使用贝叶斯模型平均方法(BMA)对中国通货膨胀建模并预测
基于惯性权重的中国核心通货膨胀及其政策含义(宏观报告,11.8_新)

基于预测视角的中国核心通货膨胀测算:以惯性为权重范志勇张鹏龙(中国人民大学经济学院100872)内容提要:本文从货币政策和对标题通货膨胀预测的角度构建了中国基于价格上涨惯性权重的核心通货膨胀指标。
与国内现有计算通货膨胀惯性的研究不同,本文通过环比价格增长率计算其惯性,从而避免了同比增长率指标可能对惯性的高估。
通过与传统的剔除法核心通货膨胀以及与标题通货膨胀进行对比,本文发现基于惯性权重的核心通货膨胀是标题通货膨胀的领先指标,对短期标题通货膨胀的变换有较强的预测能力,因而具有较高的政策参考意义。
根据我们模型的预测结果,2010年10月将是价格指数环比增长率的低点,11月份之后将会上升;如果考虑到美联储第二轮量化宽松货币政策所造成的热钱流入,中国所面临的通货膨胀压力更加严峻。
一、问题提出自2009年以来,在多种因素的作用下,中国多种商品价格出现了较大的涨幅,先是大蒜,然后是绿豆,近期鲜菜、鸡蛋等产品价格都出现了较快增长。
面临这种形式,货币政策当局究竟该如何决策?政策当局是否应该通过货币政策来应对这些商品的快速增长?事实上无论是否明确实施所谓的“通货膨胀目标制”,保持价格水平稳定都是各国货币政策的主要目标之一。
然而在具体实践中,许多中央银行都重点关注核心通货膨胀率而非总体通货膨胀率,并且往往将食品和能源价格排除在政策关注目标之外。
例如美联储所特别关注的“个人消费支出”价格指数中不包含食品和能源的价格;欧洲中央银行所计算的核心通货膨胀中则是剔除了食品原材料和能源价格①。
政策当局关注核心通胀的原因在于“总体价格水平变化中包含了较多的短期噪音”。
②因此货币政策是否该对大蒜、绿豆等食品价格进行响应的政策选择背后所隐含的理论问题是,货币政策应该对标题通货膨胀(总量通货膨胀)还是对核心通货膨胀进行反应。
中央银行为什么要关注“核心通货膨胀”,并且往往将食品和能源价格排除在外呢?Roger(1998)指出理论上核心通货膨胀特别强调标题通货膨胀两个方面的特征,一是标题通货膨胀中的持续性部分(persistent component);另一个是标题通货膨胀中的具有普遍性的部分(generalised component),其理论基础分别来自Friedman(1963)和Okun(1970)关本文得到国家社会科学基金项目“中国通货膨胀中的需求拉动与成本推动因素研究及其政策选择”(08CJL010)和国家社科基金重大招标项目“保持经济平稳较快发展、调整经济结构与管理通胀预期的关系研究”(09&ZD018)课题资助。
中国未来养老金系统的风险分析报告

中国未来养老金系统的风险分析摘要在对中国未来养老金系统的风险分析中,首先采用了两种人口预测模型Malthus模型和Logistic模型,进行对比优化后,我们采用了残差平方和较小的Logistic模型所预测出的结果,再对不同通货膨胀率下,所预测未来养老金规模是否能真正保障退休水平。
对于问题一,将从中国统计年鉴中导出1970年到2013的人口数据,来预测出中国未来40年的人口结构。
且对于人口结构,我们将其简单化,仅考虑性别、是否老龄化和城镇农村所占比例。
对此考虑采用Malthus模型、Logistic模型进行预测,matlab编程得出结果,预测出中国未来40年的人口结构。
将二者结果进行比较,推测出最优化模型为Logistic。
由于人口增长限制条件的增多,进行模型的推广,可使用Leslie模型,再分析出中国老龄化的速度。
对于问题二,利用从中国统计年鉴得出的1995年到2013年养老金规模的数据,建立在问题一Malthus模型和Logistic模型的基础上,同样利用matlab编程,预测出未来的养老金规模。
考虑让两模型进行比较,将得出较精确的数据。
对于问题三,考虑未来养老金能否真正保障退休水平,是建立在一定水平的通货膨胀率下,关键是涉及到养老人均保险和人均消费之间的关系,再其寻找一个真正能保障退休水平的条件。
对于问题四,考虑解决未来“养老难”的可行性方法,先需要了解社会当前养老现状,在经济、政策和社会观念上进行分析。
根据实际情况合理提出解决未来“养老难”的可行性方法。
关键词:Malthus模型、Logistic模型、居家养老方式1 问题重述中国的养老金制度面临一胎化政策、人口老龄化、及通膨加剧、社保基金收益低等一系列问题。
请各参赛队根据自身实际情况考虑以下全部或仅其中的几个问题。
(1)利用人口模型(如:Leslie 模型等),分析中国未来 40 年的人口结构,分析中国老龄化的速度。
(2)查找统计年鉴[1]等各种资料,找出中国已公布的历年养老金规模,并根据相关数据预测未来的养老金规模。
人大版应用时间序列分析(第5版)习题答案
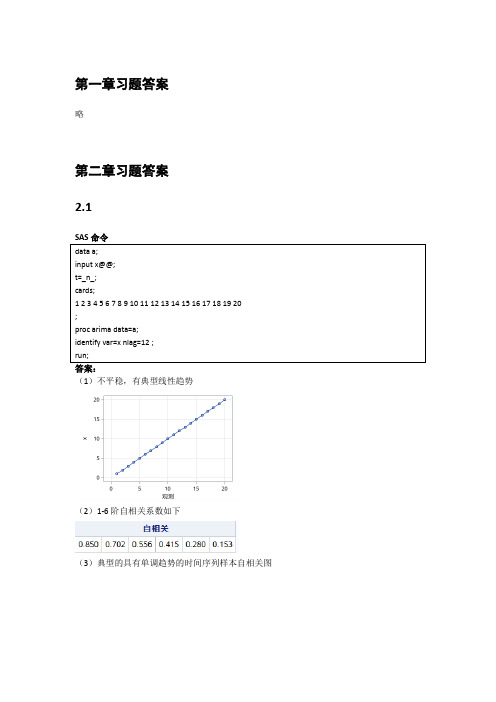
第一章习题答案略第二章习题答案2.1答案:(1)不平稳,有典型线性趋势(2)1-6阶自相关系数如下(3)典型的具有单调趋势的时间序列样本自相关图2.2答案:(1)不平稳(2)延迟1-24阶自相关系数(3)自相关图呈现典型的长期趋势与周期并存的特征2.3答案:(1)1-24阶自相关系数(2)平稳序列(3)非白噪声序列2.4计算该序列各阶延迟的Q统计量及相应P值。
由于延迟1-12阶Q统计量的P值均显著大于0.05,所以该序列为纯随机序列。
2.5答案(1)绘制时序图与自相关图(2)序列时序图显示出典型的周期特征,该序列非平稳(3)该序列为非白噪声序列2.6答案(1)如果是进行平稳性图识别,该序列自相关图呈现一定的趋势序列特征,可以视为非平稳非白噪声序列。
如果通过adf检验进行序列平稳性识别,该序列带漂移项的0阶滞后P值小于0.05,可以视为平稳非白噪声序列(2)差分后序列为平稳非白噪声序列2.7答案(1)时序图和自相关图显示该序列有趋势特征,所以图识别为非平稳序列。
(2)单位根检验显示带漂移项0阶延迟的P值小于0.05,所以基于adf检验可以认为该序列平稳(3)如果使用adf检验结果,认为该序列平稳,则白噪声检验显示该序列为非白噪声序列如果使用图识别认为该序列非平稳,那么一阶差分后序列为平稳非白噪声序列2.8答案(1)时序图和自相关图都显示典型的趋势序列特征(2)单位根检验显示该序列可以认为是平稳序列(带漂移项一阶滞后P值小于0.05)(3)一阶差分后序列平稳第三章习题答案 3.10101()0110.7t E x φφ===--() 221112() 1.96110.7t Var x φ===--() 22213=0.70.49ρφ==()12122221110.490.7=0110.71ρρρφρρ-==-(4) 3.21111222211212(2)7=0.515111=0.30.515AR φφφρφφφρφρφφφ⎧⎧⎧=⎪=⎪⎪⎪--⇒⇒⎨⎨⎨⎪⎪⎪=+=+⎩⎩⎪⎩模型有:,2115φ=3.312012(1)(10.5)(10.3)0.80.15()01t t t t t tt B B x x x x E x εεφφφ----=⇔=-+==--,22121212()(1)(1)(1)10.15=(10.15)(10.80.15)(10.80.15)1.98t Var x φφφφφφ-=+--+-+--+++=()1122112312210.83=0.70110.150.80.70.150.410.80.410.150.70.22φρφρφρφρφρφρ==-+=+=⨯-==+=⨯-⨯=() 1112223340.70.15=0φρφφφ====-()3.41211110011AR c c c c c ⎧<-<<⎧⎪⇒⇒-<<⎨⎨<±<⎪⎩⎩() ()模型的平稳条件是 1121,21,2k k k c c k ρρρρ--⎧=⎪-⎨⎪=+≥⎩() 3.5证明:该序列的特征方程为:320c c λλλ--+=,解该特征方程得三个特征根:11λ=,2λ=3λ=无论c 取什么值,该方程都有一个特征根在单位圆上,所以该序列一定是非平稳序列。
国开形成性考核51273《经济预测》形考任务(1-3)试题及答案

国开形成性考核《经济预测》形考任务(1-3)试题及答案(课程ID:51273,整套相同,如遇顺序不同,Ctrl+F查找,祝同学们取得优异成绩!)形考任务一一、判断题题目1:专家评估预测法属于客观预测范畴。
(X)题目2:围绕某一问题召开专家会议,通过共同讨论进行信息交流和相互诱发,激发出专家们创造性思维的连锁反应,产生许多有创造性的设想,从而进行集体判断预测的方法被称为头脑风暴法。
(X)题目3:质疑头脑风暴法遵守的原则和直接头脑风暴法一样,只是禁止对已有的设想提出肯定意见,而鼓励提出批评和新的可行设想。
(X)题目4:通过利用数学模型来研究一个变量(称为因变量)对另一个或者多个变量(称为自变量)的依赖关系,从而通过后者的已知值来估计或预测前者总体均值或者个别值,这一方法称为回归分析法。
(V)题目5:定量预测时有些因素由于数据不足或无法量化,一般采用定性方法修正。
(V)题目6:头脑风暴法采用了匿名函询的方式征求意见,很大程度上减少了权威对个人意见的影响。
(X)题目7:回归分析的数据资料问题中,因变量和自变量的纵向资料或横向资料是回归分析的定量分析依据。
如果观察值个数太少会使回归模型统计检验不具有显著性或预测的置信区间变宽。
应尽量多搜集数据量,一般以n>60为好。
同时对所搜集的数据资料要进行分析,如果数据序列含有季节变化,为了得到准确结果,在进行回归分析前必须从数据序列中消除季节因素。
(X)题目8:自相关问题中,当回归分析利用纵向资料,会由众多原因引起回归分析中误差项随时间显示出某种规律性形态,此即自相关问题。
如果存在自相关问题,回归方程的预测也不会出现估计过高或估计过低的现象。
(X)题目9:利用一个回归方程,两个变量可以互相推算。
(X)题目10:非线性回归有称曲线回归,是指用于市场预测的回归方程是曲线形式的。
(X)题目11:运用回归模型进行预测时,通常使用回归平方和占总的离差平方和的比重来衡量模型的拟合优良程度,并称其为判定系数,其取值范围为[0,1]。
金融计量第四章EVIEWS应用案例-通货膨胀预测分析

汪昌云 中国人民大学财政金融学院 教授 张成思 中国人民大学财政金融学院 教授 戴稳胜 中国人民大学财政金融学院 副教授
Presented By Harry Mills / PRESENTATIONPRO
本章内容梗概
Eviews预测基础
在Eviews中进行预测分析
ˆt c ˆ(1) c ˆ(2) xt c ˆ(3) zt y
• 需要确保预测期内的所有观测值对应的外生变量均为有效值。如果 预测样本中有数据缺失,那么对应的预测值将为缺失值(NA)。
Presented By Harry Mills / PRESENTATIONPRO
Eviews预测基础
Presented By Harry Mills / PRESENTATIONPRO
Eviews预测基础
• 预测效果评估
• 基于已经估计好的中国CPI的AR(2)模型,我们可以创建一个对 2005M01到2009M11中国CPI的动态预测。 • 如果我们勾选了Forecast evaluation选项,同时有预测变量在预 测期的实际数值的话,EViews将会给出评估预测结果的统计数据
Presented By Harry Mills / PRESENTATIONPRO
Eviews预测基础
• 假定使用者想用下列方程项进行动态预测: y c y(-1) ar(1) • 此时如果设定预测样本和工作簿时间范围的起始点相同,那么 EViews将会把预测样本向后推迟两期,然后使用预测样本前面的 观测值作为滞后变量来进行预测。 • 向后推迟两期,是因为滞后内生变量使得残差损失一期观测值, 所以对误差项的预测只能从第三期开始。
Presented By Harry Mills / PRESENTATIONPRO
实验指导书(ARMA模型建模与预测)

实验指导书(ARMA模型建模与预测)例1:我国1952-2011年的通货膨胀率数据建模及预测注:从国家统计局网站上下载到的cpi是以上一年为100计算的消费价格指数,即环比数据;而1952年为基期的消费价格指数的计算,需要借助环比发展速度与定基发展速度的关系来得到。
(1)数据录入打开Eviews软件,选择“File”菜单中的“New--Workfile”选项,在“Workfile structure type”栏选择“Dated –regular frequency”,在“Date specification”栏中分别选择“Annual”(年数据) ,分别在起始年输入1952,终止年输入2011,文件名输入“cpi”,点击ok,见下图,这样就建立了一个工作文件。
在workfile中新建序列cpi,并录入数据(点击File/Import/Read Text-Lotus-Excel…,找到相应的Excel数据集,打开数据集,出现如下图的窗口,在“Data order”选项中选择“By observation-series in columns”即按照观察值顺序录入,第一个数据是从B2开始的,所以在“Upper-left data cell”中输入B2,本例只有一列数据,在“Names for series or number if named in file”中输入序列的名字cpi,点击ok,则录入了数据):通过对cpi序列进行计算,得到通货膨胀率序列inflation(=(cpi-cpi(-1))/cpi(-1)):(2)绘制时序图双击序列inflation,点击view/Graph/line,得到下列对话框:选择图形类型,就可绘制下图的序列时序图,时序图看出1953-2011年的通货膨胀率数据是平稳的,这个判断比较粗糙,需要用统计方法进一步验证。
-.10-.05.00.05.10.15.20.25556065707580859095000510INFLATION在进一步分析之前,先将序列零均值化,生成新的序列x=inflation-@mean(inflation),x 序列及其序列图如下图所示,后面的分析将围绕x序列进行分析。
基于贝叶斯向量自回归的区域经济预测模型:以青海为例
基于贝叶斯向量自回归的区域经济预测模型:以青海为例王飞【摘要】由于缺乏足够的观测数据等原因,常规的区域经济预测模型在我国难以获得预期的预测效果,而贝叶斯向量自回归(BVAR)模型将变量的统计性质作为参数的先验分布引入到传统的VAR模型中,能够克服自由度过少的问题,以青海为例,本文建立了一个BVAR模型,并引入了全国GDP和中央政府转移支付作为外生变量以描述国民经济与区域经济的联系.样本内和样本外的预测误差比较以及青海经济增长转折点的准确预测都表明BVAR区域经济预测模型优于其他预测模型.【期刊名称】《经济数学》【年(卷),期】2011(028)002【总页数】6页(P95-100)【关键词】BVAR;预测;区域经济增长;青海【作者】王飞【作者单位】中央民族大学经济学院,北京,100081【正文语种】中文【中图分类】F222.3区域经济预测具有悠久的历史,只要地方政府试图管理经济运行,就必须进行某种形式的预测.准确的区域经济预测是提高政府管理效率、企业经营效率和个人投资效率的重要手段.长期以来,区域经济定量预测以经济计量模型为主.经济计量模型预测区域经济更像是对国民经济预测的翻版,是根据宏观经济理论建立联立方程组以描述经济变量之间的内在联系,然后估计参数并进行预测.该方法的优点是,以经济理论为建模基础,较易解释经济变量的变化方向和大小.但经济计量模型的缺点也很明显:方程组数量多,即使是小型的计量模型也通常含有20-30个方程左右,建模过程复杂;方程组数量多使得变量的预测误差相互累积影响最终的预测效果;对于区域经济预测而言,难以像预测国民经济一样,获得地区间贸易、投资等重要数据.从国外的预测历史来看,经济计量模型在20世纪70年代的滞涨时期预测效果不佳,建立在Box和Jenkins的单变量自回归求积移动平均模型(ARIMA)[1]基础上的现代时间序列分析逐渐兴起.与经济计量模型不同的是,时间序列分析模型较少依赖经济理论,更多的是依靠数据自身的变化规律来预测.考虑到经济变量之间的复杂联系,Sargent和Sim提出了向量自回归(VAR)模型[2-3].但随着变量个数的增加,VAR 模型中的参数迅速增加以致自由度消耗过快.由于我国区域经济历史数据较短,特别是考虑到改革开放前后经济结构发生了巨大变化,可利用的数据只能从1978年开始.而无论是经济计量模型还是ARIMA和VAR模型,都要求大量的观测数据以保证参数估计精度和预测精度.所以,传统的区域经济预测模型在我国很难获得预期的预测效果.而Litterman提出的贝叶斯向量自回归模型(BAVR)[4]利用变量的统计性质作为VAR模型参数的贝叶斯先验信息在一定程度上克服了VAR模型的过参数化缺陷.因此,从理论上看,BVAR模型在我国区域经济预测中具有广泛的应用前景.BVAR模型在国外区域经济预测中的初步应用取得了一些成效.Dua和Ray利用BVAR模型预测了美国康涅狄格州的区域经济运行情况,发现BVAR模型不论是短期还是长期预测,都会产生精确的结果[5].Puri等用BAVR模型预测了南加州地区就业情况,结果表明BVAR方法的预测精度要优于ARIMA和无约束VAR模型[6].国内学者也逐步开始使用BVAR模型进行一些经济预测工作,如陈东陵,张思奇等对我国宏观经济增长的预测,方勇,肖争艳等对我国CPI的预测[7-10],但国内应用BVAR模型进行区域经济预测的极少.本文以青海为例,建立了一个BVAR模型来说明其在区域经济预测中的应用,并与包括ARIMA在内的其他预测模型相比较来评价BVAR模型的预测效果.预测误差比较证实了BVAR模型在区域经济预测中的可行性.本文内容分为以下四部分:第一部分简要介绍了BVAR模型;第二部分是对建模的数据来源,变量选取和预测效果评价方法进行了说明;第三部分是各种模型预测效果的比较及BVAR模型关于青海2010-2015年经济增长预测值;最后给出本文的结论.BVAR模型是在普通VAR模型基础上发展起来的.考虑无约束VAR模型:其中,t表示时刻,p表示滞后阶数.Y(t)是 K维随机向量 Y在时刻t的取值,是模型中的内生变量.α是X(t)的 Km维系数向量.β(j)是 K维向量 Y(t-j)的系数,是 K维参数方阵.ε(t)是 K维随机误差项.假定ε(t)是同期相关的,但无序列相关:①假定VAR模型的滞后阶数 p足够长以保证εt是序列无关的.从VAR模型式(1)可以看出,总共有 K2p+Km个待估参数.即使需要预测的变量较少,也需要可观的观测值.因此,除非数据足够多,一般情况下,VAR模型都面临自由度较少,因而预测精度不高的问题.通过对参数施加一定的约束,比如减少滞后阶数,或在个别方程去掉一些变量,可以有效地缓解自由度过少的问题.但从贝叶斯的观点而言,这意味着预测者认为去掉的这些滞后项其系数为0的概率是100%,遗憾的是根本无法得知这种约束是否成立.而Litterman以及Doan,Litterman和Sims提出的贝叶斯VAR(BVAR)[4][11]模型创造性地将预测者对βj的先验信息与上述无约束VAR模型相结合从而解决了上述问题.因该方法首先在明尼苏达大学和美联储明尼苏达分行提出,又被称为明尼苏达先验.明尼苏达先验中每个参数β(i,k,j)(方程组(1)中第i个方程的第k个变量的滞后j阶系数)的先验分布都假定为正态分布,所以每个参数的先验分布仅取决于两个参数,先验期望μβ(i,k,j)和先验方差(i,k,j).而对某一参数先验期望μβ(i,k,j)而言,与其相对应的先验方差(i,k,j)就表示预测者对该先验期望的把握程度:(i,k,j)越小,表示预测者对该先验期望的把握较大;而一个非常大的(i,k,j)表明预测者对该先验期望没有什么信心.并不是单独地确定各个参数的先验信息,明尼苏达先验发展了一种方法,可以系统地对参数施加先验分布.明尼苏达先验从数据的统计性质来确定参数先验期望的取值.由于经济时间序列数据经常表现出随机游走的特点,明尼苏达先验根据这一特点认为模型系统(1)中的每个内生变量服从随机游走的先验分布,这时变量最佳预测值就是其上一期的取值.因此,明尼苏达先验中参数β(i,k,j)的先验期望是即方程组(1)中第i个等式右边变量i自身的滞后一期系数的先验期望都是1,而其他滞后期的系数以及其他变量交叉滞后项的系数,先验期望都是0.先验标准误s(i,k,j)是通过下式来确定的.其中,si是第i个方程的单变量自回归的标准误,而si/sk的目的是消除Y中各变量不同单位对先验标准误的影响.式(3)中 f(i,k)是相对权重,是参数β(i,k,j)的标准误相对于β(i,i,j)的标准误(即方程组(1)中第i个方程中第k个变量系数的标准误相对第i个变量系数的标准误)的取值.f(i,k)的具体数值就构成了一个 K维方阵.根据定义可知f(i,k)=1,即该K维方阵主对角线上的元素都是1.而非对角线上元素通常小于1,因从预测角度而言,变量自身的滞后项通常比其他变量的交叉滞后项的影响更大.g(j)是依赖于滞后阶数j的函数,表示β(i,k,j-1)的标准误相对于β(i,k,j)的标准误(变量滞后j-1期系数的标准误相对于滞后 j期系数的标准误)的取值.通常认为,随着滞后阶数的增加,无论是变量自身的滞后项还是其他变量的交叉滞后项的影响都越来越小.所以随着滞后阶数的增加,参数所对应的先验方差越小.明尼苏达先验中 g(j)通常采用谐函数 g(j)=j-d的形式,d的数值越大,先验方差随着滞后阶数的增加衰减的越快,d的数值越小,衰减的越慢.γ是确定所有系数先验标准误大小的一个参数.根据 f(i,k)和 g(j)的定义,可知γ实际上就等于每个方程中,变量自身滞后一期系数的先验标准误.通过式(3),所有参数先验方差s2(i,k,j)的设定就转化为所谓的超参数γ、d和f(i,k)的设定上.BVAR模型的估计可以使用 Theil所提出的混合估计方法(mixedestimation)[12].估计BVAR模型需要预测者确定上述超参数取值.因为BVAR模型的主要的目是预测,因此,与其他模型不同的是,超参数的取值标准就是获得最优的预测效果,而不是依赖于各种模型设定检验.超参数的确定实际上是一个类似栅格搜索的过程,在超参数取值范围内搜索能够获得最优预测效果的取值.为此,通常将获得的总样本 T分成两个时期 T1和 T-T1.时期 T1的数据用于估计BVAR模型和预测,T-T1的数据用于计算比较预测误差并确定最终的超参数数值.本文用BVAR模型来预测青海省地区生产总值并比较各种模型的预测误差以评价BVAR模型区域经济预测效果.想要预测的变量是青海地区生产总值.根据经济理论知道,地区生产总值、固定资产投资额、通货膨胀率和社会消费品零售总额,这几个变量之间相互影响,相互作用,适合用VAR模型来描述这几个变量之间的联系.青海作为中国西部地区的一个省份,经济发展必然会受到整个国民经济增长周期的影响.而且,作为中国较为落后的西部地区,少数民族集中的地区,青海每年都可获得较为可观的中央政府转移支付.因此,全国 GDP和中央政府转移支付是青海经济增长的重要驱动力,在BVAR模型中,将这两个变量引入到模型中作为外生变量,以反映国民经济与青海经济的联系.本文使用的是1978年到2009年的年度数据.2008年及以前的数据来自《青海统计年鉴》和《新中国五十五周年统计资料汇编》,2009年的数据来自青海2009年统计公报.考虑到统计年鉴会根据经济普查信息对已公布数据进行修正,以各年鉴中最新公布的数据为准.为了消除价格的影响,将上述变量统一转变为2000不变价的实际值.青海地区生产总值实际值根据青海生产总值指数计算得到,同时计算得到青海生产总值平减指数;固定资产投资实际值根据固定资产资产价格指数计算得到,1991年以前固定资产价格指数无记录,用青海生产总值平减指数来代替;通货膨胀率用前述计算得到的青海生产总值平减指数来衡量;社会消费品零售总额则根据青海消费价格指数进行平减;全国 GDP实际值用全国 GDP指数计算得到;中央政府转移支付公开出版资料中无记录,本文用地方财政一般预算支出与收入差额来近似地衡量,并用青海生产总值平减指数进行平减.因各变量均存在明显的指数上升趋势,对变量全部进行了取对数转化.预测效果是选择评价模型的关键.在本文中,是根据超前5步预测值的赛尔U(TheilU)统计量来确定BVAR模型各参数.TheilU统计量是预测值的均方根误差与随机游走预测值^yt+s=yt的均方根误差之比其中,s是预测步长,^yt+s是t+s期的预测值.显然,TheilU统计量是无量纲的.对于BVAR模型中的不同参数,TheilU统计量越小,预测误差越好,预测精度越高.首先把样本按照2000年为界分成两个时期①因西部大开发战略为青海经济快速发展提供了契机,所以选择2000年作为分界点.,先根据2000年以前(含2000年)的数据进行超前5步预测,然后使用卡尔曼滤波法(KalmanFilter)[13]更新BAVR模型系数,再进行超前5步预测,.……直到2009年.最终,获得了9个超前1步预测值,8个超前2步预测值,……,5个超前5步预测值.根据式(4)计算得到青海生产总值预测值的超前1步到超前5步预测的 TheilU统计量,选择BVAR模型超参数需要综合考虑这5个 TheilU统计量.预测期越长,即预测步长越长,预测精度越低,所以,不能简单地计算超前5步TheilU统计量的平均值以评价总体的预测效果.但遗憾的是,也没有任何理论指出每步步长应给予的权重,本文选择的权重是:预测步长每增加1步,权重下降10%②尽管10%的选择是任意的,但BVAR模型最优超参数取值对此较为稳健..本文的BVAR模型使用RATS软件估计和预测.首先对地区生产总值、固定资产投资额、通货膨胀率和社会消费品零售总额这四个内生变量进行ADF单位根检验,结果表明均为一阶差分平稳过程,所以本文使用前述的明尼苏达先验.BVAR模型的估计和预测需要确定内生变量滞后阶数、外生变量滞后阶数以及模型中的超参数值.考虑到自由度的原因,内生变量最大滞后阶数设为5,外生变量最大滞后阶数设为1,根据青海生产总值预测值TheilU统计量同时确定内生变量和外生变量最优滞后阶数和各超参数取值.为了降低相对权重 f(i,k)的搜寻时间,首先将其非主对角线上的元素设为0.5,因经济理论表明这些内生变量之间是相互联系、相互影响的,然后逐渐调整非对角线上的元素以得到最优的预测效果.最终确定模型中内生变量滞后阶数为3阶,两个外生变量均为当期和滞后1期;超参数γ=0.1、d=1.4;相对权重 f(i,k)非主对角线元素中,青海生产总值方程中均为0.8,而其他方程中均为0.5③除了青海生产总值方程中相对权重的取值对BVAR模型预测结果有明显影响外,其他方程中的相对权重影响很小..为了说明BVAR模型的预测效果,在表1中比较了BAVR、VAR和 ARIMA三种模型 2005~2009年间的样本内预测的 TheilU统计量.其中VAR模型根据赤池信息准则(AIC)和施瓦茨信息准则(BIC)选择内生变量滞后阶数为2阶④当样本为2007年及以后时,AIC和BIC准则均选择4阶滞后,但实际预测效果更差.,外生变量滞后阶数同BVAR模型一样,为同期和滞后1期.而ARIMA模型则根据青海生产总值的自相关图和偏相关图,系数 t值、残差检验、AIC数值确定为ARIMA(3,1,0)过程⑤ARIMA模型参数的确定可参见汉密尔顿[14]..从表1的 TheilU 统计量可以看出,BVAR模型的预测效果最好,从超前1步到超前5步,预测误差都是最小的.而且,与Litterman(1980)的预测结果相似,BVAR模型预测期(步长)越长,相对VAR和ARIMA模型的预测效果越好.VAR模型和ARIMA模型的预测效果均不太理想.与BVAR模型相似的是,VAR模型预测期越长,相对ARIMA模型的预测精度越高.BVAR和VAR模型的这个特点可能是因为考虑到了经济变量之间的联系,而ARIMA是单变量模型.但ARIMA模型超前1步预测效果要远远好于VAR模型,这可能是VAR模型自由度过少所致.在表2中进一步比较了几种模型样本外的预测效果.与样本内预测的区别在于,样本外预测时同期外生变量的取值使用的是其预测值,以模拟真正的预测过程.两个外生变量全国GDP和中央政府转移支付(地方财政收支差额)用单变量ARIMA模型加以预测.根据它们的自相关图和偏相关图,系数 t值、残差检验以及AIC数值确定分别为ARIMA(2,1,0)和ARIMA(0,1,2)过程.青海省社科院和发改委信息处每年定期发布对下年度宏观经济指标的预测结果,他们的预测模型主要是依赖于投资数据的乘数模型.为了便于同他们的预测结果进行比较,在表2中仅比较了2005~2009年间的超前1步预测误差,并将水平预测值转化为增长率.从表2可以看出,BVAR模型在所有模型中预测误差最小,除了2005年预测误差较大外①对外生变量预测值的进一步分析发现,2005年中央政府转移支付预测误差较大,导致BVAR模型在2005年预测表现不佳.,其他年份预测较为准确.ARIMA模型预测效果在所有模型中仅次于BAVR模型,好于青海社科院和发改委的预测.VAR模型预测误差最大,可能是因为自由度过小所致.而且,BVAR模型对于2009年的青海经济增长转折点的预测也更为精确.与表1中的样本内超前1步预测值TheilU统计量相比较可以发现,BVAR模型样本外预测误差要小于样本内预测误差,这可能意味着对全国经济增长形势和中央政府转移支付的预期会影响到青海实际经济增长过程.从各模型预测效果比较中可以看出,BVAR区域经济预测模型优于其他预测模型. 3.4 BVAR模型2010~2015年预测结果在表3中,根据BVAR模型给出了青海2010~2015年经济增长率的预测值.根据两个外生变量的取值考虑了以下三种情况:1)全国GDP的预测值根据单变量的ARIMA(2,1,0)过程预测得到(平均增长率为9.735%);中央政府转移支付以近五年平均增长率23.28%增长;2)全国 GDP以8%的较低速度增长,中央政府转移支付以近五年平均增长率23.28%增长;3)全国 GDP以11%的较高速度增长,中央政府转移支付以30%的较高速度增长.这三种情况可以分别看成是适中、低迷和高涨的外部经济环境.从表3可以看出中央转移支付对于青海经济增长的重要作用,即使全国经济增长形势不很乐观,但只要中央转移支付维持较高的增长率,青海经济也能够获得较快的增长.常规的区域经济计量预测模型以及ARIMA、VAR等现代时间序列分析预测模型都要求较多的观测值,在我国区域经济预测中难以获得预期的预测效果.而在VAR模型基础上发展出的BVAR模型既具有VAR模型的优点,又克服了VAR模型自由度消耗过快的问题.本文以青海为例,建立了一个BVAR模型来说明该模型在区域经济预测中的应用.各种模型的预测误差比较表明,BVAR模型无论是样本内预测还是样本外预测,预测误差都显著地小于VAR、ARIMA模型以及青海省社科院和发改委的实际预测模型.BVAR模型对2009年青海经济增长的转折点预测也更为精准.这表明BVAR模型应用于我国的区域经济预测能够得到更佳的预测效果.区域经济计量模型建模过程复杂,工作量大.即使是青海省社科院和发改委的较简单的定量预测模型也需要收集大量的投资数据,而且有些数据是不公开的,预测过程较多依赖专家的经验判断.而BVAR模型建模过程相对简单,参数和超参数的确定有明确的标准,因此,在我国区域经济预测中有广泛的应用前景.【相关文献】[1] G BOX , G JENKINS. Time series analysis : forecasting andcont rol [M] . San Francisco : Holden-Day , 1976.[2] T SARGENT. Estimating vector autoregressions using met hodsnot based on explicit economic t heories [ J ] . Federal ReserveBank of Minneapolis Quarterly Review ,1979 , 3 (3) :8 -15.[3] C SIMS. Macroeconomics and reality [ J ] . Economet rica ,1980 ,48 (1) :1 - 48.[4] R LITTERMAN. A Bayesian procedure for forecasting wit hvector autoregression[ R] . Working paper ,Department of Economics, Massachusett s Instit ute of Technology ,1980.[5] P DUA , D J SMYTH. Forecasting US homes Sales usingBVAR model s and survey data on households’buying attitudesfor homes[J ] . Journal of Forecasting ,1995 ,14 (3) :217- 227.[6] A PURI , G SOYDEMIR. Forecasting indust rial employmentfigures in Sout hern California : A Bayesian vector autoregressivemodel [J ] . The Annals of Regional Science , 2001 , 34 (4) :503 - 514.[7] 陈东陵.走向2000年——采用向量自回归方法进行宏观经济预测[J].数量经济技术经济研究.1996,(7):57-61.[8] 张思奇,P·M·萨默斯.贝叶斯向量自回归(BVAR)季度预测模型[J].数量经济技术经济研究,1998,(9):29-33.[9] 方勇,吴剑飞.中国的通货膨胀:外部冲击抑或货币超发——基于贝叶斯向量自回归样本外预测模型的实证[J].国际金融研究,2009,(4):72-28.[10]肖争艳,安德燕,易娅莉.国际大宗商品价格会影响我国CPI吗——基于BVAR模型的分析[J].经济理论与经济管理,2009,(8):17-23.[11]T DOAN , R LITERMAN , C SIMS. Forecasting and conditionalprojection using realistic prior dist ributions [ J ] . Econometric Reviews ,1984 ,3 (1) : l - 100.[12]H THEIL. Principles of economet rics [M] . New York : Wiley,1971.[13]R KALMAN. A new approach to linear filtering and predictionproblems[J ] . Journal of Basic Engineering , 1960 ,82 ( seriesD) :35 - 45.[14]汉密尔顿.时间序列分析[M].靳云汇,等译.北京:中国社会科学出版社,1999.[15]青海经济社会形势分析与预测(2004~2005——2008~2009)[M].西宁:青海人民出版社.。
学习效应_通胀目标变动与通胀预期形成
2011 年第 10 期
能力, 能形成与真实经济相一 致 的 无 偏 估 计 结 果 。 适 应 性 学 习 机 制 假 定 公 众 仅 有 有 限 信 息, 但能 “理性地 ” 使用信息, 借助于不断更新的数据集合和持续的学习, 形成通胀预期 。 相比较而言, 适应 性学习机制比理性预期可能更切合实际 。 事实上, 学习行 为 的 引 入 有 理 论 与 实 践 的 双 重 意 义 。 理
* 李成 、 马文涛 、 王彬, 西安交通大学经济 与 金 融 学 院, 邮 政 编 码: 710061 , 电 子 信 箱: mauricema2008 @ sina. com 。 本 研 究 得
ቤተ መጻሕፍቲ ባይዱ
“我国金融监管的制度框架 、 ( 09 AZD020 ) 的 资 助, 制衡机制与绩 效 评 价 研 究 ” 作者感谢两位匿名审稿专家对本文 到国家社科基金 的仔细审阅和富有启发性的修改意见, 感谢武汉大学经济与管理学院魏福成博士的有益评论 。
① 可能出现多重均衡, 论方面, 大多数理性预期模型都有锋刃特性, 到底出现哪种均衡存在任意性,
2008 ) 。 实 践 可能的解决方案是若某种 均 衡 能 被 学 习, 可 能 成 为 合 理 均 衡 ( Evans and Honkapohja , 方面, 受制于信息拥有量与信息处理能力, 公众的认识通常不 完 全, 这使持续不断地学习成为通胀 预期形成的常态 。 2003 ; Del Negro 文献中学习行为大体分 为 两 类, 一 类 是 卡 尔 曼 滤 波 式 学 习 ( Erceg and Levin , and Eusepi , 2009 等 ) , 2007 ; Ormeo , 2009 ; 另 一 类 是 最 小 二 乘 式 学 习 ( Slobodyan and Wouters , Milani , 2010 等) 。 相比较而言, 卡尔曼滤波式学习能产生更高效的学习速度, 保证经过足够长时间 之后模型最终收敛于理性预期均衡, 而最小二乘学习机制对模型的动态特征影响较大, 难以确保模 2005 ) 。 故本文选用前者 。 尽管我国政府公 布 通 胀 目 标, 型均衡的唯一( Sargent and Williams , 但政 策目标还包括经济增长 、 就业和国际收支等, 这使得公众对公 布 的 通 胀 目 标 有 不 完 全 的 信 任 度, 可 能倾向于采取“听其言不如观其行 ” 的策略, 即通过对政府行为( 尤其是货币政策调整 ) 的学习来获 这种不完全信任度具体表现在通胀目标在部分时间未得到严格执行 ( 如 取具体目标 。 事实上, 2007 年和 2008 年) 。 另一方面, 自 20 世纪 90 年代以来, 经济体制改革稳步推进, 价格形成机制趋 于成熟, 货币政策也在 1998 年实现直接调控向间接调控的转型 。 经济结构与宏观调控模式的转型 由此获取对经济体制的认识并形成对经济变量, 尤其是通胀的较为准确 提供公众学习的内在动力, 预期, 降低决策偏误 。 在利用新凯恩斯 DSGE 模型 分 析 时, 模 型 评 价 较 为 关 键, 与现有文献所采取的二阶矩匹配法 ( 许伟 、 2009 等) 和基于 SVAR 的 脉 冲 函 数 匹 配 法 ( 王 君 斌 、 2010 等 ) 不 同, 陈斌开, 王 文 甫, 本文选 借鉴 Del Negro et al. ( 2007 ) 的思想, 评价模型结构性约束对宏观经济 择 DSGE-VAR 方法 。 具体地, 的刻画程度, 还以 DSGE-VAR 模型和有西蒙斯 - 查先验分布( Sims-Zha-Prior ) 的 BVAR 模型为基准 评价模型的预测能力 。 DSGE 模型的建立和求 解; 第 三 部 分, 本文第二部分, 模 型 参 数 校 准、 评 价 与 通 胀 预 期 测 度; 第 通胀预期测度方法的比较; 第五部分, 结论以及政策含义 。 四部分,
基于贝叶斯混频模型的中国宏观经济预测研究
作者: 唐成千[1];叶梁[2]
作者机构: [1]交通银行博士后科研工作站;[2]上海财经大学经济学院
出版物刊名: 新金融
页码: 24-30页
年卷期: 2021年 第2期
主题词: 宏观经济;预测;贝叶斯;混频
摘要:本文通过构建中国宏观经济系统的BMF-VAR模型对中国的宏观经济进行预测分析,并与相关模型的预测结果进行比较,来检验BMF-VAR模型对中国宏观经济进行预测时的适用性.研究结果表明,多变量BMF-VAR模型更适合于短期预测,多变量有效信息的增加促进了短期预测精度的提高;两变量BMF-VAR模型在预测精度方面整体上优于相对应的同频模型;通过BMF-VAR 模型能够估计出潜在的月度GDP增长率,且相比于通常所使用的规模以上工业增加值月度增长率更加贴近于真实的GDP增长率走势,有效地解决了月度GDP增长率缺失的问题,据此进行决策会更加有效合理,具有重要的理论和现实意义.。
基于神经网络的通货膨胀预测模型研究
基于神经网络的通货膨胀预测模型研究内容摘要:本文采用神经网络的方法,利用消费者物价指数、工业增加值和货币供给等数据,分别以BP神经网络、RBF神经网络和Elman神经网络建立通货膨胀预测模型。
三个模型预测结果表明,采用神经网络方法建立的模型能够较好地预测通货膨胀的变动。
通过比较BP神经网络和Elman神经网络预测结果可以看出,带有反馈机制的神经网络模型预测性能优于一般神经网络模型。
关键词:通货膨胀预测神经网络通货膨胀预测对于一个国家的经济运行非常重要。
宏观政策制定者往往密切关注未来的通货膨胀趋势, 以作为制定宏观经济政策的参考因素之一。
国外学者对通货膨胀预测做了相关研究。
如Gabriel Moser(2007)比较了预测澳大利亚通货膨胀的因素模型、V AR模型和ARIMA模型三种模型,实证结果表明因素模型优于V AR及ARIMA模型。
Kirstin Hubrich(2005)的研究利用Random Walk方法、V AR方法、AR方法、菲利普斯曲线方法等方法预测欧洲地区的通货膨胀。
Prasad S. B(2008)研究发现,考虑汇率因素会提高通货膨胀的预测精度。
Cludia Duarte(2007)将总的通货膨胀指标看作不同层次的分解变量组合,如分解为教育、食品等不同的成分,并将分解后不同层次的成分使用不同的模型进行研究。
国内学者研究了我国通货膨胀的预测问题。
如张德生等(2007)利用非参数回归模型建立了我国通货膨胀模型,预测结果良好。
陈慎思(2005)研究了我国通货膨胀和GDP增长率之间的关系,研究表明通货膨胀率与GDP增长率之间存在着三次回归模型的非线性关系。
近年来,人工智能和神经网络技术的快速发展使得神经网络在金融及经济学中应用越来越广泛。
神经网络对非线性关系模拟预测具有的特有优势,对金融时间序列数据具有很好的预测能力。
Saeed Moshiri et al(1999)研究了静态、动态及混合型的神经网络在通货膨胀预测方面的应用。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
使用贝叶斯模型平均方法(BMA)对中国通
货膨胀建模并预测
Modeling and Forecasting Inflation in China:A Bayesian
Model Averaging Approach
陈伟
指导教师姓名: 牛霖琳助理教授
专业名称: 金融学
摘要
本文使用贝叶斯模型平均(BMA) 方法对中国通货膨胀建立模型,并对2007
年1月到2009年6月的通货膨胀进行样本外预测。贝叶斯模型平均(BMA)方法是
一种模型综合的方法,本文中被综合的模型是基于28个解释变量的正态线性回归
模型,这些解释变量涵盖了中国经济的各个方面。通过对28个变量进行组合,可
以衍生出228个线性回归模型,每一个模型或多或少能够对通货膨胀做出解释。
但是对于如此庞大的备选模型,实证上不可能对所有模型进行加权平均,因此本
文采用了马尔科夫链蒙特卡洛模型综合算法对模型进行选择,选择次数为1000
万次。对于马尔科夫链蒙特卡洛模型综合算法的收敛性,通过比较模型后验概率
的解析值和模拟值相似性可以得到证明。本文的研究结果表明,通货膨胀一阶滞
后作为预测因子包含在所有预测模型中;贝叶斯模型平均方法对于通货膨胀的样
本内拟合优于单一最优模型和五变量简单回归模型;对于样本外预测,在
RMSE
标准下,贝叶斯模型平均方法的预测能力优于AR模型、主成分分析模型、菲利普
斯曲线模型、利率期限结构模型、单一最优模型和五变量模型。
关键词:贝叶斯模型平均,通货膨胀,蒙特卡洛模拟,MC3
Abstract
This paper focuses on the forecasting of inflation out-of sample in
China using Bayesian Model Averaging(BMA) method. The general framework
model is a simple linear regression model using a large set of potential
indicators, comprising some 28 monthly time series covering a wide
spectrum of Chinese economic activity. I will use the MC3 method to choose
the model which can best forecast inflation. The results show that the
BMA method do better than the Philips curve model, term structure model,
the AR model and the model using principal component analysis.
KeyWords: BMA, Inflation, Bayesian Model Averaging, MC3