统计学之抽样与总体参数的估计(ppt 67页)
统计学02-第三讲 两个总体参数的区间估计_24
2 p
(n1
1)s12
(n2
1)s
2 2
n1 n2 2
3. 估计量x1-x2的抽样标准差
s
2 p
s
2 p
n1 n2
sp
11 n1 n2
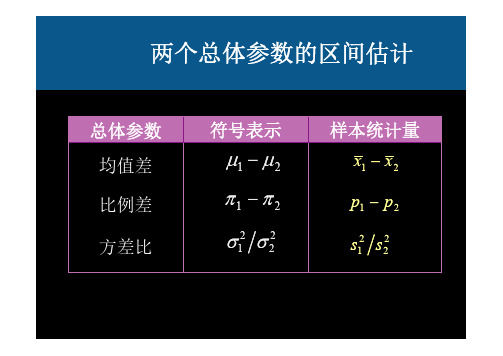
两个总体均值之差的估计
(小样本: 1222 )
1. 两个样本均值之差的标准化
t
( x1
x2 ) 1
s p n1
(1
1 n2
2 )
~
t (n1
n2
2)
2. 两个总体均值之差1-2在1- 置信水平下的
x1
32.5
s12
15.996 x2
27.875
s
2 2
23.014
自由度为
15.996
23.014
2
v 12
8
13.188 13
15.996 122 23.014 82
12 1
8 1
(32.5 27.875) 2.1604 15.996 23.014 4.625 4.433
女学生: x2 480
s
2 2
280
试以90%置信水平估计男女学生生活费支出方 差比的置信区间
两个总体方差比的区间估计 (例题分析)
解 : 根 据 自 由 度 n1=25-1=24 , n2=25-1=24 , 查 得 F/2(24)=1.98, F1-/2(24)=1/1.98=0.505
12 /22置信度为90%的置信区间为
两个总体均值之差1-2在1- 置信水平下的置
信区间为
x1 x2 t 2 (v)
s12
s
2 2
n1 n2
自由度 v
统计学第6章统计量及其抽样分布

整理ppt
16
2. T统计量
设X1,X2,…,Xn是来自正态总体N~ (μ,σ2 )
n
的一个样本,
X
1 n
n i 1
Xi
(Xi X )2 s 2 i1
n 1
则 T(X) ~t(n1)
S/ n
称为T统计量,它服从自由度为(n-1)的t分布。
整理ppt
17
F分布
定义:设随机变量Y与Z相互独立,且Y和Z分别服 从自由度为m和n的c2分布,随机变量X有如下表达式:
整理ppt
8
中心极限定理
设从均值为,方差为2的一个任意总 体中抽取容量为n的样本,当n充分大时, 样本均值的抽样分布近似服从均值为μ、 方差为σ2/n的正态分布。
当样本容量足够大时
(n≥30),样本均值的抽样
分布逐渐趋于正态分布
整理ppt
9
标准误差
标准误差:样本统计量与总体参数之间的平均差异
1. 所有可能的样本均值的标准差,测度所有样本 均值的离散程度
因此,估计这100名患者治愈成功的比 例在85%至95%的概率为90.5%
整理ppt
22
6.5 两个样本平均值之差的分布
设
X
1
是独立地抽自总体
X1 ~N(1,12)
的一个容量
为n1的样本的均值。 X 2 是独立地抽自总体
X2 ~N(2,22)的一个容量为n2的样本的均值,则有
E (X 1X 2)E (X 1) E (X 2)12
2. 样本均值的标准误差小于总体标准差
3. 计算公式为
x
n
整理ppt
10
【例】设从一个均值μ=8、标准差σ=0.7的总 体中随机抽取容量为n=49的样本。要求:
教育与心理统计学 第四章 抽样理论与参数估计考研笔记-精品

第四章抽样理论与参数估计第一节抽样理论的基本知识分层抽样,又叫分层随机抽样,这种抽样方法是按照总体已有的某些特征,承认总体中已有的差异,按差异将总体分为几个不同的部分,每一部分称为一个层,在每一个层中实行简单随机抽样。
它充分利用了总体的已知信息,因而是一种非常适用的抽样方法,其样本代表性及推论的精确性一般优于简单随机抽样。
分层的原则是层与层之间的变异越大越好,各层内的变异要小。
试述分层抽样的原则和方法?分层抽样是按照总体上已有的某些特征,将总体分成几个不同部分,在分别在每一部分中随机抽样。
分层的总的原则是:各层内的变异要小,而层与层之间的变异越大越好。
在具体操作中,没有一成不变的标准,研究人员可根据研究需要依照多个分层标准,视具体情况而定。
⑷两阶段随机抽样两阶段随机抽样首先将总体分成M个部分,每一部分叫做一个"集团"(或"群"),第一步从M个集团中随机抽取m个"集团”作为第一阶段样本,第二步是分别从所选取的m个"集团”中抽取个体(g构成第二阶段样本。
一般而言,两阶段抽样相对于简单随机抽样,标准误要大些,但是,两阶段抽样简便易行,节省经草贼,因而它是大规模调查研究中常被使用的抽样方法。
例如,如果我们要了解全国城市初中二年级学生的身高,第一步我们可以从全国几百个城市中随机抽取几十个城市作为第一阶段的样本。
第二步,在第一阶段随机抽取出来的城市中再随机抽取初中二年级的学生。
(二)非旃抽样非概率抽样不是完全按随机原则选取样本,有方便抽样、判断抽样。
方便抽样是由调查人员自由、方便地选择被调查者的非随机选样。
判断抽样是通过某些条件过滤,然后选择某些被调查者参与调查的抽样法。
当采取非概率抽样的方法选取样本时,研究者要说明采用此种方取样的原因以及对研究结果可能造成的影响。
第二节抽样分布[统计量分布、基本随机变量函数的分布]总体:又称母全体、全域,指具有某种特征的一类事物的全体。
概率论 第七章 参数估计

L( ) max L( )
称^为
的极大似然估计(MLE).
求极大似然估计(MLE)的一般步骤是:
(1) 由总体分布导出样本的联合概率分布 (或联合密度);
(2) 把样本联合概率分布(或联合密度)中自变 量看成已知常数,而把参数 看作自变量, 得到似然函数L( );
(3) 求似然函数L( ) 的最大值点(常常转化 为求ln L( )的最大值点) ,即 的MLE;
1. 将待估参数表示为总体矩的连续函数 2. 用样本矩替代总体矩,从而得到待估参
数的估计量。
四. 最大似然估计(极大似然法)
在总体分布类型已知条件下使用的一种 参数估计方法 .
首先由德国数学家高斯在1821年提出。 英国统计学家费歇1922年重新发现此
方法,并首先研究了此方法的一些性质 .
例:某位同学与一位猎人一起外出打猎.一只 野兔从前方窜过 . 一声枪响,野兔应声倒下 .
p值 P(Y=0) P(Y=1) P( Y=2) P(Y=3) 0.7 0.027 0.189 0.441 0.343 0.3 0.343 0.441 0.189 0.027
应如何估计p?
若:只知0<p<1, 实测记录是 Y=k
(0 ≤ k≤ n), 如何估计p 呢?
注意到
P(Y k) Cnk pk (1 p)nk = f (p)
第七章 参数估计
参数估计是利用从总体抽样得到的信息 估计总体的某些参数或参数的某些函数.
仅估 计一 个或 几个 参数.
估计新生儿的体重
估计废品率
估计降雨量
估计湖中鱼数
…
…
参数估计问题的一般提法:
设总体的分布函数为 F(x, ),其中为未 知参数 (可以是向量).从该总体抽样,得样本
《统计学》第10讲 参数估计(复习+习题)

(二)方差的区间估计
1.总体方差的区间估计
对于来自正态总体的容量为n的简单随机样本,统 计量 n 1s 2 / 2 服从自由度为 n 1 的卡方分布。
n 1 s 2
2
~ 2 n 1
总体方差在1- 置信水平下的置信区间为
2 n 1 s
2
2 2 2 2 s1 s2 s1 s2 , F 2 F1 2
F分布两个自由度
24
(三)总体比率区间估计
1.单样本比率的区间估计
当样本容量充分大时,样本比率p近似服从以总体比
率P为数学期望,以P(1-P)/n为方差的正态分布。
1. 样本比率的数学期望
E (p) P
2. 样本比率的方差
P (1 P ) n
n1 n2
18
( n1 3 0, n 2 3 0 )
大样本,方差已知(两个总体分布没有要求)
1. 两个样本均值之差 x 1 x 2 的抽样分布服从正态
分布,其数学期望为两个总体均值之差
E (x1 x 2 ) 1
2
2. 方差为各自的方差之和
2 x1 x 2
12 22 n1 n2
•
分别从两个独立的随机总体中抽取容量为n1和n2的 独立样本,当两个样本都为大样本时,两个样本比 率之差的抽样分布可用正态分布来近似。 数学期望为
• •
E ( p 1 p 2 ) P1 P 2
方差为各自的方差之和
27
2 p1 p 2
P1 (1 P1 ) P2 (1 P2 ) n1 n2
2
2 2 x n
统计学抽样与抽样分布

3. 需要包含所有低阶段抽样单位的抽样框;同时由于
实行了再抽样,使调查单位在更广泛的范围内展开
4. 在大规模的抽样调查中,经常被采用的方法
概率抽样(小结)
非概率抽样
n也叫非随机抽样,是指从研究目的出发,根据调查者的 经验或判断,从总体中有意识地抽取若干单位构成样本。
n重点调查、典型调查、配额抽样(是按照一定标准或一 定条件分配样本单位数量,然后由调查者在规定的数额内 主观地抽取样本)、方便抽样(指调查者按其方便任意选 取样本。如商场柜台售货员拿着厂家的调查表对顾客的调 查)等就属于非随机抽样。
样本分量:其中每一个Xi是一个随机变量,称为样本 分量。
样本观察值:一次抽样中所观察到的样本数据x1、x2、 x3称为样本观察值。 对于某一既定的总体,由于抽样的方式方法不同,样 本容量也可大可小,因而,样本是不确定的、而是可5
一、 几个概念
(二)样本总体与样本指标
样本指标(统计量)。在抽样估计中,用来反 映样本总体数量特征的指标称为样本指标,也 称为样本统计量或估计量,是根据样本资料计 算的、用以估计或推断相应总体指标的综合指 标。
3
总体和参数(续)
通常所要估计的总体指标有
X
NX
一、 几个概念
(二)样本总体与样本指标
样本总体。简称样本(Sample),它是按照随机原则, 从总体中抽取的部分总体单位的集合体 。
样本容量:样本中所包含的个体的数量,一般用n表示。 在实际工作中,人们通常把n≥30的样本称为大样本, 而把n<30的样本称为小样本。
(二)抽样平均误差(抽样标准误)
抽样平均误差是反映抽样误差一般水平的指标(因为 抽样误差是一个随机变量,它的数值随着可能抽取的 样本不同而或大或小,为了总的衡量样本代表性的高 低,就需要计算抽样误差的一般水平)。通常用样本 估计量的标准差来反映所有可能样本估计值与其中心 值的平均离散程度。
(04)第4章 参数估计

(2)99%的置信区间是多少?
(3)若样本容量为40,而观测的数据不变,则 95%的置信区间又是多少?
5 - 31
统计学
STATISTICS
总体均值的区间估计
(例题分析)
12, s 4.1
解:(1)已知n=15, 1- = 95%, =0.05 ,x
统计学
STATISTICS
总体均值的区间估计
统计学
STATISTICS
大样本的估计方法
不论总体是不是服从正态分布,在大样本 (n 30)时,样本均值均服从正态分布。 若已知 2 x
x ~ N ( ,
总体均值 在1- 置信水平下的置信区间为
n
)
z
n
~ N (0,1)
z 2
有效性:对同一总体参数的两个无偏点估计量, 有更小标准差的估计量更有效
ˆ P( )
ˆ1 的抽样分布
B A
ˆ2 的抽样分布
ˆ
5 - 11
ˆ ˆ1 是比 2 更有效,是一个更好的估计量
统计学
STATISTICS
有效性
(efficiency)
x1 x2 x3 样本均值 x 3 x1 2 x2 3x3 和 x1 6
统计学
STATISTICS
第 4 章 参数估计
4.1 参数估计的基本原理 4.2 一个总体参数的区间估计 4.4 样本容量的确定
5-1
统计学
STATISTICS
4.1 参数估计的一般问题
4.1.1 估计量与估计值 4.1.2 点估计与区间估计 4.1.3 评价估计量的标准
《统计学原理》第5章:抽样推断

σ
n )
抽样推断的基本原理
抽样推断的优良标准
设θ 为待估计的总体参数, θ为样本统计量,则 θ的优良标 准为: 1若 E(θ ) =θ ,则称 θ为 θ 的无偏估计量(无偏性)
更有效的估计量(有效性) 2若σθ1 < σθ2,则称θ1为比θ2
3若 越大σθ 越小,则称 θ 为θ 的一致估计量(一 致性)
即中选成分相同但中选顺序不同的视为同一样本
抽样推断的一般问题
抽样组织方式
简单随机抽样 类型抽样 整群抽样 等距抽样 多阶段抽样 多重抽样
抽样推断的一般问题
样本可能数目
按照一定的抽样方法和组织方式,从总体N中抽取n个 单位构成样本,一共可以抽出的不同样本的数量,一般 用M表示. 考虑顺序的不重复抽样 考虑顺序的重复抽样 不考虑顺序的不重复抽样 不考虑顺序的重复抽样
抽样推断的一般问题
全及总体指标:参数 (未知量) 统计推断 样本总体指标:统计量 (已知量)
抽样推断的一般问题
抽样推断的特点 按随机原则抽取样本 运用概率论的理论和方法,用样本指标来推断 总体指标。 推断的误差可以事先计算和控制。
抽样推断的一般问题
抽样推断的应用 无法或 很难进行全面调查而又需要了解 其全面情况时 某些可以采用全面调查的社会经济现象, 也可采用抽样推断。 可用于生产过程的质量控制 进行假设检验
抽样推断的基本原理
抽样推断的优良标准——有效性 中位数的抽样分布
9 8 7 6 5 4 3 2 1 0 -1 45 50 55 60 65 70 75
平均数的抽样 分布
E(x) =
E ( me ) =
e
σx <σm
抽样推断的基本原理