亿级Web系统分布式集群设计
云计算设计和实施方案

云计算设计和实施方案1.摘要电,并只需要对它们所使用的资源付费。
今天,计算资源在人们的H常生活中逐渐变得不可或缺,于是如何以更好地方式给公众提供计算资源受到很多研究人员和实践者的关注。
随着多核处理器、虚拟化、分布式存储、宽带互联网和自动化管理技术的发展,产生了一种新型的计算模式——云计算,它能够按需部署计算资源,用户只需要为使用的资源付费。
从本质上来讲,云计算是指用户终端通过远程连接,获取存储、计算、数据库等计算资源。
云计算在资源分布上包括“云”和“云终端”。
“云”是列互联网或大型服务器集群的一种比喻,由分布的互联网基础设施(网络设备、服务器、存储设备、安全设备等)等构成,几乎所有的数据和应用软件,都可存储在“云”里,“云终端”,例如PC、手机、车载电子设备等,只需要拥有一个功能完备的浏览器,并安装一个简单的操作系统,通过网络接入“云”,就可以轻松地使用云中的计算资源。
2.云计算概念2.1 云计算产生的背景21世纪初期,崛起的Web2.0让网络迎来了新的发展高峰。
网站或者业务系统所需要处理的业务量快速增长,例如视频在线或者照片共享,这样的网站需要为用户储存和处理大量的数据。
这类系统所面临的重要问题是如何在用户数量快速增长的情况下快速扩展原有系统,随着移动终端的智能化、移动宽带网络的普及,将有越来越多的移动设备进入互联网,意味着与移动终端相关的IT系统会承受更多的负载,而列于提供数据服务的企业来讲,IT系统需要处理更多的业务量。
由于资源的有限性,电II,J成本、空间成本、各种设施的维护成本快速上升,直接导致数据中心的成本上升,这就面临着怎样有效地利用这些资源,以及如何利用更少的资源解决更多的问题,同时,随着高速网络连接的衍生,芯片和磁盘驱动器产品在功能增强的同时,价格也在变得甘益低廉,拥有成百上千台计算机的数掂中心也具备了快速为大量用户处理复杂问题的能力…。
技术上,分布式计算的日益成熟和应用,特别是网格计算的发展通过Internet把分散在各处的硬件、软件、信息资源连接成为一个巨大的整体,从而使得人们能够利用地理上分散于各处的资源,完成大规模的、复杂的计算和数据处理的任务oJ。
分布式存储——精选推荐

分布式存储⽬录分布式系统理论基础什么是分布式系统,这个概念我们很难⽤⼀个精准的描述⽅式来概括出,所有的意义来。
但⼤体上来讲,我们可以从两个层⾯来描述⼀个分布式系统的特性。
第⼀,分布式系统⼀定是,他有很多种组1、系统的各组件分布于⽹络上多个计算机2、各组件彼此之间仅仅通过消息传递来通信并协调⾏动分布式系统存在的意义:那⼀般⽽⾔,我们要使⽤分布式系统的主要原因在于,第⼀,我们系统扩展可以有两种模型。
所谓向上和向外对不对,⽽经验表明,向上扩展的这种模型,他的性价⽐越来越低。
第⼆,单机1、向上扩展的性价⽐越来越低;2、单机扩展存在性能上升临界点:3、出于稳定性及可⽤性考虑,单机会存在多⽅⾯的问题CPU,内存,IO要想理解分布式系统所能够带给我们的意义,分布式系统的⽬的,主要是扩展了单机处理能⼒的弱势,或者说瓶颈。
我们计算机主要包含五⼤部件,根据所谓的冯诺依曼架构所构成的系统,多CPU,多线程编程假设刚开始使⽤的是LAMP或者LNMP。
最简单的时候就是这么⼀种架构。
⽽且还有可能是构建在单机上。
所以我们的⽹站刚开始的时候有可能只有⼀台主机。
⼀个主机内部有⼀个所谓的ap LAMP,LNMP应⽤从资源占⽤的⾓度分两类:CPU Bound(CPU密集型应⽤)IO Bound(IO密集型应⽤)session sticky(会话粘滞,基于IP地址的session粘滞)ip basedcookie based(基于cookie的session分发)session replication(会话复制,不是⽤⼤规模集群中,所以使⽤第3种。
)session server(session集中存储)引出缓存:1、页⾯缓存varnish, squid2、数据緩存key-value(memcached)主库写操作压⼒:数据库拆分垂直拆分:把数据库中不同的业务的数据拆分到不同的数据库服务器中⽔平拆分,把⼀个单独的表中的数据拆分到多个不同的数据库服务器上NoSQL:⾮关系数据⽂档数据库列式数据库... ...SFS:⾮结构化数据TFS,MogileFS:适⽤于存储海量⼩⽂件。
互联网架构的演变过程(一)

互联⽹架构的演变过程(⼀)简介web1.0时代web2.0时代互联⽹时代互联⽹+ --》智慧城市。
2012年提出。
云计算+⼤数据时代背景随着互联⽹的发展,⽹站应⽤的规模不断扩⼤,常规的垂直应⽤架构已⽆法应对,分布式服务架构以及流动计算架构势在必⾏,亟需⼀个治理系统确保架构有条不紊的演进。
1、第⼀时期单⼀应⽤架构all in one(所有的模块在⼀起,技术也不分层)⽹站的初期,也认为互联⽹发展的最早时期。
会在单机部署上所有的应⽤程序和软件。
所有的代码都是写在JSP⾥⾯,所有的代码都写在⼀起。
这种⽅式称为all in one。
特点:1、不具备代码的可维护性。
2、容错性差。
因为我们所有的代码都写在JSP页⾥。
当⽤户或某些原因发⽣异常。
(1、⽤户直接看到异常错误信息。
2、这个错误会导致服务器宕机)容错性,是指软件检测应⽤程序所运⾏的软件或硬件中发⽣的错误并从错误中恢复的能⼒,通常可以从系统的可靠性、可⽤性、可测性等⼏个⽅⾯来衡量。
单体地狱。
:只需⼀个应⽤,将所有功能都部署在⼀起,以减少部署节点和成本。
2 第⼀时期后阶段解决⽅案:1、分层开发(提⾼维护性)【解决容错性】2、MVC架构(Web应⽤程序的设计模式)3、服务器的分离部署特点:1、MVC分层开发(解决容错性问题)2、数据库和项⽬部署分离问题:随着⽤户的访问量持续增加,单台应⽤服务器已经⽆法满⾜需求。
解决⽅案:集群。
3 可能会产⽣的⼏个问题:1.1. ⾼可⽤“⾼可⽤性”(High Availability)通常来描述⼀个系统经过专门的设计,从⽽减少停⼯时间,⽽保持其服务的⾼度可⽤性。
(⼀直都能⽤)1.2. ⾼并发⾼并发(High Concurrency)是互联⽹分布式系统架构设计中必须考虑的因素之⼀,它通常是指,通过设计保证系统能够同时并⾏处理很多请求。
⾼并发相关常⽤的⼀些指标有响应时间(Response Time),吞吐量(Throughput),每秒查询率QPS(Query Per Second),并发⽤户数等。
基于QoS的Web集群系统设计与实现

基于QoS的Web集群系统设计与实现
郑志凌;郭李平;范明昊
【期刊名称】《军民两用技术与产品》
【年(卷),期】2016(000)020
【摘要】采用集群技术建立高性能Web服务器是当前的发展方向,本文设计并实现了一种基于QoS的Web集群系统,以资源优化为中心,基于QoS优化策略来区分不同类型的用户请求分配,实现了对客户端服务的有效区分,提供了QoS性能保证,能有效提高Web集群系统的整体性能.
【总页数】1页(P68)
【作者】郑志凌;郭李平;范明昊
【作者单位】湖南工业职业技术学院,长沙 410208;湖南工业职业技术学院,长沙410208;湖南工业职业技术学院,长沙 410208
【正文语种】中文
【相关文献】
1.基于请求分类和许可控制的Web集群QoS研究 [J], 杨武;李双庆;程代杰
2.Web集群中基于负载均衡的QoS-aware请求调度算法 [J], 韩仲海;张曦煌
3.Web集群中基于接纳控制的QoS-aware请求调度算法 [J], 张曦煌;韩仲海
4.WC-Stress:基于QoS的Web集群服务器性能评价工具 [J], 张连明;陈志刚;刘安丰
5.Web集群中基于控制论的分布式QoS量化控制 [J], 王晓川;金士尧;夏明波因版权原因,仅展示原文概要,查看原文内容请购买。
《亿级流量网站架构核心技术 跟开涛学搭建高可用高并发系统(博文》读书笔记模板

《亿级流量站架构核心技术》一书总结并梳理了亿级流量站高可用和高并发原则,通过实例详细介绍了 如何落地这些原则。本书分为四部分:概述、高可用原则、高并发原则、案例实战。从负载均衡、限流、降级、 隔离、超时与重试、回滚机制、压测与预案、缓存、池化、异步化、扩容、队列等多方面详细介绍了亿级流量站 的架构核心技术,让读者看后能快速运用到实践项目中。 不管是软件开发人员,还是运维人员,通过阅读 《亿级流量站架构核心技术》都能系统地学习实现亿级流量站的架构核心技术,并收获解决系统问题的思路和方 法。
10.1简介 10.2 HTTP缓存 10.3 HttpClient客户端缓存 10.4 Nginx HTTP缓存设置 10.5 Nginx代理层缓存 10.6一些经验 参考资料
11.1多级缓存介绍 11.2如何缓存数据 11.3分布式缓存与应用负载均衡 11.4热点数据与更新缓存 11.5更新缓存与原子性 11.6缓存崩溃与快速修复
17.1为什么需要统一服务 17.2整体架构 17.3一些架构思路和总结 17.4引入Nginx接入层 17.5前端业务逻辑后置 17.6前端接口服务器端聚合 17.7服务隔离
18.1 OpenResty简介 18.2基于OpenResty的常用架构模式 18.3如何使用OpenResty开发Web应用 18.4基于OpenResty的常用功能总结 18.5一些问题
读书笔记
试读的部分看完了,高并发高可用有些技术之前了解过,就是连贯不起来,这本书把各种要点都囊括了,读 到精彩处戛然而止,买了实体书。
目录分析
第1部分概述
1.1高并发原则 1.2高可用原则 1.3业务设计原则 1.4总结
3隔离术
2负载均衡与反向 代理
4限流详解
应用集群设计方案

应用集群设计方案一、整体目标。
咱搞这个应用集群啊,就像是盖一个超级公寓,要让好多不同的“小家庭”(应用程序)都能舒舒服服地住进去,还能相互串门(交互数据),而且整个公寓得特别坚固(稳定可靠),不怕地震(故障)啥的。
二、硬件基础。
1. 服务器选择。
咱先得挑好服务器,这就好比选公寓的楼体材料。
要是咱的应用集群规模不大,一开始可以选一些性价比高的普通服务器,就像那种经济适用房。
但如果以后要发展壮大,就得考虑那些性能超强的服务器,就像是豪华别墅。
比如说,对于一个刚开始的小电商应用集群,可能用一些四核CPU、16GB内存的服务器就够了。
2. 网络设备。
网络设备呢,就是公寓的管道系统。
咱得有好的交换机和路由器,就像大口径的水管子,能让数据“水流”快速地在服务器之间流动。
要选那种带宽足够、延迟低的设备。
比如说,千兆交换机就是个不错的基础选择,如果数据流量特别大,以后还可以升级到万兆的。
3. 存储设备。
存储设备就像是公寓的仓库。
对于一些经常读取但很少修改的数据,咱可以用固态硬盘(SSD),这就像一个快速取货的小仓库,速度特别快。
对于那些海量的、不太着急用的数据,像用户的历史订单记录啥的,可以用大容量的机械硬盘(HDD),就像大仓库一样能装很多东西。
三、软件架构。
1. 操作系统。
操作系统就像是公寓的物业管理规则。
Linux是个很不错的选择,因为它稳定又开源。
就像一个很民主、管理很合理的物业。
CentOS或者Ubuntu都是很流行的版本,CentOS比较适合企业级的稳定运行,Ubuntu则在开发环境下很友好。
2. 集群管理软件。
这就像是公寓的管理员团队。
Kubernetes(K8s)是现在很火的一个。
它能把咱的服务器资源管理得井井有条,就像管理员把公寓的房间分配得妥妥当当。
它可以轻松地部署、扩展和管理容器化的应用。
比如说,咱有个新的应用要上线,K8s可以很快地给它安排一个合适的“房间”(服务器资源)。
3. 应用部署。
大数据平台参数-技术指标要求
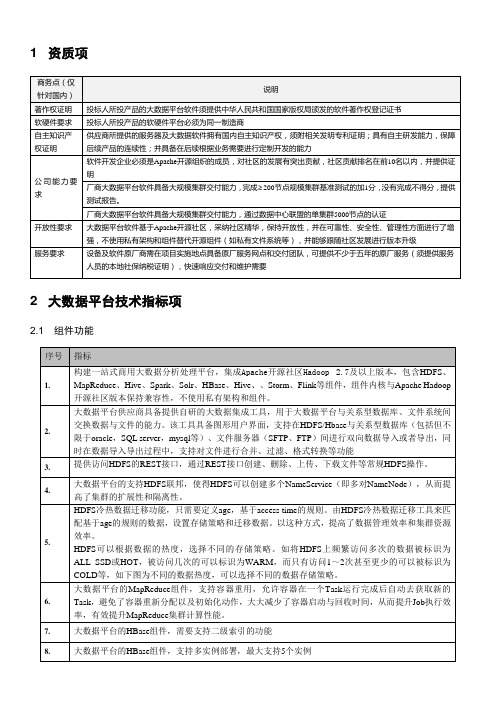
大数据平台的Spark组件,支持多租户并行执行,租户任务提交到不同的队列执行,租户间资源隔离
16.
提供基于Hadoop的SQL引擎,支持多租户,使用MPP架构,实现SQL的解析、计划、优化、执行,数据的并行查询,支持JDBC、ODBC标准接口,兼容Hive的ORC文件存储格式,兼容标准SQL 2003语法,以Hive-Test-benchmark测试集上的64个SQL语句为准和tpc-ds测试集上的99个SQL语句为准。
3.
提供访问HDFS的REST接口,通过REST接口创建、删除、上传、下载文件等常规HDFS操作。
4.
大数据平台的支持HDFS联邦,使得HDFS可以创建多个NameService(即多对NameNode),从而提高了集群的扩展性和隔离性。
5.
HDFS冷热数据迁移功能,只需要定义age,基于access time的规则。由HDFS冷热数据迁移工具来匹配基于age的规则的数据,设置存储策略和迁移数据。以这种方式,提高了数据管理效率和集群资源效率。
11.
大数据平台的HBase组件,支持聚簇表/聚簇索引框架的功能
12.
大数据平台提供小文件存储方案,支持海量图片、视频、文档等KB级的数据高并发读写。
13.
大数据平台的Spark组件支持2.0及以上版本
14.
大数据平台的Spark SQL兼容部分Hive语法(以Hive-Test-benchmark测试集上的64个SQL语句为准)和标准SQL语法(以tpc-ds测试集上的99个SQL语句为准)。
提供统一的客户端工具。
22.
大数据平台的流处理组件,集成storm和sparkstreaming,Flink,用户可根据业务需要自主选择
基于分布式集群技术的SSM购物商城系统设计

基于分布式集群技术的SSM购物商城系统设计童二宝; 彭战军【期刊名称】《《软件》》【年(卷),期】2019(040)008【总页数】4页(P123-126)【关键词】J2EE; 分布式集群; SSM; Redis; 高并发【作者】童二宝; 彭战军【作者单位】杭州电子科技大学电子信息学院杭州 310018【正文语种】中文【中图分类】TP391随着生活水平的提高,网上购物逐渐成为当下人们追求潮流的方式之一。
购物大潮导致的直接问题就是购物网站系统的崩溃,这是由于服务器在高并发情况下承受的负载压力过大,导致出现宕机现象。
在如此环境下,设计可以承受高并发的电商平台就显得十分重要。
J2EE(Java2 Platform Enterprise Edition)[1]是SUN公司使用Java技术开发的一套企业级应用规范,它是为了简化企业应用开发、管理和部署。
J2EE采用了MVC分层设计模式[2],降低了组件之间的耦合度,大大减轻了客户端和服务端的压力。
MVC包括了三大层:Model层(模型层)、View层(视图层)、Controller层(控制层)。
该系统以当前较为流行的轻量级SSM[3-5]框架(SpringMVC、Spring和MyBatis)为核心框架,摒弃了原始的SSH框架(Struts2、Spring和Hibernate),提高了开发效率,简化了程序开发步骤。
在MVC基础上,再添加服务层(Service层)以及数据访问层(Dao层),Controller层负责接收和处理来自View层的请求转发,Service层负责业务逻辑处理,Dao层负责与数据库交互,实现持久化操作。
将SSM框架与目前火热的分布式集群技术整合在一起,可以将各个功能模块独立出来,降低模块之间的耦合性,方便进行分布式部署,就有望设计出一个可使用的大型网上购物平台。
采用分布式系统架构的aiBuy商城系统的模块划分主要由以下几部分组成:后台管理模块、前台管理模块、订单生成模块、商品搜索模块、登录(注册)模块以及订单支付模块等。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
4. DNS负载均衡
DNS(Domain Name System)负责域名解析的服务,域名url实际上是服务器的别名,实际映射是一个IP地址,解析过程,就是DNS完成域名到IP的映射。而一个域名是可以配置成对应多个IP的。因此,DNS也就可以作为负载均衡服务。
如果使用PHP代码来实现这个功能,方式如下:
这个重定向非常容易实现,并且可以自定义各种策略。但是,它在大规模访问量下,性能不佳。而且,给用户的体验也不好,实际请求发生重定向,增加了网络延时。
2. 反向代理负载均衡
反向代பைடு நூலகம்服务的核心工作主要是转发HTTP请求,扮演了浏览器端和后台Web服务器中转的角色。因为它工作在HTTP层(应用层),也就是网络七层结构中的第七层,因此也被称为“七层负载均衡”。可以做反向代理的软件很多,比较常见的一种是Nginx。
这种负载均衡策略,配置简单,性能极佳。但是,不能自由定义规则,而且,变更被映射的IP或者机器故障时很麻烦,还存在DNS生效延迟的问题。
5. DNS/GSLB负载均衡
我们常用的CDN(Content Delivery Network,内容分发网络)实现方式,其实就是在同一个域名映射为多IP的基础上更进一步,通过GSLB(Global Server Load Balance,全局负载均衡)按照指定规则映射域名的IP。一般情况下都是按照地理位置,将离用户近的IP返回给用户,减少网络传输中的路由节点之间的跳跃消耗。
3. IP负载均衡
IP负载均衡服务是工作在网络层(修改IP)和传输层(修改端口,第四层),比起工作在应用层(第七层)性能要高出非常多。原理是,他是对IP层的数据包的IP地址和端口信息进行修改,达到负载均衡的目的。这种方式,也被称为“四层负载均衡”。常见的负载均衡方式,是LVS(Linux Virtual Server,Linux虚拟服务),通过IPVS(IP Virtual Server,IP虚拟服务)来实现。
图中的“向上寻找”,实际过程是LDNS(Local DNS)先向根域名服务(Root Name Server)获取到顶级根的Name Server(例如.com的),然后得到指定域名的授权DNS,然后再获得实际服务器IP。
CDN在Web系统中,一般情况下是用来解决大小较大的静态资源(html/Js/Css/图片等)的加载问题,让这些比较依赖网络下载的内容,尽可能离用户更近,提升用户体验。
例如,我访问了一张上的图片(腾讯的自建CDN,不使用域名的原因是防止http请求的时候,带上了多余的cookie信息),我获得的IP是183.60.217.90。
这种方式,和前面的DNS负载均衡一样,不仅性能极佳,而且支持配置多种策略。但是,搭建和维护成本非常高。互联网一线公司,会自建CDN服务,中小型公司一般使用第三方提供的CDN。
在负载均衡服务器收到客户端的IP包的时候,会修改IP包的目标IP地址或端口,然后原封不动地投递到内部网络中,数据包会流入到实际Web服务器。实际服务器处理完成后,又会将数据包投递回给负载均衡服务器,它再修改目标IP地址为用户IP地址,最终回到客户端。
上述的方式叫LVS-NAT,除此之外,还有LVS-RD(直接路由),LVS-TUN(IP隧道),三者之间都属于LVS的方式,但是有一定的区别,篇幅问题,不赘叙。
Web系统的缓存机制的建立和优化
刚刚我们讲完了Web系统的外部网络环境,现在我们开始关注我们Web系统自身的性能问题。我们的Web站点随着访问量的上升,会遇到很多的挑战,解决这些问题不仅仅是扩容机器这么简单,建立和使用合适的缓存机制才是根本。
最开始,我们的Web系统架构可能是这样的,每个环节,都可能只有1台机器。
1.配置反向代理的转发规则,让同一个用户的请求一定落到同一台机器上(通过分析cookie),复杂的转发规则将会消耗更多的CPU,也增加了代理服务器的负担。
2.将session这类的信息,专门用某个独立服务来存储,例如redis/memchache,这个方案是比较推荐的。
反向代理服务,也是可以开启缓存的,如果开启了,会增加反向代理的负担,需要谨慎使用。这种负载均衡策略实现和部署非常简单,而且性能表现也比较好。但是,它有“单点故障”的问题,如果挂了,会带来很多的麻烦。而且,到了后期Web服务器继续增加,它本身可能成为系统的瓶颈。
亿级Web系统分布式集群
当一个Web系统从日访问量10万逐步增长到1000万,甚至超过1亿的过程中,Web系统承受的压力会越来越大,在这个过程中,我们会遇到很多的问题。为了解决这些性能压力带来问题,我们需要在Web系统架构层面搭建多个层次的缓存机制。在不同的压力阶段,我们会遇到不同的问题,通过搭建不同的服务和架构来解决。
Web负载均衡
Web负载均衡(Load Balancing),简单地说就是给我们的服务器集群分配“工作任务”,而采用恰当的分配方式,对于保护处于后端的Web服务器来说,非常重要。
负载均衡的策略有很多,我们从简单的讲起哈。
1. HTTP重定向
当用户发来请求的时候,Web服务器通过修改HTTP响应头中的Location标记来返回一个新的url,然后浏览器再继续请求这个新url,实际上就是页面重定向。通过重定向,来达到“负载均衡”的目标。例如,我们在下载PHP源码包的时候,点击下载链接时,为了解决不同国家和地域下载速度的问题,它会返回一个离我们近的下载地址。重定向的HTTP返回码是302,如下图:
Nginx是一种非常灵活的反向代理软件,可以自由定制化转发策略,分配服务器流量的权重等。反向代理中,常见的一个问题,就是Web服务器存储的session数据,因为一般负载均衡的策略都是随机分配请求的。同一个登录用户的请求,无法保证一定分配到相同的Web机器上,会导致无法找到session的问题。
解决方案主要有两种: