OpenMP程序的编译与运行-实验报告二
并行程序设计实验报告-OpenMP 基础实验

实验1:OpenMP 基础实验1、实验目的1)了解OpenMP的运行环境2)掌握OpenMP编程的基本要素、编译方法,可运用相关知识独立完成一个基本的OpenMP程序的编写与调试过程。
2、实验要求1)掌握OpenMP运行环境在ubuntu环境中打开一个终端界面。
尝试在图形操作界面左侧寻找终端的图标进行点击,或直接使用快捷键Ctrl+Alt+T打开终端界面进行Shell环境。
2)运行一个简单OpenMP程序程序代码见程序1-1、1-23)OpenMP兼容性检查通过检查预处理宏_OPENMP 是否定义来进行条件编译。
如果定义了_OPENMP,则包含omp.h 并调用OpenMP 库函数。
程序代码见程序1-34)常用线程操作库函数语句在OpenMP编程过程中,一旦涉及线程操作,有较大的概率使用三个常用的库函数,分别为:(1) int omp_get_num_threads(void) 获取当前线程组(team)的线程数量,如果不在并行区调用,则返回1。
(2) int omp_get_thread_num(void) 返回当前线程号。
(3) int omp_get_num_procs(void) 返回可用的处理核个数。
注意区别这三个库函数的外形及意义,特别是前两个库函数,初始使用时很容易混淆。
程序代码见程序1-45)parallel语句的练习parallel 用来构造一个并行区域,在这个区域中的代码会被多个线程(线程组)执行,在区域结束处有默认的同步(隐式路障)。
我们可以在parallel 构造区域内使用分支语句,通过omp_get_thread_num 获得的当前线程编号来指定不同线程执行区域内的不同代码。
程序代码见程序1-5、1-66)critical和reducation语句的练习为了保证在多线程执行的程序中,出现资源竞争的时候能得到正确结果,OpenMP 提供了3种不同类型的多线程同步机制:排它锁、原子操作和临界区。
多核多线程技术OpenMP_实验报告2
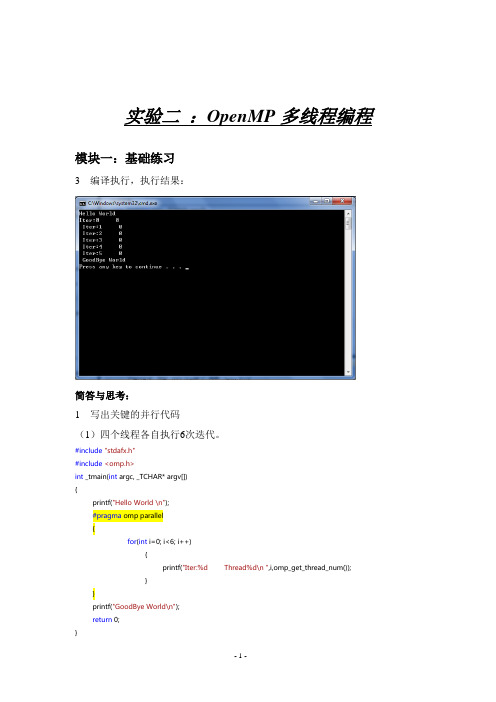
实验二:OpenMP多线程编程模块一:基础练习3 编译执行,执行结果:简答与思考:1 写出关键的并行代码(1)四个线程各自执行6次迭代。
#include"stdafx.h"#include<omp.h>int _tmain(int argc, _TCHAR* argv[]){printf("Hello World \n");#pragma omp parallel{for(int i=0; i<6; i++){printf("Iter:%d Thread%d\n ",i,omp_get_thread_num());}}printf("GoodBye World\n");return 0;}(2)四个线程协同完成6次迭代。
#include"stdafx.h"#include<omp.h>int _tmain(int argc, _TCHAR* argv[]){printf("Hello World \n");#pragma omp parallel{#pragma omp forfor(int i=0; i<6; i++){printf("Iter:%d Thread%d\n ",i,omp_get_thread_num());}}printf("GoodBye World\n");return 0;}2 附加练习:(1)编译执行下面的代码,写出两种可能的执行结果。
int i=0,j = 0;#pragma omp parallel forfor ( i= 2; i < 7; i++ )for ( j= 3; j< 5; j++ )printf(“i = %d, j = %d\n”, i, j);可能的结果:1种2种i=2,j=3 i=2,j=3i=2,j=4 i=2,j=4i=3,j=3 i=3,j=3i=3,j=4 i=3,j=4i=6,j=3 i=5,j=3i=6,j=4 i=5,j=4i=4,j=3 i=5,j=3i=4,j=4 i=5,j=4i=5,j=3 i=6,j=3i=5,j=4 i=6,j=4(2)编译执行下面的代码,写出两种可能的执行结果。
OpenMP (2)

i=3, thread_id=1i=5, thread_id=1i=6, thread_id=1i=7, thread_id=1i=8, thread_id=1i=4, thread_id=0i=9, thread_id=1由于没有指定size所以任务划分是按1此迭代进行的。
②下面为动态调度使用size参数的例子:1. #pragma omp parallel for schedule(dynamic, 2)2. for(i = 0; i < 10; i++ )3. {4. printf("i=%d, thread_id=%d\n", i, omp_get_thread_num());5. }打印结果如下:i=0, thread_id=0i=1, thread_id=0i=4, thread_id=0i=2, thread_id=1i=5, thread_id=0i=3, thread_id=1i=6, thread_id=0i=8, thread_id=1i=7, thread_id=0i=9, thread_id=1从打印结果可以看出第“0、1”,“4、5”,“6、7”次迭代被分配给了线程0,第“2、3”,“8、9”次迭代则分配给了线程1,每次分配的迭代次数为2。
较快的线程“抢到”了更多的任务。
动态调度时,size小有利于实现更好的负载均衡,但是会引起过多的任务动态申请的开销,反之size大则开销较少,但是不易于实现负在平衡,size的选择需要在这两者之间进行权衡。
4)guided调度guided调度是一种采用指导性的启发式自调度方法。
开始时每个线程会分配到较大的迭代块,之后分配到的迭代块会逐渐递减。
迭代块的大小会按指数级下降到指定的size大小,如果没有指定size参数,那么迭代块大小最小会降到1。
例如以下代码:1. #pragma omp parallel for schedule(guided,2)2. for (i = 0; i < 10; i++ )3. {4. printf("i=%d, thread_id=%d\n", i, omp_get_thread_num());5. }打印结果如下:i=0, thread_id=0i=1, thread_id=0i=2, thread_id=0i=3, thread_id=0i=4, thread_id=0i=5, thread_id=1i=6, thread_id=1i=7, thread_id=1第0、1、2、3、4次迭代被分配给线程0,第5、6、7次迭代被分配给线程1,第8、9次迭代被分配给线程0,分配的迭代次数呈递减趋势,最后一次递减到2次。
并行程序设计实验报告-OpenMP 进阶实验

实验2:OpenMP 进阶实验1、实验目的掌握生产者-消费者模型,具备运用OpenMP相关知识进行综合分析,可实现实际工程背景下生产者-消费者模型的线程级负责均衡规划和调优。
2、实验要求1)single与master语句制导语句single 和master 都是指定相关的并行区域只由一个线程执行,区别在于使用master 则由主线程(0 号线程)执行,使用single 则由运行时的具体情况决定。
两者还有一个区别是single 在结束处隐含栅栏同步,而master 没有。
在没有特殊需求时,建议使用single 语句。
程序代码见程序2-12)barrier语句在多线程编程中必须考虑到不同的线程对同一个变量进行读写访问引起的数据竞争问题。
如果线程间没有互斥机制,则不同线程对同一变量的访问顺序是不确定的,有可能导致错误的执行结果。
OpenMP中有两种不同类型的线程同步机制,一种是互斥机制,一种是事件同步机制。
其中事件同步机制的设计思路是控制线程的执行顺序,可以通过设置barrier同步路障实现。
3)atomic、critical与锁通过critical 临界区实现的线程同步机制也可以通过原子(atomic)和锁实现。
后两者功能更具特点,并且使用更为灵活。
程序代码见程序2-2、2-3、2-44)schedule语句在使用parallel 语句进行累加计算时是通过编写代码来划分任务,再将划分后的任务分配给不同的线程去执行。
后来使用paralle for 语句实现是基于OpenMP 的自动划分,如果有n 次循环迭代k 个线程,大致会为每一个线程分配[n/k]各迭代。
由于n/k 不一定是整数,所以存在轻微的负载均衡问题。
我们可以通过子句schedule 来对影响负载的调度划分方式进行设置。
5)循环依赖性检查以对π 的数值估计的方法为例子来探讨OpenMP 中的循环依赖问题。
圆周率π(Pi)是数学中最重要和最奇妙的数字之一,对它的计算方法也是多种多样,其中适合采用计算机编程来计算并且精确度较高的方法是通过使用无穷级数来计算π 值。
OpenMP并行程序设计(二)

sections,用在可能会被并行执行的代码段之前 parallel sections,parallel和sections两个语句的结合 critical,用在一段代码临界区之前 single,用在一段只被单个线程执行的代码段之前,表示后面的代码段将被单线程执行。
flush,
barrier,用于并行区内代码的线程同步,所有线程执行到barrier时要停止,直到所有线程都执行到barrier时才继续往下执
for ( int j = 0; j < 2; j++ ){ test();
} clock_t t2 = clock(); printf("Total time = %d/n", t2-t1);
test(); return 0; }
在没有执行完for循环中的代码之前,后面的clock_t t2 = clock();这行代码是不会执行的,如果和调用线程创建函数相比,它相
3、parallel 指令的用法
parallel 是用来构造一个并行块的,也可以使用其他指令如for、sections等和它配合使用。 在C/C++中,parallel的使用方法如下: #pragma omp parallel [for | sectቤተ መጻሕፍቲ ባይዱons] [子句[子句]…] {
//代码 } parallel语句后面要跟一个大括号对将要并行执行的代码括起来。 void main(int argc, char *argv[]) {
#pragma omp parallel private(i, j)
parallel 就是指令, private是子句
为叙述方便把包含#pragma和OpenMP指令的一行叫做语句,如上面那行叫parallel语句。
MPI和OpenMP程序设计实验报告

一、实验目的及要求熟悉MPI编程环境,掌握MPI编程基本函数及MPI的相关通信函数用法,掌握MPI的主从模式及对等模式编程;熟悉OpenMP编程环境,初步掌握基于OpenMP的多线程应用程序开发,掌握OpenMP相关函数以及数据作用域机制、多线程同步机制等。
二、实验设备(环境)及要求Microsoft Visual Studio .net 2005MPICH2Windows 7 32位Intel Core2 Duo T5550 1.83GHz 双核CPU2GB内存三、实验内容与步骤1.配置实验环境/research/projects/mpich2/downloads/index.php?s =downloads 处下载MPICH2,并安装。
将安装目录中的bin目录添加到系统环境变量path中。
以管理员身份运行cmd.exe,输入命令smpd -install -phrase ***。
***为安装时提示输入的passphrase。
运行wmpiregister.exe,输入具有系统管理员权限的用户名及密码,进行注册。
配置vs2005,加入MPICH2的包含文件,引用文件和库文件,如下图。
配置项目属性,添加附加依赖项mpi.lib,如下图。
VS2005支持OpenMP,只需在项目属性中做如下配置。
2.编写MPI程序题目:一个小规模的学校想给每一个学生一个唯一的证件号。
管理部门想使用6位数字,但不确定是否够用,已知一个“可接受的”证件号是有一些限制的。
编写一个并行计算程序来计算不同的六位数的个数(由0-9组合的数),要求满足以下限制:●第一个数字不能为0;●两个连续位上的数字不能相同;●各个数字之和不能为7、11、13代码如下。
#include "mpi.h"#include <stdio.h>#include <math.h>#define NUM 6#define MAX 999999#define MIN 100000int check(int n){int i, x, y, sum;if (n < MIN){return -1;}sum = 0;for (i=1; i<NUM; i++){x = (n%(int)pow(10, i))/(int)pow(10,i-1);y = (n%(int)pow(10, i+1))/(int)pow(10, i);if (x == y){return -1;}sum = sum+x+y;}if (sum==7 || sum==11 || sum==13){return -1;}return 0;}void main(int argc, char **argv){int myid, numprocs, namelen;char processor_name[MPI_MAX_PROCESSOR_NAME];MPI_Status status;double startTime, endTime;int i, mycount, count;MPI_Init(&argc,&argv);MPI_Comm_rank(MPI_COMM_WORLD,&myid);MPI_Comm_size(MPI_COMM_WORLD,&numprocs);MPI_Get_processor_name(processor_name,&namelen);if (myid == 0){startTime = MPI_Wtime();}mycount = 0;for (i=myid; i<=MAX; i+=numprocs){if (check(i) == 0){mycount++;}}printf("Process %d of %d on %s get result=%d\n", myid, numprocs, processor_name, mycount);if (myid != 0){MPI_Send(&mycount, 1, MPI_INT, 0, myid, MPI_COMM_WORLD);}else{count = mycount;for (i=1; i<numprocs; i++){MPI_Recv(&mycount, 1, MPI_INT, MPI_ANY_SOURCE, MPI_ANY_TAG, MPI_COMM_WORLD, &status);count += mycount;}endTime = MPI_Wtime();printf("result=%d\n", count);printf("time elapsed %f\n", endTime-startTime);}MPI_Finalize();}计算量平均分给每个进程,每个进程将自己计算的部分结果发送给0号进程,由0号进程将结果相加,并输出。
OpenMP及Pthread技术实验报告

多核平台下的并行计算课程
实验报告
并行技术:OpenMP、Pthread
姓名:
学号:
班级:
OpenMP并行化思路:
每个线程计算矩阵的不同部分,各线程的工作定义在函数multi()中。
使用#pragma omp parallel num_threads(thread_count) multi();实现函数的循环执行,thread_count为线程数。
multi()中,矩阵行数除以线程数取得行数,顺序分配给各线程,前n-1个线程分配相同行数,最后一个线程分配剩余行,结果存到矩阵C。
OpenMP结果与加速比展示:
OpenMP实验结果:
Pthread并行化思路:
每个线程计算矩阵的不同部分,各线程的工作定义在函数multi()中。
使用for循环创建线程。
multi()中,矩阵行数除以线程数取得行数,顺序分配给各线程,前n-1个线程分配相同行数,最后一个线程分配剩余行,结果存到矩阵C。
创建线程部分:
for(thread=0;thread<thread_count;thread++)
{
pthread_create(&thread_handles[thread],NULL,multi,(void*)thread);
}
for(thread=0;thread<thread_count;thread++)
{
pthread_join(thread_handles[thread],NULL);
}
Pthread结果与加速比展示:
Pthread实验结果:。
在Linux或Windows环境下配置OpenMP开发运行环境,并利用蒙特卡罗算法计算半径为 1 单元的球体体积。

计算机科学与技术系实验报告课程名称:并行计算及编程实验项目:专业班级:姓名:学号:实验时间:批阅时间:指导教师:成绩:兰州交通大学《并行计算及编程》课程实验报告实验名称:课内综合实验1一、实验目的在Linux或Windows环境下配置OpenMP开发运行环境,并利用蒙特卡罗算法计算半径为1 单元的球体体积。
二、实验内容1. 验证所配置OpenMP并行环境的正确性;2. 分别用串行程序和并行程序实现以上问题的求解;3. 比较并行和串行程序的执行时间,并行计算加速比;4. 提交电子版详细实验报告。
三、实验环境Windows10,下载Visual Studio2019四、实验过程(包括程序设计说明,实验步骤,经调试后正确的源程序,程序运行结果)①实验步骤:下载Visual Studio2019图1用hello world 程序验证在Solution Explorer (解决方案资源管理器)中对项目名右键,选择属性,更改图2进行配置图3配置成功后输出答案②环境配置好后,利用蒙特卡罗算法计算半径为1 单元的球体体积。
/用串行程序实现:经过调试后的正确程序:#include<iostream>#include<stdlib.h>#include<time.h>using namespace std;int main() {long int max = 10000000;long int i, count = 0;double x, y, z, bulk, start_time, end_time;start_time = clock();time_t t;srand((unsigned)time(&t));//函数产生一个以当前时间开始的随机种子for (i = 0; i < max; i++) {x = rand(); //生成0~RAND_MAX之间的一个随机数,其中RAND_MAX 是stdlib.h 中定义的一个整数,它与系统有关。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
曲阜师范大学
实验报告
课程名称:并行计算
实验名称:OpenMP并行程序的编译和运行姓名:***
学号:**********
班级:2014级全日制研究生
实验日期:2014年10月31
一. 实验目的
1) 在Linux平台上编译和运行OpenMP程序;
2) 在Windows平台上编译和运行OpenMP程序。
二. 实验环境
1) 硬件环境:32核CPU、32G内存计算机;
2) 软件环境:Linux、Win2003、GCC、MPICH、VS2008;
3) Linux登录方式:通过ssh方式(用SecureCRT工具或putty工具,可网上下载)连接曙光集群服务器,用户名:root,密码:********;
4) Windows登录方式:在自己机器上运行。
三. 实验内容
1. Linux下OpenMP程序的编译和运行。
OpenMP是一个共享存储并行系统上的应用编程接口,支持C/C++和FORTRAN等语言,编译和运行简单的"Hello World"程序。
在Linux下编辑hellomp.c源程序,或在Windows下编辑并通过附件中的FTP工具(端口号:1021)上传,用"gcc -fopenmp -O2 -o hellomp.out hellomp.c"命令编译,用"./hellomp.out"命令运行程序,代码如下:
#include <omp.h>
#include <stdio.h>
int main()
{
int nthreads,tid;
omp_set_num_threads(8);
#pragma omp parallel private(nthreads,tid)
{
tid=omp_get_thread_num();
printf("Hello World from OMP thread %d\n",tid);
if(tid==0)
{
nthreads=omp_get_num_threads();
printf("Number of threads is %d\n",nthreads);
}
}
}
答:(提供关键的截图和简单的文字描述)
(1)先通过putty连接到曙光集群,登录进去,就到了LINUX系统
(2)查询hellomp.c文件
(3)显示hellomp.c文件内容
(4)输入"gcc -fopenmp -O2 -o hellomp.out hellomp.c"命令编译(5)输入"./hellomp.out"命令运行程序
得到的结果截图如下:
2. Windows下OpenMP程序的编译和运行。
用VS2008编辑上述的hellomp.c源程序,注意在菜单“项目->属性->C/C++->语言”选中“OpenMP支持”,编译并运行程序。
// hellomp.c.cpp : 定义控制台应用程序的入口点。
//
#include<stdafx.h>
#include<stdio.h>
#include<omp.h>
int main()
{
int nthreads,tid;
omp_set_num_threads(8);
#pragma omp parallel private(nthreads,tid)
{
tid=omp_get_thread_num();
printf("Hello World from OMP thread %d\n",tid);
if(tid==0)
{
nthreads=omp_get_num_threads();
printf("Number of threads is %d\n",nthreads);
}
}
}
答:(提供关键的截图和简单的文字描述)
(1)通过远程桌面连接219.218.25.166(在自己机器上运行即可),登录进window系统(2)打开VS2008编辑上述的hellomp.c 源程序
(3)编译hellomp.c 程序
(4)运行hellomp.c 程序
(5)结果截图如下。