼆、循环三、矩阵《剑指offer》⾥讲到了⼀种斐波那契数列的 O(logN) 时间复杂度的实现,觉得挺有意思的,三种⽅法都记录⼀下。
⼀、递归⼀般来说递归实现的代码都要⽐循环要简洁,但是效率不⾼,⽐如递归计算斐波那契数列第n个元素。
long long Fibonacci_Solution1(unsigned int n) {// printf("%d ", n);if (n <= 0) return 0;if (n == 1) return 1;return Fibonacci_Solution1(n - 1) + Fibonacci_Solution1(n - 2);}如果计算数列的第4个位置上(从0开始)的数(0 1 1 2 3),也就是3,上边的 printf 输出应该是 4 3 2 1 0 1 2 1 0,这是因为计算 F(4) 要计算 F(3) 和 F(2),⽽计算 F(3) 的时候⼜要计算 F(2) 和 F(1),所以会有很多重复计算。
⽤下图可以更好地说明。
递归虽然有简洁的优点,但它同时也有显著地缺点。
递归由于是函数调⽤⾃⾝,⽽函数调⽤是有空间和时间的消耗的:每⼀次函数调⽤,都需要在内存栈中分配空间以保存参数、返回地址及临时变量,⽽且往栈⾥压⼊数据和弹出数据都需要时间。
⽽且除了效率问题之外,递归可能引起调⽤栈溢出,因为需要为每⼀次函数调⽤在内存栈中分配空间,⽽每个进程的栈的容量是有限的。
当蒂固的层级太多,就会超出栈的容量,导致栈溢出。
⽐如上边的代码,输⼊40,可以正确返回 12502500,但是输⼊ 5000 就会出错。
⼆、循环最常规的正确做法就是⽤循环从⼩到⼤计算。
long long Fibonacci_Solution2(unsigned n) {if (n <= 1) return n;long long fib1 = 1, fib0 = 0, fibN = 0;for (unsigned int i = 2; i <= n; ++i) {fibN = fib1 + fib0;fib0 = fib1;fib1 = fibN;}return fibN;}或者下边这种long long Fibonacci_Solution2(unsigned n) {if (n <= 1) return n;long long a = 0, b = 1;for (unsigned int i = 2; i <= n; ++i) {b = a + b;a =b - a;}return b;}三、矩阵数中提到了⼀种 O(logN) 时间复杂度的算法,就是利⽤数学公式计算。
c语言数组斐波那契数列

c语言数组斐波那契数列
斐波那契数列,又称黄金分割数列,是指这样一个数列:0、1、1、2、3、5、8、13、21、34、……在数学上,斐波那契数列以递归的方式定义:
F(0) = 0, F(1) = 1
F(n) = F(n-1) + F(n-2) (n>=2)
在C语言中,可以使用数组来实现斐波那契数列的计算。
以下是一个示例代码:
#include<stdio.h>
int main()
{
int n, i;
printf('请输入斐波那契数列的项数:');
scanf('%d', &n);
int fib[n];
fib[0] = 0;
fib[1] = 1;
for(i=2; i<n; i++)
{
fib[i] = fib[i-1] + fib[i-2];
}
printf('斐波那契数列的前%d项为:', n);
for(i=0; i<n; i++)
{
printf('%d ', fib[i]);
}
return 0;
}
以上代码中,通过定义一个大小为n的整型数组fib来存储斐波那契数列的前n项。
在数组中,fib[0]表示第一项,fib[1]表示第二项,以此类推。
在for循环中,通过计算fib[i] = fib[i-1] + fib[i-2]来求出每一项的值。
最后通过for循环输出斐波那契数列的前n项。
c++中斐波那契问题的编程

一、概述在计算机编程领域,斐波那契数列问题是一个经典且重要的问题。
斐波那契数列是由0和1开始,之后的每一项都是前两项的和。
斐波那契数列可以用递归、迭代等方式进行求解,而在C++语言中,我们可以利用不同的方法来编程实现斐波那契数列的计算。
本文将介绍在C++语言中如何通过递归、动态规划和矩阵快速幂等方法解决斐波那契问题。
二、递归方法1. 概述递归是一种常用的解决问题的方法,它将问题分解为更小的子问题来解决。
在计算斐波那契数列时,可以使用递归方法来实现。
2. 代码实现下面是使用递归方法计算斐波那契数列的C++代码示例:```cppint fibonacci(int n) {if (n <= 1) {return n;}return fibonacci(n - 1) + fibonacci(n - 2);}```以上代码中,我们定义了一个名为fibonacci的函数,输入参数为n,表示计算第n个斐波那契数。
在函数中,如果n小于等于1,则直接返回n;否则,通过递归调用fibonacci函数来计算第n-1和n-2个斐波那契数,并将它们相加得到结果。
3. 分析尽管递归方法在实现上非常简单,但是它在计算斐波那契数列时存在严重的效率问题。
由于递归方法会重复计算相同的子问题,导致时间复杂度极高,因此在计算较大的斐波那契数时,递归方法效率极低,甚至会导致栈溢出问题。
三、动态规划方法1. 概述动态规划是一种将问题分解为更小的子问题来解决,并将子问题的解保存下来以避免重复计算的方法。
在计算斐波那契数列时,可以使用动态规划方法来提高效率。
2. 代码实现下面是使用动态规划方法计算斐波那契数列的C++代码示例:```cppint fibonacci(int n) {int dp[n + 1];dp[0] = 0;dp[1] = 1;for (int i = 2; i <= n; i++) {dp[i] = dp[i - 1] + dp[i - 2];}return dp[n];}```以上代码中,我们使用数组dp来保存斐波那契数列的结果,初始时设置dp[0]为0,dp[1]为1。
c++ 矩阵快速幂 斐波那契数列

C++ 中的矩阵快速幂算法在解决斐波那契数列问题上有着重要的应用。
矩阵快速幂算法是一种高效的算法,可以在较短的时间内计算出斐波那契数列的第 n 个数。
本文将从原理、实现和应用三个方面介绍矩阵快速幂算法在 C++ 中解决斐波那契数列问题的具体方法。
【一、矩阵快速幂原理】1、斐波那契数列定义斐波那契数列是一个经典的数列问题,其定义如下:F(0) = 0F(1) = 1F(n) = F(n-1) + F(n-2), n > 12、矩阵快速幂算法矩阵快速幂算法是利用矩阵相乘的快速计算方法,来加速斐波那契数列的计算过程。
其原理如下:设矩阵 A = {{1, 1}, {1, 0}},则有:A^n = {{F(n+1), F(n)}, {F(n), F(n-1)}}其中 A^n 表示矩阵 A 的 n 次方。
【二、矩阵快速幂实现】1、矩阵乘法在 C++ 中,可以通过重载运算符实现矩阵的相乘操作。
代码如下:```cpp// 重载矩阵乘法Matrix operator*(const Matrix a, const Matrix b) {Matrix c;for (int i = 0; i < 2; i++) {for (int j = 0; j < 2; j++) {c.m[i][j] = 0;for (int k = 0; k < 2; k++) {c.m[i][j] += a.m[i][k] * b.m[k][j];}}}return c;}```2、矩阵快速幂算法利用矩阵乘法和快速幂算法,可以很容易地实现矩阵快速幂算法。
具体代码如下:```cpp// 矩阵快速幂算法Matrix matrixPow(Matrix a, int n) {Matrix res;res.init(); // 初始化单位矩阵while (n) {if (n 1) res = res * a;a = a * a;n >>= 1;}return res;}```【三、矩阵快速幂应用】1、斐波那契数列求解利用矩阵快速幂算法,可以在 O(logn) 的时间复杂度内求解斐波那契数列的第 n 个数。
C语言----两种方法用C语言代码实现斐波那契数列

C语⾔----两种⽅法⽤C语⾔代码实现斐波那契数列⽅法⼀:调⽤函数(递归)#include<stdio.h>int fac(int n)//递归函数{int res;if(n==1||n==2)//前两项是 1 如果没有{},那么默认执⾏其后⾯跟着的⼀条语句return 1;return res=fac(n-1)+fac(n-2);//实⾏递归,第三项开始是第⼆项的值加第⼀项}int main(){int n,ans;//n代表第n项scanf("%d",&n);ans=fac(n)%10000;//调⽤递归函数printf("%d",ans);return 0;//有局限,到第40项以后会算的特别慢,更⼤之后可能因为值的溢出所以不出结果了}第47项后值溢出变为负数⽅法⼆:(递推)#include<stdio.h>int main(){int n,ans,i;int a=1,b=1,c=0;//a , b 分别为第⼀⼆项,C为第三项scanf("%d",&n);for(i=3;i<=n;i++){c=a+b;//a,b,c的值开始逐个推换a=b;b=c;}printf("%d",c);return 0;}补充:如果是求第xxxxxxxxx项的后四位数字,即可在for循环⾥添加:if(c>10000){a%=10000;b%=10000;c%=10000;}但是如果千位为0;那么只输出三位数字。
c语言计算斐波那契数列 linux编译

c语言计算斐波那契数列 linux编译
斐波那契数列是指这样一个数列:0、1、1、2、3、5、8、13、21......即第n个数是由它前面两个数相加而来的。
以下是计算斐波那契数列的C语言代码:
```
#include<stdio.h>
int main() {
int n, i;
long long f1 = 0, f2 = 1, f3; //初始化前两个数值
printf("请输入要计算的斐波那契数列个数n:");
scanf("%d",&n);
printf("斐波那契数列的前%d个数为:\n",n);
printf("%lld %lld ",f1,f2); //先输出前两个数
for(i = 3; i <= n; i++) {
f3 = f1 + f2;
printf("%lld ",f3);
f1 = f2;
f2 = f3;
}
return 0;
}
```
代码分析:
1.首先定义变量n、i、f1、f2、f3,f1、f2分别赋值为0、1。
2.通过printf函数输出要计算的斐波那契数列的个数。
3.通过scanf函数读取用户输入的n值。
4.通过printf函数输出斐波那契数列的前两个数。
5.通过for循环,从第三个数开始计算,每次将f1、f2的值相
加得到f3,并依次更新f1、f2的值,直到计算完所有的斐波那契数列元素。
6.返回0表示程序结束。
算法之矩阵计算斐波那契数列

算法之矩阵计算斐波那契数列算法之矩阵计算斐波那契数列本节内容1. 斐波那契介绍2. 普通⽅式求解斐波那契3. 矩阵概念4. 矩阵求幂5. 矩阵求解斐波那契1.斐波那契介绍斐波那契数列有关⼗分明显的特点,那是:前⾯相邻两项之和,构成了后⼀项。
即f(n)=f(n-1)+f(n-2),f(0)=0,f(1)=f(2)=1,推导下去f(3)=2,f(4)=3,f(5)=5。
2.普通⽅式求解斐波那契按照上⾯提供的推导公式,普通⽅式求解斐波那契数列代码如下:1def normal(n):2 a,b,c=0,1,13while n:4 a,b,c=b,c,b+c5 n-=16return a使⽤上⾯的⽅式求解第n项斐波那契数列的时间复杂度为O(n),也就是说,时间复杂度随着n的增长⽽线性增长。
3.矩阵概念开始,先来介绍⼀下矩阵的概念:在数学中,矩阵(Matrix)是⼀个按照长⽅阵列排列的复数或实数集合,最早来⾃于⽅程组的系数及常数所构成的⽅阵。
这⾥不介绍矩阵的各⽅⾯知识了,如果那样的话。
就是⼀篇数学笔记了。
这⾥只讲解矩阵相乘的概念。
矩阵相乘:矩阵相乘最重要的⽅法是⼀般矩阵乘积。
它只有在第⼀个矩阵的列数(column)和第⼆个矩阵的⾏数(row)相同时才有意义。
⼀般单指矩阵乘积时,指的便是⼀般矩阵乘积。
⼀个m×n的矩阵就是m×n个数排成m⾏n列的⼀个数阵。
由于它把许多数据紧凑的集中到了⼀起,所以有时候可以简便地表⽰⼀些复杂的模型。
设A为m*p的矩阵,B为p*n的矩阵,那么称m*n的矩阵C为矩阵A与B的乘积,记作C=AB:4.矩阵求幂上⾯已经介绍过了矩阵相乘的概念了,那么,斐波那契该怎么由矩阵标⽰呢?从第三项开始,每⼀项都是前两项之和。
F(n)=F(n−1)+F(n−2), n⩾3 把斐波那契数列中相邻的两项F(n)和F(n−1)写成⼀个2×1的矩阵。
斐波那契数列⽤矩阵推导如下:求F(n)等于求⼆阶矩阵的n - 1次⽅,结果取矩阵第⼀⾏第⼀列的元素。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
矩阵快速幂求斐波那契数列c语言
矩阵快速幂求解斐波那契数列
——C语言实现
斐波那契数列是一种经典的数学问题,在计算机领域中应用广泛。
其
定义是:第1项和第2项为1,第n项为前两项的和。
即F(1)=1,F(2)=1, F(n)=F(n-1)+F(n-2)。
在计算斐波那契数列时,最通用的方法是递归算法,但是该算法效率
低下。
当n变得较大时,递归算法的时间复杂度将指数级增长。
为了
提高计算效率,我们可以采用矩阵快速幂算法。
矩阵快速幂算法原理:
我们将斐波那契数列看成一维矩阵,用矩阵乘法的方法来求解斐波那
契数列。
矩阵乘法的规则是:若A与B是n行m列和m行p列的矩阵,则它们的乘积C为n行p列的矩阵,其中C[i][j]的值是A[i][1]*B[1][j]
+ A[i][2]*B[2][j] + …+ A[i][m]*B[m][j]。
例如,若我们要求F(10),则可将其表示为如下矩阵的形式:
| F(10) | = |F(n-1) F(n-2)| * | 1 1 |
| 1 0 |
其中,矩阵 | 1 1 | 称为矩阵A,矩阵 | 1 0 | 称为矩阵B。
可以发现,在右边的矩阵乘积中,第一项是F(n-1)和矩阵A相乘,第二项是F(n-2)和矩阵B相乘,恰好对应斐波那契数列的定义。
根据矩阵乘法规则,我们可以得到:F(10) = F(9)·A = F(8)·A·A =
F(2)·A^8·A = A^9,其中A^8表示A的8次方。
这样,我们就将乘法拆分成了多个矩阵乘法,从而提高计算效率,减少了递归过程中的重复计算。
C语言实现:
下面是C语言的实现代码:
#include <stdio.h>
#define N 2
void matrixMul(int a[N][N], int b[N][N], int c[N][N])
{
int i, j, k;
for(i = 0; i < N; i++)
{
for(j = 0; j < N; j++)
{
c[i][j] = 0;
{
c[i][j] += a[i][k]*b[k][j];
}
}
}
}
void matrixPow(int A[N][N], int n, int B[N][N]) {
int i, j;
int C[N][N], D[N][N];
for(i = 0; i < N; i++)
for(j = 0; j < N; j++)
{
if(i == j) B[i][j] = 1;
else B[i][j] = 0;
}
for(i = 0; i < N; i++)
for(j = 0; j < N; j++)
C[i][j] = A[i][j];
while(n > 0)
{
if(n % 2 == 1)
{
matrixMul(B, C, D);
for(i = 0; i < N; i++)
B[i][j] = D[i][j];
}
matrixMul(C, C, D);
for(i = 0; i < N; i++)
for(j = 0; j < N; j++)
C[i][j] = D[i][j];
n = n/2;
}
}
int main()
{
int A[N][N] = {{1, 1}, {1, 0}};
int B[N][N];
matrixPow(A, 10, B);
printf("F(10) = %d\n", B[0][1]);
return 0;
}
该实现代码中,matrixMul函数实现了矩阵乘法,matrixPow函数实现了矩阵快速幂算法,最后在主函数中调用matrixPow函数即可求解
F(10)的值。
总结:
矩阵快速幂算法是一种高效的斐波那契数列计算方法,并且可以更广泛地应用到其他数学问题中。
在程序实现中,需要注意矩阵乘法的规则和矩阵快速幂算法的细节,才能保证代码正确性和效率。