编译原理第6章习题答案
编译原理附标准答案60861

第 2 章 习题2-1 设有字母表 A 1 ={a,b,c, ⋯,z} ,A 2 ={0,1, ⋯,9} ,试回答下 列问题:(1) 字母表 A 1上长度为 2 的符号串有多少个?(2) 集合 A 1A 2 含有多少个元素?(3) 列出集合 A 1(A 1∪A 2) *中的全部长度不大于 3 的符号串。
2- 2 试分别构造产生下列语言的文法:(1){a n b n |n ≥0};(2){a n b m c p |n,m,p ≥0};(3){a n #b n |n ≥ 0} ∪{c n #d n |n ≥0};( 4){w#w r # | w ∈{0,1} *,w r 是 w 的逆序排列 } ; ( 5)任何不是以 0 打头的所有奇整数所组成的集合;(6)所有由偶数个 0 和偶数个 1 所组成的符号串的集合。
2- 3 试描述由下列文法所产生的语言的特点: 1) S →10S0 S →aA A →bA A →a 2) S →SS S →1A0 A →1A0 A →ε 3) S →1A S →B0 A →1A A →CB → B0 B →C C →1C0 C →ε( 4)S →aSS S →a2- 4 试证明文法S →AB|DC A →aA|a B →bBc|bc C → cC|c D →aDb|ab 矚慫润厲钐瘗睞枥庑赖。
为二义性文法。
2- 5 对于下列的文法S→AB|c A → bA|a B →aSb|c试给出句子 bbaacb 的最右推导,并指出各步直接推导所得句型的句柄;指出句子的全部短语。
2- 6 化简下列各个文法(1)S →aABS|bCACd A → bAB|cSA|cCC B →bAB|cSB C → cS|c 聞創沟燴鐺險爱氇谴净。
(2)S → aAB|E A →dDA|e B → bE|fC→cAB|dSD|a D → eA E →fA|g(3)S → ac|bA A →cBC B →SA C → bC|d2-7 消除下列文法中的ε- 产生式(1)S →aAS|b A →cS| ε(2)S →aAA A →bAc|dAe| ε2-8 消除下列文法中的无用产生式和单产生式(1)S →aB|BC A →aA|c|aDb B →DB|C C →b D →B(2)S → SA|SB|A A → B|(S)|( ) B → [S]|[ ](3)E →E+T|T T → T*F|F F →P↑F|P P →(E)|i第 2 章习题答2- 1 答:(1)26*26=676(2)26*10=260(3) {a,b,c,...,z, a0,a1,...,a9, aa,...,az,...,zz,a00,a01,...,zzz}, 共有 26+26*36+26*36*36=34658 个残骛楼諍锩瀨濟溆塹籟。
哈工大编译原理习题及答案

1.1何谓源程序、目标程序、翻译程序、编译程序和解释程序?它们之间可能有何种关系?1.2一个典型的编译系统通常由哪些部分组成?各部分的主要功能是什么?1.3选择一种你所熟悉的程序设计语言,试列出此语言中的全部关键字,并通过上机使用该语言以判明这些关键字是否为保留字。
1.4选取一种你所熟悉的语言,试对它进行分析,以找出此语言中的括号、关键字END以及逗号有多少种不同的用途。
1.5试用你常用的一种高级语言编写一短小的程序,上机进行编译和运行,记录下操作步骤和输出信息,如果可能,请卸出中间代码和目标代码。
第一章习题解答1.解:源程序是指以某种程序设计语言所编写的程序。
目标程序是指编译程序(或解释程序)将源程序处理加工而得的另一种语言(目标语言)的程序。
翻译程序是将某种语言翻译成另一种语言的程序的统称。
编译程序与解释程序均为翻译程序,但二者工作方法不同。
解释程序的特点是并不先将高级语言程序全部翻译成机器代码,而是每读入一条高级语言程序语句,就用解释程序将其翻译成一段机器指令并执行之,然后再读入下一条语句继续进行解释、执行,如此反复。
即边解释边执行,翻译所得的指令序列并不保存。
编译程序的特点是先将高级语言程序翻译成机器语言程序,将其保存到指定的空间中,在用户需要时再执行之。
即先翻译、后执行。
2.解:一般说来,编译程序主要由词法分析程序、语法分析程序、语义分析程序、中间代码生成程序、代码优化程序、目标代码生成程序、信息表管理程序、错误检查处理程序组成。
3.解:C语言的关键字有:auto break case char const continue default do double else enum externfloat for goto if int long register return short signed sizeof static struct switch typedef union unsigned void volatile while。
编译原理(清华大学-第2版)课后习题答案

编译原理(清华⼤学-第2版)课后习题答案第三章N=>D=> {0,1,2,3,4,5,6,7,8,9}N=>ND=>NDDL={a |a(0|1|3..|9)n且 n>=1}(0|1|3..|9)n且 n>=1{ab,}a nb n n>=1第6题.(1) <表达式> => <项> => <因⼦> => i(2) <表达式> => <项> => <因⼦> => (<表达式>) => (<项>)=> (<因⼦>)=>(i)(3) <表达式> => <项> => <项>*<因⼦> => <因⼦>*<因⼦> =i*i(4) <表达式> => <表达式> + <项> => <项>+<项> => <项>*<因⼦>+<项>=> <因⼦>*<因⼦>+<项> => <因⼦>*<因⼦>+<因⼦> = i*i+i (5) <表达式> => <表达式>+<项>=><项>+<项> => <因⼦>+<项>=i+<项> => i+<因⼦> => i+(<表达式>) => i+(<表达式>+<项>)=> i+(<因⼦>+<因⼦>)=> i+(i+i)(6) <表达式> => <表达式>+<项> => <项>+<项> => <因⼦>+<项> => i+<项> => i+<项>*<因⼦> => i+<因⼦>*<因⼦> = i+i*i第7题第9题语法树ss s* s s+aa a推导: S=>SS*=>SS+S*=>aa+a*11. 推导:E=>E+T=>E+T*F语法树:E+T*短语: T*F E+T*F直接短语: T*F句柄: T*F12.短语:直接短语:句柄:13.(1)最左推导:S => ABS => aBS =>aSBBS => aBBS=> abBS => abbS => abbAa => abbaa 最右推导:S => ABS => ABAa => ABaa => ASBBaa => ASBbaa => ASbbaa => Abbaa => a1b1b2a2a3 (2) ⽂法:S → ABSS → AaS →εA → aB → b(3) 短语:a1 , b1 , b2, a2 , , bb , aa , abbaa,直接短语: a1 , b1 , b2, a2 , ,句柄:a114 (1)S → ABA → aAb | εB → aBb | ε(2)S → 1S0S → AA → 0A1 |ε第四章1. 1. 构造下列正规式相应的DFA (1)1(0|1)*101NFA(2) 1(1010*|1(010)*1)*0NFA(3)NFA(4)NFA2.解:构造DFA 矩阵表⽰b其中0 表⽰初态,*表⽰终态⽤0,1,2,3,4,5分别代替{X} {Z} {X,Z} {Y} {X,Y} {X,Y,Z} 得DFA状态图为:3.解:构造DFA矩阵表⽰构造DFA的矩阵表⽰其中表⽰初态,*表⽰终态替换后的矩阵4.(1)解构造状态转换矩阵:{2,3} {0,1}{2,3}a={0,3}{2},{3},{0,1}{0,1}a={1,1} {0,1}b={2,2}(2)解:⾸先把M的状态分为两组:终态组{0},和⾮终态组{1,2,3,4,5} 此时G=( {0},{1,2,3,4,5} ) {1,2,3,4,5}a={1,3,0,5} {1,2,3,4,5}b={4,3,2,5}由于{4}a={0} {1,2,3,5}a={1,3,5}因此应将{1,2,3,4,5}划分为{4},{1,2,3,5}G=({0}{4}{1,2,3,5}){1,2,3,5}a={1,3,5}{1,2,3,5}b={4,3,2}因为{1,5}b={4} {23}b={2,3}所以应将{1,2,3,5}划分为{1,5}{2,3}G=({0}{1,5}{2,3}{4}){1,5}a={1,5} {1,5}b={4} 所以{1,5} 不⽤再划分{2,3}a={1,3} {2,3}b={3,2}因为 {2}a={1} {3}a={3} 所以{2,3}应划分为{2}{3}所以化简后为G=( {0},{2},{3},{4},{1,5})7.去除多余产⽣式后,构造NFA如下G={(0,1,3,4,6),(2,5)} {0,1,3,4,6}a={1,3}{0,1,3,4,6}b={2,3,4,5,6}所以将{0,1,3,4,6}划分为 {0,4,6}{1,3} G={(0,4,6),(1,3),(2,5)}{0,4,6}b={3,6,4} 所以划分为{0},{4,6} G={(0),(4,6),(1,3),(2,5)}不能再划分,分别⽤ 0,4,1,2代表各状态,构造DFA 状态转换图如下;b8.代⼊得S = 0(1S|1)| 1(0S|0) = 01(S|ε) | 10(S|ε) = (01|10)(S|ε)= (01|10)S | (01|10)= (01|10)*(01|10)构造NFA由NFA可得正规式为(01|10)*(01|10)=(01|10)+9.状态转换函数不是全函数,增加死状态8,G={(1,2,3,4,5,8),(6,7)}(1,2,3,4,5,8)a=(3,4,8) (3,4)应分出(1,2,3,4,5,8)b=(2,6,7,8)(1,2,3,4,5,8)c=(3,8)(1,2,3,4,5,8)d=(3,8)所以应将(1,2,3,4,5,8)分为(1,2,5,8), (3,4)G={(1,2,5,8),(3,4),(6,7)}(1,2,5,8)a=(3,4,8) 8应分出(1,2,5,8)b=(2,8)(1,2,5,8)c=(8)(1,2,5,8)d=(8)G={(1,2,5),(8),(3,4),(6,7)}(1,2,5)a=(3,4,8) 5应分出G={(1,2), (3,4),5, (6,7) ,(8) }去掉死状态8,最终结果为 (1,2) (3,4) 5,(6,7) 以1,3,5,6代替,最简DFA为b正规式:b*a(da|c)*bb*第五章1.S->a | ^ |( T )(a,(a,a))S => ( T ) => ( T , S ) => ( S , S ) => ( a , S) => ( a, ( T )) =>(a , ( T , S ) ) => (a , ( S , S )) => (a , ( a , a ) ) S=>(T) => (T,S) => (S,S) => ( ( T ) , S ) => ( ( T , S ) , S ) => ( ( T , S , S ) , S ) => ( ( S , S , S ) , S )=> ( ( ( T ) , S , S ) , S ) => ( ( ( T , S ) , S , S ) , S ) =>( ( ( S , S ) , S , S ) , S ) => ( ( ( a , S ) , S , S ) , S ) => ( ( ( a , a ) , S , S ) , S ) => ( ( ( a , a ) , ^ , S ) , S ) => ( ( ( a , a ) , ^ , ( T ) ) , S )=> ( ( ( a , a ) , ^ , ( S ) ) , S ) => ( ( ( a , a ) , ^ , ( a ) ) , S ) => ( ( ( a , a ) , ^ , ( a ) ) , a )S->a | ^ |( T )T -> T , ST -> S消除直接左递归:S->a | ^ |( T )T -> S T’T’ -> , S T’ | ξSELECT ( S->a) = {a}SELECT ( S->^) = {^}SELECT ( S->( T ) ) = { ( }SELECT ( T -> S T’) = { a , ^ , ( }SELECT ( T’ -> , S T’ ) = { , }SELECT ( T’ ->ξ) = FOLLOW ( T’ ) = FOLLOW ( T ) = { )}构造预测分析表分析符号串( a , a )#分析栈剩余输⼊串所⽤产⽣式#S ( a , a) # S -> ( T )# ) T ( ( a , a) # ( 匹配# ) T a , a ) # T -> S T’# ) T’ S a , a ) # S -> a# ) T’ a a , a ) # a 匹配# ) T’,a) # T’ -> , S T’# ) T’ S , , a ) # , 匹配# ) T’ S a ) # S->a# ) T’ a a ) # a匹配# ) T’) # T’ ->ξ# ) ) # )匹配# # 接受2.E->TE’E’->+E E’->ξT->FT’T’->T T’->ξF->PF’F’->*F’F’->ξP->(E) P->a P->b P->∧SELECT(E->TE’)=FIRST(TE’)=FIRST(T)= {(,a,b,^)SELECT(E’->+E)={+}SELECT(E’->ε)=FOLLOW(E’)= {#,)}SELECT(T->FT’)=FIRST(F)= {(,a,b,^}SELECT(T’ —>T)=FIRST(T)= {(,a,b,^)SELECT(T’->ε)=FOLLOW(T’)= {+,#,)}SELECT(F ->P F’)=FIRST(F)= {(,a,b,^}SELECT(F’->*F’)={*}SELECT(F’->ε)=FOLLOW(F’)= {(,a,b,^,+,#,)}3. S->MH S->a H->Lso H->ξK->dML K->ξL->eHf M->K M->bLM FIRST ( S ) =FIRST(MH)= FIRST ( M ) ∪FIRST ( H ) ∪{ξ}∪{a}= {a, d , b , e ,ξ} FIRST( H ) = FIRST ( L ) ∪{ξ}= { e , ξ}FIRST( K ) = { d , ξ}FIRST( M ) = FIRST ( K ) ∪{ b } = { d , b ,ξ}FOLLOW ( S ) = { # , o }FOLLOW ( H ) = FOLLOW ( S ) ∪{ f } = { f , # , o }FOLLOW ( K ) = FOLLOW ( M ) = { e , # , o }FOLLOW ( L ) ={ FIRST ( S ) –{ξ} } ∪{o} ∪FOLLOW ( K )∪{ FIRST ( M ) –{ξ} } ∪FOLLOW ( M )= {a, d , b , e , # , o }FOLLOW ( M ) ={ FIRST ( H ) –{ξ} } ∪FOLLOW ( S )∪{ FIRST ( L ) –{ξ} } = { e , # , o }SELECT ( S-> M H) = ( FIRST ( M H) –{ξ} ) ∪FOLLOW ( S )= ( FIRST( M ) ∪FIRST ( H ) –{ξ} ) ∪FOLLOW ( S )= { d , b , e , # , o }SELECT ( S-> a ) = { a }SELECT ( H->L S o ) = FIRST(L S o) = { e }SELECT ( H ->ξ) = FOLLOW ( H ) = { f , # , o }SELECT ( K->ξ) = FOLLOW ( K ) = { e , # , o }SELECT ( L-> e H f ) = { e }SELECT ( M->K ) = ( FIRST( K ) –{ξ} ) ∪FOLLOW ( M ) = {d,e , # , o }SELECT ( M -> b L M )= { b }4 . ⽂法含有左公因式,变为S->C $ { b, a }C-> b A { b }C-> a B { a }A -> b A A { b }A-> a A’ { a }A’-> ξ{ $ , a, b }A’-> C { a , b }B->a B B { a }B -> b B’ { b }B’->ξ{ $ , a , b }B’-> C { a, b }5. <程序> --- S <语句表>――A <语句>――B <⽆条件语句>――C <条件语句>――D <如果语句>――E <如果⼦句> --FS->begin A end S->begin A end { begin }A-> B A-> B A’ { a , if }A-> A ; B A’-> ; B A’ { ; }A’->ξ{ end }B-> C B-> C { a } B-> D B-> D { if }C-> a C-> a { a }D-> E D-> E D’ { if }D-> E else B D’-> else B { else }D’->ξ{; , end } E-> FC E-> FC { if }F-> if b then F-> if b then { if }⾮终结符是否为空S-否A-否A’-是B-否C-否D-否D’-是E-否F-否FIRST(S) = { begin }FIRST(A) = FIRST(B) ∪FIRST(A’) ∪{ξ} = {a , if , ; , ξ} FIRST(A’) ={ ; , ξ}FIRST(B) = FIRST(C) ∪FIRST(D) ={ a , if }FIRST(C) = {a}FIRST(D) = FIRST(E)= { if }FIRSR(D’) = {else , ξ}FIRST(E) = FIRST(F) = { if }FIRST(F) = { if }FOLLOW(S) = {# }FOLLOW(A) = {end}FOLLOW(A’) = { end }FOLLOW(B) = {; , end }FOLLOW (C) = {; , end , else }FOLLOW(D) = {; , end }FOLLOW( D’ ) = { ; , end }FOLLOW(E) = { else , ; end }FOLLOW(F) = { a }S A A’ B C D D’ E F if then else begin end a b ;6. 1.(1) S -> A | B(2) A -> aA|a(3)B -> bB |b提取(2),(3)左公因⼦(1) S -> A | B(2) A -> aA’(3) A’-> A|ξ(4) B -> bB’(5) B’-> B |ξ2.(1) S->AB(2) A->Ba|ξ(3) B->Db|D(4) D-> d|ξ提取(3)左公因⼦(1) S->AB(2) A->Ba|ξ(3) B->DB’(4) B’->b|ξ(5) D-> d|ξ3.(1) S->aAaB | bAbB(2) A-> S| db(3) B->bB|a4(1)S->i|(E)(2)E->E+S|E-S|S提取(2)左公因⼦(1)S->i|(E)(2)E->SE’(3)E’->+SE’|-SE’ |ξ5(1)S->SaA | bB(2)A->aB|c(3)B->Bb|d消除(1)(3)直接左递归(1)S->bBS’(2)S’->aAS’|ξ(3)A->aB | c(4) B -> dB’(5)B’->bB’|ξ6.(1) M->MaH | H(2) H->b(M) | (M) |b消除(1)直接左递归,提取(2)左公因⼦(1)M-> HM’(2)M’-> aHM’ |ξ(3)H->bH’ | ( M )(4)H’->(M) |ξ7. (1)1)A->baB4)B->a将1)、2)式代⼊3)式1)A->baB2)A->ξ3)B->baBbb4)B->bb5)B->a提取3)、4)式左公因⼦1)A->baB2)A->ξ3)B->bB’4)B’->aBbb | b5)B->a(3)1)S->Aa2)S->b3)A->SB4)B->ab将3)式代⼊1)式1)S->SBa2)S->b3)A->SB4)B->ab消除1)式直接左递归1)S->bS’2)S’->BaS’ |ξ3)S->b4)A->SB5)B->ab删除多余产⽣式4)1)S->bS’(5)1)S->Ab2)S->Ba3)A->aA4)A->a5)B->a提取3)4)左公因⼦1)S->Ab4)A’-> A |ξ5)B->a将3)代⼊1)5)代⼊21)S->aA’b2)S->aa3)A->aA’4)A’-> A |ξ5)B->a提取1)2)左公因⼦1)S-> aS’2)S’->A’b | a3)A->aA’4)A’-> A |ξ5)B->a删除多余产⽣式5)1)S-> aS’2)S’->A’b | a3)A->aA’4)A’-> A |ξA A’S’S将3)代⼊4)1)S-> aS’2)S’->A’b | a3)A->aA ’4)A’-> aA’ |ξ3)S’->a4)S’->b5)A->aA ’6)A’-> aA’ |ξ对2)3)提取左公因⼦1)S->aS’2)S’->aS’’3)S’’->A’b|ξ4)S’->b5)A->aA ’6)A’-> aA’ |ξ删除多余产⽣式5)1)S->aS’2)S’->aS’’3)S’’->A’b|ξ4)S’->b第六章1S → a | ∧ | ( T )T → T , S | S解:(1) 增加辅助产⽣式 S’→#S#求 FIRSTVT集FIRSTVT(S’)= {#}FIRSTVT(S)= {a ∧ ( }= { a ∧ ( } FIRSTVT (T) = {,} ∪ FIRSTVT( S ) = { , a ∧ ( }求 LASTVT集LASTVT(S’)= { # }LASTVT(S)= { a ∧ )}LASTVT (T) = { , a ∧ )}(2)因为任意两终结符之间⾄多只有⼀种优先关系成⽴,所以是算符优先⽂法(3)a ∧( ) , #F 1 1 1 1 1 1g 1 1 1 1 1 1f 2 2 1 3 2 1g 2 2 2 1 2 1f 3 3 1 3 3 1g 4 4 4 1 2 1f 3 3 1 3 3 1g 4 4 4 1 2 1(4)栈优先关系当前符号剩余输⼊串移进或规约#<·( a,a)# 移进#( <· a ,a)# 移进#(T <·, a)# 移进#(T,<· a )# 移进#(T,a ·> ) # 规约#(T,T ·> ) # 规约#(T =·) # 移进#(T) ·> #规约#T =·#接受4.扩展后的⽂法S’→#S# S→S;G S→G G→G(T) G→H H→a H→(S)T→T+S T→S(1)FIRSTVT(S)={;}∪FIRSTVT(G) = {; , a , ( }FIRSTVT(G)={ ( }∪FIRSTVT(H) = {a , ( }FIRSTCT(H)={a , ( }FIRSTVT(T) = {+} ∪FIRSTVT(S) = {+ , ; , a , ( }LASTVT(S) = {;} ∪LASTVT(G) = { ; , a , )}LASTVT(G) = { )} ∪LASTVT(H) = { a , )}LASTVT(H) = {a, )}LASTVT(T) = {+ } ∪LASTVT(S) = {+ , ; , a , ) }构造算符优先关系表因为任意两终结符之间⾄多只有⼀种优先关系成⽴,所以是算符优先⽂法(2)句型a(T+S);H;(S)的短语有:a(T+S);H;(S) a(T+S);H a(T+S) a T+S (S) H直接短语有: a T+S H (S)句柄: a素短语:a T+S (S)最左素短语:a(3)(4)不能⽤最右推导推导出上⾯的两个句⼦。
编译原理(龙书)课后习题解答(详细)

编译原理(龙书)课后习题解答(详细)编译原理(龙书)课后题解答第一章1.1.1 :翻译和编译的区别?答:翻译通常指自然语言的翻译,将一种自然语言的表述翻译成另一种自然语言的表述,而编译指的是将一种高级语言翻译为机器语言(或汇编语言)的过程。
1.1.2 :简述编译器的工作过程?答:编译器的工作过程包括以下三个阶段:(1) 词法分析:将输入的字符流分解成一个个的单词符号,构成一个单词符号序列;(2) 语法分析:根据语法规则分析单词符号序列中各个单词之间的关系,确定它们的语法结构,并生成抽象语法树;(3) 代码生成:根据抽象语法树生成目标程序(机器语言或汇编语言),并输出执行文件。
1.2.1 :解释器和编译器的区别?答:解释器和编译器的主要区别在于执行方式。
编译器将源程序编译成机器语言或汇编语言等,在运行时无需重新编译,程序会一次性运行完毕;而解释器则是边翻译边执行,每次执行都需要进行一次翻译,一次只执行一部分。
1.2.2 :Java语言采用的是解释执行还是编译执行?答:Java一般是编译成字节码的形式,然后由Java虚拟机(JVM)进行解释执行。
但是,Java也有JIT(即时编译器)的存在,当某一段代码被多次执行时,JIT会将其编译成机器语言,提升代码的执行效率。
第二章2.1.1 :使用BNF范式定义简单的加法表达式和乘法表达式答:<加法表达式> ::= <加法表达式> "+" <乘法表达式> | <乘法表达式><乘法表达式> ::= <乘法表达式> "*" <单项式> | <单项式><单项式> ::= <数字> | "(" <加法表达式> ")"2.2.3 :什么是自下而上分析?答:自下而上分析是指从输入字符串出发,自底向上构造推导过程,直到推导出起始符号。
编译原理课后答案-第二版
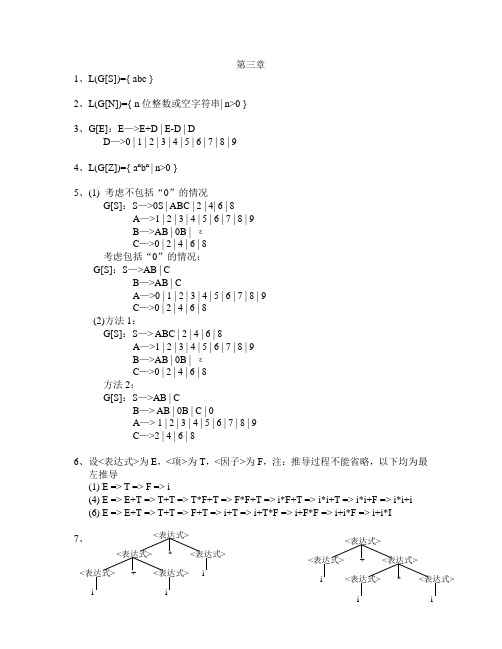
第三章1、L(G[S])={ abc }2、L(G[N])={ n位整数或空字符串| n>0 }3、G[E]:E—>E+D | E-D | DD—>0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 94、L(G[Z])={ a n b n | n>0 }5、(1) 考虑不包括“0”的情况G[S]:S—>0S | ABC | 2 | 4| 6 | 8A—>1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9B—>AB | 0B | εC—>0 | 2 | 4 | 6 | 8考虑包括“0”的情况:G[S]:S—>AB | CB—>AB | CA—>0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9C—>0 | 2 | 4 | 6 | 8(2)方法1:G[S]:S—> ABC | 2 | 4 | 6 | 8A—>1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9B—>AB | 0B | εC—>0 | 2 | 4 | 6 | 8方法2:G[S]:S—>AB | CB—> AB | 0B | C | 0A—> 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9C—>2 | 4 | 6 | 86、设<表达式>为E,<项>为T,<因子>为F,注:推导过程不能省略,以下均为最左推导(1) E => T => F => i(4) E => E+T => T+T => T*F+T => F*F+T => i*F+T => i*i+T => i*i+F => i*i+i(6) E => E+T => T+T => F+T => i+T => i+T*F => i+F*F => i+i*F => i+i*I7、<表达式><表达式>*<表达式><表达式>+<表达式>i i i<表达式><表达式>+<表达式>i <表达式>*<表达式>i i8、是有二义性的,因为句子abc 有两棵语法树(或称有两个最左推导或有两个最右推导)最左推导1:S => Ac => abc 最左推导2:S => aB => abc 9、(1)(2) 该文法描述了变量a 和运算符+、*组成的逆波兰表达式10、(1) 该文法描述了各种成对圆括号的语法结构(2) 是有二义性的,因为该文法的句子()()存在两种不同的最左推导: 最左推导1:S => S(S)S => (S)S => ()S => ()S(S)S => ()(S)S => ()()S => ()()最左推导2:S => S(S)S => S(S)S(S)S => (S)S(S)S=> ()S(S)S => ()(S)S => ()()S => ()()11、(1) 因为从文法的开始符E 出发可推导出E+T*F ,推导过程如下:E => E+T =>E+T*F ,所以E+T*F 是句型。
编译原理chapter6

宣布分析成功,退出总控程序。
第六章 LR分析法及分析程序构造 第二节 LR分析器 三、LR分析器的总控程序
4、报错
报告输入串含有错误,调用相应错误错误 处理程序。
注:1)不管哪一类分析程序,总控程序的动作 都一样。
2)LR分析器的动作情况也可以描述成机器内 部的格局间转换。
例:根据表达式文法的LR分析表分析输入串 i*i+i的LR动作过程。
状态栈
符号栈
输入串
动作
0
#
i*i+i#
05
#i
*i+i#
移进
03
#F
*i+i#
R6 归约
02
#T
027
#T*
*i+i#
R4 归约
i+i#
移进
0275
#T*i
+i#
移进
02710
#T*F
+i#
R6 归约
02
#T
+i#
R3 归约
01
#E
+i#
016
#E+
i#
R2 归约 移进
0165
#E+i
#
移进
0163
(2)与普通不带回溯的自上而下预测技术相比 也要好些。
(3)在自左向右扫描输入串时就能发现其中 的错误,并能准确地指出出错位置,其他分析 方法无法比拟。
第六章 LR分析法及分析程序构造 第一节 引言 三、LR分析法的缺点
若用手工构造分析程序,则工作量太大, 而且容易出错,因此,必须使用自动产生这种 分析程序的产生器。
4、若项目i为X•A,其中A是非终结符,则从 i项目画弧射向所有A• 的项目,V*
完整word版,汇编第六章答案,推荐文档
第六章答案=======================================1.下面的程序段有错吗?若有,请指出错误.CRAY PROCPUSH AXADD AX,BXRETENDP CRAY[解]:当然有错误,ENDP CRAY写反了,应该将其改成CRAY ENDP.2.已知堆栈寄存器SS的内容是0F0A0H,堆栈指示器SP的内容是00B0H,先执行两条把8057H和0F79BH分别入栈的PUSH指令.然后再执行一POP指令.试画出示意图说明堆栈及SP内容的变化过程.3.分析下面"6,3的程序",画出堆栈最满时各单元的地址及内容.; 6.3题的程序;===========================================S_SEG SEGMENT AT 1000H ;DEFINE STACK SEGMENTDW 200 DUP(?)TOS LABEL WORDS_SEG ENDSC_SEG SEGMENT ;DEFINE CODE SEGMENTASSUME CS:C_SEG,SS:S_SEGMOV AX,S_SEGMOV SS,AXMOV SP,OFFSET TOSPUSH DSMOV AX,0PUSH AX...PUSH T_ADDRPUSH AXPUSHF...POPFPOP AXPOP T_ADDRRETC_SEG ENDS ;END OF CODE SEGMENTEND C_SEG ;END OF ASSEMBLY4.分析下面"6.4题的程序"的功能,写出堆栈最满时各单元的地址及内容. ; 6.4题的程序;====================================STACK SEGMENT AT 500HDW 128 DUP(?)TOS LABEL WORDSTACK ENDSCODE SEGMENT ;DEFINE CODE SEGMENTMAIN PROC FAR ;MAIN PART OF PROGRAMASSUME CS:CODE,SS:STACKSTART: ;STARTING EXECUTION ADDRESSMOV AX,STACKMOV SS,AXMOV SP,OFFSET TOSPUSH DSSUB AX,AXPUSH AX;MAIN PART OF PROGRAM GOES HEREMOV AX,4321HCALL HTOARET ;RETURN TO DOSMAIN ENDP ;END OF MAIN PART OF PROGRAM HTOA PROC NEAR ;DEFINE SUBPROCEDURE HTOA CMP AX,15JLE B1PUSH AXPUSH BPMOV BP,SPMOV BX,[BP+2]AND BX,000FHMOV [BP+2],BXPOP BPMOV CL,4SHR AX,CLCALL HTOAPOP AXB1:ADD AL,30HCMP AL,3AHJL PRINTITADD AL,07HPRINTIT:MOV DL,ALMOV AH,2INT 21HRETHTOA ENDP ;END OF SUBPROCEDURECODE ENDS ;END OF CODE SEGMENTEND START ;END OF ASSEMBLY5.下面是6.5题的程序清单,请在清单中填入此程序执行过程中的堆栈变化. 0000 STACKSG SEGMENT0000 20 [. DW 32 DUP(?)????0040 ]STACKSG ENDS0000 CODESG SEGMENT PARA 'CODE'0000 BEGIN PROC FARASSUME CS:CODESG,SS:STACKSG0000 1E PUSH DS0001 2B C0 SUB AX,AX0003 50 PUSH AX0004 E8 0008 R CALL P100007 CB RET0008 BEGIN ENDP0008 B10 PROC0008 E8 000C R CALL C10000B C3 RET000C B10 ENDP000C C10 PROC000C C3 RET000D C10 ENDP000D CODESG ENDSEND BEGIN6.写一段子程序SKIPLINES,完成输出空行的功能.空行的行数在AX寄存器中. [解]:SKIPLINES PROC NEARPUSH CXPUSH DXMOV CX,AXNEXT: MOV AH,2MOV DL,0AHINT 21HMOV AH,2MOV DL,0DHINT 21HLOOP NEXTPOP DXPOP CXRETSKIPLINES ENDP7.设有10个学生的成绩分别是76,69,81,90,73,88,99,63,100和80分.试编制一个子程序统计60-69,70-79,80-89,90-99和100分的人数并分别存放到S6,S7,S8,S9和S10单元中.DSEG SEGMENTNUM DW 76,69,84,90,73,88,99,63,100,80N DW 10S6 DW 0S7 DW 0S8 DW 0S9 DW 0S10 DW 0DSEG ENDSCODE SEGMENTMAIN PROC FARASSUME CS:CODE, DS:DSEGSTART:PUSH DSSUB AX, AXPUSH AXMOV AX, DSEGMOV DS, AXCALL SUB1RETMAIN ENDPSUB1 PROC NEARPUSH AXPUSH BXPUSH CXPUSH SIMOV SI, 0MOV CX, NNEXT:MOV AX, NUM[SI]MOV BX, 10DIV BLMOV BL, ALCBWSUB BX, 6SAL BX, 1INC S6[BX]ADD SI,2LOOP NEXTPOP SIPOP CXPOP BXPOP AXRETSUB1 ENDPCODE ENDSEND START(解法二)datasg segmentgrade db 76,69,84,90,73,88,99,63,100,80 s6 db 0s7 db 0s8 db 0s9 db 0s10 db 0mess6 db '60~69:$'mess7 db '70~79:$'mess8 db '80~89:$'mess9 db '90~99:$'mess10 db '100:$'datasg endscodesg segmentmain proc farassume cs:codesg,ds:datasg start:push dssub ax,axpush axmov ax,datasgmov ds,axcall sub1lea dx,mess6call dispstrmov dl,s6call dispscorecall crlflea dx,mess7call dispstrmov dl,s7call dispscorecall crlflea dx,mess8call dispstrmov dl,s8call dispscorecall crlflea dx,mess9call dispstrmov dl,s9call dispscorecall crlflea dx,mess10call dispstrmov dl,s10call dispscorecall crlfretmain endpsub1 proc nearmov cx,10mov si,0loop1: mov al,grade[si]cmp al,60jl next5cmp al,70jge next1inc s6jmp short next5 next1: cmp al,80jge next2inc s7jmp short next5 next2: cmp al,90jge next3inc s8jmp short next5 next3: cmp al,100jg next5je next4inc s9jmp short next5next4: inc s10next5: inc siloop loop1retsub1 endpdispstr proc nearmov ah,9int 21hdispstr endpdispscore proc nearadd dl,30hmov ah,2int 21hdispscore endpcrlf proc nearmov dl,0dhmov ah,2int 21hmov dl,0ahmov ah,2int 21hretcrlf endpcodesg endsend start8.编写一个有主程序和子程序结构的程序模块.子程序的参数是一个N字节数组的首地址TABLE,数N及字符CHAR.要求在N字节数组中查找字符CHAR,并记录该字符的出现次数.;主程序则要求从键盘接收一串字符以建立字节数组TABLE,并逐个显示从键盘输入的每个字符CHAR以及它在TABLE数组中出现的次数.(为简化起见,假设出现次数<=15,可以用十六进制形式显示出来)[解]:DATA SEGMENTMAXLEN DB 40N DB ?TABLE DB 40 DUP (?)CHAR DB 'A' ; 查找字符'A'EVEN_ADDR DW 3 DUP(?)DATA ENDSCODE SEGMENTASSUME CS:CODE, DS:DATAMAIN PROC FARSTART:PUSH DSMOV AX, 0PUSH AXMOV AX, DATAMOV DS, AXLEA DX, MAXLENMOV AH, 0AHINT 21H ; 从键盘接收字符串MOV _ADDR, OFFSET TABLEMOV _ADDR+2, OFFSET NMOV _ADDR+4, OFFSET CHARMOV BX, OFFSET _ADDR ; 通过地址表传送变量地址CALL COUNT ; 计算CHAR的出现次数CALL DISPLAY ; 显示RETMAIN ENDPCOUNT PROC NEAR ; COUNT子程序PUSH SIPUSH DIPUSH AXPUSH CXMOV DI, [BX]MOV SI, [BX+2]MOV CL, BYTE PTR[SI]MOV CH, 0MOV SI, [BX+4]MOV AL, BYTE PTR[SI]MOV BX, 0AGAIN:CMP AL, BYTE PTR[DI]JNE L1INC BXL1: INC DILOOP AGAINPOP CXPOP AXPOP DIPOP SIRETCOUNT ENDPDISPLAY PROC NEAR ; DISPLAY子程序CALL CRLF ; 显示回车和换行MOV DL, CHARMOV AH, 2INT 21HMOV DL, 20HMOV AH, 2INT 21HMOV AL, BLAND AL, 0FHADD AL, 30HCMP AL, 3AHJL PRINTADD AL, 7PRINT:MOV DL, ALINT 21HCALL CRLFRETDISPLAY ENDPCRLF PROC NEAR ; CRLF子程序MOV DL, 0DHMOV AH, 2INT 21HMOV DL, 0AHMOV AH, 2INT 21HRETCRLF ENDPCODE ENDSEND START9.编写一个子程序嵌套结构的程序模块,分别从键盘输入姓名及8个字符的电话号码,并以一定的格式显示出来.主程序TELIST:(1)显示提示符INPUT NAME:;(2)调用子程序INPUT_NAME输入姓名:(3)显示提示符INPUT A TELEPHONE NUMBER:;(4)调用子程序INPHONE输入电话号码;(5)调用子程序PRINTLINE显示姓名及电话号码;子程序INPUT_NAME:(1)调用键盘输入子程序GETCHAR,把输入的姓名存放在INBUF缓冲区中;(2)把INBUF中的姓名移入输出行OUTNAME;子程序INPHONE:(1)调用键盘输入子程序GETCHAR,把输入的8位电话号码存放在INBUF缓冲区中;(2)把INBUF中的号码移入输出行OUTPHONE.子程序PRINTLINE:显示姓名及电话号码,格式为:NAME TEL**** ********==========================================;编写一个子程序嵌套结构的程序模块,分别从键盘输入姓名及8个字符的电话号码,并以一定的格式显示出来(解法一)data segmentNo_of_name db 20No_of_phone db 8inbuf db 20 dup(?)outname db 20 dup(?),'$'outphone db 8 dup(?),'$'message1 db 'please input name:','$'message2 db 'please input a telephone number:','$'message3 db 'NAME',16 dup(20h),'TEL.',13,10,'$'errormessage1 db 'you should input 8 numbers!',13,10,'$'errormessage2 db 'you input a wrong number!',13,10,'$'flag db ?data endsprog segmentmain proc farassume cs:prog,ds:datastart:push dssub ax,axpush axmov ax,datamov ds,axmov flag,0lea dx,message1mov ah,09int 21hcall input_namecall crlflea dx,message2mov ah,09int 21hcall inphonecall crlfcmp flag,1je exitcall printline exit:retmain endpinput_name proc nearpush axpush dxpush cxmov cx,0mov cl,No_of_namecall getcharmov ax,0mov al,No_of_namesub ax,cxmov cx,axmov si,0next1:mov al,inbuf[si]mov outname[si],alinc siloop next1pop cxpop dxpop axretinput_name endpinphone proc nearpush axpush dxmov cx,0mov cl,No_of_phonecall getcharcmp cx,0jnz error1mov cl,No_of_phonemov si,0next2:mov al,inbuf[si]cmp al,30hjl error2cmp al,39hja error2mov outphone[si],alinc siloop next2jmp exit2error1:call crlflea dx,errormessage1mov ah,09int 21hmov flag,1jmp exit2error2:call crlflea dx,errormessage2mov ah,09int 21hmov flag,1jmp exit2exit2:pop dxpop axretinphone endpgetchar proc nearpush axpush dxmov di,0rotate:mov ah,01int 21hcmp al,0dhje exit1mov inbuf[di],alinc diloop rotateexit1:pop dxpop axretgetchar endpcrlf proc nearpush axpush dxmov dl,0dhmov ah,2int 21hmov dl,0ahmov ah,2int 21hpop dxpop axretcrlf endpprintline proc nearpush axpush dxlea dx,message3mov ah,09int 21hlea dx,outnamemov ah,09int 21hlea dx,outphonemov ah,09int 21hpop dxpop axretprintline endpprog endsend main==========================================;从键盘输入姓名及8个字符的电话号码,并以一定的格式显示出来datarea segmentinbuf label byte;name parameter list:maxnlen db 9;max.lengthnamelen db ?;no. char enterednamefld db 9 dup(?)crlf db 13,10,'$'messg1 db 'INPUT NAME:',13,10,'$'messg2 db 'INPUT A TELEPHONE NUMBER:',13,10,'$' messg3 db 'NAME TEL ',13,10,'$'OUTNAME db 21 dup(?),'$'OUTPHONE db 8 dup(?),'$'datarea endsprognam segmentassume cs:prognam,ds:datareastart: push dssub ax,axpush axmov ax,datareamov ds,axmov es,ax TELIST proc farmov ah,09lea dx,messg1int 21hcall INPUT_NAMEmov ah,09lea dx,messg2int 21hcall INPHONEcall PRINTLINEretTELIST endpINPUT_NAME proc nearcall GETCHARmov bh,0mov bl,namelenmov cx,21sub cx,bxb20: mov namefld[bx],20hinc bxloop b20lea si,namefldlea di,OUTNAMEmov cx,9cldrep movsbretINPUT_NAME endpINPHONE proc nearcall GETCHARmov bh,0mov bl,namelenmov cx,9sub cx,bxb30: mov namefld [bx],20hinc bxloop b30lea si,namefldlea di,OUTPHONEmov cx,8cldrep movsbretINPHONE endpPRINTLINE proc nearmov ah,09hlea dx,messg3int 21hmov ah,09lea dx,OUTNAMEint 21hmov ah,09lea dx,OUTPHONEint 21hretPRINTLINE endpGETCHAR proc nearmov ah,0ahlea dx,inbufint 21hmov ah,09lea dx,crlfint 21hretGETCHAR endpprognam endsend start==========================================10.编写子程序嵌套结构的程序,把整数分别用二进制和八进制形式显示出来.主程序BANDO:把整数字变量VAL1存入堆栈,并调用子程序PAIRS;子程序PAIRS:从堆栈中取出VAL1;调用二进制显示程序OUTBIN显示出与其等效的二进制数;输出8个空格;调用八进制显示程序OUTOCT显示出与其等效的八进制数;调用输出回车及换行符的子程序..model small.stack 100h.dataval1 dw 0ffffh.codemain proc farstart:push dssub ax,axmov ax,@data mov ds,ax push val1call pairsretmain endppairs proc near push bpmov bp,sp mov bx,[bp+4] call outbinmov cx,8loop1:mov dl,20h mov ah,2int 21hloop loop1call outoctcall crlfpop bpret 2pairs endpoutbin proc near mov cx,16 loop2:mov dl,0rol bx,1rcl dl,1or dl,30h mov ah,2int 21hloop loop2retoutbin endp outoct proc near mov dl,0rol bx,1rcl dl,1add dl,30h mov ah,2int 21hmov ch,5mov cl,3rol bx,clmov al,bland al,07hadd al,30hmov dl,almov ah,2int 21hdec chjnz loop3retoutoct endpcrlf proc nearmov dl,13mov ah,2int 21hmov dl,10mov ah,2int 21hretcrlf endpend start11.假定一个名为MAINPRO的程序要调用子程序SUBPRO,试问:(1)MAINPRO中的什么指令告诉汇编程序SUBPRO是在外部定义的?(2)SUBPRO怎么知道MAINPRO要调用它?[解]:(1)EXTRN SUBPRO: FAR(2)PUBLIC SUBPRO12.假定程序MAINPRO和SUBPRO不在同一模块中,MAINPRO中定义字节变量QTY 和字变量VALUE和PRICE.SUBPRO程序要把VALUE除以QTY,并把商存在PRICE中,试问:(1)MAINPRO怎么告诉汇编程序外部子程序要调用这三个变量?(2)SUBPRO怎么告诉汇编程序这三个变量是在另一个汇编语言程序中定义的? [解]:(1)PUCLIC QTY,VALUE,PRICE(2)EXTRN QTY: BYTE, VALUE: WORD, PRICE: WORD13.假设:(1)在模块1中定义了双字变量VAR1,首地址为VAR2的字节数组和NEAR标号LAB1,它们将由模块2和模块3所使用;(2)在模块2中定义了字变量VAR3和FAR标号LAB2,而模块1中要用到VAR3,模块3中要用到LAB2;(3)在模块3中定义了FAR标号LAB3,而模块2中要用到它. 试对每个源模块给出必要的EXTRN和PUBLIC说明.;模块1extrn var3:wordpublic var1,var2,lab1data1 segmentvar1 dd ?var2 db 10 dup(?)data1 endscode1 segmentassume cs:code1, ds:data1main proc farmov ax,data1mov ds,ax...lab1:...mov ax,4c00hint 21hmain endpcode1 endsend start;模块2extrn var1:dword,var2:byte,lab1:near,lab3:farpublic var3,lab2data2 segmentvar3 dw ?data2 endscode2 segmentassume cs:code2, ds:data2...lab2:...code2 endsend;模块3extrn var1:dword,var2:byte,lab1:near,lab2:farpublic lab3code3 segmentassume cs:code3...lab3:...code3 endsend14.主程序CALLMUL定义堆栈段,数据段和代码段,并把段寄存器初始化;数据段中定义变量QTY和PRICE;代码段中将PRICE装入AX,QTY装入BX,然后调用子程序SUBMUL.程序SUBMUL没有定义任何数据,它只简单地把AX中的内容(PRICE)乘以BX中的内容(QTY),乘积放在DX,AX中.请编制这两个要连接起来的程序. datasg segmentqty dw 2price dw 4datasg endsstacksg segmentdw 100 dup(?)tos label wordstacksg endscodesg segmentmain proc farassume cs:codesg,ds:datasg,ss:stacksgstart:mov ax,datasgmov ds,axmov ax,stacksgmov ss,axmov sp,offset tosmov ax,pricemov bx,qtycall submulmov ax,4c00hint 21hmain endpsubmul proc nearmov dx,0mul bxretsubmul endpcodesg endsend start15.试编写一个执行以下计算的子程序COMPUTE:R<-X+Y-3其中X,Y及R均为字数组.假设COMPUTE与其调用程序都在同一代码段中,数据段D_SEG中包含X和Y数组,数据段E_SEG中包含R数组,同时写出主程序调用COMPUTE过程的部分.如果主程序和COMPUTE在同一程序模块中,但不在同一代码段中,程序就如何修改?如果主程序和COMPUTE不在同一程序模块中,程序就如何修改?(1)d_seg segmentx dw 1y dw 4d_seg endse_seg segmentr dw ?e_seg endsc_seg segmentmain proc farassume cs:c_seg,ds:d_seg,es:e_segstart:mov ax,d_segmov ds,axmov ax,e_segmov es,axcall computemov ax,4c00hint 21hmain endpcompute proc nearmov ax,xadd ax,ysub ax,3mov es:r,axretcompute endpc_seg endsend start;========================================(2)d_seg segmentx dw 1y dw 4d_seg endse_seg segmentr dw ?e_seg endsc_seg segmentmain proc farassume cs:c_seg,ds:d_seg,es:e_segstart:mov ax,d_segmov ds,axmov ax,e_segmov es,axcall far ptr computemov ax,4c00hint 21hmain endpc_seg endsprognam segmentassume cs:prognamcompute proc farmov ax,xadd ax,ysub ax,3mov es:r,axretcompute endpprognam endsend start;============================================= (3);模块1extrn compute:farpublic x,y,rd_seg segmentx dw 1y dw 4d_seg endse_seg segmentr dw ?e_seg endsc_seg segmentmain proc farassume cs:c_seg,ds:d_seg,es:e_seg start:mov ax,d_segmov ds,axmov ax,e_segmov es,axcall far ptr computemov ax,4c00hint 21hmain endpc_seg endsend start;模块2extrn x:word,y:word,r:wordpublic computeprognam segmentassume cs:prognamcompute proc farmov ax,xadd ax,ysub ax,3mov es:r,axretcompute endpprognam endsend。
《编译原理》习题及答案
第一章1、将编译程序分成若干个“遍”是为了。
b.使程序的结构更加清晰2、构造编译程序应掌握。
a.源程序b.目标语言c.编译方法3、变量应当。
c.既持有左值又持有右值4、编译程序绝大多数时间花在上。
d.管理表格5、不可能是目标代码。
d.中间代码6、使用可以定义一个程序的意义。
a.语义规则7、词法分析器的输入是。
b.源程序8、中间代码生成时所遵循的是- 。
c.语义规则9、编译程序是对。
d.高级语言的翻译10、语法分析应遵循。
c.构词规则二、多项选择题1、编译程序各阶段的工作都涉及到。
b.表格管理c.出错处理2、编译程序工作时,通常有阶段。
a.词法分析b.语法分析c.中间代码生成e.目标代码生成三、填空题1、解释程序和编译程序的区别在于是否生成目标程序。
2、编译过程通常可分为5个阶段,分别是词法分析、语法分析中间代码生成、代码优化和目标代码生成。
3、编译程序工作过程中,第一段输入是源程序,最后阶段的输出为标代码生成程序。
4、编译程序是指将源程序程序翻译成目标语言程序的程序。
一、单项选择题1、文法G:S→xSx|y所识别的语言是。
a. xyxb. (xyx)*c. x n yx n(n≥0)d. x*yx*2、文法G描述的语言L(G)是指。
a. L(G)={α|S+⇒α , α∈V T*}b. L(G)={α|S*⇒α, α∈V T*}c. L(G)={α|S*⇒α,α∈(V T∪V N*)}d. L(G)={α|S+⇒α, α∈(V T∪V N*)}3、有限状态自动机能识别。
a. 上下文无关文法b. 上下文有关文法c.正规文法d. 短语文法4、设G为算符优先文法,G的任意终结符对a、b有以下关系成立。
a. 若f(a)>g(b),则a>bb.若f(a)<g(b),则a<bc. a~b都不一定成立d. a~b一定成立5、如果文法G是无二义的,则它的任何句子α。
a. 最左推导和最右推导对应的语法树必定相同b. 最左推导和最右推导对应的语法树可能不同c. 最左推导和最右推导必定相同d. 可能存在两个不同的最左推导,但它们对应的语法树相同6、由文法的开始符经0步或多步推导产生的文法符号序列是。
06编译答案
06年答案第一题:填空题(30分)1、共有30个空,每空1分, 30×1=30分。
2、参考答案:说明:(1)各个答案可有不同表达方式,只要意思相同即可;(2)带*的题中的答案可交换次序。
第二题:(7分)典型编译程序在各个工作阶段的任务参考答案:1、词法分析阶段的任务:对构成源程序的字符串进行扫描和分解,识别出单词(如标识符等)符号序列。
(1分)2、语法分析阶段的任务:根据语言的语法规则对单词符号串(符号序列)进行语法分析,识别出各类语法短语(可表示成语法树的语法单位),判断输入串在语法上是否正确。
(1分)3、语义分析阶段的任务:按语义规则对语法分析器归约出的语法单位进行语义分析,审查有无语义错误,为代码生成阶段收集类型信息,并进行类型审查和违背语言规范的报错处理。
(1分)4、中间代码生成阶段的任务:将语义分析得到的源程序变成一种结构简单,含义明确,容易生成,容易译成目标代码的内在代码形式。
(1分)5、代码优化阶段的任务:对中间代码或目标代码进行等价的变换改造等优化处理,使生成的代码更高效。
(1分)6、目标代码生成阶段的任务:将中间代码生成特定机器上的绝对或可重定位的指令代码或汇编指令代码。
(1分)说明:结合具体高级语言的答案再加1分。
第三题:(10分)1、正规文法G[S](4分):S→0A|1BA →1S|1B →0S|0 2、NFA (3分) :3、DFA (3分) : 步骤如下表所示(可省):将集合T0至T3各用一个状态表示,确定化后所得DFA M 如下:说明:此答案只供参考,可以是其他答案,只要功能等价即可。
第四题:(10分)1、 证明(3分):因为存在推导序列E=>E-T=>E-T*F=>E-F*F=>E- F*(E) =>E-F*(T)=>E-F*(F)=>E-F*(i),即有E *E-F*(i)成立,所以,E-F*(i)是文法的一个句型。
编译原理例题习题讲解(ch6-ch7)
7、文法如下: PD DD;D|id:T|proc id;D;S (1)设计语法制导定义,打印该程序一共声明的 id 个数 (2)设计翻译模式,打印 P 所生成的程序中每个 id 的嵌套深度 解:
(1) 语法制导定义:引入属性 i,记录 id 的个数 PD {printf(D.i);} DD1;D2 {D.i=D1.i+D2.i;} Did:T {D.i=1;} Dproc id;D1;S {D.i=D1.i+1} (2)翻译模式:引入属性 level 和 name P{D.level=1;}D D{D1.level=D.level; }D1;{ D2.level=D.level;}D2 Did:T {printf(,D.lev);} Dproc id; {D1.level=D.level+1; }D1;S 8、请将下列语句 while (A<B )do if (C>D) then X:=Y+Z 翻译成四元式 解:翻译的三地址码序列: L1: if A<B goto L1 goto L4 L2: if C<D goto L3 goto L1 L3:T∶=Y+Z X∶=T goto L1 L4:
9、将下列C程序的执行语句翻译成三地址代码(设 S.next 为 L0):
if( i < j ) s = 10 * s else i=-j 解:翻译的三地址码序列: if i < j goto L1 goto L2 L1: t0 = 10 * s s = t0 goto L0 L2: t1 = - j i = t1 L0: ...
S’S {print(S.val);} SL1.L2 { S.val:=L1.val+L2.val/2L2.length ;} S L { S.val:=L.val; } LL1B { L.val:=L1.val*2+B.val; L.length:=L1.length+1; } LB { L.val:=B.val; L.length:=1;} B0 { B.val:=0; } B1 { B.val:=1;}