编译原理LR1
简述 slr(1)和 lr(1)文法的定义(一)

简述 slr(1)和 lr(1)文法的定义(一)简述 SLR(1) 和 LR(1) 文法SLR(1)和LR(1)是两种常见的自底向上的语法分析算法。
它们都可以用于语法分析器生成过程中,帮助开发者构建和验证语法分析器。
下面将对SLR(1)和LR(1)的相关定义进行列举,并阐述理由和书籍简介。
SLR(1)文法•定义:SLR(1)(Simple LR)文法是一种自底向上的语法分析方法,它使用LR(0)项目集作为状态,具有一定的限制,只能处理一些相对简单的文法。
SLR(1)文法通过构造LR(0)自动机,然后结合First集和Follow集来进行分析。
•理由:SLR(1)文法的优势是在实现过程中相对简单,并且可以处理一些常见的文法,例如算术表达式、条件语句等。
由于SLR(1)文法的限制较多,相比其他更复杂的LR分析方法,其文法设计要求相对低,因此更适合初学者理解和使用。
•书籍简介:《编译原理》(作者:龙书)是一本经典的编译原理教材,其中涵盖了SLR(1)文法的相关内容。
这本书详细介绍了语法分析的各种方法,从简单的自底向上方法到更复杂的自顶向下方法,包括SLR(1)文法的构造和应用。
《编译原理》对于初学者来说是一本很好的参考书,可以帮助读者理解SLR(1)文法及其在语法分析中的应用。
LR(1)文法•定义:LR(1) 文法是一种更强大的自底向上语法分析方法,通过考虑下一个输入符号的展望符号(look-ahead)来解决由于有多个项目具有相同的前缀而导致的归约冲突。
LR(1) 文法通过构造 LR(1) 项目集来构建 LR(1) 分析表。
•理由:相比 SLR(1) 文法,LR(1) 文法可以处理更复杂的文法,具有更强的表达能力。
通过展望符号的引入,LR(1)文法能够更准确地分析语法,解决冲突。
在实际的编译器设计中,LR(1) 文法更为常用,可以处理包括C、Java等语言中的大部分语法规则。
•书籍简介:《编译原理与设计》(作者: Aho, Lam, R. Sethi, Ullman)是一本经典的编译原理教材,其中详细介绍了LR(1)文法及其相关内容。
编译原理语法分析程序设计(LL(1)分析法)

编译原理语法分析程序设计(LL(1)分析法)1. 实验目的:掌握 LL(1)分析法的基本原理,掌握 LL(1)分析表的构造方法,掌握 LL(1)驱动程序的构造方法。
2.实验要求:实现 LR分析法(P147,例 4.6)或预测分析法(P121,例4.3)。
3.实验环境:一台配置为 1G 的 XP 操作系统的 PC机;Visual C++6.0.4.实验原理:编译程序的语法分析器以单词符号作为输入,分析单词符号串是否形成符合语法规则的语法单位,如表达式、赋值、循环等,最后看是否构成一个符合要求的程序,按该语言使用的语法规则分析检查每条语句是否有正确的逻辑结构,程序是最终的一个语法单位。
编译程序的语法规则可用上下文无关文法来刻画。
语法分析的方法分为两种:自上而下分析法和自下而上分析法。
自上而下就是从文法的开始符号出发,向下推导,推出句子。
而自下而上分析法采用的是移进归约法,基本思想是:用一个寄存符号的先进后出栈,把输入符号一个一个地移进栈里,当栈顶形成某个产生式的一个候选式时,即把栈顶的这一部分归约成该产生式的左邻符号。
自顶向下带递归语法分析:1、首先对所以的生成式消除左递归、提取公共左因子2、在源程序里建立一个字符串数组,将所有的生成式都存在这个数组中。
3、给每个非终结符写一个带递归的匹配函数,其中起始符的函数写在 main 函数里。
这些函数对生成式右边从左向右扫描,若是终结符直接进行匹配,匹配失败,则调用出错函数。
如果是非终结符则调用相应的非终结符函数。
4、对输入的符号串进行扫描,从起始符的生成式开始。
如果匹配成功某个非终结符生成式右边的首个终结符,则将这个生成式输出。
匹配过程中,应该出现的非终结符没有出现,则出错处理。
5.软件设计与编程:对应源程序代码:#include#include1#includeusing namespace std;struct Node1{char vn;char vt;char s[10];}MAP[20];//存储分析预测表每个位置对应的终结符,非终结符,产生式int k;//用 R 代表E”,W 代表T”,e 代表空char start=“E”;int len=8;charG[10][10]={“E->TR”,”R->+TR”,”R->e”,”T->FW”,”W->*FW”,”W ->e”,”F->(E)”,”F->i”};//存储文法中的产生式char VN[6]={“E”,”R”,”T”,”W”,”F”};//存储非终结符char VT[6]={“i”,”+”,”*”,”(“,”)”,”#”};//存储终结符charSELECT[10][10]={“(,i”,”+”,”),#”,”(,i”,”*”,”+,),#”,”(“,”i”};//存储文法中每个产生式对应的 SELECT 集charRight[10][8]={“->TR”,”->+TR”,”->e”,”->FW”,”->*FW”,”->e”,”->(E)”,”->i”};stack stak;bool compare(char *a,char *b){2int i,la=strlen(a),j,lb=strlen(b);for(i=0;i1;j--){stak.push(action[j]);}}}if(strcmp(output,”#”)!=0)return “ERROR”;}int main (){freopen(“in.txt”,”r”,stdin);char source[100];int i,j,flag,l,m;printf(“\n***为了方便编写程序,用 R 代表E”,W 代表T”,e 代表空*****\n\n”);printf(“该文法的产生式如下:\n”);for(i=0;i>source){ printf(“\n 分析结果:%s\n\n”,Analyse(source));}return 0;}6. 程序测试结果:3。
编译原理 语法分析(2)_ LL(1)分析法1
自底向上分析法
LR分析法的概念 LR分析法的概念 LR(0)项目族的构造 LR(0)项目族的构造 SLR分析法 SLR分析法 LALR分析法 LALR分析法
概述
功能:根据文法规则 文法规则, 源程序单词符号串 单词符号串中 功能:根据文法规则,从源程序单词符号串中
识别出语法成分,并进行语法检查。 识别出语法成分,并进行语法检查。
9
【例】文法G[E] 文法G[E] E→ E +T | T 消除左递归 T→ T * F | F F→(E)|i 请用自顶向下的方法分析是否字 分析表 符串i+i*i∈L(G[E])。 符串i+i*i∈L(G[E])。
E→TE’ E’→+TE’|ε T →FT’ T’→*FT’|ε F→(E)|i
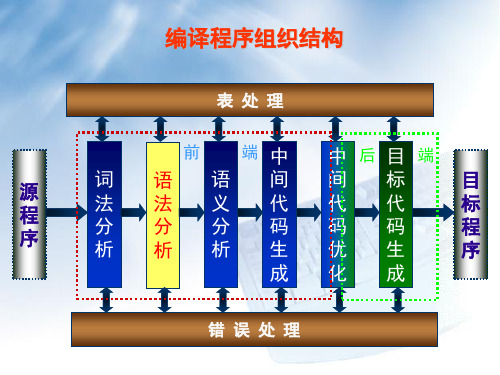
编译程序组织结构
表 处 理
前
端 中
源 程 序
词 法 分 析
语 法 分 析
语 义 分 析
间 代 码 生 成
中 后 目 端 间 标 代 代 码 码 优 生 化 成
目 标 程 序
错 误 处 理
第4章 语法分析
自顶向下分析法
递归子程序法(递归下降分析法) 递归子程序法(递归下降分析法) LL(1)分析法 LL(1)分析法
通常把按LL(1)方法完成语法分析任务的程序叫LL(1)分析程序或者LL(1)分析器。 通常把按LL(1)方法完成语法分析任务的程序叫LL(1)分析程序或者LL(1)分析器。 LL(1)方法完成语法分析任务的程序叫LL(1)分析程序或者LL(1)分析器
输入串
一、分析过程
#
此过程有三部分组成: 此过程有三部分组成: 分析表 总控程序) 执行程序 (总控程序) 分析栈) 符号栈 (分析栈)
编译原理语法分析报告+代码

编译原理语法分析报告+代码1000字一、语法分析语法分析是编译器的重要部分,它的作用是对源程序进行分析和判断,判断源程序是否符合语法规则,把源程序划分为一个个语法单元,并建立语法树,这里介绍一种常见的语法分析方法——LR(1)分析。
1.LR(1)分析LR(1)分析是一种自底向上的语法分析方法,它是以LR语法分析机为基础的。
LR(1)分析是在扫描整个输入的基础上作出决策的,名字中的1表示当扫描到一个符号时,它会读下一个符号来做决策并且仅仅读一个符号。
2.LR(1)分析器构建构建LR(1)分析器首先需要构建LR(1)自动机,然后对其进行分析,得到一个分析表。
分析表有两个函数:action和goto。
分析表的行是状态,列是终结符或非终结符,如果分析表的项中既包含action又包含goto,那么这个表就是一个LR(1)分析表。
3.核心算法核心算法就是通过分析表进行分析,具体步骤如下:(1)创建一个栈,将一个状态push入栈。
(2)循环扫描输入,每扫描一个符号就执行一个操作,直到栈为空。
(3)在栈的顶部状态上查找action表。
如果输入符号是一个终结符,那么应该执行的动作是shift。
如果输入符号是一个结束符号,那么说明输入已经结束,执行acc(accept)操作。
(4)如果找到了一个shift,就将其作为下一个状态push入栈,并将上次扫描到的符号作为标记push入栈。
(5)否则,在栈的顶部状态上查找goto表。
在状态表中查找新状态,并将其push入栈。
常见的错误处理:(1)在action表中找不到适当的输入:语法错误,报错。
(2)在goto表中找不到适当的输入:一个状态不能在当前符号的词法单元下产生任何变化。
4.算法实现这里提供一个简单的C++代码实现。
1)自动机的结构体声明:struct Automaton {int status; // 状态编号char symbol; // 符号int go_to; // 跳转状态int move_type; // 移动类型Automaton() : status(-1), symbol(0), go_to(-1),move_type(-1) {}};2)分析表结构体声明:struct AnalyzeTable {static const int ROWS = 100; // 分析表行数static const int COLS = 100; // 分析表列数Automaton analyze_table[ROWS][COLS]; // 分析表};3)LR(1)分析器的实现:class LR1Parser {public:LR1Parser(const std::string& grammar_file); // 构造函数~LR1Parser();void parse(const std::string& input_file); // 解析函数private:std::map<char, std::vector<std::string>> productions_; // 产生式std::map<char, std::set<char>> first_; // First集合std::map<char, std::set<char>> follow_; // Follow集合AnalyzeTable analyze_table_; // 分析表};4)分析表构建函数实现:void LR1Parser::build_analyze_table() {// 对于每个项A -> α.Bβ, a,把它添加到一个集合中。
编译原理 COMPILER_LR(1)文法

编译原理实验报告--LR(1)文法班级:小组人员:实验2.3 LR(1)分析法一.实验目的构造LR(1)分析程序,利用它进行语法分析,判断给出的符号串是否为该文法识别的句子。
二.实验平台Windows + VC + Win32 Console三.实验过程和指导1.范例程序文法S → BBB → aBB → b要求:(1)请输出完整的分析过程。
即详细输出每一步骤状态栈和符号栈的变化情况.(2)请输出最终的分析结果, 即输入串“合法”或“非法”步骤:(1)构造LR(1)项目集规范族I0S →·S I1Goto[I0,S] I2Goto[I0,B] S →·BB S →S· S →B·BB →·aB B →·aBB →·b B →·bI3Goto[I0,a] I4Goto[I0,b] I5Goto[I1,S]B →a·B B →b·S →BB·B →a·BB →·bI6Goto[I2,a] I7Goto[I2,b] I8Goto[I3,B]B →a·B B →b· B →aB·B →·aBB →·bI9Goto[I6,B]B →aB·(2)构造LR(1)分析表(3)程序代码:4-LR1.c1)输入符合文法的字符串abab#,结果显示如图:输入的字符串符合文法要求,结果为接受状态该文法分析步骤:第一步,符号栈#进栈,0进状态栈,Action表中0—#执行S3,所以3进符号栈,a进符号栈。
第二步,此时符号栈#a,状态栈03,Action表中3—b执行S4,所有4进符号栈,b进符号栈。
第三步,此时符号栈#ab,状态栈034,Action表中4—a执行r3,所以用第三个式B → b规约,Goto表中转向8状态。
第四步,此时符号栈是#aB,状态栈038,Action表中8—a执行r2,所以用第二个式B → aB规约,Goto表中转向2状态。
编译原理LR1(精选.)

姓名:刘玉华学号: 20101103846课题:LR(1)分析法指导教师:富玉柱LR(1)分析法1.LR(1)分析法定义LR分析法是一种有效的自底向上的语法分析技术,它能适用于大部分上下文无关文法的分析,一般叫LR(k)分析方法,其中L是指自左(Left)向右扫描输入单词串,R是指分析过程都是构造最右(Right)推导的逆过程(规范归约),括号中的k是指在决定当前分析动作时向前看的符号个数。
LR(1)项目可以看成两个部分组成,一部分和LR(0)项目相同,这部分成为心,另一部分为向前搜索符集合。
所以只有当面临的输入符属于向前搜索符的集合,才做规约动作,其他情况均出错。
LR(1)方法恰好解决SLR(1)方法在某些情况下存在的无效规约问题。
2. LR(1)分析法的主要思想(1)严格地进行最左归约(识别句柄并归约它)。
(2)将识别句柄的过程划分为由若干状态控制,每个状态控制识别出句柄的一个符号。
(3)分析栈:存放已识别的文法符号和状态,描述的是分析过程中的历史和展望信息。
(4)由一个总控程序来控制整个识别过程。
3. LR(1)分析法的构造方法(Aα→•β,a)的二元式称为LR(1)项目。
其中,Aβα→是文法的一个产生式,a 是终结符,称为搜索符。
文法的LR(1)项目集规范族指文法活前缀的有效的项目集。
(1)构造LR(1)项目集I的闭包函数CLOSURE(I)a)I的任何项目都属于CLOSURE(I);b)若项目(Aα→•Bβ,a)属于CLOSURE(I),Bγ→是一个产生式,则对于FIRST(βa)中的每个终结符b,如果(B→•γ,b)原来不在CLOSURE(I)中,则把它加进去;c)重复步骤b)直到CLOSURE(I)不再扩大为止。
(2)构造转换函数即GO函数令I是一个LR(1)项目集,X是一个文法符号,函数GO(I,X)定义为:GO(I,X)=CLOSURE(J),其中: J={(Aα→X•β,a)|(Aα→•Xβ,a)∈I}。
编译原理实验报告LR(1)分析法

河南工业大学实验报告课程编译原理实验名称实验四LR(1)分析法一.实验目的1.掌握LR(1)分析法的基本原理;2.掌握LR(1)分析表的构造方法;3.掌握LR(1)驱动程序的构造方法。
二.实验内容及要求根据某一文法编制调试LR(1)分析程序,以便对任意输入的符号串进行分析。
本次实验的目的主要是加深对LR(1)分析法的理解。
对下列文法,用LR(1)分析法对任意输入的符号串进行分析:(0)E->S(1)S->BB(2)B->aB(3)B->b程序输入一以#结束的符号串(包括a、b、#),如:abb#。
输出过程如下:步骤状态栈符号栈输入串ACTION GOTO1 0 # abb# S3... ... ... ... ... ...三.实验过程及结果(说明:实验结果可以是运行画面的抓屏,抓屏图片要尽可能的小。
)实验代码:#include<stdio.h>#include<string.h>char *action[10][3]={"S3#","S4#",NULL, /*ACTION表*/ NULL,NULL,"acc","S6#","S7#",NULL,"S3#","S4#",NULL,"r3#","r3#",NULL,NULL,NULL,"r1#","S6#","S7#",NULL,NULL,NULL,"r3#","r2#","r2#",NULL,NULL,NULL,"r2#"};int goto1[10][2]={1,2, /*GOTO表*/0,0,0,5,0,8,0,0,0,0,0,9,0,0,0,0,0,0};char vt[3]={'a','b','#'}; /*存放非终结符*/ char vn[2]={'S','B'}; /*存放终结符*/ char *LR[4]={"E->S#","S->BB#","B->aB#","B->b#"};/*存放产生式*/int a[10];char b[10],c[10],c1;int top1,top2,top3,top,m,n;void main(){int g,h,i,j,k,l,p,y,z,count;char x,copy[10],copy1[10];top1=0;top2=0;top3=0;top=0;a[0]=0;y=a[0];b[0]='#';count=0;z=0;printf("请输入表达式\n");/*输出状态栈、输出符号栈、输出输入串*/do{scanf("%c",&c1);c[top3]=c1;top3=top3+1;}while(c1!='#');printf("步骤\t状态栈\t\t符号栈\t\t输入串\t\tACTION\tGOTO\n"); do{y=z;m=0;n=0; /*y,z指向状态栈栈顶*/ g=top;j=0;k=0;x=c[top];count++;printf("%d\t",count);while(m<=top1){ /*输出状态栈*/printf("%d",a[m]);m=m+1;}printf("\t\t");while(n<=top2){ /*输出符号栈*/printf("%c",b[n]);n=n+1;}printf("\t\t");while(g<=top3){ /*输出输入串*/ printf("%c",c[g]);g=g+1;}printf("\t\t");while(x!=vt[j]&&j<=2) j++;if(j==2&&x!=vt[j]){printf("error\n");return;}if(action[y][j]==NULL){printf("error\n");return;}elsestrcpy(copy,action[y][j]);if(copy[0]=='S'){ /*处理移进*/ z=copy[1]-'0';top1=top1+1;top2=top2+1;a[top1]=z;b[top2]=x;i=0;while(copy[i]!='#'){printf("%c",copy[i]);i++;}printf("\n");}if(copy[0]=='r'){ /*处理归约*/ i=0;while(copy[i]!='#'){printf("%c",copy[i]);i++;}h=copy[1]-'0';strcpy(copy1,LR[h]);while(copy1[0]!=vn[k]) k++;l=strlen(LR[h])-4;top1=top1-l+1;top2=top2-l+1;y=a[top1-1];a[top1]=p;b[top2]=copy1[0];z=p;printf("\t");printf("%d\n",p);} }while(action[y][j]!="acc");printf("acc\n");getchar();}截屏如下:四.实验中的问题及心得同前面一样。
编译原理 第06章_LR分析法(3)

的。将同心集合并为: I5,12: L→i•, =/# I4,11: L→*•R, =/# R→•L, =/# I7,13: L→*R•, =/# L→•*R, =/# I8,10: R→L•, =/# L→•i, =/#
6.4 LALR(1)分析法
我们看到合并同心集后的项目集其核心 部分不变,仅搜索符合并。对合并同心集后 的项目集的转换函数为GO(I,X)自身的合并, 这是因为相同的心之转换函数仍属同心集, 例如: GO(I4,11, i)=GO(I4, i)∪GO(I11, i)= I5,12 GO(I4,11, R)=GO(I4, R)∪GO(I11, R)= I7,13 GO(I4,11, *)=GO(I4, *)∪GO(I11, *)= I4,11
0. S' →S 1. S →L=R
2. S →R 3. L →*R
4. L →i 5. R →L
6.4 LALR(1)分析法
3. 若LALR(1)项目集族中不存在归约一 归约冲突,则该文法是LALR(1)文法。对例 中的文法,由于合并同心集后不存在归约— 归约冲突,所以该文法是LALR(1)文法。
S'→•S,# I0: R→•L,# S→•L=R,# L I :R→L•,# L→• * R,# S→•R,# 10 L I2:S→L•=R,# L→•i,# L→•*R,=/# L R→L•,# * i L→•i,=/# i R I11: L→*•R,# R→•L,# I3: S→R•,# I12: L→i•,# R→•L,# * i L→• * R,# R L→ * •R,=/# I4: I13:L→*R•,# L→•i,# R→•L,=/# I5: L→i•,=/# L→•*R,=/# R * i I7: L→*R•,=/# L→•i,=/#
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
姓名:刘玉华学号: 20101103846
课题:LR(1)分析法指导教师:富玉柱
LR(1)分析法
1.LR(1)分析法定义
LR分析法是一种有效的自底向上的语法分析技术,它能适用于大部分上下文无关文法的分析,一般叫LR(k)分析方法,其中L是指自左(Left)向右扫描输入单词串,R是指分析过程都是构造最右(Right)推导的逆过程(规范归约),括号中的k是指在决定当前分析动作时向前看的符号个数。
LR(1)项目可以看成两个部分组成,一部分和LR(0)项目相同,这部分成为心,另一部分为向前搜索符集合。
所以只有当面临的输入符属于向前搜索符的集合,才做规约动作,其他情况均出错。
LR(1)方法恰好解决SLR(1)方法在某些情况下存在的无效规约问题。
2. LR(1)分析法的主要思想
(1)严格地进行最左归约(识别句柄并归约它)。
(2)将识别句柄的过程划分为由若干状态控制,每个状态控制识别出句柄的一个符号。
(3)分析栈:存放已识别的文法符号和状态,描述的是分析过程中的历史和展望信息。
(4)由一个总控程序来控制整个识别过程。
3. LR(1)分析法的构造方法
(A a®•b,a)的二元式称为LR(1)项目。
其中,A ba®是文法的一个产生式,a 是终结符,称为搜索符。
文法的LR(1)项目集规范族指文法活前缀的有效的项目集。
(1)构造LR(1)项目集I的闭包函数CLOSURE(I)
a)I的任何项目都属于CLOSURE(I);
b)若项目(A a®•Bb,a)属于CLOSURE(I),B g®是一个产生式,则对于FIRST(ba)
中的每个终结符b,如果(B®•g,b)原来不在CLOSURE(I)中,则把它加进去;
c)重复步骤b)直到CLOSURE(I)不再扩大为止。
(2)构造转换函数即GO函数
令I是一个LR(1)项目集,X是一个文法符号,函数GO(I,X)定义为:GO(I,X)=CLOSURE(J),其中: J={(A a®X•b,a)|(A a®•Xb,a)ÎI}。
注:在执行转换函数GO时,搜索符并不改变。
(3)构造拓广文法G`的LR(1)项目集族C的算法
{C={CLOSURE({(S` ®•S,#)})};
DO{FOR C中的每个项目集I和每个文法符号X
IF GO(I,X)非空且不属于C
把GO(I,X)加入C中;
}WHILE C依然扩大;
}
4. LR(1)分析表的构造
假定LR(1)项目集规范族C={I0, I1,……,In},令每个项目集Ik的下标k 为分析器的一个状态,G’的LR(1)分析表含有状态0,1,……,n。
1.令那个含有项目[S’→.S ,#]的Ik的下标k为状态0(初态).ACTION 表和GOTO表可按如下方法构造。
2.若项目[A→α.,b]属于Ik, 那么置ACTION[k, b]为“用产生式A→α进行规约”,简记为“rj”;(假定A→α为文法G’的第j个产生式)。
3.若项目[A→α.aβ,b]属于Ik且GO (Ik, a)= Ij,则置ACTION[k, a]为“把状态j和符号a移进栈”,简记为“sj”。
4.若项目[S’→S.,#]属于Ik, 则置ACTION[k, #]为“接受”,简记为“acc”。
5.若GO (Ik, A)= Ij, A为非终结符,则置GOTO(k, A)=j;分析表中凡不能用规则1至5填入信息的空白格均置上“出错标志”。
按上述算法构造的含有ACTION和GOTO两部分的分析表,如果每个入口
不含多重定义,则称它为文法G的一张规范的LR(1)分析表。
具有规范的LR(1)表的文法G称为一个LR(1)文法。
5. LR(1)分析法的利弊
LR(1)的规约项目不存在任何无效规约,但在多数情况下同一个文法的LR(1)项目集的个数比LR(0)项目集的个数多。
这是因为对同一个LR(0)项目集,由于搜索符不同而对应着多个LR(1)项目集。
LR(1)分析法虽然可以解决SRLR(1)方法所难以解决的“移进-归约”或“归约-归约”冲突,但是对同一个文法而言,但搜索符不同时,是的同一个项目集被分裂成多个项目集从而引起状态数的剧烈增长,导致了时间和内存空间的急剧上升,它的应用也相应地受到了一定的限制。
为了克服LR(1)分析法的这种缺点,可以采用LALR(1)分析法。
LR分析法(适用范围广;分析速度快;报错准确)。
LR(1)分析法比递归下降分析法、预测分析法和算符优先分析法对文法的限制要少得多。
对于大多数用无二义性上下文无关文法描述的语言都可以用LR分析法进行有效的分析,而且这种分析法分析速度快,并能准确及时地指出输入串的语法错误和出错的位置。
但是,这种分析法有一个主要缺点,那就是对于一个语言的文法,构造LR分析器的工作量相当大,具体实现较困难。
SLR(1)的状态数少,LR(1)的适用范围广,但LR(1)分析表含有较多的状态数,占用存储太大,影响了实践使用。
1.LR(1)比SLR(1)能力强
例: (0)S`→S
(1)S→L=R
(2)S→R
(3)L→*R
(4)L→i
(5)R→L
不能用SLR(1)技术解决,但能用LR(1)。
2.LR(1)项目集不存在动作冲突,合并同心集后会不会产生新的冲突(移进-归约,归约-归约)
例:S' –> S
S –> aBc | bCc | aCd | bBd
B –> e
C –> e
3.如果栈里的符号串为$da,归约后编程$dA,当前读到的输入符号是a,若文法中不存在以$da为前缀的规范句型,那么,这种归约无效。
例:规范句型i=i的SLR(1)分析过程
状态栈符号栈输入串
0 $ i=i$
05 $i =i$
02 $L =i$
03 $R =i$
4.一个SLR文法的规范LR分析表比其SLR分析表含有更多的状态。
在严重的情况下,状态数可能成几倍增长,因此需要简化。
例:有如下文法:
1. Z ®S
2. S ®L=R
3. S ®R
4. L ®aR
5. L ®b
6. R ®L
按照求LR(1)项目集规范族的算法,求G(S)文法的项目集族解:求初态项目集I0:从(Z ®•S,#)项目开始求闭包得:
接着利用GO函数,对该项目集内得各项目求后继项目集,然后再对新求的项目集重复上面的过程,直到项目集不再增加为止。
最后的LR(1)图为:
I0初态
Z→•S,# S→•L=R, #
S→•R,# L→•aR,= L →•b,= R→•L,# L→•aR,#
I0初态
Z→•S,#
S→•L=R,#
S→•R,#
L→•aR,=|#
L →•b,=|# 简化为。