web文本挖掘
Web信息挖掘现状及应用前景

[ ] 姜瑞其 . 3 国外 机构库发展 概况 [] 图书情报工 作 ,0 5 1 )1 2 J. 20 ( 1 :4 —
1 5; 49 4 1 .
( 责任编辑 : 刘翠玲 ) 第一作者简介 : 春燕 , ,9 9 5 李 女 17 年 月生 ,0 2 2 0 年毕业于武汉大学 图书馆 学系,助理馆员 ,中山大学图书馆 , 广东 省广州市新港西路 15 3
之 为半结 构化数据 。半结构化是 We 上数据 的最大特点 。 b 23 解 决半结构化的数据源 问题 .
1 We 信 息挖 掘概 述 b
We b挖掘( bMiig是数据挖掘在 We We nn ) b上的应用 , 是一项 综合 技
术, 涉及 W b 数据挖掘 、 机语言学 、 e、 计算 信息学等多个领域 , 同研究 者 不 从 自身的领域 出发 ,对网络挖掘的含义有着不 同的理解 。但 总体 而言 ,
从数据库研究的角度出发 , b网站上 的信息也可以看作是一个数 We
据库 , 一个更大 、 复杂的数据库 。We 更 b上 的每一 个站点就是一 个数据
源, 每个数据源都是异构 的, 因而每一站点 之间的信 息和组织都不一样 , 这就构成 了一个巨大的异 构数据库环境 。 如果想要利用这些数据进行数 据挖 掘 , 首先必须要研究站 点之间异构数 据的集成 问题 , 只有将 这些站 点的数据都集成起来 , 提供 给用户一个统 一的视图 , 才有 可能从 巨大的 数据资源 中获取所需 的东西 。其 次 , 还要解决 We b上的数据查询 问题 , 因为如果所需的数 据不能很有效地得到 , 对这些数据进行 分析、 集成 、 处
理就无从谈起 。 22 半结构化的数据结构 .
【国家自然科学基金】_web内容挖掘_基金支持热词逐年推荐_【万方软件创新助手】_20140802

推荐指数 2 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
2011年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30
2008年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38
科研热词 页面聚类 自适应站点 web使用挖掘 频繁访问页组 领域本体 阈值 遗传算法 通信 语义网地图 语义web服务 语义 自适应网站 网页相关性 网页信息 网络信息挖掘 统计学习 统计关系学习 知识元挖掘 用户兴趣变化 消息 本体 日志挖掘 搜索引擎 推荐系统 多关系数据挖掘 反馈式搜索引擎 军事情报 兴趣度 关系学习 信息检索 信息抽取 似然逻辑学习 会话切分 web挖掘 web信息检索 p2p jxta clickthrough数据
2010年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43
科研热词 文本挖掘 数据挖掘 香山科学会议 集成算法 遗传算法 论坛 计算机应用 褒贬分类 网页泛化 网页去噪 网络论坛 网络社区 网络挖掘 综合集成研讨厅 结构化数据 突发话题 知识发现 用户意图 潜在语义 时间序列 数据预处理 数据清洗 数字图书馆 搜索导航 情感分析 信息检索 信息抽取 会话识别 主观性识别 中文信息处理 个性化推荐 万维网 web日志挖掘 web文本挖掘 web文本分类 web挖掘 vsm ais
数据挖掘的方法有哪些

数据挖掘的方法有哪些
数据挖掘的方法主要包括以下几种:
1.分类:用于将数据分为不同的类别或标签,包括决策树、逻辑回归、支持向量机等。
2.聚类:将数据分为不同的组或簇,根据数据的相似性进行分组,包括k均值聚类、层次聚类等。
3.关联规则:寻找数据中的相关联关系,包括频繁模式挖掘、关联规则挖掘等。
4.异常检测:寻找数据中与正常模式不符的异常值,包括离群点检测、异常检测等。
5.预测建模:利用历史数据进行模型建立,用于预测未来事件的可能性,包括回归模型、时间序列分析等。
6.文本挖掘:从非结构化文本数据中提取有用信息,如情感分析、主题建模等。
7.图像和视觉数据挖掘:从图像和视频数据中提取特征和模式,用于图像处理、目标识别等。
8.Web挖掘:从互联网上的大量数据中发现有价值的信息,包括网页内容挖掘、链接分析等。
9.时间序列分析:研究时间维度上数据的相关性和趋势,包括ARIMA模型、周期性分析等。
10.集成学习:通过结合多个单一模型获得更好的预测性能,如随机森林、Adaboost等。
这些方法常常结合使用,根据具体问题和数据来选择合适的方法。
北大考研-计算机科学技术研究所研究生导师简介-杨建武_ 副研究员

爱考机构-北大考研-计算机科学技术研究所研究生导师简介-杨建武_副研究员杨建武副研究员杨建武,男,1973年7月出生,博士,副研究员。
2002年7月毕业于北京大学计算机研究所,获博士学位。
主讲课程:·课程名称:文本挖掘技术·教学对象:北京大学信息科学技术学院研究生研究方向·信息检索、文本挖掘、SGML/XML主要研究工作面向互联网内容安全的Web挖掘技术研究。
获得信息产业部电子信息产业发展基金(“以智能信息分析处理为核心的数据挖掘软件平台”)、国家自然科学基金(“基于核矩阵学习的半结构化文本挖掘研究”)以及方正集团的课题资助。
主持研发的“方正智思”信息检索与智能分析产品已被广泛应用于国务院新闻办、中宣部等国家重要部门的互联网舆情分析预警系统等大型项目之中。
主要科研成果、专利、奖励:·《ASemi-StructuredDocumentModelForTextMining》计算机科学技术学报(JCST英文刊)2002.9·《半结构化数据相似搜索的索引技术研究》计算机学报2002.11·《基于规范划分集的并行循环计算划分》软件学报2003.3·《基于核矩阵学习的XML文档相似度量方法》软件学报2006.5·IntegratingElementKernelandTermSemanticsforSimilarity-BasedXMLDocumentClusteringWI'05·UsingProportionalTransportationSimilaritywithlearnedelementsemanticsforXMLdocumentclusteri ng.WWW2006·Manifold-rankingbasedtopic-focusedmulti-documentsummarization.IJCAI’07·SingleDocumentSummarizationwithDocumentExpansion.AAAI2007·Towardsaniterativereinforcementapproachforsimultaneousdocumentsummarizationandkeywordext raction.ACL2007·CollabSum:ExploitingMultipleDocumentClusteringforCollaborativeSingleDocumentSummarizati ons.SIGIR2007·LearninginformationdiffusionprocessontheWeb.WWW’07申请专利10多项,其中2项已获授权:·一种对半结构化文档集进行文本挖掘的方法专利,2004.8·一种基于快速排序算法的快速分页排序方法专利,2006.10奖励:·2004年度北京大学优秀博士论文。
数据挖掘考试题库

1 数据清洗:包括填充空缺值,识别孤立点,去掉噪声和无关数 据。
13. 预测型知识:是根据时间序列型数据,由历史的和当前的数据 去推测未来的数据,也可以认为是以时间为关键属性的关联知 识。
14. 偏差型知识:是对差异和极端特例的描述,用于揭示事物偏离 常规的异常现象,如标准类外的特例,数据聚类外的离群值 等。
15. 遗传算法:是一种优化搜索算法,它首先产生一个初始可行解 群体,然后对这个群体通过模拟生物进化的选择、交叉、变异 等遗传操作遗传到下一代群体,并最终达到全局最优。
融合、决策支持等。 数据挖掘的功能包括:概念描述、关联分析、分类与预测、聚
类分析、趋势分析、孤立点分析以及偏差分析等。 2. 何谓数据仓库?为什么要建立数据仓库?
数据仓库是一种新的数据处理体系结构,是面向主题的、集成 的、不可更新的(稳定性)、随时间不断变化(不同时间)的数据集 合,为企业决策支持系统提供所需的集成信息。
当前数据
历史数据
经常更新
不更新,但周期性刷新
一次性处理的数据量小 一次处理的数据量大
对响应时间要求高
响应时间合理
用户数量大
用户数据相对较少
面向操作人员,支持日 面向决策人员,支持管
常操作
理需要
面向应用,事务驱动 面向分析,分析驱动
5. 何谓粒度?它对数据仓库有什么影响?按粒度组织数据的方式 有哪些? 粒度是指数据仓库的数据单位中保存数据细化或综合程度的级
2、 判断题 ( )1. ( )2. ( )3. ( )4. ( )5. ( )6. ( )7. ( )8. ( )9. (
【国家自然科学基金】_web结构挖掘_基金支持热词逐年推荐_【万方软件创新助手】_20140801
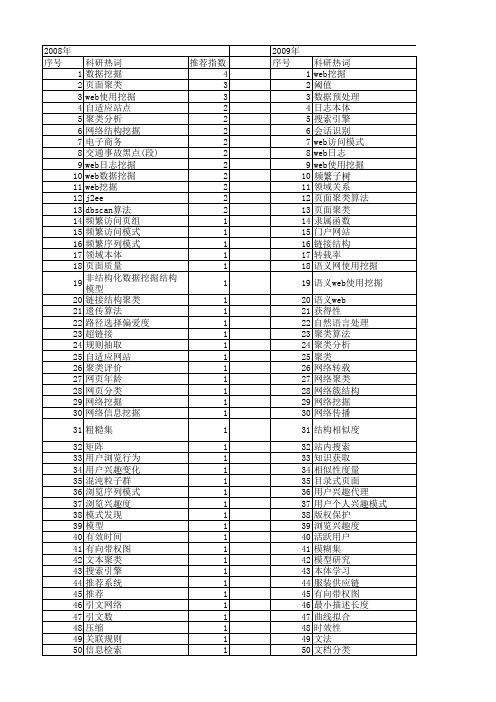
数据抽取 归纳逻辑编程 异构系统 并行爬虫 巴克斯范式 层次链接分析 层次关联规则 实证分析 复杂网络 增量更新策略 动态数据挖掘 分装器 分布式搜索引擎 内容相似度 内容式页面 关联规则 信息检索 信息抽取 余弦向量法 会话 互联网 事件进展图 事件时间线分析 xml检索结果 web结构挖掘 web服务 web数据抽取 web数据抓取 sspisia rails框架 pagerank odbweb算法 mvc模式 k-means算法 frame页面 frame 页面 dbscan算法 a数据挖掘 web日志挖掘 集成算法 逻辑域核 逻辑域 论坛 自适应网站 聚类 网络社区 结构挖掘 结构化数据 精简网站 电力营销 潜在语义 混合推理 模式发现 日志本体 文本挖掘 数据预处理 数据清洗 数据仓库 拓扑结构 技术发展趋势 归纳逻辑编程 导入路径 实时测速 地标系数 可视化 双视图 动态地图 农业决策支持系统 公共决策 信息抽取 信息 会话识别 主色调 web站点核心逻辑结构 web日记 web-gis web services page rank j2ee hits gtpfwld dl-safe规则
2008年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52
53 54 55 56 57
web结构挖掘 web日志 web文本挖掘 pagerank算法 pagerank
1 1 1 1 1
53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90
基于文本挖掘的分类与聚类技术
基于文本挖掘的分类与聚类技术
夏咏梅
【期刊名称】《情报探索》
【年(卷),期】2005(000)003
【摘要】从基于文本挖掘理论和实践两方面,探讨了文本的分类与聚类的理论、技术及两者之间的区别,讨论了聚类与分类技术在文本挖掘过程中的重要作用,通过所列举的自动分类与聚类的应用实例,能给读者的实际工作以一定的借鉴.
【总页数】3页(P65-67)
【作者】夏咏梅
【作者单位】南京大学信息管理系,江苏,210098
【正文语种】中文
【中图分类】G2
【相关文献】
1.基于层次聚类算法的WEB文本挖掘技术研究 [J], 吕岚
2.基于文本挖掘的计算机漏洞自动分类技术研究 [J], 邢翀
3.基于层次聚类算法的WEB文本挖掘技术探索 [J], 吕岚
4.基于自然语言处理技术的电力文本挖掘与分类 [J], 魏焱;杜斌;邓旭阳;何杰
5.基于文本挖掘的计算机漏洞自动分类技术分析 [J], 乔毅弘
因版权原因,仅展示原文概要,查看原文内容请购买。
数据挖掘简介
生物信息或基因数据挖掘
生物信息或基因数据挖掘则完全属于另外一个领域,在商业上很 难讲有多大的价值,但对于人类却受益非浅。例如,基因的组合 千变万化,得某种病的人的基因和正常人的基因到底差别多大?能 否找出其中不同的地方,进而对其不同之处加以改变,使之成为 正常基因?这都需要数据挖掘技术的支持。
海量数据搜索,对巨大量数据的快速访问;
数ining)就是从大量的,不完全的,有噪声的,模糊的, 随机的实际应用数据中,提取隐含在其中的,人们事先不知道的,但又是 潜在有用的信息和知识的过程。
与数据挖掘相近的同义词有数据融合,数据分析和决策支持等。
寸和创建时间等; 人工实现则极为费时、费力; 自动实现则往往结果不理想。
基于内容的检索系统 支持基于图像内容的检索,例如颜色、质地、形状、对象及小波
变换
数据挖掘与其它学科的关系
数据挖掘与传统数据分析的区别
数据挖掘的数据源与以前相比有显著的改变; 数据是海量的; 数据有噪声; 数据可能是非结构化的;
传统的数据分析方法基于假设驱动的:一般都是先给出一个假设然 后通过数据验证
数据挖掘在一定意义上是基于发现驱动的:模式都是通过大量的搜 索工作从数据中自动提取出来。即数据挖掘是要发现那些不能靠 直觉发现的信息或知识,甚至是违背直觉的信息或知识,挖掘出 的信息越是出乎意料,就可能越有价值。
此外,大部分模式是用数学手段描述的表达式,很难被人理解, 还需要将其解释成可理解的方式以呈现给用户。
未来应用领域
网站的数据挖掘(Web site data mining) 生物信息或基因的数据挖掘 文本挖掘(Textual mining) 多媒体挖掘
从大量数据中提取知识的过程
从大量数据中提取知识的过程
从大量数据中提取知识的过程通常称为数据挖掘。
数据挖掘是一个计算机科学术语,读音shùjùwājué,意思一般是指从大量
的数据中通过算法搜索隐藏于其中信息的过程。
数据挖掘通常与计算机科学有关,并通过统计、在线分析处理、情报检索、机器学习、专家系统(依靠过去的经验法则)和模式识别等诸多方法来实现上述目标。
数据挖掘分为有指导的数据挖掘和无指导的数据挖掘。
有指导的数据挖掘是利用可用的数据建立一个模型,这个模型是对一个特定属性的描述。
无指导的数据挖掘是在所有的属性中寻找某种关系。
具体而言,分类、估值和预测属于有指导的数据挖掘;关联规则和聚类属于无指导的数据挖掘。
数据挖掘简要分为:频繁模式挖掘(Frequent Pattern Mining)、序列挖掘(Sequence Mining)、数据流挖掘(Data Stream Mining)、文本挖掘(Text Mining)、Web挖掘(Web Minging)、图挖掘(Graph Mining)和时空数据挖掘(Temporal-spatial Mining)等,具体地:
数据流挖掘是针对数据流的数据挖掘,数据特点是数据随时间变化快且数据量大。
数据挖掘概述
数据挖掘是20世纪90年代中期兴起的决策支持新技术,是基于大规模数据库的决策支持系统的核心,它是从数据库中发现知识的核心技术。
数据挖掘能够对数据库中的数据进行分析,以获得对数据更加深入的了解。
数据挖掘技术经历了三个演变时期。
第一时期称为机器学习时期,在这时期人们将已知的并且已经成功解决的事例输入计算机,由计算机对输入的事例进行总结产生相应的规则,在把总结出来的这些规则应用于实践;第二时期称为神经网络技术时期,这一时期人们关注的重点主要是在知识工程领域,向计算机输入代码是知识工程的重要特征,然而,专家们在这方面取得的成果并不理想,因为它投资大、效果差。
第三时期称为KDD时期,即数据挖掘现阶段所处的时期。
它是在20世纪80年代神经网络理论和机器学习理论指导下进一步发展的成果。
当时的KDD全称为数据库知识发现。
它一般是指从样本数据中寻找有用信息或联系的全部方法,如今人们已经接受这个名称,并用KDD这个词来代替数据挖掘的全部过程。
这里我们需要指出的是数据挖掘只是整个KDD过程中的一个重要过程。
数据仓库技术的发展促进了数据挖掘的发展,因为数据仓库技术为数据挖掘提供了原动力。
但是,数据仓库并不是数据挖掘的唯一源泉,数据挖掘不但可以从数据库中提取有用的信息,而且还可以从其它许多源数据中挖掘有价值的信息。
数据挖掘(Data Mining,DM),也称数据库中知识发现(knowlegde discovery in database,KDD),就是从大量的、不完全的、有噪声的、模糊的及随机的实际数据中提取隐含在其中的、未知的、但又是潜在有用的信息和知识的过程。
现在与之相应的有很多术语,如数据分析、模式分析、数据考古等。
我们从数据挖掘的定义中可以看出它包含了有几层意义:所使用的样本数据一般要求是有代表性的、典型的、可靠的;在样本数据中发现的规律是我们需要的;在样本数据中发现的规律能够被我们理解、接受、运用。
数据挖掘过程从数据库中发现知识,简称KDD,是20世纪80年代末开始的,现在人们把KDD 过程可定义为从数据集中识别出有效的、新颖的、潜在有用的,以及最终可以理解的模式的高级处理过程[14]。