Blind Separation of Speech Signals Based on a Lattice-Ica Geometric Procedure
盲源分离算法的分类

盲源分离算法的分类
盲源分离(Blind Source Separation, BSS)算法是一类用于提取混合信号中各自独立源信号的技术,常见分类包括:
1. 独立成分分析(Independent Component Analysis, ICA):通过最大化源信号统计独立性来分离信号,常用于处理非高斯信号。
2. 主成分分析(Principal Component Analysis, PCA)及相关方法:用于线性相关的信号分离,侧重于最大化信号方差。
3. 第二阶盲信号分离(Second-order Blind Identification, SOBI):利用信号的二次统计特性,如互协方差矩阵和时间延迟来分离源。
4. 时空盲源分离(Spatial and Temporal Blind Source Separation):针对多通道信号,结合空间布局信息和时间动态特征进行分离。
5. 基于深度学习的盲源分离:利用神经网络模型从混合信号中学习分离映射关系。
每种方法都有其适用范围和优势,选择合适的方法取决于信号特性及应用场景。
语音信号盲分离—ICA算法PPT29页

46、我们若已接受最坏的,就再没有什么损失。——卡耐基 47、书到用时方恨少、事非经过不知难。——陆游 48、书籍把我们引入最美好的社会,使我们认识各个时代的伟大智者。——史美尔斯 49、熟读唐诗三百首,不会作诗也会吟。——孙洙 50、谁和我一样用功,谁就会和我一样成功。——莫扎特
语音信号盲分离—ICA算法
6、法律的基础有两个,而且只有两个……公平和实用。——伯克 7、有两种和平的暴力,那就是法律和礼节。——歌德
8、法律就是秩序,有好的法律才有好的秩序。——亚里士多德 9、上帝把法律和公平凑合在一起,可是人类却把它拆开。——查·科尔顿 10、一切法律都是无用的,因为德谟耶克斯
基于ResNet-LSTM的多类型伪装语音检测

(7)
ht = ot ⊗ tanh(ct )
(8)
其中 U1,W1,b1 为线性关系的系数和偏置,σ 为 Sigmoid
激活函数,⊗为 Hadamard 积(对应位置相乘)。
2.3 ResNet-LSTM 网络
本文提出的 ResNet-LSTM 结构如表 1 所示。网络由
xt
xt
Input Gate it
(3)关于语音变形 (Voice Transformation, VT) 的
方法。
研究,大多利用如频谱图、修改群延迟(MGD)和梅尔普
1 伪装语音检测研究现状
倒谱系数(MFCC)作为特征再利用支持向量机(SVM)、
近年来,自动说话人验证(Automatic Speech Verification, ASV)系统这种低成本的生物识别技术已被广泛地应用
Output Gate Ot
Cell
xt
CtLeabharlann htft Forget Gate
xt
图 4 LSTM 记忆单元结构图 Fig.4 LSTM memory unit structure diagram
13 Copyright©博看网. All Rights Reserved.
第 41 卷
数字技术与应用
现有的关于伪装语音检测的研究主要集中在三种不 判断结果。实验结果表明,该方法在多种类型的伪装语
同的伪装类型 :
音检测上都有超过 90% 的识别精度,能应对各种不同时
(1)语音转换(Voice Conversion, VC)和语音合 长及不同类型的伪装语音攻击。
成(Speech Synthesis, SS)方面 :F. Hassan 等人提出 2 多类型伪装语音检测系统
基于特征音素的说话人识别方法

基于特征音素的说话人识别方法第28卷第1O期2007年1O月仪器仪表ChineseJournalofScientificInstrumentV o1.28No.100ct.2007基于特征音素的说话人识别方法王昌龙,周福才,凌裕平,於锋(1扬州大学机械学院扬州225009;2扬州大学农学院扬州225009)摘要:本文提出了一种基于特征音素的说话人识别方法,并在低成本门禁系统中获得实现.首先利用清音和浊音悬殊的数字特征将语音信号中的清音和浊音分离,再将分离后的几个浊音的特征频率和相对强度作为特征参数组成3O维特征向量.在Pc上进行了高阶谱分析和快速傅里叶变换,比较了2种方法声韵分离的效果.然后分别用神经网络识别算法和模板比对法进行识别实验,主要应用目标为单住户语音门禁系统,具有自学习功能,能随着家庭成员的年龄和生理变化不断调整特征向量模板,该方法已在低成本单片机系统中实现.关键词:语音信号处理;说话人识别;特征提取;频谱分析中图分类号:TP312文献标识码:A国家标准学科分类代码:510.4010 SpeakerrecognitionbyspecialphonemesWangChanglong,ZhouFucai,LingYuping,YuFeng (JCollegeofMechanicalEngineering,Y angzhouUniversity,Y angzhou225009,China;2CollegeofAgricultural,Y angzhouUniversity,Y angzhou225009,China)Abstract:Aspeakerrecognitionmethodwasproposedbasedonspecialphonemes.Thisspea kerrecognitionmethodwasimplementedinalowcostvoicedoormanagingsystem.V oicedandunvoicedphonemeso ftimedomainspeech signalweredistinguishedbytheirgreatdifferencesindigitalcharacteristics.A30elementeig envectorwasextractedfromseveralvoicedphonemes.BothhighorderspectrumanalysisandFFTrmethodswereem ployedtodistinguishthevoicedandunvoicedphonemes.Thedistinguishingefficienciesofthesemethodswerecomp aredwitheachother. Recognitionexperimentswerecarriedoutusingneuralnetworkandtemplatematchingmeth ods.Singleinhabitant voicedoormanagingsystemisourmainapplicationtarget.Thesystemhasself-learningfunct ion,whichcanadjust theeigenvectoraccordingtophysiologicalchangesoftheinhabitant.Thismethodhasbeenim plementedinlowcostsinglechipmicrocomputersystems.Keywords:speechsignalprocessing;speakerrecognition;featureextraction;spectrumanal ysis1引言目前,开锁公司众多,开锁队伍良莠不齐.只要打个电话,许多服务人员不要求查看任何证件,收费就给开锁,对居室安全带来严重威胁.本课题设计了一种多信息智能锁具,附加在原有锁具附近,具有人声,密码等多种信息识别功能.电子锁具位于室内,有效地防止了非收稿日期:2007-02ReceivedDate:2007-02基金项目:江苏省教委科学研究基金(06KJB510135)资助项目法开锁.该系统以单片机为核心,具备声音采集功能和电磁执行机构.本文主要介绍其中的说话人识别部分.说话人识别是语音识别的一个重要分支,在公安侦察,声控装置,甚至在医生进行病情诊断等方面都有着广泛的应用. 说话人识别和语音识别的主要差别在于,它并不注重语音信号的含义,只是从语音信号中提取出个人的声道,发音习惯等特征信息.因此,说话人识别是深入挖掘出包1832仪器仪表第28卷含在语音信号中的个性因素,而语音识别是从不同人的语音信号中寻找共同因素.2说话人识别基本原理2.1发声方式人的发声过程是通过肺部的收缩压迫气流由支气管经过声门和声道引起音频振荡而产生的.发音有3种激励方式:(1)气流通过声门时声带发生较低频率的振荡, 形成准周期性的空气脉冲,脉冲激励声道产生浊音,脉冲周期就是基音周期;(2)如果把声道最小截面面积控制得很小,气流高速冲过,形成清音;(3)声道某处完全封闭,气流突然冲出形成爆破音.2.2清浊音的分离清音频谱近似白噪声,虽然对于人耳听辩语义有重要的意义,但对于说话人识别不能提供多少有用信息. 而浊音由几种频率的正弦波叠加而成,构成人的"声纹" 数据,对于说话人识别有重要价值引.本文对每一帧采样信号分别进行高阶谱估计和FFr变换.定义浊音度为几个峰值频率的能量之和与总能量之比为:∑s:()V=L(1)∑s2()=I5.02.5孽0.0-2.5-5.O5.02?5孽0.0-2.5-5.0式中:为浊音度,即特征频率能量之和与频谱总能量之比.V=0为清音,相当于白噪声;V=1为浊音;V:0—1之间为清浊音混合帧口.Ⅳ为特征频率(共振峰)个数, 为采样点数的一半(512),s2(i)为第i个特征频率成分的能量.2.3浊音音素特征的提取对于浊音帧,用一组中心频率可调的窄带滤波器对采样信号(t)进行带通滤波,再对各频率分量A,(t)取平方,得到功率谱密度:r,,,.G(:‰寺一㈩d(2)对于离散时问信号(rt),通过对其自相关函数()l-+,作快速傅里叶变换得到功率谱密度:()=2h∑()c0s~xk__zr,其中r:一m,…,一1,0,1,…,m一1,为时延数;h为采样时间间隔;Ⅳ为每帧采样点数.清浊音分离后进行浊音音素的识别,根据人们同一浊音的发音特点,"a","o","e"等韵母中,能量集中的频带内能量之比,不同音素差别很大,可以识别出具体的浊音音素(见图2—5).02505oo750loool25o15001750200022502500025*******loool250l500l75020002250250027503000(b)去除清音帧后的浊音波形~一一一一.一一.…一A一人一H(c)浊音帧频谱图1汉字"胡"的时域波形记录和分离出的浊音波形以及浊音帧频谱Fig.1Timedomainwaveform_recordingofChinesesyllable"hu",itsseparatedvoicewavefo rmandspectrum第1O期王昌龙等:基于特征音素的说话人识别方法l8332.4特征向量的构成说话人识别技术的难点在于尚未找到简单可靠的语音特征参数,也没有发现简单的声学参数能够可靠地识别说话人.而语音信号的时变特征,情绪,环境和健康因素的影响更增加了特征提取的难度,因此研究人员至今仍在不断寻找更好的识别方法.说话人有关的特征参数大体分2类:一类是生理因素决定的固有参数,如基音和共振峰,不易被模仿,但受健康状况和年龄影响;另一类是发音习惯决定的动态参数,比较稳定但容易被模仿".图2—4每幅图包含30多帧对同一个人"a","e","u"3个浊音的采样数据的频谱分析结果,可见频谱比较稳定,但每种频率成分的幅度时变明显.图5为不同音量下特征频率成分的幅度比较,可见随着音量的改变,每种频率的幅度变化趋势相近,即随音量的增加,各频率成分幅度都有相近的增加程度(直流分量除外).这就为进行图2浊音…a'30次采样的频谱Fig.2Spectrumof30voicea'samples图3浊音…e'30次采样的频谱Fig.3Spectrumof30,voicee'samples图4浊音"u"3O次采样的频谱Fig.4Spectrumof30voice''O"samples图5音量变化时频谱幅度同时增减Fig.5Spectrumamplitudevarieswithvolume为了提高可靠性,防止单一音素被他人模仿,根据汉语普通话的音节结构框架细节(见图6),每个人发音习惯不同,过渡方式不同,本文选用了几个特征音素组成高维特征向量,为了增加安全性还可以定期更换特征音素.l23456789图6汉语普通话语音结构框架Fig.6SyllableframeofChinesePutonghua3说话人识别系统的实现用驻极体话筒和音频放大电路获取语音信号,语音信号A/D采样率为8kHz.对采集到的语音信号进行帧分割,每帧1024点.采集的语音信号中提取[a],[o],[I1]等浊音音节,采用神经网络和模板比对2种识别算法进行识别实验, 将现场提取的特征向量与特征库中存储的频谱和相对幅1834仪器仪表第28卷度进行比较.这里提出的相对幅度概念是考虑到人们说话时音量可大可小,因此不同频率成分幅度大小只有相对意义,绝对值并不重要,只按幅度大小排出序号,不计绝对数值.每个浊音只选取频谱中幅度最大的5个频率作为特征,幅度最大的成分相对幅度为1,其余频率的幅度与最大幅度之比作为相对幅度.选取3个浊音建立了一个30 维的浊音特征向量,对于每个浊音来说,由5个频率及其各自的相对幅度组成.考虑到同一个人不同时问说相同内容也是时变的,特别是儿童成长中的"变声"现象,系统设计了学习功能,每次成功识别后对存储于24C02在线串行EPROM中的特征模板按照偏差的10%进行修正.3.1系统的软硬件组成说话人识别系统主要由语音传感器——驻极体话筒,音频信号放大滤波电路,A/D转换电路和单片机控制单元,执行单元组成.软件系统由数据采集与说话人识别软件组成,如图7,图8所示.图7系统硬件结构框图Fig.7Blockdiagramofsystemhardwarestructure采集子程序图8系统软件流程图Fig.8Flowchartofsoftwaresystem研制初期,首先在PC上进行了相关实验,取得了信号采集和特征提取方面的第一手资料.为在单片机系统中实现打下了基础.系统软件主要包括A/D转换启动触发,数据存储和模式识别,神经网络训练过程在Pc上完成.神经网络权值固化在单片机中的FlashROM中, 家庭成员的语音特征向量存储在串行EPROM中,每次识别成功后,按照新的特征向量与原先存储的特征向量差值的1/10进行修正.保证系统可以跟随少年儿童成长逐渐调整特征向量.3.2识别算法的效果比较目前语音识别所应用的模式匹配和模型训练技术主要有动态时间归整技术(DTW),隐马尔可夫模型(HMM)和人工神经元网络(ANN).文本相关的说话人识别方法容易被模仿,伪造,特别是样本数较大时,容易误识别.因此只有提取语音信号中与说话人有关的生物学信息,才不易被模仿,伪造.本文从语音信号中提取与说话人口腔,声道结构,发音习惯有关的特征信息,建立特征库,进行识别实验,取得了较为精确的识别结果,正确识别接收率达到97%.由于语音信号的时变特征,有时需要多次呼叫才能达到这一正确率,这是为了适应门禁系统的要求,允许偏差设置较小造成的,对于安全性要求不高的多人工作场所,可以通过增大允许偏差提高通过速度.4结论本文根据语音识别的基本原理,从语音信号中提取共性信息的一般方法,根据人类语音发音的共性特征提取特定音素.在这一点上比语音识别要求理解语意要简单得多.根据汉字发音的特点,除少数零声母汉字外,均为声一韵结构.而利用声母和韵母悬殊的频谱特征很容易将声母和韵母分离,再将分离后的几个韵母的特征参数组成高维特征向量,该方法易于在低成本单片机系统中实现,主要应用目标为单住户门禁系统.不需要记住特殊的口令,只要随便说几句话,包含常见的韵母即可. 参考文献【1】A VCIE.Anewoptimumfeatureextractionandclassifi. cationforspeakerrecognition[J].GWPNN,ExpertSys.temwithAlications,2007,32(4):485-498.[2]于哲舟.智能仪器嵌入式声纹识别技术方法[J].仪器仪表,2004,25(5):447-450.YUZHZH.Intelligentinstrumentembeddedvoicerecog. nitiontechnology[J].ChineseJournalofScientificIn strument,20O4,25(5):447-450.[3]王成儒.一种用于说话人辨认的概率神经网络的MCE 训练算法[J].仪器仪表,2002,23(8):154.156.W ANGCHR.MCE—basedPNNtrainingalgorithmfor speakeridentification[J].ChineseJournalofScientific第1O期王昌龙等:基于特征音素的说话人识别方法1835 Instrument,2002,23(8):154—156.[4]杨行峻,迟惠生.语音信号数字处理[M].北京:电子工业出版社,1995:4-26.Y ANGXJ.CHIHSH.Speechsignaldataprocess[M]. Bering:ElectronicIndustrialPress,1995:4-26.[5]马建芬.一种基于小波参数滤波的音素分段算法[J].电子测量与仪器,2001(2):36-39.MAJF.Anewspeechsegmentmethodbywaveletpa—rameterfiltering『J].JournalofElectronicMeasurement andInstrument,2001(2):36—39.[6]应娜,赵晓晖.语音清浊音分类及浊音谐波提取算法一三阶累积量基于正弦语音模型的应用[J].计算机工程与应用,2006(1):64.68.YINGN,ZHAOXH.Aspeechunvoiced/voicedclassi—ficationandvoicedharmonicextractionalgorithm--Using third?ordercumulantbasedonsinusoidalspeechmodel [J].ComputerEngineeringandApplications,2006,(1):648.[7]ZEKERIYAT.Aliedmel—frequencydiscretewaveletCO—efficientsandparallelmodelcompensationfornoise--ro-- bustspeechrecognition[J].Speechcommunication,2006,48(1):1294.1307.[8]MAHADEVASR.Extractionofspeaker—specificexitati—oninformationfromlinearpredictionresidualofspeech [J].SpeechCommunication,2006,48(8):1243—1261. [9]DIMITRIOSV.Emotionalspeechrecognition,resouree8, featuresandmethods[J].SpeechCommunication,2006,48(7):1162—1181.[10]ZHENYX.Atreebasedkernelselectionapproachtoef- ficientGaussianmixturemode1.universalbackground modelbasedspeskeridentifyication[J].SpeechCommu. nication,2006,48(9):1273—1282.作者简介王昌龙,男,1963年出生,1984年获浙江大学学士学位,1991年获江苏大学硕士学位,2003年获东南大学博士学位,现为扬州大学副教授,主要研究方向为传感器,信号处理和模式识别.地址:扬州大学机械学院,225009E—mail:******************* WangChanglong,male,bornin1963,receivedBScfrom ZhejiangUniversityin1984,MScfromJiangsuUniversityin 1991.andPhDfromSoutheastUniversityin2003.HeiSnowan associateprofessorinYangzhouUniversity.Hismainresearch fieldsaresensors,DSPandpatternrecognition.Address:MechanicalSchool,Y angzhouUniversity,Y angzhou 22509.Jiangsu,ChinaE.mail:*******************周福才,男,1964年出生,1993年获扬州大学硕士学位,2002年获华南农业大学博士学位,现为扬州大学副教授,主要研究方向为昆虫嗅觉感知.地址:扬州大学农学院,225009E.mail:**************.cnZhouFucai,male,bornin1964,receivedhismasterdegree fromY angzhouUniversityin1993,PhDfromSouthChinaAgIi—culturalUniversityin2002.HeisnowanassistantprofessorinY angzhouUniversity.Hismainresearchfieldsareinsectolfactory sensing.Address:AgriculturalCollege,Y angzhouUniversity,yangzhou 22509,Jiangsu,ChinaE—mail:**************.cn。
语音信号识别基于盲源信号分离的实现

语音信号识别基于盲源信号分离的实现张敏;于海燕;武克斌【摘要】The blind source separation (BSS) is usually used to distinguish two-channel sound signals of spectrum aliasing, but it is difficult to achieve in engineering practice. Therefore, a method which makes use of the principle and feature of blind source signal separation is introduced. The technological process to implement BSS with FastICA algorithm on ADSP_BF533 platform is described. The proposed scheme in this paper eonsumes less time, needs less memory and is high efficient.%为了识别两路频谱混叠语音信号,多采用盲信号分离的方法.但是该方法在工程实践中实现较困难.因此给出了一种利用盲源信号分离的原理及特点的实现方法,具体说明了用FastICA算法在ADSP_BF533平台上实现盲源信号分离时的具体流程.该设计方案所需时间短,效率高,而且占用内存较少.【期刊名称】《现代电子技术》【年(卷),期】2011(034)011【总页数】4页(P79-81,84)【关键词】盲信号分离;DSP;FastICA;ADSP_BF533平台【作者】张敏;于海燕;武克斌【作者单位】哈尔滨工业大学,威海,山东威海264209;哈尔滨工业大学,威海,山东威海264209;哈尔滨工业大学,威海,山东威海264209【正文语种】中文【中图分类】TN971.2-340 引言近年来,许多学者都针对盲信号分离不断地提出新的理论算法,盲信号分离(BSS)发展也日趋完善。
基于稀疏编码和ICA的带噪混叠语音盲分离
( I 1 2 利 用 最 大 似 然 估 计 法 ( ai m L eho 一 ) , M x u i lod m ki
Et ao , L ) sm t n M E 可由带噪信号 y得到 i i
*国家 自然科 学肇金 资助项 目(07 15 ; 6520 ) 高等学校博士学科点专项科研 基金资助项 目( o200 207 N .0542 1 ) 收稿 日期 :08—1 20 0—0 8
16 3
第 4期
杜
军 :基 于稀疏 编码和 IA的带 噪混 叠语音盲分离 C
第 2 卷 3
( 是列矢 量) W 为该神经元 网络权值矩 阵 , 网络 中只有少 数的一些 神经元权 值起主 要作用 . s s, … . ] 在该 设 =[ , 为该
一
些神经元权值起主要的作用… . 后来 H v i n对稀疏编码 的应用从 整体上进行 了系统 的分析 . y ̄n e 稀疏编码 的关
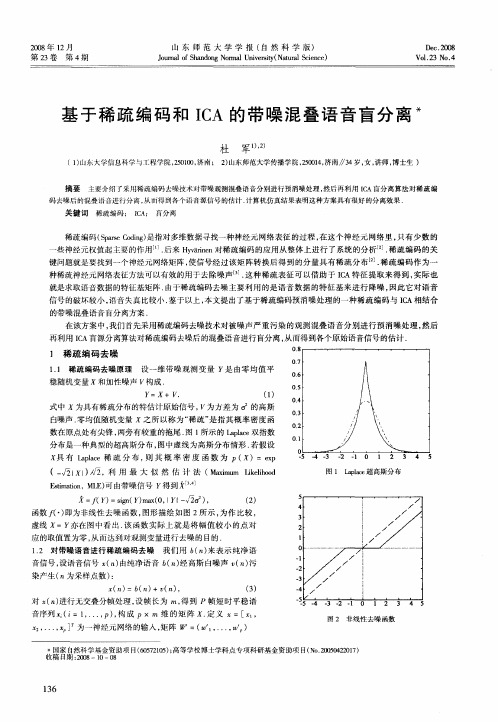
键 问题就是要找到一 个神经元 网络矩阵 , 一 使信号经 过该矩 阵转换后得 到 的分量 具有稀 疏分布 . 疏编码 作为一 』稀 种稀疏神经元 网络表征方法可 以有效的用于去除 噪声 . 这种稀 疏表 征可 以借 助于 IA特 征提取来 得到 , C 实际也
=
图 1 Lpae al 超高斯分布 c
厂 Y =s n r m x0 f 一 2 ) ( ) i ( ) a( , yf √ , g
() 2
/
/
函数 厂 ・即为非线性去 噪 函数 , () 图形描 绘如 图 2 示 , 所 为作 比较 ,
虚线 X=Y亦在图 中看 出 . 函数 实 际上 就是 将幅值 较小 的点对 该
镜像法解混响
We model the rooms of interest as simple rectangular enclosures. This choice of geometry is made for several reasons-
P(co,X,X') =exp[{o•(R/c 4•.R- t)]'
Image method for efficiently simulating small-room acoustics
Jont B. Allen and David A. Berkley
Acoustics Research Department, Bell Laboratories, Murray Hill, New Jersey 07974
basic studies of room acoustics.
(2) This model can be most easily realized in an efficient computer program. (3) The image solution of a rectangular enclosure
The room model assumed is a rectangular enclosure with a source-to-receiver impulse response, or transfer function, calculated using a time-domain image expansion method. Frequent applications have been made of the image method in the past as in deriving the re-
基于Conformer_的时域多通道语音分离方法
doi:10.3969/j.issn.1003-3106.2023.09.009引用格式:陈佳佳,张海剑,华光.基于Conformer的时域多通道语音分离方法[J].无线电工程,2023,53(9):2054-2060.[CHENJiajia,ZHANGHaijian,HUAGuang.Time domainMulti channelSpeechSeparationUsingConformer[J].RadioEngineering,2023,53(9):2054-2060.]基于Conformer的时域多通道语音分离方法陈佳佳,张海剑,华 光(武汉大学电子信息学院,湖北武汉430072)摘 要:多通道语音中的空间特征信息为说话人分离提供了重要的线索,为了更好地提取通道间信息并有效降低网络的处理时延,提出一种多通道时域语音分离方法。
利用多层编码器实现语音特征提取并挖掘通道间信息,在逐层编码过程中获得不同时间分辨率的语音特征并降低特征时间维度;引入Conformer结构对语音全局时间关系进行建模,在解码阶段使用特征加权跳跃连接融合对应编码层的输出特征进行解码,并将高维语音特征恢复为时域信号。
在基于LibriSpeech仿真的多通道混响带噪语音数据集中进行实验,实验结果表明,所提方法通过多层编解码机制充分利用了多通道语音信息并降低了网络处理时延,通过Conformer实现并行数据处理和全局时间关系建模,在推理速度、分离语音质量和语音感知质量方面均优于基线单通道和多通道时域语音分离算法。
关键词:语音分离;Conformer;多通道;多层编码器中图分类号:TN912.3文献标志码:A开放科学(资源服务)标识码(OSID):文章编号:1003-3106(2023)09-2054-07Time domainMulti channelSpeechSeparationUsingConformerCHENJiajia,ZHANGHaijian,HUAGuang(ElectronicInformationSchool,WuhanUniversity,Wuhan430072,China)Abstract:Thespatialinformationofmulti channelaudiosprovidesimportantcluesforspeakerseparation.Inordertobetterextracttheinter channelinformationandgetlowerprocessingdelay,amulti channeltime domainspeechseparationmethodisproposed.Firstofall,themultilayerencoderisusedtoextractspeechfeaturesandspatialinformation.Intheprocessoflayerbylayerencoding,speechfeatureswithdifferenttimeresolutionareobtainedandthefeaturetimedimensionisreduced.ThentheConformerstructureisusedtomodelthetemporalsequence.Inthedecodingstage,decoderlayer’sinputisweightedbycorrespondingencoderlayeroutput,andthemultilayerdecoderisusedtorestorehigh dimensionalspeechfeaturestotimedomainsignals.ExperimentsarecarriedoutonasimulateddatasetusingthecleanLibriSpeechcorpusthatismixedwithadditivenoisesunderreverberantconditions.Experimentalresultsshowthattheproposedmethodeffectivelyrealizestheextractionofmulti channelspeechinformationandreducesthenetworkprocessingdelaythroughthemulti layercodingmechanism,implementsparalleldataprocessingandglobaltemporalrelationshipmodelingbasedonConformerstructure,andoutperformsthebaselinesingle channelandmulti channeltime domainspeechseparationalgorithmsininferencetime,separationperformanceandtheperceptualspeechquality.Keywords:speechseparation;Conformer;multi channel;multilayerencoder收稿日期:2023-03-01基金项目:湖北省自然科学基金(2022CFB084)FoundationItem:HubeiProvincialNaturalScienceFoundationofChina(2022CFB084)0 引言人类的听觉系统可以轻松地从有噪声或者其他人声干扰的复杂声学环境中分离出目标声源信号,然而对于机器来说,这仍是一个极具挑战性的任务。
盲源分离算法在语音识别中的应用研究
盲源分离算法在语音识别中的应用研究随着智能化科技的不断发展,语音识别技术在我们的日常生活中越来越普及。
从手机助手中的语音输入,到智能音响上的指令控制,人机交互越来越趋向于语音化。
而在实现这些功能中,语音信号的预处理和识别技术扮演着至关重要的角色。
随着计算机处理能力的提升和信号处理算法的优化,语音信号的处理和识别精度已经大幅度提升。
本次文章将深入研究盲源分离算法在语音识别中的应用。
一、盲源分离算法的起源及原理盲源分离算法(Blind Source Separation, BSS)最早起源于独立成分分析(ICA, Independent Component Analysis)技术。
其基本思路是假设观测信号 $x$ 是由多个源信号 $s$ 线性加权叠加组成的,即 $x = A s$,其中 $A$ 为混合矩阵,$s$ 为源信号。
目标是在不知道 $A$ 和 $s$ 的情况下,利用 $x$ 恢复出原始的源信号 $s$。
盲源分离算法与传统的信号处理方法不同之处在于其不需要预先知道信号的特征和参数。
相反,它是通过对输入信号的分析和统计处理,来提取出源信号的特征。
传统的信号处理方法往往需要依靠个别信号的知识,然后利用这些知识来构建复杂的模型,来分析和处理信号。
而盲源分离算法则是利用多个信息流之间的相互作用和统计特性,来实现信号分离和恢复的过程。
二、盲源分离算法的应用盲源分离算法在语音处理领域的应用较为广泛,主要涉及信号降噪、语音选通、源定位、语音分离和语音识别等多个方面。
1.信号降噪:在实际的语音信号处理中,由于环境噪声的影响,会导致语音信号的质量下降,影响语音信号的分析和识别。
而通过盲源分离算法对噪声和语音信号进行分离和降噪处理,可以有效提升语音信号的质量,提高语音识别的准确性。
2.语音选通:语音选通(Voice Activity Detection,VAD)是识别不同语音节拍之间的静默间隙的过程。
这些信息对于识别发音很重要,并且可以被用在语音合成和语音压缩的应用中。
基于自适应MMSE-LSA与NMF的语音增强算法
第43卷第4
期
202 年8
月
探JournalofDetection & Control
Aug.202
基于自适应MMSE-LSA与
NMF的语音增强算法
董胡1,
刘冈『
2马振中
1
(1.长沙师范学院信息科学与工程学院
,湖南长沙
410100
;
2.中南大学物理与电子学院,湖南长沙
410012)
摘 要:
针对目前已有的语音增强算法在低信噪比的非平稳噪声环境下存在语音增强性能欠佳、计算复杂度
高、语音失真与音乐噪声的问题,提出基于自适应对数谱幅度的最小均方误差
(MMSE-LSA)与非负矩阵分解
(NMF)的语音增强算法。首先利用自适应MMSE-LSA估计器对含噪语音信号进行增强
,以提高输入信号的
信噪比,接着对增强后产生的语音失真和残留噪声利用
NMF算法进行补偿,既保证语音质量,
又尽可能地消
除噪声干扰。仿真实验结果表明,语音增强算法与经典的谱减算法、维纳滤波算法相比,不仅提高了输出信噪 比,而且降低了音乐噪声,在可懂度和清晰度方面均具有较明显的优势。关键词:语音增强;最小均方误差;非负矩阵分解;
语音失真
中图分类号:TN912. 35 文献标识码:A 文章编号:1008-1194(2021)04-0081-05
Speech Enhancement Algorithm Based on Adaptive MMSE-LSA and NMF
DONG Hu1 , LIU Gang1 '
2 ,
MA
Zhenzhong1
(1. School of information science and Engineering
, Changsha Normal University, Changsha
4 10100, China;
2. School of physics and electronics, Central South University, Changsha 4 10012, China.)
Abstract: Aiming at the problems of poor speech enhancement performance, high