SPSS相关分析案例讲解
SPSS第10章相关分析

第10章相关分析 (225)1 双变量相关分析 (225)1.1 双变量相关分析的数据特征 (225)1.2 皮尔逊相关系数 (225)1.3 肯德尔相关系数 (228)1.4 例题3 (230)2 偏相关关系 (232)2.1 偏相关关系 (232)2.2 例题 (232)3 距离相关分析 (234)3.1 特征 (234)3.2 主要参数 (235)3.3 例题 (235)3.4 实例介绍 (237)第10章相关分析相关分析是研究变量之间关系密切程度的一种统计方法,包括双变量相关分析、偏相关分析和距离相关分析。
1 双变量相关分析1.1 双变量相关分析的数据特征当某一个事物存在着多个变量时,而各个变量之间呈数量关系时,可以用双变量相关分析来研究,并做出统计学推断。
双变量相关分析可以输出两两变量之间的相关系数,相关系数的种类有皮尔逊相关系数、肯德尔相关系数、斯皮尔曼等级相关系数等。
1.2 皮尔逊相关系数X和Y有线性函数关系,两变量间的相关系数是+1~-1,相关系数没有单位。
1.2.1 例题133名产妇进行产前检查,测定X1-X6六项指标,试计算X1-X4的皮尔逊相关系数。
1.2.2 SPSS过程Data,analyze,correlate,打开bivariate对话框,选择x1-x4→variables,选择pearson 相关系数,two-tail,flag significant correlations,打开options对话框,means and standard deviations,exclude case pairwirs,continue,ok.two-tail,双尾检验;Flag significant correlations:用星号显示有显著性相关的相关系数;Exclude case pairwirs:剔除有缺失值的配对变量;Cross-product deviations and covarances:显示每一对变量的离均差交叉积与协方差。
SPSS典型相关分析案例

SPSS典型相关分析案例典型相关分析(Canonical Correlation Analysis,CCA)是一种统计方法,用于研究两组变量之间的相关性。
它可以帮助研究人员了解两组变量之间的关系,并提供有关这些关系的详细信息。
在SPSS中,可以使用典型相关分析来探索两个或多个变量之间的关系,并进一步理解这些变量如何相互影响。
下面我们将介绍一个典型相关分析的案例,以展示如何在SPSS中执行该分析。
案例背景:假设我们有一个医学研究数据集,包含30名患者的多个生物标记物和他们的疾病严重程度评分。
我们希望了解这些生物标记物与疾病严重程度之间的关系,并查看是否可以建立一个线性模型来预测疾病严重程度。
以下是执行这个案例的步骤:第1步:准备数据首先,我们需要准备数据,确保所有变量都是数值型。
在SPSS中,我们可以通过检查数据集的描述性统计信息或查看变量视图来做到这一点。
第2步:导入数据在SPSS中,我们可以通过选择菜单中的"File"选项,然后选择"Open"来导入数据集。
我们应该选择包含待分析数据的文件,并确保正确指定变量的类型。
第3步:执行典型相关分析要执行典型相关分析,我们可以选择菜单中的"Analyze"选项,然后选择"Canonical Correlation"。
在弹出的对话框中,我们应该选择我们希望研究的生物标记物变量和疾病严重程度评分变量。
然后,我们可以选择一些选项,如方差-协方差矩阵、相关矩阵和判别系数,并点击"OK"执行分析。
第4步:解释结果完成分析后,SPSS将提供几个输出表。
我们应该关注典型相关系数和标准化典型系数,以了解两组变量之间的关系。
我们可以使用这些系数来解释生物标记物如何与疾病严重程度相关联,并找到最重要的变量。
此外,我们还可以使用SPSS提供的其他统计结果来进一步解释模型的效果和预测能力。
SPSS统计分析实例讲解

SPSS统计分析实例讲解引言在社会科学研究和商业分析中,统计分析是一个重要的工具,可以帮助我们理解数据背后的规律和关系。
SPSS(Statistical Package for the Social Sciences)是一种常用的统计分析软件,具有强大的数据处理和分析功能。
本文将通过一个实例,介绍如何使用SPSS进行统计分析。
实例背景假设我们是一家快餐连锁店的运营经理,我们想了解不同分店的顾客满意度与相关因素之间的关系。
为了实现这个目标,我们收集了以下三个变量的数据:1.顾客满意度:用于评估顾客对快餐店的满意程度,以1-10的等级进行评分。
2.服务质量:用于评估不同分店提供的服务质量,以1-5的等级进行评分。
3.价格水平:用于评估不同分店的价格水平,以1-5的等级进行评分。
我们希望通过分析这些数据,了解不同分店的服务质量和价格水平对顾客满意度的影响。
数据分析步骤步骤一:载入数据首先,我们需要将收集到的数据导入SPSS软件进行分析。
打开SPSS软件,点击菜单栏中的文件(File),选择导入(Import),然后选择收集到的数据文件进行导入。
步骤二:数据清洗在进行数据分析之前,我们需要对数据进行清洗,以确保数据的准确性和一致性。
一般来说,数据清洗包括以下几个方面的处理:•去除缺失值:检查数据中是否存在缺失值,如果有,可以删除含有缺失值的观测样本或者使用合适的方法进行填补。
•标准化变量:如果不同变量的测量单位和量级存在差异,可以对变量进行标准化处理,使得它们具有可比性。
•检查异常值:检查数据中是否存在异常值,如果有,可以进行修正或者删除。
•数据转换:对于非正态分布的变量,可以进行对数变换或者其他适当的转换,以满足统计分析的前提条件。
步骤三:描述性统计分析描述性统计分析是对数据的整体情况进行概括和描述的统计方法。
通过描述性统计分析,我们可以了解数据的中心趋势、离散程度和分布形态等。
在SPSS中,可以使用以下方法进行描述性统计分析:•平均值:计算变量的平均值,以反映数据的中心趋势。
SPSS相关性和回归分析一元线性方程案例解析

其中在“样本数据统计”中,随即误差一般叫“残差”:
从结果分析来看,可以简单的认为:居民总储蓄每增加1亿,那居民总消费将会增加0.954亿
提示:对于回归参数的估计,一般采用的是“最小二乘估计法”原则即为:“残差平方和最小“
1:点击“分析”—相关—双变量,进入如下界面:
将“居民总储蓄”和“居民总消费”两个变量移入“变量”框内,在“相关系数”栏目中选择“Pearson",(Pearson是一种简单相关系数分析和计算的方法,如果需要进行进一步分析,需要借助“多远线性回归”分析)在“显著性检验”中选择“双侧检验”并且勾选“标记显著性相关”点击确定,得到如下结果:
从以上结果,可以看出“Pearson"的相关性为0.821,(可以认为是“两者的相关系数为0.821)属于“正相关关系”同时“显著性(双侧)结果为0.000,由于0.000<0.01,所以具备显著性,得出:“居民总储蓄”和“居民总消费”具备相关性,有关联。
既然具备相关性,那么我们将进一步做分析,建立回归分析,并且构建“一元线性方程”,如下所示:
2:从anvoa b的检验结果来看(其实这是一个“回归模型的方差分析表)F的统计量为:29.057,P值显示为0.000,拒绝模型整体不显著的假设,证明模型整体是显著的
3:从“系数a”这个表可以看出“回归系数,回归系数的标准差,回归系数的T显著性检验等,回归系数常量为:2878.518,但是SIG为:0.452,常数项不显著,回归系数为:0.954,相对的sig为:0.000,具备显著性,由于在“anvoa b”表中提到了模型整体是“显著”的
SPSS-相关性和回归分析(一元线性方程)案例解析
SPSS数据分析实例详解

第一章 SPSS概览--数据分析实例详解1.1 数据的输入和保存1.1.1 SPSS的界面1.1.2 定义变量1.1.3 输入数据1.1.4 保存数据1.2 数据的预分析1.2.1 数据的简单描述1.2.2 绘制直方图1.3 按题目要求进行统计分析1.4 保存和导出分析结果1.4.1 保存文件1.4.2 导出分析结果欢迎加入SPSS使用者的行列,首先祝贺你选择了权威统计软件中界面最为友好,使用最为方便的SPSS来完成自己的工作。
由于该软件极为易学易用(当然还至少要有不太高的英语水平),我们准备在课程安排上做一个新的尝试,即不急于介绍它的界面,而是先从一个数据分析实例入手:当你将这个例题做完,SPSS的基本使用方法也就已经被你掌握了。
从下一章开始,我们再详细介绍SPSS各个模块的精确用法。
我们教学时是以SPSS 10.0版为蓝本讲述的--什么?你还在用7.0版!那好,由于10.0版在数据管理的界面操作上和以前版本有较大区别,本章我们将特别照顾一下老版本,在数据管理界面操作上将按9.0及以前版本的情况讲述,但具体的统计分析功能则按10.0版本讲述。
没关系,基本操作是完全一样的。
好,说了这么多废话,等急了吧,就让我们开始吧!希望了解SPSS 10.0版具体情况的朋友请参见本网站的SPSS 10.0版抢鲜报道。
例1.1 某克山病区测得11例克山病患者与13名健康人的血磷值(mmol/L)如下, 问该地急性克山病患者与健康人的血磷值是否不同(卫统第三版例4.8)?患者: 0.84 1.05 1.20 1.20 1.39 1.53 1.67 1.80 1.87 2.07 2.11健康人: 0.54 0.64 0.64 0.75 0.76 0.81 1.16 1.20 1.34 1.35 1.48 1.56 1.87让我们把要做的事情理理顺:首先要做的肯定是打开计算机(废话),然后进入瘟98或瘟2000(还是废话,以下省去废话2万字),在进入SPSS后,具体工作流程如下:1.将数据输入SPSS,并存盘以防断电。
spss相关分析案例多因素方差分析
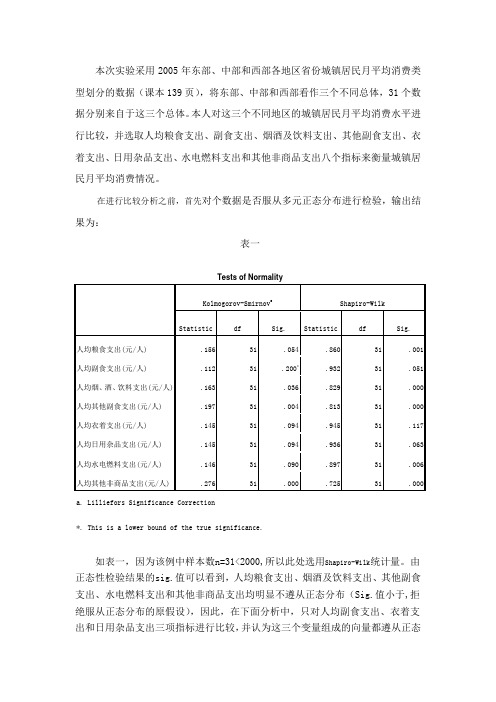
本次实验采用2005年东部、中部和西部各地区省份城镇居民月平均消费类型划分的数据(课本139页),将东部、中部和西部看作三个不同总体,31个数据分别来自于这三个总体。
本人对这三个不同地区的城镇居民月平均消费水平进行比较,并选取人均粮食支出、副食支出、烟酒及饮料支出、其他副食支出、衣着支出、日用杂品支出、水电燃料支出和其他非商品支出八个指标来衡量城镇居民月平均消费情况。
在进行比较分析之前,首先对个数据是否服从多元正态分布进行检验,输出结果为:表一如表一,因为该例中样本数n=31<2000,所以此处选用Shapiro-Wilk统计量。
由正态性检验结果的sig.值可以看到,人均粮食支出、烟酒及饮料支出、其他副食支出、水电燃料支出和其他非商品支出均明显不遵从正态分布(Sig.值小于,拒绝服从正态分布的原假设),因此,在下面分析中,只对人均副食支出、衣着支出和日用杂品支出三项指标进行比较,并认为这三个变量组成的向量都遵从正态分布,并对城镇居民月平均消费状况做出近似的度量。
另外,正态性的检验还可以通过Q-Q图来实现,此时应判别数据点是否与已知直线拟合得好。
如果数据点均落在直线附近,说明拟合得好,服从正态分布,反之,不服从。
具体情况这里不再赘述。
下面进行多因素方差分析:一、多变量检验表二由地区一栏的(即第二栏)所列几个统计量的Sig.值可以看到,无论从那个统计量来看,三个地区的城镇居民月平均消费水平都是有显著差别的(Sig.值小于,拒绝地区取值不同,对Y,即城镇居民月平均消费水平的取值没有显著影响的原假设)。
二、主体间效应检验表三如表三,可以看到三个指标地区一栏的(即第三栏)Sig.值分别为、、,说明三个地区在人均衣着支出指标上没有明显的差别(Sig.值大于,不拒绝地区取值不同,对指标的取值没有显著影响的原假设),反之,而在人均副食支出和日用杂品支出指标上有显著差别。
三、多重比较表四Contrast Results (K Matrix)地区 Simple Contrast aDependent Variable 人均副食支出(元/人)人均日用杂品支出(元/人)人均衣着支出(元/人)Level 1 vs. Level 3 Contrast EstimateHypothesized Value0 0 0 Difference (Estimate - Hypothesized) Std. Error Sig..001.036.51795% Confidence Interval for DifferenceLower Bound.173Upper BoundLevel 2 vs. Level 3 Contrast EstimateHypothesized Value0 0 0 Difference (Estimate - Hypothesized) Std. Error Sig..668.343.63895% Confidence Interval for DifferenceLower BoundUpper Bound表四Contrast Results (K Matrix)地区 Simple Contrast aDependent Variable 人均副食支出(元/人)人均日用杂品支出(元/人)人均衣着支出(元/人)Level 1 vs. Level 3 Contrast EstimateHypothesized Value0 0 0 Difference (Estimate - Hypothesized) Std. Error Sig..001.036.51795% Confidence Interval for DifferenceLower Bound.173Upper BoundLevel 2 vs. Level 3 Contrast EstimateHypothesized Value0 0 0 Difference (Estimate - Hypothesized) Std. Error Sig..668.343.63895% Confidence Interval for DifferenceLower BoundUpper Bounda. Reference category = 3如表四,在显著水平下,东部和西部的人均副食支出(Sig.值为)和日用杂品支出(Sig.值为)指标有明显差别(小于,拒绝原假设),而在人均衣着支出(Sig.值为)指标上没有明显的差别。
用SPSS进行相关分析的典型案例
数据预处理
缺失值处理
对于缺失值,可以采用删除缺失样本、均值插补、多重插补等方法进行处理。在本案例中,由于缺失值较少,采用删 除缺失样本的方法进行处理。
异常值处理
对于异常值,可以采用箱线图、散点图等方法进行识别和处理。在本案例中,通过箱线图发现存在少数极端异常值, 采用删除异常样本的方法进行处理。
数据标准化
06
典型案例三:经济学领域 应用
案例背景介绍
研究目的
探讨某国经济增长与失业率之间的关系 。
VS
数据来源
采用某国统计局发布的年度经济数据,包 括GDP增长率、失业率等指标。
SPSS操作步骤详解
1. 数据导入与整理 将原始数据导入SPSS软件。 对数据进行清洗和整理,确保数据质量和准确性。
SPSS操作步骤详解
显著性检验
观察相关系数旁边的显著性水平 (p值),判断相关关系是否具有 统计显著性。通常情况下,p值小 于0.05被认为具有统计显著性。
结果讨论
结合相关系数和显著性检验结果 ,讨论社会经济地位与心理健康 之间的关系。例如,可以探讨不 同教育水平或职业对心理健康的 影响,以及这种关系在不同人群 中的差异。
关注SPSS输出的显著性检验结果。如 果P值小于设定的显著性水平(如 0.05),则认为药物剂量与症状改善 程度之间的相关性是显著的,即两变 量之间存在统计学意义的关联。
结合专业背景和实际情境,对结果进 行解释和讨论。例如,如果药物剂量 与症状改善程度呈正相关且相关性显 著,可以认为增加药物剂量有助于改 善患者症状。同时,需要注意结果的 局限性和可能的影响因素,以便为医 学实践提供有价值的参考信息。
提出政策建议或未来研究方向,以促进经济增长和降 低失业率。
SPSS实验5-相关分析
SPSS作业5:相关分析(一)相关分析研究背景:能源是经济增长的战略投入要素,在经济增长初期,能源的投入能够带动经济快速增长。
理论上认为影响能源消费需求总量的因素主要有经济发展水平、产业发展、能源生产总量、人口总数等。
这里将研究能源消费需求总量X1,国内生产总值X2,工业增加值X3,建筑业增加值X4,交通运输邮电业增加值X5,人均电力消费X6,能源加工转换效率X7的关系。
绘制散点图的基本操作:(1)选择菜单Graph s―Scatter;(2)分别作简单散点图,矩阵散点图,结果如下:分析:从上可知:能源消费需求总量X1与国内生产总值X2呈强正线性相关。
分析:能源消费需求总量,工业增加值以及建筑业增加值三者之间,两两呈较强正线性相关。
分析:能源消费需求总量,国内生产总值以及能源加工转换率这三者之间,只有能源消费需求总量与国内生产总值呈较强正线性相关,而能源消费需求总量与能源加工转换率,国内生产总值与能源加工转换率之间呈弱相关。
计算相关系数的基本操作:(1)选择菜单Analyz e―Correlate―Bivariate;(2)选择所需计算的相关系数,双尾或单尾检验p值;(3)在Option按钮的Statistics选项中,选择Cros s―product deviations and covariances,结果如下:分析:由表可知,能源消费需求总量与国内生产总值的简单相关系数为0.984,与能源加工转换率间的简单相关系数为0.716。
它们的相关系数检验的概率p值都近似为0。
因此,当显著性水平a=0.05或0.01时,都应拒绝相关系数检验的零假设,认为两总体存在线性关系。
总之,能源消费需求总量将受国内生产总值,能源加工转换率的正向影响。
同样的基本操作,对能源消费需求总量,国内生产总值,人均电力消费作分析:对能源消费需求总量,国内生产总值,工业增加值做分析:对能源消费分析:能源消费需求总量与国内生产总值,人均电力消费的简单相关系数分别为0.984,0.980,对应的p值近似为0,因此都拒绝原假设,认为两总体存在线性关系。
SPSS典型相关分析及结果解释
SPSS典型相关分析及结果解释SPSS 11.0 - 23.0典型相关分析1方法简介如果要研究一个变量和一组变量间的相关,则可以使用多元线性回归,方程的复相关系数就是我们要的东西,同时偏相关系数还可以描述固定其他因素时某个自变量和应变量间的关系。
但如果要研究两组变量的相关关系时,这些统计方法就无能为力了。
比如要研究居民生活环境与健康状况的关系,生活环境和健康状况都有一大堆变量,如何来做?难道说做出两两相关系数?显然并不现实,我们需要寻找到更加综合,更具有代表性的指标,典型相关(Canonical Correlation)分析就可以解决这个问题。
典型相关分析方法由Hotelling提出,他的基本思想和主成分分析非常相似,也是降维。
即根据变量间的相关关系,寻找一个或少数几个综合变量(实际观察变量的线性组合)对来替代原变量,从而将二组变量的关系集中到少数几对综合变量的关系上,提取时要求第一对综合变量间的相关性最大,第二对次之,依此类推。
这些综合变量被称为典型变量,或典则变量,第1对典型变量间的相关系数则被称为第1典型相关系数。
一般来说,只需要提取1~2对典型变量即可较为充分的概括样本信息。
可以证明,当两个变量组均只有一个变量时,典型相关系数即为简单相关系数;当一组变量只有一个变量时,典型相关系数即为复相关系数。
故可以认为典型相关系1数是简单相关系数、复相关系数的推广,或者说简单相关系数、复相关系数是典型相关系数的特例。
2引例及语法说明在SPSS中可以有两种方法来拟合典型相关分析,第一种是采用Manova过程来拟合,第二种是采用专门提供的宏程序来拟合,第二种方法在使用上非常简单,而输出的结果又非常详细,因此这里只对它进行介绍。
该程序名为Canonical correlation.sps,就放在SPSS的安装路径之中,调用方式如下:INCLUDE 'SPSS所在路径\Canonical correlation.sps'.CANCORR SET1=第一组变量的列表/SET2=第二组变量的列表.在程序中首先应当使用include命令读入典型相关分析的宏程序,然后使用cancorr名称调用,注意最后的“.”表示整个语句结束,不能遗漏。
SPSS 典型相关分析案例
SPSS典型相关分析是一种通过分析一组变量与另一组变量之间的相关性来解释对方变量
差异的统计方法。
在企业管理和人力资源管
理领域,这种方法常被用来研究员工工作满
意度与各种因素的关系,并制定相关的管理
策略。
以下是一个SPSS典型相关分析的案例。
假设我们有一个样本,由100名员工组成,我们想要研究员工工作满意度与以下9个因
素之间的关系:薪酬、晋升机会、培训机会、福利、工作环境、工作内容、工作压力、同
事关系和公司文化。
在进行典型相关分析之前,我们需要将这些变量进行预处理,即去
除不需要的变量、处理缺失值和异常值等。
然后,我们进入SPSS软件,点击“Analyze”菜单下的“Canonical Correlation”命令,在打开的对话框中选择所有9个因素和员工
满意度作为“Variable(s)”并点击“OK”按钮。
SPSS会自动给出相应的结果,包括典型相关系数、方差解释比、典型相关变量等。
假设结果表明第一个典型相关系数为0.70,方差解释比为49%,前三个典型相关变量分别是薪酬、晋升机会和工作内容。
这意味着
这三个变量与员工工作满意度的关系最为密切,可以通过调整这些变量来提高员工的工
作满意度。
具体的建议可以根据调查结果和
实际情况制定,比如提高薪酬水平、加强晋升机会和职业发展支持、改善工作环境等。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
相关分析一、两个变量的相关分析:Bivariate1.相关系数的含义相关分析是研究变量间密切程度的一种常用统计方法。
相关系数是描述相关关系强弱程度和方向的统计量,通常用r 表示。
①相关系数的取值范围在-1和+1之间,即:–1≤r ≤ 1。
②计算结果,若r 为正,则表明两变量为正相关;若r 为负,则表明两变量为负相关。
③相关系数r 的数值越接近于1(–1或+1),表示相关系数越强;越接近于0,表示相关系数越弱。
如果r=1或–1,则表示两个现象完全直线性相关。
如果=0,则表示两个现象完全不相关(不是直线相关)。
④3.0<r ,称为微弱相关、5.03.0<≤r ,称为低度相关、8.05.0<≤r ,称为显著(中度)相关、18.0<≤r ,称为高度相关⑤r 值很小,说明X 与Y 之间没有线性相关关系,但并不意味着X 与Y 之间没有其它关系,如很强的非线性关系。
⑥直线相关系数一般只适用与测定变量间的线性相关关系,若要衡量非线性相关时,一般应采用相关指数R 。
2.常用的简单相关系数(1)皮尔逊(Pearson )相关系数皮尔逊相关系数亦称积矩相关系数,1890年由英国统计学家卡尔•皮尔逊提出。
定距变量之间的相关关系测量常用Pearson 系数法。
计算公式如下:∑∑∑===----=n i n i i i n i i i y y x xy y x x r 11221)()())(( (1) (1)式是样本的相关系数。
计算皮尔逊相关系数的数据要求:变量都是服从正态分布,相互独立的连续数据;两个变量在散点图上有线性相关趋势;样本容量30≥n 。
(2)斯皮尔曼(Spearman )等级相关系数Spearman 相关系数又称秩相关系数,是用来测度两个定序数据之间的线性相关程度的指标。
当两组变量值以等级次序表示时,可以用斯皮尔曼等级相关系数反映变量间的关系密切程度。
它是根据数据的秩而不是原始数据来计算相关系数的,其计算过程包括:对连续数据的排秩、对离散数据的排序,利用每对数据等级的差额及差额平方,通过公式计算得到相关系数。
其计算公式为:()16122--=∑n n d r R (2)(2)式中,R r 为等级相关系数;d 为每对数据等级之差;n 为样本容量。
斯皮尔曼等级相关对数据条件的要求没有积差相关系数严格,只要两个变量的观测值是成对的等级评定资料,或者是由连续变量观测资料转化得到的等级资料,不论两个变量的总体分布形态、样本容量的大小如何,都可以用斯皮尔曼等级相关来进行研究。
(3)肯德尔(Kendall )等级相关系数肯德尔(Kendall )等级相关系数是在考虑了结点(秩次相同)的条件下,测度两组定序数据或等级数据线性相关程度的指标。
它利用排序数据的秩,通过计算不一致数据对在总数据对中的比例,来反映变量间的线性关系的。
其计算公式如下:()141--=∑n n i r K (3)(3)式中,K r 是肯德尔等级相关系数;i 是不一致数据对数;n 为样本容量。
计算肯德尔等级相关系数的数据要求与计算斯皮尔曼等级相关系数的数据要求相同。
3.相关系数的显著性检验通常,我们用样本相关系数r 作为总体相关系数ρ的估计值,而r 仅说明样本数据的X 与Y 的相关程度。
有时候,由于样本数据太少或其它偶然因素,使得样本相关系数r 值很大,而总体的X 与Y 并不存在真正的线性关系。
因而有必要通过样本资料来对X 与Y 之间是否存在真正的线性相关进行检验,即检验总体相关系数ρ是否为零(即原假设是:总体中两个变量间的相关系数为0)。
SPSS 的相关分析过程给出了该假设成立的概率(输出结果中的Sig.)。
样本简单相关系数的检验方法为:当原假设0H :0=ρ,50≥n 时,检验统计量为:211rn r Z --= (4) 当原假设0H :0=ρ,50<n 时,检验统计量为:212r n r t --= ()2-=n df (5)式中,r 为简单相关系数;n 为观测值个数(或样本容量)。
4.背景材料设有10个厂家,序号为1,2,…,10,各厂的投入成本记为x ,所得产出记为y 。
各厂家的投入和产出如表7-18-1所示,根据这些数据,可以认为投入和产出之间存在相关性吗?表1 10个厂家的投入产出 单位:万元5.操作步骤5-1 绘制散点图的步骤(1)选择菜单命令“Graphs ”→“Legacy Dialogs ”→“Scatter/Dot ”,打开Scatter/Dot 对话框,如图1所示。
图1 选择散点图窗口(2)选择散点图类型。
SPSS 提供了五种类型的散点图。
(3)根据所选择的散点图类型,单击“Define”按钮设置散点图。
不同类型的散点图的设置略有差别。
①简单散点图(Simple Scatter)简单散点图的设置窗口如图2所示。
图2 简单散点图的设置窗口从对话框左侧的变量列表中指定某个变量为散点图的纵坐标和横坐标,分别选入Y-Axis和X-Axis框中。
这两项是必选项。
可以把作为分组的变量指定到Set Markers by框中,根据该变量取值的不同对同一个散点图中的各点标以不同的颜色(或形状)。
该项可以省略。
把标记变量指定到Label Cases by框中,表示将标记变量的各变量值标记在散点图的旁边。
该项可以省略。
从左侧变量列表框中选择变量到Panel by框中作为分类变量,可以使该变量作为行(Rows)或列(Columns)将数据分成不同的组,便于比较。
该项可以省略。
选择Use Chart Specifications From选项,可以选择散点图的文件模板,单击“File”可以选择指定的文件。
单击“Title”按钮可以对散点图的标题进行设置,单击“Options”按钮可以对缺失值以及是否显示数据的标注进行设置。
②重叠散点图(Overlay Scatter)重叠散点图能同时生成多对相关变量间统计关系的散点图,首先根据分类变量的不同取值对原始数据进行分类,然后对各分类数据做简单散点图。
重叠散点图的设置窗口如图7-18-3所示。
图3 重叠散点图的设置窗口从左侧框中选择一对变量进入Pairs框中,其中前一个为图的纵坐标变量(Y-Variable),后一个作为图的横轴变量(X-Variable),可以通过点击按钮进行横纵轴变量的调换。
其他设置与同简单散点图都相同。
③矩阵散点图(Matrix Scatter)矩阵散点图以方形矩阵的形式在多个坐标轴上分别显示多对变量间的统计关系。
矩阵散点图的关键是弄清各矩阵单元中的横纵变量。
矩阵散点图的设置窗口如图4所示。
图4 矩阵散点图的设置窗口把参与绘图的若干变量指定到Matrix Variables框中。
选择变量的先后顺序决定了矩阵对角线上变量的排列顺序。
其他设置也与简单散点图相同。
④三维散点图(3-D Scatter)三维散点图生成三个相关变量的三维散点图,由三个坐标轴对应变量的数据决定,它以立体图的形式展现三对变量间的统计关系。
设置窗口如图5所示。
图5 三维散点图设置窗口从左侧的变量列表中指定三个变量分别选入Y-Axis、X-Axis、Z-Axis框中。
其他设置均与简单散点图相同。
⑤单点散点图(Sample Dot)单点散点图生成单个变量的散点图,显示数值型变量的每一个观测值,这些值都堆积在X轴附近,由于没有指定Y轴,所以数据点的Y坐标没有特殊的含义。
设置窗口如图6所示。
图6 单点散点图设置窗口从左侧变量列表中选择一个变量选入X-Axis Variable框中。
其他设置与简单散点图相同。
5-2 计算简单相关系数的操作步骤通过散点图可以初步判断变量是否具有线性趋势。
对具有线性趋势的变量计算相应的简单相关系数的步骤如下:(1)选择菜单命令“Analyze”→“Correlate”→“Bivariate”,打开两变量相关分析的对话框,如图7所示。
图7 两变量相关分析窗口(2)选入需要进行相关分析的变量进入Variables框,至少需要选入两个,如选入“投入”、“产出”变量。
(3)在Correlation Coefficients复选框中选择需要计算的相关系数。
主要有:Pearson复选框:选择进行积距相关分析,即最常用的参数相关分析;Kendall's tau-b复选框:计算Kendall's等级相关系数;Spearman复选框:计算Spearman 相关系数,即最常用的非参数相关分析(秩相关)。
(4)Test of Significance单选框用于确定是进行相关系数的单侧(One-tailed)或双侧(Two-tailed)检验,系统默认双侧检验。
(5)Flag significant correlations用于确定是否在结果中用星号标记有统计学意义的相关系数,一般选中。
此时P<0.05的系数值旁会标记一个星号,P<0.01的则标记两个星号。
(6)单击Options按钮,弹出Options对话框,选择需要计算的描述统计量和统计分析,如图8所示。
图8 两变量相关分析的Options子对话框在Statistics复选框中定义各变量输出的描述统计量。
Means and standard deviations选项表示每个变量的样本均值和标准差;Cross-product deviations and covariances选项表示各对变量的离差平方和、样本方差、两变量的叉积离差以及协方差阵。
叉积离差为Pearson相关系数公式中的分子部分;协方差为叉积离差/(n-1)。
在Missing Values单选框中定义分析中对缺失值的处理方法,可以是具体分析用到的两个变量有缺失值才去除该记录(Exclude cases pairwise),或只要该记录中进行相关分析的变量有缺失值(无论具体分析的两个变量是否缺失),则在所有分析中均将该记录去除(Excludes cases listwise)。
(7)单击“OK”按钮完成设置,提交运行。
6.结果解析根据背景资料,利用表1中的数据,建立SPSS数据文件,分别将变量投入、产出选入Variables框中,并在Options子对话框选中Means and standard deviations 选项和Cross-product deviations and covariances选项,其他选择默认。
结果如表2、表3所示。
6-1 表2为描述统计量,表3为相关分析结果。
从表3中可以看出皮尔逊相关系数为0.759,即投入与产出的相关系数为0.759,双侧检验的P值为0.011,明显小于0.05,拒绝二者不相关的原假设。
因此,我们可以得出结论:可以认为投入与产出之间存在正相关,当投入增加时,产出也会相应增加。