3. 计算机是如何处理汉字的?
汉字显示原理

汉字显示原理
汉字显示原理是指在计算机中如何将汉字以可读的方式显示出来。
计算机是一种二进制系统,所以它最初并不支持直接显示汉字。
为了解决这个问题,人们发明了汉字编码,将每个汉字与一个唯一的数字对应起来。
最早的汉字编码方式是GB2312,它使用两个字节来表示一个
汉字。
后来随着汉字数量的增加,GB2312已经无法满足需求,于是发展出了GB18030和UTF-8等新的编码方式。
UTF-8成
为最为广泛使用的汉字编码方式,它使用变长字节表示一个字符,可以灵活地处理各种不同语言的字符。
在计算机中,文本文件通常以字节流的形式存储,每个字符对应着一系列的字节。
当显示汉字时,计算机会根据编码方式将对应的字节转换成可识别的字符,然后通过显示设备显示出来。
在显示设备上,汉字的显示原理依赖于字体文件。
字体文件中包含了每个汉字的图形信息,计算机根据字体文件中的信息渲染出每个汉字的像素点,再通过显示设备将其显示出来。
不同的字体文件可能会有不同的字形设计和排版效果,所以同一个汉字在不同的字体下可能会有略微的差异。
总之,汉字的显示原理主要涉及汉字编码和字体文件的使用,通过这两个步骤计算机可以将汉字以可读的方式显示出来。
917482-大学计算机基础-资料4-3汉字编码

汉字编码Hanzi bianma汉字编码Chinese character encoding为汉字设计的一种便于输入计算机的代码。
由于电子计算机现有的输入键盘与英文打字机键盘完全兼容。
因而如何输入非拉丁字母的文字(包括汉字)便成了多年来人们研究的课题。
汉字信息处理系统一般包括编码、输入、存储、编辑、输出和传输。
编码是关键。
不解决这个问题,汉字就不能进入计算机。
汉字进入计算机的三种途径分别为:①机器自动识别汉字:计算机通过“视觉”装置(光学字符阅读器或其他),用光电扫描等方法识别汉字。
②通过语音识别输入:计算机利用人们给它配备的“听觉器官”,自动辨别汉语语音要素,从不同的音节中找出不同的汉字,或从相同音节中判断出不同汉字。
③通过汉字编码输入:根据一定的编码方法,由人借助输入设备将汉字输入计算机。
机器自动识别汉字和汉语语音识别,国内外都在研究,虽然取得了不少进展,但由于难度大,预计还要经过相当一段时间才能得到解决。
在现阶段,比较现实的就是通过汉字编码方法使汉字进入计算机。
1.分类计算机中汉字的表示也是用二进制编码,同样是人为编码的。
根据应用目的的不同,汉字编码分为外码、交换码、机内码和字形码。
(1)外码(输入码)外码也叫输入码,是用来将汉字输入到计算机中的一组键盘符号。
常用的输入码有拼音码、五笔字型码、自然码、表形码、认知码、区位码和电报码等,一种好的编码应有编码规则简单、易学好记、操作方便、重码率低、输入速度快等优点,每个人可根据自己的需要进行选择。
(2)交换码(国标码)计算机内部处理的信息,都是用二进制代码表示的,汉字也不例外。
而二进制代码使用起来是不方便的,于是需要采用信息交换码。
中国标准总局1981年制定了中华人民共和国国家标准GB2312--80《信息交换用汉字编码字符集--基本集》,即国标码。
区位码是国标码的另一种表现形式,把国标GB2312--80中的汉字、图形符号组成一个94×94的方阵,分为94个“区”,每区包含94个“位”,其中“区”的序号由01至94,“位”的序号也是从01至94。
将汉字转换成二维数组的程序

将汉字转换成二维数组的程序1.引言1.1 概述概述部分的内容可以如下所述:概述部分将为读者提供一个有关本篇长文的简要介绍。
在本文中,我们将讨论如何编写一个程序,用于将汉字转换成二维数组。
汉字是中文的基本单位,但是在计算机编程中,处理汉字可以是一项具有挑战性的任务。
通过将汉字转换成二维数组,我们可以更方便地对其进行处理和操作。
本文将首先介绍汉字转换成二维数组的需求。
汉字是由笔画组成的字符,而我们需要将其转换成数字形式,以便进行后续处理。
接着,我们将探讨实现汉字转换成二维数组的方法。
这包括了解如何将汉字字符转换成相应的数字表示,并将其存储在二维数组中的合适位置。
通过本文的阅读,读者将能够全面了解汉字转换成二维数组的过程和原理,并掌握相关的编程技巧。
本文所提供的方法可以在各种应用场景中使用,例如汉字图像处理、文本分析和机器学习等领域。
值得注意的是,本文将以简单明了的方式进行讲解,并提供示例代码以帮助读者更好地理解和应用所学知识。
在下一节中,我们将详细介绍汉字转换成二维数组的需求,以及如何实现这一转换的方法。
让我们开始吧!1.2文章结构文章结构部分的内容:文章结构是指文章的整体组织架构和分章节的安排。
本文的结构分为引言、正文和结论三个部分。
引言部分介绍了本文要讨论的主题——将汉字转换成二维数组的程序。
引言部分包括概述、文章结构和目的三个方面。
在概述部分,将简要介绍汉字转换成二维数组的背景和相关应用。
可以提到随着科技的发展,人们对文字信息的处理需求日益增加,同时也对文字的表现方式提出了更高的要求。
将汉字转换成二维数组的程序可以满足这一需求,为后续的文字处理提供了基础。
文章结构部分将具体说明本文的章节安排和内容分布。
本文包括引言、正文和结论三部分。
其中,引言部分介绍了本文的主题和目的,正文部分主要分为两个小节,分别阐述了汉字转换成二维数组的需求和实现方法,结论部分对整篇文章进行总结并展望未来的研究方向。
目的部分说明了本文的写作目的和意义。
四年级上册信息技术教案-2汉字在电脑中原来是这样表示的|闽教版(2016)

2 汉字在电脑中原来是这样表示的学习目标1、了解汉字输入电脑的途径,体验不同输入法的特点。
2、体验汉字的点阵表示。
3、初步了解汉字的编码规律。
重点、难点或关键教学重点:了解电脑如何处理汉字,体验不同输入法的特点教学难点:汉字编码方法及汉字的点阵表示。
教学具准备教学环境:计算机网络教室、互联网环境、转播控制系统教学资源:汉字点阵图手写板、扫描仪等图片教学流程一、创设情境,导入新课同学们,你们喜欢看《名侦探柯南》吗?今天,柯南的叔叔毛利小五郎接到一个电话,在一个公园里发现一名死者,死者周围只有一张纸条。
经过重重排查,找到三位嫌疑人,分别是井田先生、三木先生、美一小姐。
柯南苦苦研究那张纸条,还是无法确定谁是凶手,所以,他将那张写满“0”、“1”的阿拉伯数字的纸条带来了,希望大家能帮他破解这个死亡密码,孩子们,你们愿意帮他吗?不过,要想帮助柯南破解这个死亡密码,同学们还需掌握三个关键知识哦!二、电脑处理汉字的过程知识一:人和电脑是怎样交流的?1、引导学生思考我们人和人是怎样交流的。
2、总结:(l)电脑只能识别“0 ”和“l ”两种数字符号,但输入到电脑的数据是由字母、数字、标点符号及各种专用符号等组成的、为了便于这些数据的表示、交换、处理和存储,须对数据进行编码,则有了输入码、存储码和输出码。
(2) 人与人之间的交流,主要以语言、文字为工具,才能使交流得以顺畅进行,而人机会话,要通过计算机指令。
首先要通过输入设备,将这些指令等数据输入到电脑中,其次对这些数据按一定的规律进行处理,并将处理结果存储在电脑中,最后经过电脑的输出设备、显示出来处理结果,让人们阅读。
这样,人与电脑就能顺利进行交流。
同样,电脑处理汉字,也要经过这三个环节,即输入、存储和输出。
3、课件显示课题:第 2 课汉字在电脑中原来是这样表示的三、了解汉字输入电脑的途径知识二:汉字输入电脑有哪些方法?1、提出问题:汉字输入电脑的途径有哪些?2、引导学生回答问题并予以适当补充。
计算机中的字是如何处理的
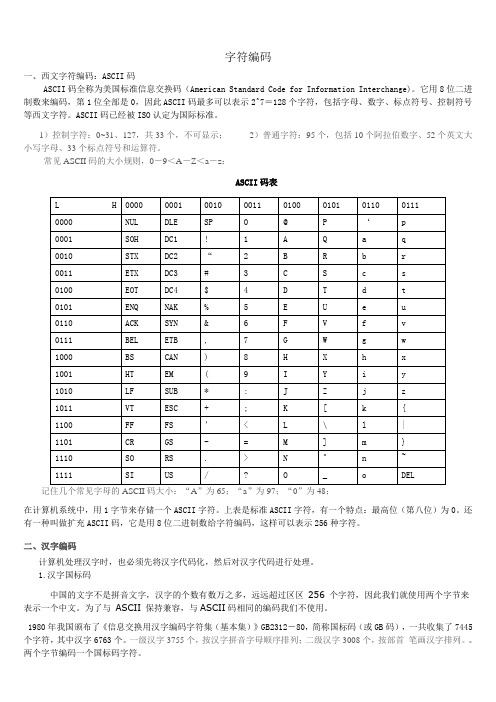
字符编码一、西文字符编码:ASCII码ASCII码全称为美国标准信息交换码(American Standard Code for Information Interchange)。
它用8位二进制数来编码,第1位全部是0,因此ASCII码最多可以表示2^7=128个字符,包括字母、数字、标点符号、控制符号等西文字符。
ASCII码已经被ISO认定为国际标准。
1)控制字符:0~31、127,共33个,不可显示;2)普通字符:95个,包括10个阿拉伯数字、52个英文大小写字母、33个标点符号和运算符。
常见ASCII码的大小规则,0-9<A-Z<a-z:ASCII码表记住几个常见字母的ASCII码大小:“A”为65;“a”为97;“0”为48;在计算机系统中,用1字节来存储一个ASCII字符。
上表是标准ASCII字符,有一个特点:最高位(第八位)为0。
还有一种叫做扩充ASCII码,它是用8位二进制数给字符编码,这样可以表示256种字符。
二、汉字编码计算机处理汉字时,也必须先将汉字代码化,然后对汉字代码进行处理。
1.汉字国标码中国的文字不是拼音文字,汉字的个数有数万之多,远远超过区区256 个字符,因此我们就使用两个字节来表示一个中文。
为了与ASCII 保持兼容,与ASCII码相同的编码我们不使用。
1980年我国颁布了《信息交换用汉字编码字符集(基本集)》GB2312-80,简称国标码(或GB码),一共收集了7445个字符,其中汉字6763个。
一级汉字3755个,按汉字拼音字母顺序排列;二级汉字3008个,按部首笔画汉字排列。
两个字节编码一个国标码字符。
2.汉字的机内表示:机内码:计算机在信息处理时表示汉字的编码,称作机内码。
现在我国都用国标码(GB2312)作为机内码。
中国的台湾省也在使用中文,但是由于历史的原因,那里没有使用大陆的简体中文,还在使用着繁体的中文,并且他们自己也制定了一套表示繁体中文的字符编码,称为BIG5,不幸的是,虽然他们的也使用两个字节来表示一个汉字,但他们没有象我们兼容ASCII 一样兼容大陆的简体中文,他们使用了大致相同的编码范围来表示繁体的汉字。
计算机系统结构答案

一、选择题1、对汇编语言程序员,下列(A )不是透明的。
A: 中断字寄存器 B: 乘法器 C: 移位器 D: 指令缓冲器2、假设对A机器指令系统的每条指令的解释执行可直接由B机器的一段微程序解释执行,则A称为(D )。
A: 仿真机 B: 宿主机 C: 虚拟机 D: 目标机3、 1. 查看下面三条指令:V3←A;V2←V0+V1;V4←V2*V3;假设向量长度小于64,且前后其他的指令均没有相关性,数据进入和流出每个功能部件,包括访问存储器都需要一拍的时间,假设向量的长度为N。
三条指令全部采用串行的方法,那么执行的时间是:A: 3N+20 B: 3N+21 C: 3N+22 D: 3N+234、某向量处理机有16个向量寄存器,其中V0-V5种分别存放有向量A,B,C,D,E,F,向量的长度是8,向量各元素均为浮点数;处理部件采用两个单功能流水线,加法功能部件时间为2拍,乘法功能部件时间为3拍。
采用类似CRAY-1的链接技术,先计算(A+B)*C,在流水线不停的情况下,接着计算(D+E)*F。
求此链接流水线的通过时间是多少拍?(设寄存器出入各需1拍)A: 8 B: 9 C: 17 D: 185、设有一个4个处理器的MIMD系统,假设在系统中访存取指和取数的时间可以忽略不计;加法与乘法分别需要2拍和4拍;在MIMD系统中处理器(机)之间每进行一次数据传送的时间为1拍;在MIMD系统中,每个PE都可以和其它PE有直接的的通路。
求利用此系统计算表达式所需的节拍数。
A: 23 B: 12 C: 11 D: 106、以下哪些是周期窃取方式的特点?A : 硬件结构简单B : 硬件结构复杂C : 数据输入或输出过程中占用了CPU时间D : 数据输入或输出过程中不占用CPU时间7、从下列有关Cache的描述中,选出应填入空格中的正确答案:(1)今有甲、乙两台计算机,甲计算机的Cache存取时间为50ns,主存储器为2us;乙计算机的Cache存储时间为100ns,主存储器为1.2us。
大学计算机基础重点笔记
1. 现代计算机发展历程:① 第一代电子管计算机(1946 EMIAC ,标志着现代计算机的诞生), ② 第二代晶体管计算机, ③ 第三代集成电路计算机,④ 第四代(超)大规模集成电路计算机(1981年IBM 推出PC )2. 计算机系统:包括硬件和软件两个部分。
硬件:运算器、控制器、存储器、输入设备、输出设备。
(或:CPU 、存储器、I/O 设备)软件3. 存储器:包括主存(内存)和辅存(外存)两种。
内存:①特点:相对快、小、带电储存(易失性)②举例:CPU 内存元件、内存条、高速缓存外存:①特点:相对慢、大、不带电储存②举例:硬盘、光盘、MP3(4,5)、U 盘、磁盘等4. ROM (只读存储器)与 RAM (可读写存储器)5. ( 1)键盘键区分布(2) 正确的打字方法 (3) 一些键的描述:例如:组合键 Ctrl ,Alt ; 上档键 Shift ; 奇偶键 Num Lock ,Caps Lock, Insert (插入/替换)6. 显示器7. 打印机击打式打印机 例如:点阵式,高速宽行 非击打式打印机例如:喷墨,激光8. 总线:各种公共信号线的集合。
AB :地址总线一传递地址功能DB :控制总线一传送控制信号和时序信号 CB :数据总线一传递数据信息 9. 软件系统(1) 系统软件:OS (操作系统),DVMS (数据库管理系统) (2) 应用软件10. 计算机病毒(1) 计算机病毒的特点(性征):破坏性、传染性、潜伏性、隐蔽性(2) 计算机病毒的分类: 根据其对计算机和用户使用的危害 /干扰程度分为良性病毒、恶系统 总 线RAM ROM I/O 接口外设C P U性病毒两种。
11.计算机的数字和单位(1) 计算机中,"0"或"1"代表的含义为相反的两个方面,比较简单。
它们各自占据一比 特(Bit )的空间。
(2)1字节(Byte )中包含8个比特(Bits )。
【实训】谈一谈你所理解的汉字信息在计算机里的存储与表达的过程与原理,并同英文的处理做比较。
一、汉字信息在计算机中的处理与存储计算机对每一个字符进行编码形成其对应的唯一一个内码就是汉字的存储,然而同一个字符(例如“中”字)不同编码对应的内码不一样。
计算机中汉字编码一般采用两个高位( 左边第一位)为1 的ASCⅡ码表示一个汉字,即用两个字节表示一个汉字。
汉字在计算机内的编码很复杂,涉及汉字的各种代码,如汉字输入码,汉字机内码,汉字交换码,汉字字形码等。
1、汉字输入码汉字输入码也叫外码,是为了通过键盘字符把汉字输入计算机而设计的一种编码。
汉字的输入码种类繁多,大致有4种类型,即音码、形码、数字码和音形码。
2、汉字机内码汉字机内码又称内码或汉字存储码。
该编码的作用是统一了各种不同的汉字输入码在计算机内的表示。
汉字机内码是计算机内部存储、处理的代码。
3、汉字交换码汉字交换码主要是用作汉字信息交换的。
4、汉字字形码汉字字形码是指确定一个汉字字形点阵的代码(汉字字形码)。
一般采用点阵字形表示字符.普遍使用的汉字字型码是用点阵方式表示的 称为“点阵字模码”。
所谓“点阵字模码” 就是将汉字像图像一样置于网状方格上 每格是存储器中的一个位 16×16点阵是在纵向16点、横向16点的网状方格上写一个汉字 有笔画的格对应1 无笔画的格对应0。
这种用点阵形式存储的汉字字型信息的集合称为汉字字模库 简称汉字字库。
通常汉字显示使用16×16点阵 而汉字打印可选用24×24点阵、32×32点阵、64×64点阵等。
汉字字形点阵中的每个点对应一个二进制位 1字节又等于8个二进制位 所以16×16点阵字形的字要使用32个字节 16×16÷8字节 32字节 存储 64×64点阵的字形要使用512个字节。
在16×16点阵字库中的每一个汉字以32个字节存放 存储一、二级汉字及符号共8836个 需要282.5KB磁盘空间。
而用户的文档假定有10万个汉字 却只需要200KB的磁盘空间 这是因为用户文档中存储的只是每个汉字 符号 在汉字库中的地址 内码 。
计算机一级考试《MSOffice》知识考点
计算机一级考试《MSOffice》知识考点计算机一级考试《MS Office》知识考点计算机一级考试主要考核微型计算机基础知识和使用办公软件及因特网(Internet)的基本技能。
下面店铺为大家搜索整理了关于《MS Office》知识考点,欢迎参考练习,希望对大家有所帮助!想了解更多相关信息请持续关注我们店铺!1、选择题部分(20分)1.世界上第一台计算机ENIAC是1946年在美国诞生的,主要元件是电子管,主要设计思想是科学家“冯•诺依曼”的二进制和存储程序理论。
计算机根据所采用的电子元件不同,可分为电子管、晶体管、集成电路和大规模超大规模集成电路四个时代。
现代计算机最主要的发展趋势是微型化和巨型化,其他趋势还有网络化、智能化。
2.计算机根据处理数据的类型分为数字计算机、模拟计算机、数字模拟计算机;根据适用范围分为通用计算机和专用计算机;根据性能和规模分为巨型、大型、微型计算机、工作站和服务器。
3.微型计算机(PC)1971年诞生,通常以微处理器(CPU)来划分,可分为8086、286、386、486,PI、PII、PIII、P4等8个阶段,其中286是16位机,其他均为32位机。
4.最新技术:人工智能(让计算机完成人才能做的工作);网格计算(利用互联网把不同地方的计算机组成一个虚拟网络);中间件(介于应用软件和操作系统之间的系统软件);云计算(对基于网络的、可配置的共享计算资源按需访问的一种模式)。
5.计算机辅助设计CAD、计算机辅助制造CAM、计算机辅助教学CAI。
6.进制计算步骤:开始菜单,程序,附件,计算器,查看菜单,程序员。
7.ASCII码(美国标准信息码)是最常用的计算机字符编码,码长7位,编码范围从0000000B到1111111B可以表示128个不同的编码值。
8.ASCII码中,各种码值大小关系为:符号<数字<大写字母<小写字母;几个特殊的码值大小:0(48)、A(65)、a(97),遇到大写字母组成的单词默认为符号类型。
汉字的机内码是指在计算机中表示一个汉字的编码
汉字的机内码是指在计算机中表示一个汉字的编码。
机内码与区位码稍有区别。
汉字区位码的区码和位码的取值均在1~94之间,如直接用区位码作为机内码,就会与基本ASCII码混淆。
为了避免机内码与基本ASCII码的冲突,需要避开基本ASCII码中的控制码(00H~1FH),还需与基本ASCII码中的字符相区别。
为了实现这两点,可以先在区码和位码分别加上20H,在此基础上再加80H(此处“H”表示前两位数字为十六进制数)。
经过这些处理,用机内码表示一个汉字需要占两个字节,分别称为高位字节和低位字节,这两位字节的机内码按如下规则表示:高位字节=区码+20H+80H(或区码+A0H)低位字节=位码+20H+80H(或位码+AOH)由于汉字的区码与位码的取值范围的十六进制数均为01H~5EH(即十进制的01~94),所以汉字的高位字节与低位字节的取值范围则为A1H~FEH(即十进制的161~254)。
例如,汉字“啊”的区位码为1601,区码和位码分别用十六进制表示即为1001H,它的机内码的高位字节为B0H,低位字节为A1H,机内码就是B0A1H。
2603 = 1A03H 区位码+ A0A0H= BAA3H 机内码[本帖最后由 rossini23 于 2006-10-11 13:28 编辑]计算机处理汉字信息的前提条件是对每个汉字进行编码,这些编码统称为汉字编码。
汉字信息在系统内传送的过程就是汉字编码转换的过程。
汉字交换码:汉字信息处理系统之间或通信系统之间传输信息时,对每一个汉字所规定的统一编码,我国已指定汉字交换码的国家标准“信息交换用汉字编码字符集——基本集”,代号为GB 2312—80,又称为“国标码”。
国标码:所有汉字编码都应该遵循这一标准,汉字机内码的编码、汉字字库的设计、汉字输入码的转换、输出设备的汉字地址码等,都以此标准为基础。
GB 2312—80就是国标码。
该码规定:一个汉字用两个字节表示,每个字节只有7位,与ASCII码相似。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
其他方式的字符编码(略)
CJK统一汉字编码字符集 BIG5 GBK GB 18030/2000 ANSI Unicode
23
Unicode (略)
由统一编码组织于 20世纪90年代初制 定的一种16位字符编码标准 双字节码 理论编码空间65536个 39000个字符编码已经做出了规定 其中21000个编码用于表示汉字 Unicode编码中尚未定义的编码留待以 后使用
1980年,我国国家标准总局颁布了 《信息交换用汉字编码字符集——基 本集》(GB2312-80) 又称汉字交换码(汉字系统之间或与 通信系统之间进行信息传输时,对每 个汉字所规定的统一编码)的国家标 准,因此又称“国标码”
5
国标码(2)
国标码是一种双字节码 即表示一个汉字的编码由两个字节组 成
6
在FONTS目录下 扩展名为FON,图标为红色的“A”——点阵字 库 扩展名为TTF,图标是两个“T”——矢量字库46
补充——如何造生僻字?
参考实验02文档
47
计算机汉字处理总结
(1)通过某种汉字输入法,由输入设备输入 汉字的外码(汉字输入码); (2)由汉字输入系统将汉字外码转换为内码 并存储、处理; (3)如果要进行汉字通信,将内码转换为汉 字交换码实现不同汉字系统之间的传输; (4)将汉字内码转换为相应汉字字形码; (5)通过输出设备把汉字字形码输出为汉字。
无重码
缺点
最难记
典型编码:区位码
33
区位码(1)
国标码是以十六进制的形式来表示,共有两 个字节,高低字节的取值范围都是从21H到 7EH,共94种取值 用十进制的从1到94来表示这94种状态,就 形成了区位码。 区位码共四位十进制数字,前两位数字对应 国标码的高字节,取值为1~94,我们称之为 “区号(区码)”;后两位数字对应国标码 的低字节,取值为1~94,我们称之为“位号 (位码)”
34
区位码(2)
区位码与国标码是一种一一对应关系 注意
区位码的区号和位号都是两位的,即便实 际上一位数,也要写成两位数(一位数前 面补“0”) 例如,如果某个汉字的位号是3,我们在 书写时,也要写成“03”
35
区位码与国标码之间转换关系
区位码
1 94 = = 01H 5EH
国标码
21H对应区码或位码的1,即01H 7EH对应区码或位码的94,即5EH
GB18030的全称是GB18030-2000《信息 交换用汉字编码字符集基本集的扩 充》,是我国政府于2000年3月17日发 布的新的汉字编码国家标准 共收录27484个汉字,技术上是GBK的 超集,并与其兼容,最终将结束GBK历 史使命
19
GB 18030/2000 (略)
编码方法: GB 18030标准采用单字节、双字节和 四字节三种方式对字符编码。
24
Unicode如何在网络上传输 (略)
UTF
Unicode transformation format
根据最小编码单位不同分为
1字节——UTF8 2字节——UTF16 4字节——UTF32
25
Unicode如何在网络上传输略)
给定一个字节流,如何判断是那种编码
1. 各种UTF编码之间如何区分?
16
GBK (略)
汉字扩充内码规范 一共收录了20902个汉字
GB2312-80的6763个常用汉字 中国台湾BIG5码(繁体中文)13000多个 汉字。
17
其他方式的字符编码(略)
CJK统一汉字编码字符集 BIG5 GBK GB 18030/2000 ANSI Unicode
18
GB 18030/2000 (略)
44
点阵字库的最大缺点
不能放大,一旦放大后就会发现文字 边缘的锯齿(失真) 解决方法:
矢量字库
45
矢量字库
矢量字库保存的是对每一个汉字的描述信 息,比如一个笔划的起始、终止坐标,半 径、弧度等等。 在显示、打印这一类字库时
经过一系列的数学运算 可以被无限地放大
Windows使用的字库也为以上两类
键盘输入方式 非键盘输入方式
28
键盘输入方式
音码 形码 音形码(形音码) 顺序码(流水码)
29
音码
按汉语拼音方案对汉字进行编码。 优点
简单易学
缺点
重码较多 输入速度较慢
典型编码:全拼、双拼等
30
形码
将汉字分解为一些笔画、部首或字根 进行编码,再由笔画、部首或字根组 成单个汉字 优点
重码率低 输入速度较快
总结:
1、区位码<国标码<机内码 2、国标码的高位、低位=区位码的高 位、低位各加32 (10) 3、机内码的高位、低位=国标码的高 位、低位各加128 (10)
39
非键盘输入方式
笔 语音 扫描 „„
40
汉字字形码(1)
汉字在屏幕上显示或在打印机上输出时, 为了能被人们理解和接受,必须以汉字 字形输出,这种编码称为汉字字形码。 汉字字形一般是以点阵方式表示汉字的
把两个字节国标码(二进制)的最高 位置“1”,即可得到该汉字的“机内 码” 机内码是用来存储和处理汉字时用到 的编码
8
机内码与国标码之间的关系
假设国标码的两个字节分别是G1,G2; 机内码的两个字节分别是J1,J2 ① 国标码——机内码 J1=G1+80H J2=G2+80H ② 机内码——国标码 G1=J1-80H G2=J2-80H 为什么这样转换?
中国传媒大学计算机与网络中心
3. 计算机是如何处理汉字的
1
其它系统的汉字编码
汉字 信息
输 入
交换码 (国标码)
汉字 信息
显 示 打 印
外码 (输入码) 信息
机内码
计算机内部
字形码
2
汉字编码
“汉字的表示”问题
机外表示 机内表示
3
几种常用的汉字编码
国标码 机内码 汉字输入码(外码) 汉字字形码
4
国标码(1)
48
其它系统的汉字编码
汉字 信息
输 入
交换码 (国标码)
汉字 信息
显 示 打 印
外码 (输入码) 信息
机内码
字形码
49
9
机内码与国标码之间的转换
已知“啊”的国标码是3021H,求它的 机内码。 1、将国标码分成两个字节G1和G2 G1=30H G2=21H 2、代入公式,求出机内码的两个字节J1 和J2 J1=G1+80H=30H+80H=B0H J2=G2+80H=21H+80H=A1H 3、排列J1和J2,写出机内码 机内码=J1J2=B0A1H
20
其他方式的字符编码(略)
CJK统一汉字编码字符集 BIG5 GBK GB 18030/2000 ANSI Unicode
21
ANSI编码方式(略)
ASCII字符集定义了128个字符,扩展后的 ASCII字符集定义了256个字符,后来每个 国家定义了自己的MBCS(多字节字符系统), 被统称为ANSI字符集。 ANSI编码方式与操作系统默认的编码方式 一致。 中文Windows记事本的ANSI编码方式实际上 采用的GBK编码(代码页936),英文Windows 记事本的ANSI编码方式实际上采用的Latin 1(代码页1252)编码。
41
汉字字形码(2)
用点阵方式表示汉字,即每个汉字分解 成若干点,一个点对应一位(bit)。 点阵中的每个点可以有明、暗两种状态, 如果该处有笔划,则为亮,否则为暗
42
行序为主序 16×16 32字节 第一行
F800
第二行
8BFE
以列为主序? 还有其他规 模的字形
43
汉字点阵占存储空间计算
在100个汉字存储在32 ×32 的点阵中, 所需的存储空间是多少KB? 解:32*32/8=128 Byte 128*100/1024=12.5KB
网上传递信息时有一个很重要的问题
对于数据高低位的解读方式
little-endian
低位先发送的方法 Intel架构
big-endian
高位先发送的方式
如何判断是LE还是BE?
在文本流的开始时向对方发送一个标志符
27
汉字输入码(外码)
为了将汉字输入计算机而编制的代码, 又称为外码 该码直接与汉字输入法相关,即每种 汉字输入法对应一种外码,因此,通 常情况下一个汉字的外码不唯一 分类
13
其他方式的字符编码(略)
CJK统一汉字编码字符集 BIG5 GBK GB 18030/2000 ANSI Unicode
14
BIG5 (略)
BIG5是中国台湾计算机界实行的汉字 编码字符集 包含了 420 个图形符号和 13070 个 汉字(不包含简化汉字)。
15
其他方式的字符编码(略)
CJK统一汉字编码字符集 BIG5 GBK GB 18030/2000 ANSI Unicode
10
其他方式的字符编码(略)
CJK统一汉字编码字符集 BIG5 GBK GB 18030/2000 ANSI Unicode
11
其他方式的字符编码(略)
CJK统一汉字编码字符集 BIG5 GBK GB 18030/2000 ANSI Unicode
12
CJK统一汉字编码字符集(略)
国家标准 GB13000.1。 有 65536个码位空间中,定义了几乎 所有国家的语言文字和符号。 其中从 4E00H 到 9FA5H 的连续区域 包含了 20902 个来自中国(包括中国 台湾)、日本、韩国的汉字,称为 CJK (Chinese Japanese Korean) 汉 字。 CJK 是《GB2312-80》、《BIG5》等字 符集的超集。