Linux连接跟踪源码分析报告
linux trace 解读

linux trace 解读
LinuxTrace解读是关于如何使用LinuxTrace工具进行系统跟踪和分析的指南。
本文将介绍LinuxTrace工具的基本知识和用法,包括如何使用 ftrace、perf 和 SystemTap 等工具进行系统跟踪和分析。
首先,本文将介绍 ftrace 工具,它是 Linux 内核提供的一个跟踪框架,可以用于跟踪内核函数、进程和系统调用等信息。
本文将详细介绍 ftrace 的用法和其它相关工具。
其次,本文将介绍 perf 工具,它是一个基于硬件性能计数器的工具,可以用于跟踪系统的硬件性能,如 CPU 使用率、缓存命中率和内存带宽等信息。
本文将详细介绍 perf 工具的用法和其它相关工具。
最后,本文将介绍 SystemTap 工具,它是一个基于内核动态追踪技术的工具,可以用于跟踪内核函数、系统调用和进程等信息。
本文将详细介绍 SystemTap 工具的用法和其它相关工具。
通过本文的介绍,读者将能够了解 Linux Trace 工具的基本知识和用法,掌握如何使用 ftrace、perf 和 SystemTap 等工具进行系统跟踪和分析,为系统调优和性能优化提供有力的支持。
- 1 -。
Jflash-s3c2410(linux 版本)源码分析
Jflash-s3c2410(linux 版本)源码分析最近在远峰公司买了arm9的板子,S3C2410,ARM920T ,没有Nor flash ,Nand Flash 是64M ,SDRAM 是K9f1208,本人对linux 的热情大于windows ,所以想在linux 下做开发,可是远峰公司只给我YFSJF.exe 文件,而且没有源代码,每次在linux 下编译好了后还得切换到windows 下烧录,很是麻烦,于是在网上找了很多Jflash 类似的程序,不过不同的烧录针对不同的硬件平台,Jflash 是跟硬件紧密结合的,比如有的针对Nor Flash ,有的针对Nand Flash 的,不同内核有不同的Jflash ,而且相同的内核也有不同的版本,因为Jtag 的原理图不同,就只能有相对应的Jflash ,程序中的定义要与pc 机并口与Jtag 接口的对应相一致。
在进入源码分析之前要介绍一些预备的知识,有助于理解源代码,毕竟这个程序和硬件联系很紧密的。
首先介绍一下对PC 并口做一些简要的介绍一、PC 标准配备并行口介绍本文主要介绍计算机的标准配备并行端口即25针的母接头端口的应用,在此基础上可以运用相同的原理使用其它模式的并行端口。
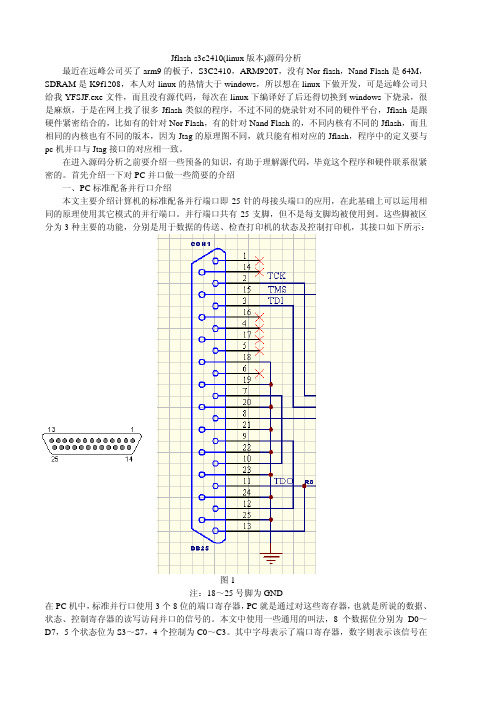
并行端口共有25支脚,但不是每支脚均被使用到。
这些脚被区图1分为3种主要的功能,分别是用于数据的传送、检查打印机的状态及控制打印机,其接口如下所示:注:18~脚为GND在PC 机中,标准并行口使用3个8位对这些寄存器,也就是所说的数据、25号的端口寄存器,PC 就是通过状态、控制寄存器的读写访问并口的信号的。
本文中使用一些通用的叫法,8个数据位分别为D0~D7,5个状态位为S3~S7,4个控制为C0~C3。
其中字母表示了端口寄存器,数字则表示该信号在寄存器中的位。
数据寄存器据端口或称数据寄存器(D0~D7)保存了写入数据输出端口的一字节信息。
数据端口可以写入数数据寄存器(即数据输出端口)可擦写、基地址数据,也可以读出数据(即可擦写);写进去的当然是我们希望从数据端口引脚输出的数据,不过读进来的也只是我们上次写进去的数据,或是原来保留在里面的数据,并不是从端口引脚输入PC 的数据。
看Linux0.11源码分析书籍,补充知识

看Linux0.11源码分析书籍,补充知识在看本书的时候, 很多CPU或汇编或操作系统的知识太⽋缺了, 所以补充看了⼀下 x86汇编语⾔从实模式到保护模式⾥⾯⽤了bochs来跟踪调试汇编代码.但是书⾥⽤了 vhd来承载引导程序, 其实跟IMG镜像倒是区别没那么⼤.作者提供了⼀个写⼊VHD的⼩⼯具, ⽽VHD的⽣成, 其实更简单, 就是在 WINDOWS系统⾥⾯, --- 设备管理器 ---磁盘管理创建⼀个固定⼤⼩的VHD就可以了.只不过, bochs.bxrc配置⽂件要跟着改⼀下那个写⼊的⼩程序, ⾥⾯有提⽰的,按照显⽰的⼤⼩改⼀下这个就可以了(windows下要管理员启动才⾏, )同时, 可以把需要的⽂件都拷贝出来, 在⾃定义的路径下去执⾏run.bat,也不是不可以(注意⼀些⽂件的路径就好)例如:可以直接在 bochsrc.bxrc上右键, RUN即可.下⾯是VHD的简单介绍, 可以看出来, 跟img映像,只是多了尾部信息⽽已. (这么说不太准确, 就这么理解就完事⼉了,反正只是硬盘,⽤扇区来读, ⾄于内容是什么, 只有OS才关⼼)参考资料:《x86汇编语⾔-从实模式到保护模式.pdf》《Virtual Hard Disk Format Spec_10_18_06.doc》《x86汇编语⾔》中 “第4章虚拟机的安装和使⽤”,通过虚拟机创建虚拟硬盘,然后⽤⼯具修改虚拟硬盘,写⼊程序,最后启动虚拟机观察运⾏结果。
该⽅法缺点是不便调试,推荐使⽤Bochs,⽅便调试。
Bochs需要加载Image格式镜像。
如下是虚拟硬盘VHD格式(固定⼤⼩)和Image镜像格式的对⽐。
VHD格式只是多了⼀个Footer fileds:Image格式似乎没什么特殊的,只是要求第⼀个扇区最后的两个字节必须是0x55、0xAA。
Footer fileds在规范中有详细说明,其中开头8个字节为Cookie字段,固定为字符串“conectix”。
linux_kernel_fuse_源码剖析
FUSE源码剖析1. 前言本文是对FUSE-2.9.2源码的学习总结。
FUSE代码在用户空间和内核空间都有运行,为了突出重点,先简要描述了在基于FUSE的用户空间文件系统中执行write操作的一般流程,接下来介绍了重要的数据结构,最后以FUSE的运行过程为线索,剖析FUSE程序运行过程的3个关键步骤:1.FUSE模块加载2.mount和open过程3.对文件write。
对于虚拟文件系统和设备驱动的相关概念本文仅作简要说明。
需要说明的是,由于内核的复杂性及个人能力的有限,本文省略了包括内核同步,异常检查在内的诸多内容,希望可以突出重点。
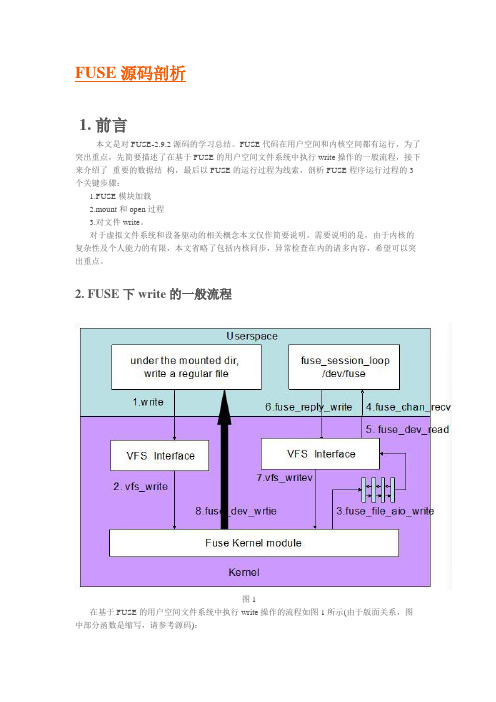
2. FUSE下write的一般流程图1在基于FUSE的用户空间文件系统中执行write操作的流程如图1所示(由于版面关系,图中部分函数是缩写,请参考源码):1.客户端在mount目录下面,对一个regular file调用write, 这一步是在用户空间执行2.write内部会调用虚拟文件系统提供的一致性接口vfs_write3.根据FUSE模块注册的file_operations信息,vfs_write会调用fuse_file_aio_write,将写请求放入fuse connection的request pending queue, 随后进入睡眠等待应用程序reply4.用户空间的libfuse有一个守护进程通过函数fuse_session_loop轮询杂项设备/dev/fuse, 一旦request queue有请求即通过fuse_kern_chan_receive接收5.fuse_kern_chan_receive通过read读取request queue中的内容,read系统调用实际上是调用的设备驱动接口fuse_dev_read6.在用户空间读取并分析数据,执行用户定义的write操作,将状态通过fuse_reply_write返回给kernel7.fuse_reply_write调用VFS提供的一致性接口vfs_write8.vfs_write最终调用fuse_dev_write将执行结果返回给第3步中等待在waitq的进程,此进程得到reply 后,write返回3. 数据结构本节主要介绍了FUSE中比较重要的数据结构,需要说明的是图示中只列出了与叙述相关的数据成员,完整的数据结构细节请参考源码。
深入分析Linux内核源码
2.4.1 分页机构如前所述,分页是将程序分成若干相同大小的页,每页4K个字节。
如果不允许分页(CR0的最高位置0),那么经过段机制转化而来的32位线性地址就是物理地址。
但如果允许分页(CR0的最高位置1),就要将32位线性地址通过一个两级表格结构转化成物理地址。
1. 两级页表结构为什么采用两级页表结构呢?在80386中页表共含1M个表项,每个表项占4个字节。
如果把所有的页表项存储在一个表中,则该表最大将占4M字节连续的物理存储空间。
为避免使页表占有如此巨额的物理存储器资源,故对页表采用了两级表的结构,而且对线性地址的高20位的线性—物理地址转化也分为两部完成,每一步各使用其中的10位。
两级表结构的第一级称为页目录,存储在一个4K字节的页面中。
页目录表共有1K个表项,每个表项为4个字节,并指向第二级表。
线性地址的最高10位(即位31~位32)用来产生第一级的索引,由索引得到的表项中,指定并选择了1K个二级表中的一个表。
两级表结构的第二级称为页表,也刚好存储在一个4K字节的页面中,包含1K个字节的表项,每个表项包含一个页的物理基地址。
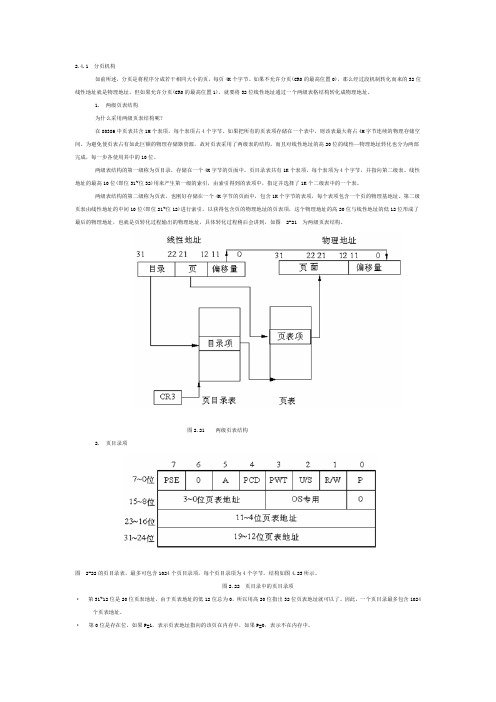
第二级页表由线性地址的中间10位(即位21~位12)进行索引,以获得包含页的物理地址的页表项,这个物理地址的高20位与线性地址的低12位形成了最后的物理地址,也就是页转化过程输出的物理地址,具体转化过程稍后会讲到,如图 2-21 为两级页表结构。
图2.21 两级页表结构2. 页目录项图 2-22的页目录表,最多可包含1024个页目录项,每个页目录项为4个字节,结构如图4.23所示。
图2.22 页目录中的页目录项·第31~12位是20位页表地址,由于页表地址的低12位总为0,所以用高20位指出32位页表地址就可以了。
因此,一个页目录最多包含1024个页表地址。
·第0位是存在位,如果P=1,表示页表地址指向的该页在内存中,如果P=0,表示不在内存中。
·第1位是读/写位,第2位是用户/管理员位,这两位为页目录项提供硬件保护。
linux调度器源码分析-运行(四)

linux调度器源码分析-运⾏(四)本⽂为原创,转载请注明:引⾔ 之前的⽂章已经将调度器的数据结构、初始化、加⼊进程都进⾏了分析,这篇⽂章将主要说明调度器是如何在程序稳定运⾏的情况下进⾏进程调度的。
系统定时器 因为我们主要讲解的是调度器,⽽会涉及到⼀些系统定时器的知识,这⾥我们简单讲解⼀下内核中定时器是如何组织,⼜是如何通过通过定时器实现了调度器的间隔调度。
⾸先我们先看⼀下内核定时器的框架 在内核中,会使⽤strut clock_event_device结构描述硬件上的定时器,每个硬件定时器都有其⾃⼰的精度,会根据精度每隔⼀段时间产⽣⼀个时钟中断。
⽽系统会让每个CPU使⽤⼀个tick_device描述系统当前使⽤的硬件定时器(因为每个CPU都有其⾃⼰的运⾏队列),通过tick_device所使⽤的硬件时钟中断进⾏时钟滴答(jiffies)的累加(只会有⼀个CPU负责这件事),并且在中断中也会调⽤调度器,⽽我们在驱动中常⽤的低精度定时器就是通过判断jiffies实现的。
⽽当使⽤⾼精度定时器(hrtimer)时,情况则不⼀样,hrtimer会⽣成⼀个普通的⾼精度定时器,在这个定时器中回调函数是调度器,其设置的间隔时间同时钟滴答⼀样。
所以在系统中,每⼀次时钟滴答都会使调度器判断⼀次是否需要进⾏调度。
时钟中断 当时钟发⽣中断时,⾸先会调⽤的是tick_handle_periodic()函数,在此函数中⼜主要执⾏tick_periodic()函数进⾏操作。
我们先看⼀下tick_handle_periodic()函数: 1void tick_handle_periodic(struct clock_event_device *dev)2 {3/* 获取当前CPU */4int cpu = smp_processor_id();5/* 获取下次时钟中断执⾏时间 */6 ktime_t next = dev->next_event;78 tick_periodic(cpu);910/* 如果是周期触发模式,直接返回 */11if (dev->mode != CLOCK_EVT_MODE_ONESHOT)12return;1314/* 为了防⽌当该函数被调⽤时,clock_event_device中的计时实际上已经经过了不⽌⼀个tick周期,这时候,tick_periodic可能被多次调⽤,使得jiffies和时间可以被正确地更新。
Linux下Libpcap源码分析和包过滤机制
libpcap是unix/Linux平台下的网络数据包捕获函数包,大多数网络监控软件都以它为基础。
libpcap可以在绝大多数类unix平台下工作,本文分析了libpcap在Linux下的源代码实现,其中重点是Linux的底层包捕获机制和过滤器设置方式,同时也简要的讨论了libpcap使用的包过滤机制BPF。
网络监控绝大多数的现代操作系统都提供了对底层网络数据包捕获的机制,在捕获机制之上可以建立网络监控(Network Monitoring)应用软件。
网络监控也常简称为sniffer,其最初的目的在于对网络通信情况进行监控,以对网络的一些异常情况进行调试处理。
但随着互连网的快速普及和网络攻击行为的频繁出现,保护网络的运行安全也成为监控软件的另一个重要目的。
例如,网络监控在路由器,防火墙、入侵检查等方面使用也很广泛。
除此而外,它也是一种比较有效的黑客手段,例如,美国政府安全部门的"肉食动物"计划。
包捕获机制从广义的角度上看,一个包捕获机制包含三个主要部分:最底层是针对特定操作系统的包捕获机制,最高层是针对用户程序的接口,第三部分是包过滤机制。
不同的操作系统实现的底层包捕获机制可能是不一样的,但从形式上看大同小异。
数据包常规的传输路径依次为网卡、设备驱动层、数据链路层、IP层、传输层、最后到达应用程序。
而包捕获机制是在数据链路层增加一个旁路处理,对发送和接收到的数据包做过滤/缓冲等相关处理,最后直接传递到应用程序。
值得注意的是,包捕获机制并不影响操作系统对数据包的网络栈处理。
对用户程序而言,包捕获机制提供了一个统一的接口,使用户程序只需要简单的调用若干函数就能获得所期望的数据包。
这样一来,针对特定操作系统的捕获机制对用户透明,使用户程序有比较好的可移植性。
包过滤机制是对所捕获到的数据包根据用户的要求进行筛选,最终只把满足过滤条件的数据包传递给用户程序。
libpcap应用程序框架libpcap提供了系统独立的用户级别网络数据包捕获接口,并充分考虑到应用程序的可移植性。
Linux网络地址转换NAT源码分析
Network Address Translation地址转换用来改变源/目的地址/端口,是netfilter的一部分,也是通过hook 点上注册相应的结构来工作Nat注册的hook点和conntrack相同,只是优先级不同,数据包进入netfilter之后先经过conntrack,再经过nat。
而在数据包离开netfilter之前先经过nat,再经过conntrack。
1 nat模块的初始化1.1数据结构ip_nat_standalone.c在ip_conntrack结构中有为nat定义的一个nat结构,为什么把这个结构放在ip_conntrack里呢。
简单的说,对于非初始化连接的数据包,即后续的数据包,一旦确定它属于某个连接,则可以直接利用连接状态里的nat信息来进行地址转换;而对于初始数据包,必须在nat表里查找相应的规则,确定了地址转换的内容后,将这些信息放到连接跟踪结构的nat参量里面,供后续的数据包使用。
#ifdef CONFIG_IP_NF_NAT_NEEDEDstruct {struct ip_nat_info info;union ip_conntrack_nat_help help;#if defined(CONFIG_IP_NF_TARGET_MASQUERADE) || \ defined(CONFIG_IP_NF_TARGET_MASQUERADE_MODULE) int masq_index;#endif#if defined(CONFIG_IP_NF_RTSP) ||defined(CONFIG_IP_NF_RTSP_MODULE)struct ip_nat_rtsp_info rtsp_info;#endif} nat;#endif /* CONFIG_IP_NF_NAT_NEEDED */#if defined(CONFIG_IP_NF_CONNTRACK_MARK)unsigned long mark;#endif它包括两个参数,struct ip_nat_info和union ip_conntrack_nat_help,后一个暂时没什么用,只看前一个struct ip_nat_info{/* 用来检测该连接是否已经进行过某类nat初始化了,在新的内核中该参数被去掉了,当然,有其它方法来实现它的作用。
linux调度器源码分析-概述(一)
linux调度器源码分析-概述(⼀)引⾔ 调度器作为操作系统的核⼼部件,具有⾮常重要的意义,其随着linux内核的更新也不断进⾏着更新。
本系列⽂章通过linux-3.18.3源码进⾏调度器的学习和分析,⼀步⼀步将linux现有的调度器原原本本的展现出来。
此篇⽂章作为开篇,主要介绍调度器的原理及重要数据结构。
调度器介绍 随着时代的发展,linux也从其初始版本稳步发展到今天,从2.4的⾮抢占内核发展到今天的可抢占内核,调度器⽆论从代码结构还是设计思想上也都发⽣了翻天覆地的变化,其普通进程的调度算法也从O(1)到现在的CFS,⼀个好的调度算法应当考虑以下⼏个⽅⾯:公平:保证每个进程得到合理的CPU时间。
⾼效:使CPU保持忙碌状态,即总是有进程在CPU上运⾏。
响应时间:使交互⽤户的响应时间尽可能短。
周转时间:使批处理⽤户等待输出的时间尽可能短。
吞吐量:使单位时间内处理的进程数量尽可能多。
负载均衡:在多核多处理器系统中提供更⾼的性能 ⽽整个调度系统⾄少包含两种调度算法,是分别针对实时进程和普通进程,所以在整个linux内核中,实时进程和普通进程是并存的,但它们使⽤的调度算法并不相同,普通进程使⽤的是CFS调度算法(红⿊树调度)。
之后会介绍调度器是怎么调度这两种进程。
进程 上⼀节已经说明,在linux中,进程主要分为两种,⼀种为实时进程,⼀种为普通进程实时进程:对系统的响应时间要求很⾼,它们需要短的响应时间,并且这个时间的变化⾮常⼩,典型的实时进程有⾳乐播放器,视频播放器等。
普通进程:包括交互进程和⾮交互进程,交互进程如⽂本编辑器,它会不断的休眠,⼜不断地通过⿏标键盘进⾏唤醒,⽽⾮交互进程就如后台维护进程,他们对IO,响应时间没有很⾼的要求,⽐如编译器。
它们在linux内核运⾏时是共存的,实时进程的优先级为0~99,实时进程优先级不会在运⾏期间改变(静态优先级),⽽普通进程的优先级为100~139,普通进程的优先级会在内核运⾏期间进⾏相应的改变(动态优先级)。
Linux KVM虚拟化源代码分析文档
KVM虚拟机源代码分析1,KVM结构及工作原理1.1K VM结构KVM基本结构有两部分组成。
一个是KVM Driver ,已经成为Linux 内核的一个模块。
负责虚拟机的创建,虚拟内存的分配,虚拟CPU寄存器的读写以及虚拟CPU的运行等。
另外一个是稍微修改过的Qemu,用于模拟PC硬件的用户空间组件,提供I/O设备模型以及访问外设的途径。
图1 KVM基本结构KVM基本结构如图1所示。
其中KVM加入到标准的Linux内核中,被组织成Linux中标准的字符设备(/dev/kvm)。
Qemu通KVM提供的LibKvm应用程序接口,通过ioctl系统调用创建和运行虚拟机。
KVM Driver使得整个Linux成为一个虚拟机监控器。
并且在原有的Linux两种执行模式(内核模式和用户模式)的基础上,新增加了客户模式,客户模式拥有自己的内核模式和用户模式。
在虚拟机运行下,三种模式的分工如下:客户模式:执行非I/O的客户代码。
虚拟机运行在客户模式下。
内核模式:实现到客户模式的切换。
处理因为I/O或者其它指令引起的从客户模式的退出。
KVM Driver工作在这种模式下。
用户模式:代表客户执行I/O指令Qemu运行在这种模式下。
在KVM模型中,每一个Guest OS 都作为一个标准的Linux进程,可以使用Linux的进程管理指令管理。
在图1中./dev/kvm在内核中创建的标准字符设备,通过ioctl系统调用来访问内核虚拟机,进行虚拟机的创建和初始化;kvm_vm fd是创建的指向特定虚拟机实例的文件描述符,通过这个文件描述符对特定虚拟机进行访问控制;kvm_vcpu fd指向为虚拟机创建的虚拟处理器的文件描述符,通过该描述符使用ioctl系统调用设置和调度虚拟处理器的运行。
1.2K VM工作原理KVM的基本工作原理:用户模式的Qemu利用接口libkvm通过ioctl系统调用进入内核模式。
KVM Driver为虚拟机创建虚拟内存和虚拟CPU后执行VMLAUCH指令进入客户模式。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
. . . Linux连接跟踪源码分析 IP Connection tracking 连接跟踪用来跟踪和记录连接状态,是netfilter的一部份,也是通过在hook点上注册相应的结构来工作的。
无论是发送,接收,还是转发的数据包,都要经过两个conntrack模块。 第一个conntrack点的优先级是最高的,所有数据包进入netfilter后都会首先被它处理,其作用是创建ip_conntrack结构。而最后一个conntrack的优先级最低,总是在数据包离开netfilter之前做最后的处理,它的作用是将该数据包的连接跟踪结构添加到系统的连接状态表中
1. ip_conntarck结构 ip_conntrack.h 内核中用一个ip_conntrack结构来描述一个连接的状态 struct ip_conntrack { /* nf_conntrack结构定义于include/linux/skbuff.h,Line89,其中包括一个计数器use和一个destroy函数。计数器use对本连接记录的公开引用次数进行计数 */ struct nf_conntrack ct_general;
/*其中的IP_CT_DIR_MAX是一个枚举类型ip_conntrack_dir(位于include/linux/netfilter_ipv4/ip_conntrack_tuple.h,Line65)的第3个成员,从这个结构实例在源码中的使用看来,实际上这是定义了两个tuple多元组的hash表项tuplehash[IP_CT_DIR_ORIGINAL/0]和tuplehash[IP_CT_DIR_REPLY/1],利用两个不同方向的tuple定位一个连接,同时也可以方便地对ORIGINAL以及REPLY两个方向进行追溯*/ struct ip_conntrack_tuple_hash tuplehash[IP_CT_DIR_MAX];
/* 这是一个位图,是一个状态域。在实际的使用中,它通常与一个枚举类型ip_conntrack_status(位于include/linux/netfilter_ipv4/ip_conntrack.h,Line33)进行位运算来判断连接的状态。其中主要的状态包括: IPS_EXPECTED(_BIT),表示一个预期的连接 IPS_SEEN_REPLY(_BIT),表示一个双向的连接 . . .
IPS_ASSURED(_BIT),表示这个连接即使发生超时也不能提早被删除 IPS_CONFIRMED(_BIT),表示这个连接已经被确认(初始包已经发出) */ unsigned long status;
/*其类型timer_list位于include/linux/timer.h,Line11,其核心是一个处理函数。这个成员表示当发生连接超时时,将调用此处理函数*/ struct timer_list timeout;
/*所谓“预期的连接”的链表,其中存放的是我们所期望的其它相关连接*/ struct list_head sibling_list;
/*目前的预期连接数量*/ unsigned int expecting;
/*结构ip_conntrack_expect位于ip_conntrack.h,这个结构用于将一个预期的连接分配给现有的连接,也就是说本连接是这个master的一个预期连接*/ struct ip_conntrack_expect *master;
/* helper模块。这个结构定义于ip_conntrack_helper.h,这个模块提供了一个可以用于扩展Conntrack功能的接口。经过连接跟踪HOOK的每个数据报都将被发给每个已经注册的helper模块(注册以及卸载函数分别为ip_conntrack_helper_register()以及ip_conntrack_helper_unregister(),分别位于ip_conntrack_core.c)。这样我们就可以进行一些动态的连接管理了*/ struct ip_conntrack_helper *helper;
/*一系列的nf_ct_info类型(定义于include/linux/skbuff.h ,Line92,实际上就是nf_conntrack结构)的结构,每个结构对应于某种状态的连接。这一系列的结构会被sk_buff结构的nfct指针所引用,描述了所有与此连接有关系的数据报。其状态由枚举类型ip_conntrack_info定义(位于include/linux/netfilter_ipv4/ip_conntrack.h,Line12)共有5个成员: IP_CT_ESTABLISHED: 数据报属于已经完全建立的连接 IP_CT_RELATED: 数据报属于一个新的连接,但此连接与一个现有连接相关(预期连接);或者是ICMP错误 IP_CT_NEW: 数据报属于一个新的连接 IP_CT_IS_REPLY: 数据报属于一个连接的回复 IP_CT_NUMBER: 不同IP_CT类型的数量,这里为7,NEW仅存于一个方向上 */ struct nf_ct_info infos[IP_CT_NUMBER];
/* 为其他模块保留的部分 */ union ip_conntrack_proto proto;
union ip_conntrack_help help; . . .
#ifdef CONFIG_IP_NF_NAT_NEEDED struct { struct ip_nat_info info; union ip_conntrack_nat_help help; #if defined(CONFIG_IP_NF_TARGET_MASQUERADE) || \ defined(CONFIG_IP_NF_TARGET_MASQUERADE_MODULE) int masq_index; #endif #if defined(CONFIG_IP_NF_RTSP) || defined(CONFIG_IP_NF_RTSP_MODULE) struct ip_nat_rtsp_info rtsp_info; #endif } nat; #endif /* CONFIG_IP_NF_NAT_NEEDED */
#if defined(CONFIG_IP_NF_CONNTRACK_MARK) unsigned long mark; #endif
}; struct ip_conntrack_tuple_hash结构描述链表中的节点,这个数组包含“初始”和“应答”两个成员(tuplehash[IP_CT_DIR_ORIGINAL]和tuplehash[IP_CT_DIR_REPLY]),所以,当一个数据包进入连接跟踪模块后,先根据这个数据包的套接字对转换成一个“初始的”tuple,赋值给tuplehash[IP_CT_DIR_ORIGINAL],然后对这个数据包“取反”,计算出“应答”的tuple,赋值给tuplehash[IP_CT_DIR_REPLY],这样,一条完整的连接已经跃然纸上了。 enum ip_conntrack_dir { IP_CT_DIR_ORIGINAL, IP_CT_DIR_REPLY, IP_CT_DIR_MAX };
2. 连接跟踪表 Netfilter用“来源地址/来源端口+目的地址/目的端口”,即一个“tuple”,来唯一标识一个连接。用一张连接跟踪表来描述所有的连接状态,该表用了hash算法。
hash表用一个全局指针来描述(ip_conntrack_core.c) . . .
struct list_head *ip_conntrack_hash; 表的大小,即hash节点的个数由ip_conntrack_htable_size全局变量决定,默认是根据内存计算出来的。而每个hash节点又是一条链表的首部,所以,连接跟踪表就是一个由ip_conntrack_htable_size 条链表构成的一个hash表,整个连接跟踪表大小使用全局变量ip_conntrack_max描述,与hash表的关系是ip_conntrack_max = 8 * ip_conntrack_htable_size。
链表的每个节点,都是一个ip_conntrack_tuple_hash结构: struct ip_conntrack_tuple_hash { /* 用来组织链表 */ struct list_head list; /* 用来描述一个tuple */ struct ip_conntrack_tuple tuple; /* this == &ctrack->tuplehash[DIRECTION(this)]. */ struct ip_conntrack *ctrack; };
实际描述一个tuple的是ip_conntrack_tuple结构 ip_conntrack_tuple.h struct ip_conntrack_tuple { /* 源 */ struct ip_conntrack_manip src;
/* These are the parts of the tuple which are fixed. */ struct { /* 目的地址 */ u_int32_t ip; union { /* Add other protocols here. */ u_int64_t all;
struct { u_int16_t port; } tcp; struct { u_int16_t port; } udp; struct { u_int8_t type, code; } icmp; struct { u_int16_t protocol;