第2章 多元数据数学表达
多元数据数学表达及R使用
#利用对角线元素创建对角矩阵 diag(diag(A))
#获取对角线元素 A=matrix(1:16,nrow=4,ncol=4) diag(A)
#创建3阶单位矩阵 diag(3)
2 多元数据的数学表达及R使用
#求逆矩阵 A=matrix(rnorm(16),4,4) solve(A)
#求矩阵特征根与特征向量 A=diag(4)+1 A.e=eigen(A,symmetric=T)
数
期望
据
的
表
方差
达
样本均值 和方差
多元数据
期望
协方差
cov(x1, x1) cov(x1, x2) cov(x1, xp) 11 12 1p
=Var(X ) cov(x2,x1) cov(x2,x2)
cov(x2,
xp
)
21
22
2
p
cov(xp, x1) cov(xp, x2)
cov(xp, xp) p1 p2
#矩阵按行求和 rroowwSSuummss((AA))
#矩阵按行求均值 ccoollSSuummss((AA))
#矩阵按列求和 colSums(A)
#矩阵按列求均值 colSums(A)
apply()函数
apply(X, MARGIN, FUN, ...)
#矩阵按行求和 apply(A,1,sum)
注意: apply(B,2,function(x,a) x*a,a=2)与B*2效果相同, 此处旨在说明如何应用 apply函数。
2 多元数据的数学表达及R使用
数据框(data frame)是一种矩阵形式的数据,但数据框中各列可以是不同类型的数据。 数据框录入限制条件
《多元统计分析及R语言》第2章多元数据的数学表达

5 - 16
饼图: 分析单变量分布特征 pie(table(结果))
5 - 17
(2)两因素分析
条形图:分析单变量分布特征 data=read.table("clipboard",header=T) table(年龄,性别) #二维列联表 barplot(table(年龄,性别),beside=T, col=1:7)
所在包 base base base base base base base base base
base
base
base base base base
2.4 数据的R语言表示-数据框
数据框:是一种矩阵形式的数据,但数据框中各列可 以是不同类型的数据。
地区 A A A B B A D
性别(X1) 教育程度(X2) 观点(X3)
t diag solve
eigen
chol
svd qr kronecker dim
用途 向量生成函数 向量长度函数 对象类型函数 行合并函数 列合并函数 矩阵生成函数 矩阵转置函数 对角阵生成函数 逆矩阵计算函数
矩阵的特征值与特征向量函数
进行Choleskey分解
进行奇异值分解 进行QR分解 kronecker积计算函数 矩阵维数
设备 981.13 760.56 546.75 477.74 561.71 439.28 407.35 355.67
医疗 1294.07 1163.98 833.51 640.22 719.13 879.08
854.8 729.55
交通 2328.51 1309.94 1010.51 1027.99 1123.82 1033.36 873.88 746.03
多元统计分析及R语言建模-全书课件完整版ppt全套教学教程最全电子教案教学设计(最新)

#赋予数据框新的列标签 X=data.frame('身高'=x1,'体重'=x2)
2 多元数据的数学表达及R使用 2.5 多元数据的R语言调用
从
选择需要进行计算的数据块 (比如上例中名为UG的数据),
剪
拷贝之。
切
在R中使用dat <-
板
read.table("clipboard",header=T)
modreg mva nlme nls nnet rpart spatial splines
survival tcltk tools ts
Packages (继续)
Modern Regression: Smoothing and Local Methods
Classical Multivariate Analysis Linear and nonlinear mixed effects models Nonlinear regression Feed-forward neural networks and multinomial log-linear models Recursive partitioning functions for kriging and point pattern analysis Regression Spline Functions and Classes stepfun Step Functions, including Empirical Distributions
多元统计分析及R语言建模
第1章 多元统计分析概述
- 1-
多元统计分析及R语言建模 1 多元统计分析概述
多元统计分析及R语言建模
多元统计分析概述
应用多元统计分析教学课件02多元正态分布

其中 μ 是一个 p 维向量,称为均值向量。
15
四、多维随机向量的数字特征
若 Xi 和X j 的协方差 Cov(Xi , X j ) ( i, j 1, 2, , p )存 在,则称
D(X) COV (X, X) E(X EX)(X EX)
DX1 Cov( X 2 , X1)
Cov( X p , X1)
多维随机向量的条件分布。当 X 的密度函数
为 f (x(1) , x(2) ),X(2) 的密度函数为 f2(x(2) )时,给定 X(2)
时 X(1)的条件密度为
f1(x(1) | x(2) )
f (x(1) , x(2) ) f2 (x(2) )
称给定 X(2)时X(1) 的分布为条件分布。
13
x j (x1j , x2 j , xnj )
表示对第 j 个变量的 n 次重复观测值,在 x j 获得具
体观测之前,是一个 随机变量。
7
二、多元分布函数和多元密度函数
随机向量(变量) 离散型、连续型
刻画随机向量(变量) 分布函数、密度函数
8
二、多元分布函数和多元密度函数
分布函数 设 X (X1, X2 , X p)为一随机向量,它的多元分布函数
四、多维随机向量的数字特征
概率分布是对随机变量的概率性质最完整的刻 画。优点是刻画的完整性,不便之处在于表示形 式有时是非常复杂的。而随机变量的数字特征, 则是指某些由随机变量的分布所决定的常数,它 刻画了随机变量(或者其分布)的某一方面的性质。 对于多维随机变量刻画其性质的最重要的数字特 征有均值、自协差阵与协差阵及相关矩阵。
f (x1, x2, , xq )
f (x1, x2,
2.多元数据描述与展示-讲解(上)

第 2 章多元数据的描述与展示Characterizing and DisplayingMultivariate Data随机变量数值特征描述可视化随机向量多元数据的矩阵表示均值向量、协方差矩阵与相关系数矩阵多元散点图随机向量分割分块均值向量与协方差矩阵变量线性组合随机变量的线性组合随机变量数值特征描述可视化随机向量多元数据的矩阵表示均值向量、协方差矩阵与相关系数矩阵多元散点图随机向量分割分块均值向量与协方差矩阵变量线性组合随机变量的线性组合随机变量均值、方差与标准差随机变量 :总体均值:总体方差:总体标准差:(独立同分布的)随机样本 :样本均值:样本方差:样本标准差:随机变量协方差和相关系数二元随机变量 :样本协方差:样本相关系数:随机样本 :样本协方差:样本相关系数:随机变量协方差与独立性 和 是不相关/线性独立的如果 和 服从二元正态分布,那么 和 是独立的是在样本空间中,两个经过中心化的 维向量和 的夹角余弦不相关的变量对应的 维样本向量是正交的(orthogonal)目录随机变量数值特征描述可视化随机向量多元数据的矩阵表示均值向量、协方差矩阵与相关系数矩阵多元散点图随机向量分割分块均值向量与协方差矩阵变量线性组合随机变量的线性组合例:由20名男大学生构成的样本所提供的身高(单位:英寸)和体重(单位:磅)数据如下:目录随机变量数值特征描述可视化随机向量多元数据的矩阵表示均值向量、协方差矩阵与相关系数矩阵多元散点图随机向量分割分块均值向量与协方差矩阵变量线性组合随机变量的线性组合随机向量多元数据的结构随机向量通常来说,我们使用矩阵来表示多元数据集假设数据集是通过对 个样本/观测点(subjects/units/samples/observations)测量它们对应的 个变量所得到的,那么这个数据集就能够表示为 的数据矩阵:其中 由 的第 行构成,表示第 个样本多元数据的矩阵表示随机向量矩阵表示:鸢尾花数据集这里收集到150个鸢尾花样本:对于每个样本,这里测量了5个变量:第 朵鸢尾花的第 个变量测量值为:例: 的值是多少?它代表什么?目录随机变量数值特征描述可视化随机向量多元数据的矩阵表示均值向量、协方差矩阵与相关系数矩阵多元散点图随机向量分割分块均值向量与协方差矩阵变量线性组合随机变量的线性组合总体均值向量 (Mean vector):对随机向量 ,样本均值向量:对随机样本 (其中 ),样本均值 是总体均值 的无偏估计,也即,其中随机向量的特征均值向量:鸢尾花数据集例如:鸢尾花数据中数值型变量的样本均值向量为:也就是说,总体协方差矩阵 (Covariance matrix):对随机向量 来说, 的总体协方差矩阵 定义为:其中 是 和 之间的总体协方差, 是 的总体方差样本协方差矩阵:对随机样本 (其中 )来说, 的样本协方差矩阵 定义为:其中 是该向量的第 和第 个变量之间的样本协方差, 是第 个变量的样本方差随机向量的特征和 是对称的,因为 和是 的无偏估计,也即的协方差矩阵是 协方差矩阵总体相关系数矩阵 (Correlation matrix):其中 为 与 之间的总体相关系数样本相关系数矩阵:对随机样本 来说,其中 是第 和第 个变量之间的样本相关系数和 是对称的,因为 和相关系数矩阵可以由协方差矩阵得到,反之亦然. 比如,其中 的对角矩阵 定义为:验证 :。
多元统计分析第2章

2.7 矩阵不等式和极大化
现在,令 易证,
是一个椭圆。 满足 ,同样, 给出了沿e2方向的适当距离。 因此,距离为c的点落在椭圆上,它的轴由A的特征 向量给出,其长度与特征值得平方根的倒数成比例
如果p>2,到原点距离为常数 的点 落在超椭圆球 上,其轴由A的特征向量给出。沿ei方向的半轴长等 于 ,其中λ i为A的特征值。
例如,当k =4
对称阵和逆矩阵
对于一个方阵A,如果A=A’,则称此方阵为对称阵。 当两个方阵A和B维数相同时,两个乘积AB和BA均有 定义,尽管它们未必相等。 单位矩阵I,表示主对角线元素均为1,其余元素均为 0的方阵。
如果存在矩阵B,使得
则称B为A的逆矩阵,并记作A-1
特征值和特征向量
引入两个向量的内积,
根据内积定义和式(2-3),有
利用内积,就能将n个分量的向量的长度和夹角自然 地推广为,
仅当
,即x与y相互垂直。
如果存在不全为零的常数,使得
就说这对向量线性相关。
投影
向量x在向量y上的投影为
其中向量
的长度为1,投影的长度为
其中是x与y间的夹角(见图2.5)
矩阵
2.4 平方根矩阵
设A是k×k正定矩阵,有谱分解 化特征向量是另一矩阵的列向量
。设标准 ,有
其中
,且∧为如下对角矩阵
因为
,有
平方根矩阵
2.5 随机向量和矩阵
随机向量是元素为随机变量的向量。类似地,随机 矩阵是元素为随机变量的矩阵。 随机矩阵X的期望值E(X),如下
多元数据图表示法
第二类分类方法可用后面介绍的主成分分析、因 子分析等去解决。这一章只对第一类方法介绍四种 图表示法,更多的方法可在有关专著中找到。
多元数据图表示法
作图步骤为: (1)作平面坐标系,横坐标取 p 个点表示 p 个变量。 (2)对给定的一次观测值,在 p 个点上的纵 坐标(即高度)和它对应的变量取值成正比。 (3)连接 p 个高度的顶点得一折线,则一次观
例 考察北京、上海、陕西、甘肃四个省市人均生 活消费支出情况,选取以下五项指标,具体数据如下 表:
肉禽及制品 住房 医疗保健 交通和通讯 文娱用品及服务
北京 上海 陕西 甘肃
563.51 678.92 237.38 253.41
227.78 365.07 174.48 156.13
147.76 112.82 119.78 102.96
测值的轮廓为一条多角折线形。n 次观测值可 画出n 条折线,构成轮廓图。
多元数据图表示法
800 700 600 500 400 300 200 100
0
品 制 禽及 肉
北京 上海 陕西 甘肃
房
健
讯
化
住
保
通
文
医疗
交通
教育
轮廓图
乐 娱
由轮廓图可以看出:北京、上海的居民生活 消费较高且相似;陕西、甘肃生活消费较低且相 似。
利用SPSS制作矩阵散点图的步骤如下: (1)在SPSS中按图11.6的形式组织数据,即把支 出指标当成变量,而把不同地区当成观测。
图11.6 作散点图时的数据组织形式
(2)选择菜单项Graphs→Scatter,打开 Scatter plot对话框,如图11.7。该对话框用于 选择散点图的形式。选定Matrix,即矩阵散 点图 ,单击Define按钮,打开Scatter plot Matrix对话框,如图11.8。
多元统计分析及R语言建模(第五版)课件第一二章
2 多元数据的数学表达及R使用
数据框(data frame)是一种矩阵形式的数据,但数据框中各列可以是不同类型的数据。 数据框录入限制条件
数 据 框
在数据框中 以变量形式 出现的向量 长度必须一 致,矩阵结 构必须有一 样的行数。
2 多元数据的数学表达及R使用
#矩阵按列求和 apply(A,2,sum)
#矩阵按列求均值 aplly(A,2,mean)
#矩阵按列求方差 A=matrix(rnorm(100),20,5) aplly(A,2,var)
#矩阵按列求函数结果 B=matrix(1:12,3,4) apply(B,2,function(x,a) x*a, a=2)
#矩阵按行求和 rowSums(A)
#矩阵按行求均值 colSums(A)
#矩阵按列求和 colSums(A)
#矩阵按列求均值 colSums(A)
apply()函数
apply(X, MARGIN, FUN, ...)
#矩阵按行求和 apply(A,1,sum)
#矩阵按行求均值 apply(A,1,mean)
命令结果窗口
R里面有什么?
Packages (每个都有大量数据和可以读写修 改的函数/程序)
base boot class cluster ctest eda foreign grid KernSmooth lattice lqs MASS methods mgcv
The R base package Bootstrap R (S-Plus) Functions (Canty) Functions for classification Functions for clustering (by Rousseeuw et al.) Classical Tests Exploratory Data Analysis Read data stored by Minitab, SAS, SPSS, ... The Grid Graphics Package Functions for kernel smoothing for Wand & Jones (1995) Lattice Graphics Resistant Regression and Covariance Estimation Main Library of Venables and Ripley's MASS Formal Methods and Classes Multiple smoothing parameter estimation and GAMs by GCV
《高数教学课件》第二节多元函数的基本概念
多元函数的极值与最值
Part
定义
设$D$是平面或空间的一个区域,$f(x,y)$是定义在$D$上的二元函数。如果对于点$P_0(x_0,y_0)$的某个邻域内的所有点$(x,y)$都有$f(x,y) leq f(x_0,y_0)$(或$f(x,y) geq f(x_0,y_0)$),则称$f(x,y)$在点$P_0(x_0,y_0)$取得极大值(或极小值)。
偏导数的定义
偏导数描述了函数在某一点处沿某一方向的变化率,具有连续性、可加性和可微性等性质。
偏导数的性质
在二维空间中,偏导数可以解释为函数图像在该点的切线的斜率;在三维空间中,偏导数可以解释为函数图像在该点的切面的法线斜率。
偏导数的几何意义
偏导数的概念与性质
全微分的定义
如果一个多元函数在某点的各个方向的偏导数都存在,并且存在一个与这些偏导数相对应的线性组合,使得该线性组合在任意点都等于该点的函数值,则称该线性组合为该函数在该点的全微分。
求解方法
通过极值定理,将多维问题转化为多个一维问题求解。
应用
在解决实际问题时,常常需要找到函数在某个区域上的最大值或最小值,以便了解该问题的最优解或最劣解。
01
02
03
多元函数的最值
联系
最值和极值都是函数在某个点或区域的取值特性,它们都反映了函数在某个特定点或区域附近的取值情况。极值是局部的概念,而最值是全局的概念。在某些情况下,极值点可能就是最值点,但最值点不一定都是极值点。
判定方法
一阶条件(偏导数等于零的点)、二阶条件(海森矩阵的判别式小于零的点)。
应用
解决实际问题时,常常需要找到函数的极值点,因为这些点往往对应着最优解或最劣解。
多元函数的极值
多元统计分析:第二章 多元正态分布及ppt课件
性质3 若X~Np(μ,Σ),E(X)=μ,D(X)=Σ. 证明 因Σ≥0,Σ可分解为:Σ=AA′,
则由定义2.2.1可知
X =d AU+μ (A为p×q实矩阵)
其中U=(U1,…,Uq)′,且U1,…,Uq相互独立同 N(0,1)分布,故有
E(U )=0, D(U )=Iq .
Z=BX+d d= B(AU+μ)+d
= (BA)U+(Bμ+d) 由定义2.2.1可知
Z ~Ns(Bμ+d, (BA)(BA)),
Z ~Ns(Bμ+d, BΣB). (这里Σ=AA).
ppt精选版
21
第二章 多元正态分布及参数的估计
§2.2 多元正态分布性质2
推论
分为
设X=
X(1) X(2)
r p-r
§2.2
在一元统计中,若U~N(0,1),则U的任意 线性变换X=σU+μ~N(μ,σ2)。利用这一性质, 可以从标准正态分布来定义一般正态分布:
若U~N(0,1),则称X =σU+μ的分布为 一般正态分布,记为X ~N(μ, σ2 )。
此定义中,不必要求σ>0,当σ退化为0时仍 有意义。把这种新的定义方式推广到多元情况
本课程所讨论的是多变量总体.把 p个随机变量放在一起得
X=(X1,X2,…,Xp)′ 为一个p维随机向量,如果同时对p维 总体进行一次观测,得一个样品为 p 维数据.常把n个样品排成一个n×p矩 阵,称为样本资料阵.
ppt精选版
4
第二章 多元正态分布及参数的估计
§2.1 随 机 向
X xx1211
其L 中
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
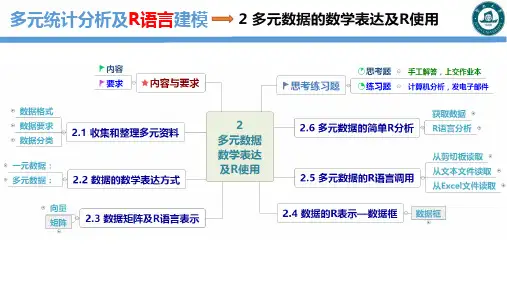
多元统计分析及R语言建模第2章多元数据的数学表达及R使用
内容与要求
多元数据的基本格式,如何收集和整理多元统计分析资料、数据的
数学表达、数据矩阵及R 表示、数据的R 语言表示、R 调用多元的数据和多元的数据的简单R 语言分析。
要求学生熟练如何收集和整理多元统计分析资料、数据的数学表达、掌握多元数据的数字特征的解析表达式、数字特征的基本性质。
熟悉有关统计软件。
利用统计软件来练习矩阵的有关计算。
练习在已
给数据下,求样本均值、样本离差阵、样本协差阵等。
【例2.1】为了了解股民的投资状况,研究股民的股票投资特征,我们在2002年组织统计系本科生进行小范围的“股民投资状况抽样调查”。
本次调查的抽样框主要涉及广东省的6个城市(广州、深圳、珠海、中山、佛山和东莞,其中,广州、深圳各100份,其他城市各80份),共发放问卷520份,回收有效问卷514份。
问卷中设计了18个问题。
为了简化分析,本例只考虑:年龄、性别、风险意识、是否专兼职、职业状况、教育程度和投资结果共7个变量进行分析。
#本例性别、风险、专兼职、职业、教育和结果
为定性变量,年龄是定量变量,有时为了分析问
题方便,也可将其定量化,例如
⏹年龄(age):19岁以下(1);20至29岁(2);
30 至39岁(3);40至49岁(4);50至59岁
(5);60岁及以上(6);缺失(*)。
⏹性别(sex): 男(1),女(2)。
⏹风险(risk):有(1);无(2)。
⏹专兼职(post):专职(1);业余(2)。
⏹职业(career):干部(1);管理(2);3科教
(3);金融(4);工人(5);农民(6);个体(7);无业(8)。
⏹教育(edu):文盲(1);小学(2);中学(3);
高中(4);中专(5);
大专(6);大学(7);研究生(8)。
⏹投资结果(result):赚钱(1);不赔不赚(2);
赔钱(3)。
方差
样本均值和方差
一元数据
多元数据
期望
期望
协方差
111211112
12122
2212221212cov(,)cov(,)cov(,)cov(,)cov(,)
cov(,)=()cov(,)cov(,)cov(,)p p p p p p p p p p pp x x x x x x x x x x x x Var X x x x x x x σσσσσσσσσ⎡⎤⎡⎤
⎢⎥⎢⎥⎢
⎥⎢⎥∑==⎢⎥⎢⎥⎢⎥⎢⎥⎢⎥⎢⎥⎣⎦⎣⎦
数据的表达
2 多元数据的数学表达及R使用
2.3 数据矩阵
在R中可以用函数c()来创建向量:
在R中结果输出如下:
#将向量按列和并
rbind(x1,x2)
#利用x1数据创建矩阵
matrix(x1,nrow=3,ncol=4)
#创建按照行排列的矩阵
matrix(x1,nrow=3,ncol=4,byrow=T)
#创建两个相同的矩阵
A=B=matrix(1:12,nrow=3,ncol=4)
#矩阵转置
t(A)
#矩阵加法
A+B
#矩阵加法
A+B
#矩阵相乘
A=matrix(1:12,nrow=3,ncol=4)
B=matrix(1:12,nrow=4,ncol=3)
A%in%B
#获取对角线元素
A=matrix(1:16,nrow=4,ncol=4)
diag(A)
#利用对角线元素创建对角矩阵
diag(diag(A))
#创建3阶单位矩阵
diag(3)
#求逆矩阵
A=matrix(rnorm(16),4,4) solve(A)
#求矩阵特征根与特征向量
A=diag(4)+1
A.e=eigen(A,symmetric=T) #矩阵的Choleskey分解A.c=chol(A)
#矩阵奇异值分解
A=matrix(1:18,3,6)
A.s=svd(A)
#矩阵的维数
A=matrix(1:12,3,4)
dim(A)
#矩阵的行数
nrow(A)
#矩阵的行数
ncol(A)
#矩阵按行求和
rowSums(A)
#矩阵按行求均值
rowMeans(A)
#矩阵按列求和
colSums(A)
#矩阵按列求均值
colMeans(A)
apply()函数
apply(X, MARGIN, FUN, ...)
#矩阵按行求和
apply(A,1,sum)
#矩阵按行求均值
apply(A,1,mean)
#矩阵按列求和
apply(A,2,sum)
#矩阵按列求均值
apply(A,2,mean)
#矩阵按列求方差
A=matrix(rnorm(100),20,5)
apply(A,2,var)
#矩阵按列求函数结果
B=matrix(1:12,3,4)
apply(B,2,function(x,a) x*a, a=2)
注意:
apply(B,2,function(x,a)
x*a,a=2)与B*2效果相同,
此处旨在说明如何应用
apply函数。
数据框(data frame )是一种矩阵形式的数据,但数据框中各列可以是不同类型的数据。
在数据框中以变量形式出现的向量长度必须一致,矩阵结构必须有一样的行数。
数据框录入限制条件
数据框
#由x1和x2构建数据框
X=data.frame(x1,x2)
#赋予数据框新的列标签
X=data.frame('身高'=x1,'体重'=x2)
从剪切板读取选择需要进行计算
的数据块(比如上
例中名为UG的数
据),拷贝之。
在R中使用dat <-
read.table("clipbo
ard",header=T)
01
02
从文本文件读取#读取名为textdata的txt格式文档
X=read.table("textdata.txt")
X=read.table('textdata.txt',header=T)
第一行作为标题时
读取csv 格式
读取excel 格式
X=read.csv("textdata.csv")
1.下载读取excel 文件的包“readxl”
2. 调用包:library(readxl)
3. 读取文件:X=read_excel(“data.xls”)
#身高的直方图hist(x1) #身高与体重散点图plot(x1,x2)
定量变量分析
#将剪切板数据读入数据框d2.1中 d2.1=read.table("clipboard",header=T) #显示数据前6行 head(d2.1) 定性变量分析 #绑定数据 attach(d2.1) #一维列联表 table(年龄)
#条形图
barplot(table(年龄),col=1:7) #饼图
pie(table(结果))
定性变量分析︵单因素︶
#以性别分组的年龄条图barplot(table(年龄,性别),
beside =T, col = 1:7) #以年龄分组的性别条图barplot(table(性别,年龄),
beside=T,col =1:2)
定性变量分析︵双因素︶
#以年龄、性别排列的结果频数三维列联表ftable(年龄,性别,结果) #以性别、年龄排列的结果频数三维列联表ftable(性别,年龄,结果)
定性变量分析︵三因素︶
#ft=ftable(性别,结果,年龄) #求ft 的行和 rowSums(ft) 定性变量分析︵三因素︶#求ft 的列和 colSums(ft) #整理得 注意 detach(d2.1) 当数据框不使用时,解除绑定!!。