抽样调查-分层抽样实验报告

实验报告
实验思考题:
1、某调查员欲从某大学所有学生中抽样调查学生平均生活费支出情况,假设该调查员已经
完成了抽样,并获得样本情况(见样本文件),请根据此样本分别按性别、家庭所在地分层,并计算各层的样本量、平均生活费支出、生活费支出的方差及标准差。
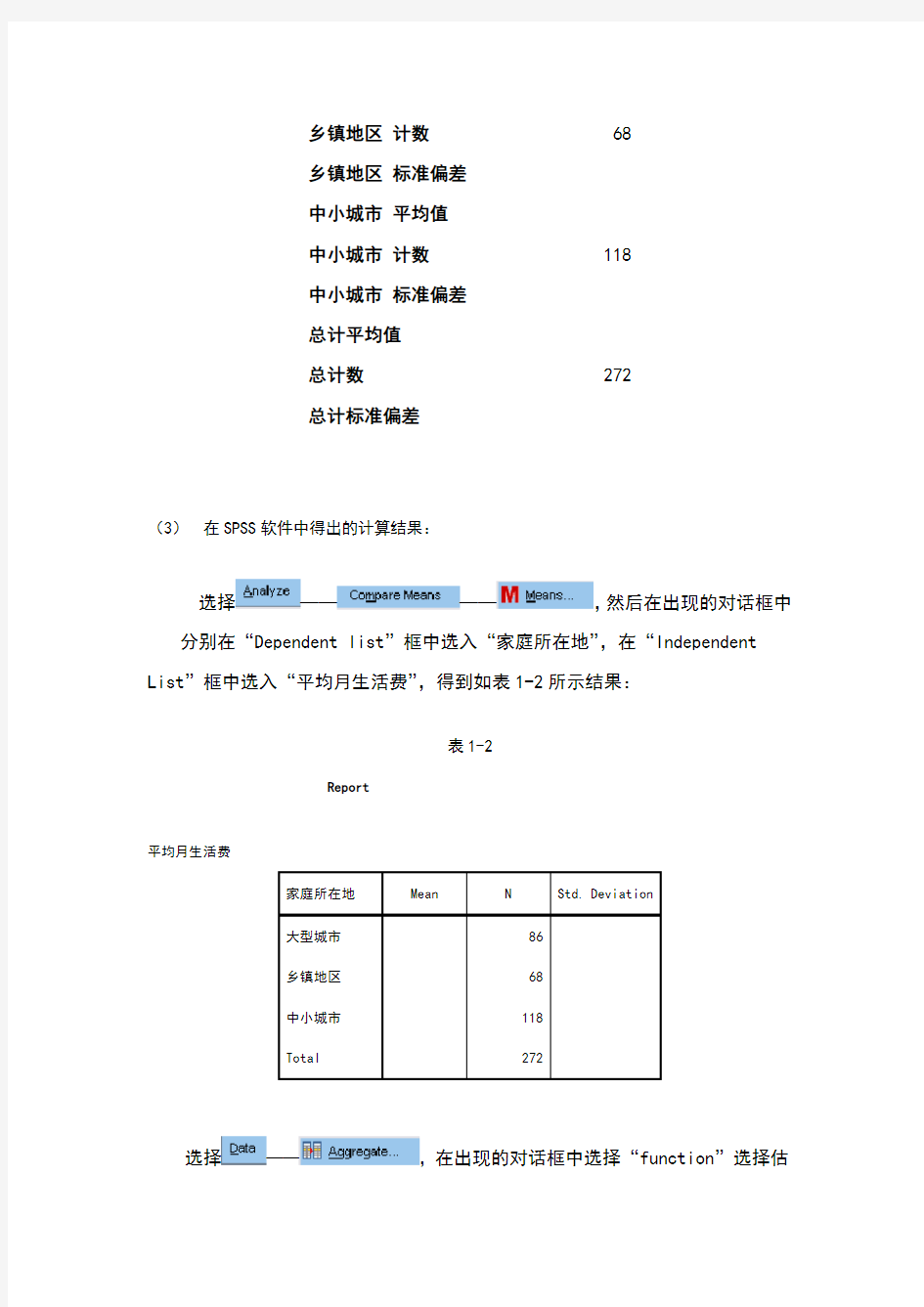
(1)先对数据按照家庭所在地进行排序:【数据】→【排序】,选择“家庭所在地”(2)再对数据进行分类汇总:【数据】→【分类汇总】,“分类字段”选择“家庭所在地”,“汇总方式”选择“平均值”,“选定汇总项”选择“平均月生活费”,在对话框下方选择“汇总结果显示在数据下方”;再做两次分类汇总,“汇总方式”分别选择“计数”和“标准偏差”。最后得到表1-1所示结果:
表1-1
家庭所在地平均月生活费
大型城市平均值
大型城市计数86
大型城市标准偏差
乡镇地区平均值
乡镇地区计数68
乡镇地区标准偏差
中小城市平均值
中小城市计数118
中小城市标准偏差
总计平均值
总计数272
总计标准偏差
(3)在SPSS软件中得出的计算结果:
选择————,然后在出现的对话框中分别在“Dependent list”框中选入“家庭所在地”,在“Independent List”框中选入“平均月生活费”,得到如表1-2所示结果:
表1-2
Report
平均月生活费
家庭所在地Mean N Std. Deviation
大型城市86
乡镇地区68
中小城市118
Total272
选择——,在出现的对话框中选择“function”选择估
计量,得到如图1-2所示结果:
图1-1
图1-2
选择————,出现如下图所示对话框,并按照下图1-3中所选项进行操作:
得到如下图表的结果:
Case Processing Summary
家庭所在地
Cases
Valid Missing Total
N Percent N Percent N Percent
平均月生活费大型城市86%0.0%86%乡镇地区68%0.0%68%
中小城市118%0.0%118%
Descriptives
家庭所在地Statistic Std. Error
平均月生活费大型城市Mean
95% Confidence Interval for Mean Lower Bound Upper Bound
Median
Variance
Std. Deviation
Minimum100
Maximum2500
Range2400
Interquartile Range
Skewness.260
Kurtosis.514乡镇地区Mean
95% Confidence Interval for Mean Lower Bound Upper Bound
5% Trimmed Mean
Median
Variance
Std. Deviation
Minimum200
Maximum1000
Range800
Interquartile Range
Skewness.996.291
Kurtosis.172.574中小城市Mean
95% Confidence Interval for Mean Lower Bound Upper Bound
Median
Variance
Std. Deviation
Minimum200
Maximum1200
Range1000
Interquartile Range
Skewness.686.223 Kurtosis.168.442
118
68
86
N =
家庭所在地
中小城市
乡镇地区大型城市平均月生活费
3000
2000
1000
-1000
199
124978986774035246
2、 教材129页第题
层
样本
1 10 10
2 0 20 10 0 10 30 20 2 20 35 10 50 0 40 50 10 20 20 3
20
30
30
50
40
30
(1)数据结构、运用Excel的计算步骤及结果如下:
层样本
110102020100103020
22035105004050102020
30200303050400300
sum8441
总样本量
比例分配
奈曼分配
比例分配
奈曼分配 奈曼分配层权 n1 w1 n2 w2 n3 w3 sum
1
第h 层的层权:N
N W h
h =
第h 层的样本均值:∑==
h
n i hi
h
h y
n y 1
1
第h 层的样本方差: )1/()(1
22--=∑=h n i h hi h
n y y s h
总体均值方差:h 2
L
h
h
h 2
h
n 1W )(?)(s f y V Y V st
∑-===
0483.1)96
.10678.20*%10()(
)(2
22/==?=αu Y r y V st 下面计算两种分配方法的样本量及每层要抽的样本量: 1.比例分配:
比例分配的层权为:h h W w = 故:n w n ?=21= 取整得1n =57
n w n ?=22= 取整得2n =93 n w n ?=33= 取整得3n =38
2.奈曼分配:
奈曼分配的层权为:∑==L
h h
h
h h h S
W S W w 1
/
故:n w n ?=21= 取整得1n =34
n w n ?=22= 取整得2n =99 n w n ?=33= 取整得3n =43
(2)在SPSS 中的计算均值与方差的结果如下:
Descriptives
Maximum30
Range30
Interquartile Range
Skewness.668.687
Kurtosis
2样本Mean
95% Confidence Interval for Mean Lower Bound Upper Bound
5% Trimmed Mean
Median
Variance
Std. Deviation
Minimum0
Maximum50
Range50
Interquartile Range
Skewness.330.687
Kurtosis
3样本Mean
95% Confidence Interval for Mean Lower Bound Upper Bound
5% Trimmed Mean
3、教材130页第题
Wh ah
27
28
27
26
28
29
426
528
629
sum1165
总体比例估计比例分配层权总体比例估计方差w1
总体比例估计标准差w2
V w3
w4
w5
总样本量w6
比例分配
奈曼分配
比例分配奈曼分
配奈曼分配层权
n1w1
n2w2
n3w3
n4w4
n5w5
n6w6
SUM1公式:
(1) 总体比例P 的简单估计量:
P Y =,h h P Y =,h p y st =.
按照总体均值估计量的公式,可推出总体比例(成数)P的估计量为:
h h
h
h h h ??p W P W P L L
st ∑∑===
(2) 总体比例P 的方差为
∑---=L
st n p p f W P V h h
h h h 2h 1)1()1()?(?=∑---L
h
h h h h h h 2
1
)
1()
(1n p p n N N N
(3) 第h 层的样本方差为:h h h h h h
h q p def q p n n S 1
2
-= (4) 样本总量:
若h N 较大,则2
h S ≈)1(h h P P -,此时可进一步求出估计P 时对给定的分配形式(h h nw n =)有:
∑∑-+-=
L
h
h h h h
h h h P P W N V w P P W n )
1(1)1(2
计算抽样的样本量:
在此题中,总体数量N 非常大,故,
0)1(1
1
≈-∑=L
h h
h
h
p
P W N
,
因此:由公式(4)得:
(比例分配的层权为:h h W w =)
各层的样本量为:n w n ?=21= 取整得1n =480
n w n ?=22= 取整得2n =560 n w n ?=33= 取整得3n =373
=?=n w n 44 取整得4n =240 =?=n w n 55 取整得5n =427 =?=n w n 66 取整得6n =586
(奈曼分配的层权为:∑==L
h h
h
h h h S
W S W w 1
/
)
各层的样本量为:n w n ?=21= 取整得1n =536
n w n ?=22= 取整得2n =520 n w n ?=33= 取整得3n =417
=?=n w n 44 取整得4n =304 =?=n w n 55 取整得5n =397 =?=n w n 66 取整得6n =392
【实验报告】SPSS相关分析实验报告
SPSS相关分析实验报告 篇一:spss对数据进行相关性分析实验报告 实验一 一.实验目的 掌握用spss软件对数据进行相关性分析,熟悉其操作过程,并能分析其结果。 二.实验原理 相关性分析是考察两个变量之间线性关系的一种统计分析方法。更精确地说,当一个变量发生变化时,另一个变量如何变化,此时就需要通过计算相关系数来做深入的定量考察。P值是针对原假设H0:假设两变量无线性相关而言的。一般假设检验的显著性水平为0.05,你只需要拿p值和0.05进行比较:如果p值小于0.05,就拒绝原假设H0,说明两变量有线性相关的关系,他们无线性相关的可能性小于0.05;如果大于0.05,则一般认为无线性相关关系,至于相关的程度则要看相关系数R值,r越大,说明越相关。越小,则相关程度越低。而偏相关分析是指当两个变量同时与第三个变量相关时,将第三个变量的影响剔除,只分析另外两个变量之间相关程度的过程,其检验过程与相关分析相似。三、实验内容 掌握使用spss软件对数据进行相关性分析,从变量之间的相关关系,寻求与人均食品支出密切相关的因素。 (1)检验人均食品支出与粮价和人均收入之间的相关关系。 a.打开spss软件,输入“回归人均食品支出”数据。
b.在spssd的菜单栏中选择点击,弹出一个对话窗口。 C.在对话窗口中点击ok,系统输出结果,如下表。 从表中可以看出,人均食品支出与人均收入之间的相关系数为0.921,t检验的显著性概率为0.0000.01,拒绝零假设,表明两个变量之间显著相关。人均食品支出与粮食平均单价之间的相关系数为0.730,t检验的显著性概率为 0.0000.01,拒绝零假设,表明两个变量之间也显著相关。 (2)研究人均食品支出与人均收入之间的偏相关关系。 读入数据后: A.点击系统弹出一个对话窗口。 B.点击OK,系统输出结果,如下表。 从表中可以看出,人均食品支出与人均收入的偏相关系数为0.8665,显著性概率p=0.0000.01,说明在剔除了粮食单价的影响后,人均食品支出与人均收入依然有显著性关系,并且0.86650.921,说明它们之间的显著性关系稍有减弱。通过相关关系与偏相关关系的比较可以得知:在粮价的影响下,人均收入对人均食品支出的影响更大。 三、实验总结 1、熟悉了用spss软件对数据进行相关性分析,熟悉其操作过程。 2、通过spss软件输出的数据结果并能够分析其相互之间的关系,并且解决实际问题。 3、充分理解了相关性分析的应用原理。
数据挖掘实验报告
《数据挖掘》Weka实验报告 姓名_学号_ 指导教师 开课学期2015 至2016 学年 2 学期完成日期2015年6月12日
1.实验目的 基于https://www.360docs.net/doc/4118540819.html,/ml/datasets/Breast+Cancer+WiscOnsin+%28Ori- ginal%29的数据,使用数据挖掘中的分类算法,运用Weka平台的基本功能对数据集进行分类,对算法结果进行性能比较,画出性能比较图,另外针对不同数量的训练集进行对比实验,并画出性能比较图训练并测试。 2.实验环境 实验采用Weka平台,数据使用来自https://www.360docs.net/doc/4118540819.html,/ml/Datasets/Br- east+Cancer+WiscOnsin+%28Original%29,主要使用其中的Breast Cancer Wisc- onsin (Original) Data Set数据。Weka是怀卡托智能分析系统的缩写,该系统由新西兰怀卡托大学开发。Weka使用Java写成的,并且限制在GNU通用公共证书的条件下发布。它可以运行于几乎所有操作平台,是一款免费的,非商业化的机器学习以及数据挖掘软件。Weka提供了一个统一界面,可结合预处理以及后处理方法,将许多不同的学习算法应用于任何所给的数据集,并评估由不同的学习方案所得出的结果。 3.实验步骤 3.1数据预处理 本实验是针对威斯康辛州(原始)的乳腺癌数据集进行分类,该表含有Sample code number(样本代码),Clump Thickness(丛厚度),Uniformity of Cell Size (均匀的细胞大小),Uniformity of Cell Shape (均匀的细胞形状),Marginal Adhesion(边际粘连),Single Epithelial Cell Size(单一的上皮细胞大小),Bare Nuclei(裸核),Bland Chromatin(平淡的染色质),Normal Nucleoli(正常的核仁),Mitoses(有丝分裂),Class(分类),其中第二项到第十项取值均为1-10,分类中2代表良性,4代表恶性。通过实验,希望能找出患乳腺癌客户各指标的分布情况。 该数据的数据属性如下: 1. Sample code number(numeric),样本代码; 2. Clump Thickness(numeric),丛厚度;
控制系统仿真与设计实验报告
控制系统仿真与设计实验报告 姓名: 班级: 学号: 指导老师:刘峰 7.2.2控制系统的阶跃响应 一、实验目的 1.观察学习控制系统的单位阶跃响应; 2.记录单位阶跃响应曲线; 3.掌握时间相应的一般方法; 二、实验内容 1.二阶系统G(s)=10/(s2+2s+10)
键入程序,观察并记录阶跃响应曲线;录系统的闭环根、阻尼比、无阻尼振荡频率;记录实际测去的峰值大小、峰值时间、过渡时间,并与理论值比较。 (1)实验程序如下: num=[10]; den=[1 2 10]; step(num,den); 响应曲线如下图所示: (2)再键入: damp(den); step(num,den); [y x t]=step(num,den); [y,t’] 可得实验结果如下:
记录实际测取的峰值大小、峰值时间、过渡时间,并与理论计算值值比较 实际值理论值 峰值 1.3473 1.2975
峰值时间 1.0928 1.0649 过渡时间+%5 2.4836 2.6352 +%2 3.4771 3.5136 2. 二阶系统G(s)=10/(s2+2s+10) 试验程序如下: num0=[10]; den0=[1 2 10]; step(num0,den0); hold on; num1=[10]; den1=[1 6.32 10]; step(num1,den1); hold on; num2=[10]; den2=[1 12.64 10]; step(num2,den2); 响应曲线:
(2)修改参数,分别实现w n1= (1/2)w n0和w n1= 2w n0响应曲线试验程序: num0=[10]; den0=[1 2 10]; step(num0,den0); hold on; num1=[2.5]; den1=[1 1 2.5]; step(num1,den1); hold on; num2=[40]; den2=[1 4 40]; step(num2,den2); 响应曲线如下图所示:
SPSS相关分析报告实验报告材料
本科教学实验报告 (实验)课程名称:数据分析技术系列实验
实验报告 学生姓名: 一、实验室名称: 二、实验项目名称:相关分析 三、实验原理 相关关系是不完全确定的随机关系。在相关关系的情况下,当一个或几个相互联系的变量取一定值得时候,与之相应的另一变量的值虽然不确定,但它仍然按照某种规律在一定的范围内变化。 按照数据度量的尺度不同,相关分析的方法也不同,连续变量之间的相关性常用Pearson简单相关系数测定;定序变量的相关系数常用Spearman秩相关系数和Kendall 秩相关系数测定;定类变量的相关分析要使用列连表分析法。 四、实验目的 理解相关分析的基本原理,掌握在SPSS软件中相关分析的主要参数设置及其含义,掌握SPSS软件分析结果的含义及其分析。 五、实验内容及步骤 实验内容:以雇员表为例,共有474条数据,运用相关分析方法对变量间的相关关系进行分析。
1)分析性别与工资之间是否存在相关关系。 2)分析教育程度与工资之间是否存在相关关系。 实验要求:掌握相关分析方法的计算思路及其在SPSS环境下的操作方法,掌握输出结果的解释。 1. 分析性别与工资之间是否存在相关关系。 分析:性别属于定类变量,是离散值,因使用卡方检验。 Step1.操作为Analyze \ Descriptive Statistics \ Crosstabs Step2.将性别(Gender)和收入(Current Salary)分别移入Rows列表框和Columns 列表框。
Step3.单击Statistics按钮,在弹出的子对话框中选中默认的Chi-square,进行卡方检验。退回到主对话框,单击ok。
数据挖掘实验报告(一)
数据挖掘实验报告(一) 数据预处理 姓名:李圣杰 班级:计算机1304 学号:1311610602
一、实验目的 1.学习均值平滑,中值平滑,边界值平滑的基本原理 2.掌握链表的使用方法 3.掌握文件读取的方法 二、实验设备 PC一台,dev-c++5.11 三、实验内容 数据平滑 假定用于分析的数据包含属性age。数据元组中age的值如下(按递增序):13, 15, 16, 16, 19, 20, 20, 21, 22, 22, 25, 25, 25, 25, 30, 33, 33, 35, 35, 35, 35, 36, 40, 45, 46, 52, 70。使用你所熟悉的程序设计语言进行编程,实现如下功能(要求程序具有通用性): (a) 使用按箱平均值平滑法对以上数据进行平滑,箱的深度为3。 (b) 使用按箱中值平滑法对以上数据进行平滑,箱的深度为3。 (c) 使用按箱边界值平滑法对以上数据进行平滑,箱的深度为3。 四、实验原理 使用c语言,对数据文件进行读取,存入带头节点的指针链表中,同时计数,均值求三个数的平均值,中值求中间的一个数的值,边界值将中间的数转换为离边界较近的边界值 五、实验步骤 代码 #include
哈工大_控制系统实践_磁悬浮实验报告
研究生自动控制专业实验 地点:A区主楼518房间 姓名:实验日期:年月日斑号:学号:机组编号: 同组人:成绩:教师签字:磁悬浮小球系统 实验报告 主编:钱玉恒,杨亚非 哈工大航天学院控制科学实验室
磁悬浮小球控制系统实验报告 一、实验内容 1、熟悉磁悬浮球控制系统的结构和原理; 2、了解磁悬浮物理模型建模与控制器设计; 3、掌握根轨迹控制实验设计与仿真; 4、掌握频率响应控制实验与仿真; 5、掌握PID控制器设计实验与仿真; 6、实验PID控制器的实物系统调试; 二、实验设备 1、磁悬浮球控制系统一套 磁悬浮球控制系统包括磁悬浮小球控制器、磁悬浮小球实验装置等组成。在控制器的前部设有操作面板,操作面板上有起动/停止开关,控制器的后部有电源开关。 磁悬浮球控制系统计算机部分 磁悬浮球控制系统计算机部分主要有计算机、1711控制卡等; 三、实验步骤 1、系统实验的线路连接 磁悬浮小球控制器与计算机、磁悬浮小球实验装置全部采用标准线连接,电源部分有标准电源线,考虑实验设备的使用便利,在试验前,实验装置的线路已经连接完毕。 2、启动实验装置 通电之前,请详细检察电源等连线是否正确,确认无误后,可接通控制器电源,随后起动计算机和控制器,在编程和仿真情况下,不要启动控制器。 系统实验的参数调试
根据仿真的数据及控制规则进行参数调试(根轨迹、频率、PID 等),直到获得较理想参数为止。 四、实验要求 1、学生上机前要求 学生在实际上机调试之前,必须用自己的计算机,对系统的仿真全部做完,并且经过老师的检查许可后,才能申请上机调试。 学生必须交实验报告后才能上机调试。 2、学生上机要求 上机的同学要按照要求进行实验,不得有违反操作规程的现象,严格遵守实验室的有关规定。 五、系统建模思考题 1、系统模型线性化处理是否合理,写出推理过程? 合理,推理过程: 由级数理论,将非线性函数展开为泰勒级数。由此证明,在平衡点)x ,(i 00对 系统进行线性化处理是可行的。 对式2x i K x i F )(),(=作泰勒级数展开,省略高阶项可得: )x -)(x x ,(i F )i -)(i x ,(i F )x ,F(i x)F(i,000x 000i 00++= )x -(x K )i -(i K )x ,F(i x)F(i,0x 0i 00++= 平衡点小球电磁力和重力平衡,有 (,)+=F i x mg 0 |,δδ===00 i 00 i i x x F(i,x) F(i ,x )i ;|,δδ===00x 00i i x x F(i,x)F (i ,x )x 对2 i F(i,x )K()x =求偏导数得:
数据挖掘实验报告资料
大数据理论与技术读书报告 -----K最近邻分类算法 指导老师: 陈莉 学生姓名: 李阳帆 学号: 201531467 专业: 计算机技术 日期 :2016年8月31日
摘要 数据挖掘是机器学习领域内广泛研究的知识领域,是将人工智能技术和数据库技术紧密结合,让计算机帮助人们从庞大的数据中智能地、自动地提取出有价值的知识模式,以满足人们不同应用的需要。K 近邻算法(KNN)是基于统计的分类方法,是大数据理论与分析的分类算法中比较常用的一种方法。该算法具有直观、无需先验统计知识、无师学习等特点,目前已经成为数据挖掘技术的理论和应用研究方法之一。本文主要研究了K 近邻分类算法,首先简要地介绍了数据挖掘中的各种分类算法,详细地阐述了K 近邻算法的基本原理和应用领域,最后在matlab环境里仿真实现,并对实验结果进行分析,提出了改进的方法。 关键词:K 近邻,聚类算法,权重,复杂度,准确度
1.引言 (1) 2.研究目的与意义 (1) 3.算法思想 (2) 4.算法实现 (2) 4.1 参数设置 (2) 4.2数据集 (2) 4.3实验步骤 (3) 4.4实验结果与分析 (3) 5.总结与反思 (4) 附件1 (6)
1.引言 随着数据库技术的飞速发展,人工智能领域的一个分支—— 机器学习的研究自 20 世纪 50 年代开始以来也取得了很大进展。用数据库管理系统来存储数据,用机器学习的方法来分析数据,挖掘大量数据背后的知识,这两者的结合促成了数据库中的知识发现(Knowledge Discovery in Databases,简记 KDD)的产生,也称作数据挖掘(Data Ming,简记 DM)。 数据挖掘是信息技术自然演化的结果。信息技术的发展大致可以描述为如下的过程:初期的是简单的数据收集和数据库的构造;后来发展到对数据的管理,包括:数据存储、检索以及数据库事务处理;再后来发展到对数据的分析和理解, 这时候出现了数据仓库技术和数据挖掘技术。数据挖掘是涉及数据库和人工智能等学科的一门当前相当活跃的研究领域。 数据挖掘是机器学习领域内广泛研究的知识领域,是将人工智能技术和数据库技术紧密结合,让计算机帮助人们从庞大的数据中智能地、自动地抽取出有价值的知识模式,以满足人们不同应用的需要[1]。目前,数据挖掘已经成为一个具有迫切实现需要的很有前途的热点研究课题。 2.研究目的与意义 近邻方法是在一组历史数据记录中寻找一个或者若干个与当前记录最相似的历史纪录的已知特征值来预测当前记录的未知或遗失特征值[14]。近邻方法是数据挖掘分类算法中比较常用的一种方法。K 近邻算法(简称 KNN)是基于统计的分类方法[15]。KNN 分类算法根据待识样本在特征空间中 K 个最近邻样本中的多数样本的类别来进行分类,因此具有直观、无需先验统计知识、无师学习等特点,从而成为非参数分类的一种重要方法。 大多数分类方法是基于向量空间模型的。当前在分类方法中,对任意两个向量: x= ) ,..., , ( 2 1x x x n和) ,..., , (' ' 2 ' 1 'x x x x n 存在 3 种最通用的距离度量:欧氏距离、余弦距 离[16]和内积[17]。有两种常用的分类策略:一种是计算待分类向量到所有训练集中的向量间的距离:如 K 近邻选择K个距离最小的向量然后进行综合,以决定其类别。另一种是用训练集中的向量构成类别向量,仅计算待分类向量到所有类别向量的距离,选择一个距离最小的类别向量决定类别的归属。很明显,距离计算在分类中起关键作用。由于以上 3 种距离度量不涉及向量的特征之间的关系,这使得距离的计算不精确,从而影响分类的效果。
过程控制系统实验报告
实验一过程控制系统的组成认识实验 过程控制及检测装置硬件结构组成认识,控制方案的组成及控制系统连接 一、过程控制实验装置简介 过程控制是指自动控制系统中被控量为温度、压力、流量、液位等变量在工业生产过程中的自动化控制。本系统设计本着培养工程化、参数化、现代化、开放性、综合性人才为出发点。实验对象采用当今工业现场常用的对象,如水箱、锅炉等。仪表采用具有人工智能算法及通讯接口的智能调节仪,上位机监控软件采用MCGS工控组态软件。对象系统还留有扩展连接口,扩展信号接口便于控制系统二次开发,如PLC控制、DCS控制开发等。学生通过对该系统的了解和使用,进入企业后能很快地适应环境并进入角色。同时该系统也为教师和研究生提供一个高水平的学习和研究开发的平台。 二、过程控制实验装置组成 本实验装置由过程控制实验对象、智能仪表控制台及上位机PC三部分组成。 1、被控对象 由上、下二个有机玻璃水箱和不锈钢储水箱串接,4.5千瓦电加热锅炉(由不锈钢锅炉内胆加温筒和封闭外循环不锈钢锅炉夹套构成),压力容器组成。 水箱:包括上、下水箱和储水箱。上、下水箱采用透明长方体有机玻璃,坚实耐用,透明度高,有利于学生直接观察液位的变化和记录结果。水箱结构新颖,内有三个槽,分别是缓冲槽、工作槽、出水槽,还设有溢流口。二个水箱可以组成一阶、二阶单回路液位控制实验和双闭环液位定值控制等实验。 模拟锅炉:锅炉采用不锈钢精致而成,由两层组成:加热层(内胆)和冷却层(夹套)。做温度定值实验时,可用冷却循环水帮助散热。加热层和冷却层都有温度传感器检测其温度,可做温度串级控制、前馈-反馈控制、比值控制、解耦控制等实验。 压力容器:采用不锈钢做成,一大一小两个连通的容器,可以组成一阶、二阶单回路压力控制实验和双闭环串级定值控制等实验。 管道:整个系统管道采用不锈钢管连接而成,彻底避免了管道生锈的可能性。为了提高实验装置的使用年限,储水箱换水可用箱底的出水阀进行。 2、检测装置 (液位)差压变送器:检测上、下二个水箱的液位。其型号:FB0803BAEIR,测量范围:0~1.6KPa,精度:0.5。输出信号:4~20mA DC。 涡轮流量传感器:测量电动调节阀支路的水流量。其型号:LWGY-6A,公称压力:6.3MPa,精度:1.0%,输出信号:4~20mA DC 温度传感器:本装置采用了两个铜电阻温度传感器,分别测量锅炉内胆、锅炉夹套的温度。经过温度传感器,可将温度信号转换为4~20mA DC电流信号。 (气体)扩散硅压力变送器:用来检测压力容器内气体的压力大小。其型号:DBYG-4000A/ST2X1,测量范围:0.6~3.5Mpa连续可调,精度:0.2,输出信号为4~20mA DC。 3、执行机构 电气转换器:型号为QZD-1000,输入信号为4~20mA DC,输出信号:20~100Ka气压信号,输出用来驱动气动调节阀。 气动薄膜小流量调节阀:用来控制压力回路流量的调节。型号为ZMAP-100,输入信号为4~20mA DC或0~5V DC,反馈信号为4~20mA DC。气源信号 压力:20~100Kpa,流通能力:0.0032。阀门控制精度:0.1%~0.3%,环境温度:-4~+200℃。 SCR移相调压模块:采用可控硅移相触发装置,输入控制信号0~5V DC或4~20mA DC 或10K电位器,输出电压变化范围:0~220V AC,用来控制电加热管加热。 水泵:型号为UPA90,流量为30升/分,扬程为8米,功率为180W。
社会调查实验报告
专业:J信息1101 学号:4111118002 姓名:彭倩 社会调查实验报告 在这次社会调查实验中,我了解到CATI,即计算机辅助电话访问(Computer Assisted Telephone Interview),是将近年高速发展的通讯技术及计算机信息处理技术应用于传统的电话访问所得到的产物,问世以来得到越来越广泛的应用。它是在加深对中国调查业的理解和对国外同类软件研究的基础上,自主开发了这套符合中国国情的系统。 CATI是具有高技术含量、高专业性和高实用性的电话调研产品。自20世纪70年代诞生以来,计算机辅助电话调查以其可控性高、时效性强等特点越来越为研究者所接受。在信息挂帅的今天,CATI系统更被视为收集资料、分析数据的利器,在商业、学术以及政府调研行为中得到了广泛应用。 从社会调查实验中,我们也可以了解到CATI项目整体业务流程如下:
通过利用CATI系统,我知道了计算机辅助电话访问就是用计算机为媒介设计问卷,用电话向被调查者进行访问。从而让计算机代替了问卷、答案纸和铅笔。通过计算机拨打所要的号码,电话接通之后,调查员就读出计算机屏幕上显示出的问答题并直接将被调查者的回答(用号码表示)用键盘记入计算机的记忆库之中。计算机会系统地指引整个业务流程。问卷可以直接在计算机中设计、调试,抽样过程可以大大简化,配额也完全由计算机系统自动控制,问卷执行时所有的问卷内部的流程和逻辑都有计算机内部控制,并且计算机会检查答案的适当性和一致性。 从中我感受到计算机收集数据的过程是自然的、平稳的,而且访问时间大大缩减,数据质量得到了加强,数据的录入等过程也不再需要,编码也可以统一的自动实现。由于回答是直接输入计算机的,关于数据收集和结果的阶段性的和最新的报告几乎可以立刻就得到。同时CATI可以提供更高效更全面透明的监控方式,所有的话务监控、通话录音、监听、监看都在一个独立的计算机上执行,大大减低了对访问过程的产生干扰的可能性。采用这种访问调查方式,具有调查内容客观真实、保密性强、访问效率高等特点。 在这次社会调查中,我深刻的感受到CATI在社会调查访问中具有强大的功能。 1、实效快。省去了传统调查所必须的印刷问卷、上门入户或邮寄问卷、审核问卷、数据录入等环节,在短时间内即可完成调查,访问结束后几十分钟内即可汇总数据,周期较短。
数据挖掘实验报告-关联规则挖掘
数据挖掘实验报告(二)关联规则挖掘 姓名:李圣杰 班级:计算机1304 学号:1311610602
一、实验目的 1. 1.掌握关联规则挖掘的Apriori算法; 2.将Apriori算法用具体的编程语言实现。 二、实验设备 PC一台,dev-c++5.11 三、实验内容 根据下列的Apriori算法进行编程:
四、实验步骤 1.编制程序。 2.调试程序。可采用下面的数据库D作为原始数据调试程序,得到的候选1项集、2项集、3项集分别为C1、C2、C3,得到的频繁1项集、2项集、3项集分别为L1、L2、L3。
代码 #include 自动控制系统实验报告 学号: 班级: 姓名: 老师: 一.运动控制系统实验 实验一.硬件电路的熟悉和控制原理复习巩固 实验目的:综合了解运动控制实验仪器机械结构、各部分硬件电路以及控制原理,复习巩固以前课堂知识,为下阶段实习打好基础。 实验内容:了解运动控制实验仪的几个基本电路: 单片机控制电路(键盘显示电路最小应用系统、步进电机控制电路、光槽位置检测电路) ISA运动接口卡原理(搞清楚译码电路原理和ISA总线原理) 步进电机驱动检测电路原理(高低压恒流斩波驱动电路原理、光槽位置检测电路)两轴运动十字工作台结构 步进电机驱动技术(掌握步进电机三相六拍、三相三拍驱动方法。) 微机接口技术、单片机原理及接口技术,数控轮廓插补原理,计算机高级语言硬件编程等知识。 实验结果: 步进电机驱动技术: 控制信号接口: (1)PUL:单脉冲控制方式时为脉冲控制信号,每当脉冲由低变高是电机走一步;双 脉冲控制方式时为正转脉冲信号。 (2)DIR:单脉冲控制方式时为方向控制信号,用于改变电机转向;双脉冲控制方式 时为反转脉冲信号。 (3)OPTO :为PUL 、DIR 、ENA 的共阳极端口。 (4)ENA :使能/禁止信号,高电平使能,低电平时驱动器不能工作,电机处于自由状 态。 电流设定: (1)工作电流设定: (2)静止电流设定: 静态电流可用SW4 拨码开关设定,off 表示静态电流设为动态电流的一半,on 表示静态电流与动态电流相同。一般用途中应将SW4 设成off ,使得电机和驱动器的发热减少,可靠性提高。脉冲串停止后约0.4 秒左右电流自动减至一半左右(实际值的60%),发热量理论上减至36%。 (3)细分设定: (4)步进电机的转速与脉冲频率的关系 电机转速v = 脉冲频率P * 电机固有步进角e / (360 * 细分数m) 逐点比较法的直线插补和圆弧插补: 一.直线插补原理: 如图所示的平面斜线AB ,以斜线起点A 的坐标为x0,y0,斜线AB 的终点坐标为(xe ,ye),则此直线方程为: 00 00Y Ye X Xe Y Y X X --= -- 取判别函数F =(Y —Y0)(Xe —Xo)—(X-X0)(Ye —Y0) 实验报告 实验思考题: 1、某调查员欲从某大学所有学生中抽样调查学生平均生活费支出情况,假设该调查员已经 完成了抽样,并获得样本情况(见样本文件),请根据此样本分别按性别、家庭所在地分层,并计算各层的样本量、平均生活费支出、生活费支出的方差及标准差。 (1)先对数据按照家庭所在地进行排序:【数据】→【排序】,选择“家庭所在地”(2)再对数据进行分类汇总:【数据】→【分类汇总】,“分类字段”选择“家庭所在地”,“汇总方式”选择“平均值”,“选定汇总项”选择“平均月生活费”,在对话框下方选择“汇总结果显示在数据下方”;再做两次分类汇总,“汇总方式”分别选择“计数”和“标准偏差”。最后得到表1-1所示结果: 表1-1 家庭所在地平均月生活费 大型城市平均值614.5348837 大型城市计数86 大型城市标准偏差300.0849173 乡镇地区平均值529.4117647 乡镇地区计数68 乡镇地区标准偏差219.0950339 中小城市平均值618.6440678 中小城市计数118 中小城市标准偏差202.5264159 总计平均值595.0367647 总计数272 总计标准偏差243.4439223 (3)在SPSS软件中得出的计算结果: 选择————,然后在出现的对话框中 分别在“Dependent list”框中选入“家庭所在地”,在“Independent List”框中选入“平均月生活费”,得到如表1-2所示结果: 表1-2 Report 平均月生活费 家庭所在地Mean N Std. Deviation 大型城市614.5386300.085 乡镇地区529.4168219.095 中小城市618.64118202.526 Total595.04272243.444 选择——,在出现的对话框中选择“function”选择估计量,得到如图1-2所示结果: 图1-1 图1-2 实验五相关分析实验报关费 一、实验目的: 学习利用spss对数据进行相关分析(积差相关、肯德尔等级相关)、偏相关分析。利用交叉表进行相关分析。 二、实验内容: 某班学生成绩表1如实验图表所示。 1.对该班物理成绩与数学成绩之间进行积差相关分析和肯德尔等级相关 分析。 2.在控制物理成绩不变的条件下,做数学成绩与英语成绩的相关分析(这 种情况下的相关分析称为偏相关分析)。 3.对该班物理成绩与数学成绩制作交叉表及进行其中的相关分析。 三、实验步骤: 1.选择分析→相关→双变量,弹出窗口,在对话框的变量列表中选变量 “数学成绩”、“物理成绩”,在相关系数列进行选择,本次实验选择 皮尔逊相关(积差相关)和肯德尔等级相关。单击选项,对描述统计 量进行选择,选择标准差和均值。单击确定,得出输出结果,对结果 进行分析解释。 2.选择分析→相关→偏相关,弹出窗口,在对话框的变量列表选变量“数 学成绩”、“英语成绩”,在控制列表选择要控制的变量“物理成绩” 以在控制物理成绩的影响下对变量数学成绩与英语成绩进行偏相关分 析;在“显著性检验”框中选双侧检验,单击确定,得出输出结果, 对结果进行分析解释。 3.选择分析→描述统计→交叉表,弹出窗口,对交叉表的行和列进行选 择,行选择为数学成绩,列选择为物理成绩。然后对统计量进行设置, 选择相关性,点击继续→确定,得出输出结果,对结果进行分析解释。 四、实验结果与分析: 表1 五、实验结果及其分析: 分析一:由实验结果可观察出,数学成绩与物理成绩的积差相关系数r=,肯德尔等级相关系数r=可知该班物理成绩和数学成绩之间存在显著相关。 一、实验目的 使用数据挖掘中的分类算法,对数据集进行分类训练并测试。应用不同的分类算法,比较他们之间的不同。与此同时了解Weka平台的基本功能与使用方法。 二、实验环境 实验采用Weka 平台,数据使用Weka安装目录下data文件夹下的默认数据集iris.arff。 Weka是怀卡托智能分析系统的缩写,该系统由新西兰怀卡托大学开发。Weka使用Java 写成的,并且限制在GNU通用公共证书的条件下发布。它可以运行于几乎所有操作平台,是一款免费的,非商业化的机器学习以及数据挖掘软件。Weka提供了一个统一界面,可结合预处理以及后处理方法,将许多不同的学习算法应用于任何所给的数据集,并评估由不同的学习方案所得出的结果。 三、数据预处理 Weka平台支持ARFF格式和CSV格式的数据。由于本次使用平台自带的ARFF格式数据,所以不存在格式转换的过程。实验所用的ARFF格式数据集如图1所示 图1 ARFF格式数据集(iris.arff) 对于iris数据集,它包含了150个实例(每个分类包含50个实例),共有sepal length、sepal width、petal length、petal width和class五种属性。期中前四种属性为数值类型,class属性为分类属性,表示实例所对应的的类别。该数据集中的全部实例共可分为三类:Iris Setosa、Iris Versicolour和Iris Virginica。 实验数据集中所有的数据都是实验所需的,因此不存在属性筛选的问题。若所采用的数据集中存在大量的与实验无关的属性,则需要使用weka平台的Filter(过滤器)实现属性的筛选。 实验所需的训练集和测试集均为iris.arff。 四、实验过程及结果 应用iris数据集,分别采用LibSVM、C4.5决策树分类器和朴素贝叶斯分类器进行测试和评价,分别在训练数据上训练出分类模型,找出各个模型最优的参数值,并对三个模型进行全面评价比较,得到一个最好的分类模型以及该模型所有设置的最优参数。最后使用这些参数以及训练集和校验集数据一起构造出一个最优分类器,并利用该分类器对测试数据进行预测。 1、LibSVM分类 Weka 平台内部没有集成libSVM分类器,要使用该分类器,需要下载libsvm.jar并导入到Weka中。 用“Explorer”打开数据集“iris.arff”,并在Explorer中将功能面板切换到“Classify”。点“Choose”按钮选择“functions(weka.classifiers.functions.LibSVM)”,选择LibSVM分类算法。 在Test Options 面板中选择Cross-Validatioin folds=10,即十折交叉验证。然后点击“start”按钮: 哈尔滨理工大学实验报告 控制系统仿真 专业:自动化12-1 学号:1230130101 姓名: 一.分析系统性能 课程名称控制系统仿真实验名称分析系统性能时间8.29 地点3# 姓名蔡庆刚学号1230130101 班级自动化12-1 一.实验目的及内容: 1. 熟悉MATLAB软件的操作过程; 2. 熟悉闭环系统稳定性的判断方法; 3. 熟悉闭环系统阶跃响应性能指标的求取。 二.实验用设备仪器及材料: PC, Matlab 软件平台 三、实验步骤 1. 编写MATLAB程序代码; 2. 在MATLAT中输入程序代码,运行程序; 3.分析结果。 四.实验结果分析: 1.程序截图 得到阶跃响应曲线 得到响应指标截图如下 2.求取零极点程序截图 得到零极点分布图 3.分析系统稳定性 根据稳定的充分必要条件判别线性系统的稳定性最简单的方法是求出系统所有极点,并观察是否含有实部大于0的极点,如果有系统不稳定。有零极点分布图可知系统稳定。 二.单容过程的阶跃响应 一、实验目的 1. 熟悉MATLAB软件的操作过程 2. 了解自衡单容过程的阶跃响应过程 3. 得出自衡单容过程的单位阶跃响应曲线 二、实验内容 已知两个单容过程的模型分别为 1 () 0.5 G s s =和5 1 () 51 s G s e s - = + ,试在 Simulink中建立模型,并求单位阶跃响应曲线。 三、实验步骤 1. 在Simulink中建立模型,得出实验原理图。 2. 运行模型后,双击Scope,得到的单位阶跃响应曲线。 四、实验结果 1.建立系统Simulink仿真模型图,其仿真模型为 3.3 3.3 经调查研究发现,家庭书刊消费受家庭收入及户主受教育年数的影响,表3.6为对某地区部分家庭抽样调查得到的样本数据。 表3.6 家庭书刊消费、家庭收入及户主受教育年数数据 (1)作家庭书刊消费(Y )对家庭月平均收入(X )和户主受教育年数(T )的多元线性回归: 1 2 3 i i i i u Y X T βββ=+++ 利用样本数据估计模型的参数,对模型加以检验,分析所估计模型的经济意义和作用。 步骤: 1.打开EViews6,点“File ”→“New ”→“Workfile ”。选择 “Unstructured/Unda=ted ”在Observations 后输入18,点击ok 。 2. 在命令行输入:DATA Y X T,回车。将数据复制粘贴到Group中的表格中。 3. 建立数据关系图为初步观察数据的关系,在命令行输入命令:sort Y,从而实现数据Y的递增排序。 4. 在数据表“group”中点“view/graph/line”,最后点击确定,出现序列Y、X、T 的线性图。 5. OLS 估计参数,点击主界面菜单Quick\Estimate Equation ,弹出对话框,如下图。在其中输入Y c X T ,点确定即可得到回归结果。 ()()()()()() 2 2 50.01620.0864552.3703 49.46026 0.02936 5.20217 t= 1.011244 2.944186 10.067020.951235 =0.944732 F=146.2974 ?i i i X T Y R R =-++-= 经济意义:家庭月平均收入每增加1元,家庭书刊消费将增加0.08645 元。户主受教育年数每 实验一 ID3算法实现 一、实验目的 通过编程实现决策树算法,信息增益的计算、数据子集划分、决策树的构建过程。加深对相关算法的理解过程。 实验类型:验证 计划课间:4学时 二、实验内容 1、分析决策树算法的实现流程; 2、分析信息增益的计算、数据子集划分、决策树的构建过程; 3、根据算法描述编程实现算法,调试运行; 4、对所给数据集进行验算,得到分析结果。 三、实验方法 算法描述: 以代表训练样本的单个结点开始建树; 若样本都在同一个类,则该结点成为树叶,并用该类标记; 否则,算法使用信息增益作为启发信息,选择能够最好地将样本分类的属性; 对测试属性的每个已知值,创建一个分支,并据此划分样本; 算法使用同样的过程,递归形成每个划分上的样本决策树 递归划分步骤,当下列条件之一成立时停止: 给定结点的所有样本属于同一类; 没有剩余属性可以进一步划分样本,在此情况下,采用多数表决进行 四、实验步骤 1、算法实现过程中需要使用的数据结构描述: Struct {int Attrib_Col; // 当前节点对应属性 int Value; // 对应边值 Tree_Node* Left_Node; // 子树 Tree_Node* Right_Node // 同层其他节点 Boolean IsLeaf; // 是否叶子节点 int ClassNo; // 对应分类标号 }Tree_Node; 2、整体算法流程 主程序: InputData(); T=Build_ID3(Data,Record_No, Num_Attrib); OutputRule(T); 释放内存; 3、相关子函数: 3.1、 InputData() { 输入属性集大小Num_Attrib; 输入样本数Num_Record; 分配内存Data[Num_Record][Num_Attrib]; 输入样本数据Data[Num_Record][Num_Attrib]; 获取类别数C(从最后一列中得到); } 3.2、Build_ID3(Data,Record_No, Num_Attrib) { Int Class_Distribute[C]; If (Record_No==0) { return Null } N=new tree_node(); 计算Data中各类的分布情况存入Class_Distribute Temp_Num_Attrib=0; For (i=0;i 第五章仿真及实验 第一节晶闸管直流调速系统参数和环节特性的测定 一、实验目的 1 熟悉晶闸管直流调速系统的组成及其基本结构。 2掌握晶闸管直流调速系统参数及反馈环节测定方法。 二、实验原理 晶闸管直流调速系统由整流变压器、晶闸管整流跳水装置、平波电抗器、电动机-发电机组等组成。 在本实验中,整流装置的主电路喂三相桥式电路,控制电路可直接由给定电压Ug作为触发器的移相控制电压Ua。改变Ug的大小即可改变控制角a,从而获得可调的直流电压,以满足实验要求。实验系统的组成原理如图5.1所示。 三.实验内容 1测定晶闸管直流调速系统主电路总电阻值R。 2测定晶闸管直流系统电路电感值L.. 3测定直流电机-直流发电机-测速发电机的飞轮惯量GD的平方。 4测定晶闸管直流调速系统主电路电磁时间常数Td。 5测定直流电动机电势常数Ce和转矩常数Cm。 6测定晶闸管直流调速系统机电时间常数Tm。 7测定晶闸管触发及整流装置特性Ud=f(Ue)。 8测定测速发电机特性Utg=f(n)。 四.实验仿真 晶闸管直流调速系统的原理如图5.1所示。该系统由给定信号、同步脉冲触发器、晶闸管整流桥、平波电抗器、直流电动机等部分组成。图5.2势采用面向电气原理图方法构成的晶闸管直流系统的仿真模型。下面介绍各部分建模与参数设置过程。 1.系统的建模和模型参数设置 系统的建模包括主电路的建模和控制电路的建模俩部分。 1)主电路的建模和参数设置 由图5.2可见,开环直流调速系统的主电路由三相对称交流电压器、晶闸管整流桥、平波电抗器、直流电动机等部分组成。由于同步脉冲与晶闸管整流桥是不可分割的两个环节,通常作为一个组合体讨论,所以将触发器归到主电路进行建模。 2)三相整流桥时,桥臂数取3,A,B,C三相交流电源接到整流桥的输入端,自动控制系统实验报告
抽样调查-分层抽样实验报告
spss相关分析实验报告
大数据挖掘weka大数据分类实验报告材料
控制系统仿真实验报告
最新版计量经济学实验报告
数据挖掘实验报告1
实验一电力拖动自动控制系统实验报告