stata基本操作
Stata入门手册 STATA操作方法概述

统计分析与计量分析的结合
单元统计:描述统计、假设检验(参数、非参数)、ANOVA、质量控制、统计 作图
多元统计:MANOVA、主成分、因子分析、典型相关、聚类、判别分析、对应 分析、多维标度 线性回归、非线性回归、工具变量回归、广义线性回归、分位数回归(稳健回 归)、系统方程模型(SUR、联立方程)、离散选择模型(二项选择、排序选择、 多项选择、条件Logit、嵌套Logit模型、二元选择模型等)、计数模型(泊松回归、 负二项回归)、截断与归并模型、海克曼选择模型、逐步回归(stepwise)等。 时间序列分析:时间序列的平滑、相关图、ARIMAX、GARCH、单位根检验、 Johansen协整检验、 VAR、VEC、滚动回归等。 面板数据(线性模型、工具变量回归、动态面板、分层混合效应、广义估计方 程(GEE)、随机边界模型等)。
语法结构(varlist)
已存在的变量
varlist表示若干变量。对于数据中存在的变量,允许的表达形式包括 *、?和。其中,*表示任意字符,?表示一个字符,表示两个变量 之间的所有变量(根据数据中变量的存放位置)。 比如,数据文件中共有20个变量,依次为var1、var2、… 、 var20,则var* 表示所有变量var1-var20,var?表示变量var1、 var2、… 、var9,var1-var6表示变量var1、var2、… 、var6。 新变量
生成新变量时,变量名称不能简化。如果变量具有相同的前缀并且 都以数字结尾,可以用-表示。比如,生成新变量V1、V2、V3、V4 input v1 v2 v3 v4 或者 . input v1-v4。
16
《STATA应用高级培训教程》 南开大学数量经济研究所 王群勇
语法结构(varlist)
Stata软件基本操作:统计描述入门

Stata软件基本操作和数据分析入门第二讲统计描述入门赵耐青一调查某市1998年110名19岁男性青年的身高(cm)资料如下,计算均数、标准差、中位数、百分位数和频数表。
Stata数据结构(读者可以把数据直接粘贴到Stata的Edit窗口)在介绍统计分析命令之前,先介绍打开一个保存统计分析结果的文件操作:计算样本的均数、标准差、最大值和最小值命令1:su 变量名 (可以多个变量:即:su 变量名1 变量名2 …变量名m)命令2:su 变量名,d (可以多个变量:即:su 变量名1 变量名2 …变量名m,d) 本例命令su x本例命令. su x,d计算百分位数还可以用专用命令centile。
centile 变量名(可以多个变量),centile(要计算的百分位数) 例如计算P2.5,P97.5等centile 变量名,centile(2.5 97.5)本例计算P2.5,P97.5,P50,P25,P75。
本例命令. centile x,centile(2.5 25 50 75 97.5)制作频数表,组距为2,从164开始,gen f=int((x-164)/2)*2+164 其中int( )表示取整数tab f 频数汇总和频率计算作频数图命令 graph 变量,bin(#) norm其中#表示频数图的组数;norm表示画一条相应的正态曲线(可以不要) 本例命令为graph x,bin(8) norm为了使坐标更清楚地在图上显示,可以输入下列命令graph x,bin(8) xlabel norm ylabel图形可以从Stata中复制到word中来,操作如下:计算几何均数可以用means 变量名(可以多个变量:即:means 变量1 …变量m) means x作Pie图描述构成比:每一类的频数用一个变量表示,命令:graph 各类频数变量名,pie第1地区血型构成比的Pie图的命令和图graph a b o ab if area==1,pie注意逻辑表达式中if area==1是两个等号。
STATA实用教程

STATA实用教程STATA是一种统计分析软件,广泛应用于数据分析、统计建模、数据可视化等领域。
它具有强大的数据处理能力和丰富的统计功能,能够快速、准确地处理大规模的数据集。
下面是一些STATA实用教程,帮助初学者快速上手该软件。
1.STATA基本操作STATA的基本操作包括数据导入和导出、数据集处理、变量管理等。
首先要学会使用STATA命令行界面和菜单栏来进行操作,了解STATA常用的命令和语法,掌握STATA常用的数据结构,如数据集、变量类型等。
同时,还需要学会使用STATA的帮助文档和网络资源,解决自己在使用过程中遇到的问题。
2.数据的描述性统计STATA可以进行各种描述性统计,例如计算均值、中位数、标准差、四分位数等,了解数据的分布情况。
可以利用summarize、describe等命令来进行描述性统计,还可以使用tabulate、histogram等命令进行变量的频数统计和画出直方图。
3.数据清洗和转换在实际应用中,数据往往需要进行清洗和转换。
STATA提供了一系列的命令,用于数据的清洗和转换。
比如,drop、keep命令可以删除不需要的变量或观察值;rename、recode命令可以对变量进行重命名和重新编码;reshape、merge命令可以进行数据重塑和合并等操作。
4.统计分析STATA提供了许多常用的统计方法和模型,可以进行统计分析。
例如,t检验、方差分析、线性回归、Logistic回归、生存分析、聚类分析等。
用户可以使用STATA内置的命令来进行统计分析,也可以使用STATA扩展包来进行更加复杂的分析。
5.高级数据处理STATA还提供了一些高级数据处理方法,如面板数据分析、时间序列分析、密度估计、非参数统计等。
这些方法对于处理复杂的数据结构和模型非常有用。
通过学习STATA的面板数据命令如xtreg、xtsum等,可以进行面板数据分析;通过学习STATA的时间序列命令如arima、xtdes等,可以进行时间序列分析。
Stata软件操作教程 (10)

下面,让我们通过例子来加深对命令的理解。 拟合前面的约束回归: cnsreg mpg price weight displ gear_ratio foreign length, c(1-5) 命令中,cnreg代表进行约束回归,mpg是被解释变量的名称,
price weight displ gear_ratio foreign length为各个解释变量的 名称,选项c(1-5)表示在1到5个约束之下进行回归。
利用nerlove的数据,我们分别用大样本理论和小样本
理论进行回归分析,以比较二者的不同,从而使用户 更加深刻地理解这两个理论。
三、实验操作指导 1 模型的建立
2 使用小样本理论进行回归 首先,我们假设数据符合小样本理论严格的假设,所
以可以直接运用小样本理论进行回归。使用use命令打 开数据后,在命令窗口中输入回归命令如下: regress lntc lnq lnpl lnpk lnpf 这个命令的含义就是以lntc作为因变量,以lnq、lnpl、 lnpk、lnpf作为自变量建立线性回归模型。之后,我 们就可以得到如图6.7所示的小样本理论下的回归结果 了。
实验6-3:约束回归
一、实验基本原理
二、实验内容和实验数据
本实验中,我们将利用与实验6-1相同的数据,即本书
附带光盘data文件夹下的“usaauto.dta”文件中的数 据,来研究回归系数存在约束的情况下,价格、汽车 重量等因素对每加仑汽油所行驶的路程的影响。我们 将介绍如何定义约束、列出已定义的约束、取消已定 义的约束、以及在定义好约束后如何进行约束回归。
2 利用最小二乘法进行模型的估计 对模型进行回归的仍然是采用命令方式进行操作,命
令的基本格式如下: regress depvar [indepvar] [if] [in] [weight] [,options] 其中regress代表“回归”的基本命令语句,depvar代 表被解释变量(或称因变量)的名称,indepvar代表 解释变量(或称自变量)的名称,if代表条件语句,in 代表范围语句,weight代表权重语句,options代表其 他选项。
Stata面板回归操作过程、基本指令及概要
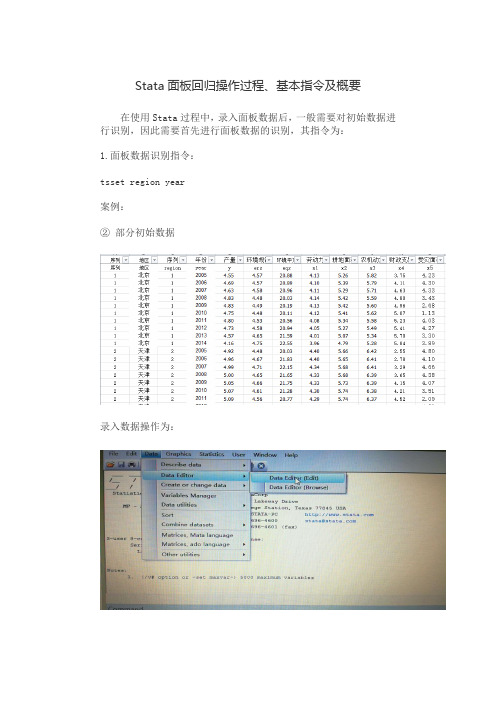
Stata面板回归操作过程、基本指令及概要在使用Stata过程中,录入面板数据后,一般需要对初始数据进行识别,因此需要首先进行面板数据的识别,其指令为:1.面板数据识别指令:tsset region year案例:②部分初始数据录入数据操作为:②将上述初始数据录入stata后(注意:录入数据及首行只能是英文字母或者数字,不能有汉字),显示如下:③输入指令tsset region year,显示如下结果. tsset region yearpanel variable: region (strongly balanced)time variable: year, 2005 to 2014delta: 1 unit2.面板数据固定效应回归指令:xtreg y ers eqs x1 x2 x3 x4 x5,fe案例:录入数据,并进行面板数据识别之后,输入以上指令:xtreg y ers eqs x1 x2 x3 x4 x5,fe其中,xtreg为面板回归指令,y为选取的因变量,ers、eqs、x1、x2、x3、x4、x5为自变量,末尾加fe表示为固定效应,如果末尾加re则是随机效应。
上述回归结果显示如下:3.面板数据随机效应回归指令:xtreg y ers eqs x1 x2 x3 x4 x5,re4.hausman 检验指令:Hausman检验是固定效应或者随机效应回归之后,需要加入的一个检验,具体指令如下:qui xtreg y ers eqs x1 x2 x3 x4 x5,feest store fequi xtreg y ers eqs x1 x2 x3 x4 x5,feest store rehausman fe re5.门限回归指令使用门限(或者门槛)回归模型的,只需要在录入数据后,使用以下指令进行回归即可,xthreg为门限回归指令,y eqs x1 x2 x3 x4 x5分别为自变量和因变量,rx和qx括号中的分别为核心解释变量与门限变量,可以一致也可以不一致。
STATA统计分析软件使用教程

STATA统计分析软件使用教程引言STATA统计分析软件是一款功能强大、使用广泛的统计分析软件,广泛应用于经济学、社会学、医学和其他社会科学领域的研究中。
本教程将介绍STATA的基本操作和常用功能,并提供实例演示,帮助读者快速上手使用。
第一章:STATA入门1.1 安装与启动首先,下载并安装STATA软件。
完成安装后,点击软件图标启动STATA。
1.2 界面介绍STATA的界面分为主窗口、命令窗口和结果窗口。
主窗口用于数据显示,命令窗口用于输入分析命令,结果窗口用于显示分析结果。
1.3 数据导入与保存使用命令`use filename`导入数据,使用命令`save filename`保存当前数据。
1.4 基本命令介绍常用的基本命令,如`describe`用于显示数据的基本信息、`summarize`用于计算变量的统计描述等。
第二章:数据处理与变量管理2.1 数据选择与筛选通过命令`keep`和`drop`选择和删除数据的特定变量和观察值。
2.2 数据排序与重编码使用命令`sort`对数据进行排序,使用命令`recode`对变量进行重编码。
2.3 缺失值处理介绍如何检测和处理数据中的缺失值,包括使用命令`missing`和`recode`等。
第三章:数据分析3.1 描述性统计介绍如何使用STATA计算和展示数据的描述性统计量,如均值、标准差、最大值等。
3.2 统计检验介绍如何进行常见的统计检验,如t检验、方差分析、卡方检验等。
3.3 回归分析介绍如何进行回归分析,包括一元线性回归、多元线性回归和逻辑回归等。
3.4 生存分析介绍如何进行生存分析,包括Kaplan-Meier生存曲线和Cox比例风险模型等。
第四章:图形绘制与结果解释4.1 图形绘制基础介绍如何使用STATA进行常见的数据可视化,如散点图、柱状图、折线图等。
4.2 图形选项与高级绘图介绍如何通过调整图形选项和使用高级绘图命令,进一步美化和定制图形。
stata17 中文操作手册
文章标题:深度探究stata17 中文操作手册1. 概述在今天这个信息爆炸的时代,数据分析软件的需求越来越大。
stata17 作为一款专业的数据分析软件,其中文操作手册更是对中文用户友好。
本文将从深度和广度两个方面探讨stata17 中文操作手册,旨在帮助读者更全面、深入地了解该软件。
2. 简介让我们来简要介绍一下stata17 中文操作手册。
stata17 是一款专业的统计学软件,其中文操作手册为中文用户提供了方便快捷的使用帮助。
无论是初学者还是专业用户,都可以通过阅读中文操作手册,快速掌握stata17 的使用方法和技巧。
3. 深度探讨3.1 逐步介绍stata17 的基本操作步骤,如数据导入、数据整理、数据分析等。
在stata17 中文操作手册中,不仅提供了stata17 的基本操作步骤,还对每个步骤进行了详细的解释和示例。
这有助于用户从简单的数据导入开始,逐步掌握stata17 的各种高级功能。
3.2 深入分析stata17 的高级功能,如面板数据分析、生存分析、结构方程模型等。
stata17 中文操作手册还介绍了stata17 的高级功能,如面板数据分析、生存分析、结构方程模型等。
这些高级功能的详细介绍和示例,为用户提供了丰富的学习资源,帮助他们更深入地了解stata17 的强大功能。
4. 广度覆盖4.1 涵盖的领域广泛,包括经济学、社会学、医学等各个领域。
除了深入介绍stata17 的操作方法和高级功能外,stata17 中文操作手册还涵盖了各个领域对数据分析的需求。
无论是经济学、社会学还是医学等领域的数据分析方法,都可以在stata17 中文操作手册中找到相关内容。
4.2 提供丰富的实例和案例,帮助用户更好地理解和运用stata17。
stata17 中文操作手册提供了丰富的实例和案例,这些实例和案例不仅有助于用户更好地理解stata17 的操作方法,还可以帮助他们将stata17 应用到实际的数据分析中去。
《STATA简易操作》课件
使用Stata进行生存分析,包括数据导 入、选择合适的生存分析模型、参数 估计和结果解释。
分析生存曲线和风险函数,探究影响 因素对生存时间的影响。
进行模型假设检验和模型比较。
案例三:面板数据分析
总结词:利用面板数据分析方
法,探究个体、时间和其他变
量的交互作用。
01
详细描述
绘制折线图
折线图用于展示随时间变化的数据 趋势。
VS
在Stata中,可以通过输入“line yvar xvar”命令来绘制折线图。其中 yvar代表要展示的数据变量,xvar代 表时间变量。还可以通过添加选项来 修改线条样式、标记等。
05
Stata实战案例
案例一:线性回归分析
总结词:通过线性回归分析,探究自变量与因 变量之间的关系。
01
确定研究问题,选择合适的自变量和因变 量。
03
02
详细描述
04
使用Stata进行线性回归分析,包括数据 导入、模型设定、参数估计和结果解释。
分析模型的拟合优度,如判定系数、调整 判定系数等。
05
06
检验模型的假设条件,如线性关系、误差 项独立同分布等。
案例二:生存分析
总结词:利用生存分析方法,研究生 存时间与影响因素之间的关系。 详细描述
多元回归
探讨多个自变量对因变量的影响,以 及交互项和平方项的设定。
面板数据分析
面板数据介绍
阐述面板数据的概念、特点及其在经济学中 的应用。
固定效应与随机效应模型
比较两种模型的适用场景和结果解释。
面板数据的单位根与协整检验
介绍用于检验数据稳定性和长期关系的检验 方法。
Stata软件基本操作和数据分析入门
1|
25
101.52 1.900982 9.504911 97.59657 105.4434
---------+--------------------------------------------------------------------
combined |
50
95.3 1.577456 11.1543 92.12998 98.47002
Group | Obs
Mean Std. Err. Std. Dev. [95% Conf. Interval]
---------+--------------------------------------------------------------------
0|
25
89.08 1.822928 9.11464 85.31766 92.84234
Group | Obs
Mean Std. Err. Std. Dev. [95% Conf. Interval]
---------+--------------------------------------------------------------------
0|
25
89.08 1.822928 9.11464 85.31766 92.84234
9 13.0 13.8
10 12.3 12.0
问:治疗前后的血红蛋白的平均水平有没有改变
这是一个典型的前后配对设计的研究(但不提倡,因为对结果的解
释可能会有问题)
操作如下:
Stata 数据输入结构
X1 11.3
15 15 13.5 12.8 10 11 12 13 12.3
Stata软件应用1---【Stata软件基本操作】
二、Stata常用基本操作
方式 2:直接将结果存入Word或Excel等文本编辑软件 中,即在Stata结果窗口中选择上述计算结果→ 鼠标右 键→Copy Table →打开Excel窗口粘帖,结果按表格方式 呈现。 计算相关系数(基本命令:corr) 键入 corr rjgdp rjcap 回车→显示两个变量的相关系数 矩阵 →依据前述两种方式保存运行结果; 进行简单回归分析(基本命令:reg) 键入 reg rjgdp rjcap 回车(第一个变量rjgdp为被解释变 量,第二个变量rjcap为解释变量) →显示回归结果→依 据前述两种方式保存运行结果;
二、Stata常用基本操作 Stata数据管理 在对数据进行分析时,经常会遇到这些事情:合并两个文 件;删除某个变量;重新生成一个新变量;计算某个变量的 函数值等。这些事情的处理就是数据管理。这里介绍一些常 用的数据管理命令,其他的可参考Stata帮助文件或User’s Guide。常用的数据管理命令包括以下几类:
二、Stata 常用基本操作
启动 Stata
下载Stata10压缩包,解压后,在Stata10文件夹中,找 到wsestata图标,鼠标双击它即会出现Stata的界面。今 后大部分工作都将在这个界面上完成。
Stata 窗口简介
Stata窗口主要由以下几部分构成: 1、Command(命令,右下部分)窗口:用于向Stata键入 需要执行的命令,回车后即开始执行,相应的结果则会 在结果窗口中显示出来。 2、Stata results(结果,右上部分)窗口:显示运行结 果、所执行的命令以及出错信息等。窗口中会使用不同 的颜色区分不同的文本,如白色表示命令,红色表示错 误信息。
2、数据文件的合并