spss分类分析
spss聚类分析树状图

spss 聚类分析树状图
借助主成分得分对河南省各市进行聚类分析。
在进行聚类分析时,指标越多就会使样品间的共性显示得越少,太多的指标会使计算出的样品间的距离偏大,从而不利于样品间相似性的综合和聚类分析的进行,往往达不到所想要的分类效果。
SPSS 软件可以在不知道最终类别个数的情况下,画出完整的聚类分析谱系图,因此下面用SPSS 软件对河南省18 个市进行聚类分析。
在spss 中打开数据,选择分析→分类→系统聚类:
变量选择f1,f2 得分,聚类选择个案,勾选输出统计量和绘图;
点击设置统计量,默认选择即可
点击选择分类方法,这里选择了离差平方和法;
点击绘制,勾选树状图,这个是我们输入查看谱系图的依据:
确定查看谱系图,分析聚类结果,改用不同的分类方法,得到谱系图进行综合分析;
由于方法众多,这里选取最为常用较结合实际的离差平方和法进行分析,。
spss对有序分类资料的统计分析方法

spss对有序分类资料的统计分析
方法
【摘要】:目的本科及以下,乃至部分研究生使用的《卫生统计学》、《医学统计学》教材和所有有关SPSS的书籍中,没有介绍有序分类资料这一基本的统计分析方法,导致误用无序分类资料的卡方检验方法屡有发生。
本文提出利用SPSS卡方检验处理有序分类资料的简易统计分析方法。
方法用SPSS交叉表统计分析方法,选择"线性和线性组合"行的结果作为判别单向和双向有序分类资料的统计量,并用经典的Ridit分析和SAS程序分析结果比较。
结果在SPSS交叉表对单向有序分类资料的实例分析中,"线性和线性组合"的P值(0.022)与Ridit 分析和SAS程序统计分析的结果(0.0258)相近,统计推断结论一致。
在双向有序分类资料中,"线性和线性组合"的P值(0.044)与Ridit分析和SAS程序统计分析的结果(0.0446)完全一致。
2例均与用无序分类资料的统计分析结果相差很远。
结论 "线性和线性组合"对单向和双向有序分类资料均有效;区分有序分类资料与无序资料的统计分析方法,其分析结果和统计推断结论明显不同。
建议在各种统计学教材和有关SPSS的书籍中增加这部分内容,并明确提示为有序分类资料的统计分析方法。
用SPSS对分类变量进行相关分析_光环大数据培训

用SPSS对分类变量进行相关分析_光环大数据培训图形化解决方案——网络图网络图适合多分类型变量之间的相关分析,是一种更为生动和直观地展示两个或多个分类型变量相关特征的图形。
图形由节点和节点间的连线组成,每个节点对应一个分类取值,连线代表两个分类变量不同类型的组合。
根据图形,最细连线代表44人,最粗连线代表237人,可见Plus service (附加服务套餐)节点和未流失节点之间的连线最粗,选择附加服务套餐的用户相对而言比较忠实,而选择基本服务类型的用户保持情况不如选择附加服务的用户保持情况理想。
以上过程可采用Clementine的web节点实现。
数值型解决方案——交叉表分析图形化方法并不能正确反映两分类变量之间的相关程度,因此精细的数值分析是必要的。
两分类变量之间的相关分析通常采用交叉表分析,或称为列联表分析方法。
包括两部分,第一,两分类变量交叉计算和对比频数,第二,在交叉表的基础上利用卡方检验衡量二者之间的关系。
1、交叉表频数对比分析的解读由表可知,用户总体保持率72.6%,流失率27.4%,用户保持情况不太理想。
总体而言,样本量较小的情况下,四种套餐的占比分布情况不甚明了。
其中最突出的是,附加服务的客户忠诚度相对较高,保持率达到84.3%,高出总体保持率,流失率在四个套餐中最低,仅15.7%,低于总体流失率。
可见,不同类型套餐用户的保持和流失存在差异。
因此说,客户流失与套餐类型是相关联的。
2、卡方检验解读卡方检验原假设:行与列分类变量相互独立,没有相关关系。
由卡方检验表看出,其sig值为0.000,小于小概率事件的界定值0.01,由小概率事件不发生可以知道,原假设即二者独立这个说法是不合理的,也就是说套餐类型和客户流失是有极显著的相关关系。
以上交叉表分析可利用 SPSS 实现。
为什么大家选择光环大数据!大数据培训、人工智能培训、Python培训、大数据培训机构、大数据培训班、数据分析培训、大数据可视化培训,就选光环大数据!光环大数据,聘请大数据领域具有多年经验的讲师,提高教学的整体质量与教学水准。
如何使用SPSS作数据分析

如何使用SPSS作数据分析SPSS(Statistical Package for the Social Sciences)是一种常用的统计分析软件,广泛应用于社会科学领域的数据分析。
本文将介绍如何使用SPSS进行数据分析的基本步骤和常用功能。
一、数据导入与清洗在使用SPSS进行数据分析之前,首先需要将数据导入软件,并对数据进行清洗,确保数据的准确性和完整性。
以下是数据导入与清洗的步骤:1. 打开SPSS软件,并创建一个新的数据文件。
2. 选择导入数据的方式,可以是从Excel、csv等格式导入,也可以手动输入数据。
3. 导入数据后,检查数据是否包含缺失值或异常值。
可以使用SPSS的数据清洗工具进行处理,比如删除缺失值或替代为合适的值。
4. 检查数据的变量类型,确保每个变量的类型正确,比如分类变量、连续变量等。
5. 对需要的变量进行重命名,并添加变量标签,便于后续分析的理解和解释。
二、数据描述统计分析数据描述统计是对数据的基本特征进行概括和描述的分析方法。
SPSS提供了丰富的数据描述统计功能,如均值、标准差、频数分布等。
以下是数据描述统计分析的步骤:1. 运行SPSS软件,打开已经导入并清洗好的数据文件。
2. 选择"统计"菜单下的"描述统计"选项。
3. 在弹出的对话框中,选择需要进行描述统计分析的变量,并选择所需的统计指标,如均值、标准差等。
4. 点击"确定"进行计算,SPSS将输出所选变量的描述统计结果,包括均值、标准差、中位数等。
三、相关性分析相关性分析用于衡量两个或多个变量之间的相关程度,常用于探究变量之间的关系。
SPSS提供了多种相关性分析方法,如皮尔逊相关系数、斯皮尔曼相关系数等。
以下是相关性分析的步骤:1. 打开已导入的数据文件。
2. 选择"分析"菜单下的"相关"选项。
3. 在弹出的对话框中,选择需要进行相关性分析的变量,并选择所需的相关系数方法。
SPSS聚类以及各种聚类分析详解

精选可编辑ppt
3
精选可编辑ppt
4
数据标准化处理:
精选可编辑ppt
5
存储中间过程数据
精选可编辑ppt
6
数据标准 化处理, 并存储。
精选可编辑ppt
7
精选可编辑ppt
8
指定5类
精选可编辑ppt
9
精选可编辑ppt
收敛标准值 10
精选可编辑ppt
11
存储最终结果输出情况,在数据文件中(QCL-1、QCL-2)
(4)若选出的一对样品都出现在同一组中,则这对样 品就不用再分组了。
按上述四条原则反复进行,直到把所有样品都分类完毕, 最后以分类图形式表示
精选可编辑ppt
25
2、分类方法 例:设有7个样品,每个样品测得P个指标,数据如表
样品 指标
X1 X2 XP
X1 X2 X3 X4 X5 X6 X7
精选可编辑ppt
2)形成一个由小到大的分析系统。 3)把整个分类系统画成一张分类图
精选可编辑ppt
21
二、聚类统计量
首先定义一些分类统计指标 —— 刻画样或指标之间 的相似程度(这些统计指标称为聚类统计量)
在市场研究中,样品 —— 用作分类的事物
指标ቤተ መጻሕፍቲ ባይዱ—— 用来作为分类依据的变量。(如: 年龄、收入、销售量)
(一)相似系数(夹角余弦)
39
观测量概述表
精选可编辑ppt
40
聚类步骤,与图结合看!
精选可编辑ppt
41
4、5
精选可编辑ppt
42
精选可编辑ppt
43
聚类方法有系统聚类和逐步聚类,输入数据集可以是普 通数据集、相关矩阵(CORR过程产生)或协方差矩阵 (FACTOR等过程产生)。SAS提供的聚类过程有:
SPSS软件聚类分析过程的图文解释及结果的全面分析

SPSS聚类分析过程聚类的主要过程一般可分为如下四个步骤:1.数据预处理(标准化)2.构造关系矩阵(亲疏关系的描述)3.聚类(根据不同方法进行分类)4.确定最佳分类(类别数)SPSS软件聚类步骤1. 数据预处理(标准化)→Analyze →Classify →Hierachical Cluster Analysis →Method 然后从对话框中进行如下选择从Transform Values框中点击向下箭头,此为标准化方法,将出现如下可选项,从中选一即可:标准化方法解释:None:不进行标准化,这是系统默认值;Z Scores:标准化变换;Range –1 to 1:极差标准化变换(作用:变换后的数据均值为0,极差为1,且|x ij*|<1,消去了量纲的影响;在以后的分析计算中可以减少误差的产生。
);Range 0 to 1(极差正规化变换/ 规格化变换);2. 构造关系矩阵在SPSS中如何选择测度(相似性统计量):→Analyze →Classify →Hierachical Cluster Analysis →Method 然后从对话框中进行如下选择常用测度(选项说明):Euclidean distance:欧氏距离(二阶Minkowski距离),用途:聚类分析中用得最广泛的距离;Squared Eucidean distance:平方欧氏距离;Cosine:夹角余弦(相似性测度;Pearson correlation:皮尔逊相关系数;3. 选择聚类方法SPSS中如何选择系统聚类法常用系统聚类方法a)Between-groups linkage 组间平均距离连接法方法简述:合并两类的结果使所有的两两项对之间的平均距离最小。
(项对的两成员分属不同类)特点:非最大距离,也非最小距离b)Within-groups linkage 组内平均连接法方法简述:两类合并为一类后,合并后的类中所有项之间的平均距离最小C)Nearest neighbor 最近邻法(最短距离法)方法简述:用两类之间最远点的距离代表两类之间的距离,也称之为完全连接法d)Furthest neighbor 最远邻法(最长距离法)方法简述:用两类之间最远点的距离代表两类之间的距离,也称之为完全连接法e)Centroid clustering 重心聚类法方法简述:两类间的距离定义为两类重心之间的距离,对样品分类而言,每一类中心就是属于该类样品的均值特点:该距离随聚类地进行不断缩小。
SPSS数据分析—二分类Logistic回归模型
对于分类变量,我们知道通常使用卡方检验,但卡方检验仅能分析因素的作用,无法继续分析其作用大小和方向,并且当因素水平过多时,单元格被划分的越来越细,频数有可能为0,导致结果不准确,最重要的是卡方检验不能对连续变量进行分析。
使用线性回归模型可以解决上述的部分问题,但是传统的线性模型默认因变量为连续变量,当因变量为分类变量时,传统线性回归模型的拟合方法会出现问题,因此人们继续发展出了专门针对分类变量的回归模型。
此类模型采用的基本方法是采用变量变换,使其符合传统回归模型的要求。
根据变换的方法不同也就衍生出不同的回归模型,例如采用Logit变换的Logistic回归模型,采用Probit变换的Probit回归模型等,相比之下,Logistic是使用最为广泛的针对分类数据的回归模型。
Logistic回归模型的适用条件1.因变量为二分类变量或是某事件的发生率2.自变量与Logit变换后的因变量呈线性关系3.残差合计为0,且服从二项分布4.各观测值之间独立由于Logistic回归模型的残差项服从二项分布而不是正态分布,因此不能使用最小二乘法进行参数估计,而是要使用最大似然法。
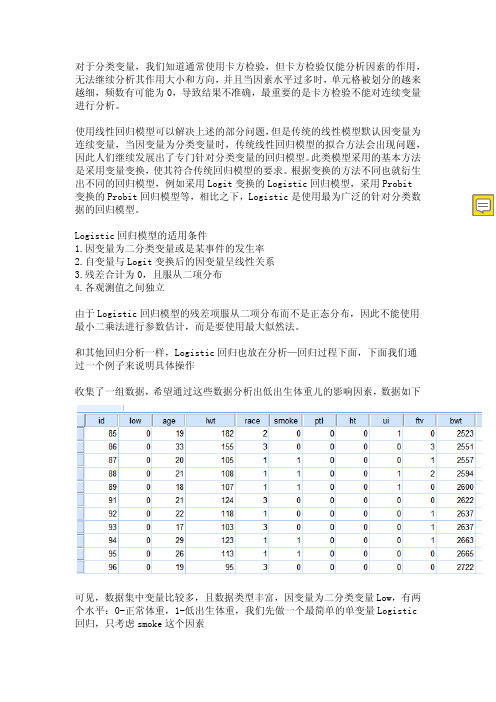
和其他回归分析一样,Logistic回归也放在分析—回归过程下面,下面我们通过一个例子来说明具体操作收集了一组数据,希望通过这些数据分析出低出生体重儿的影响因素,数据如下可见,数据集中变量比较多,且数据类型丰富,因变量为二分类变量Low,有两个水平:0-正常体重,1-低出生体重,我们先做一个最简单的单变量Logistic 回归,只考虑smoke这个因素分析—回归—二元Logistic回归前面我们只引入了一个自变量,可以看到模型的效果并不理想,而且Logistic 回归和传统回归模型一样,也可以引入多个自变量并且可以对自变量进行筛选,尽量引入对因变量存在强影响的自变量,下面我们继续加入自变量并进行筛选。
SPSS聚类和判别分析

1 8.193 3.909 1.303 .434 .145 .048 .016 .005 .002 .001
聚类中心内的更改
2
3
9.889
13.472
7.631
4.701
1.526
.672
.305
.096
.061
.014
.012
.002
.002
.000
.000
3.996E-5
9.768E-5
5.709E-6
➢ 变量间的关系度量模型与样本间相类似,只不过一个 用矩阵的行进行计算,另一个用矩阵的列进行计算。
6
SPSS 19(中文版)统计分析实用教程
主要内容
9.1 聚类与判别分析概述 9.2 二阶聚类 9.3 K-均值聚类 9.4 系统聚类 9.5 判别分析
电子工业出版社
7
SPSS 19(中文版)统计分析实用教程
聚类 1 2 3
有效 缺失
2.000 4.000 6.000 12.000
.000
可看出第1,2,3类中分别含 有2,4,6个样本
21
SPSS 19(中文版)统计分析实用教程
9.3 K-均值聚类
➢分类保存情况
电子工业出版社
查看数据文件,可看到多出两 个变量,分别表示每个个案的 具体分类归属和与类中心的距 离。
SPSS 19(中文版)统计分析实用教程
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第八章 分类分析
第一节 K-Means Cluster过程 8.1.1 主要功能 调用此过程可完成由用户指定类别数的大样本资料的逐步聚类分析。所谓逐步聚类分析就是先把被聚对象进行初始分类,然后逐步调整,得到最终分类。 8.1.2 实例操作 [例8.1]为研究儿童生长发育的分期,调查1253名1月至7岁儿童的身高(cm)、体重(kg)、胸围(cm)和坐高(cm)资料。资料作如下整理:先把1月至7岁划成19个月份段,分月份算出各指标的平均值,将第1月的各指标平均值与出生时的各指标平均值比较,求出月平均增长率(%),然后第2月起的各月份指标平均值均与前一月比较,亦求出月平均增长率(%),结果见下表。欲将儿童生长发育分为四期,故指定聚类的类别数为4,请通过聚类分析确定四个儿童生长发育期的起止区间。
月份 月平均增长率(%) 身高 体重 胸围 坐高 1 2 3 4 6 8 10 12 15 18 24 30 36 42 48 54 60 66 72 11.03 5.47 3.58 2.01 2.13 2.06 1.63 1.17 1.03 0.69 0.77 0.59 0.65 0.51 0.73 0.53 0.36 0.52 0.34 50.30 19.30 9.85 4.17 5.65 1.74 2.04 1.60 2.34 1.33 1.41 1.25 1.19 0.93 1.13 0.82 0.52 1.03 0.49 11.81 5.20 3.14 1.47 1.04 0.17 1.04 0.89 0.53 0.48 0.52 0.30 0.49 0.16 0.35 0.16 0.19 0.30 0.18 11.27 7.18 2.11 1.58 2.11 1.57 1.46 0.76 0.89 0.58 0.42 0.14 0.38 0.25 0.55 0.34 0.21 0.55 0.16
8.1.2.1 数据准备 激活数据管理窗口,定义变量名:虽然月份分组不作分析变量,但为了更直观地了解聚类结果,也将之输入数据库,其变量名为month;身高、体重、胸围和坐高的变量名分别为x1、x2、x3和x4,输入原始数额。
8.1.2.2 统计分析 激活Statistics菜单选Classify中的K-Means Cluster...项,弹出K-Means Cluster Analysis对话框(如图8.1示)。从对话框左侧的变量列表中选x1、x2、x3、x4,点击钮使之进入Variables框;在Number of Clusters(即聚类分析的类别数)处输入需要聚合的组数,本例为4;在聚类方法上有两种:Iterate and classify指先定初始类别中心点,而后按K-means算法作叠代分类,Classify only指仅按初始类别中心点分类,本例选用前一方法。
为在原始数据库中逐一显示分类结果,点击Save...钮弹出K-Means Cluster:Save New Variables对话框,选择Cluster membership项,点击Continue钮返回K-Means Cluster Analysis对话框。 本例还要求对聚类结果进行方差分析,故点击Options...钮弹出K-Means Cluster:来Options对话框,在Statistics栏中选择ANOVA table项,点击Continue钮返回K-Means Cluster Analysis对话框,再点击OK钮即完成分析。
8.1.2.3 结果解释 在结果输出窗口中将看到如下统计数据: 首先系统根据用户的指定,按4类聚合确定初始聚类的各变量中心点,未经K-means算法叠代,其类别间距离并非最优;经叠代运算后类别间各变量中心值得到修正。 Initial Cluster Centers. Cluster X1 X2 X3 X4 1 11.0300 50.3000 11.8100 11.2700 2 5.4700 19.3000 5.2000 7.1800 3 3.5800 9.8500 3.1400 2.1100 4 .3400 .4900 .1800 .1600
Convergence achieved due to no or small distance change. The maximum distance by which any center has changed is .0000 Current iteration is 2
Minimum distance between initial centers is 10.5200 Iteration Change in Cluster Centers 1 2 3 4 1 .0000 .0000 2.46E+00 1.27E+00 2 .0000 .0000 .0000 .0000
Case listing of Cluster membership. Case ID Cluster Distance 1 1 .000 2 2 .000 3 3 2.457 4 4 3.219 5 3 2.457 6 4 1.530 7 4 1.346 8 4 .515 9 4 .915 10 4 .266 11 4 .281 12 4 .668 13 4 .467 14 4 .844 15 4 .415 16 4 .873 17 4 1.215 18 4 .619 19 4 1.269
Final Cluster Centers. Cluster X1 X2 X3 X4 1 11.0300 50.3000 11.8100 11.2700 2 5.4700 19.3000 5.2000 7.1800 3 2.8550 7.7500 2.0900 2.1100 4 .9060 1.4660 .4820 .6560
之后对聚类结果的类别间距离进行方差分析,方差分析表明,类别间距离差异的概率值均<0.001,即聚类效果好。这样,原有19类(即原有的19个月份分组)聚合成4类,第一类含原有1类,第二类含原有1类,第三类含原有2类,第四类含原有15类。具体结果系统以变量名QCL_1存于原始数据库中。 Distances between Final Cluster Centers. Cluster 1 2 3 4 1 .0000 2 32.4397 .0000 3 45.3400 13.2521 .0000 4 52.2325 20.0924 6.9273 .0000
Analysis of Variance. Variable Cluster MS DF Error MS DF F Prob X1 37.5806 3 .369 15.0 101.7853 .000 X2 817.1164 3 1.354 15.0 603.2588 .000 X3 45.4089 3 .281 15.0 161.1145 .000 X4 46.0994 3 .235 15.0 195.4933 .000
Number of Cases in each Cluster. Cluster unweighted cases weighted cases 1 1.0 1.0 2 1.0 1.0 3 2.0 2.0 4 15.0 15.0 Missing 0 Valid cases 19.0 19.0
Variable Saved into Working File. QCL_1 (Cluster Number)
在原始数据库(图8.2)中,我们可清楚地看到聚类结果;参照专业知识,将儿童生长发育分期定为:
第一期,出生后至满月,增长率最高; 第二期,第2个月起至第3个月,增长率次之; 第三期,第3个月起至第8个月,增长率减缓; 第四期,第8个月后,增长率显著减缓。
图8.2 逐步聚类分析的分类结果 第二节 Hierarchical Cluster过程
8.2.1 主要功能 调用此过程可完成系统聚类分析。在系统聚类分析中,用户事先无法确定类别数,系统将所有例数均调入内存,且可执行不同的聚类算法。系统聚类分析有两种形式,一是对研究对象本身进行分类,称为Q型举类;另一是对研究对象的观察指标进行分类,称为R型聚类。
8.2.2 实例操作 [例8.2]29名儿童的血红蛋白(g/100ml)与微量元素(μg/100ml)测定结果如下表。由于微量元素的测定成本高、耗时长,故希望通过聚类分析(即R型指标聚类)筛选代表性指标,以便更经济快捷地评价儿童的营养状态。
编号 N0. 钙 X1 镁 X2 铁 X3 锰 X4 铜 X5 血红蛋白 X6 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 54.89 72.49 53.81 64.74 58.80 43.67 54.89 86.12 60.35 54.04 61.23 60.17 69.69 72.28 55.13 70.08 63.05 48.75 52.28 52.21 49.71 61.02 53.68 50.22 65.34 56.39 66.12 73.89 47.31 30.86 42.61 52.86 39.18 37.67 26.18 30.86 43.79 38.20 34.23 37.35 33.67 40.01 40.12 33.02 36.81 35.07 30.53 27.14 36.18 25.43 29.27 28.79 29.17 29.99 29.29 31.93 32.94 28.55 448.70 467.30 425.61 469.80 456.55 395.78 448.70 440.13 394.40 405.60 446.00 383.20 416.70 430.80 445.80 409.80 384.10 342.90 326.29 388.54 331.10 258.94 292.80 292.60 312.80 283.00 344.20 312.50 294.70 0.012 0.008 0.004 0.005 0.012 0.001 0.012 0.017 0.001 0.008 0.022 0.001 0.012 0.000 0.012 0.012 0.000 0.018 0.004 0.024 0.012 0.016 0.048 0.006 0.006 0.016 0.000 0.064 0.005 1.010 1.640 1.220 1.220 1.010 0.594 1.010 1.770 1.140 1.300 1.380 0.914 1.350 1.200 0.918 1.190 0.853 0.924 0.817 1.020 0.897 1.190 1.320 1.040 1.030 1.350 0.689 1.150 0.838 13.50 13.00 13.75 14.00 14.25 12.75 12.50 12.25 12.00 11.75 11.50 11.25 11.00 10.75 10.50 10.25 10.00 9.75 9.50 9.25 9.00 8.75 8.50 8.25 8.00 7.80 7.50 7.25 7.00