A Hierarchical Recurrent Neuro-Fuzzy System
PDP 模型

PDP 模型It is a theoretical framework which adopts some assumptions about the nature of the representations and processes that subserve semantic memory: namely, those articulated in the parallel distributed processing (PDP) paradigm (Rumelhart, McClelland, & PDP Research Group, 1986). The principles embodied in PDP networks offer a powerful set of tools for understanding learning and development, generalization and induction, the time-course of processing, and the breakdown of cognitive function as a result of neuroanatomic deterioration. These principles apply to human cognition generally, and extend well to the domain of semantics in particular.In contrast to categorization based theories, the PDP framework posits that all semantic knowledge is stored in and processed by the same set of hardware elements (the weights and units respectively). Generalization of stored knowledge to new items and situations results as a natural consequence of the similarities among object representations in a given context, and not from the operation of a categorization mechanism and taxonomic processing hierarchy. The representation of objects as patterns of activity across real-valued units allows the network to capture the disparate, graded, and quasi-regular relations that exist in the semantic domain. The backpropagation learning algorithm provides a concrete mechanism for acquiring semantic information (McClelland, 1995), and hence may help to explain the development of conceptual knowledge in childhood and expertise.The models are variants of an architecture first proposed by Rumelhart (Rumelhart 1990; Rumelhart & Todd 1993) .Rumelhart was interested in understanding how the propositional information stored in a hierarchical propositional model could be acquired and processed by a connectionist network employing distributed internal representations. Thus, the individual nodes in the Rumelhart network’s input and output layers correspond to the constituents of propositions – the items that occupy the first (subject) slot in each proposition, relation terms that occupy the second slot, and the attribute values that occupy the third slot. Each item is represented by an individual input unit in the layer labeled Item, each relation is represented by the individual units in the layer labeled Relation, and the various possible completions of three element propositions are represented by individual units in the layer labeled Attribute. When presented with a particular Item and Relation pair in the input, the network’s job is to turn on the attribute units in the output that correspond to valid completions of the proposition.The network consists of a series of nonlinear processing units, organized into layers, and connected in a feedforward mannerUnder this approach, the main function of the semantic system is to support performance on tasks that require one to generate, from perceptual or linguistic input, properties of objects and events that are not directly apparent in the environment. The representations that support semantic task performance consist of patterns of activity across a set of units in a connectionist network, with semantically related objects represented by similar patterns of activity. In a given semantic task, these representations may be constrained both by incoming information about the item of interest (in the form of a verbal description, a visual image, or other sensory information) and by the context in which the item is encountered.The two parts of the input in the model – the Item and Context units – represent a perceived object (perhaps foregrounded for some reason to be in the focus of attention) and a context provided by other Information available together with the perceived object. Different item/context input pairs provoke different patterns of activation across internal representation units; and the instantiation of any particular pattern of activation propagates forward to allow the system to generate an output specifying the relevant object properties, which are encoded in the model’s outpu ts.。
北大内部Python教程(含课件)

北大内部Python教程(含课件)目录•Python基础语法•Python高级特性•Python科学计算库NumPy •Python数据分析库pandas •Python机器学习库scikit-learn•Python Web开发框架Django01Python基础语法变量与数据类型变量定义在Python中,变量无需事先声明,可以直接赋值。
变量名可以包含字母、数字和下划线,但必须以字母或下划线开头。
数据类型Python中的数据类型包括整数、浮点数、布尔值、字符串、列表、元组、字典和集合等。
可以使用`type()`函数来查看变量的数据类型。
类型转换Python提供了多种内置函数来实现数据类型之间的转换,如`int()`、`float()`、`str()`等。
1 2 3使用`if`、`elif`和`else`关键字来实现条件判断,根据条件执行不同的代码块。
条件语句使用`for`和`while`循环来遍历序列或执行重复操作。
在循环中,可以使用`break`和`continue`来控制循环流程。
循环语句使用`switch`语句(在Python中通过字典或函数实现)来根据不同的条件执行不同的操作。
选择语句控制流语句函数定义与调用函数定义使用`def`关键字来定义函数,指定函数名、参数列表和函数体。
函数调用通过函数名和参数列表来调用函数,执行函数体中的代码并返回结果。
参数传递Python中的参数传递采用传值方式,对于可变对象(如列表和字典),在函数内部对其修改会影响原始对象。
文件操作与异常处理文件操作使用`open()`函数来打开文件,并指定打开模式(如读取、写入或追加)。
然后可以使用文件对象的方法(如`read()`、`write()`和`close()`)来进行文件读写操作。
异常处理使用`try`和`except`语句块来捕获和处理异常。
可以在`try`块中编写可能引发异常的代码,在`except`块中处理异常。
视觉问答(VQA)综述
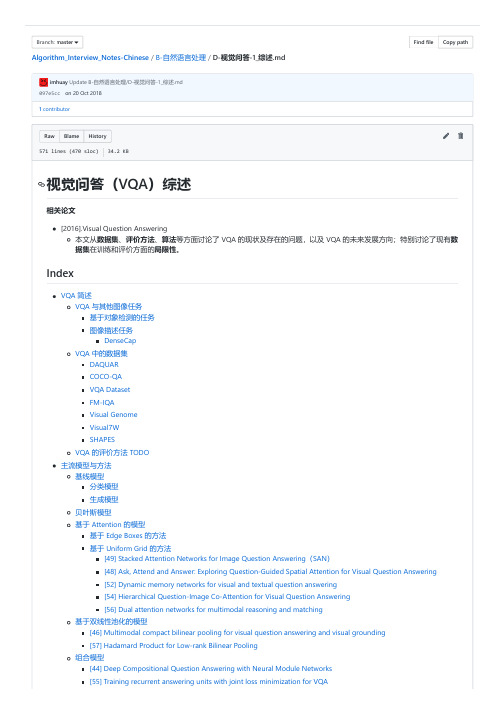
097e5cc标签歧义【图1】目标检测和语义分割语义分割或实例分割都不足以全面理解整个场景;其中主要的问题在于标签歧义(label ambiguity)比如上述图中“黄叉”的位置取 "bag"、"black"、"person" 之一都没有问题。
一般来说,具体选取哪个标签,取决于具体的任务。
此外,目前的主流方法(CNN+标签)不足以理解物体在整个场景下的作用(role)比如,将“黄叉”位置标记为 "bag" 不足以了解该包与人的关系;或者标记为 "person" 也不能知道这个人的状态(跑、坐、...)理想的 VQA 要求能够回答关于图像的任意问题,因此除了基本的检测问题,还需要理解对象彼此,以及和整个场景之间的关系。
图像描述任务除了 VQA 外,图像描述(image captioning)是另一个比较主流的、需要结合 CV 和 NLP 的任务。
图像描述任务的目标是对给定图像生成相关的自然语言描述。
结合 NLP 中的一些方法(RNN等),生成描述有不同的解决方案。
但是,图像描述的另一个难点是评价。
一些自动评价方法:BLEU、ROUGE、METEOR、CIDEr这些方法中,除了 CIDEr,最初都是为了评价机器翻译的结果而提出的。
这些方法每一个都存在一些局限性,它们常常将由机器生成的标题排在人工标题之前,但从人的角度看,这些结果并不够好,或者说不是目标描述。
评价的一个难点在于,给定图像可以存在许多有效的标题,这些标题可以比较宽泛,也可能很具体。
比如【图1】既可以描述为"A busy town sidewalk next to street parking and intersections.";也可以使用 "A woman jogging with a dog on a leash."如果不加限制,图像描述系统总是倾向于生成“得分”更高的表述。
spatio-temporall...

Spatio-Temporal LSTM with Trust Gates for3D Human Action Recognition817 respectively,and utilized a SVM classifier to classify the actions.A skeleton-based dictionary learning utilizing group sparsity and geometry constraint was also proposed by[8].An angular skeletal representation over the tree-structured set of joints was introduced in[9],which calculated the similarity of these fea-tures over temporal dimension to build the global representation of the action samples and fed them to SVM forfinal classification.Recurrent neural networks(RNNs)which are a variant of neural nets for handling sequential data with variable length,have been successfully applied to language modeling[10–12],image captioning[13,14],video analysis[15–24], human re-identification[25,26],and RGB-based action recognition[27–29].They also have achieved promising performance in3D action recognition[30–32].Existing RNN-based3D action recognition methods mainly model the long-term contextual information in the temporal domain to represent motion-based dynamics.However,there is also strong dependency between joints in the spatial domain.And the spatial configuration of joints in video frames can be highly discriminative for3D action recognition task.In this paper,we propose a spatio-temporal long short-term memory(ST-LSTM)network which extends the traditional LSTM-based learning to two con-current domains(temporal and spatial domains).Each joint receives contextual information from neighboring joints and also from previous frames to encode the spatio-temporal context.Human body joints are not naturally arranged in a chain,therefore feeding a simple chain of joints to a sequence learner can-not perform well.Instead,a tree-like graph can better represent the adjacency properties between the joints in the skeletal data.Hence,we also propose a tree structure based skeleton traversal method to explore the kinematic relationship between the joints for better spatial dependency modeling.In addition,since the acquisition of depth sensors is not always accurate,we further improve the design of the ST-LSTM by adding a new gating function, so called“trust gate”,to analyze the reliability of the input data at each spatio-temporal step and give better insight to the network about when to update, forget,or remember the contents of the internal memory cell as the representa-tion of long-term context information.The contributions of this paper are:(1)spatio-temporal design of LSTM networks for3D action recognition,(2)a skeleton-based tree traversal technique to feed the structure of the skeleton data into a sequential LSTM,(3)improving the design of the ST-LSTM by adding the trust gate,and(4)achieving state-of-the-art performance on all the evaluated datasets.2Related WorkHuman action recognition using3D skeleton information is explored in different aspects during recent years[33–50].In this section,we limit our review to more recent RNN-based and LSTM-based approaches.HBRNN[30]applied bidirectional RNNs in a novel hierarchical fashion.They divided the entire skeleton tofive major groups of joints and each group was fedSpatio-Temporal LSTM with Trust Gates for3D Human Action RecognitionJun Liu1,Amir Shahroudy1,Dong Xu2,and Gang Wang1(B)1School of Electrical and Electronic Engineering,Nanyang Technological University,Singapore,Singapore{jliu029,amir3,wanggang}@.sg2School of Electrical and Information Engineering,University of Sydney,Sydney,Australia******************.auAbstract.3D action recognition–analysis of human actions based on3D skeleton data–becomes popular recently due to its succinctness,robustness,and view-invariant representation.Recent attempts on thisproblem suggested to develop RNN-based learning methods to model thecontextual dependency in the temporal domain.In this paper,we extendthis idea to spatio-temporal domains to analyze the hidden sources ofaction-related information within the input data over both domains con-currently.Inspired by the graphical structure of the human skeleton,wefurther propose a more powerful tree-structure based traversal method.To handle the noise and occlusion in3D skeleton data,we introduce newgating mechanism within LSTM to learn the reliability of the sequentialinput data and accordingly adjust its effect on updating the long-termcontext information stored in the memory cell.Our method achievesstate-of-the-art performance on4challenging benchmark datasets for3D human action analysis.Keywords:3D action recognition·Recurrent neural networks·Longshort-term memory·Trust gate·Spatio-temporal analysis1IntroductionIn recent years,action recognition based on the locations of major joints of the body in3D space has attracted a lot of attention.Different feature extraction and classifier learning approaches are studied for3D action recognition[1–3].For example,Yang and Tian[4]represented the static postures and the dynamics of the motion patterns via eigenjoints and utilized a Na¨ıve-Bayes-Nearest-Neighbor classifier learning.A HMM was applied by[5]for modeling the temporal dynam-ics of the actions over a histogram-based representation of3D joint locations. Evangelidis et al.[6]learned a GMM over the Fisher kernel representation of a succinct skeletal feature,called skeletal quads.Vemulapalli et al.[7]represented the skeleton configurations and actions as points and curves in a Lie group c Springer International Publishing AG2016B.Leibe et al.(Eds.):ECCV2016,Part III,LNCS9907,pp.816–833,2016.DOI:10.1007/978-3-319-46487-950。
会议日程安排
阎朝坤 (马敬敬)
云南大学 中山大学 上海大学 河南大学
7
CBC 2019
第一阶段 主持人
时间
13:45-14:10
分会场三:蛋白质结构预测与计算(13:45-18:10,纽约厅)
章乐,四川大学计算机学院,教授,副院长 郭菲,天津大学智能与计算学部,副教授
题目
报告人
Deep Learning for Protein Bioinformatics and Medicine
Phenotype
Identification of Key Regulatory Genes and Pathways in Prefrontal Cortex of Alzheimer’s Disease
李伟忠 (姚国财)
谢江 (杨伏长)
17:45-18:05 [ID:77]
Research on Feature Selection Strategy Based on Wrapper Model for High Dimensional Microarray Data
题目
报告人
主持人
用人工智能进行常见眼病筛查诊 断、风险和预后预测的研究
刘奕志 中山大学中山眼科国家重点 实验室主任、眼科医院院长
王建新 中南大学计算机学院教授,院
长
New Findings for Rearrangement Events and Efficient Algorithms for Longest Common Subsequence with
Integrative Analysis of Multi-Dimensional Cancer Genomics Data
张世华 郑春厚
多尺度分类挖掘算法

收稿日期:2020 01 13;修回日期:2020 03 03 基金项目:国家社科基金重大项目(13&ZD091,18ZDA200) 作者简介:张璐璐(1993 ),女,河北景县人,硕士,主要研究方向为数据挖掘、智能信息处理;赵书良(1967 ),男(通信作者),河北献县人,教授,博导,主要研究方向为数据挖掘、智能信息处理(zhaoshuliang@sina.com);田真真(1994 ),女,河北威县人,硕士,主要研究方向为数据挖掘、智能信息处理;陈润资(1981 ),男,河南潢川人,博士研究生,主要研究方向为数据挖掘、智能信息处理.多尺度分类挖掘算法张璐璐a,b,c,赵书良a,b,c ,田真真a,b,c,陈润资d(河北师范大学a.计算机与网络空间安全学院;b.河北省供应链大数据分析与数据安全工程研究中心;c.河北省网络与信息安全重点实验室;d.数学科学学院,石家庄050024)摘 要:多尺度分类挖掘多局限于空间数据,且对一般数据尺度特性进行分类的研究较少。
针对上述问题,进行普适的多尺度分类方法研究,以扩大多尺度适用范围。
从空间数据估计角度出发,结合层次理论和尺度特性,基于概率密度估计离散化方法,针对数据的多尺度特性进行分类挖掘。
以非局部均值和三次卷积插值为理论基础,利用Q统计和不一致度量进行操作,提出多尺度分类尺度上推算法和多尺度分类尺度下推算法。
采用UCI数据集和H省人口真实数据集进行实验,并与CFW、MSCSUA和MSCSDA等算法进行对比,结果表明,该算法可行有效。
与其他算法相比,尺度上推算法正确率平均提高4.5%,F score提高4.8%,NMI提高12.3%,尺度下推算法各个相应指标分别平均提高5.3%,6.6%和11.8%。
关键词:多尺度;不一致度量;尺度转换;多尺度分类挖掘;Q统计中图分类号:TP391 文献标志码:A 文章编号:1001 3695(2021)02 016 0414 07doi:10.19734/j.issn.1001 3695.2020.01.0007Multi scaleclassificationalgorithmZhangLulua,b,c,ZhaoShulianga,b,c ,TianZhenzhena,b,c,ChenRunzid(a.CollegeofComputer&CyberSecurity,b.HebeiProvincialEngineeringResearchCenterforSupplyChainBigDataAnalytics&DataSecurity,c.KeyLaboratoryofNetwork&InformationSecurity,d.SchoolofMathematicalSciences,HebeiNormalUniversity,Shijiazhuang050024,China)Abstract:Multi scaleclassificationminingaremostlylimitedtospatialdata,andtherearefewresearchesonscalecharacteristicsofgeneraldata.Bysolvingtheaboveproblems,thispapertriedtostudytheuniversalmulti scaleclassificationmethod,inordertoexpandthescopeofmulti scaleapplication.Fromtheperspectiveofspatialdataestimation,combinedthehierar chicaltheoryandscalecharacteristics,andbasedonthediscretizationmethodofprobabilitydensityestimation,thispaperstudiedtheclassificationminingonmulti scalecharacteristicsofgeneraldata.Basedonthetheoryofnon localmeananddoublecubeinterpolation,usingQstatisticsandinconsistentmeasurementtooperate,itproposedtheupscalingalgorithmofmulti scaleclassificationanddownscalingalgorithmofmulti scaleclassification.ThispaperperformedexperimentsonUCIda tasetsandHprovincerealpopulationdataset,andcomparedwithCFW,MSCSUA,MSCSDAandotheralgorithms.Theresultsshowthatthealgorithmsinthispaperarefeasibleandeffective.Comparedwithotheralgorithms,theupscalingalgorithmimprovesaccuracyby4.5%,Fscoreby4.8%andNMIby12.3%andthedownscalingalgorithmimprovesthecorrespon dingindexesby5.3%,6.6%and11.8%.Keywords:multi scale;disagreementmeasure;scaleconversion;multi scaleclassificationmining;Qstatistics0 引言尺度是各种数据自身的属性,普遍存在于客观世界中[1,2]。
RadLex-DICOM
• Disclosure:
– Consultant, Elsevier, Inc. – Radiology Advisory Board, GE Healthcare
Outline
• RadLex background • RadLex status report
– RadLex 2.0 overview – Early adoption – Future plans
What about the other 4 fingers?
What about synonyms (e.g., index finger)?
Identifying Studies of Interest Problems with CPT
Key information is not explicit : • • Thorax and chest are synonyms MRI chest w/o dye and CT chest w/o dye use different modalities to image the same anatomic region CT thorax w/o dye and CT thorax w/dye are the same procedure, except for administration of IV contrast CT angiography, chest is similar to CT thorax w/dye, except the former is designed to visualize the vascular system CT thorax w/o&w dye is a combination of CT thorax w/o dye and CT thorax w/dye
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
∏
∑
…
νl
(j)
∑
…
∑
ν l( k ) ( yk ) = e 2 (
ˆl( k ) ) 2 −( yk − c
2 ˆ l( k ) α
νk(n)
)
,
where ν l( k ) is the l-th fuzzy set assigned to output yk. (ii) Each rule is a tuple Rr = ( µ j rr1 ,, µ j rrn ,ν l r r1 ,,ν l r rn )
i , j :µ (j i ) ∈ Ant ( r )
(iv) The output of the system for each output variable yk is computed by a weighted sum: ∑ area(ν l(k ) , ar (t )) ⋅ center(ν l(k ) , ar (t )) yk (t ) =
system data usually has to be preprocessed or restructured to map the dynamic information appropriately. In this paper a model is presented that was designed to learn and optimize a hierarchical fuzzy rule base with feedback connections. The model is restricted to optimize fuzzy systems using Mamdani-like fuzzy rules. Logistic or Gaussian-like fuzzy sets can be used to define the membership functions of the antecedents and Gaussian-like fuzzy sets to define the consequents. In the following the structure of the model and the used learning methods are described. Furthermore, an application example is presented. 2. Model Structure The main idea of this model is to combine simple feedforward fuzzy systems – which may consist of just one rule – to arbitrary hierarchical models. Therefore, the interpretability of every part is ensured before, during and after optimization. Backward connections between the models are realized by time-delayed feedback links. The interpretability of the fuzzy sets is ensured by the use of coupled weights in the consequents (fuzzy sets, which are assigned to the same linguistic terms share their parameters) and in the antecedents (layer two). Furthermore, constraints can be defined, which have to be observed by the learning method, e.g. that the fuzzy sets have to cover the considered state space. A possible structure is shown in Figure 1. A formal definition is given in the following. Definition 1. Let Ant(r) be the set of the fuzzy sets used in the antecedent and Con(r) be the set of the fuzzy sets used in the consequent of rule r, then the recurrent neuro-fuzzy system is a fuzzy system with the following specifications: (i) All fuzzy sets µ (ji ) ( xi ) ∈ Ant (r ) are defined by
Abstract Fuzzy systems, neural networks and its combination in neuro-fuzzy systems are already well established in data analysis and system control. Especially, neurofuzzy systems are well suited for the development of interactive data analysis tools, which enable the creation of rule-based knowledge from data and the introduction of a-priori knowledge into the process of data analysis. However, its recurrent variants - especially recurrent neuro-fuzzy models - are still rarely used. In this article a (hybrid) recurrent neuro-fuzzy model is presented which is designed for application in time series prediction and identification of dynamic systems. It has been implemented in a tool for the interactive design of hierarchical recurrent fuzzy systems. 1. Introduction The main idea of neuro-fuzzy systems is to combine the advantages of fuzzy systems (e.g. interpretability, use of prior knowledge for initialization) with the learning capabilities of neural networks. Thus, using fuzzy rules, it is possible to interpret the network structure and to introduce prior knowledge to the learning process in a convenient way. A disadvantage of these approaches is that in most cases the quality of the solution result is reduced due to the constraints that ensure the interpretability. However, meanwhile a lot of models have been proposed for control [1, 2, 3], classification [4, 5] and function approximation [6, 7]. For a detailed overview of neuro-fuzzy systems see, for example, [8, 2, 9]. Despite of the research that has already been done in the area of neuro-fuzzy systems the recurrent variants of this architecture are still rarely studied. One of the first approaches was presented in [10]. However, in contrast to pure feed-forward architectures, that have a static input-output behavior, recurrent models are able to store information of the past (e.g. prior system states) and are thus more appropriate for the analysis of dynamic systems. If pure feed-forward architectures are applied to these types of problems (e.g. prediction of time series data or physical systems), the obtained
A Hierarchical Recurrent Neuro-Fuzzy System
Andreas Nürnberger University of Magdeburg, Faculty of Computer Science 39106 Magdeburg, Germany E-mail: andreas.nuernberger@cs.uni-magdeburg.de Fax: +49 391 67 12018, Phone: +49 391 67 11358