第7章 非线性回归
《非线性回归分析》课件
封装式
• 基于模型的错误率和复 杂性进行特征选择。
• 常用的封装方法包括递 归特征消除法和遗传算 法等。
嵌入式
• 特征选择和模型训练同 时进行。
• 与算法结合在一起的特 征选择方法,例如正则 化(Lasso、Ridge)。
数据处理方法:缺失值填充、异常值 处理等
1
网格搜索
通过预定义的参数空间中的方格进行搜
随机搜索
2
索。
在预定义的参数空间中进行随机搜索。
3
贝叶斯调参
使用贝叶斯优化方法对超参数进行优化。
集成学习在非线性回归中的应用
集成学习是一种将若干个基学习器集成在一起以获得更好分类效果的方法,也可以用于非线性回归建模中。
1 堆叠
使用多层模型来组成一个 超级学习器,每个模型继 承前一模型的输出做为自 己的输入。
不可避免地存在数据缺失、异常值等问题,需要使用相应的方法对其进行处理。这是非线性回归 分析中至关重要的一环。
1 缺失值填充
常见的方法包括插值法、代入法和主成分分析等。
2 异常值处理
常见的方法包括删除、截尾、平滑等。
3 特征缩放和标准化
为了提高模型的计算速度和准确性,需要对特征进行缩放和标准化。
偏差-方差平衡与模型复杂度
一种广泛用于图像识别和计算机 视觉领域的神经网络。
循环神经网络
一种用于处理序列数据的神经网 络,如自然语言处理。
sklearn库在非线性回归中的应用
scikit-learn是Python中最受欢迎的机器学习库之一,可以用于非线性回归的建模、评估和调参。
1 模型建立
scikit-learn提供各种非线 性回归算法的实现,如 KNN回归、决策树回归和 支持向量机回归等。
第七章相关与回归分析

第七章 相关与回归分析一、本章学习要点(一)相关分析就是研究两个或两个以上变量之间相关程度大小以及用一定函数来表达现象相互关系的方法。
现象之间的相互关系可以分为两种,一种是函数关系,一种是相关关系。
函数关系是一种完全确定性的依存关系,相关关系是一种不完全确定的依存关系。
相关关系是相关分析的研究对象,而函数关系则是相关分析的工具。
相关按其程度不同,可分为完全相关、不完全相关和不相关。
其中不完全相关关系是相关分析的主要对象;相关按方向不同,可分为正相关和负相关;相关按其形式不同,可分为线性相关和非线性相关;相关按影响因素多少不同,可分为单相关和复相关。
(二)判断现象之间是否存在相关关系及其程度,可以根据对客观现象的定性认识作出,也可以通过编制相关表、绘制相关图的方式来作出,而最精确的方式是计算相关系数。
相关系数是测定变量之间相关密切程度和相关方向的代表性指标。
相关系数用符号“γ”表示,其特点表现在:参与相关分析的两个变量是对等的,不分自变量和因变量,因此相关系数只有一个;相关系数有正负号反映相关系数的方向,正号反映正相关,负号反映负相关;计算相关系数的两个变量都是随机变量。
相关系数的取值区间是[-1,+1],不同取值有不同的含义。
当1||=γ时,x 与y 的变量为完全相关,即函数关系;当1||0<<γ时,表示x 与y 存在一定的线性相关,||γ的数值越大,越接近于1,表示相关程度越高;反之,越接近于0,相关程度越低,通常判别标准是:3.0||<γ称为微弱相关,5.0||3.0<<γ称为低度相关,8.0||5.0<<γ称为显著相关,1||8.0<<γ称为高度相关;当0||=γ时,表示y 的变化与x 无关,即不相关;当0>γ时,表示x 与y 为线性正相关,当0<γ时,表示x 与y 为线性负相关。
皮尔逊积距相关系数计算的基本公式是: ∑∑∑∑∑∑∑---==])(][)([22222y y n x x n y x xy n y x xy σσσγ 斯皮尔曼等级相关系数和肯特尔等级相关系数是测量两个等级变量(定序测度)之间相关密切程度的常用指标。
电力负荷预测第七章 回归分析预测法

几个基本问题
1. 回归的含义 2. 相关关系的概念 3. 相关分析与回归分析的区别与联系 4. 相关分析与回归分析的作用 5. 回归分析模型的种类
1.回归的含义 回归——研究自变量与因变量之间关系形式的分析方法。
长期 预测
GDP
短期 预测
气象因素
自 变 量
电量需求
系统负荷
因 变 量
主要内容
1.模型描述 2.参数估计 3.相关系数 4.显著性检验 5.预测及预测区间的确定 6.算例
1.模型描述
因变量
自变量
y a bx
i
i
i
——一元线性回归模型
i 1, n
xi: 影响因素(可以控制或预先给定);
ε:各种随机因素对y的影响的总和,服从正态分布 ,即
ε~N(0, σ2);
( yi y)2
( yi y)2
[ (xi x)( yi y)]2 • (xi x)2
(xi x)2
( yi y)2
[ (xi x)( yi y)]2 (xi x)2 • ( yi y)2
(x x)(yˆ y)
R
i
i
(x x )2 ( y y)2 ——积差法计算公式
;
yi y
对1个观察值,离差为 ( yi y)2 记Lyy ( yi y)2为总离差
对n个观察值,离差为
Lyy
(y y)2 i
[( y i
yi
)
(
yi
y )]2
为0, 证明(略)
( y y )2 ( y y)2 2 ( y y )( y y)
i
i
i
i
i
i
数据建模—非线性回归

数据建模—非线性回归
什么是非线性回归
一般线性回归假设因变量与自变量呈线性关系,但现实中有很
多问题并非是线性相关的。
而非线性回归可以用来拟合非线性关系。
非线性模型示例
下面以一些示例来介绍非线性回归:
1. 多项式回归
多项式回归就是一种非线性回归,它将线性模型中的自变量的
各次幂作为回归系数,即将 $y=a_0+a_1x+a_2x^2+...+a_nx^n$ 作为
模型进行回归。
这种方法适用于自变量$x$与因变量$y$之间的关系
大致呈多项式分布。
2. 对数函数回归
对数函数回归是一类将对数函数作为函数形式的非线性回归方法,它们适用于特定类型的数据。
如指数增长、充分增长、衰减等类型的数据。
3. Sigmoid函数回归
Sigmoid函数(S型函数)经常用于二分类问题,由于其形状为S型,经过合适的处理可以用来拟合非线性关系。
Sigmoid函数的形式为: $y=\frac{1}{1+e^{-ax+b}}$
非线性回归方法
与线性回归不同,非线性模型中的回归系数无法直接求解,需要使用非线性优化算法对其进行拟合。
非线性优化算法有很多种,常见的有:梯度下降法、拟牛顿法、Levenberg-Marquardt算法等。
总结
非线性回归适用于许多实际问题,可以通过多项式回归、对数函数回归、Sigmoid函数回归等方法进行建模。
然后,我们可以使用非线性优化算法对模型进行优化拟合以得到最优参数。
《非线性回归》课件

灵活性高
非线性回归模型形式多样,可以根据 实际数据和问题选择合适的模型,能 够更好地适应数据变化。
解释性强
非线性回归模型可以提供直观和易于 理解的解释结果,有助于更好地理解 数据和现象。
预测准确
非线性回归模型在某些情况下可以提 供更准确的预测结果,尤其是在数据 存在非线性关系的情况下。
缺点
模型选择主观性
势。
政策制定依据
政府和决策者可以利用非线性回归模型来评估不同政策方案的影响,从而制定更符合实 际情况的政策。例如,通过分析税收政策和经济增长之间的关系,可以制定更合理的税
收政策。
生物学领域
生态学研究
在生态学研究中,非线性回归模型被广 泛应用于分析物种数量变化、种群动态 和生态系统稳定性等方面。通过建立非 线性回归模型,可以揭示生态系统中物 种之间的相互作用和环境因素对种群变 化的影响。
模型诊断与检验
诊断图
通过绘制诊断图,可以直观地观察模型是否满足回归分析的假设条件,如线性关系、误差同方差性等 。
显著性检验
通过显著性检验,如F检验、t检验等,可以检验模型中各个参数的显著性水平,从而判断模型是否具 有统计意义。
04
非线性回归在实践中的应用
经济学领域
描述经济现象
非线性回归模型可以用来描述和解释经济现象,例如消费行为、投资回报、经济增长等 。通过建立非线性回归模型,可以分析影响经济指标的各种因素,并预测未来的发展趋
VS
生物医学研究
在生物医学研究中,非线性回归模型被用 于分析药物疗效、疾病传播和生理过程等 方面。例如,通过分析药物浓度与治疗效 果之间的关系,可以制定更有效的治疗方 案。
医学领域
流行病学研究
在流行病学研究中,非线性回归模型被用于 分析疾病发病率和死亡率与各种因素之间的 关系。通过建立非线性回归模型,可以揭示 环境因素、生活方式和遗传因素对健康的影 响。
非线性回归分析

非线性回归分析随着数据科学和机器学习的发展,回归分析成为了数据分析领域中一种常用的统计分析方法。
线性回归和非线性回归是回归分析的两种主要方法,本文将重点探讨非线性回归分析的原理、应用以及实现方法。
一、非线性回归分析原理非线性回归是指因变量和自变量之间的关系不能用线性方程来描述的情况。
在非线性回归分析中,自变量可以是任意类型的变量,包括数值型变量和分类变量。
而因变量的关系通常通过非线性函数来建模,例如指数函数、对数函数、幂函数等。
非线性回归模型的一般形式如下:Y = f(X, β) + ε其中,Y表示因变量,X表示自变量,β表示回归系数,f表示非线性函数,ε表示误差。
二、非线性回归分析的应用非线性回归分析在实际应用中非常广泛,以下是几个常见的应用领域:1. 生物科学领域:非线性回归可用于研究生物学中的生长过程、药物剂量与效应之间的关系等。
2. 经济学领域:非线性回归可用于经济学中的生产函数、消费函数等的建模与分析。
3. 医学领域:非线性回归可用于医学中的病理学研究、药物研发等方面。
4. 金融领域:非线性回归可用于金融学中的股票价格预测、风险控制等问题。
三、非线性回归分析的实现方法非线性回归分析的实现通常涉及到模型选择、参数估计和模型诊断等步骤。
1. 模型选择:在进行非线性回归分析前,首先需选择适合的非线性模型来拟合数据。
可以根据领域知识或者采用试错法进行模型选择。
2. 参数估计:参数估计是非线性回归分析的核心步骤。
常用的参数估计方法有最小二乘法、最大似然估计法等。
3. 模型诊断:模型诊断主要用于评估拟合模型的质量。
通过分析残差、偏差、方差等指标来评估模型的拟合程度,进而判断模型是否适合。
四、总结非线性回归分析是一种常用的统计分析方法,可应用于各个领域的数据分析任务中。
通过选择适合的非线性模型,进行参数估计和模型诊断,可以有效地拟合和分析非线性关系。
在实际应用中,需要根据具体领域和问题的特点来选择合适的非线性回归方法,以提高分析结果的准确性和可解释性。
《非线性回归》课件
挑战与未来发展趋势
• 数据收集和质量 • 参数估计和模型拟合 • 算法选择和性能评估 总结当前非线性回归面临的挑战,并展望其未来发展的趋势和应用前景。
3
Dropout
解释dropout技术如何防止过拟合,并提升模型的泛化能力。
4
Early Stopping
介绍early stopping方法来优化非线性回归模型的训练过程。
实例分析:Pytho n 实现
通过Python编程语言示例,演示如何使用非线性回归模型来解决实际问题。
非线性回归的应用案例
指数回归
1 背景
探索指数回归模型在描述 增长趋势时的优势。
2 应用
介绍指数回归在经济、生 物、市场等领域的实际应 用案例。
3 模型拟合
讨论如何通过最小二乘法 获取指数回归模型的参数。
对数回归
数学基础
介绍对数函数和对数回归模型的 数学原理。
金Байду номын сангаас市场预测
探索对数回归在金融市场预测中 的应用案例。
生物医学领域
非线性回归
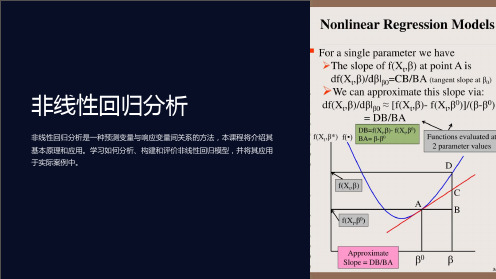
探索非线性回归的概念、应用场景和解决方案。比较线性回归与非线性回归 的区别,并介绍求解非线性回归模型的最小二乘法。
多项式回归
1
简介
利用多项式函数逼近非线性关系,探索多项式回归的应用和优缺点。
2
示例
通过案例研究,展示如何使用多项式回归模型来拟合实际数据。
3
拟合度
介绍如何选择合适的多项式阶数以获得最佳拟合度。
展示对数回归在生物医学领域中 用于研究和分析的实际应用。
非线性回归模型
• 由于逻辑表达式只能是1或0,于是 当X<=0时,结果为1*0+0*X+0*1=0 当X>0&X<1时,结果为0*0+1*X+0*1=X 当X>1时, 结果为0*0+0*X+1*1=1 • 字符串变量也可以用于逻辑表达式,如:
(city=‘New York’)*costliv+(city=Washington)*0.59*costliv
缺点:a.计算复杂;b.初始值不适当时,估计不准确.
采用SPSS进行曲线拟合
曲线直线化
Analyze Regression Curve Estimation … 可选Power 、Logarithmic、Exponential、 Quadratic、Cubic 等
非线性回归
Analyze Regression Nonlinear … 设置模型: Model Expression 参数赋初值:Parameters…
Parameter Estimates 95% Confidence Interval Lower Bound Upper Bound .088 .234 .075 .097
Parameter A B
Estimate .161 .086
Std. Error .035 .005
Correlations of Parameter Estimates A B A 1.000 -.990 B -.990 1.000
ANOVAa Source Reg ression Residual Uncorrected Total Corrected Total Sum of Squares 201.543 3.510 205.053 108.796 df 2 19 21 20 Mean Squares 100.771 .185
第七章回归模型--华东理工大学数学建模课件
确定自变量和因变量之间的数学关系式(称为实
数学建模
验公式或回归方程)。
(2)对回归方程中的参数进行估计和统计检
验,分析影响因素(自变量)与预测目标(因变
(
量)之间关系强弱和影响程度。
(3)利用回归方程,预测因变量的值,并分
析研究预测结果的误差范围和精度。
回归分析分为线性回归和非性回归。而线性回
归又可分为一元线性回归和多元线性回归。
数学建模
yi a bxi i (i 1, 2,L n )
E
(
i
)
0
co v( i , j ) 0 (i j; i, j 1, 2,L , n )
var(iLeabharlann )2 i(常
数
)
cov(
xi
,
i
)
0
i : N (0, i 2 )
2020/4/26
数学建模
y aˆ bˆx
2020/4/26
数学建模
▪ 称(2)为一元线性回归模型. ▪ “一元”是指只有一个自变量X,这个自变量X
是引起因变量Y变化的部分原因. ▪ “线性”它一方面指因变量Y与自变量X之间
为线性关系,即 y 2 y x b, x2 0
▪ 另一方面也指因变量Y与参数a,b之间为线性 关系,即
y1,2y0;yx,2y0 a a2 b b2
2020/4/26
“一元线性回归模型”及其参数估 计
数学建模
设x为自变量,y为因变量,y与x之间满足如下线性关
系:
yabx……………..(1)
其中 为随机变量E() 0 。
若
(x i,y i) ( i 1 ,2 ,L ,n )
第七章非参数回归模型与半参数回归模型
第七章 非参数回归模型与半参数回归模型第一节 非参数回归与权函数法一、非参数回归概念前面介绍的回归模型,无论是线性回归还是非线性回归,其回归函数形式都是已知的,只是其中参数待定,所以可称为参数回归。
参数回归的最大优点是回归结果可以外延,但其缺点也不可忽视,就是回归形式一旦固定,就比较呆板,往往拟合效果较差。
另一类回归,非参数回归,则与参数回归正好相反。
它的回归函数形式是不确定的,其结果外延困难,但拟合效果却比较好。
设Y 是一维观测随机向量,X 是m 维随机自变量。
在第四章我们曾引进过条件期望作回归函数,即称g (X ) = E (Y |X ) (7.1.1)为Y 对X 的回归函数。
我们证明了这样的回归函数可使误差平方和最小,即22)]([min )]|([X L Y E X Y E Y E L-=-(7.1.2)这里L 是关于X 的一切函数类。
当然,如果限定L 是线性函数类,那么g (X )就是线性回归函数了。
细心的读者会在这里立即提出一个问题。
既然对拟合函数类L (X )没有任何限制,那么可以使误差平方和等于0。
实际上,你只要作一条折线(曲面)通过所有观测点(Y i ,X i )就可以了是的,对拟合函数类不作任何限制是完全没有意义的。
正象世界上没有绝对的自由一样,我们实际上从来就没有说放弃对L(X)的一切限制。
在下面要研究的具体非参数回归方法,不管是核函数法,最近邻法,样条法,小波法,实际都有参数选择问题(比如窗宽选择,平滑参数选择)。
所以我们知道,参数回归与非参数回归的区分是相对的。
用一个多项式去拟合(Y i ,X i ),属于参数回归;用多个低次多项式去分段拟合(Y i ,X i ),叫样条回归,属于非参数回归。
二、权函数方法非参数回归的基本方法有核函数法,最近邻函数法,样条函数法,小波函数法。
这些方法尽管起源不一样,数学形式相距甚远,但都可以视为关于Y i 的线性组合的某种权函数。
也就是说,回归函数g (X )的估计g n (X )总可以表为下述形式:∑==ni i i n Y X W X g 1)()((7.1.3)其中{W i (X )}称为权函数。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
7.4非线性回归分析
7.4.1统计学上的定义及计算公式
定义:研究在非线性相关条件下,自变量对因变量的数量变化关系,称为非线性回归分析。
在实际问题中,变量之间的相关关系往往不是线性的,而是非线性的,因而不能用线性回归方程来描述它们之间的相关关系,而要采用适当的非线性回归分析。
非线性回归问题大多数可以化为线性回归问题来求解,也就是通过对非线性回归模型进行适当的变量变换,使其化为线性模型来求解。
一般步骤为:
1,根据经验或者绘制散点图,选择适当的非线性回归方程;
2,通过变量置换,把非线性回归方程化为线性回归;
3,用线性回归分析中采用的方法来确定各回归系数的值;
4,对各系数进行显著性检验。
计算公式如下:
在本届中介绍几种常见的非线性回归
1,双曲线模型
若因变量y随自变量x的增加(或减少),最初增加(或减少)很快,以后逐渐放慢并趋于稳定,则可以选用双曲线来拟合。
双曲线模型形式是:
线性化方法:令
则转化为线性回归方程:
2.幂函数模型
幂函数模型的一般形式
线性化方法:令
则转化为线性回归方程:
3.指数函数模型
指数函数用于描述几何级数递增或递减的现象。
一般的自然增长及大多数经济数列属于此类。
指数函数模型为
线性化方法:令
则转化为线性回归方程:
4.对数函数模型
对数函数是指数函数的反函数,其方程形式为
线性化方法:令
则转化为线性回归方程:
5.多项式模型
多项式模型在非线性回归分析中占有重要的地位。
因为根据级数展开的原理,任何曲线、曲面、超曲面的问题,在一定的范围内都能够用多项式任意逼近。
所以,当因变量与自变量之间的确定关系未知时,可以用适当幂次的多项式来近似反应。
当所涉及的自变量只有一个时,所采用的多项式方程称为一元多项式,其一般形式为
线性化方法:利用最小二乘法确定系数代入原方程即可。
说明:最后,并不是所有的非线性模型都可以通过变换得到与原方程完全等价的线性模型。
在遇到这种情况时,还需要利用其他一些方法如泰勒级数展开法等去进行估计。
7.4.2SPSS实现过程
研究问题
研究民用汽车总量与国内生产总值的关系。
数据如表7-3所示。
(资料来源:《中国统计年鉴2007》,中国统计出版社,2007年)
实现步骤
步骤1首先,绘制自变量x(国内生产总值)与因变量y(民用汽车总量)之间的散点图。
把表7-3中的数据一一输入SPSS数据编辑窗口,并存为“多元线性回归分析.sav”文件,研究国内生产总值对民用汽车总量的影响。
在“图形”菜单中“旧对话框”子菜单中选择“散点/点状”命令,弹出“散点/点状”对话框。
在“散点/点状”对话框中选择“简单分布”,单击“定义”按钮,弹出“简单分布图”对话框。
在“简单分布图”对话框中,把左侧的x,y这两个变量分别通过单击按钮使之添加到右侧的“X轴”和“Y轴”框中,表示散点图将分别把国内生产总值与民用汽车总量绘制在X轴和Y轴上。
其他选项不改变,以SPSS默认的为准,如图7-9所示。
步骤2 单击“”按钮,开始绘图。
绘图结果如图7-10所示。
从上面的散点图可以看出,民用汽车总量(y)随着国内生产总值(x)的提高而逐渐提高,而且当国内生产总值达到一定水平后,民用汽车总量的增幅更加明显。
因此,用线性回归模型表示民用汽车总量(y)与国内生产总值(x)的关系是不恰当的。
从上面散点图的形状特征,可以推断它与Cubic(三次函数)和Power(幂函数)两种曲线比较类似。
但究竟这两种曲线中哪一种与样本观察值的拟合优度更高,还需作进一步判断。
步骤3 为了进一步判断民用汽车总量与国内生产总值之间的关系,重新回到SPSS数据编辑窗口。
在“分析”菜单的“回归”子菜单中选择“曲线估计”命令,弹出“曲线估计”对话框
(一)。
图7-9“曲线估计”对话框
图表:
图7-10 散点图
在弹出的“曲线估计”对话框(一)中,从左侧的变量列表中选择y变量(民用汽车总
量),单击按钮使之添加到“因变量”框中,表示该变量是因变量。
选择x 变量(国内
生产总值),单击
按钮使之添加到“变量”框中,表示其为自变量,如图7-11所示。
“模型”框内列出了11种曲线模型。
图7-11 “”对话框(一)
“在等式中包含常量”框表示在输出结果中将列出常数项“b 0”。
“根据模型进行绘制”框表示将绘制观察值和预测值的对比图。
“显示ANOV A 表格”框表示作回归方程显著性检验,并输出相应的方差分析表。
这里选择“模型”框内的“Cubic ”(三次函数)和“Power ”(幂函数)这两种曲线模型进行非线性回归分析估计:同时选择“在等式中包含常量”项和“根据模型进行绘制”项。
步骤4 单击“确定”按钮,即可得到SPSS 回归分析结果。
7.4.3结果和讨论
SPSS 输出结果文件如下。
(1)第一部分输出相关统计量和参数的值,如下表所示。
从这部分结果可以看出,在所选的立方,幂这种曲线函数中,立方的拟合优度更高(其
模型摘要和参数估算
因变量: 民用汽车总值 方程式
模型摘要 参数估计值
R 平方
F df1
df2 显著性
常量 b1 b2 b3 立方(U)
.997 1290.705 3 13 .000 526.423
.002 1.107E-7
-2.426E-13
幂
.956
324.417
1
15
.000
.270
.762
自变量为 国内生产总值。
R2统计量的值为0.997),所以选择3次函数拟合国内生产总值和民用汽车总量之间的关系,下面还将进一步结合观察值和这两种函数模型预测值得对比图加以证实。
(2)第二部分输出的是观察值和立方,幂两种曲线预测值得对比图,如图7-12所示。
从对比图可以看出立方曲线的拟合优度的确比幂曲线的要高。
因此,决定在此研究问题中,选择三次函数立方来对观察值进行拟合。
其具体模型为
y=526.423+0.002x+1.107*10-7x2-2.426*10-13x3
其中y代表民用汽车总值,x代表国内生产总值。
图7-12 观察值与Cubic和Power两种曲线预测值的对比。