一元线性回归是一个主要影响因素作为自变量来解释因变量的变化
徐建华计量地理学课后习题

计量地理学期末第二章1. 地理数据有哪几种类型,各种类型地理数据之间的区别和联系是什么?答:地理数据就是用一定的测度方式描述和衡量地理对象的有关量化指标。
按类型可分为:1)空间数据:点数据,线数据,面数据;2)属性数据:数量标志数据,品质标志数据地理数据之间的区别与联系:数据包括空间数据和属性数据,空间数据的表达可以采用栅格和矢量两种形式。
空间数据表现了地理空间实体的位置、大小、形状、方向以及几何拓扑关系。
属性数据表现了空间实体的空间属性以外的其他属性特征,属性数据主要是对空间数据的说明。
如一个城市点,它的属性数据有人口,GDP,绿化率等等描述指标。
它们有密切的关系,两者互相结合才能将一个地理试题表达清楚。
^2. 各种类型的地理数据的测度方法分别是什么?地理数据主要包括空间数据和属性数据:空间数据——对于空间数据的表达,可以将其归纳为点、线、面三种几何实体以及描述它们之间空间联系的拓扑关系;属性数据——对于属性数据的表达,需要从数量标志数据和品质标志数据两方面进行描述。
其测度方法主要有:(1) 数量标志数据①间隔尺度(Interval Scale)数据: 以有量纲的数据形式表示测度对象在某种单位(量纲)下的绝对量。
②比例尺度(Ratio Scale)数据: 以无量纲的数据形式表示测度对象的相对量。
这种数据要求事先规定一个基点,然后将其它同类数据与基点数据相比较,换算为基点数据的比例。
【(2) 品质标志数据①有序(Ordinal)数据。
当测度标准不是连续的量,而是只表示其顺序关系的数据,这种数据并不表示量的多少,而只是给出一个等级或次序。
②二元数据。
即用0、1 两个数据表示地理事物、地理现象或地理事件的是非判断问题。
③名义尺度(Nominal Scale)数据。
即用数字表示地理实体、地理要素、地理现象或地理事件的状态类型。
3. 地理数据的基本特征有哪些?1)数量化、形式化与逻辑化2 )不确定性3 )多种时空尺度,4 ) 多维性4. 地理数据采集的来源渠道有哪些?1)来自于观测、测量部门的有关专业数据。
Spss统计分析解释

面板数据面板数据,即Panel Data,是截面数据与时间序列数据综合起来的一种数据类型。
其有时间序列和截面两个维度,当这类数据按两个维度排列时,是排在一个平面上,与只有一个维度的数据排在一条线上有着明显的不同,整个表格像是一个面板,所以把panel data译作“面板数据”。
但是,如果从其内在含义上讲,把panel data译为“时间序列—截面数据” 更能揭示这类数据的本质上的特点。
也有译作“平行数据”或“TS-CS数据(Time Series - Cross Section)”。
举例:如:城市名:北京、上海、重庆、天津的GDP分别为10、11、9、8(单位亿元)。
这就是截面数据,在一个时间点处切开,看各个城市的不同就是截面数据。
如:2000、2001、2002、2003、2004各年的北京市GDP分别为8、9、10、11、12(单位亿元)。
这就是时间序列,选一个城市,看各个样本时间点的不同就是时间序列。
如:2000、2001、2002、2003、2004各年中国所有直辖市的GDP分别为:北京市分别为8、9、10、11、12;上海市分别为9、10、11、12、13;天津市分别为5、6、7、8、9;重庆市分别为7、8、9、10、11(单位亿元)。
这就是面板数据。
面板数据是按照英文的直译,也有人将Panel data翻译成综列数据、平行数据等。
由于国内没有统一的说法,因此直接使用Panel data这种英文说法应该更准确一些。
说面板数据也是比较通用的,但是面板数据并不能从名称上反映出该种数据的实际意义,故很多研究者不愿使用。
主成分分析法主成分分析(Principal Component Analysis简称PCA)也称为主分量分析,是由霍特林(Hotelling)于1933年首先提出来的。
主成分分析是一种多指标决策,这种决策常遇到的问题是,指标数量大,并且指标之间存在某种程度的相关关系,这不仅增加决策的工作量,也直接影响到决策的有效性和可靠性。
一元回归分析

一元回归分析
一元回归分析是统计学中一个重要的研究方法,是探讨一个或多个特征对一个变量的影响程度的有效工具。
即对一个变量(称为因变量)的变化,由另一变量(称为自变量)决定的这种关系强度的大小,分析方法就是一元回归分析。
回归的最基本形式是一元线性回归,也就是说,自变量和因变量之间的关系是一条直线。
一元回归分析中的最重要的因素是多元线性回归模型,也被称为最小二乘法。
其核心思想是寻找一条能够最好地拟合给定数据的直线,以评估每一条直线的拟合错误率为目标函数,通过最小二乘法求解最优化模型,来获得其参数估计值。
最后,一元回归分析也有诊断检验来测试模型的有效性。
诊断检验包括残差检验、正态性检验、相关性检验和自相关性检验等,这些检验可以帮助检查模型是否满足预先设定的假设,因此可以确定模型的可靠性。
从上面可以看出,一元回归分析是一种重要的统计学研究方法,它不仅可以用来研究一个或多个特征对因变量的影响程度,而且还可以通过诊断检验来测试模型的有效性。
因此,它应用广泛,可以为不同领域的研究者提供有价值的结果,如社会、医学、经济和心理等。
实际的应用中,除了研究因变量的影响,还可以使用回归分析来预测未来的值,同时可以采用回归模型来识别与所研究的变量关联的模式和关系。
此外,一般会使用协方差分析识别两个变量之间的关系,这可以使用线性回归模型来完成,即计算变量之间的协方差和相关系
数来评估两个变量之间的强弱程度。
总之,一元回归分析是一种有效的统计分析工具,其主要用途是研究一个或多个特征对一个变量的影响程度,进而识别出两个变量之间的关系,并利用诊断检验来测试模型的有效性,它的应用非常广泛,可用于社会、医学、经济和心理等许多领域。
江苏旅游人才需求预测——基于灰色系统理论和一元回归方程混合模型
Tourism旅游经济1742012年5月 江苏旅游人才需求预测①——基于灰色系统理论和一元回归方程混合模型南京旅游职业学院 王新宇 方法林 宋益丹摘 要:旅游人才与旅游经济发展有着密切的联系,有效的旅游人才需求预测能为宏观调控提供依据,有利于旅游人力资源开发与旅游经济增长的良性互动。
本文分别用一元回归方程和灰色系统理论,对旅游人才需求进行了数学建模。
本文的研究成果可以为江苏省旅游人才的开发和培养提供数据参考。
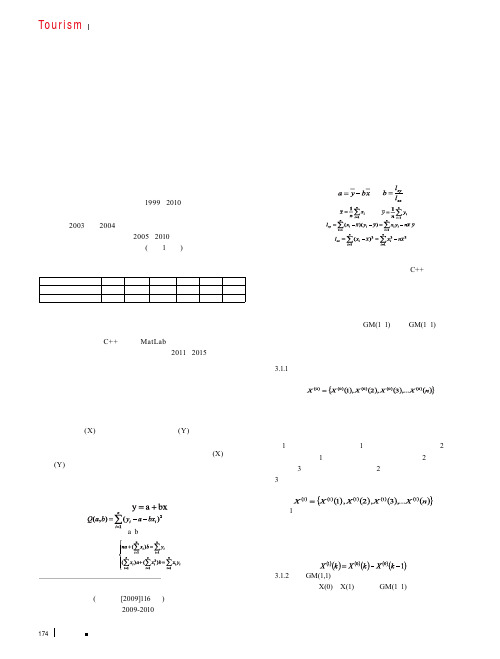
关键词:旅游人才 灰色系统模型 一元回归方程中图分类号:F590 文献标识码:A 文章编号:1005-5800(2012)05(b)-174-021 数据来源与研究方法1.1 数据来源本文中所计算的数据是根据1999~2010年历年的《中国旅游统计年鉴》以及各年的统计公报中相关数据进行加工处理得来的,尤其是对2003年和2004年受“非典”的影响数据进行剔除,以保证数据计算的准确性,最终选用2005~2010年的江苏旅游人才数量和旅游总收入作为研究样本数据,(如表1所示)。
表1 江苏省2005~2010年间的旅游人才的数量和旅游总收入年份200520062007200820092010旅游总收入(万元)Xi223920026653002826900311980034495004287900旅游人才总量(人)Yi1251481338001512731586411681031881671.2 研究方法本文选用了一元回归方程和灰色系统理论分别进行建模,并根据数学模型,使用C++语言和MatLab软件混合编程,实现了这两种模型的计算机软件,可以自动计算出2011~2015年江苏旅游人才需求的数据。
在研究过程中,充分利用先进的计算机技术,自行开发和实现建模软件,对原始样本数据进行准确、快速的运算,得到所需结果,大大缩短了研究时间,这是本文的特点之一。
2 一元线性回归模型本文应用的第一种模型是一元线性回归方程,此模型用一个主要影响因素(X)作为自变量来解释因变量(Y)的变化,历史资料表明,旅游人才数量旅游营业收入成高度的正相关关系。
第二章 一元线性回归

n ei 0 i 1 n xe 0 i i i 1
经整理后,得正规方程组
n n ˆ ˆ n ( x ) 0 i 1 yi i 1 i 1 n n n ( x ) ˆ ( x 2 ) ˆ xy i 0 i 1 i i i 1 i 1 i 1
y ˆ i 0 1xi ˆi 之间残差的平方和最小。 使观测值 y i 和拟合值 y
ei y i y ˆi
n
称为yi的残差
ˆ , ˆ ) ˆ ˆ x )2 Q( ( y i 0 1i 0 1
i 1
min ( yi 0 1 xi ) 2
i
xi x
2 ( x x ) i i 1 n
yi
2 .3 最小二乘估计的性质
二、无偏性
ˆ ) E ( 1
i 1 n
n
xi x
2 ( x x ) j j 1 n
其中用到
E ( yi )
( x x) 0 (xi x) xi (xi x)2
二、用统计软件计算
1.例2.1 用Excel软件计算
什么是P 值?(P-value)
• P 值即显著性概率值 ,Significence Probability Value
•
是当原假设为真时所得到的样本观察结果或更极端情况 出现的概率。
P值与t值: P t t值 P值
•
它是用此样本拒绝原假设所犯弃真错误的真实概率,被 称为观察到的(或实测的)显著性水平。P值也可以理解为 在零假设正确的情况下,利用观测数据得到与零假设相 一致的结果的概率。
2 .1 一元线性回归模型
基于存在交互项的多元线性回归汽车油耗预测模型

间是线性关系时,所进行的回归分析就是多元线性回归。
设随机变量 y 与一般变量 x1 ,x2 ,…,xp 的线性回归模型为:
y = β0 + β1 x1 + β2 x2 + … + βp xp + ε
( 1)
其中,β0 ,β1 ,…,βp 是 p + 1 个未知参数,β0 称为回归常数,β1 ,
…,βp 称为回归系数。y 称为被解释变量 ( 因变量) ,x1 ,x2 ,…,xp 是 p
^^
^
βp 的估计值 β0 ,β1 ,…,βp ,使离差平方和
∑ Q = ( β0 ,β1 ,…,βp ) =
n
(
i =1
yi
- β0
- β1 xi1
- xi2
-
…
-
βp xip )
2
( 2)
达到最小。
( 三) 模型检验
在实际问题的研究中,事先并不能断定随机变量 y 与一般变量
x1 ,x2 ,…,xp 之间一定有线性关系,在进行回归参数的估计前,用多 元线性回归方程去拟合 y 与 x1 ,x2 ,…,xp 之间的关系,只是根据一些 定性分析所作的一种假设。因此,当求出多元线性回归方程后,需
关键词: 交互项; 多元线性回归预测模型; 模型评估; 回归诊断
一、引言
多元线性回归是多元统计分析中的一个重要方法,被广泛应用
于众多自然科学领域的研究中。而多元线性回归预测模型则是以统
计学为理论基础,研究一个随机变量 y 与两个或两个以上一般变量 x1 , x2 ,…,xp 之间的依存关系,并利用现有数据,进行统计分析,发现变 化规律,建立多元线性回归的预测模型,来预测未来的变化情况。本文
一元线性回归分析的原理

一元线性回归分析的原理
一元线性回归分析是一种用于研究变量之间相互关系的统计分析方法。
它旨在
在一组数据中,以一个线性方程的式子去拟合变量之间的关系。
借此,分析一个独立变量(即自变量)和一个取决变量(即因变量)之间的关系,求出最合适的回归系数。
一元线性回归分析可以用来发现和描述变量之间的复杂方程式,用来估计参数,以及构建预测模型。
具体而言,一元线性回归分析指的是自变量和因变量之间有线性关系的回归分析。
也就是说,自变量和因变量均遵从一元线性方程,也就是y=βx+α,其中y
为因变量,x为自变量,β为系数,α为常数。
通过一元线性回归分析可以精确
的定义出变量之间的关系,从而可以得出最佳的回归系数和常数,并估计每个参数。
一元线性回归分析用于研究很多方面,例如决策科学、经济学和政治学等领域。
例如,在政治学研究中,可以使用一元线性回归分析来分析政府的软性政策是否能够促进社会发展,以及社会福利是否会影响民众的投票行为。
在经济学研究中,则可以使用一元线性回归分析来检验价格是否会影响消费水平,或检验工资水平是否会影响经济增长率等。
总结而言,一元线性回归分析是一种有效的研究变量之间关系的统计分析方法,精确地检验独立变量和取决变量之间的关系,从而求得最合适的回归系数和常数,并用该回归方程式构建预测模型,为决策提供参考。
第三章 一元线性回归

LOGO
三、一元线性回归模型中随机项的假定
( xi , yi ),i,j=1,2,3,…,n后,为了估计(3.1.5) 在给定样本观测值(样本值) 式的参数 0和 1 ,必须对随机项做出某些合理的假定。这些假定通常称 为古典假设。
假设1、解释变量X是确定性变量,不是随机变量; 假设2、随机误差项具有零均值、同方差和不序列相关性: E(i)=0 Var (i)=2 i=1,2, …,n i=1,2, …,n
ˆ i ) ( y i 0 1 xi ) 2 Q( 0,1) ( yi y
2 i 1 i 1 n n
(3.2.3)
ˆ , ˆ ,使式 所谓最小二乘法,就是寻找参数 0,,1 的估计值 0 1 ˆ , ˆ 满足: (3.2.3)定义的离差平方和最小,即寻找 0 1
y 1 x
2 y 0 2 x
LOGO
二是被解释变量x与参数 之间为线性关系,即参数 仅以一次方的 形式出现在模型之中。用数学语言表示为:
y 1 0
y 0 2 0
2
y x 1
2 y 0 2 1
在经济计量学中,我们更关心被解释变量y与参数
之间的线性关系。因
第三章 一元线性回归
3.1 一元线性回归模型 3.2 回归参数 0,1 的估计 3.3 最小二乘估计的性质 3.4 回归方程的显著性检验
3.5 预测和控制
LOGO
3.1 一元线性回归模型
一、回归模型的一般形式
1、变量间的关系 经济变量之间的关系,大体可分为两类:
(1)确定性关系或函数关系:变量之间有唯一确定性的函数关 系。其一般表现形式为:
对于总体回归模型,
y f ( x1, x2 ,, xk ) u
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
参考文献【1】易丹辉.数据分析与EViews应用.北京:中国人民大学出版社,2008【2】何晓群,刘文卿.应用回归分析(第三版).北京:中国人民大学出版社,2011 【3】张晓峒.EViews实用指南与案例.北京:机械工业出版社,2007【4】百度文库.网址:(/s?wd=%B0%D9%B6%C8%CE%C4%BF%E2&rsv_bp=0&rsv_spt=3&inputT= 4144)一元线性回归是一个主要影响因素作为自变量来解释因变量的变化,在现实问题研究中,因变量的变化往往受几个重要因素的影响,此时就需要用两个或两个以上的影响因素作为自变量来解释因变量的变化,这就是多元回归亦称多重回归。
当多个自变量与因变量之间是线性关系时,所进行的回归分析就是多元性回归。
设y为因变量,为自变量,并且自变量与因变量之间为线性关系时,则多元线性回归模型为:其中,b0为常数项,为回归系数,b1为固定时,x1每增加一个单位对y的效应,即x1对y的偏回归系数;同理b2为固定时,x2每增加一个单位对y的效应,即,x2对y的偏回归系数,等等。
如果两个自变量x1,x2同一个因变量y呈线相关时,可用二元线性回归模型描述为:其中,b0为常数项,为回归系数,b1为固定时,x2每增加一个单位对y的效应,即x2对y的偏回归系数,等等。
如果两个自变量x1,x2同一个因变量y呈线相关时,可用二元线性回归模型描述为:y= b0+ b1x1+ b2x2+ e建立多元性回归模型时,为了保证回归模型具有优良的解释能力和预测效果,应首先注意自变量的选择,其准则是:(1)自变量对因变量必须有显著的影响,并呈密切的线性相关;(2)自变量与因变量之间的线性相关必须是真实的,而不是形式上的;(3)自变量之彰应具有一定的互斥性,即自变量之彰的相关程度不应高于自变量与因变量之因的相关程度;(4)自变量应具有完整的统计数据,其预测值容易确定。
多元性回归模型的参数估计,同一元线性回归方程一样,也是在要求误差平方和()为最小的前提下,用最小二乘法求解参数。
以二线性回归模型为例,求解回归参数的标准方程组为解此方程可求得b0,b1,b2的数值。
亦可用下列矩阵法求得即[编辑]多元线性回归模型的检验[1]多元性回归模型与一元线性回归模型一样,在得到参数的最小二乘法的估计值之后,也需要进行必要的检验与评价,以决定模型是否可以应用。
1、拟合程度的测定。
与一元线性回归中可决系数r2相对应,多元线性回归中也有多重可决系数r2,它是在因变量的总变化中,由回归方程解释的变动(回归平方和)所占的比重,R2越大,回归方各对样本数据点拟合的程度越强,所有自变量与因变量的关系越密切。
计算公式为:其中,2.估计标准误差估计标准误差,即因变量y的实际值与回归方程求出的估计值之间的标准误差,估计标准误差越小,回归方程拟合程度越程。
其中,k为多元线性回归方程中的自变量的个数。
3.回归方程的显著性检验回归方程的显著性检验,即检验整个回归方程的显著性,或者说评价所有自变量与因变量的线性关系是否密切。
能常采用F检验,F统计量的计算公式为:根据给定的显著水平a,自由度(k,n-k-1)查F分布表,得到相应的临界值F a,若F> F a,则回归方程具有显著意义,回归效果显著;F< F a,则回归方程无显著意义,回归效果不显著。
4.回归系数的显著性检验在一元线性回归中,回归系数显著性检验(t检验)与回归方程的显著性检验(F检验)是等价的,但在多元线性回归中,这个等价不成立。
t检验是分别检验回归模型中各个回归系数是否具有显著性,以便使模型中只保留那些对因变量有显著影响的因素。
检验时先计算统计量t i;然后根据给定的显著水平a,自由度n-k-1查t分布表,得临界值t a或t a/ 2,t> t− a 或t a/ 2,则回归系数b i与0有显著关异,反之,则与0无显著差异。
统计量t的计算公式为:其中,C ij是多元线性回归方程中求解回归系数矩阵的逆矩阵(x'x)− 1的主对角线上的第j个元素。
对二元线性回归而言,可用下列公式计算:其中,5.多重共线性判别若某个回归系数的t检验通不过,可能是这个系数相对应的自变量对因变量的影平不显著所致,此时,应从回归模型中剔除这个自变量,重新建立更为简单的回归模型或更换自变量。
也可能是自变量之间有共线性所致,此时应设法降低共线性的影响。
多重共线性是指在多元线性回归方程中,自变量之彰有较强的线性关系,这种关系若超过了因变量与自变量的线性关系,则回归模型的稳定性受到破坏,回归系数估计不准确。
需要指出的是,在多元回归模型中,多重共线性的难以避免的,只要多重共线性不太严重就行了。
判别多元线性回归方程是否存在严惩的多重共线性,可分别计算每两个自变量之间的可决系数r2,若r2> R2或接近于R2,则应设法降低多重线性的影响。
亦可计算自变量间的相关系数矩阵的特征值的条件数k= λ1/ λp(λ1为最大特征值,λp为最小特征值),k<100,则不存在多重点共线性;若100≤k≤1000,则自变量间存在较强的多重共线性,若k>1000,则自变量间存在严重的多重共线性。
降低多重共线性的办法主要是转换自变量的取值,如变绝对数为相对数或平均数,或者更换其他的自变量。
6.D.W检验当回归模型是根据动态数据建立的,则误差项e也是一个时间序列,若误差序列诸项之间相互独立,则误差序列各项之间没有相关关系,若误差序列之间存在密切的相关关系,则建立的回归模型就不能表述自变量与因变量之间的真实变动关系。
D.W检验就是误差序列的自相关检验。
检验的方法与一元线性回归相同。
[编辑]多元线性回归分析预测法案例分析[编辑]案例一:公路客货运输量多元线性回归预测方法探讨[2]一、背景公路客、货运输量的定量预测,近几年来在我国公路运输领域大面积广泛地开展起来,并有效的促进了公路运输经营决策的科学化和现代化。
关于公路客、货运输量的定量预测方法很多,本文主要介绍多元线性回归方法在公路客货运输量预测中的具体操作。
根据笔者先后参加的部、省、市的科研课题的实践,证明了多元线性回归方法是对公路客、货运输量预测的一种置信度较高的有效方法。
二、多元线性回归预测线性回归分析法是以相关性原理为基础的.相关性原理是预测学中的基本原理之一。
由于公路客、货运输量受社会经济有关因素的综合影响。
所以,多元线性回归预测首先是建立公路客、货运输量与其有关影响因素之间线性关系的数学模型。
然后通过对各影响因素未来值的预测推算出公路客货运输量的预测值。
三、公路客、货运输量多元线性回归预测方法的实施步骤1.影响因素的确定影响公路客货运输量的因素很多,主要包括以下一些因素:(1)客运量影响因素人口增长量裤保有量、国民生产总值、国民收入工农业总产值,基本建设投资额城乡居民储蓄额铁路和水运客运量等。
(2)货运量影响因素人口货车保有量(包括拖拉机),国民生产总值,国民收入、工农业总产值,基本建设投资额,主要工农业产品产量,社会商品购买力,社会商品零售总额.铁路和水运货运量菩。
上述影响因素仅是对一般而言,在针对具体研究对象时会有所增减。
因此,在建立模型时只须列入重要的影响因素,对于非重要因素可不列入模型中。
若疏漏了某些重要的影响因素,则会造成预测结果的失真。
另外,影响因素太少会造成模型的敏感性太强.反之,若将非重要影响因素列入模型,则会增加计算工作量,使模型的建立复杂化并增大随机误差。
影响因素的选择是建立预测模型首要的关键环节,可采取定性和定量相结合的方法进行.影响因素的确定可以通过专家调查法,其目的是为了充分发挥专家的聪明才智和经验。
具体做法就是通过对长期从事该地区公路运输企业和运输管理部门的领导干部、专家、工作人员和行家进行调查。
可通过组织召开座谈会.也可以通过采访,填写调查表等方法进行,从中选出主要影响因素为了避免影响因素确定的随意性,提高回归模型的精度和减少预测工作量,可通过查阅有关统计资料后,再对各影响因素进行相关度(或关联度)和共线性分析,从而再次筛选出最主要的影响因素.所谓相关度分析就是将各影响因素的时间序列与公路客货运量的时间序列做相关分杯事先确定—个相关系数,对相关系数小于的影响因素进行淘汰.关联度是灰色系统理论中反映事物发展变化过程中各因素之间的关联程度,可通过建空公路客、货运量与各影响影响因素之间关联系数矩阵,按一定的标准系数舍去关联度小的影响因素.所谓共线性是指某些影响因素之问存在着线性关系或接近于线性关系.由于公路运输经济自身的特点,影响公路客,货运输量的诸多因素之问总是存在着一定的相关性,持别是与国民经济有关的一些价值型指标。
我们研究的不是有无相关性问题而是共线性的程度,如果影响因素之间的共线性程度很高,首先会降低参数估计值的精度。
其次在回归方程建立后的统计检验中导致舍去重要的影响因素或错误的地接受无显著影响的因素,从而使整个预测工作失去实际意义。
关于共线性程度的判定,可利用逐步分析估计法的数理统计理论编制计算机程序来实现。
或者通过比较r i j和R2的大小来判定。
在预测学上,一般认为当r i j> R2时,共线性是严重的,其含义是,多元线性回归方程中所含的任意两个自变量x i,x j之间的相关系数r i j大于或等于该方程的样本可决系数R2时,说明自变量中存在着严重的共线性问题。
2.建立经验线性回归方程利用最小二乘法原理寻求使误差平方和达到撮小的经验线性回归方程:y——预测的客、货运量g——各主要影响因数3.数据整理对收集的历年客、货运输量和各主要影响因素的统计资料进行审核和加工整理是为了保证预测工作的质量。
资料整理主要包括下列内容:(1)资料的补缺和推算。
(2)对不可靠资料加以核实调整.对查明原因的异常值加以修正。
(3)对时间序列中不可比的资料加以调整和规范化;对按当年价格计算的价值指标应折算成按统。
4.多元线性回归模型的参数估计在经验线性回归模型中,是要估计的参数,可通过数理统计理论建立模型来确定。
在实际预测中,可利用多元线性回归复相关分析的计算机程序来实现·5.对模型参数的估计值进行检验。
此项工作的目的在于判定估计值是否满意、可靠。
一般检验工作须从以下几方面来进行。
∙经济意义检验关于经济预测的数学模型,首先要检验模型是否有经济意义,γp若参数估计值的符号和大小与公路运输经济发展以及经济判别不符合时,这时所估计的模型就不能或很难解释公路运输经济的一般发展规律.就应抛弃这个模型.需要重新构造模型或重新挑选影响因素。
∙统计检验统计检验是数理统计理论的重要内容,用于检验模型估计值的可靠性。
通常,在公路客、货运量预测中应采用的统计检验是:∙拟合度检验所谓拟合度是指所建立的模型与观察的实际情况轨迹是否吻合、接近,接近到什么程度。